spark shuffle——shuffle管理
ShuffleManager
shuffle系统的入口。ShuffleManager在driver和executor中的sparkEnv中创建。在driver中注册shuffle,在executor中读取和写入数据。
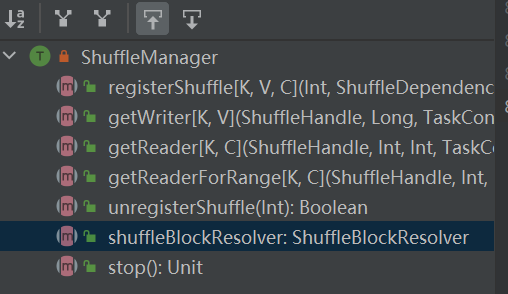
registerShuffle:注册shuffle,返回shuffleHandle
unregisterShuffle:移除shuffle
shuffleBlockResolver:获取shuffleBlockResolver,用于处理shuffle和block之间的关系
getWriter:获取partition对应的writer,在executor的map task中调用
getReader、getReaderForRange:获取一段范围partition的reader,在executor的 reduce task中调用
SortShuffleManager
是shuffleManager的唯一实现。
在基于sort的shuffle中,进入的消息会按照partition进行排序,最后输出一个单独的文件。
reducer会读取这个文件的一段区域数据。
当输出的文件太大了,不能全部放在内存中的时候,会spill在磁盘上生成排序的中间结果文件,这些中间文件会合并成一个最终文件输出。
Sort-based shuffle有两个方式:
- 序列化sort,使用序列化sort需要满足三个条件:
- 没有map-side combine
- 支持序列化的值relocation(KryoSerializer和sparkSql自定义序列化器)
- 小于等于16777216个partition
- 非序列化sort,其它所有情况都可以使用非序列化sort
序列化sort的优势
在序列化sort模式下,shuffle writer将进来的消息序列化后保存在一个数据结构中并排序。
- 二进制数据排序而非Java对象:排序操作直接在序列化的二进制数据上进行,而不是在Java对象上,这样可以降低内存消耗并减少垃圾回收(GC)的开销。
这一优化要求所使用的记录序列化器具备特定属性,使得序列化后的记录能够在无需先反序列化的情况下重新排序。 - 高效的缓存排序算法:采用专门设计的缓存效率高的排序器(ShuffleExternalSorter),它能够对压缩后的记录指针数组和分区ID进行排序。通过每个记录仅占用8字节的空间,这种策略使得更多的数据能够装入缓存中,从而提升性能。
- 溢出合并过程针对同一分区内的序列化记录块进行,整个合并过程中不需要对记录进行反序列化,避免了不必要的数据转换开销。
- 如果溢出压缩编解码器支持压缩数据的拼接,那么溢出合并过程仅需简单地将序列化并压缩过的溢出分区数据拼接起来,形成最终输出分区。这允许使用高效的直接数据拷贝方法,如NIO中的transferTo,并且在合并过程中避免了分配解压缩或复制缓冲区的需要,提升了整体效率。
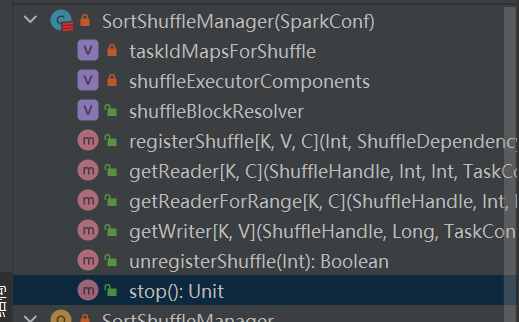
registerShuffle
根据不同场景选择对应的handle。优先顺序是BypassMergeSortShuffleHandle>SerializedShuffleHandle>BaseShuffleHandle
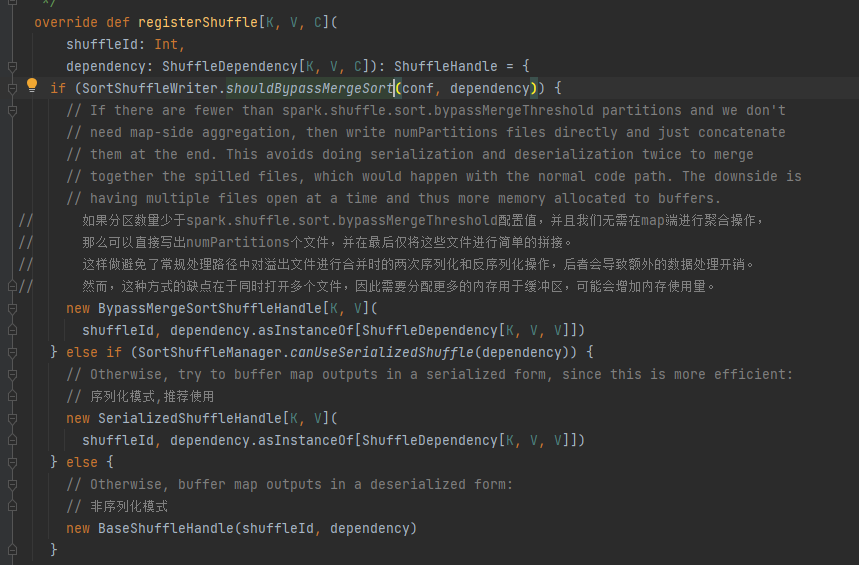
bypass条件:没有mapside,partition数量小于等于_SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD_

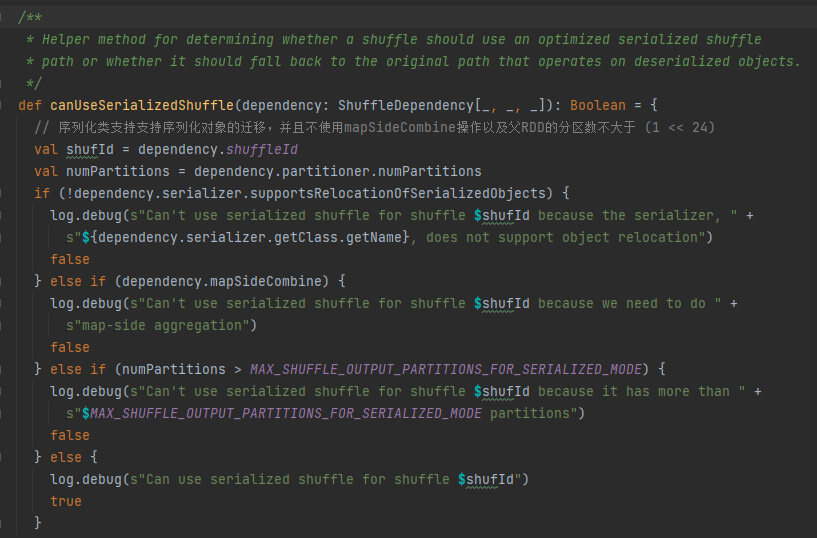
序列化handle条件:序列化类支持支持序列化对象的迁移,并且不使用mapSideCombine操作以及父RDD的分区数不大于 (1 << 24)
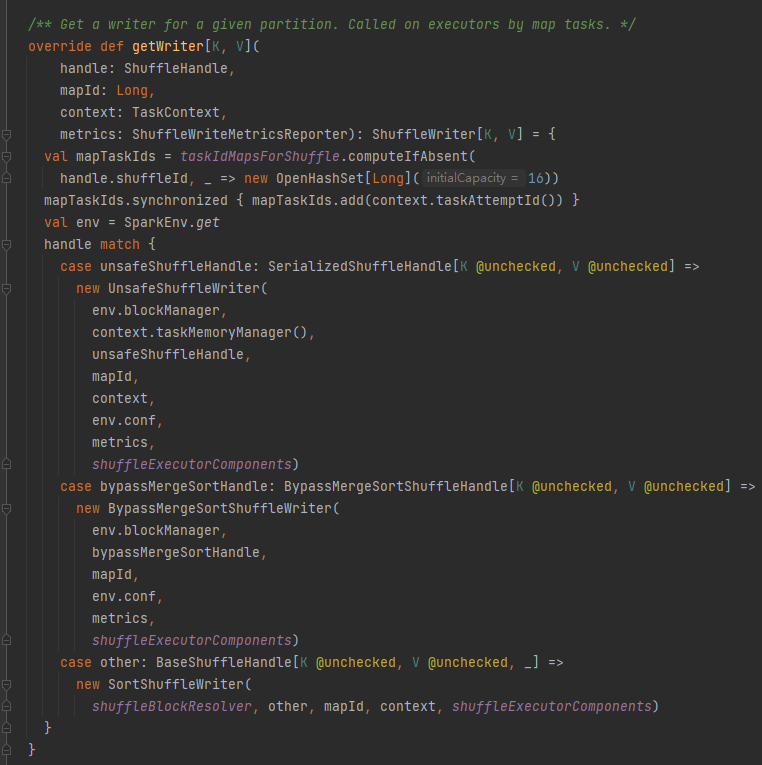
getWriter
首先缓存此次的shuffle和map信息到taskIdMapsForShuffle_中_
根据shuffle对应的handle选择对应的writer.
BypassMergeSortShuffleHandle->BypassMergeSortShuffleWriter
SerializedShuffleHandle->UnsafeShuffleWriter
BaseShuffleHandle->SortShuffleWriter
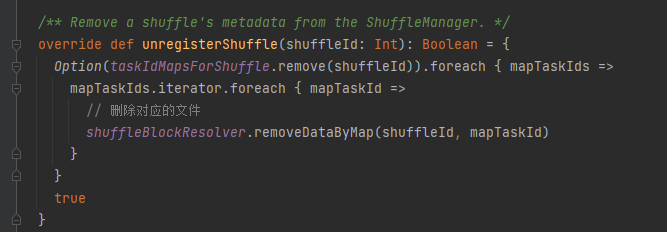
unregisterShuffle
taskIdMapsForShuffle移除对应的shuffle和shuffle对应map产生的文件
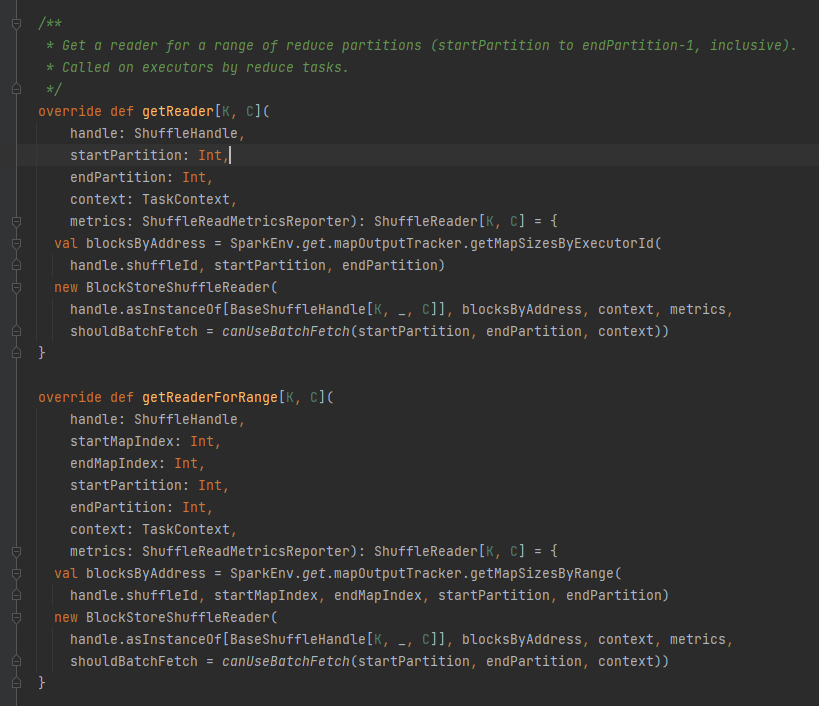
getReader/getReaderForRange
获取shuffle文件对应全部block地址,即blocksByAddress.
创建BlockStoreShuffleReader对象并返回.
ShuffleHandle
主要是用来传递shuffle的参数,同时也是一个标记,标记选择哪个writer
BaseShuffleHandle

BypassMergeSortShuffleHandle

SerializedShuffleHandle
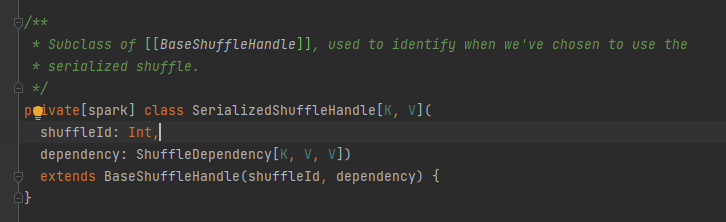
ShuffleWriter
抽象类,负责map任务输出消息.主要方法是write,有三个实现类
- BypassMergeSortShuffleWriter
- SortShuffleWriter
- UnsafeShuffleWriter
后面在单独分析。
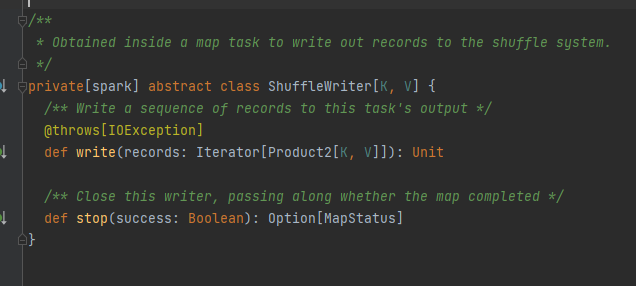
ShuffleBlockResolver
特质,实现类可以根据mapId、reduceId、shuffleId来获取对应的block数据.
IndexShuffleBlockResolver
ShuffleBlockResolver的唯一实现类。
创建并维护逻辑块与物理文件位置之间的映射关系,针对来自同一map任务的shuffle块数据。
属于同一个map任务的shuffle块数据会被存储在一个整合的数据文件中。
而这些数据块在数据文件中的偏移量,则被单独存储在一个索引文件中。
.data是数据文件后缀
.index是索引文件后缀
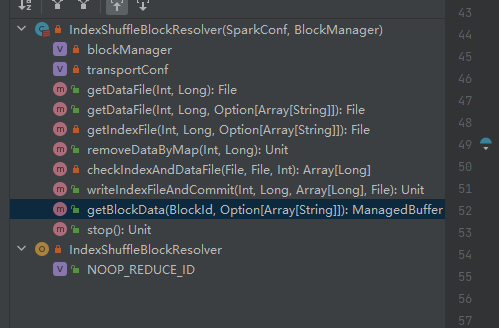
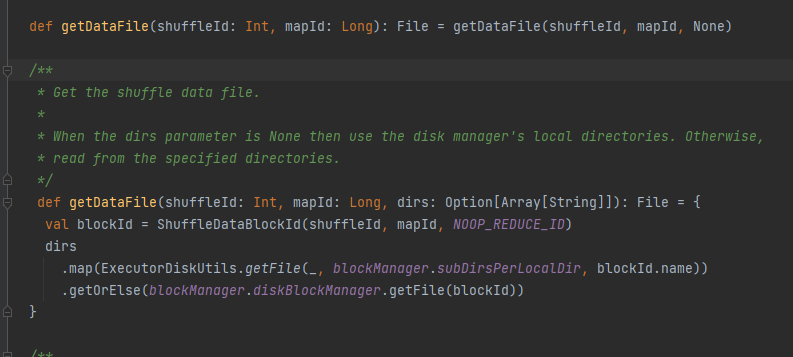
getDataFile
获取数据文件。
生成ShuffleDataBlockId,调用的blockManager.diskBlockManager.getFile方法获取file
getIndexFile
同getDataFile类似
生成ShuffleIndexBlockId,调用的blockManager.diskBlockManager.getFile方法获取file

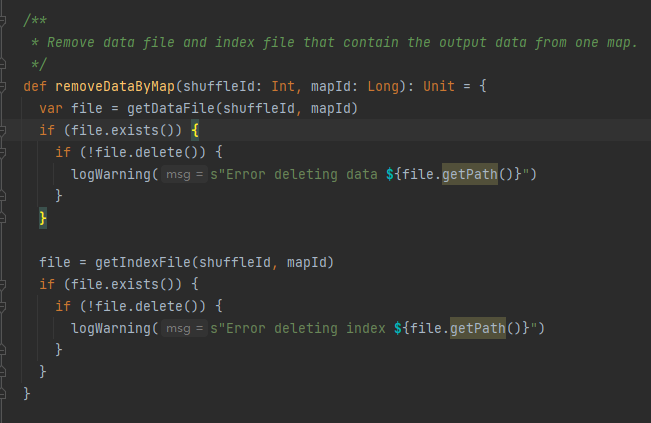
removeDataByMap
根据shuffleId和mapId获取到data文件和index文件,然后删除
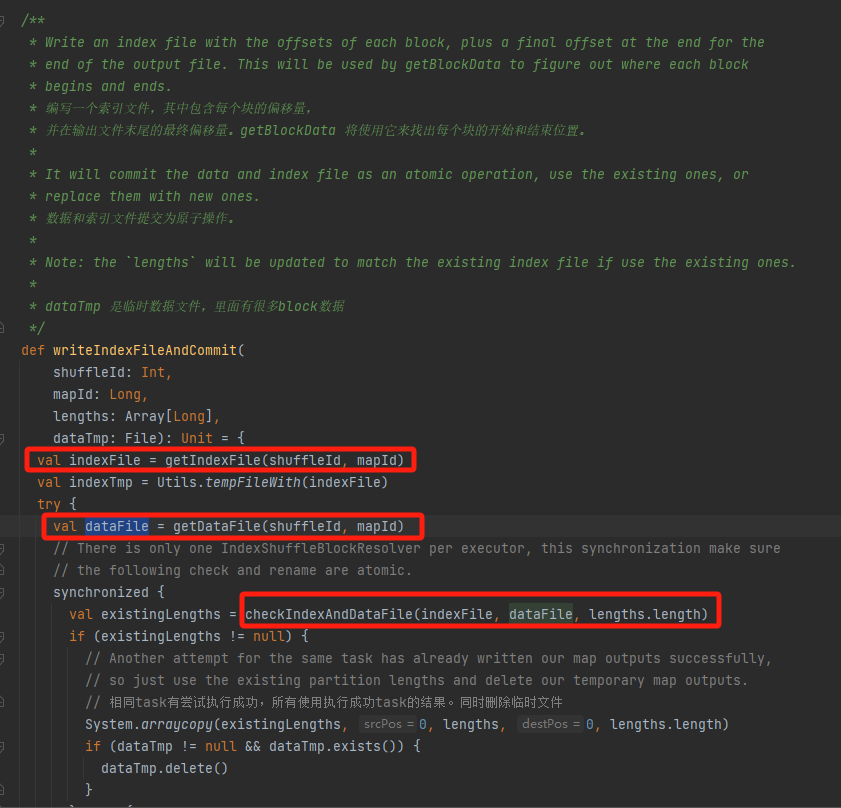
writeIndexFileAndCommit
根据mapId、shuffleId获取对应的data文件和index文件。
检查data文件和index文件是否存在并且能够匹配上,直接返回。
不能匹配上,就生成新的index临时文件。再重命名生成新的index文件和data文件并返回。

假设shuffle有3个partition,对应数据大小分别是1000、1500、2500。
index文件,首行是0,后面都是partition数据的累加值,第二行是1000,第三行是1000+1500=2500,第三行是2500+2500=5000.
data文件是按照partition大小排序进行存储的。

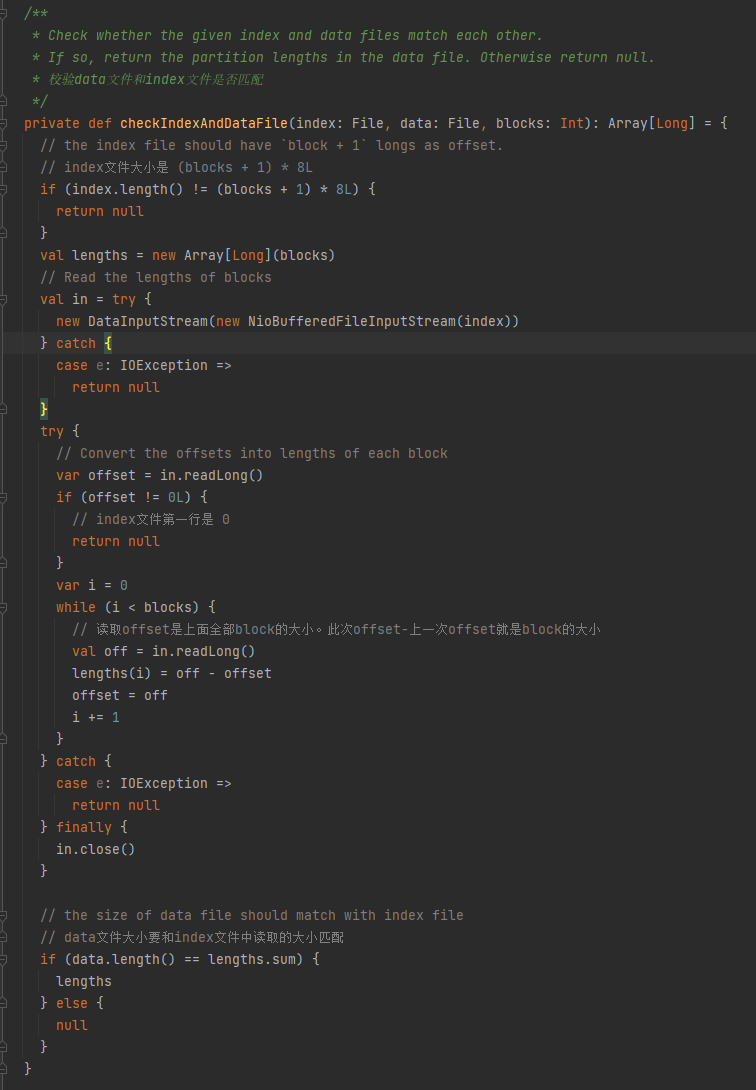
checkIndexAndDataFile
校验data文件和index文件是否匹配,不匹配返回null,匹配返回partition大小的数组。
1.index文件大小是 (blocks + 1) * 8L
2.index文件第一行是 0
3.获取partition的大小写入lengths,lengths的汇总值等于data文件大小
满足上面三个条件,返回lengths,否则返回null
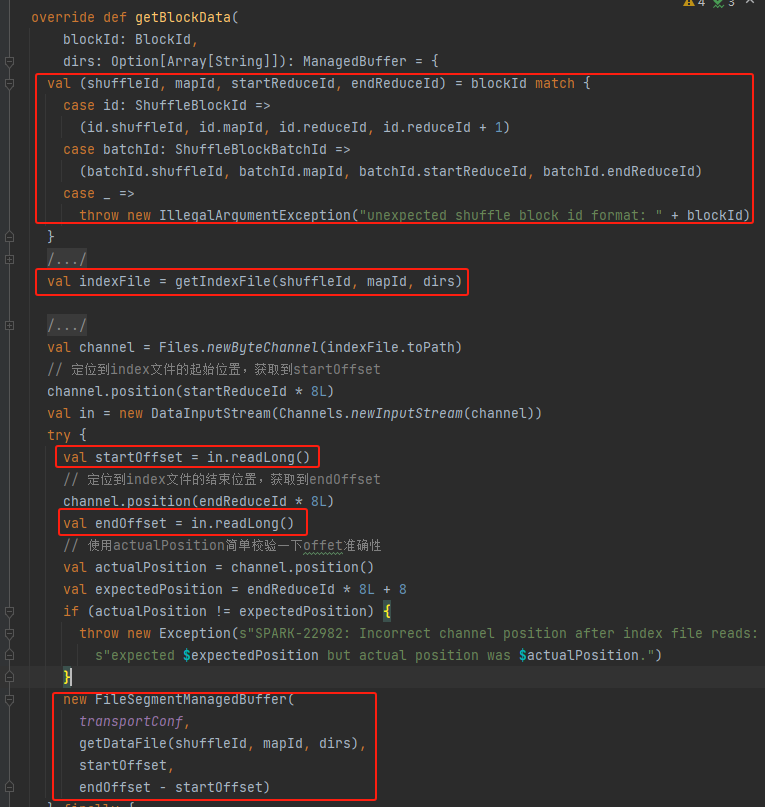
getBlockData
获取到shuffleId、mapId、startReduceId、endReduceId
获取到index文件
读取对应的startOffset和endOffset
使用data文件、startOffset、endOffset生成FileSegmentManagedBuffer并返回
相关文章:
spark shuffle——shuffle管理
ShuffleManager shuffle系统的入口。ShuffleManager在driver和executor中的sparkEnv中创建。在driver中注册shuffle,在executor中读取和写入数据。 registerShuffle:注册shuffle,返回shuffleHandle unregisterShuffle:移除shuff…...

HTMLCSS(入门)
HTML <html> <head><title>第一个页面</title></head><body>键盘敲烂,工资过万</body> </html> <!DOCTYPE>文档类型声明,告诉浏览器使用哪种HTML版本显示网页 <!DOCTYPE html>当前页面采取…...

富格林:曝光可信策略制止亏损
富格林指出,相信大家都对黄金投资的价值空间有目共睹,现如今黄金市场波动频繁,因此不少投资者也开始加入该市场试图赢得额外的财富。但作为新手投资者贸贸然地进场操作,亏损的几率是很大的,因此要学会掌握正规平台曝光…...

Android --- Service
出自于此,写得很清楚。关于Android Service真正的完全详解,你需要知道的一切_android service-CSDN博客 出自【zejian的博客】 什么是Service? Service(服务)是一个一种可以在后台执行长时间运行操作而没有用户界面的应用组件。 服务可由其他应用组件…...

Vue3从入门到精通(三)
vue3插槽Slots 在 Vue3 中,插槽(Slots)的使用方式与 Vue2 中基本相同,但有一些细微的差异。以下是在 Vue3 中使用插槽的示例: // ChildComponent.vue <template><div><h2>Child Component</h2&…...

【FreeRTOS】同步与互斥通信-有缺陷的互斥案例
目录 同步与互斥通信同步与互斥的概念同步与互斥并不简单缺陷分析汇编指令优化过程 - 关闭中断时间轴分析 思考时刻 参考《FreeRTOS入门与工程实践(基于DshanMCU-103).pdf》 同步与互斥通信 同步与互斥的概念 一句话理解同步与互斥:我等你用完厕所,我再…...

Docker 安装 Python
Docker 安装 Python 在当今的软件开发领域,Docker 已成为一项关键技术,它允许开发人员将应用程序及其依赖环境打包到一个可移植的容器中。Python,作为一种广泛使用的高级编程语言,经常被部署在 Docker 容器中。本文将详细介绍如何在 Docker 中安装 Python,以及如何配置环…...
外泌体相关基因肝癌临床模型预测——2-3分纯生信文章复现——4.预后相关外泌体基因确定单因素cox回归(2)
内容如下: 1.外泌体和肝癌TCGA数据下载 2.数据格式整理 3.差异表达基因筛选 4.预后相关外泌体基因确定 5.拷贝数变异及突变图谱 6.外泌体基因功能注释 7.LASSO回归筛选外泌体预后模型 8.预后模型验证 9.预后模型鲁棒性分析 10.独立预后因素分析及与临床的…...

C++: Map数组的遍历
在C中,map是一个关联容器,它存储的元素是键值对(key-value pairs),其中每个键都是唯一的,并且自动根据键来排序。遍历map的方式有几种,但最常用的两种是使用迭代器(iterator…...

【Windows】Bootstrap Studio(网页设计)软件介绍及安装步骤
软件介绍 Bootstrap Studio 是一款专为前端开发者设计的强大工具,主要用于快速创建现代化的响应式网页和网站。以下是它的主要特点和功能: 直观的界面设计 Bootstrap Studio 提供了直观的用户界面,使用户能够轻松拖放元素来构建网页。界面…...

二维舵机颜色追踪,使用树莓派+opencv+usb摄像头+两个舵机实现颜色追踪,采用pid调控
效果演示 二维云台颜色追踪 使用树莓派opencvusb摄像头两个舵机实现颜色追踪,采用pid调控 import cv2 import time import numpy as np from threading import Thread from servo import Servo from pid import PID# 初始化伺服电机 pan Servo(pin19) tilt Serv…...

c进阶篇(四):内存函数
内存函数以字节为单位更改 1.memcpy memcpy 是 C/C 中的一个标准库函数,用于内存拷贝操作。它的原型通常定义在 <cstring> 头文件中,其作用是将一块内存中的数据复制到另一块内存中。 函数原型:void *memcpy(void *dest, const void…...

新手入门:无服务器函数和FaaS简介
无服务器(Serverless)架构的价值在于其成本效益、弹性和扩展性、简化的开发和部署流程、高可用性和可靠性以及使开发者能够专注于业务逻辑。通过自动化资源调配和按需计费,无服务器架构能够降低成本并适应流量变化,同时简化开发流…...

基于Transformer的端到端的目标检测 | 读论文
本文正在参加 人工智能创作者扶持计划 提及到计算机视觉的目标检测,我们一般会最先想到卷积神经网络(CNN),因为这算是目标检测领域的开山之作了,在很长的一段时间里人们都折服于卷积神经网络在图像处理领域的优势&…...
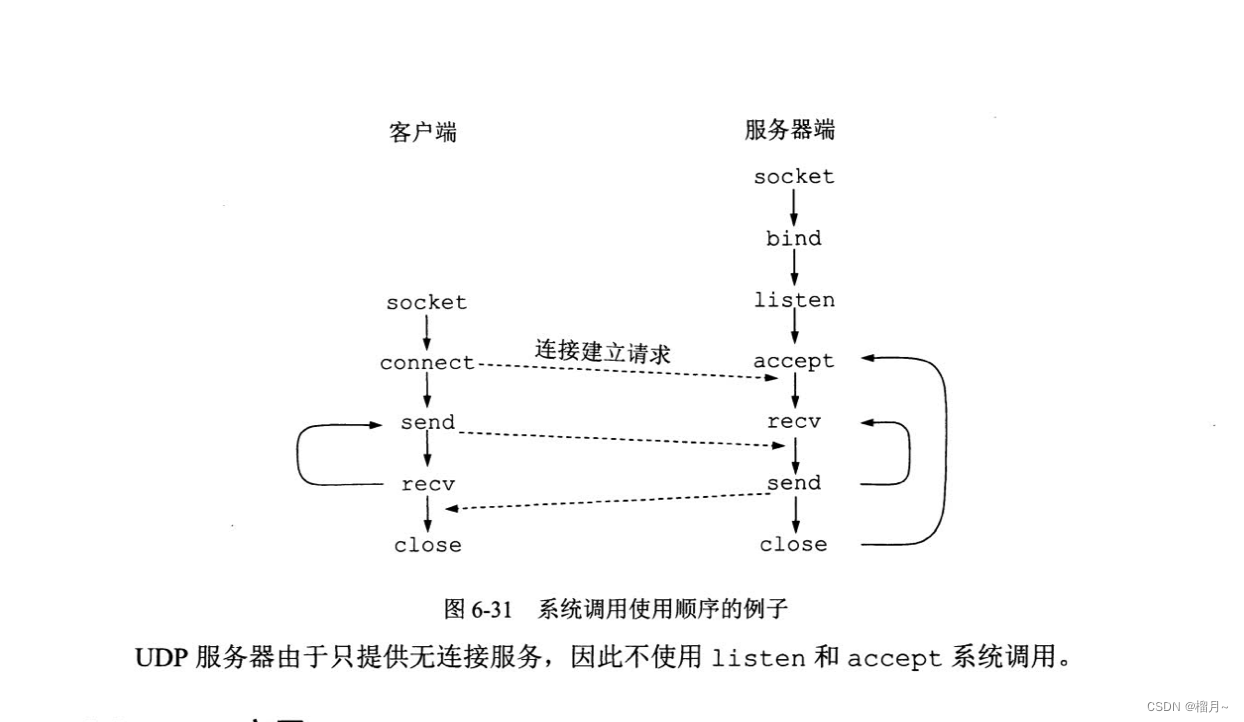
6.8应用进程跨网络通信
《计算机网络》第7版,谢希仁 理解socket通信...

redis布隆过滤器原理及应用场景
目录 原理 应用场景 优点 缺点 布隆过滤器(Bloom Filter)是一种空间效率很高的随机数据结构,它利用位数组和哈希函数来判断一个元素是否存在于集合中。 原理 数据结构: 位数组:一个由0和1组成的数组,初始…...
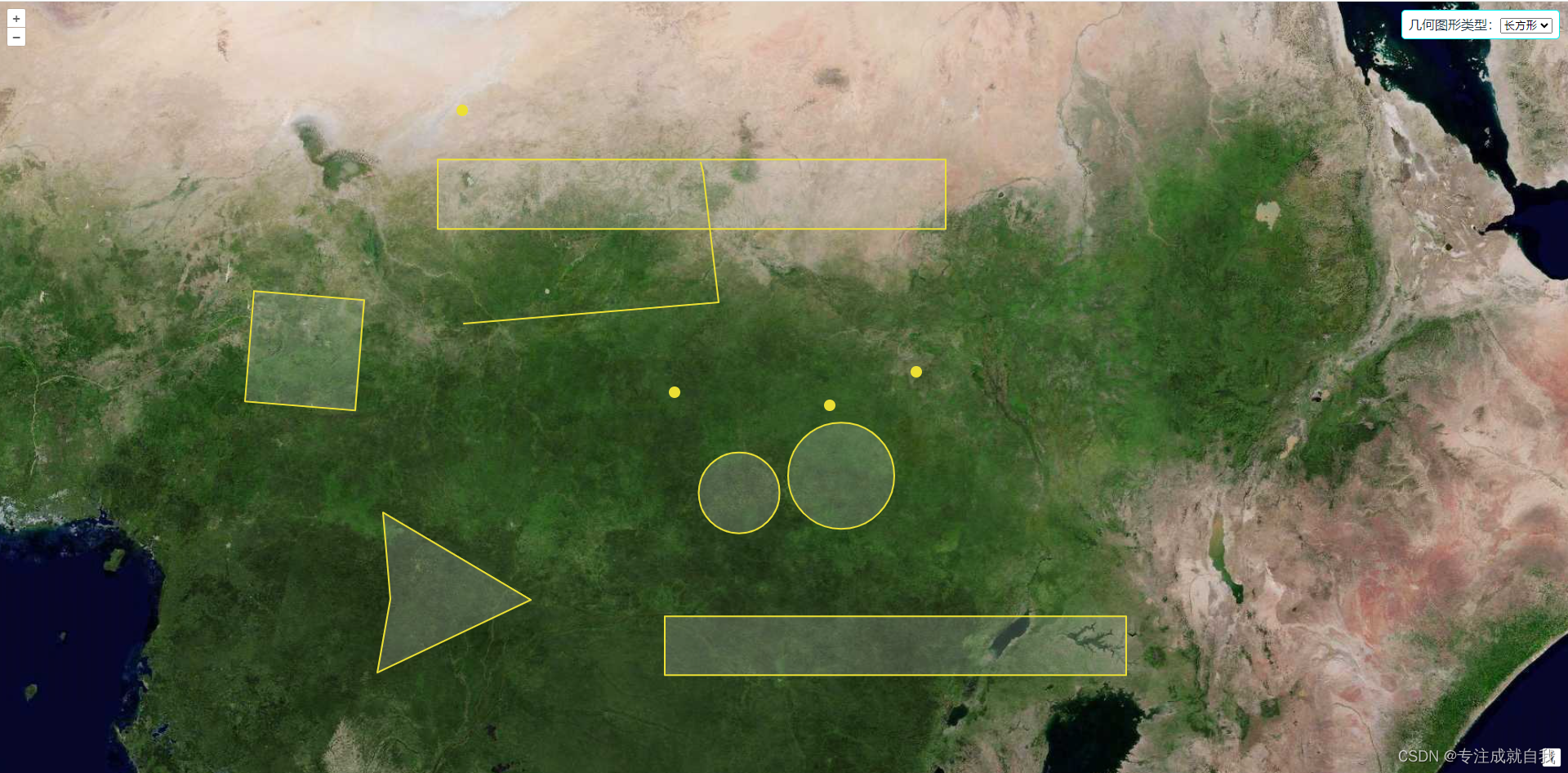
vue+openlayers之几何图形交互绘制基础与实践
文章目录 1.实现效果2.实现步骤3.示例页面代码3.基本几何图形绘制的关键代码 1.实现效果 绘制点、线、多边形、圆、正方形、长方形 2.实现步骤 引用openlayers开发库。加载天地图wmts瓦片地图。在页面上添加几何图形绘制的功能按钮,使用下拉列表(sel…...

「多模态大模型」解读 | 突破单一文本模态局限
编者按:理想状况下,世界上的万事万物都能以文字的形式呈现,如此一来,我们似乎仅凭大语言模型(LLMs)就能完成所有任务。然而,理想很丰满,现实很骨感——数据形态远不止文字一种&#…...

Redis深度解析:核心数据类型与键操作全攻略
文章目录 前言redis数据类型string1. 设置单个字符串数据2.设置多个字符串类型的数据3.字符串拼接值4.根据键获取字符串的值5.根据多个键获取多个值6.自增自减7.获取字符串的长度8.比特流操作key操作a.查找键b.设置键值的过期时间c.查看键的有效期d.设置key的有效期e.判断键是否…...
C语言 指针和数组——指针的算术运算
目录 指针的算术运算 指针加上一个整数 指针减去一个整数 指针相减 指针的关系比较运算 小结 指针的算术运算 指针加上一个整数 指针减去一个整数 指针相减 指针的关系比较运算 小结 指针变量 – 指针类型的变量,保存地址型数据 指针变量与其他类型…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...