Python后端面试题
1. 文件操作w+和r+的区别
在Python中,文件操作模式中的w+和r+都表示对文件的读写操作,但它们在打开文件时的行为有所不同:
-
r+模式:- 读写:这种模式允许你同时读取和写入文件。文件必须已经存在,否则会抛出一个
FileNotFoundError。 - 位置:打开文件时,文件指针位于文件的开始。这意味着你可以从文件的开头开始读取数据,或者覆盖(而不是追加)现有内容开始写入。
- 用途:通常用于修改文件的现有内容,比如先读取一些数据,然后在同一个地方或后面写入新数据。
- 读写:这种模式允许你同时读取和写入文件。文件必须已经存在,否则会抛出一个
-
w+模式:- 读写:同样允许读取和写入文件,但与
r+不同,如果文件已存在,则会被清空(即原有内容会被删除);如果文件不存在,则会创建一个新文件。 - 位置:打开文件后,文件指针同样位于文件的开始,但由于文件被清空,实际上你是从一个空白文件开始写入和读取。
- 用途:适合于需要重新初始化文件内容的场景,即先清空文件内容,然后写入新的数据,同时也可能需要读取刚写入的数据进行验证或其他处理。
- 读写:同样允许读取和写入文件,但与
总结来说,选择r+还是w+主要取决于你的具体需求:
- 如果你需要保留并可能修改文件的现有内容,应该使用
r+。 - 如果你想创建一个新文件或覆盖现有文件的内容,并随后可能进行读取,那么应使用
w+。
2. @staticmethod和@classmethod的区别,两者可否通过实例调用?
@staticmethod和@classmethod都是Python中用于定义特殊方法的装饰器,它们改变了方法调用的方式和能访问的数据范围,但各自有不同的应用场景和行为特点:
@staticmethod
- 特点:静态方法不需要访问实例或类的属性,因此它不接收隐式的
self(实例)或cls(类)参数。静态方法类似于普通的函数,只是它们在类的命名空间中定义,有助于逻辑上的组织或归类。 - 调用方式:静态方法可以通过类名直接调用,如
ClassName.static_method(),也可以通过类的实例来调用,尽管这样做在语义上并不直观,因为静态方法不操作实例数据,如instance.static_method()。
@classmethod
- 特点:类方法接收一个隐式的参数
cls,代表调用该方法的类本身。这使得类方法可以访问类的属性或方法,而且在继承体系中,如果子类重写了此类方法,cls会指向子类,这对于基于类的逻辑非常有用。 - 调用方式:类方法既可以通过类名调用,如
ClassName.class_method(),也可以通过类的实例调用,如instance.class_method()。虽然通过实例调用,但重要的是理解在这个过程中cls参数传递的是类本身,而不是实例。
总结区别
- 访问权限:静态方法不涉及类或实例的状态,因此无法直接访问类变量或实例变量。类方法通过
cls参数可以访问类变量,修改类的状态(但不建议直接修改),并且能够调用其它类方法或创建类的新实例。 - 设计意图:静态方法通常用于那些逻辑上属于类但不需要特定实例或类上下文的操作。类方法则用于需要类的信息,但在没有具体实例或为了实现多态性时使用。
是否可通过实例调用
- @staticmethod:可以,尽管这样做没有特别的意义,因为静态方法不依赖于实例。
- @classmethod:同样可以,通过实例调用时,
cls参数自动绑定到实例所属的类,这在需要基于类而不是实例进行操作时很有用。
__new__()与__init__()区别
在Python中,__new__和__init__都是用于对象创建过程中的特殊方法,但它们在对象生命周期中的作用点和职责有所不同:
__new__
- 作用:
__new__是一个静态方法,负责创建并返回一个新实例。它是实例化过程中的第一步,负责分配内存空间给新对象。当调用一个类来创建新实例时,Python会自动调用__new__方法。 - 目的:主要用于控制实例的创建过程,比如实现单例模式、定制实例的生成过程(如改变生成的类类型)、执行复杂的初始化前任务等。
- 返回值:必须返回一个实例,这个实例可以是当前类的一个新实例,也可以是其父类或任何其他类的实例。如果不返回,会抛出异常。
- 调用时机:在
__init__之前被调用,且仅在类首次被实例化时调用一次。对于后续的实例化,如果__new__缓存了实例(如在单例模式中),则可能不会再次调用。
__init__
- 作用:
__init__是一个实例方法,负责初始化新创建的对象。当__new__完成实例的创建并返回一个实例后,Python接着会自动调用__init__方法来设置对象的初始状态,如给对象的属性赋初值。 - 目的:主要用于设置对象的初始属性值,执行必要的初始化任务,使对象达到可用状态。
- 参数:第一个参数总是
self,表示当前实例本身,后面可以有其他参数用于接收传入的初始化数据。 - 调用时机:在
__new__返回一个实例后立即调用,每次创建实例时都会执行。
总结
__new__关注于创建实例本身,包括决定由哪个类来创建实例以及是否复用现有实例(如在单例模式中)。__init__关注于实例创建完成后,如何设置实例的初始状态,使其准备好被使用。
3. CPU密集型适合用多线程还是多进程
CPU密集型任务更适合使用多进程。原因在于CPU密集型任务主要依赖处理器的计算能力,这类任务倾向于最大化利用CPU的计算资源。在多进程环境下,每个进程可以被操作系统调度到不同的CPU核心上并行执行,从而实现真正的并行计算,提高整体的计算效率。
相比之下,虽然多线程也能提供一定程度的并发执行,但是在某些编程环境中(特别是像Python的CPython解释器,受全局解释器锁GIL的影响),多线程并不能在CPU密集型任务上实现真正的并行计算,因为GIL限制了同一时间只有一个线程能在CPU上执行Python字节码。这意味着在CPU密集型任务中,多线程可能会因为GIL而无法充分利用多核CPU的优势,甚至在某些情况下,多线程的线程切换开销可能会降低程序的执行效率。
因此,对于CPU密集型任务,选择多进程能够更好地利用多核处理器的并行计算能力,提高程序的执行效率。
4. 协程的缺点
协程作为一种轻量级的并发编程工具,在处理高并发和IO密集型任务时表现出诸多优势,如节省资源、简化编程模型等。然而,它也存在一些局限性和缺点,主要包括:
-
无法充分利用多核资源:协程的本质是单线程的,意味着它在同一时间只能运行在一个CPU核心上。对于拥有多个核心的现代CPU,协程自身无法直接实现并行计算,无法充分发挥多核处理器的计算潜力。要利用多核,通常需要结合多进程或多线程,让每个进程或线程内部使用协程来处理IO密集型任务。
-
阻塞操作会阻塞整个程序:尽管协程擅长处理非阻塞的IO操作,但如果协程中出现了阻塞操作(如某些未优化的IO操作、长时间的计算任务等),它会阻塞住整个执行协程的线程,影响其他协程的执行,直到阻塞操作完成。
-
调试和追踪复杂:相较于传统的线程或顺序执行的程序,协程的执行流程更为复杂,包含更多的控制转移,这可能会增加调试的难度。调试工具和日志可能需要特殊的支持来清晰地追踪协程间的跳转和执行顺序。
-
编程模型的学习成本:虽然协程可以简化异步编程,但理解和正确使用协程(特别是涉及复杂的协同和调度逻辑时)仍需要开发者有一定的学习曲线,尤其是对于那些习惯于同步编程模型的开发者来说。
-
语言和生态系统支持程度不一:并非所有编程语言都原生支持协程,或者支持的程度和易用性不同。此外,围绕协程的库和框架生态系统成熟度也有差异,这可能影响到开发效率和可用资源。
综上所述,尽管协程是处理高并发和IO密集型应用的强大工具,但在设计和实施时,需要充分考虑上述缺点并采取相应的策略来规避或缓解这些问题。
5. 列表推导式和生成器的优劣
列表推导式和生成器各有其优势和劣势,具体选择取决于应用场景的需求:
列表推导式的优势:
- 简洁明了:列表推导式提供了一种简洁的方式来创建列表,代码更加直观易读。
- 执行速度:对于较小的数据集,列表推导式通常执行较快,因为CPython对这类结构进行了优化。
- 一次性计算:所有元素一次性计算并存储在内存中,适合于数据量不大且需要频繁访问的情况。
- 功能丰富:可以直接用于构建复杂的列表结构,包括嵌套和条件过滤。
列表推导式的劣势:
- 内存消耗:对于大数据集,列表推导式会消耗大量内存,因为它需要一次性存储所有元素。
- 不可中断:一旦开始计算,必须生成完整列表,即使只需要部分结果。
生成器的优势:
- 内存效率:生成器采用惰性求值,仅在需要时计算下一个值,大大减少了内存使用。
- 流式处理:适合处理大数据集或无限数据流,能够在不耗尽内存的情况下逐步处理数据。
- 可中断:生成器可以暂停和恢复执行,提供了更好的控制灵活性。
生成器的劣势:
- 延迟计算:需要时才计算下一个值,对于需要立即访问所有数据的场景不如列表推导式直接。
- 功能相对有限:相比列表推导式,生成器在构造复杂数据结构方面可能不够直观或灵活。
- 迭代特性:生成器是一次性的,一旦遍历完就不能再次使用,除非重新创建。
6. Python中的重载
在Python中,传统意义上的“重载”(overloading)概念,即基于不同参数类型或数量来提供多个同名函数的机制,并不是语言直接内置支持的特性。这是因为Python是一种动态类型语言,它在设计上鼓励使用鸭子类型(duck typing)和默许参数(default arguments)、可变参数(*args, **kwargs)等机制来实现类似的功能,而不是依赖于严格的类型检查。
尽管如此,Python 提供了一些方法来模仿重载的效果,尤其是在处理不同类型数据时,可以让一个函数或方法根据传入参数的不同表现不同的行为。这些方法包括但不限于:
-
默许参数与关键字参数:通过为函数参数设置默认值,或者使用
*args和**kwargs来捕获额外的参数,可以在一个函数体内实现多种情况的处理逻辑。 -
类型检查:在函数内部使用类型检查(如
isinstance()函数)来判断参数类型,并据此执行不同的代码路径。 -
使用
functools.singledispatch装饰器:对于基于类的方法,Python 3.4 引入了functools.singledispatch装饰器,它允许为一个函数的第一个参数的不同类型定义多个实现。这是一种更加面向对象的重载模拟方式,更接近静态类型语言中的重载概念。
7. MVC和MVT
MVC (Model-View-Controller) 是一种软件设计模式,广泛应用于构建用户界面和应用程序。它的核心思想是将应用程序分为三个核心部分,以促进代码的解耦、可维护性和可扩展性:
-
Model(模型):负责管理应用程序的数据和业务逻辑。它封装了数据并定义了对数据进行操作的方法,如存取数据库、数据验证等。
-
View(视图):负责展示数据给用户,即用户界面。它从模型获取数据并格式化显示。视图应该只关注如何展示数据,而不涉及数据的获取和处理。
-
Controller(控制器):作为模型和视图之间的桥梁,处理用户的输入,控制应用程序的流程。它接收用户的请求,调用模型来处理数据,然后选择合适的视图来展示处理后的数据。
MVT (Model-View-Template) 是Django框架采用的一种设计模式,它是MVC的一个变体,尤其是在视图和模板的分离上做了进一步的区分:
-
Model(模型):与MVC中的模型角色相同,负责数据管理和业务逻辑处理。
-
View(视图):在Django中,视图的概念与MVC中的控制器角色更相似。Django的视图主要负责接收HTTP请求,处理请求(可能包括调用模型来获取或更新数据),并返回响应。这里的视图更侧重于逻辑处理,而不是展示层。
-
Template(模板):对应于MVC中的视图角色,负责页面的布局和渲染。模板从视图那里接收数据,并按照定义好的HTML结构展示数据。模板应该只包含展示逻辑,不包含业务逻辑或数据处理。
8. FBV和CBV,CBV的优点
在Django框架中,视图可以使用两种风格来编写:FBV(Function-Based Views)和CBV(Class-Based Views)。
FBV(Function-Based Views):
- 简单直观:对于简单的逻辑,FBV更容易理解和编写,因为它们直接以函数的形式呈现,直观明了。
- 快速开发:对于小型项目或一次性使用的视图,直接使用FBV可以更快地完成开发。
CBV(Class-Based Views):
- 代码组织和重用:CBV允许更好的代码组织,通过继承和组合,可以重用和扩展视图逻辑。这在大型项目中特别有用,有助于保持代码的模块化和DRY(Don't Repeat Yourself)原则。
- 功能丰富:Django为CBV提供了丰富的内置类和Mixin,这些类和Mixin封装了常见的操作,如分页、表单处理、权限控制等,简化了视图的实现。
- 面向对象编程:作为Python的类,CBV充分利用了面向对象编程的优势,如继承、封装和多态性,使代码更加灵活和易于维护。
- 清晰的HTTP方法处理:CBV使得针对不同HTTP方法(GET、POST等)的处理更加清晰,每个方法都可以单独定义,提高了代码的可读性。
- 易于扩展:通过覆盖或添加方法,可以轻松地扩展视图的行为,而不必重写整个视图逻辑。
总之,CBV在代码结构、重用性和扩展性方面具有明显优势,尤其适合于构建复杂、可维护的大型应用程序。而FBV则因其简单直接,在处理简单视图时依然有其价值。开发者可以根据项目的规模和需求来选择最合适的视图实现方式。
9. orm和原生sql的优缺点
ORM (Object-Relational Mapping, 对象关系映射) 的优缺点:
优点:
- 提高开发效率:通过将数据库操作转换为面向对象的编程方式,开发者可以使用熟悉的对象操作,而无需编写复杂的SQL语句。
- 减少错误:自动化的查询生成有助于避免SQL语法错误和拼写错误。
- 易于维护:当数据库结构发生变化时,只需调整对应的对象模型,相关查询也会自动适应变化,减少了硬编码SQL带来的维护负担。
- 数据库无关性:良好的ORM实现可以抽象出底层数据库的差异,使得在不同数据库间迁移变得更加容易。
- 安全性:许多ORM框架内置了防范SQL注入的机制,提高应用的安全性。
缺点:
- 性能损失:由于ORM增加了额外的抽象层,相比于直接编写SQL,可能会有轻微的性能下降,尤其是在处理复杂查询时。
- 学习曲线:对于初学者,理解ORM的概念和使用方式可能需要时间。
- 不够灵活:对于高度定制化的查询,ORM可能无法提供足够的灵活性,有时需要编写原生SQL作为补充。
- 资源消耗:某些情况下,ORM可能会产生多余的数据库访问,如N+1查询问题,这会增加资源消耗。
原生SQL的优缺点:
优点:
- 性能高效:直接编写SQL可以针对特定查询进行优化,从而获得最佳的执行性能。
- 灵活性高:可以编写任何复杂的查询,不受ORM框架的限制,适合处理特殊或复杂的数据库操作。
- 直观性:对于熟悉SQL的开发者来说,直接查看和编辑SQL语句更加直观和直接。
缺点:
- 开发效率低:需要手动编写和维护SQL语句,这可能降低开发速度,特别是在处理大量的数据库交互时。
- 易出错:手动编写SQL容易出现语法错误或逻辑错误,需要额外的测试和调试。
- 数据库耦合:原生SQL紧密绑定特定数据库的语法,更换数据库系统时可能需要重写大量SQL代码。
- 安全性问题:没有ORM框架提供的自动防护,需要手动防范SQL注入等安全问题。
10. 什么是跨域
跨域(Cross-Origin)是指在互联网上的一个域下的文档或脚本尝试请求另一个域下的资源时,域名、协议或端口不同的这种情况。由于浏览器的同源策略(Same-origin policy)安全限制,默认情况下,出于安全考虑,Web浏览器禁止网页脚本跨域访问其他源的资源。同源策略要求Web内容只能从同一个源加载,这里的“源”指的是协议、域名和端口号的组合,三者完全一致方视为同源。如果源不相同,则构成了跨域访问。
同源策略的目的是为了防止恶意网站通过脚本读取另一个网站的敏感数据,例如:Cookies、存储在浏览器中的数据等,从而保护用户的信息安全。
跨域场景示例
- 页面
https://example.com中的 JavaScript 尝试请求https://api.example.org/data的资源。 - 页面
http://www.example.com中的 AJAX 请求发送到https://www.example.com。
解决跨域的方法
为了解决合法的跨域需求,同时保持安全,现代Web开发中采用了多种技术和策略,包括但不限于:
- CORS(跨源资源共享,Cross-Origin Resource Sharing):通过服务端设置
Access-Control-Allow-Origin等响应头,允许特定来源的请求访问资源。 - JSONP(JSON with Padding):利用
<script>标签没有跨域限制的特点,通过动态插入<script>标签来实现跨域请求,通常用于GET请求。 - 代理服务器:设置一个代理服务器(如 Nginx 或自己搭建的代理服务),将跨域请求转发到目标服务器,从而绕过浏览器的同源策略限制。
- WebSockets:虽然主要用于实时通信,但WebSockets协议本身并不受同源策略限制,可以实现跨域通信。
- PostMessage API:HTML5引入的API,允许来自不同源的脚本采用异步方式进行有限制的通信,通常用于iframe间的跨域消息传递。
11. 接口的幂等性
接口的幂等性(Idempotency)是指一个操作或者API无论执行多少次,其结果都是一样的,对系统的影响也是一致的。换句话说,多次重复执行同一请求应该具有相同的效果,不会因为多次请求而导致额外的副作用,比如多次扣款、多次创建相同的记录等。
幂等性对于提升系统可靠性、处理网络重试和容错非常重要,尤其是在分布式系统和网络环境中,请求可能会因为网络延迟、丢包、重传等原因到达服务器多次。确保接口的幂等性可以简化系统设计,提高用户体验。
实现幂等性的策略
-
唯一标识: 对于每个可能改变系统状态的请求,生成一个唯一的标识符(例如事务ID),并在后续的重试中使用这个标识符检查操作是否已经执行过。如果之前已经处理过相同的请求(依据唯一ID判断),则直接返回之前的处理结果,不再执行业务逻辑。
-
乐观锁: 在更新数据时,利用数据的一个版本字段(如version或timestamp),每次更新时检查版本是否发生变化,如果版本与请求中的版本匹配,则执行更新并递增版本号;如果不匹配,则拒绝此次操作,因为数据已经被其他请求修改过。
-
悲观锁: 在处理请求前锁定资源,确保同一时间只有一个请求能操作资源,处理完后再释放锁。这种方法可能导致资源竞争和阻塞,因此在高并发场景下不太适用。
-
状态机: 对于有状态转换的操作,可以设计成状态机的形式,确保状态迁移是幂等的。每个状态只允许特定的转换,避免重复处理导致状态异常。
-
补偿机制: 如果无法直接实现幂等性,可以设计补偿操作来撤销或修正非幂等操作带来的副作用。例如,发生重复扣款时,可以通过退款操作来补偿。
12. 进程间的通信方式
进程间的通信(Inter-Process Communication, IPC)是多进程系统中非常关键的一部分,它允许不同的进程之间交换数据和同步执行。多种技术被用于实现进程间通信,以下是一些常见的进程间通信方式:
-
管道(Pipe)和命名管道(Named Pipe):
- 管道是一种半双工的通信方式,数据只能单向流动,通常用于具有亲缘关系的进程(例如,父子进程)之间的通信。
- 命名管道则是存在于文件系统中的一种特殊文件,它可以用于任意两个进程间的通信,无论它们是否有亲缘关系。
-
信号(Signal):
- 信号是一种进程间的异步通信方式,用于通知接收进程某个事件的发生,如程序终止、挂起等。信号处理机制允许进程对接收到的信号做出响应。
-
消息队列(Message Queue):
- 消息队列提供了一种低级的通信方式,允许多个进程读写一系列固定大小的消息。消息队列独立于发送和接收进程的生命周期,可以实现进程间的同步。
-
共享内存(Shared Memory):
- 共享内存是最直接的通信方式,它允许多个进程访问同一块内存区域。这种方式速度快,但需要程序员处理同步问题,如使用互斥锁(Mutex)或信号量来防止数据竞争。
-
信号量(Semaphore):
- 信号量是一种同步工具,用于解决多个进程对共享资源的访问控制问题。它不仅可以用来同步进程,还能作为一种计数器,限制对资源的访问数量。
-
套接字(Socket):
- 虽然最初是为了网络通信而设计的,但套接字同样可以用于同一台机器上不同进程间的通信,支持TCP(面向连接)和UDP(无连接)两种通信模式,具有很好的通用性和跨平台性。
-
内存映射文件(Memory-Mapped Files):
- 类似于共享内存,内存映射文件将文件映射到内存地址空间,使得进程可以像访问内存一样访问文件内容,适合大容量数据交换。
-
远程过程调用(Remote Procedure Call, RPC):
- RPC提供一种透明调用远程系统上过程的方法,让开发者感觉像是在调用本地函数,底层通过网络通信实现,常用于分布式系统中。
选择哪种通信方式取决于具体的应用需求,包括通信的数据量、实时性要求、是否需要跨网络通信、同步还是异步的需求等因素。
相关文章:

Python后端面试题
1. 文件操作w和r的区别 在Python中,文件操作模式中的w和r都表示对文件的读写操作,但它们在打开文件时的行为有所不同: r模式: 读写:这种模式允许你同时读取和写入文件。文件必须已经存在,否则会抛出一个Fi…...

docker打包 arm32v7/debian 问题总结
1.架构不同 我的宿主是x86 ,但是打包的是arm架构 安装qemu sudo apt-get install binfmt-support qemu qemu-user-static 然后使用buildx打包 docker buildx build --no-cache --platform linux/arm/v7 -t tdc_post:1.0.1 . --load 保存tar docker save -o tdc_post.tar tdc_p…...
【HarmonyOS4学习笔记】《HarmonyOS4+NEXT星河版入门到企业级实战教程》课程学习笔记(二十)
课程地址: 黑马程序员HarmonyOS4NEXT星河版入门到企业级实战教程,一套精通鸿蒙应用开发 (本篇笔记对应课程第 30 节) P30《29.数据持久化-用户首选项》 实现数据持久化在harmonyOS中有很多种方式,比较常见的是以下两…...

Vuetify3:监听当前手机还是电脑
我们在开发的时候,实现根据移动设备或PC设备来改编一些交互样式,这个时候我们需要监听宽度,在Vuetify3中可我们可以参考 显示 & 平台配合监听即可在窗口缩小的时候判断出手机还是电脑 <template><v-app><div v-if…...
Zabbix 配置钉钉告警
Zabbix 配置钉钉告警 随着企业IT运维需求的不断增加,及时、准确地获取系统告警信息显得尤为重要。在众多告警工具中,Zabbix 因其强大的监控功能和灵活的告警机制,成为了很多企业的首选。同时,随着企业内部沟通工具的多样化&#…...

TTL转RS232与USB转TTL
USB转TTL是一种常用的通信接口转换器,它将USB(通用串行总线)接口转换为TTL(晶体管-晶体管逻辑)电平的串行接口。这种转换器在许多场景下非常有用: USB转TTL: 功能: 将计算机的USB接…...
)
【力扣 896】单调数列 C++题解(循环)
如果数组是单调递增或单调递减的,那么它是 单调 的。 如果对于所有 i < j,nums[i] < nums[j],那么数组 nums 是单调递增的。 如果对于所有 i < j,nums[i]> nums[j],那么数组 nums 是单调递减的。 当给定…...
)
代码随想录Day71(图论Part07)
53.寻宝 题目:53. 寻宝(第七期模拟笔试) (kamacoder.com) 思路:首先,我不知道怎么存这样的东西,用三维数组吗,没搞懂,果断放弃 prim算法实现 import java.util.*;class Main {publi…...
)
[Mdp] lc 494. 目标和(01背包变种+dp+dfs)
文章目录 1. 题目来源2. 题目解析1. 题目来源 链接:494. 目标和 2. 题目解析 方法一:dfs 数据量比较小,长度只有 20,那么针对每一个数都有两种选择,正、负,即 2 20 = 100 w 2^{20} = 100w 220=100w 差不多的时间复杂度,dfs 解决即可。时间复杂度: O ( 2 n ) O(2^{n…...

React vs Vue:谁是构建现代Web应用的王者?
在前端开发领域,React 和 Vue 是两大备受推崇的框架(React实为库),各自拥有庞大的社区和丰富的生态系统。本文旨在深入探讨这两者之间的区别,通过代码示例来分析它们各自的优势和适用场景,从而帮助开发者做…...
Linux CentOS 宝塔中禁用php8.2的eval函数详细图文教程
PHP_diseval_extension 这个方法是支持PHP8的, Suhosin禁用eval函数,不支持PHP8 一、安装 cd / git clone https://github.com/mk-j/PHP_diseval_extension.gitcd /PHP_diseval_extension/source/www/server/php/82/bin/phpize ./configure --with-php-config/ww…...

Matlab 中 fftshift 与 ifftshift
文章目录 【 1. fftshift、ifftshift 的区别】【 2. fftshift(fft(A)) 作图 】【 3. fftshift(fft(A)) 还原到 A 】Matlab 直接对信号进行 FFT 的结果中,前半部分是正频,后半部分是负频,为了更直观的表示,需要将 负频 部分移到 前面。【 1. fftshift、ifftshift 的区别】 M…...
)
被裁了(9年)
那年(2015年)我刚毕业有一年多(20出头),阴差阳错来到了现在的单位。 那时互联网腾起,单位也迅速发展,部门从起初的不到30号人发展到500人;A轮、B轮.....D轮,一轮轮的融资…...
13. Revit API: Filter(过滤器)
13. Revit API: Filter(过滤器) 前言 在讲Selection之前,还是有必要先了解一下的过滤器的。 对了,关于查找一些比较偏的功能或者API的用法,可以这样查找 关键词 site:https://thebuildingcoder.typepad.com/ site是…...
)
hadoop 3.X 分布式HA集成Kerbos(保姆级教程)
前提:先安装Kerbos 1、创建keytab目录 在每台机器上上提前创建好对应的kertab目录 [hadooptv3-hadoop-01 ~]$ sudo mkdir -p /BigData/run/hadoop/keytab/ [hadooptv3-hadoop-01 ~]$ sudo mkdir -p /opt/security/ [hadooptv3-hadoop-01 ~]$ sudo chown hadoop:had…...
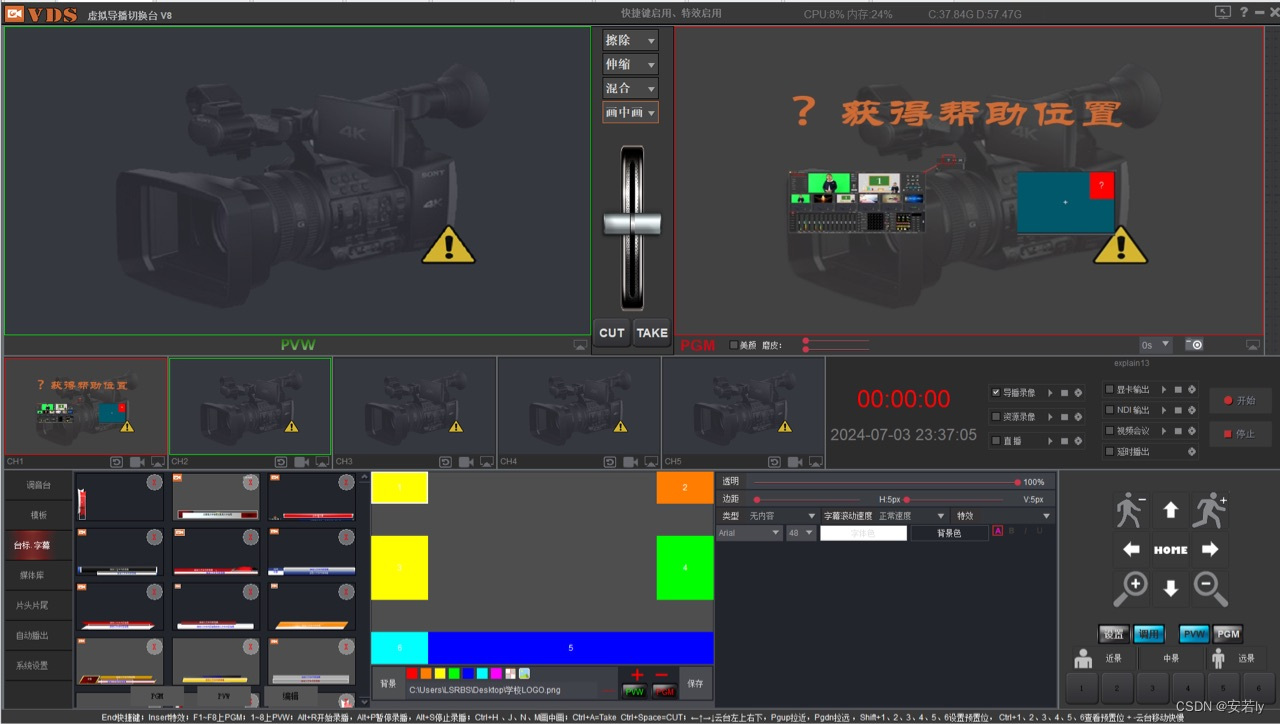
VDS虚拟导播切换台软件
VDS 导播软件是一款功能强大的虚拟导播系统软件,具有全媒体接入、播出内容丰富、调音台、快捷切播与导播键盘、云台控制等特点,同时支持向多个平台直播推流。以下是一些常见的 VDS 导播软件特点: 1. 全媒体接入:支持多种设备和网…...

UE4_材质_使用彩色半透明阴影
学习笔记,不喜勿喷!侵权立删,祝愿大美临沂生活越来越好! 本教程将介绍如何配置虚幻引擎来投射彩色半透明阴影。 此功能在许多应用中都很有用,常见例子就是透过彩色玻璃窗的彩色光。 一、半透明阴影颜色 阴影在穿过半…...
monior等)
arthas监控工具笔记(二)monior等
文章目录 monitor/watch/trace 相关monitormonitor例子monitor -c <value>monitor -m <vaule>monitor 条件表达式monitor -b monitor文档(界面描述)monitor文档(help) stack - 输出当前方法被调用的调用路径trace - 方法内部调用路径,并输出方法路径上的…...

【mybatis】mybatis-plus中主键生成策略
1、简介 MyBatis-Plus 中的主键生成策略是一个关键特性,它决定了如何为新插入的行生成唯一标识符(即主键)。MyBatis-Plus 提供了多种主键生成策略,以满足不同场景下的需求。 2、常见主键生成策略 1. AUTO(数据库ID自…...

模型情景制作-如何制作棕榈树
夏天,沙滩,海景,棕榈树,外加美女,想象下热带海滨的样子吧 可是口年的上班族没有多少机会去到海滩,肿么办?我们自己DIY一个海滨情景摆在办公桌上吧~~~ 什么什么?棕榈树不会做…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...