机器学习——无监督学习(k-means算法)
1、K-Means聚类算法
K表示超参数个数,如分成几个类别,K值就取多少。若无需求,可使用网格搜索找到最佳的K。
步骤:
1、随机设置K个特征空间内的点作为初始聚类中心;
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记种类;
3、接着对标记的聚类中心之后,重新计算出每个聚类的中心点(平均值);
4、如果计算得出的新中心点与原中心点一样,那么结束,否则执行第二步。
means表示寻找新的聚类中心点是采用特征平均值确定。
2、K-means图解
具体演示视频可查看(B站UP主:KnowingAI知智)
若我们手上有一些水果,我们希望对它们进行分类,假设分为两类,则此时K=2。
step1:随机选取两个样本点作为聚类中心点centrol

step2:计算其他每个样本与聚类中心centrol的距离,距离谁近就归为哪类,一般采用欧氏距离。

step3:根据已分类的结果,重新计算聚类中心,聚类中心是已分类的所有样本的平均值(means)

然后重复之前的步骤,重新计算距离进行划分,直到某一次计算聚类中心点和上次相同,则聚类结束。
3、聚类算法优缺点分析
聚类算法不需要手动设置标签,故属于无监督学习,相比于监督学习,它更加简单、易于理解,但是准确率方面不如监督学习。
4、K-Means()算法实现案例
API调用:
API:sklearn.cluster.KMeans(n_clusters=8, init='k=means++')
n_cluster:初始聚类中心数量,即K值
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据,100个二维数据,横坐标纵坐标都在0-1范围内
X = np.random.rand(100, 2)
# 创建K-means模型
kmeans = KMeans(n_clusters=3)
# 训练模型
kmeans.fit(X)
# 获取聚类结果
labels = kmeans.labels_
# 获取每个数据点的簇标签。labels_是一个数组,表示每个数据点所属的簇的索引。
centroids = kmeans.cluster_centers_
# 获取每个簇的质心坐标。cluster_centers_是一个形状为(n_clusters, n_features)的数组,表示每个簇的质心位置。
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], s=300, c='red', marker='x')
plt.show()

5、聚类效果的评估(轮廓系数评估法)
内部距离最小化,外部距离最大化
轮廓系数: S C i = b i − a i m a x ( b i , a i ) SCi=\frac{b_i-a_i}{max(b_i,a_i)} SCi=max(bi,ai)bi−ai
b i b_i bi:一个簇内某个样本到其他簇的所有样本距离的最小值
a i a_i ai:一个簇内某个样本到本身簇内所有样本距离的平均值
b i > > a i b_i>>a_i bi>>ai 此时 S C i ≈ 1 SCi≈1 SCi≈1 效果好
b i < < a i b_i<<a_i bi<<ai 此时 S C i ≈ − 1 SCi≈-1 SCi≈−1 效果差
轮廓系数取值范围在 ( − 1 , 1 ) (-1,1) (−1,1),越接近 1 1 1,聚类效果越好,越接近 − 1 -1 −1,聚类效果越差
from sklearn.metrics import silhouette_score #计算轮廓系数,传入样本点和分类标签
如上例中,加上如下代码
from sklearn.metrics import silhouette_score
score = silhouette_score(X,labels)
print(f"轮廓系数为{score}")
轮廓系数为0.3873688462341751,分类效果一般。可以加一个循环找到一定范围内最优的K值,此处用轮廓系数衡量
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据,100个二维数据,横坐标纵坐标都在0-1范围内
X = np.random.rand(100, 2)
# 创建K-means模型
best_score=0
for k in range(2,11):kmeans = KMeans(n_clusters=k)# 训练模型kmeans.fit(X)# 获取聚类结果labels = kmeans.labels_# 获取每个数据点的簇标签。labels_是一个数组,表示每个数据点所属的簇的索引。centroids = kmeans.cluster_centers_score = silhouette_score(X,labels)if score > best_score:best_score = scorebest_k = k
print(f'最佳簇数: {best_k}, 轮廓系数: {best_score}')
# 最佳簇数: 4, 轮廓系数: 0.42684837185343705
相关文章:
机器学习——无监督学习(k-means算法)
1、K-Means聚类算法 K表示超参数个数,如分成几个类别,K值就取多少。若无需求,可使用网格搜索找到最佳的K。 步骤: 1、随机设置K个特征空间内的点作为初始聚类中心; 2、对于其他每个点计算到K个中心的距离,…...

强化学习-6 DDPG、PPO、SAC算法
文章目录 1 DPG方法2 DDPG算法3 DDPG算法的优缺点4 TD3算法4.1 双Q网络4.2 延迟更新4.3 噪声正则 5 附15.1 Ornstein-Uhlenbeck (OU) 噪声5.1.1 定义5.1.2 特性5.1.3 直观理解5.1.4 数学性质5.1.5 代码示例5.1.6 总结 6 重要性采样7 PPO算法8 附28.1 重要性采样方差计算8.1.1 公…...

vue3实现多表头列表el-table,拖拽,鼠标滑轮滚动条优化
需求背景解决效果index.vue 需求背景 需要实现多表头列表的用户体验优化 解决效果 index.vue <!--/** * author: liuk * date: 2024-07-03 * describe:**** 多表头列表 */--> <template><el-table ref"tableRef" height"calc(100% - 80px)&qu…...

Micron近期发布了32Gb DDR5 DRAM
Micron Technology近期发布了一项内存技术的重大突破——一款32Gb DDR5 DRAM芯片,这项创新不仅将存储容量翻倍,还显著提升了针对人工智能(AI)、机器学习(ML)、高性能计算(HPC)以及数…...

SQL Server时间转换
第一种:format --转化成年月日 select format( GETDATE(),yyyy-MM-dd) --转化年月日,时分秒,这里的HH指24小时的,hh是12小时的 select format( GETDATE(),yyyy-MM-dd HH:mm:ss) --转化成时分秒的,这里就不一样的&…...

kubernetes集群部署:node节点部署和CRI-O运行时安装(三)
关于CRI-O Kubernetes最初使用Docker作为默认的容器运行时。然而,随着Kubernetes的发展和OCI标准的确立,社区开始寻找更专门化的解决方案,以减少复杂性和提高性能。CRI-O的主要目标是提供一个轻量级的容器运行时,它可以直接运行O…...

03:Spring MVC
文章目录 一:Spring MVC简介1:说说自己对于Spring MVC的了解?1.1:流程说明: 一:Spring MVC简介 Spring MVC就是一个MVC框架,Spring MVC annotation式的开发比Struts2方便,可以直接代…...

玩转springboot之springboot注册servlet
springboot注册servlet 有时候在springboot中依然需要注册servlet,filter,listener,就以servlet为例来进行说明,另外两个也都类似 使用WebServlet注解 在servlet3.0之后,servlet注册支持注解注册,而不需要在…...

推荐好玩的工具之OhMyPosh使用
解除禁止脚本 Set-ExecutionPolicy RemoteSigned 下载Oh My Posh winget install oh-my-posh 或者 Install-Module oh-my-posh -Scope AllUsers 下载Git提示 Install-Module posh-git -Scope CurrentUser 或者 Install-Module posh-git -Scope AllUser 下载命令提示 Install-Mo…...
pydub、ffmpeg 音频文件声道选择转换、采样率更改
快速查看音频通道数和每个通道能力判断具体哪个通道说话;一般能量大的那个算是说话 import wave from pydub import AudioSegment import numpy as npdef read_wav_file(file_path):with wave.open(file_path, rb) as wav_file:params wav_file.getparams()num_cha…...

0803实操-Windows Server系统管理
Windows Server系统管理 系统管理与基础配置 查看系统信息、更改计算机名称 网络配置 启用网络发现 Windows启用网络发现是指在网络设置中启用一个功能,该功能允许您的计算机在网络上识别和访问其他设备和计算机。具体来说,启用网络发现后ÿ…...

使用Java构建物联网应用的最佳实践
使用Java构建物联网应用的最佳实践 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 随着物联网(IoT)技术的快速发展,越来越…...
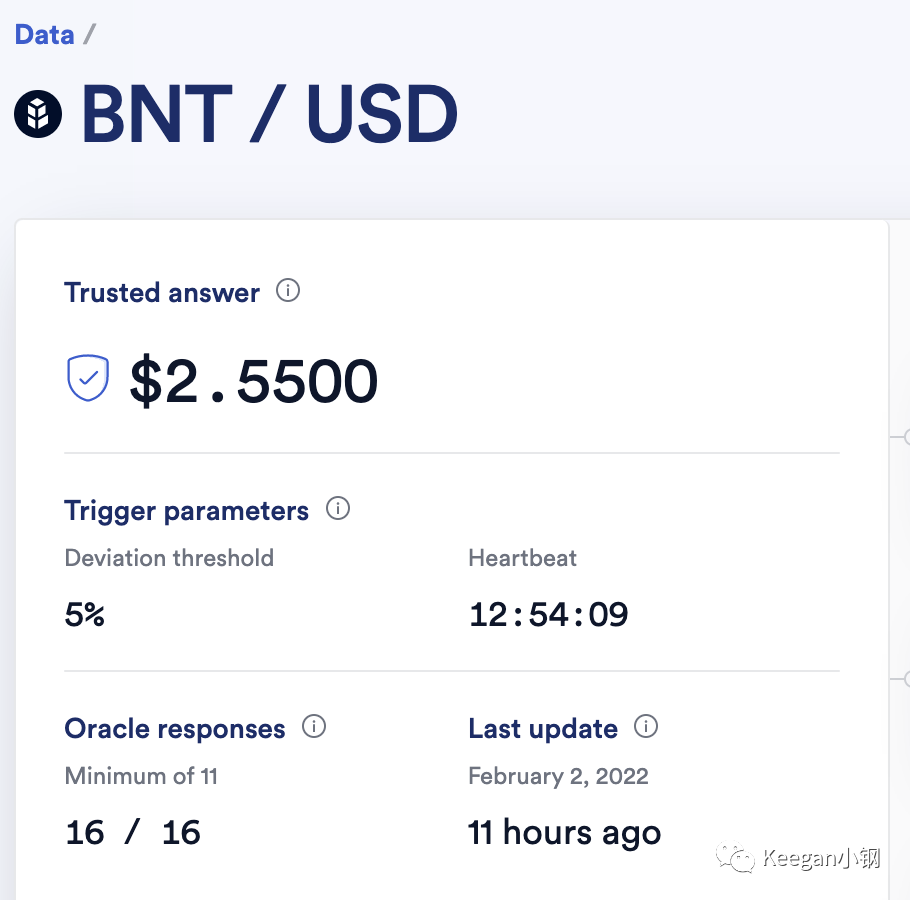
价格预言机的使用总结(一):Chainlink篇
文章首发于公众号:Keegan小钢 前言 价格预言机已经成为了 DeFi 中不可获取的基础设施,很多 DeFi 应用都需要从价格预言机来获取稳定可信的价格数据,包括借贷协议 Compound、AAVE、Liquity ,也包括衍生品交易所 dYdX、PERP 等等。…...
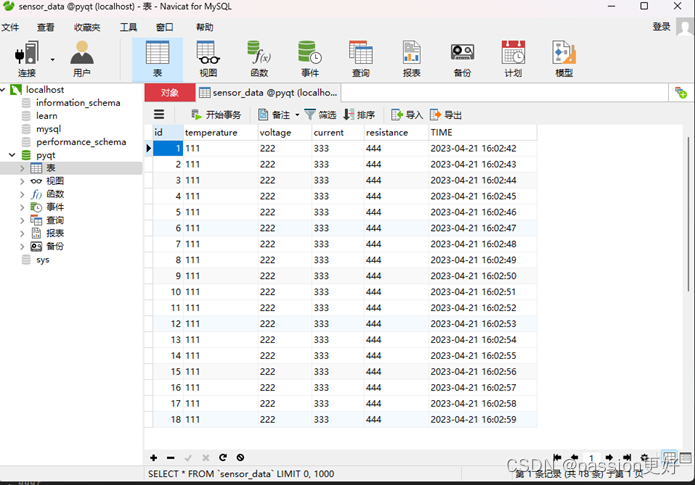
【Pyhton】读取寄存器数据到MySQL数据库
目录 步骤 modsim32软件配置 Navicat for MySQL 代码实现 步骤 安装必要的库:确保安装了pymodbus和pymysql。 配置Modbus连接:设置Modbus从站的IP地址、端口(对于TCP)或串行通信参数(对于RTU)。 连接M…...

jmeter-beanshell学习3-beanshell获取请求报文和响应报文
前后两个报文,后面报文要用前面报文的响应结果,这个简单,正则表达式或者json提取器,都能实现。但是如果后面报文要用前面请求报文的内容,感觉有点难。最早时候把随机数写在自定义变量,前后两个接口都用这个…...

【C++】B树及其实现
写目录 一、B树的基本概念1.引入2.B树的概念 二、B树的实现1.B树的定义2.B树的查找3.B树的插入操作4.B树的删除5.B树的遍历6.B树的高度7.整体代码 三、B树和B*树1.B树2.B*树3.总结 一、B树的基本概念 1.引入 我们已经学习过二叉排序树、AVL树和红黑树三种树形查找结构&#x…...

C++(Qt)-GIS开发-QGraphicsView显示瓦片地图简单示例
C(Qt)-GIS开发-QGraphicsView显示瓦片地图简单示例 文章目录 C(Qt)-GIS开发-QGraphicsView显示瓦片地图简单示例1、概述2、实现效果3、主要代码4、源码地址 更多精彩内容👉个人内容分类汇总 👈👉GIS开发 👈 1、概述 支持多线程加…...

CTFShow的RE题(三)
数学不及格 strtol 函数 long strtol(char str, char **endptr, int base); 将字符串转换为长整型 就是解这个方程组了 主要就是 v4, v9的关系, 3v9-(v10v11v12)62d10d4673 v4 v12 v11 v10 0x13A31412F8C 得到 3*v9v419D024E75FF(1773860189695) 重点&…...
WordPress主题开发进群付费主题v1.1.2 多种引流方式
全新前端UI界面,多种前端交互特效让页面不再单调,进群页面群成员数,群成员头像名称,每次刷新页面随机更新不重复,最下面评论和点赞也是如此随机刷新不重复 进群页面简介,群聊名称,群内展示&…...
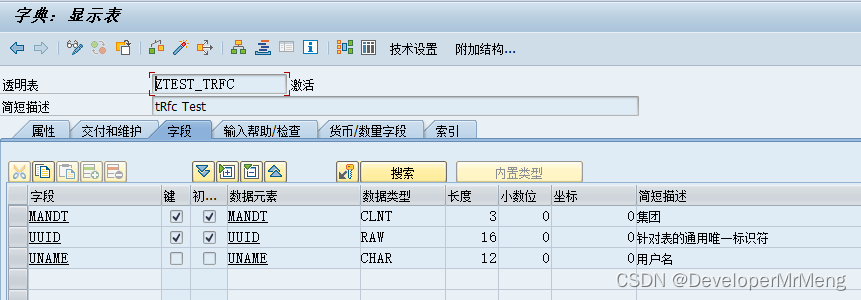
SAP中的 UPDATA TASK 和 BACKGROUND TASK
前言: 记录这篇文章起因是调查生产订单报工问题引申出来的一个问题,后来再次调查后了解了其中缘由,大概记录以下,如有不对,欢迎指正。问题原贴如下: SAP CO11N BAPI_PRODORDCONF_CREATE_TT连续报工异步更…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...