昇思25天学习打卡营第13天|BERT

一、简介:
BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自然语言推理、文本分类等在许多自然语言处理任务中发挥着重要作用。模型是基于Transformer中的Encoder并加上双向的结构,因此一定要熟练掌握Transformer的Encoder的结构。
BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
在用Masked Language Model方法训练BERT的时候,随机把语料库中15%的单词做Mask操作。对于这15%的单词做Mask操作分为三种情况:80%的单词直接用[Mask]替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
因为涉及到Question Answering (QA) 和 Natural Language Inference (NLI)之类的任务,增加了Next Sentence Prediction预训练任务,目的是让模型理解两个句子之间的联系。与Masked Language Model任务相比,Next Sentence Prediction更简单些,训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,BERT模型预测B是不是A的下一句。
BERT预训练之后,会保存它的Embedding table和12层Transformer权重(BERT-BASE)或24层Transformer权重(BERT-LARGE)。使用预训练好的BERT模型可以对下游任务进行Fine-tuning,比如:文本分类、相似度判断、阅读理解等。
二、环境准备:
在导入包之前,首先咱们要确定已经在实验的环境中安装了mindspore和mindnlp:mindspore的安装可以参考昇思25天学习打卡营第1天|快速入门-CSDN博客,mindnlp的安装则直接运行下面的命令即可:
pip install mindnlp==0.3.1安装完成之后,导入我们下面训练需要的包:
import os
import timeimport mindspore
from mindspore.dataset import text, GeneratorDataset, transforms
from mindspore import nn, contextfrom mindnlp._legacy.engine import Trainer, Evaluator
from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback
from mindnlp._legacy.metrics import Accuracy三、数据集:
1、数据集下载:
这里使用的是来自于百度飞桨的一份已标注的、经过分词预处理的机器人聊天数据集。数据由两列组成,以制表符('\t')分隔,第一列是情绪分类的类别(0表示消极;1表示中性;2表示积极),第二列是以空格分词的中文文本,如下示例,文件为 utf8 编码。
label--text_a
0--谁骂人了?我从来不骂人,我骂的都不是人,你是人吗 ?
1--我有事等会儿就回来和你聊
2--我见到你很高兴谢谢你帮我
wget https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz -O emotion_detection.tar.gz
tar xvf emotion_detection.tar.gz2、数据预处理:
新建 process_dataset 函数用于数据加载和数据预处理:
import numpy as npdef process_dataset(source, tokenizer, max_seq_len=64, batch_size=32, shuffle=True):is_ascend = mindspore.get_context('device_target') == 'Ascend'column_names = ["label", "text_a"]dataset = GeneratorDataset(source, column_names=column_names, shuffle=shuffle)# transformstype_cast_op = transforms.TypeCast(mindspore.int32)def tokenize_and_pad(text):if is_ascend:tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text)return tokenized['input_ids'], tokenized['attention_mask']# map datasetdataset = dataset.map(operations=tokenize_and_pad, input_columns="text_a", output_columns=['input_ids', 'attention_mask'])dataset = dataset.map(operations=[type_cast_op], input_columns="label", output_columns='labels')# batch datasetif is_ascend:dataset = dataset.batch(batch_size)else:dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})return dataset昇腾NPU环境下暂不支持动态Shape,数据预处理部分采用静态Shape处理,也就是说数据预处理阶段需要采用固定的数据形状。
定义bert的分词器:
from mindnlp.transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
tokenizer.pad_token_id
将数据集划分为训练集、开发集和测试集:
class SentimentDataset:"""Sentiment Dataset"""def __init__(self, path):self.path = pathself._labels, self._text_a = [], []self._load()def _load(self):with open(self.path, "r", encoding="utf-8") as f:dataset = f.read()lines = dataset.split("\n")for line in lines[1:-1]:label, text_a = line.split("\t")self._labels.append(int(label))self._text_a.append(text_a)def __getitem__(self, index):return self._labels[index], self._text_a[index]def __len__(self):return len(self._labels)dataset_train = process_dataset(SentimentDataset("data/train.tsv"), tokenizer)
dataset_val = process_dataset(SentimentDataset("data/dev.tsv"), tokenizer)
dataset_test = process_dataset(SentimentDataset("data/test.tsv"), tokenizer, shuffle=False)dataset_train.get_col_names()
print(next(dataset_train.create_tuple_iterator()))
四、模型构建:
通过 BertForSequenceClassification 构建用于情感分类的 BERT 模型,加载预训练权重,设置情感三分类的超参数自动构建模型。后面对模型采用自动混合精度操作,提高训练的速度,然后实例化优化器,紧接着实例化评价指标,设置模型训练的权重保存策略,最后就是构建训练器,模型开始训练。
from mindnlp.transformers import BertForSequenceClassification, BertModel
from mindnlp._legacy.amp import auto_mixed_precision# set bert config and define parameters for training
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)
model = auto_mixed_precision(model, 'O1')optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)metric = Accuracy()
# define callbacks to save checkpoints
ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='bert_emotect', epochs=1, keep_checkpoint_max=2)
best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='bert_emotect_best', auto_load=True)trainer = Trainer(network=model, train_dataset=dataset_train,eval_dataset=dataset_val, metrics=metric,epochs=5, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb])%%time
# start training
trainer.run(tgt_columns="labels")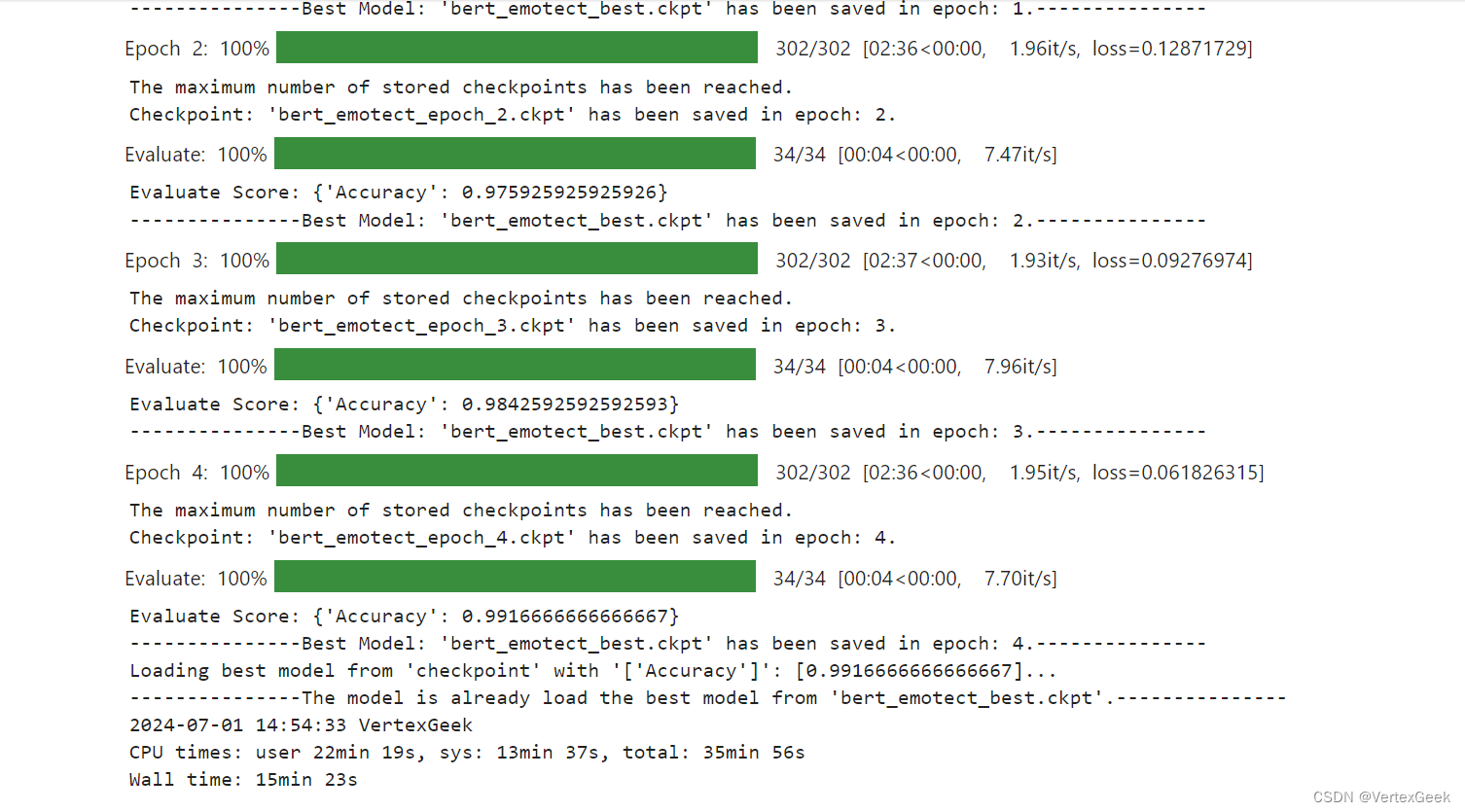
五、模型验证:
将验证数据集加再进训练好的模型,对数据集进行验证,查看模型在验证数据上面的效果,此处的评价指标为准确率。
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)
evaluator.run(tgt_columns="labels")
六、模型推理:
遍历推理数据集,将结果与标签进行统一展示。
dataset_infer = SentimentDataset("data/infer.tsv")def predict(text, label=None):label_map = {0: "消极", 1: "中性", 2: "积极"}text_tokenized = Tensor([tokenizer(text).input_ids])logits = model(text_tokenized)predict_label = logits[0].asnumpy().argmax()info = f"inputs: '{text}', predict: '{label_map[predict_label]}'"if label is not None:info += f" , label: '{label_map[label]}'"print(info)from mindspore import Tensorfor label, text in dataset_infer:predict(text, label)
输入一句话测试一下(doge):
predict("家人们咱就是说一整个无语住了 绝绝子叠buff")
相关文章:
昇思25天学习打卡营第13天|BERT
一、简介: BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自…...

跨平台书签管理器 - Raindrop
传统的浏览器书签功能虽然方便,但在管理和分类上存在诸多局限。今天,我要向大家推荐一款功能强大的跨平台书签管理-Raindrop https://raindrop.io/ 📢 主要功能: 智能分类和标签管理 强大的搜索功能 跨平台支持 分享与协作 卡片式…...
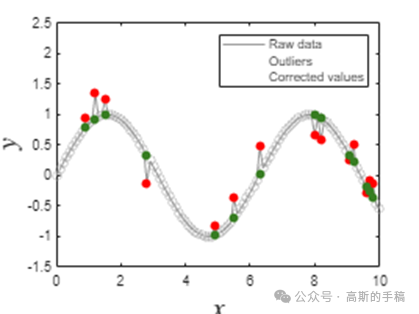
均匀采样信号的鲁棒Savistky-Golay滤波(MATLAB)
S-G滤波器又称S-G卷积平滑器,它是一种特殊的低通滤波器,用来平滑噪声数据。该滤波器被广泛地运用于信号去噪,采用在时域内基于多项式最小二乘法及窗口移动实现最佳拟合的方法。与通常的滤波器要经过时域-频域-时域变换…...

c++ 可以再头文件种直接给成员变量赋值吗
在C中,你通常不能在头文件中直接给类的成员变量赋值,因为这会导致每个包含该头文件的源文件中都尝试进行赋值,从而引发多重定义错误。然而,你可以在类的构造函数中初始化成员变量,或者在类声明中使用初始化列表或默认成…...

47.HOOK引擎优化支持CALL与JMP位置做HOOK
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 上一个内容:46.修复HOOK对代码造成的破坏 以 46.修复HOOK对代码造成的破坏 它的代码为基础进行修改 优化的是让引擎支持从短跳JMP(E9&…...

liunx上修改Firefox版本号
在Linux上修改Firefox的版本号并不直接推荐也不鼓励,因为这可能会影响到浏览器的安全性、兼容性和自动更新功能。但如果你因为某些特殊测试场景确实需要修改其显示的版本号(请注意,这样做可能会引发不可预料的问题),可…...

bug——多重定义
bug——多重定义 你的问题是在C代码中遇到了"reference to data is ambiguous"的错误。这个错误通常发生在你尝试引用一个具有多重定义的变量时。 在你的代码中,你定义了一个全局变量data,同时,C标准库中也有一个名为data的函数模板…...
与最大值(Xmx)设置为相同的配置,可以防止JVM在运行过程中根据需要动态调整堆内存大小)
将堆内存的最小值(Xms)与最大值(Xmx)设置为相同的配置,可以防止JVM在运行过程中根据需要动态调整堆内存大小
将堆内存的最小值(Xms)与最大值(Xmx)设置为相同的配置,可以防止JVM在运行过程中根据需要动态调整堆内存大小,从而避免因内存分配策略变化引起的性能波动,也就是所谓的"内存震荡"&…...

安装 tesseract
安装 tesseract 1. Ubuntu-24.04 安装 tesseract2. Ubuntu-24.04 安装支持语言3. Windows 安装 tesseract4. Oracle Linux 8 安装 tesseract 1. Ubuntu-24.04 安装 tesseract sudo apt install tesseract-ocr sudo apt install libtesseract-devreference: https://tesseract-…...
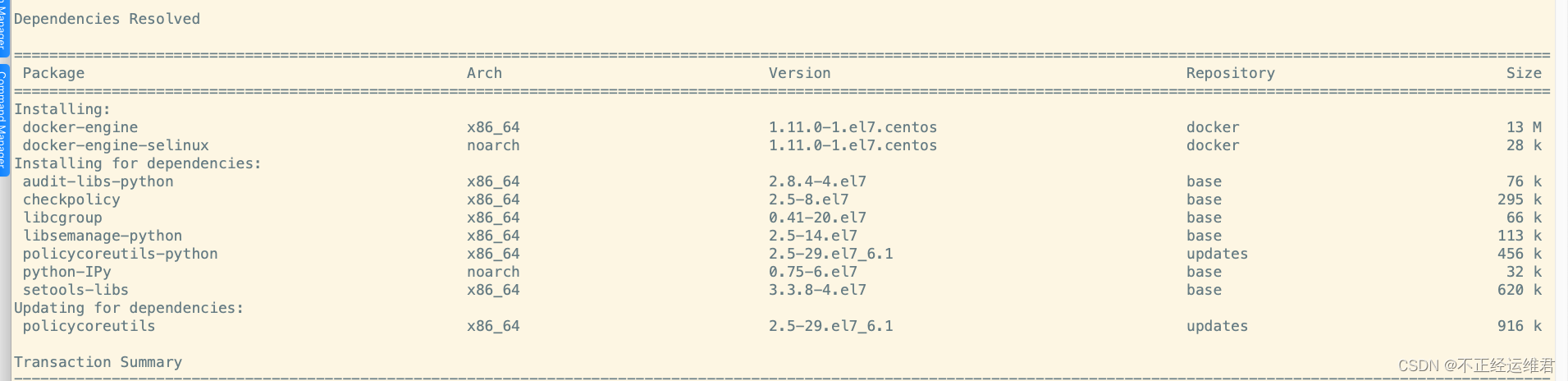
为适配kubelet:v0.4 安装指定版本的docker
系统版本信息 cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core) iso 文件下载地址 https://vault.centos.org/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso0.4 版本的kubelet 报错信息记录 E0603 19:00:38.273720 44142 kubelet.go:734] Error synci…...

vivado CLOCK_REGION、CLOCK_ROOT
时钟区域 CLOCK_REGION属性用于将时钟缓冲区分配给 UltraScale设备,同时让Vivado放置程序将时钟缓冲区分配给最佳站点 在该区域内。 重要提示:对于UltraScale设备,不建议将时钟缓冲区固定到特定站点,因为 你可以在时钟上规划一个7…...

alphazero学习
AlphaGoZero是AlphaGo算法的升级版本。不需要像训练AlphaGo那样,不需要用人类棋局这些先验知识训练,用MCTS自我博弈产生实时动态产生训练样本。用MCTS来创建训练集,然后训练nnet建模的策略网络和价值网络。就是用MCTSPlayer产生的数据来训练和…...

剖析DeFi交易产品之UniswapV3:交易路由合约
本文首发于公众号:Keegan小钢 SwapRouter 合约封装了面向用户的交易接口,但不再像 UniswapV2Router 一样根据不同交易场景拆分为了那么多函数,UniswapV3 的 SwapRouter 核心就只有 4 个交易函数: exactInputSingle:指…...

Agent下载安装步骤
目录 一. 环境准备 二. 部署安装 三. Server端Web页面添加agent客户端 一. 环境准备 准备一台虚拟机,关闭防火墙和selinux,进行时间同步。 版本主机名IP系统zabbix6.4-agentweb1192.168.226.29Rocky_linux9.4 修改主机名 [rootlocalhost ~]# hostna…...

2024年AI技术深入研究
2024年AI技术持续快速发展,应用领域广泛,产业发展迅速,市场趋势积极,学术研究深入。 AI技术进展大模型发展 2024年,智谱AI正在研发对标OpenAI Sora的高质量文生视频模型,预计最快年内发布。智谱AI的进展显示了国内AI大模型领域的快速发展,以及与国际领先技术的竞争态势…...

Apache Seata分布式事务启用Nacos做配置中心
本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 本文来自 Apache Seata官方文档,欢迎访问官网,查看更多深度文章。 Seata分布式事务启用Nacos做配置中心 Seata分布式事务启用Nacos做配置中心 项目地址 本文作…...

Emacs之解决:java-mode占用C-c C-c问题(一百四十六)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...

go语言day10 接口interface 类型断言 type关键字
接口: 空接口类型: 要实现一个接口,就要实现该接口中的所有方法。因为空接口中没有方法,所以自然所有类型都实现了空接口。那么就可以使用空接口类型变量去接受所有类型对象。 类比java,有点像Object类型的概念&#x…...

Java实现登录验证 -- JWT令牌实现
目录 1.实现登录验证的引出原因 2.JWT令牌2.1 使用JWT令牌时2.2 令牌的组成 3. JWT令牌(token)生成和校验3.1 引入JWT令牌的依赖3.2 使用Jar包中提供的API来实现JWT令牌的生成和校验3.3 使用JWT令牌验证登录3.4 令牌的优缺点 1.实现登录验证的引出 传统…...
liunx文件系统,日志分析
文章目录 1.inode与block1.1 inode与block概述1.2 inode的内容1.3 文件存储1.4 inode的大小1.5 inode的特殊作用 2.硬链接与软链接2.1链接文件分类 3.恢复误删除的文件3.1 案例:恢复EXT类型的文件3.2 案例:恢复XFS类型的文件3.2.1 xfsdump使用限制 4.分析日志文件4.1日志文件4.…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...