【深度学习】图形模型基础(5):线性回归模型第一部分:认识线性回归模型
1. 回归模型定义
最简单的回归模型是具有单一预测变量的线性模型,其基本形式如下:
y = a + b x + ϵ y = a + bx + \epsilon y=a+bx+ϵ
其中, a a a 和 b b b 被称为模型的系数或更一般地,模型的参数。 ϵ \epsilon ϵ 代表误差项,即模型未能解释的变异性。
简单的线性模型可以通过多种方式进行扩展,以适应更复杂的数据结构和关系,包括但不限于以下几种:
- 包含额外的预测变量:
当模型中包含多个预测变量时,其形式变为:
y = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β k x k + ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k + \epsilon y=β0+β1x1+β2x2+⋯+βkxk+ϵ
这可以进一步以向量-矩阵表示法写为:
y = X β + ϵ \mathbf{y} = \mathbf{X} \mathbf{\beta} + \mathbf{\epsilon} y=Xβ+ϵ
其中, y \mathbf{y} y 是因变量向量, X \mathbf{X} X 是设计矩阵(包含所有预测变量和常数项), β \mathbf{\beta} β 是系数向量, ϵ \mathbf{\epsilon} ϵ 是误差向量。
- 非线性模型:
当预测变量与因变量之间的关系不是线性时,可以考虑非线性模型,如对数线性模型:
log y = α + β log x + ϵ \log y = \alpha + \beta \log x + \epsilon logy=α+βlogx+ϵ
这种模型允许通过变换变量来探索非线性关系。
- 非加性模型:
在某些情况下,预测变量之间可能存在交互作用,此时可以使用非加性模型,如包含交互项的模型:
y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 1 x 2 + ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_1 x_2 + \epsilon y=β0+β1x1+β2x2+β3x1x2+ϵ
这样的模型能够捕捉到变量间的复杂关系。
-
广义线性模型(GLM):
GLM 扩展了线性回归模型,使其能够处理因变量服从非正态分布的情况,如二项分布(用于逻辑回归)、泊松分布等。GLM 通过链接函数将线性预测值与因变量的期望值联系起来。 -
非参数模型:
非参数模型不预设函数形式,而是通过数据本身来估计预测变量与因变量之间的关系。这类模型通常包含大量的参数,以允许预测值随预测变量的变化而灵活变化。 -
多层次模型(Hierarchical Models 或 Mixed Effects Models):
在这些模型中,回归系数可能因组或情境而异。例如,在预测不同大学学生的成绩时,可以允许每个大学的系数有所不同,以反映不同大学的特定效应。 -
测量误差模型:
当预测变量和因变量都存在测量误差时,可以使用测量误差模型来估计底层真实量之间的关系。这类模型在处理带有不确定性的数据时特别有用,如部分依从性研究中的药物效果估计。
2 使用R和 r s t a n a r m rstanarm rstanarm拟合简单线性回归
在本节中,我们将通过R中的rstanarm包来演示如何拟合一个简单的线性回归模型到模拟的假数据上。rstanarm利用Stan的统计推断引擎来执行贝叶斯回归分析,这为我们提供了参数估计的不确定性度量。
2.1. 模拟数据集
首先,我们模拟一组包含20个数据点的假数据集,这些数据点遵循线性关系 ( y_i = a + bx_i + \epsilon_i ),其中 ( x_i ) 从1到20,截距 ( a = 0.2 ),斜率 ( b = 0.3 ),误差项 ( \epsilon_i ) 服从均值为0、标准差为0.5的正态分布。
# 加载rstanarm包
library(rstanarm)# 设置预测变量x
x <- 1:20
n <- length(x)# 设置模型参数
a <- 0.2
b <- 0.3
sigma <- 0.5# 生成响应变量y
y <- a + b * x + sigma * rnorm(n)# 将数据组合成数据框
fake <- data.frame(x, y)
2.2. 拟合线性回归模型
接下来,我们使用stan_glm函数来拟合线性回归模型。这个函数允许我们指定模型公式(在这里是y ~ x)和数据集(fake)。
# 拟合模型
fit_1 <- stan_glm(y ~ x, data = fake)# 显示拟合结果
print(fit_1, digits = 2)
输出将展示模型参数的估计值及其不确定性度量(中位数和MAD_SD,即中位数绝对偏差标准差)。
2.3. 绘制数据和拟合线
为了直观地展示数据和拟合的回归线,我们可以使用R的绘图功能。
# 绘制数据点
plot(fake$x, fake$y, main = "Data and fitted regression line", xlab = "x", ylab = "y")# 提取拟合的截距和斜率
a_hat <- coef(fit_1)[1]
b_hat <- coef(fit_1)[2]# 绘制拟合线
abline(a_hat, b_hat, col = "red")# 在图表上添加公式
x_bar <- mean(fake$x)
text(x_bar, a_hat + b_hat * x_bar, paste("y =", round(a_hat, 2), "+", round(b_hat, 2), "* x"), adj = 0)
2.4. 比较估计值与假定参数值
拟合模型后,我们可以将估计的参数值与模拟时设定的假定值进行比较。由于贝叶斯方法提供了参数的不确定性度量,我们可以观察到估计值如何围绕真实值波动。
- 截距 ( a ) 的假定值为0.2,估计值为0.40(带有不确定性)。
- 斜率 ( b ) 的假定值为0.3,估计值为0.28(带有不确定性)。
- 残差标准差 ( \sigma ) 的估计值为0.49(带有不确定性)。
这些估计值在它们各自的真实值的一个或两个标准误差范围内,这是符合预期的。重要的是要注意,任何单次模拟的估计值都可能不会精确地等于真实值,但在多次重复模拟下,我们期望看到估计值能够正确地覆盖真实值。
通过这种方式,我们可以利用rstanarm包和R的强大功能来拟合线性回归模型,并深入理解模型参数的不确定性。
3. 回归系数的解释
在回归分析中,我们常常会遇到将回归系数称为“效应”的表述,但这种表述往往容易引发误解。为了更准确地理解这些系数,我们通过一个具体的例子来探讨其含义,这个例子涉及使用身高(以英寸为单位)和性别(男性=1,女性=0)来预测1816名受访者的年收入(以千美元计)。
3.1.拟合模型与结果解读
首先,我们使用rstanarm包中的stan_glm函数来拟合模型,代码如下:
# 假设earnings数据框已包含earn(年收入)和height(身高)以及male(性别)变量
earnings$earnk <- earnings$earn / 1000 # 将年收入转换为千美元
fit_2 <- stan_glm(earnk ~ height + male, data = earnings)
print(fit_2, digits = 2)
输出结果可能如下:
Median MAD_SD
(Intercept) -26.0 11.8
height 0.6 0.2
male 10.6 1.5
Auxiliary parameter(s):
Median MAD_SD
sigma 21.4 0.3
这些输出显示了模型参数的估计值及其不确定性。特别地,height的系数表明,在保持其他因素不变的情况下,身高每增加一英寸,平均预期年收入会增加600美元(因为系数是0.6,乘以1000得到千美元单位下的值)。同样,male的系数表示,在身高相同的情况下,男性的平均预期年收入比女性高10,600美元。
3.2.理解残差标准差与 R 2 R^2 R2
残差标准差 σ σ σ估计为21.4千美元,这意味着大多数(约68%)的数据点的实际年收入将位于模型预测值的±21,400美元范围内,而95%的数据点将位于±42,800美元范围内。这是基于正态分布性质的近似估计,尽管实际误差分布可能不完全符合正态分布。
通过计算 R 2 R^2 R2值(决定系数),我们可以评估模型对总方差的解释程度。 R 2 = 0.10 R^2 = 0.10 R2=0.10表示线性模型仅解释了年收入总方差的10%,这反映了年收入变化的复杂性和多因素影响性。
3.3.回归系数的正确解释
重要的是要认识到,将回归系数直接称为“效应”可能不够准确,因为它们更多地反映了样本中的平均比较关系,而非因果效应。具体来说:
- 身高的系数:不应简单地理解为“身高对收入的效应是600美元”。更恰当的解释是,在控制性别和其他潜在影响因素后,样本中身高相差一英寸的两个个体,其平均年收入差异约为600美元。
- 性别的系数:同样,说“性别对收入的效应是10,600美元”也是不准确的。更准确的表述是,在控制身高和其他潜在影响因素后,样本中身高相同的男性和女性,男性的平均年收入比女性高10,600美元。
回归系数是预测工具中不可或缺的一部分,但它们应该被解释为描述性的比较关系,而非直接的因果效应。在缺乏额外因果推断证据的情况下,我们应谨慎地将回归结果用于因果解释。回归分析的真正力量在于其预测和描述能力,而非直接揭示因果关系。
4 .回归的历史起源
在字典中,"回归"一词被定义为“退回到较少完善或较少发达状态的过程或实例”。然而,在统计学中,这个术语被赋予了全新的含义,这主要归功于弗朗西斯·高尔顿(Francis Galton)的开创性工作。作为最初的定量社会科学家之一,高尔顿通过拟合线性模型来探索人类身高的遗传规律。他观察到,在预测孩子的身高时,基于父母的身高,高个子父母的孩子的身高虽然高于平均水平,但往往比他们的父母矮;相反,矮个子父母的孩子的身高则倾向于比平均水平矮,但高于他们的父母。这一现象在统计术语中被形象地称为“回归”到平均值或均值。
4.1.女儿身高“回归”到平均值
为了更具体地说明这一点,我们可以引用卡尔·皮尔逊(Karl Pearson)和爱丽丝·李(Alice Lee)在1903年发表的一项经典身高遗传研究。图6.3a展示了母亲和女儿的身高数据,以及一条最佳拟合线(回归线),用于根据母亲的身高预测女儿的身高。这条线穿过x轴和y轴的平均值(由中心的大点表示)。
图6.3b单独展示了这条回归线,其公式为:
y = 30 + 0.54 x y = 30 + 0.54x y=30+0.54x
或者,为了强调模型并非完美拟合每一个数据点,我们可以写成:
y = 30 + 0.54 x + error y = 30 + 0.54x + \text{error} y=30+0.54x+error
(公式4.1)
接下来,我们将通过R代码来展示数据和拟合这条线,但在此之前,我们先简要讨论这条线本身。
方程 ( y = 30 + 0.54x ) 描述了一条截距为30,斜率为0.54的直线。虽然截距-斜率公式是可视化直线的简单方法,但在实际应用中可能会遇到解释上的困难。例如,截距30在这里表示一个母亲身高为0英寸时女儿的预测身高,这在现实中显然是无意义的。因此,我们更倾向于使用以数据平均值为中心的回归线表达方式。方程 ( y = 30 + 0.54x ) 可以等价地写成:
y = 63.9 + 0.54 ( x − 62.5 ) y = 63.9 + 0.54(x - 62.5) y=63.9+0.54(x−62.5)
(公式4.2)
这个公式表明,当母亲的身高 $ x = 62.5$英寸(即平均身高)时,女儿的预测身高 y y y将是63.9英寸。换句话说,如果一个母亲具有平均身高,那么她的成年女儿的身高预计也将接近平均身高。进一步地,对于母亲比平均身高每高(或矮)一英寸,她的女儿预计会比她那一代的平均身高大约高(或矮)半英寸。
4.2.在R中拟合模型
方程 y = 30 + 0.54 x y = 30 + 0.54x y=30+0.54x是近似最佳拟合线的表达式,其中“最佳拟合”定义为最小化平方误差之和。即,通过某种算法找到 a a a 和 b b b的值,使得下式最小化:
∑ i = 1 n ( y i − ( a + b x i ) ) 2 \sum_{i=1}^{n} (y_i - (a + bx_i))^2 ∑i=1n(yi−(a+bxi))2
在这里我们主要展示如何在R中得到这个解。首先,我们需要读取数据并查看前几行以确认数据内容:
heights <- read.table("Heights.txt", header=TRUE)
print(heights[1:5,])
这段代码读取名为"Heights.txt"的数据文件,并将其存储在变量heights中,然后打印出数据的前五行以便检查。
5.平均回归的悖论
现在我们已经经历了拟合和绘制预测女儿身高的回归线的步骤,我们可以回到身高“回归到平均值”的问题上。
当以某种方式看待时,图6.3中的回归斜率为0.54——实际上,任何不等于1的斜率——似乎都是悖论。如果高个子母亲很可能有只是相对较高的女儿,而矮个子母亲很可能有相对矮的女儿,这难道不是意味着女儿会比她们的母亲更接近平均水平,如果这种情况持续下去,每一代都会比上一代更接近平均水平,直到几代之后,每个人都几乎有平均身高吗?例如,比平均水平高出8英寸的母亲预计会有一个比平均水平高出4英寸的女儿,而她的女儿预计只会比平均水平高出2英寸,以此类推。
但显然这不是正在发生的事情。我们已经在皮尔逊和李之后几代了,女性的身高仍然和以前一样多变。
解决这个表面上的悖论的方法是,是的,与母亲的身高相比,女性的预测身高更接近平均水平,但实际身高与有误差的预测不是一回事;回想一下公式(6.1)。点预测回归到平均值——这就是系数小于1——这减少了变异。同时,模型中的误差——预测的不完美——增加了变异,足以保持身高的总变异从一代到下一代大致恒定。
因此,平均回归总会以某种形式出现在一些预测不完美的稳定环境中。预测的不完美引入了变异,而点预测的回归是必要的,以保持总变异恒定。
平均回归的误区可能会混淆人们对因果推断的理解;使用假数据演示
平均回归可能会令人困惑,并且已经导致人们错误地归因于因果关系。为了看看这是如何发生的,我们从父母和孩子身高的问题转向数学上等价的情景,即参加两次考试的学生。
图6.5显示了一个假设的数据集,包含1000名学生期中考试和期末考试的分数。
我们没有使用真实数据,而是使用以下简单的过程模拟考试分数,代表信号和噪声:
- 假设每个学生都有一个真实的能力,来自平均值为50,标准差为10的分布。
- 每个学生期中考试的分数是两个组成部分的总和:学生的真实能力,以及平均值为0,标准差为10的随机组成部分,反映了任何给定测试的表现将是不可预测的:期中考试远非完美的测量工具。
- 同样,每个学生期末考试的分数是他或她的真实能力,加上另一个独立的随机组成部分。
以下是我们模拟假数据的代码:
n <- 1000
true_ability <- rnorm(n, 50, 10)
noise_1 <- rnorm(n, 0, 10)
noise_2 <- rnorm(n, 0, 10)
midterm <- true_ability + noise_1
final <- true_ability + noise_2
exams <- data.frame(midterm, final)
然后我们绘制数据和拟合的回归线:
fit_1 <- stan_glm(final ~ midterm, data=exams)
plot(midterm, final, xlab="Midterm exam score", ylab="Final exam score")
abline(coef(fit_1))
这是回归输出:
Median MAD_SD
(Intercept) 24.8 1.4
midterm 0.5 0.0
Auxiliary parameter(s):
Median MAD_SD
sigma 11.6 0.3
估计的斜率是0.5(也见图6.5),由于小于1,是平均回归的一个例子:期中考试得分高的学生往往在期末考试上只比平均水平高出大约一半;期中考试得分低的学生得分低,但通常不会像平均水平那样低。例如,在图6.5的最左边,有两名学生期中考试得了0分,期末考试得了33分和42分;在图表的最右边,有三名学生期中考试得了91分,期末考试在61到75之间。
人们可能会很自然地这样解释,说期中考试得分好的学生有能力,但之后他们往往会变得过于自信和松懈;因此,他们通常在期末考试上表现不佳。从另一个方向看,吸引人的因果故事是期中考试得分低的学生受到激励,更加努力,所以当期末考试来临时,他们的表现有所提高。
实际上,数据是从没有包含任何激励效应的理论模型中模拟出来的;期中考试和期末考试都是真实能力加上随机噪声的函数。我们知道这一点,因为我们创建了模拟!
平均回归的模式——即图6.5中的线斜率小于1——是第一次和第二次观察之间变化的结果:期中考试得分非常好的学生可能有一定的运气,并且有高水平的技能,所以在期末考试中,学生表现得比平均水平好但不如期中考试是有意义的。
关键是,对图6.5中数据的简单解释可能会导致你推断出一个完全虚假的效果(得分好的学生在期末考试上懒惰;得分差的学生更努力学习)。这个错误被称为“回归谬误”。
心理学家Amos Tversky和Daniel Kahneman在1973年报告了一个著名的现实世界例子:
飞行学校的教练采纳了心理学家推荐的一贯积极强化政策。他们口头强化每次成功执行飞行机动。在采用这种训练方法的一些经验之后,教练声称,与心理学教条相反,对复杂机动执行得好的高赞扬通常会导致下一次尝试时表现下降。实际上,他们解释说:
由于表现不是完全可靠的,而且连续机动之间的进步是缓慢的,因此回归在飞行机动中是不可避免的。因此,在一个试验中表现出色的飞行员很可能在下一次试验中表现下降,无论教练对最初的成功有何反应。经验丰富的飞行教练实际上发现了回归,但将其归因于积极强化的有害效果。这个真实的故事揭示了人类状况的一个令人难过的方面。我们通常在别人表现好时给予强化,而在他们表现不好时惩罚他们。因此,仅仅通过回归,他们最有可能在受到惩罚后改善,在受到奖励后恶化。因此,我们暴露在一生中的安排中,最常因为惩罚他人而受到奖励,因为奖励他人而受到惩罚。
这个故事的要点是,对预测的定量理解澄清了关于变异和因果关系的基本概念混淆。从纯粹的数学考虑来看,预期最好的飞行员将相对其他人排名下降,而最差的将提高他们的排名,就像我们期望高个子母亲的女儿平均上高,但不如她们的母亲那么高,等等。
“平均回归”与书中更大主题的关系
上述回归谬误是误解比较的一个特例。
关键思想是,对于因果推断,你应该比较类似的事物。
我们可以将这个想法应用到平均回归的例子中。在考试成绩问题中,因果主张是期中考试成绩不佳激励学生为期末考试努力学习,而期中考试成绩好的学生更有可能放松。在这个比较中,结果y是期末考试成绩,预测变量x是期中考试成绩。显著的结果是,比较x上相差1个单位的学生,他们在y上的预期差异只有1/2个单位。
这为什么引人注目?因为它与斜率为1的比较。回归表和图6.5中显示的观察模式正在与一个隐含的默认模型进行比较,即期中考试和期末考试成绩相同。但这两种模型之间的比较是不恰当的,因为默认模型是不正确的——实际上,没有任何理由怀疑在没有任何激励干预的情况下,期中考试和期末考试成绩会是相同的。
我们的观点不是有一个简单的分析可以让我们在这个设置中进行因果推断。相反,我们正在演示平均回归,与一个隐含的(但经过反思,不恰当的)模型进行比较,可能会导致错误的因果推断。
同样,在飞行学校的例子中,正在与一个隐含的模型进行比较,在该模型中,没有积极或消极的强化,个人表现将保持不变。但这样的模型在试验与试验之间真实变化的背景下是不恰当的。
6. 参考文献说明
对于身高与收入关联的案例研究,可进一步参阅Ross在1990年的著作,以及第12章所附的参考文献综述。图6.3展示的母亲与女儿身高数据最早由Pearson和Lee于1903年收集;对于此案例的深入分析,也可参见Wachsmuth、Wilkinson和Dallal在2003年的研究,以及Pagano和Anokey在2013年的贡献。将回归系数理解为一种比较手段,这与Efron在1982年提出的四大基本统计操作紧密相关。
关于平均回归的历史脉络,Stigler在1986年的作品中有所阐释,他还在1983年的论文中讨论了这一概念与其他统计学思想的联系。Lord在1967年和1969年的著作中分析了平均回归如何可能引起对因果关系的误解。而飞行学员训练的故事,最早是由Kahneman和Tversky在1973年的论文中提出。
相关文章:
:线性回归模型第一部分:认识线性回归模型)
【深度学习】图形模型基础(5):线性回归模型第一部分:认识线性回归模型
1. 回归模型定义 最简单的回归模型是具有单一预测变量的线性模型,其基本形式如下: y a b x ϵ y a bx \epsilon yabxϵ 其中, a a a 和 b b b 被称为模型的系数或更一般地,模型的参数。 ϵ \epsilon ϵ 代表误差项&#…...

2024 年第十四届 APMCM 亚太地区大学生数学建模竞赛B题超详细解题思路+数据预处理问题一代码分享
B题 洪水灾害的数据分析与预测 亚太中文赛事本次报名队伍约3000队,竞赛规模体量大致相当于2024年认证杯,1/3个妈杯,1/10个国赛。赛题难度大致相当于0.6个国赛,0.8个妈杯。该比例仅供大家参考。 本次竞赛赛题难度A:B:C3:1:4&…...

Yarn有哪些功能特点
Yarn是一个由Facebook团队开发,并联合Google、Exponent和Tilde等公司推出的JavaScript包管理工具,旨在提供更优的包管理体验,解决npm(Node Package Manager)的一些痛点。Yarn的功能特点主要包括以下几个方面࿱…...

深度学习算法bert
bert 属于自监督学习的一种(输入x的部分作为label) 1. bert是 transformer 中的 encoder ,不同的bert在encoder层数、注意力头数、隐藏单元数不同 2. 假设我们有一个模型 m ,首先我们为某种任务使用大规模的语料库预训练模型 m …...

PyTorch - 神经网络基础
神经网络的主要原理包括一组基本元素,即人工神经元或感知器。它包括几个基本输入,例如 x1、x2… xn ,如果总和大于激活电位,则会产生二进制输出。 样本神经元的示意图如下所述。 产生的输出可以被认为是具有激活电位或偏差的加权…...
docker-compose搭建minio对象存储服务器
docker-compose搭建minio对象存储服务器 最近想使用oss对象存储进行用户图片上传的管理,了解了一下例如aliyun或者腾讯云的oss对象存储服务,但是呢涉及到对象存储以及经费有限的缘故,决定自己手动搭建一个oss对象存储服务器; 首先…...

vue3使用pinia中的actions,需要调用接口的话
actions,需要调用接口的话,假如页面想要调用actions中的方法获取数据, 必须使用try catch async await 进行包裹,详情看下面代码 import {defineStore} from pinia import {reqCode,reqUserLogin} from ../../api/hospital/i…...

Python酷库之旅-第三方库Pandas(003)
目录 一、用法精讲 4、pandas.read_csv函数 4-1、语法 4-2、参数 4-3、功能 4-4、返回值 4-5、说明 4-6、用法 4-6-1、创建csv文件 4-6-2、代码示例 4-6-3、结果输出 二、推荐阅读 1、Python筑基之旅 2、Python函数之旅 3、Python算法之旅 4、Python魔法之旅 …...

社交电商中的裂变营销利器,二级分销模式,美妆家具成功案例分享
二级分销返佣模式是一种帮助商家迅速扩大市场覆盖的有效营销策略,不仅能降低营销成本,还能提升品牌知名度。下面通过两个具体的案例来说明这种模式的好处和优势。 某知名美妆品牌在市场竞争日益激烈的情况下,决定采用二级分销返佣模式进行市场…...

【国产开源可视化引擎Meta2d.js】图层
独立图层 每个图元都有先后绘画顺序,即每个图元拥有一个独立图层,即meta2d.data().pens的数组索引。 可以通过meta2d.top/bottom/up/down等函数改变独立图层顺序。 分组图层 通过标签可以标识一个分组图层,通过meta2d.find(图层标签)获取…...

基于Redisson实现分布式锁
基于redisson实现分布式锁 之前背过分布式锁几种实现方案的八股文,但是并没有真正自己实操过。现在对AOP有了更深一点的理解,就自己来实现一遍。 1、分布式锁的基础知识 分布式锁是相对于普通的锁的。普通的锁在具体的方法层面去锁,单体应…...

Android Studio下载Gradle特别慢,甚至超时,失败。。。解决方法
使用Android studio下载或更新gradle时超级慢怎么办? 切换服务器,立马解决。打开gradle配置文件 修改服务器路径 distributionUrlhttps\://mirrors.cloud.tencent.com/gradle/gradle-7.3.3-bin.zip 最后,同步,下载,速…...
leetcode--二叉树中的最长交错路径
leetcode地址:二叉树中的最长交错路径 给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下: 选择二叉树中 任意 节点和一个方向(左或者右)。 如果前进方向为右,那么移动到当前节点的的右子节点&…...

c++ primer plus 第15章友,异常和其他:15.1.3 其他友元关系
c primer plus 第15章友,异常和其他:15.1.3 其他友元关系 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 15.1.3 其他友元关系 提示:写完文章后,目录可以自动生成,如何生成可…...

uniapp+vue3页面跳转和传参
页面跳转: uni.navigateTo({url: /pages/index}) 返回上一层: uni.navigateBack ({delta: 1 }) 页面跳转时传参: 跳转前的页面: uni.navigateTo({url: "/pages/index?id123"}) 跳转后的页面: onLoa…...

硬链接和软链接
在Linux系统中,链接(Link)是一种特殊的文件,它指向另一个文件或目录。链接分为两种类型:硬链接(Hard Link)和软链接(也称为符号链接,Symbolic Link)。 1. 硬…...
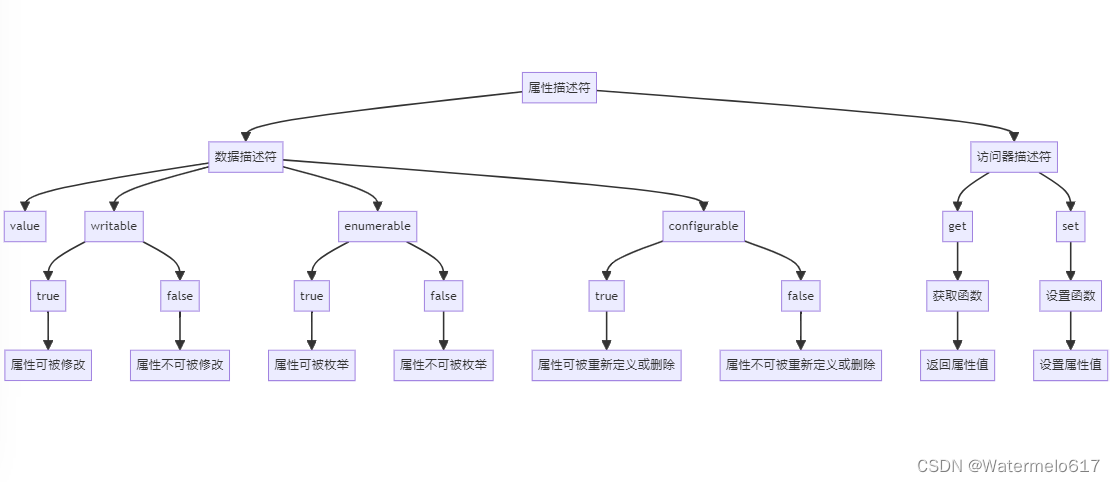
属性描述符初探——Vue实现数据劫持的基础
目录 属性描述符——Vue实现数据劫持的基础 一、属性描述符是什么? 编辑 1.1、属性描述符示例 1.2、用属性描述符定义属性及获取对象的属性描述符 1.3、带有读取器和设置器的属性描述符 二、使用属性描述符的情景 2.1、封装和数据隐藏 使用getter和setter…...

字节也没余粮了?天底下没有永远免费的GPT-4;AI产品用订阅制就不合理!让用户掏钱的N种定价技巧嘿嘿 | ShowMeAI日报
👀日报&周刊合集 | 🎡ShowMeAI官网 | 🧡 点赞关注评论拜托啦! 1. 当 Coze 也开始收费:天底下没有「永远」免费的 GPT-4 注:这里 Coze 指海外版。国内版 扣子 还是免费。 Coze (海外版) 官网链接 → htt…...

【Matlab 路径优化】基于蚁群算法的XX市旅游景点线路优化系统
基于蚁群算法的XX市旅游景点线路优化系统 (一)客户需求: ①考虑旅游景点的空间分布、游客偏好等因素,实现了旅游线路的智能规划 ②游客选择一景点出发经过所要游览的所有景点只一次,最后回到出发点的前提下…...

我关于Excel使用点滴的笔记
本篇笔记是我关于Excel使用点滴的学习笔记,摘要和地址链接列表。临时暂挂,后面可能在不需要时删除。 (笔记模板由python脚本于2024年06月28日 12:23:32创建,本篇笔记适合初通Python,熟悉六大基本数据(str字符串、int整型、float浮…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...