论文解读:SuperPoint: Self-Supervised Interest Point Detection and Description

发表时间: 2018年
项目地址:https://arxiv.org/abs/1712.07629
论文地址:https://github.com/magicleap/SuperPointPretrainedNetwork
本文提出了一种用于训练计算机视觉中大量多视点几何问题的兴趣点检测器和描述符的自监督框架。与patch-based的神经网络相比,我们的全卷积模型处理全尺寸的图像,并在一次前向传播中计算像素级的特征点和特征描述符。我们引入单应性自适应,这是一种多尺度、多单应性方法,用于提高兴趣点检测重复性并执行跨域自适应(例如,合成到真实)。我们的模型在使用同态的MS-COCO通用图像数据集自适应,能够重复检测更丰富的集合与初始预适应深度模型相比以及任何其他传统的角检测器。最终系统结果与LIFT、SIFT和ORB相比,产生了最先进的单应性估计。
1、 关键点
一种使用自我训练的自监督(self-training)解决方案,而不是使用人类监督来定义真实图像中的兴趣点。不需要人工标记数据,仅依赖于模型的迭代提升性能。
1.1 训练机制
通过对单个图像进行单适应性变化(透视变化),形成Image Pair,以孪生网络的机制进行训练

1.2 训练步骤
所有的训练都是使用PyTorch [19]完成的,默认参数为lr = 0.001和β =(0.9,0.999)的ADAM求解器(0.999)。我们还使用了标准的数据增强技术,如随机高斯噪声、运动模糊、亮度水平的变化,以提高网络对照明和视点变化的鲁棒性。
1、兴趣点预训练
先基于点和线等基本图形伪造了一个基本数据集:synthetic data,然后使用该数据集训练模型。synthetic data包含上百万的合成形状的数据集,形状都是由简单的几何图形(多边形、弧形、圆等图形)组成,在兴趣点(角点、定点)上是没有争议的(如)。该步骤训练出来的模型称之为MagicPoint,只能提取特征点,在该步骤进行了超过 200,000次的迭代训练(实时动态训练数据不重复)
synthetic data:
- 基本形状:四边形、三角形、线和椭圆的合成数据渲染,由简化的二维几何组成
- 歧义消除:使用Y连接、T连接、L连接、椭圆中心点、线条端点为特征点,以此消除歧义
- 鲁棒性增强:对每个随机样本进行单适应变化,数据全为动态生成不重复
数据集示意如下:

2、兴趣点自监督
MagicPoint在shape上效果较好,但是域适应能力有限(在伪数据上训练,在真实数据上测试),与经典检测器相比,遗失了不少兴趣点。 为此,提出一种多尺度、多变换技术–Homographic Adaptation方法。将多尺度变化、仿射变化所生成的伪标签还原到原始图像中,用于生成最终的伪标签,用于提升检测器的特征点提取能力。该步骤训练出来的模型为SuperPoint,只能提取特征点,在COCO 2014数据集上训练,约80000多个图像(读取为灰度图),size为240x320,自监督时数据单适应变化参数NhN_hNh=100,该操作重复了两次。
方法的具体运算流程如下:

3、联合训练
在检测到鲁棒和可重复的兴趣点后,最常见的步骤是在每个点上附加一个固定的维度描述符向量,用于更高层次的语义任务,例如,图像匹配。最后将SuperPoint与一个描述符子网络结合起来(参见图2c)。由于超级点架构由一个深层的卷积层组成,它可以提取多尺度特征,因此可以直接将兴趣点网络与一个计算兴趣点描述符的附加子网络结合起来。该步骤训练出来的模型为SuperPoint,在提取提取特征点的基础上增加了特征描述符。

2、网络结构
SuperPoint在全尺寸的图像上运行,一次前向传播即可输出特征点和特征描述符(以往的方法需要两次,特征点与描述符要分开计算,缺乏共享),网络结构如下图所示,有一个共享的encoder部分。

2.1 实现代码
实现代码如下所示,是一个vgg风格的模型
class SuperPointNet(torch.nn.Module):""" Pytorch definition of SuperPoint Network. """def __init__(self):super(SuperPointNet, self).__init__()self.relu = torch.nn.ReLU(inplace=True)self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)c1, c2, c3, c4, c5, d1 = 64, 64, 128, 128, 256, 256# Shared Encoder.self.conv1a = torch.nn.Conv2d(1, c1, kernel_size=3, stride=1, padding=1)self.conv1b = torch.nn.Conv2d(c1, c1, kernel_size=3, stride=1, padding=1)self.conv2a = torch.nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1)self.conv2b = torch.nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1)self.conv3a = torch.nn.Conv2d(c2, c3, kernel_size=3, stride=1, padding=1)self.conv3b = torch.nn.Conv2d(c3, c3, kernel_size=3, stride=1, padding=1)self.conv4a = torch.nn.Conv2d(c3, c4, kernel_size=3, stride=1, padding=1)self.conv4b = torch.nn.Conv2d(c4, c4, kernel_size=3, stride=1, padding=1)# Detector Head.self.convPa = torch.nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)self.convPb = torch.nn.Conv2d(c5, 65, kernel_size=1, stride=1, padding=0)# Descriptor Head.self.convDa = torch.nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)self.convDb = torch.nn.Conv2d(c5, d1, kernel_size=1, stride=1, padding=0)def forward(self, x):""" Forward pass that jointly computes unprocessed point and descriptortensors.Inputx: Image pytorch tensor shaped N x 1 x H x W.Outputsemi: Output point pytorch tensor shaped N x 65 x H/8 x W/8.desc: Output descriptor pytorch tensor shaped N x 256 x H/8 x W/8."""# Shared Encoder.x = self.relu(self.conv1a(x))x = self.relu(self.conv1b(x))x = self.pool(x)x = self.relu(self.conv2a(x))x = self.relu(self.conv2b(x))x = self.pool(x)x = self.relu(self.conv3a(x))x = self.relu(self.conv3b(x))x = self.pool(x)x = self.relu(self.conv4a(x))x = self.relu(self.conv4b(x))# Detector Head.cPa = self.relu(self.convPa(x))semi = self.convPb(cPa)# Descriptor Head.cDa = self.relu(self.convDa(x))desc = self.convDb(cDa)dn = torch.norm(desc, p=2, dim=1) # Compute the norm.desc = desc.div(torch.unsqueeze(dn, 1)) # Divide by norm to normalize.output = {'semi': semi, 'desc': desc}self.output = outputreturn output
2.2 Shared Encoder
SuperPoint使用了一个VGG风格的[27]编码器来降低图像的size。该编码器由卷积层、池化空间降采样和非线性激活函数组成。编码器使用三个最大池层,其输出的特征图size在长宽上均为原图的1/8,及输出图的一个坐标点对应原图8x8的区域.此时,特征图的channel为256,相比于原图,具有更小的空间维度和更大的通道深度。
2.3 Interest Point Decoder
对于兴趣点检测,输出的每个像素对应于输入中该像素的“关键点”概率。head为两个conv的堆叠,实现代码为self.convPb(self.relu(self.convPa(x))),具体输出的特征维度为65维,即特征图上的一个像素点有65维,其中有64维对应着原图中一个不重叠的8x8区域,第65维作为垃圾桶(表示该区域没有特征点)。在后续步骤中,可以通过reshape操作,即可得到原图大小的特征点概率图,具体运算步骤如下:
Hc=H/8RHc×Wc×64⇒RH×WH_c=H/8 \\ \mathbb{R}^{H_{c} \times W_{c} \times 64} \Rightarrow \mathbb{R}^{H \times W} Hc=H/8RHc×Wc×64⇒RH×W
2.4 Descriptor Decoder
特征描述符的提取与特征点提取类似,也为两个conv的堆叠,head实现代码为desc = self.convDb( self.relu(self.convDa(x)))。该head输出的特征图最终为N x 256 x H/8 x W/8,可以理解为原图8x8的区域像素都共用一个特征描述符。在输出时,对desc进行了L2归一化(整体值除以某个维度的2范数)。计算过程中shape变化如下:
import torch
desc=torch.rand((8,256,40,40)) # 模拟Descriptor Head的输出
dn = torch.norm(desc, p=2, dim=1) #torch.Size([8, 40, 40]) 计算desc在第一个维度的二范数
dn = torch.unsqueeze(dn, 1) #torch.Size([8, 1, 40, 40])
desc = desc.div(dn) #torch.Size([8, 256, 40, 40])
3、loss设计
最终的损失是两个中间损失的和:一个用于兴趣点检测器Lp,另一个用于描述符Ld。使用成对的合成扭曲图<具有两个伪标签(兴趣点位置)和来自图像随机扭曲中的单应性矩阵H>。这允许我们同时优化两个损失,给出一对图像,。我们使用λ= 0.0001来平衡最终损失为:
L(X,X′,D,D′;Y,Y′,S)=Lp(X,Y)+Lp(X′,Y′)+λLd(D,D′,S)\begin{array}{l} \mathcal{L}\left(\mathcal{X}, \mathcal{X}^{\prime}, \mathcal{D}, \mathcal{D}^{\prime} ; Y, Y^{\prime}, S\right)= \\ \quad \mathcal{L}_{p}(\mathcal{X}, Y)+\mathcal{L}_{p}\left(\mathcal{X}^{\prime}, Y^{\prime}\right)+\lambda \mathcal{L}_{d}\left(\mathcal{D}, \mathcal{D}^{\prime}, S\right) \end{array} L(X,X′,D,D′;Y,Y′,S)=Lp(X,Y)+Lp(X′,Y′)+λLd(D,D′,S)
最终的输入有X、D、Y、S、X’、D’、Y’(两组XDY和单适应矩阵H),其中X为输入特征点,Y为特征点标签,D为输出的特征描述符,S为特征点的对应性(在特征描述符loss中会描述)。
兴趣点检测器loss Lp的计算公式如下,其代码实质就是在输出chanel上做了一次softmax激活。
Lp(X,Y)=1HcWc∑h=1w=1Hc,Wclp(xhw;yhw)wherelp(xhw;y)=−log(exp(xhwy)∑k=165exp(xhwk)).\mathcal{L}_{p}(\mathcal{X}, Y)=\frac{1}{H_{c} W_{c}} \sum_{\substack{h=1 \\ w=1}}^{H_{c}, W_{c}} l_{p}\left(\mathbf{x}_{h w} ; y_{h w}\right) \\ where \\ l_{p}\left(\mathbf{x}_{h w} ; y\right)=-\log \left(\frac{\exp \left(\mathbf{x}_{h w y}\right)}{\sum_{k=1}^{65} \exp \left(\mathbf{x}_{h w k}\right)}\right) . Lp(X,Y)=HcWc1h=1w=1∑Hc,Wclp(xhw;yhw)wherelp(xhw;y)=−log(∑k=165exp(xhwk)exp(xhwy)).
特征描述符loss Ld的计算公式如下,可以看到是一个加权的hinge loss(因为正样本对数量与负样本对的数量是不一样的,故对正样本用λd\lambda_{d}λd=250进行加权),其中s=1表示为正样本。dTd′d^{T}d'dTd′表示两个特征描述符的乘积,当描述符正交(垂直)时,乘积为0(即两个描述符不相似时【反向时】,乘积-1,相似时乘积接近1);mpm_pmp=1,mnm_nmn=0.2。该loss的本意就是,空间(通过仿射变化后)位置接近的点,所提取的特征描述符应该是相似的;空间位置远的点,所提取的特征描述符应该是不同的。
Ld(D,D′,S)=1(HcWc)2∑h=1w=1Hc,Wc∑h′=1w′=1Hc,Wcld(dhw,dh′w′′;shwh′w′)whereld(d,d′;s)=λd∗s∗max(0,mp−dTd′)+(1−s)∗max(0,dTd′−mn)\begin{array}{l} \mathcal{L}_{d}\left(\mathcal{D}, \mathcal{D}^{\prime}, S\right)= \frac{1}{\left(H_{c} W_{c}\right)^{2}} \sum_{\substack{h=1 w=1}}^{H_{c}, W_{c}} \sum_{\substack{h^{\prime}=1 w^{\prime}=1}}^{H_{c}, W_{c}} l_{d}\left(\mathbf{d}_{h w}, \mathbf{d}_{h^{\prime} w^{\prime}}^{\prime} ; s_{h w h^{\prime} w^{\prime}}\right) \\ \text{where} \\ l_{d}\left(\mathbf{d}, \mathbf{d}^{\prime} ; s\right)=\lambda_{d} * s * \max \left(0, m_{p}-\mathbf{d}^{T} \mathbf{d}^{\prime}\right) +(1-s) * \max \left(0, \mathbf{d}^{T} \mathbf{d}^{\prime}-m_{n}\right) \end{array} Ld(D,D′,S)=(HcWc)21∑h=1w=1Hc,Wc∑h′=1w′=1Hc,Wcld(dhw,dh′w′′;shwh′w′)whereld(d,d′;s)=λd∗s∗max(0,mp−dTd′)+(1−s)∗max(0,dTd′−mn)
s的计算方式如下所示,主要是用于区分样本对。当特征描述符1坐标*单适应矩阵(即还原到原坐标系下)- 特征描述符2坐标小于8时,则构成正样本对,否则为负样本对。

4、实验报告
4.1 MagicPoint
将MagicPoint与其他传统的角检测方法进行评估时,如FAST [21]、Harris角[8]和Shi-Tomasi的“跟踪合成形状数据集上的良好特征”[25]时,作者发现了一个巨大的性能差距,作者测量了合成形状数据集的1000张保留图像的平均平均精度(mAP),并将结果报告在表2中。经典探测器在存在成像噪声下挣扎的定性例子如图4所示(MagicPoint特征点对于噪声鲁棒性更好)。

更详细的实验方法见附录B(即下图),其中MLE为平均定位误差(Mean Localization Error)。

噪声强度测试
通过改变噪声的大小来更仔细地研究它的影响。我们很好奇,我们添加到图像上的噪声对于一个点探测器来说是否过于极端和不合理。为了验证这一假设,我们在干净图像(s = 0)和有噪声图像(s = 1)之间进行线性插值。为了将探测器推到极限,我们还在噪声图像和随机噪声(s = 2)之间进行插值。随机噪声图像不包含几何形状,因此对所有检测器的mAP评分为0.0。下图显示了不同程度噪声的例子和图示。

噪声类型测试
我们把噪音分为八类。我们单独研究这些噪声类型的影响,以更好地了解哪一种对点探测器的影响最大。散斑噪声对于传统的探测器来说尤其困难。结果总结在图12中,从中可以看出MagicPoint所提取的特征点在loss上基本上不受噪声类型的影响(其loss直方图[最前面两个柱形]在不同噪声下变化很小)

Blob检测
我们实验了我们的模型检测形状中心的能力,如四边形和椭圆。我们使用了MagicPoint的架构并增强了合成形状训练集,除了角落外,还包括斑点中心。我们观察到,只要整个形状不太大,我们的模型就能够检测到这些斑点。然而,为这种“斑点检测”产生的干扰通常低于角落的干扰,这使得将两种检测集成到一个系统中有些麻烦。在本文的主要实验中,除了下面的实验外,我们省略了用斑点进行的训练。
我们在白色背景上创建了96×96的黑色正方形图像。我们将方块的宽度从3到91像素,并报告输出两个不同输入图heatmap的一致性:中心像素(斑点的位置)和方块的左上角像素(一个易于检测的角)。本实验的MagicPoint的角置信图如图13所示。我们观察到,我们可以自信地检测斑点的中心当size宽为11到43像素是(图13中红色区域),检测较低的信心当广场43和71像素宽(黄色区域),并且无法检测中心斑点当广场大于71(图13中的蓝色区域)。

整体实验效果较好,但该实验带来的问题是:人工形状效果能推广到真实的图像吗?
总结我们稍后在7.2节中介绍的一个结果,答案是肯定的,但没有作者希望的那么好。作者惊讶地发现,魔法点在现实世界的图像上表现得相当好,特别是在那些具有强大的角状结构的场景中,如桌子、椅子和窗户。不幸的是,在所有自然图像的空间中,与相同的经典探测器相比,它在视点变化下的可重复性方面表现不佳。这激发了作者训练真实世界图像的自我监督方法,作者称之为 Homographic Adaptation。
4.2 Homographic Adaptation
SuperPoint从一个基本的兴趣点检测器和来自目标域的大量未标记图像(如MS-COCO)引导自己。在自我监督范式(也称为self-training)中,我们首先为目标域中的每个图像生成一组伪地面真实兴趣点位置,然后使用传统的监督学习机制。方法的核心是一个数据增强过程,将随机单适应变化应用用于输入图像的副本,并将结果还原到原图上累加——我们称之为同质自适应。
并不是所有随机生成的3x3单适应矩阵都是同质自适应的好选择。对好的同型性进行抽样,以表示看似合理的相机转换,我们将一个潜在的同构性分解成更简单,表达力较差的转换类。我们在预先确定的范围内采样的平移、尺度、平面内旋转和对称透视失真使用截断的正态分布。这些转换与初始的根中心作物一起组成,以帮助避免边界工件。具体的单适应图像变化,可以拆解为以下步骤:

所进行的单适应变化也应该是有限的,作者表明一个图在进行100次单适应变化后,它的增益会递减。且在训练过程中图像仅是有概率进行单适应变化,并非都变化。
迭代提升
我们在训练时应用Homographic Adaptation技术来提高MagicPoint在真实图像上的泛化能力。该过程可以反复重复,以不断地自我监督和改进兴趣点检测器。在我们所有的实验中,我们在应用Homographic Adaptation后,将结果模型命名为SuperPoint,并显示了图7中来自HPatches的图像的定性进展。

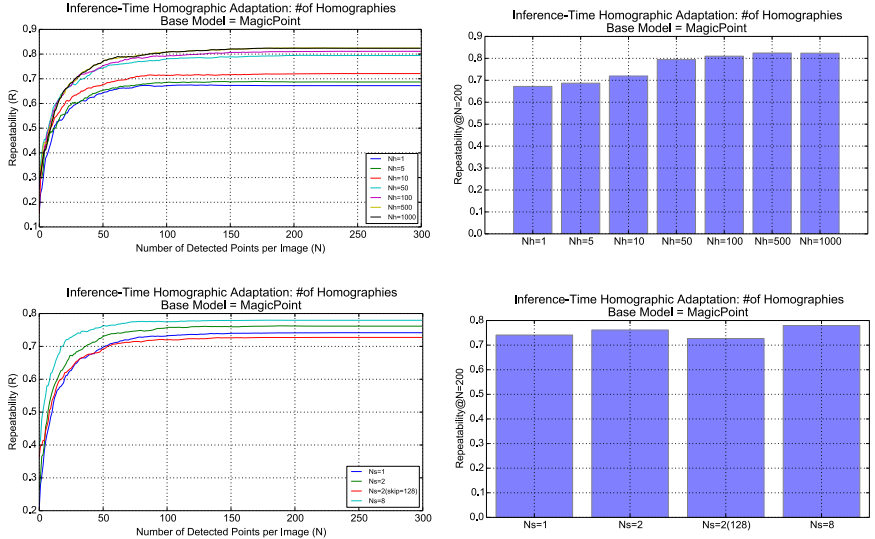
尺度变化
区分尺度内聚合和跨尺度聚合是很重要的。现实世界的图像通常包含不同尺度的特征,因为一些在高分辨率图像中被认为是有趣的点,通常甚至在更粗糙、更低分辨率的图像中都不可见。然而,在单一尺度内,图像的转换,如旋转和平移,不应该使兴趣点出现/消失。图像的这种潜在的多尺度性质对于尺度内和跨尺度的聚合策略具有不同的含义。尺度内聚合应该类似于计算集合的交集,而跨尺度聚合应该类似于集合的并集。此外,我们还可以使用跨尺度的平均响应作为兴趣点置信度的多尺度度量。当兴趣点在所有尺度上都可见时,跨尺度的平均响应将被最大化,而这些很可能是跟踪应用程序的最强大的兴趣点。
-
尺度内的聚合 我们使用了对输入图像的大量均形扭曲的平均响应。在选择随机同态时应该注意,因为不是所有的同态都是真实的图像变换。同形扭曲的数量Nh是我们的方法的一个超参数。我们通常强制第一个同等性相等,这样在我们的实验中Nh = 1对应于不做同等性(或等价地,应用恒等同等性)。我们的实验范围从“小”Nh = 10,到“中”Nh = 100,和“大”Nh = 1000。
-
跨尺度的聚合 考虑的尺度的数量是我们方法的一个超参数。Ns = 1的设置对应于没有多尺度聚合(或只是跨大的图像大小聚合)。对于Ns > 1,我们将被处理的多尺度图像集称为“多尺度图像金字塔”。我们考虑加权方案,加权金字塔的水平不同,给更高分辨率的图像一个更大的权重。这一点很重要,因为在较低分辨率下检测到的兴趣点具有较差的定位能力,而且我们希望最终的聚合点尽可能精准定位。我们在MS-COCO图像的持续测试中进行了尺度内和跨尺度聚合的实验。结果总结在图14中。我们发现,尺度内聚合对可重复性的影响最大
5、论文总结
我们提出了一种全卷积神经网络架构,用于兴趣点检测和描述,使用自形自适应的自监督域适应框架。我们的实验表明,(1)可以转移知识从一个合成数据集到现实世界的图像,(2)稀疏兴趣点检测和描述可以作为一个有效的卷积神经网络,和(3)产生的系统适用于几何计算机视觉匹配任务等同质估计。
未来的工作将研究同质自适应是否可以提高模型的性能,如用于语义分割(如SegNet [1])和目标检测(如SSD [14])。它还将仔细研究兴趣点检测和描述(以及潜在的其他任务)对彼此有益的方式。
最后,我们相信我们的超级点网络可以用于解决3D计算机视觉问题中的所有视觉数据关联,如SLAM和SfM,并且基于学习的视觉SLAM前端将在机器人技术和增强现实中实现更健壮的应用
相关文章:
论文解读:SuperPoint: Self-Supervised Interest Point Detection and Description
发表时间: 2018年 项目地址:https://arxiv.org/abs/1712.07629 论文地址:https://github.com/magicleap/SuperPointPretrainedNetwork 本文提出了一种用于训练计算机视觉中大量多视点几何问题的兴趣点检测器和描述符的自监督框架。与patch-based的神经网…...

游戏玩的多,陪玩你了解的多吗?用Python来采集陪玩数据,看看行情和美照
前言 (。・∀・)ノ゙嗨 大家好 现在应该每个人都玩过游戏吧,有些的上瘾,天天玩停不下来,有些的倒是没啥感觉 有游戏就肯定有陪玩啊,毕竟当朋友忙的时候,自己一个…...

React框架创建项目详细流程-项目的基本配置-项目的代码规范
文章目录React创建项目流程与规范项目规范项目配置目录结构样式重置Router配置Redux状态管理axios配置React创建项目流程与规范 项目规范 项目规范: 在项目中都会有一些开发规范和代码风格, 下面介绍一下我采用的规范与风格 文件夹、文件名称统一小写、多个单词以连接符(-)连…...
)
nnunet入门之一 (CT图像分割)
目录安装环境数据处理预处理训练测试MIC-DKFZ/nnUNet 选择Linux环境运行该项目,Windows环境需要更改较多的参数,暂不支持。 安装环境 安装cuda, cudnn,已安装的检测cuda版本 检测cuda版本: nvcc -v cd /usr/local nvidia-smi&…...
从0到1_批量下载视频
简介:真实从0到1,童叟无欺~ 目标:用python批量下载搜索视频,以“CG 服装”为例 搜索图片就不放啦,不能过审 本章主要介绍如何用python把搜索到的视频直接下载到自己的本地文件夹中~ 介绍一下工作…...

CNCF x Alibaba云原生技术公开课 第十二章 可观测性:监控与日志
1、监控 监控类型 资源监控:cpu、内存、网络等。性能监控:apm监控,一般是通过一些 Hook 的机制在,在虚拟机层、字节码执行层通过隐式调用,或者是在应用层显示注入,获取更深层次的一个监控指标,…...

C语言宏定义几个问题
1.#define Ant A虽说做的是将代码中Ant替换成A,但是是整体的替换,不能将整体分离替换。 不带宏参定义一般形式如下: 格式: #define 标识符 字符串 其中“标识符”为所定义的宏名,“字符串”可以是常数、表达式、格式串…...
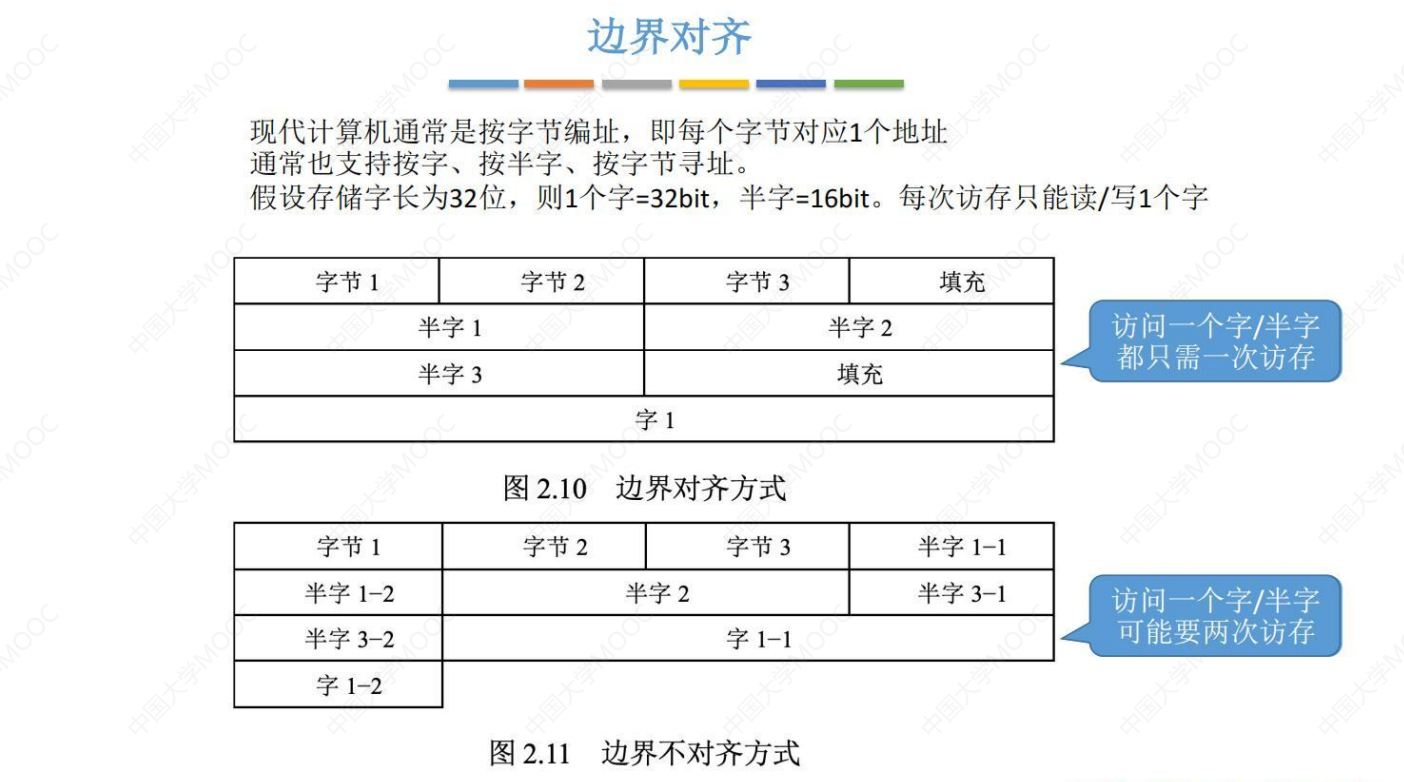
王道计算机组成原理课代表 - 考研计算机 第二章 数据的表示和运算 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对 计算机组成 知识点的理解的总结。希望对新一届的计算机考研人提供帮助!!! 关于对 数据的表示和运算 章节知识点总结的十分全面,涵括了《计算机组成原理…...
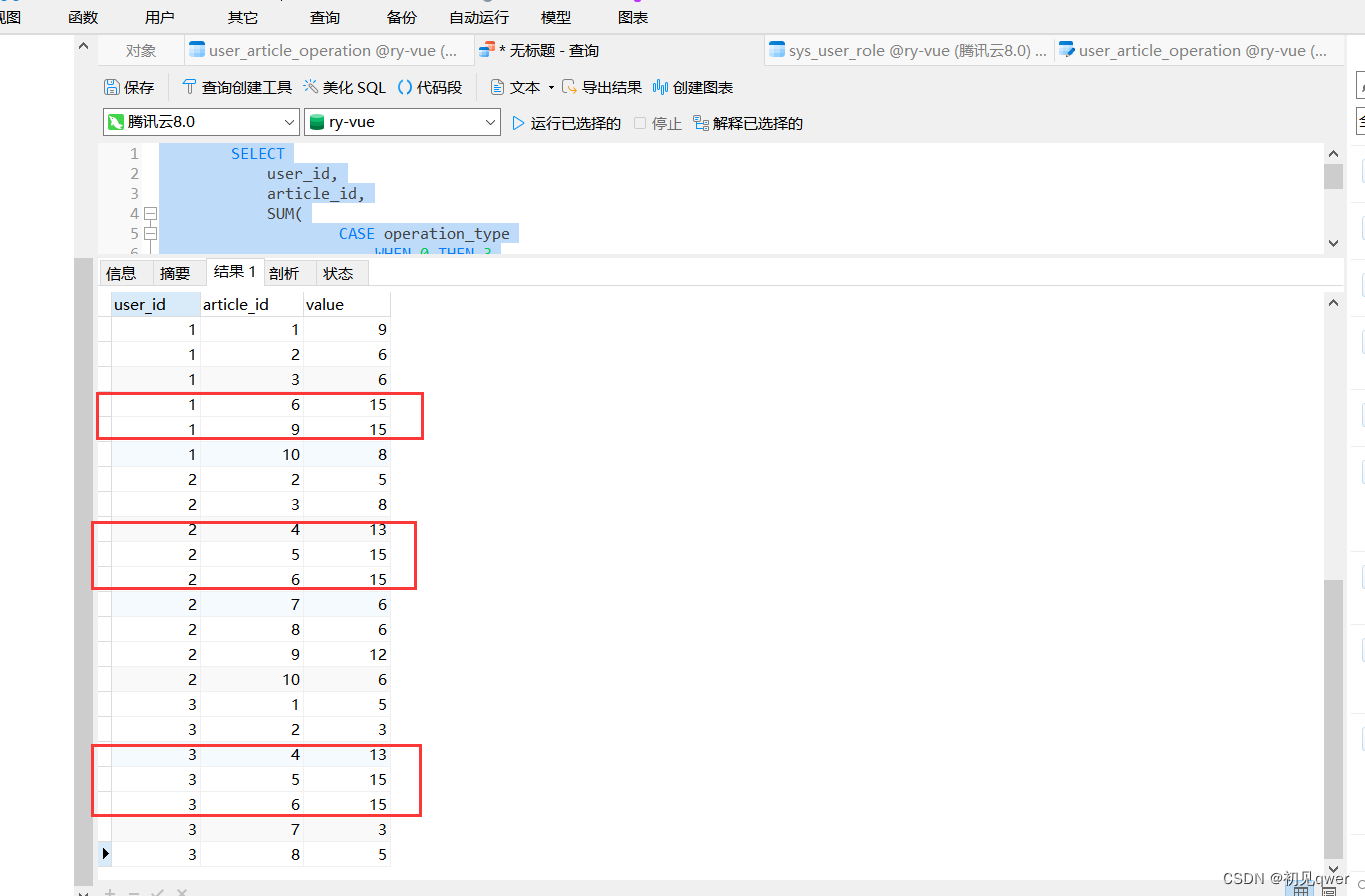
springboot集成mahout实现简单基于协同过滤算法的文章推荐算法
文章目录前言1.建表并且生成一些数据首先,建立一个用户文章操作表(user_article_operation)使用case when语句简单分析数据2. 代码与测试只需要根据表生成相应实体类(注意要加一个value属性来存储分数)主要代码如下&am…...
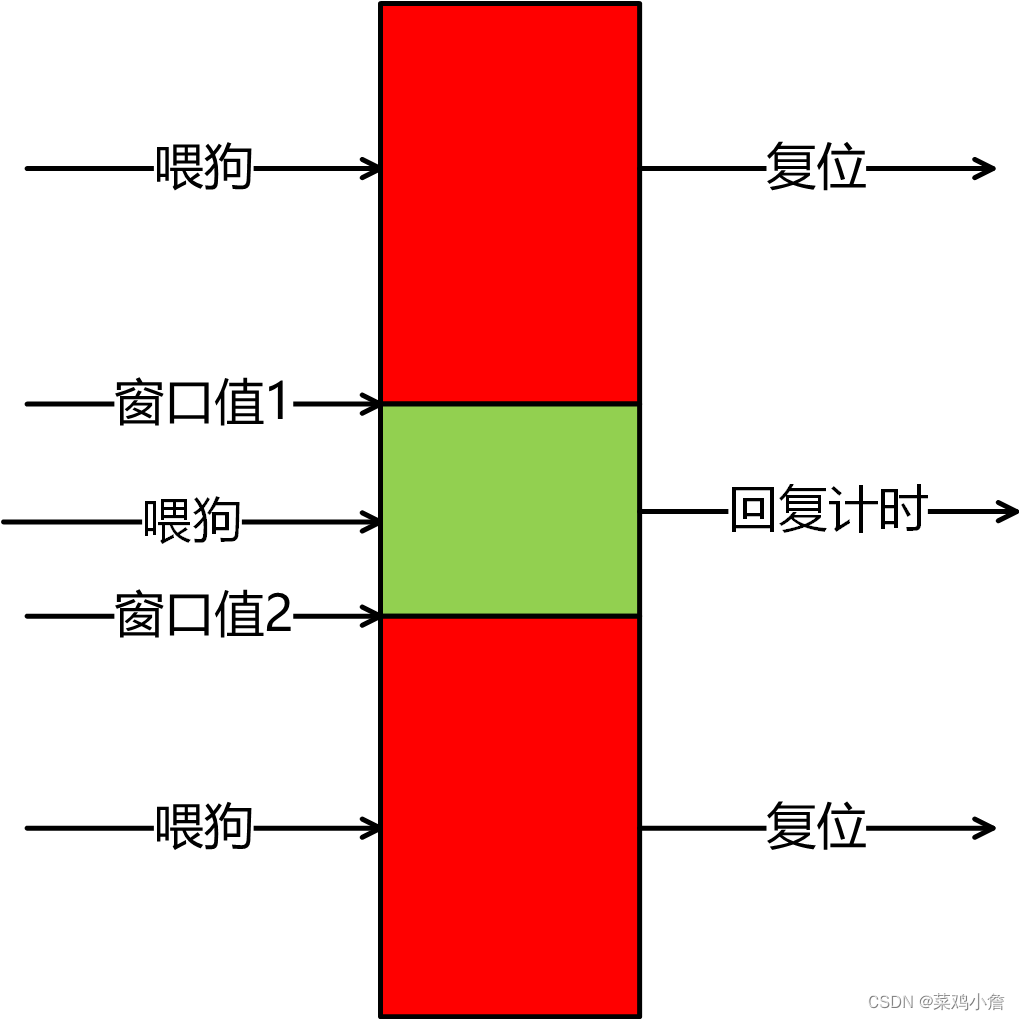
自动驾驶介绍系列 ———— 看门狗
文章目录硬件看门狗软件看门狗差异分析延申窗口看门狗硬件看门狗 硬件看门狗的本质上是一个定时器电路。通常存在一个输入,输入到MCU的RST端。在正常工作状态下,MCU每隔固定时间间隔会输出一个信号给RST端,实现对看门狗端清零。如果在指定的时…...
今天打开个税APP,我直接人麻了!
点击上方“码农突围”,马上关注这里是码农充电第一站,回复“666”,获取一份专属大礼包真爱,请设置“星标”或点个“在看这是【码农突围】的第 432 篇原创分享作者 l 突围的鱼来源 l 码农突围(ID:smartyuge&…...

javascript进阶学习笔记(含AJAX)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、JS变量(var、let和const)二、for/in循环三、正则表达式语法:正则表达式修饰符:正则表达式模式字符串方法&…...

今年没有金三银四
最近好几个铁子咨询目前的大环境如何,甚至还有几个CTO和总监级别的大佬想跳槽问有没有对应的岗位。 又到了每年金三银四的时间点,往年(去年除外)这个时候用工市场都是一遍火热,大家跳槽涨薪好不快活。 面对这些咨询我…...

NFS - Network FileSystem网络文件系统的实现原理
文章目录PreNFS简介NFS共享数据结构图NFS服务器的实现原理是否安装nfs安装配置NFSPre NFS - MIPS架构下构建NFS共享目录服务 NFS简介 NFS的全称是Network FileSystem,即网络文件系统 NFS最初是由 Sun Microsytem 公司开发出来的,主要实现的功能是让网络…...
C#【汇总篇】语法糖汇总
文章目录0、语法糖简介1、自动属性2、参数默认值和命名参数3、类型实例化4、集合4.1 初始化List集合的值4.2 取List中的值5、隐式类型(var)6、扩展方法【更换测试实例】7、匿名类型(Anonymous type)【待补充】8、匿名方法…...
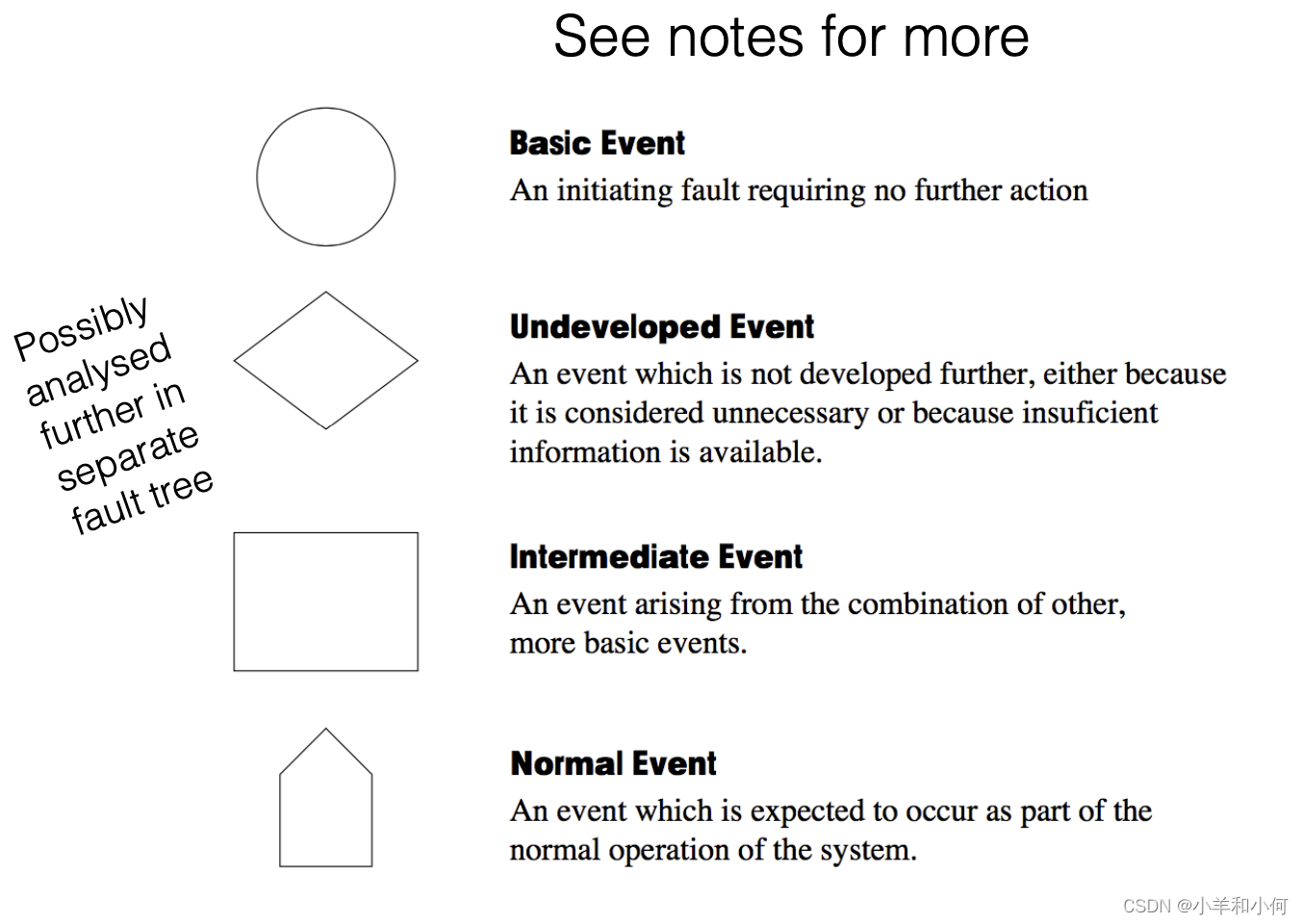
高完整性系统工程(一): Safety Engineering, HAZOP Fault Tree Analysis
目录 1. 因果性不等同于相关性 2. HAZOP 2.1 学习HAZOP 2.2 HAZOP概览 2.3 Assessing Hazard Risks 评估 2.4 示例场景 2.5 HAZOP Guidewords 2.6 HAZOP Process 2.7 HAZOP Outcomes 2.8 HAZOP Summary 3. FAULT TREE ANALYSIS 3.1 Analysis Outcomes 1. 因果性不等…...
)
VGG16分类模型的网页界面(Flask,keras)
开发一个网页版的VGG16模型界面可以分为以下几个步骤: 步骤1:数据准备 首先要准备一组图片数据集,建议使用ImageNet数据集,该数据集包含超过1000个类别和100万张图像。您可以将ImageNet数据集转换为Keras的格式。如果您没有Imag…...
)
互联网摸鱼日报(2023-03-12)
互联网摸鱼日报(2023-03-12) InfoQ 热门话题 又拍云邵海杨:25年Linux老兵聊DevOps八荣八耻 快猫来炜:如何端好运维的饭碗 作业帮聂安:运维如何转型,听听作业帮的OPaS思路 CTO药方:如何搭建运…...

SpringBoot异常处理?用这两个就够啦!
在日常项目中,我们难免会遇到系统错误的情况。如果对系统异常的情况不做处理,Springboot本身会默认将错误异常作为接口的请求返回。 GetMapping("/testNorError") public void testNorError() {try {throw new MyException(6000, "我…...

mysql-查询重复数据的条数-count
查询重复数据的条数 select name , count(*) from table group by name; 查询结果:查询表table中name相同重复的个数 补充:count的用法 查询一个表中总共多少行(多少条数据) select count (*) from table 小结 …...

哈尔滨工业大学学位论文latex模板下载及编译方法
1、下载文件夹chinese:https://download.csdn.net/download/wzz110011/92774930?spm1011.2124.3001.6210 2、安装TexStudio 3、设置TexStuidio编译器为XeLaTex,具体设置方法可百度...

MongoDB中大型文本字段怎么存_GridFS切分与外部存储对比
会。MongoDB单文档上限16MB,但超2MB字符串易致客户端OOM或超时;GridFS非自动魔法,需手动管理分块、拼接与清理;大文本应优先存OSS/S3,Mongo仅存元数据。大文本存MongoDB会撑爆内存吗?会。MongoDB单文档上限…...

免费开源字体 Source Sans 3 完整配置使用教程
免费开源字体 Source Sans 3 完整配置使用教程 【免费下载链接】source-sans Sans serif font family for user interface environments 项目地址: https://gitcode.com/gh_mirrors/so/source-sans Source Sans 3 是由 Adobe 开发的开源无衬线字体家族,专为现…...

科学护眼智能提醒:3个维度破解数字时代眼健康难题
科学护眼智能提醒:3个维度破解数字时代眼健康难题 【免费下载链接】ProjectEye 😎 一个基于20-20-20规则的用眼休息提醒Windows软件 项目地址: https://gitcode.com/gh_mirrors/pr/ProjectEye 在数字时代,我们每天面对屏幕的时间急剧增…...

【无标题】MySQL数据库基础实例教程单元2 学习笔记
2.1 关系数据库设计 2.1.1 数据的加工 数据设计本质上是对现实世界信息的逐步抽象和加工,过程分为三个阶段。首先是现实世界,包含客观存在的事物、业务需求和事物之间的联系。然后进入信息世界,把现实事物抽象为概念模型,方便理解…...

闲鱼数据采集终极指南:零代码自动化抓取二手商品信息
闲鱼数据采集终极指南:零代码自动化抓取二手商品信息 【免费下载链接】xianyu_spider 闲鱼APP数据爬虫 项目地址: https://gitcode.com/gh_mirrors/xia/xianyu_spider 想要轻松获取闲鱼平台上的商品数据,却不想编写复杂的爬虫代码?xia…...

终极SyntaxHighlighter CDATA处理指南:如何实现完美的XML兼容性
终极SyntaxHighlighter CDATA处理指南:如何实现完美的XML兼容性 【免费下载链接】syntaxhighlighter SyntaxHighlighter is a fully functional self-contained code syntax highlighter developed in JavaScript. 项目地址: https://gitcode.com/gh_mirrors/sy/s…...

Phi-4-mini-reasoning应用场景:AI竞赛教练系统自动出题与解析
Phi-4-mini-reasoning应用场景:AI竞赛教练系统自动出题与解析 1. 引言:当AI遇见竞赛训练 想象一下,一位数学竞赛教练每天需要: 设计不同难度的题目准备详细的解题步骤针对学生错误提供个性化解析不断更新题库保持新鲜度 传统方…...
|零基础复刻经典贪吃蛇!AI 生成完整代码,支持难度切换》)
《AI 小游戏开发(5)|零基础复刻经典贪吃蛇!AI 生成完整代码,支持难度切换》
目录 一、本课目标 二、需要准备的工具 三、超详细操作步骤(分两步:生成基础代码 → 添加难度切换) 第一步:生成基础贪吃蛇游戏(AI 一键生成) 1. 给 AI 的详细提示词(复制完整) 2. 复制 AI 生成的基础代码 3. 保存并运行基础游戏 第二步:给游戏添加难度切换功…...

Vue3路由缓存优化指南:用keep-alive的include+max实现淘宝级页面保活
Vue3路由缓存优化实战:电商场景下的keep-alive高阶用法 电商平台的商品详情页与列表页频繁切换时,页面重载导致的性能损耗直接影响用户体验。去年双十一大促期间,某头部电商平台通过优化路由缓存策略,将页面切换速度提升了47%&…...