面试官:关于CPU你了解多少?
CPU是如何执行程序的?
程序执行的基本过程
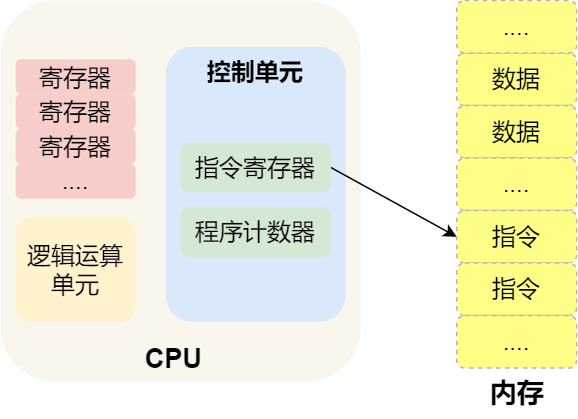
- 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总线」将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到「指令寄存器」。
- 第二步,「程序计数器」的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
- 第三步,CPU 分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
简单总结:一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后程序计数器根据指令长度自增,开始顺序读取下一条指令。
- 在指令寄存器中,CPU会分析指令寄存器中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
- 程序计数器自增的长度与CPU位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 CPU 的指令周期。
-
冯诺依曼模型定义了计算机基本结构:运算器、控制器、存储器、输入输出设备。
-
内存
我们的程序和数据都是存储在内存,存储的区域是线性的。
在计算机数据存储中,存储数据的基本单位是字节(byte),1 字节等于 8 位(8 bit)。每一个字节都对应一个内存地址。
-
中央处理器(CPU)
中央处理器也就是我们常说的 CPU,32 位和 64 位 CPU 最主要区别在于一次能计算多少字节数据。这里的32位和64位,通常表示CPU的位宽。
- 32 位 CPU 一次可以计算 4 个字节;(4个字节就是32位 4 * 8)
- 64 位 CPU 一次可以计算 8 个字节;
CPU内部还有一些组件,常见的有寄存器,控制单元和逻辑运算单元
-
控制单元:负责控制CPU的工作。
-
逻辑运算单元:负责运算。
-
寄存器:存储计算时的数据,由于内存离CPU太远了,而寄存器就在CPU内部,计算速度更快。寄存器有以下几种:
- 通用寄存器:存放需要运算的数据。
- 程序计数器:存储CPU要执行的下一条指令的地址。
- 指令寄存器:存放当前正在执行的指令。
-
总线
负责各种设备之间的通信。比如CPU读取内存数据时,要通过三个总线:
- 先通过地址总线来指定内存的地址。
- 再通过控制总线来指定读或写的命令。
- 最后通过数据总线来传递数据。
-
线路位宽与CPU位宽
-
线路位宽:数据在线路中传输,其实是通过操作电压,低电压表示0,高电压表示1。这样一位一位进行传输的方式称为串行,想要一次性多传输数据,可以增加线路的位宽。比如CPU 想要操作内存地址就需要地址总线,可以通过增加线路位宽的方式,增加CPU能操作的最大内存地址数量。(注意,不是说同时操作的最大内存地址数量)
- 如果地址总线有 2 条,那么能表示 00、01、10、11 这四种地址,所以 CPU 能操作的内存地址最大数量为 4(2^2)个。那么,想要 CPU 操作 4G 大的内存,那么就需要 32 条地址总线,因为
2 ^ 32 = 4G。(32位对应有232个地址,对应的内存数是232 * 8bit=4Gbyte即4GB)
- 如果地址总线有 2 条,那么能表示 00、01、10、11 这四种地址,所以 CPU 能操作的内存地址最大数量为 4(2^2)个。那么,想要 CPU 操作 4G 大的内存,那么就需要 32 条地址总线,因为
-
CPU位宽:CPU 的位宽最好不要小于线路位宽,否则工作起来会非常复杂且麻烦。如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别的,只有当计算超过 32 位数字的情况下,64 位的优势才能体现出来。
- 另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为
2^64。
- 另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为
-
-
a = 1 + 2的执行具体过程
-
程序—>汇编语言—>计算机指令
CPU 是不认识
a = 1 + 2这个字符串,这些字符串只是方便我们程序员认识,要想这段程序能跑起来,还需要把整个程序翻译成汇编语言的程序,这个过程称为编译成汇编代码。针对汇编代码,我们还需要用汇编器翻译成机器码,这些机器码由 0 和 1 组成的机器语言,这一条条机器码,就是一条条的计算机指令,这个才是 CPU 能够真正认识的东西。 -
程序编译过程中,编译器分析代码,发现1和2是数据,所以放在内存中的「数据段」,编译器会把a = 1 + 2翻译成4条指令,存放到正文段中。
-
编译完成后,具体执行程序的时候,程序计数器会被设置为 0x100 地址,然后依次执行这 4 条指令。
-
-
上面的例子中,由于是在 32 位 CPU 执行的,因此一条指令是占 32 位大小,所以你会发现每条指令间隔 4 个字节。而数据的大小是根据你在程序中指定的变量类型,比如
int类型的数据则占 4 个字节,char类型的数据则占 1 个字节。 -
你知道软件的 32 位和 64 位之间的区别吗?再来 32 位的操作系统可以运行在 64 位的电脑上吗?64 位的操作系统可以运行在 32 位的电脑上吗?如果不行,原因是什么?
-
64 位和 32 位软件,实际上代表指令是 64 位还是 32 位的:
- 如果 32 位指令在 64 位机器上执行,需要一套兼容机制,就可以做到兼容运行了。但是如果 64 位指令在 32 位机器上执行,就比较困难了,因为 32 位的寄存器存不下 64 位的指令;
- 操作系统其实也是一种程序,我们也会看到操作系统会分成 32 位操作系统、64 位操作系统,其代表意义就是操作系统中程序的指令是多少位,比如 64 位操作系统,指令也就是 64 位,因此不能装在 32 位机器上。
总之,硬件的 64 位和 32 位指的是 CPU 的位宽,软件的 64 位和 32 位指的是指令的位宽。
-
-
CPU时钟频率:1GHz表示该CPU的时钟频率是1G,表示1秒会发出1G次数的脉冲信号,每一次脉冲信号的高低电平就是一个时钟周期。时钟周期时间越短,CPU运算的越快。
磁盘比内存慢几万倍?
-
机械硬盘、固态硬盘、内存这三个存储器,到底和
CPU L1 Cache相比速度差多少倍呢?-
CPU L1 Cache 随机访问延时是 1 纳秒,内存则是 100 纳秒,所以 CPU L1 Cache 比内存快 100 倍左右。
-
SSD 随机访问延时是 150 微秒,所以 CPU L1 Cache 比 SSD 快 150000 倍左右。
-
最慢的机械硬盘随机访问延时已经高达 10 毫秒,CPU L1 Cache 比机械硬盘快 10000000 倍左右;
-
-
寄存器
寄存器用来存储计算的数据,是最靠近 CPU 的控制单元和逻辑计算单元的存储器。
寄存器的价格很贵,数量通常在几十到几百之间,每个寄存器可以用来存储一定的字节(byte)的数据。比如:
- 32 位 CPU 中大多数寄存器可以存储 4 个字节;
- 64 位 CPU 中大多数寄存器可以存储 8 个字节。
寄存器的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写,CPU 时钟周期跟 CPU 主频息息相关,比如 2 GHz 主频的 CPU,那么它的时钟周期就是 1/2G,也就是 0.5ns(纳秒)。
-
CPU Cache
CPU Cache 用的是一种叫 SRAM(Static Random-Access Memory,静态随机存储器) 的芯片。静态,说明有电时数据一直存在,但掉电数据丢失。
在 SRAM 里面,一个 bit 的数据,通常需要 6 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间下,能存储的数据是有限的,不过也因为 SRAM 的电路简单,所以访问速度非常快。
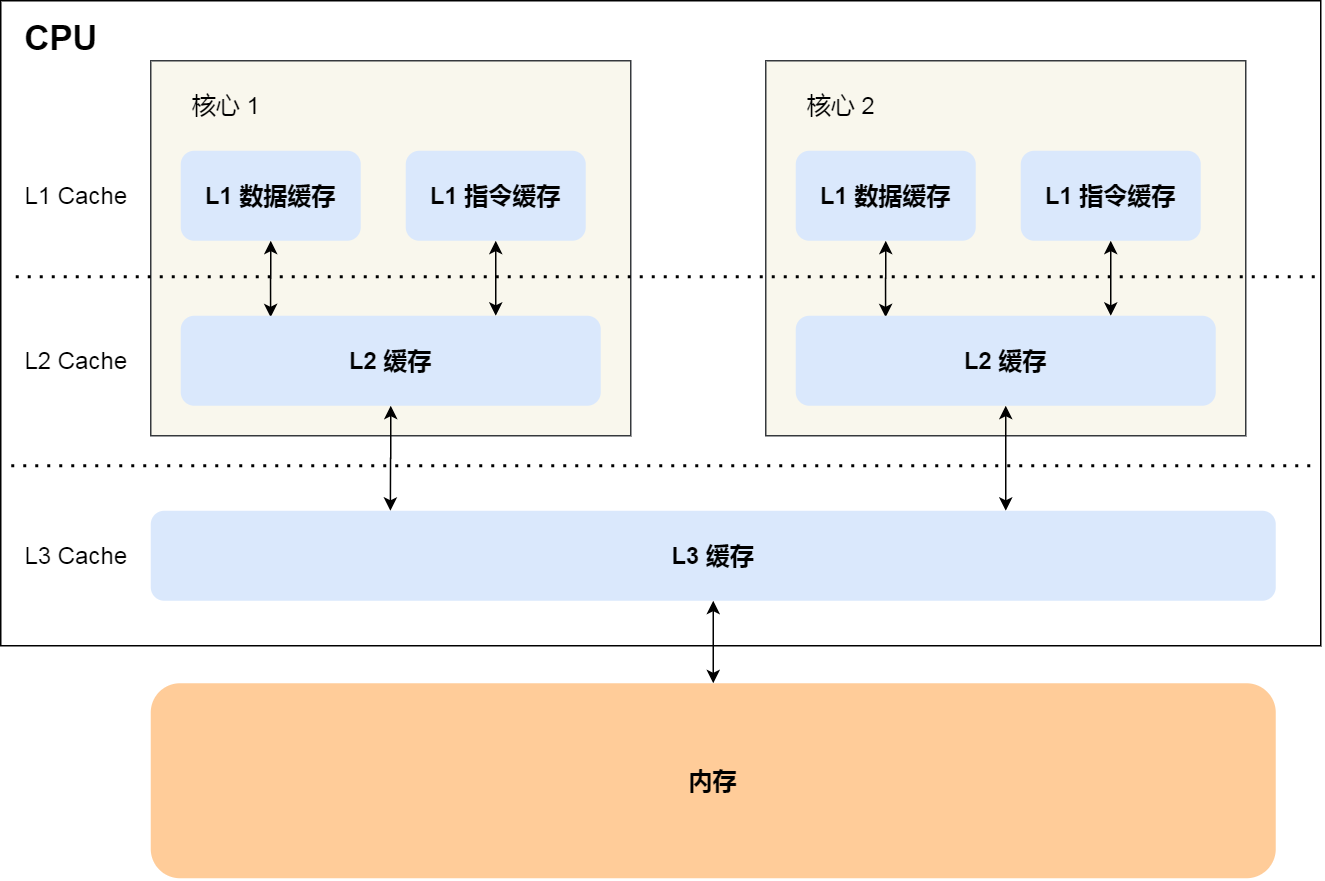
CPU 的高速缓存,通常可以分为 L1、L2、L3 三层高速缓存,也称为一级缓存、二级缓存、三级缓存。
-
L1 高速缓存是每个CPU Core独有的,访问速度快,只需要 2~4 个时钟周期。大小在几十 KB 到几百 KB 不等。
L1 高速缓存的指令和数据是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存。
-
L2 高速缓存同样每个 CPU 核心都有,但是 L2 比L1 距离 CPU 核心更远,访问速度则更慢,速度在 10~20 个时钟周期。但大小比 L1 更大,通常大小在几百 KB 到几 MB不等,
-
L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,访问速度相对也比较慢一些,访问速度在 20~60 个时钟周期。大小也会更大些,通常大小在几 MB 到几十 MB 不等。
-
-
内存
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。动态,因为数据会被存储在电容里,电容会不断漏电,所以需要定时刷新电容,才能保证数据不会被丢失。
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。存储一个 bit 数据,只需要一个晶体管和一个电容就能存储。
DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问的速度会更慢,内存速度大概在 200~300 个 时钟周期之间。
-
SSD/HDD硬盘
固态硬盘(Solid-state disk,SSD) 结构和内存类似。相比寄存器/Cache/内存的优点是断电后数据还存在;缺点是读写速度很慢。
机械硬盘(Hard Disk Drive, HDD),通过物理读写的方式来访问数据的,因此它访问速度是非常慢的,它的速度比内存慢 10W 倍左右。由于 SSD 的价格快接近机械硬盘了,因此机械硬盘已经逐渐被 SSD 替代了。
-
存储器的层次关系
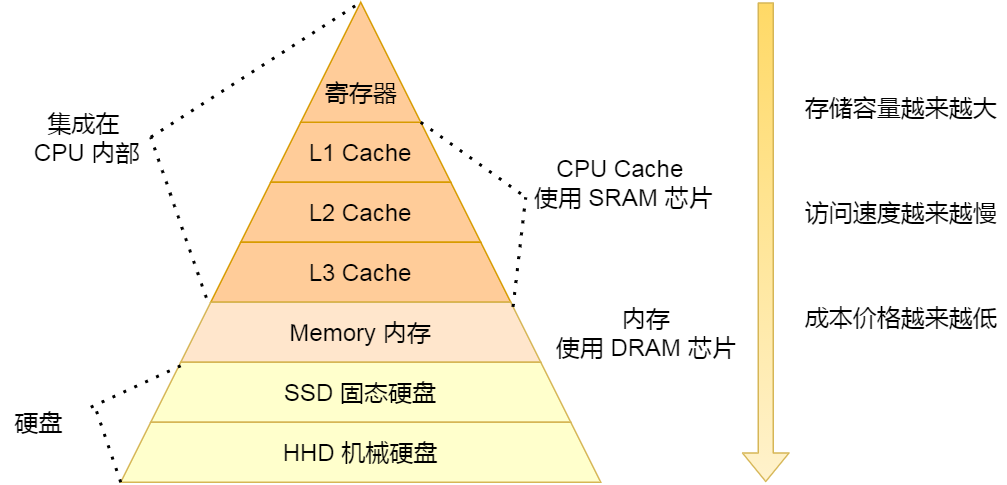
CPU 并不会直接和每一种存储器设备直接打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。比如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,再从内存写回到硬盘中。
- 另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据,并把内存中的数据读入到 Cache 中,CPU 再从 CPU Cache 读取数据。
不同的存储器之间性能差距很大,构造存储器分级很有意义,分级的目的是要构造缓存体系。这样的访问机制,跟我们使用「内存作为硬盘的缓存」的逻辑是一样的。
如何写出让CPU跑的更快的代码?
-
CPU Cache有多快?
根据摩尔定律,CPU 的访问速度每 18 个月就会翻倍,相当于每年增长 60% 左右,内存的速度当然也会不断增长,但是增长的速度远小于 CPU,平均每年只增长 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。到现在,一次内存访问所需时间是 200~300 多个时钟周期,这意味着 CPU 和内存的访问速度已经相差 200~300 多倍了。
为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。
-
CPU Cache 数据结构?
CPU Cache 是由很多个 Cache Line 组成的,Cache Line (缓存块)是 CPU 从内存读取数据的基本单位。
Cache Line 结构
- 有效位(Valid bit):标记对应Cache Line 中数据是否有效的有效位。
- 组标记(Tag):为了区分不同的内存块,在对应的CPU Cache LIne中会存储一个组标记,用来记录当前CPU Cache Line 中存储的数据对应的内存块,区分不同的内存块。
- 数据(Data):从内存加载过来的数据。
-
内存地址与Cache Line的直接映射
CPU 访问内存数据时,是一小块一小块数据读取的,具体这一小块数据的大小,取决于 coherency_line_size 的值,一般 64 字节。在内存中,这一块的数据我们称为内存块(Block),读取的时候我们要拿到数据所在内存块的地址。
一个内存的访问地址,包括组标记、CPU Cache Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。
- 对于直接映射 Cache 采用的策略,就是把内存块的地址始终映射在一个 CPU Cache Line 的地址,至于映射关系实现方式,则是使用取模运算,取模运算的结果就是内存块地址对应的 CPU Cache Line(缓存块) 的地址。
- 使用偏移量,可以在CPU Cache Line 中的数据块找到对应的字。
-
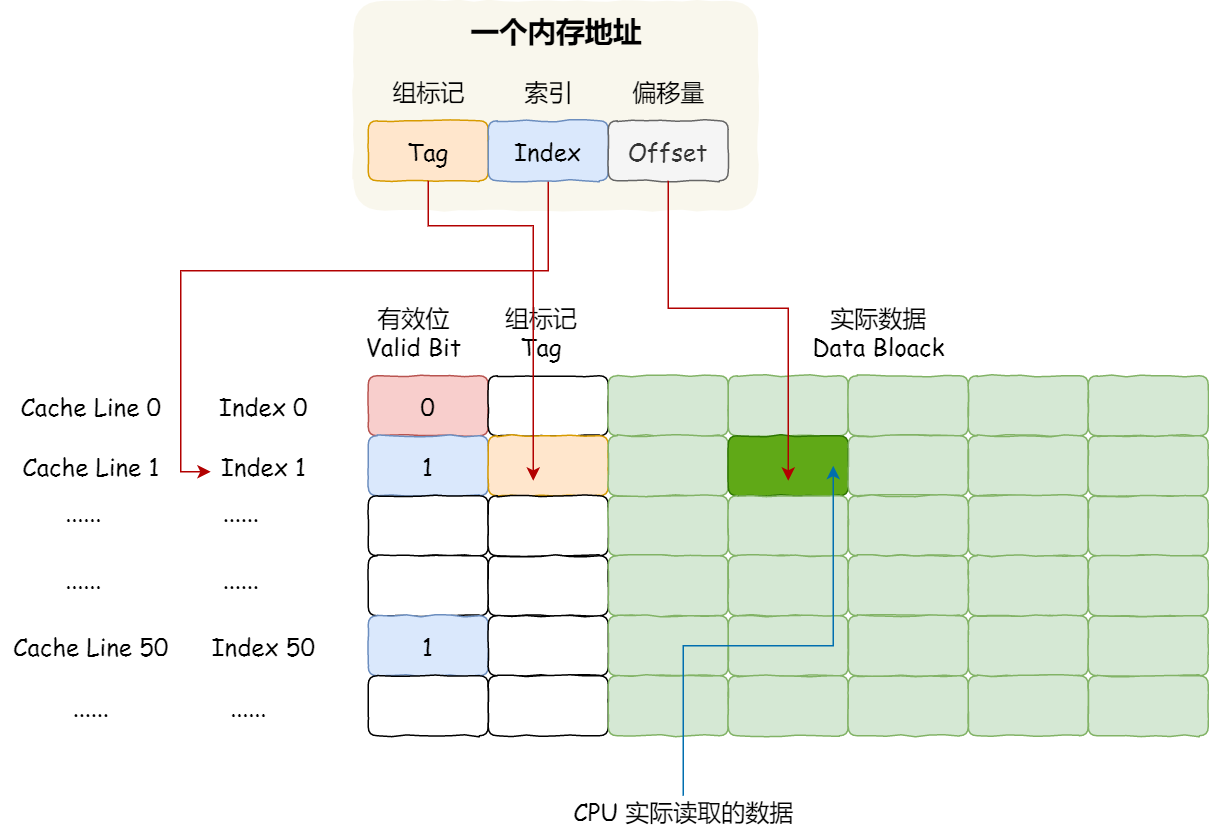
CPU Cache 读写过程?
-
根据内存地址中索引信息,计算在 CPU Cache 中的索引,也就是找出对应的 CPU Cache Line 的地址;
-
找到对应 CPU Cache Line 后,判断 CPU Cache Line 中的有效位,确认 CPU Cache Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
-
对比内存地址中组标记和 CPU Cache Line 中的组标记,确认 CPU Cache Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行;
-
根据内存地址中偏移量信息,从 CPU Cache Line 的数据块中,读取对应的字。
- CPU 在从 CPU Cache 读取数据的时候,并不是读取 CPU Cache Line 中的整个数据块,而是读取 CPU 所需要的一个数据片段,这样的数据统称为一个字(Word)。
-
-
写出让CPU跑得更快的程序
CPU操作L1 Cache的速度是很快的,提升CPU运行速度,可以提升访问L1 Cache的速度。
那么L1 Cache 通常分为「数据缓存」和「指令缓存」,因此要分别提高「数据缓存」和「指令缓存」的缓存命中率。
-
提升数据缓存的命中率
CPU会一次从内存中加载多少元素到 CPU Cache ,可以在Linux 里通过 coherency_line_size 配置查看 它的大小,通常是 64 个字节。
如果遇到遍历数组之类的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升。
-
提升指令缓存的命中率
使用显式分支预测工具,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
- 比如:如果你肯定代码中的 if 中的表达式判断为 true 的概率比较高,我们可以使用显示分支预测工具,比如在 C/C++ 语言中,如果 if 条件为 ture 的概率大,则可以用 likely 宏把 if 里的表达式包裹起来。
还可以提升多核CPU的缓存命中率
-
L2 Cache和L1 Cache 是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,可以把线程绑定到某一个CPU核心上。
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
-
整理自:小林coding
相关文章:
面试官:关于CPU你了解多少?
CPU是如何执行程序的? 程序执行的基本过程 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准…...

UI自动化测试-Selenium的使用
文章目录 1. 环境搭建1.1 入门示例1.2 元素操作常用方法1.3 浏览器操作常用方法1.4 获取元素信息常用方法1.5 鼠标操作常用方法1.6 键盘操作常用方法1.7 下拉选择框操作2. 元素定位2.1 id定位2.2 name定位2.3 class_name定位2.4 tag_name定位2.5 link_text定位2.6 partail_link…...
嵌入式学习笔记——STM32的USART相关寄存器介绍及其配置
文章目录前言USART的相关寄存器介绍状态寄存器:USARTX->SR具体位代表的含义实际代码数据寄存器 USARTX->DR波特率寄存器 USARTX->BRR控制寄存器 (USART_CR)控制寄存器1(USART_CR1)控制寄存器2(USART_CR2)GPIO…...
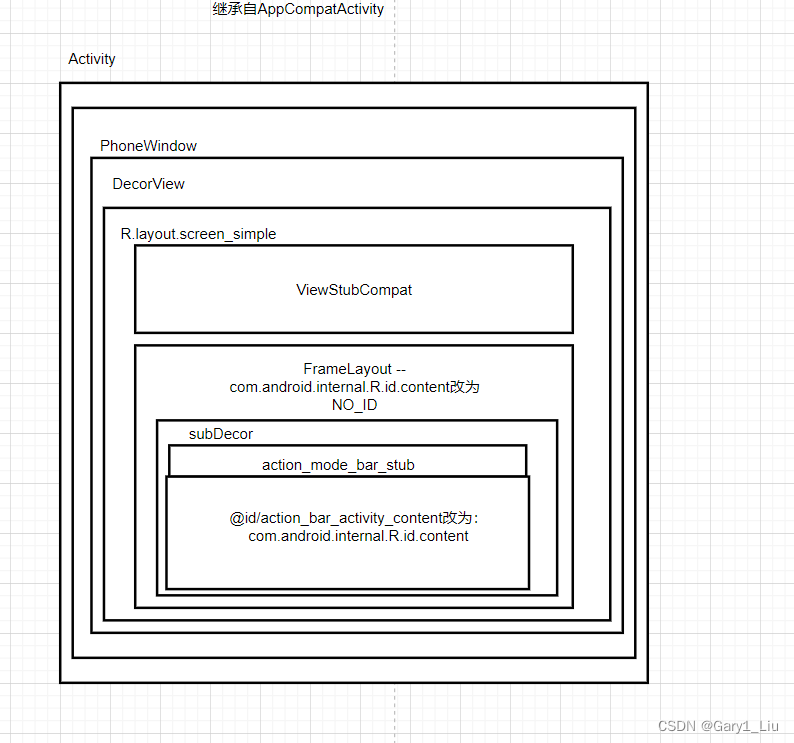
Android setContentView流程分析(一)
对于做Android App的小伙伴来说setContentView这个方法再熟悉不过了,那么有多少小伙伴知道它的调用到底做了多少事情呢?下面就让我们来看看它背后的故事吧? setContentView()方法将分为两节来讲: 第一节:如何获取De…...

doris数据库操作数字遇到的问题
关于doris数据库Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。…...

3.13文件的IO操作
一.文件1.定义文件一般指的是存储在硬盘上的普通文件形如:txt.jpg.mp4,rar等这些文件在计算机中,文件可能是一个广义的概念,不仅可以包含普通文件,还可以包含目录(也就是文件夹.把目录称为目录文件)在操作系统中,还会用文件来描述一些其他的硬件设备或者软件资源比如网卡,显示器…...
ffmpeg使用
1 下载FFmpeg安装 官网地址:https://www.ffmpeg.org/download.html#build-windows 进入网址,点击下面红框部分 点击下面范围进行下载,下载速度有点慢,等等吧! 下载成功后,解压后,复制bin的路…...
/分区器如何确定)
spark中的并行度(分区数)/分区器如何确定
源头RDD有自己的分区计算逻辑,一般没有分区器,并行度是根据分区算法自动计算的,RDD的compute函数中记录了数据如何而来,如何分区的hadoopRDD,根据XxxinputFormat.getInputSplits()来决定,比如默认的TextInputFormat将文…...

00后女生“云摆摊”两周赚1.5万,实体店转战线上真的能赚钱吗?
最近,山东临沂的00后女生利用小程序在线上“云摆摊”卖水果,两周赚1.5万,引发网友热议。不少人发出质疑的声音:年轻人不要有稳定的工作不做,去摆摊;网上开店成本低,开实体店结果就难说了&#x…...
| 机考必刷)
华为OD机试题 - 最优资源分配(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:最优资源分配题目输入输出描述备注示例一输入输出说明示例二输入…...

利用python判断字符串是否为回文
1 问题 如何用python判断字符串是否为回文。 2 方法 用两个变量left,right模仿指针(一个指向第一个字符,一个指向最后一个字符),每比对成功一次,left向右移动一位,right向左移动一位,…...
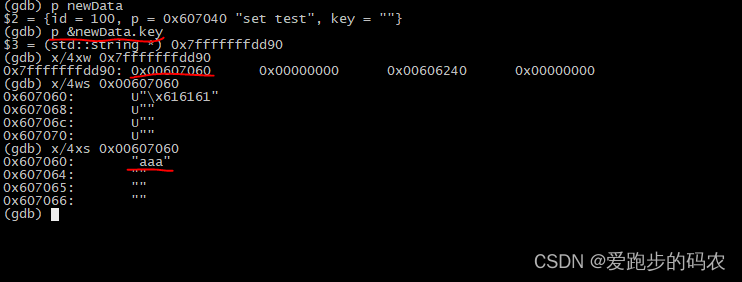
GDB 调用之ptype、set variable
今天在公司的时候,排查一个问题,创建l3 lif 失败,查看各种日志发现是用key去创建的 lif失败了,日志里指示key为空,导致的创建失败。原因为一个结构体比基线的多了一些东西,导致版本不对,既而计算…...
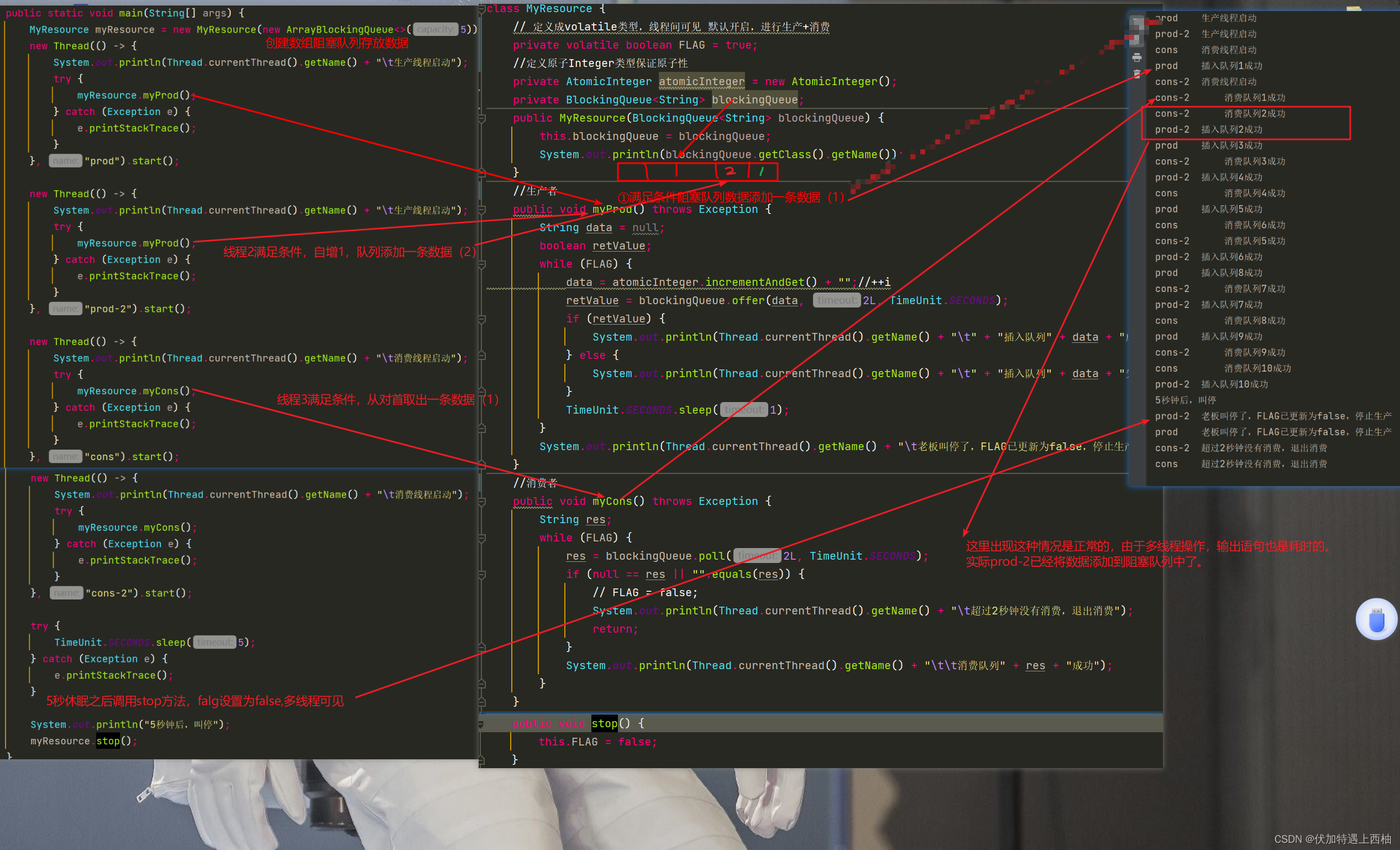
并发编程---阻塞队列(五)
阻塞队列一 阻塞队列1.1.阻塞队列概念1.2.阻塞队列API案例1.2.1. ArrayBlockingQueue1.2.1.1.抛出异常1.2.1.2.返回布尔1.2.1.3.阻塞1.2.1.4.超时1.2.2.SynchronousQueue二 阻塞队列应用---生产者消费者2.1.传统模式案例代码结果案例问题---防止虚假唤醒2.2.⽣产者消费者防⽌虚…...

本科课程【计算机组成原理】实验1 - 输出ABCD程序的生成
大家好,我是【1+1=王】, 热爱java的计算机(人工智能)渣硕研究生在读。 如果你也对java、人工智能等技术感兴趣,欢迎关注,抱团交流进大厂!!! Good better best, never let it rest, until good is better, and better best. 近期会把自己本科阶段的一些课程设计、实验报…...
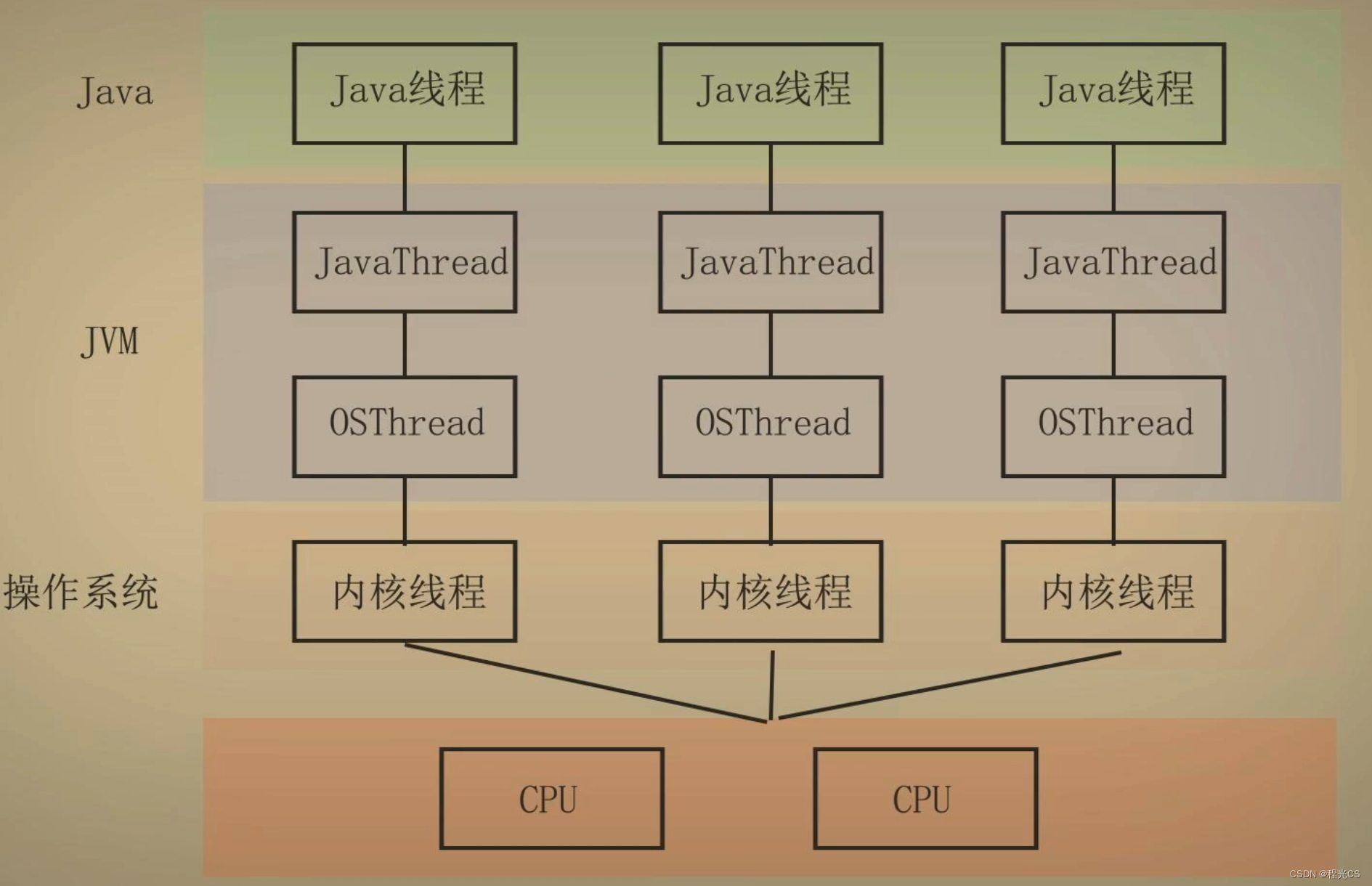
Java并发编程(2) —— 线程创建的方式与原理
一、Java线程创建的三种方式 1. 继承Thread类并重写run()方法 ///方法一:使用匿名内部类重写Thread的run()方法Thread t1 new Thread() {Overridepublic void run() {try {sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}log.debug("…...

你写的js性能有多差你知道吗 | js性能优化
性能的计算⽅式 确认⾃⼰需要关注的指标 常⻅的指标有: ⻚⾯总加载时间 load⾸屏时间⽩屏时间 代码 尝试⽤⼀个指令, 挂载在重要元素上, 当此元素inserted就上报 各个属性所代表的含义 connectStart, connectEnd 分别代表TCP建⽴连接和连接成功的时间节点。如果浏…...
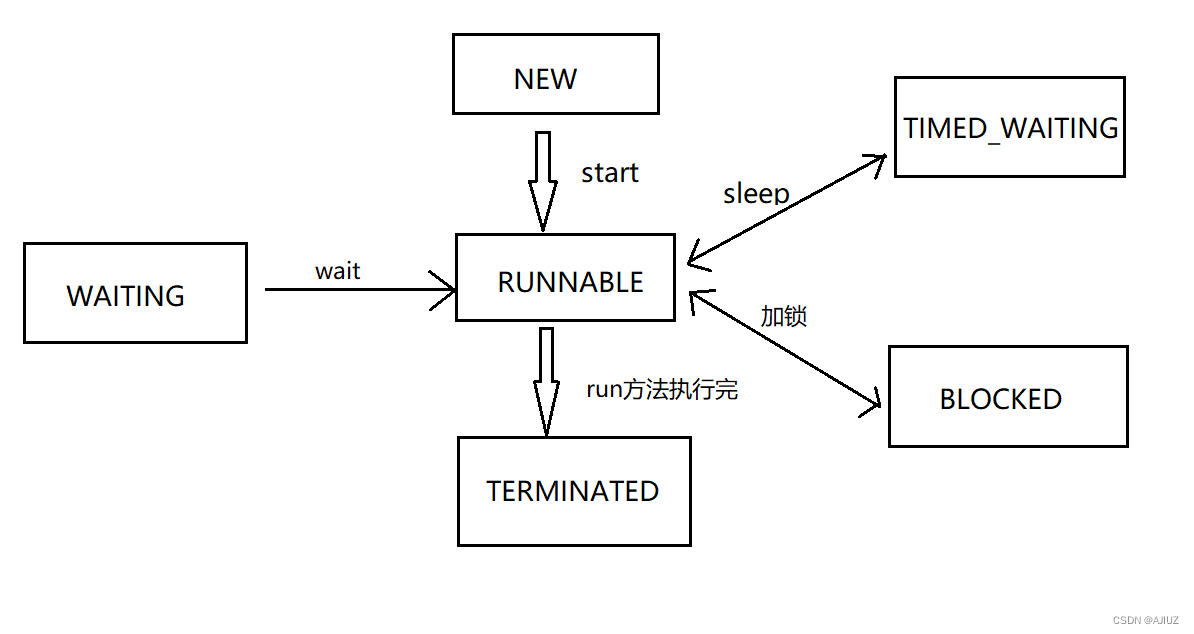
线程的状态、状态之间的相互转换
目录 一、线程的状态 1. NEW 2. TERMINATED 3. RUNNABLE 4. TIMED_WAITING 5. BLOCKED 6. WAITING 二、线程状态转换 1. 线程状态转换简图 一、线程的状态 线程的状态一共有 6 种: NEW:安排了工作,还未开始行动(调用 st…...

Java8使用Lambda表达式(流式)快速实现List转map 、分组、过滤等操作
利用java8新特性,可以用简洁高效的代码来实现一些数据处理。1 数据准备1.1 定义1个Fruit对象package com.wkf.workrecord.work;import org.junit.Test;import java.math.BigDecimal; import java.util.ArrayList; import java.util.List;/*** author wuKeFan* date …...
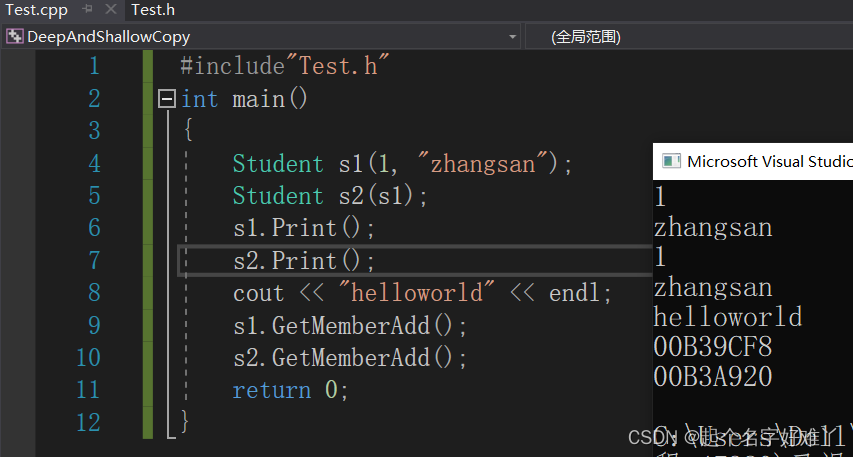
C++之深浅拷贝
一、浅拷贝 我们看下以下代码 Test.h 文件 #pragma once #include<iostream> using namespace std; class Student { public:Student(){}~Student(){if (m_Id ! nullptr){delete m_Id;m_Id nullptr;}}Student(int id, string strName){m_Id new int[id];m_strName s…...

CoreLocation的一切
Overview 概述 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pgnvehxf-1678717852996)(./blog_cover.png)] Core Location 提供的服务可以确定设备的地理位置、高度和方向,或者它相对于附近 iBeacon 设备的位置。 该框架使用设备上的所…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
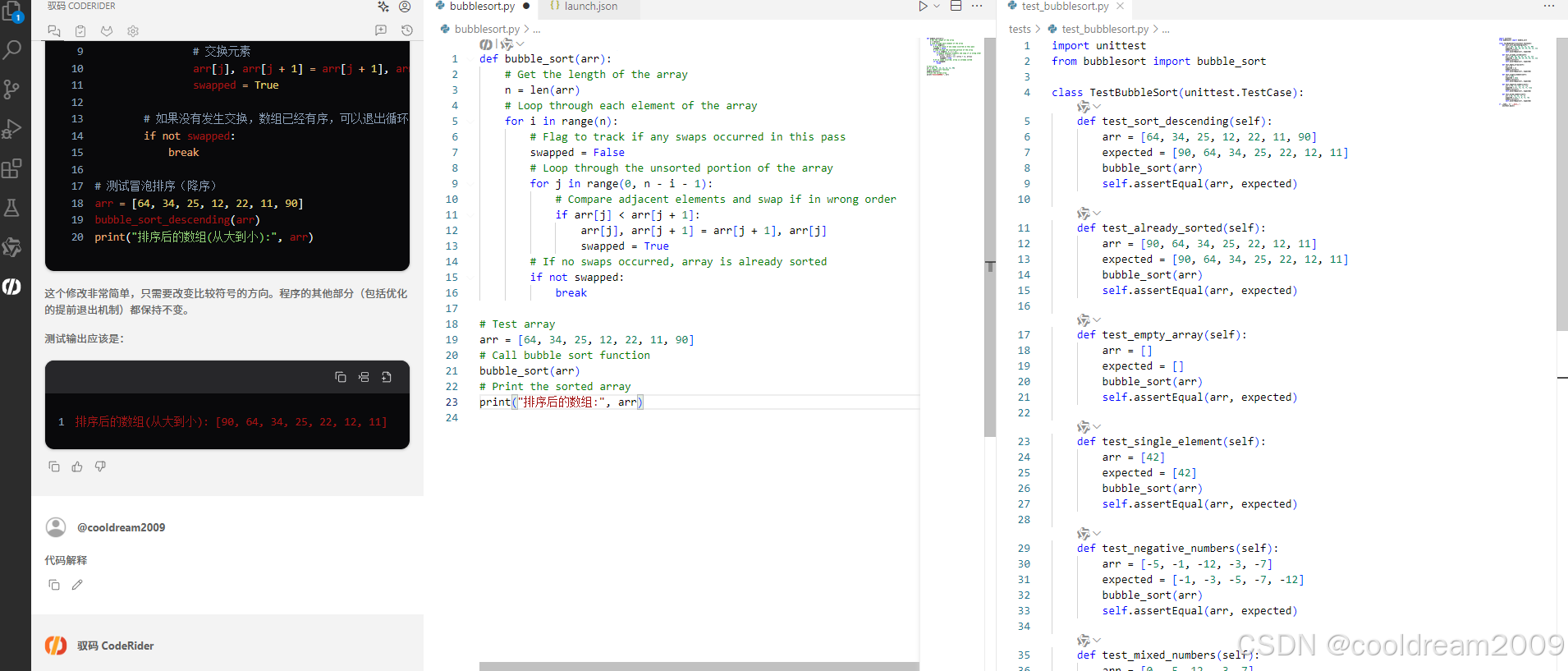
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

数据结构第5章:树和二叉树完全指南(自整理详细图文笔记)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 原创笔记:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 上一篇:《数据结构第4章 数组和广义表》…...