Python脚本:将Word文档转换为Excel文件

引言
在文档处理中,我们经常需要将Word文档中的内容转换成其他格式,如Excel,以便更好地进行数据分析和报告。针对这一需求,我编写了一个Python脚本,能够批量处理指定目录下的Word文档,将其内容结构化并转换为Excel文件。
功能概述
这个脚本的主要功能包括:
- 批量读取Word文档:自动检索指定目录下的所有Word文档(.docx格式)。
- 内容抽取和组织:根据Word文档中的标题层级(Heading),抽取和组织内容。
- 关键信息提取:自动从Word文档的文件名中提取关键信息,作为Excel表格中的一级节点名称。
- 结构化DataFrame创建:将抽取的信息转化为DataFrame,包含一级至四级节点及其对应内容。
- Excel文件保存:将每个Word文档转换得到的DataFrame保存为同名的Excel文件,位于原始Word文档所在的同一目录。
使用方法
- 准备文档:确保所有待处理的Word文档位于同一目录下,并且每个文档中要有定义好的标题样式(一级标题、二级标题等)。
- 指定目录:修改脚本中的
batch_process_word_to_excel函数中的directory参数,指定Word文档所在目录。 - 运行脚本:执行脚本,等待处理完成。脚本将在指定目录下生成对应的Excel文件,文件名与原Word文档一致,但扩展名为’.xlsx’。
代码解析
以下是脚本的完整代码,包含了所需的库和函数定义:
# -*- coding: utf-8 -*-
"""
此Python脚本旨在自动化处理目录下所有的Word文档(.docx),将其内容结构化并转换为Excel文件(.xlsx)。主要功能:
1. 批量读取指定目录下的所有Word文档。
2. 对每个Word文档,根据文档内的标题层级(Heading)结构,抽取和组织内容。
3. 自动从Word文档的文件名中提取关键信息作为Excel表格中的一级节点名称,特别关注“分册”和“细则”之间的文本。
4. 将抽取的信息转化为结构化的DataFrame,其中包含一级至四级节点及其对应内容。具体转换规则如下:填充说明:1.word文件名为一级标题,作为Excel中的一级节点;2.word中的一级标题作为Excel中的二级节点,一级标题和当前一级标题下的第一个二级标题之间的正文内容作为Excel的二级内容;3.word中的二级标题作为Excel中的三级节点,二级标题和当前二级标题下的第一个三级标题之间的正文内容作为Excel的三级内容;4.word中的三级标题作为Excel中的四级节点,三级标题和当前三级标题下的第一个四级标题之间的正文内容作为Excel的四级内容;
5. 将每个Word文档转换得到的DataFrame保存为同名的Excel文件,位于原始Word文档所在的同一目录。使用方法:
- 确保所有待处理的Word文档位于同一目录下。并且,每个word中要有样式:一级标题、二级标题、三级标题等
- 修改'batch_process_word_to_excel'函数中的'directory'参数,指定Word文档所在目录。
- 运行脚本,脚本将在指定目录下生成对应的Excel文件,文件名与原Word文档一致,但扩展名为'.xlsx'。依赖库:
- os: 提供与操作系统交互的功能,如文件和目录操作。
- docx: 用于读取Word文档的库。
- pandas: 用于数据处理和分析的库,创建DataFrame和保存Excel文件。注意事项:
- 代码假设Word文档中的标题层级不超过四级。
- 一级节点名称的提取逻辑基于文件名中包含“分册”和“细则”的特定格式。
- 如需处理不同层级或文件命名规则,需相应调整代码逻辑。"""
import os
import docx
import pandas as pddef extract_title_from_filename(filename):# 分割文件名找到"分册"和"细则"parts = filename.split('分册')if len(parts) > 1:title_part = parts[1].split('细则')[0]return title_part.strip() # 去除前后空格else:return filename # 如果没有找到"分册"或"细则",返回原文件名def process_word_to_excel(file_path):doc = docx.Document(file_path)columns = ['一级节点', '二级节点', '二级内容', '三级节点', '三级内容', '四级节点', '四级内容']df = pd.DataFrame(columns=columns)# 获取Word文档的文件名,并从中提取一级节点名称filename = os.path.basename(file_path)word_file_name = extract_title_from_filename(filename)current_level2 = ""current_level3 = ""current_level4 = ""current_content = ""last_level = 0for paragraph in doc.paragraphs:if paragraph.style.name.startswith('Heading'):heading_level = int(paragraph.style.name[-1])if heading_level <= last_level:if current_level4:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'四级节点': [current_level4],'四级内容': [current_content]})elif current_level3:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'三级内容': [current_content]})elif current_level2:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'二级内容': [current_content]})df = pd.concat([df, new_row], ignore_index=True)current_content = ""if heading_level == 1:current_level2 = paragraph.textcurrent_level3 = ""current_level4 = ""last_level = 1elif heading_level == 2:current_level3 = paragraph.textcurrent_level4 = ""last_level = 2elif heading_level == 3:current_level4 = paragraph.textlast_level = 3else:current_content += paragraph.text + '\n'if current_content:if current_level4:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'四级节点': [current_level4],'四级内容': [current_content]})elif current_level3:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'三级节点': [current_level3],'三级内容': [current_content]})elif current_level2:new_row = pd.DataFrame({'一级节点': [word_file_name],'二级节点': [current_level2],'二级内容': [current_content]})df = pd.concat([df, new_row], ignore_index=True)return dfdef batch_process_word_to_excel(directory):for filename in os.listdir(directory):if filename.endswith('.docx'):file_path = os.path.join(directory, filename)df = process_word_to_excel(file_path)excel_filename = os.path.splitext(filename)[0] + '.xlsx'excel_path = os.path.join(directory, excel_filename)df.to_excel(excel_path, index=False)print(f'Processed {filename} to {excel_filename}')# 调用函数,指定目录
batch_process_word_to_excel('D:\\test')
相关文章:
Python脚本:将Word文档转换为Excel文件
引言 在文档处理中,我们经常需要将Word文档中的内容转换成其他格式,如Excel,以便更好地进行数据分析和报告。针对这一需求,我编写了一个Python脚本,能够批量处理指定目录下的Word文档,将其内容结构化并转换…...

【单链表】03 设L为带头结点的单链表,编写算法实现从尾到头反向输出每个结点的值。
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux算法题上机准备 😘欢迎 ❤️关注 👍点赞 🙌收藏 ✍️留言 题目 设L为带头结点的单链表,编写算法实现从尾到头反向输出每个结点的值。 算法…...
鸿蒙开发设备管理:【@ohos.vibrator (振动)】
振动 说明: 开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harmony-os/blob/master/README.md点击或者复制转到。 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 imp…...

【信息学奥赛】CSP-J/S初赛07 排序算法及其他算法在初赛中的考察
本专栏👉CSP-J/S初赛内容主要讲解信息学奥赛的初赛内容,包含计算机基础、初赛常考的C程序和算法以及数据结构,并收集了近年真题以作参考。 如果你想参加信息学奥赛,但之前没有太多C基础,请点击👉专栏&#…...

第N7周:seq2seq翻译实战-pytorch复现-小白版
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 理论基础 seq2seq(Sequence-to-Sequence)模型是一种用于机器翻译、文本摘要等序列转换任务的框架。它由两个主要的递归神经网络&#…...

java集合(1)
目录 一.集合概述 二. 集合体系概述 1. Collection接口 1.1 List接口 1.2 Set接口 2. Map接口 三. ArrayList 1.ArrayList常用方法 2.ArrayList遍历 2.1 for循环 2.2 增强for循环 2.3 迭代器遍历 一.集合概述 我们经常需要存储一些数据类型相同的元素,之前我们学过…...
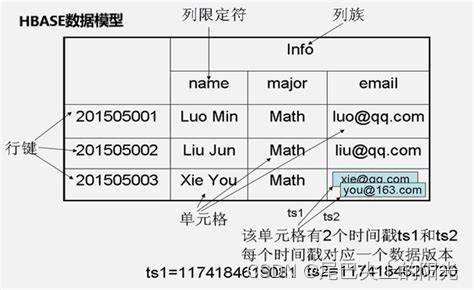
分布式数据库HBase:从零开始了解列式存储
在接触过大量的传统关系型数据库后你可能会有一些新的问题: 无法整理成表格的海量数据该如何储存? 在数据非常稀疏的情况下也必须将数据存储成关系型数据库吗? 除了关系型数据库我们是否还有别的选择以应对Web2.0时代的海量数据? 如果你也曾经想到过这些问题, 那么HBase将是…...

接口测试流程及测试点!
一、什么时候开展接口测试 1.项目处于开发阶段,前后端联调接口是否请求的通?(对应数据库增删改查)--开发自测 2.有接口需求文档,开发已完成联调(可以转测),功能测试展开之前 3.专…...
已经安装deveco-studio-4.1.3.500的基础上安装deveco-studio-3.1.0.501
目录标题 1、执行exe文件后安装即可2、双击devecostudio64_3.1.0.501.exe2.1、安装Note (注意和4.1的Note放不同目录)2.2、安装ohpm (注意和4.1版本的ohpm放不同目录)2.3、安装SDK (注意和4.1版本的SDK放不同目录) 1、执行exe文件后安装即可 2、双击devecostudio64_3.1.0.501.e…...

【C++】 解决 C++ 语言报错:Use of Uninitialized Variable
文章目录 引言 使用未初始化的变量(Use of Uninitialized Variable)是 C 编程中常见且危险的错误之一。它通常在程序试图使用尚未赋值的变量时发生,导致程序行为不可预测,可能引发运行时错误、数据损坏,甚至安全漏洞。…...

2024年7月6日 十二生肖 今日运势
小运播报:2024年7月6日,星期六,农历六月初一 (甲辰年庚午月辛未日),法定节假日。 红榜生肖:猪、马、兔 需要注意:狗、鼠、牛 喜神方位:西南方 财神方位:正…...
ubuntu丢失网络/网卡的一种原因解决方案
现象 开机进入ubuntu后发现没有网络,无论是在桌面顶部状态栏的快捷键 还是 系统设置中,都没有”有线网“和”无线网“的选项,”代理“的选项是有的使用数据线连接电脑和手机,手机开启”通过usb共享网络“,还是没有任何…...

第6篇 共识机制深度解析:PoW、PoS、DPoS和PBFT
在区块链的世界里,有一个非常重要的概念叫做“共识机制”。它就像是区块链的心脏,保证大家在这条链上的信息是可靠的、不可篡改的。今天,我们就来通俗易懂地聊聊区块链里的四大共识机制:工作量证明(PoW)、权益证明(PoS)、委托权益证明(DPoS)和拜占庭容错(PBFT)。为…...
Windows环境使用SpringBoot整合Minio平替OSS
目录 配置Minio环境 一、下载minio.exe mc.exe 二、设置用户名和密码 用管理员模式打开cmd 三、启动Minio服务器 四、访问WebUI给的地址 SpringBoot整合Minio 一、配置依赖,application.yml 二、代码部分 FileVO MinioConfig MinioUploadService MinioController 三…...

LeetCode 196, 73, 105
目录 196. 删除重复的电子邮箱题目链接表要求知识点思路代码 73. 矩阵置零题目链接标签简单版思路代码 优化版思路代码 105. 从前序与中序遍历序列构造二叉树题目链接标签思路代码 196. 删除重复的电子邮箱 题目链接 196. 删除重复的电子邮箱 表 表Person的字段为id和email…...

在Apache HTTP服务器上配置 TLS加密
安装mod_ssl软件包 [rootlocalhost conf.d]# dnf install mod_ssl -y此时查看监听端口多了一个443端口 自己构造证书 [rootlocalhost conf.d]# cd /etc/pki/tls/certs/ [rootlocalhost certs]# openssl genrsa > jiami.key [rootlocalhost certs]# openssl req -utf8 -n…...

C语言力扣刷题11——打家劫舍1——[线性动态规划]
力扣刷题11——打家劫舍1和2——[线性动态规划] 一、博客声明二、题目描述三、解题思路1、线性动态规划 a、什么是动态规划 2、思路说明 四、解题代码(附注释) 一、博客声明 找工作逃不过刷题,为了更好的督促自己学习以及理解力扣大佬们的解…...
房屋租赁管理小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,中介管理,房屋信息管理,房屋类型管理,租房订单管理,租房信息管理 微信端账号功能包括:系统首页,房屋信息&am…...

oracle sql语句 排序 fjd = ‘0101‘ 排在 fjd = ‘0103‘ 的前面
要实现这个排序需求,你可以使用 CASE 表达式来自定义排序逻辑。假设你有一个表格名为 your_table,并且有一个字段 fjd 存储类似 ‘0101’, ‘0103’ 这样的值,你可以这样编写 SQL 查询: SELECT * FROM your_table ORDER BY CASE …...
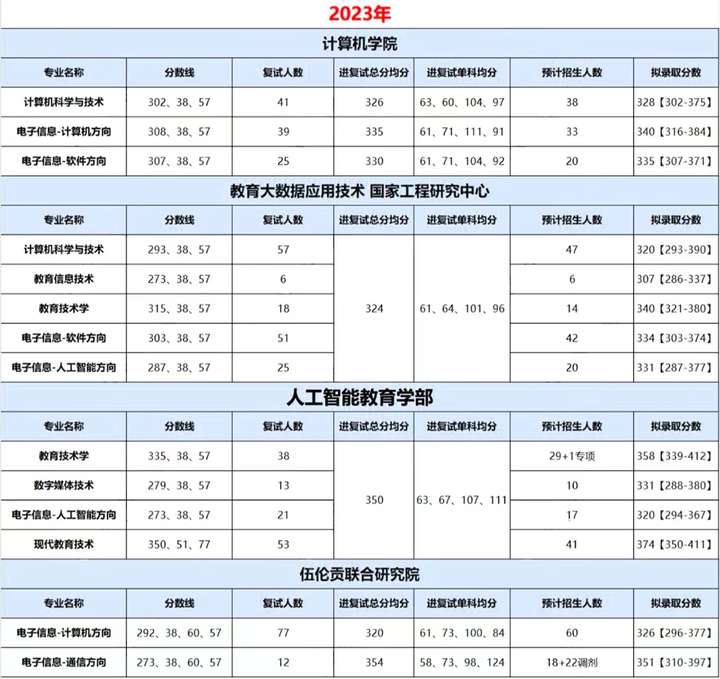
初试成绩占比百分之70!计算机专硕均分340+!华中师范大学计算机考研考情分析!
华中师范大学(Central China Normal University)简称“华中师大”或“华大”,位于湖北省会武汉,是中华人民共和国教育部直属重点综合性师范大学,国家“211工程”、“985工程优势学科创新平台”重点建设院校,…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...