3. train_encoder_decoder.py
train_encoder_decoder.py
#__future__ 模块提供了一种方式,允许开发者在当前版本的 Python 中使用即将在将来版本中成为标准的功能和语法特性。此处为了确保代码同时兼容Python 2和Python 3版本中的print函数
from __future__ import print_function # 导入标准库和第三方库#os 是一个标准库模块,全称为 "operating system",用于提供与操作系统交互的功能。导入os.path模块用于处理文件和目录路径
import os.path
#从os模块中导入了path子模块,可以直接使用path来调用os.path中的函数(上面的代码可以不用写)
from os import path #导入了sys模块,用于系统相关的参数和函数
import sys
#导入了math模块,提供了数学运算函数
import math
#导入了NumPy库,并使用np作为别名,NumPy是用于科学计算的基础库
import numpy as np
#导入了Pandas库,并使用pd作为别名,Pandas是用于数据分析的强大库
import pandas as pd # 导入深度学习相关库
# keras 是一个机器学习和深度学习的库。backend 模块提供了对底层深度学习框架(如TensorFlow、Theano等)的访问接口,使得在不同的后端之间进行无缝切换变得更加容易。
import tensorflow as tf # 导入了Keras的backend模块,并使用K作为别名,用于访问后端引擎的函数
from keras import backend as K
# Model 类在 Keras 中允许用户以函数式 API 的方式构建更为复杂的神经网络模型。通过使用 Model 类,可以自由地定义输入层、输出层和中间层,并将它们连接起来形成一个完整的模型。
from keras.models import Model # 1. LSTM (Long Short-Term Memory) 和 GRU (Gated Recurrent Unit) 都是循环神经网络 (RNN) 的变体,可以用来学习长期依赖关系,用于处理序列数据。
# 2. 在处理序列数据时,经常需要将某个层(如 Dense 层)应用于序列中的每一个时间步。TimeDistributed 可以将这样的层包装起来,使其能够处理整个序列。
# 3. 在函数式 API 中,可以使用 Input 来定义模型的输入节点,指定输入的形状和数据类型。
# 4. 在神经网络中,Dense 层是最基本的层之一,每个输入节点都与输出节点相连,用于学习数据中的非线性关系。
# 5. RepeatVector接受一个 2D 张量作为输入,并重复其内容 n 次生成一个3D张量,用于序列数据处理中的某些操作,例如将上下文向量重复多次以与每个时间步相关联。
from keras.layers import LSTM, GRU, TimeDistributed, Input, Dense, RepeatVector # 1. CSVLogger 是一个回调函数,用于将每个训练周期的性能指标(如损失和指标值)记录到 CSV 文件中。训练完成后,可以使用记录的数据进行分析和可视化,帮助了解模型在训练过程中的表现
# 2. EarlyStopping 是一个回调函数,用于在训练过程中根据验证集的表现来提前终止训练。它监控指定的性能指标(如验证损失)并在连续若干个周期内没有改善时停止训练,防止模型过拟合。
# 3. TerminateOnNaN 是一个回调函数,用于在训练过程中检测到损失函数返回 NaN(Not a Number)时提前终止训练。这可以帮助捕捉和处理训练过程中出现的数值问题,避免模型继续训练无效参数
from keras.callbacks import CSVLogger, EarlyStopping, TerminateOnNaN# regularizers 用于定义正则化项,减少模型的过拟合,通过向模型的损失函数添加惩罚项来限制模型参数的大小或者复杂度。
from keras import regularizers # Adam (Adaptive Moment Estimation) 优化器是基于随机梯度下降 (Stochastic Gradient Descent, SGD) 的方法之一,但它结合了动量优化和自适应学习率的特性:
# 1. 动量(Momentum):类似于经典的随机梯度下降中的动量项,Adam会在更新参数时考虑上一步梯度的指数加权平均值,以减少梯度更新的方差,从而加速收敛;
# 2. 自适应学习率:Adam根据每个参数的梯度的一阶矩估计(均值)和二阶矩估计(方差)来自动调整学习率。这种自适应学习率的机制可以使得不同参数有不同的学习率,从而更有效地优化模型。
from keras.optimizers import Adam # 1. 假设有一个函数 func(a, b, c),通过 partial(func, 1) 可以创建一个新函数,相当于 func(1, b, c),其中 1 是已经固定的参数。
# 2. update_wrapper 是一个函数,用于更新后一个函数的元信息(比如文档字符串、函数名等)到前一个函数上
from functools import partial, update_wrapper
def wrapped_partial(func, *args, **kwargs):partial_func = partial(func, *args, **kwargs)update_wrapper(partial_func, func)return partial_func# 这是一个自定义的损失函数,计算加权的均方误差(Mean Squared Error)
# y_true是真实值,y_pred是预测值,weights是权重
# axis=-1指定了在计算均值时应该沿着最内层的轴进行操作,即在每个样本或数据点上进行平均,而不是在整个批次或特征维度上进行平均
def weighted_mse(y_true, y_pred, weights):return K.mean(K.square(y_true - y_pred) * weights, axis=-1)# 这部分代码用于选择使用的GPU设备。它从命令行参数中获取一个整数值gpu,如果gpu小于3,则设置CUDA环境变量以指定使用的GPU设备
import os
gpu = int(sys.argv[-13])
if gpu < 3:os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" # see issue #152os.environ["CUDA_VISIBLE_DEVICES"]= "{}".format(gpu)from tensorflow.python.client import device_libprint(device_lib.list_local_devices())# 这部分代码获取了一系列命令行参数,并将它们分别赋值给变量
# 这些参数包括dataname数据集名称、nb_batches训练的批次数量、nb_epochs训练周期数、lr学习率、penalty正则化惩罚、dr丢弃率、patience耐心(用于Early Stopping),n_hidden神经网络中隐藏层的数量,hidden_activation隐藏层激活函数
imp = sys.argv[-1]
T = sys.argv[-2]
t0 = sys.argv[-3]
dataname = sys.argv[-4]
nb_batches = sys.argv[-5]
nb_epochs = sys.argv[-6]
lr = float(sys.argv[-7])
penalty = float(sys.argv[-8])
dr = float(sys.argv[-9])
patience = sys.argv[-10]
n_hidden = int(sys.argv[-11])
hidden_activation = sys.argv[-12]# results_directory 是一个字符串,表示将要创建的结果文件夹路径,dataname 是之前从命令行参数中获取的数据集名称。
# .format(dataname) 是字符串的格式化方法,它会将 dataname 变量的值插入到占位符 {} 的位置。
# 如果这个文件夹路径不存在,就使用 os.makedirs 函数创建它。这个路径通常用于存储训练模型的结果或者日志。
results_directory = 'results/encoder-decoder/{}'.format(dataname)
if not os.path.exists(results_directory):os.makedirs(results_directory)# 定义了一个函数 create_model,用于创建、编译和返回一个循环神经网络(RNN)模型
def create_model(n_pre, n_post, nb_features, output_dim, lr, penalty, dr, n_hidden, hidden_activation):""" creates, compiles and returns a RNN model @param nb_features: the number of features in the model"""# 这里定义了两个输入层:# 1. inputs 是一个形状为 (n_pre, nb_features) 的输入张量,用于模型的主输入;# 2. weights_tensor 是一个形状相同的张量,用于传递权重或其他需要的信息inputs = Input(shape=(n_pre, nb_features), name="Inputs") weights_tensor = Input(shape=(n_pre, nb_features), name="Weights") # 编码器,这里使用了两个 LSTM 层: # lstm_1 的主要作用是将输入序列转换为一个语义上丰富的固定长度表示(即隐藏状态),并且该表示包含了输入序列的全部信息。这个固定长度的表示将作为解码器的输入,用于生成目标序列。# 1. n_hidden:指定 LSTM 层的隐藏单元数,决定了网络的记忆容量和复杂度。# 2. dropout=dr 和 recurrent_dropout=dr:分别指定了输入和循环 dropout 的比例,有助于防止过拟合。# 3. activation=hidden_activation:设置了 LSTM 单元的激活函数,这里是通过 hidden_activation 参数传递的。# 4. return_sequences=True:指定返回完整的输出序列,而不是只返回最后一个时间步的输出。这是为了将完整的输入序列信息编码成隐藏状态序列,以便后续的解码器使用。# lstm_2 是一个相同的 LSTM 层,但它只返回最后一个时间步的输出 lstm_1 = LSTM(n_hidden, dropout=dr, recurrent_dropout=dr, activation=hidden_activation, return_sequences=True, name='LSTM_1')(inputs) lstm_2 = LSTM(n_hidden, activation=hidden_activation, return_sequences=False, name='LSTM_2')(lstm_1) repeat = RepeatVector(n_post, name='Repeat')(lstm_2) # get the last output of the LSTM and repeats itgru_1 = GRU(n_hidden, activation=hidden_activation, return_sequences=True, name='Decoder')(repeat) # Decoderoutput= TimeDistributed(Dense(output_dim, activation='linear', kernel_regularizer=regularizers.l2(penalty), name='Dense'), name='Outputs')(gru_1)model = Model([inputs, weights_tensor], output)# model.compile(optimizer=Adam(lr=lr), loss=cl) 对模型进行编译。# optimizer=Adam(lr=lr) 指定了优化器为 Adam,并设置了学习率为 lr。# loss=cl 指定了损失函数为 cl,即上面定义的加权均方误差函数。cl = wrapped_partial(weighted_mse, weights=weights_tensor)model.compile(optimizer=Adam(lr=lr), loss=cl)print(model.summary()) return modeldef train_model(model, dataX, dataY, weights, nb_epoches, nb_batches):# Prepare model checkpoints and callbacksstopping = EarlyStopping(monitor='val_loss', patience=int(patience), min_delta=0, verbose=1, mode='min', restore_best_weights=True)csv_logger = CSVLogger('results/encoder-decoder/{}/training_log_{}_{}_{}_{}_{}_{}_{}_{}.csv'.format(dataname,dataname,imp,hidden_activation,n_hidden,patience,dr,penalty,nb_batches), separator=',', append=False)terminate = TerminateOnNaN()# 训练过程中会生成一个 history 对象,其中包含了训练过程中的损失和指标等信息,但并没有直接输出最终的参数值history = model.fit(x=[dataX,weights], y=dataY, batch_size=nb_batches, verbose=1,epochs=nb_epoches, callbacks=[stopping,csv_logger,terminate],validation_split=0.2)def test_model():n_post = int(1)n_pre =int(t0)-1seq_len = int(T)wx = np.array(pd.read_csv("data/{}-wx-{}.csv".format(dataname,imp)))print('raw wx shape', wx.shape) wXC = []for i in range(seq_len-n_pre-n_post):wXC.append(wx[i:i+n_pre]) wXC = np.array(wXC)print('wXC shape:', wXC.shape)x = np.array(pd.read_csv("data/{}-x-{}.csv".format(dataname,imp)))print('raw x shape', x.shape) dXC, dYC = [], []for i in range(seq_len-n_pre-n_post):dXC.append(x[i:i+n_pre])dYC.append(x[i+n_pre:i+n_pre+n_post])dataXC = np.array(dXC)dataYC = np.array(dYC)print('dataXC shape:', dataXC.shape)print('dataYC shape:', dataYC.shape)nb_features = dataXC.shape[2]output_dim = dataYC.shape[2]# create and fit the encoder-decoder networkprint('creating model...')model = create_model(n_pre, n_post, nb_features, output_dim, lr, penalty, dr, n_hidden, hidden_activation)train_model(model, dataXC, dataYC, wXC, int(nb_epochs), int(nb_batches))# now testprint('Generate predictions on full training set')preds_train = model.predict([dataXC,wXC], batch_size=int(nb_batches), verbose=1)print('predictions shape =', preds_train.shape)preds_train = np.squeeze(preds_train)print('predictions shape (squeezed)=', preds_train.shape)print('Saving to results/encoder-decoder/{}/encoder-decoder-{}-train-{}-{}-{}-{}-{}-{}.csv'.format(dataname,dataname,imp,hidden_activation,n_hidden,patience,dr,penalty,nb_batches))np.savetxt("results/encoder-decoder/{}/encoder-decoder-{}-train-{}-{}-{}-{}-{}-{}.csv".format(dataname,dataname,imp,hidden_activation,n_hidden,patience,dr,penalty,nb_batches), preds_train, delimiter=",")print('Generate predictions on test set')wy = np.array(pd.read_csv("data/{}-wy-{}.csv".format(dataname,imp)))print('raw wy shape', wy.shape) wY = []for i in range(seq_len-n_pre-n_post):wY.append(wy[i:i+n_pre]) # weights for outputswXT = np.array(wY)print('wXT shape:', wXT.shape)y = np.array(pd.read_csv("data/{}-y-{}.csv".format(dataname,imp)))print('raw y shape', y.shape) dXT = []for i in range(seq_len-n_pre-n_post):dXT.append(y[i:i+n_pre]) # treated is inputdataXT = np.array(dXT)print('dataXT shape:', dataXT.shape)preds_test = model.predict([dataXT, wXT], batch_size=int(nb_batches), verbose=1)print('predictions shape =', preds_test.shape)preds_test = np.squeeze(preds_test)print('predictions shape (squeezed)=', preds_test.shape)print('Saving to results/encoder-decoder/{}/encoder-decoder-{}-test-{}-{}-{}-{}-{}-{}.csv'.format(dataname,dataname,imp,hidden_activation,n_hidden,patience,dr,penalty,nb_batches))np.savetxt("results/encoder-decoder/{}/encoder-decoder-{}-test-{}-{}-{}-{}-{}-{}.csv".format(dataname,dataname,imp,hidden_activation,n_hidden,patience,dr,penalty,nb_batches), preds_test, delimiter=",")def main():test_model()return 1if __name__ == "__main__":main()
相关文章:

3. train_encoder_decoder.py
train_encoder_decoder.py #__future__ 模块提供了一种方式,允许开发者在当前版本的 Python 中使用即将在将来版本中成为标准的功能和语法特性。此处为了确保代码同时兼容Python 2和Python 3版本中的print函数 from __future__ import print_function # 导入标准库…...

Hyper-V克隆虚拟机教程分享!
方法1. 使用导出导入功能克隆Hyper-V虚拟机 导出和导入是Hyper-V服务器备份和克隆的一种比较有效的方法。使用此功能,您可以创建Hyper-V虚拟机模板,其中包括软件、VM CPU、RAM和其他设备的配置,这有助于在Hyper-V中快速部署多个虚拟机。 在…...
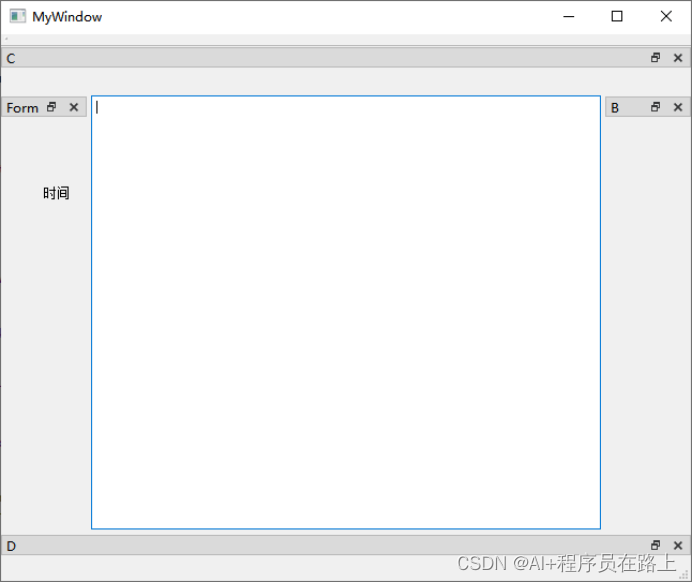
QDockWidget类详解
一.QDockWidget类概述 1.QDockWidget类 QDockWidget类提供了一个特殊的窗口部件,它可以是被锁在QMainWindow窗口内部或者是作为顶级窗口悬浮在桌面上。 QDockWidget类提供了dock widget的概念,dock widget也就是我们熟悉的工具面板或者是工具窗口。Do…...
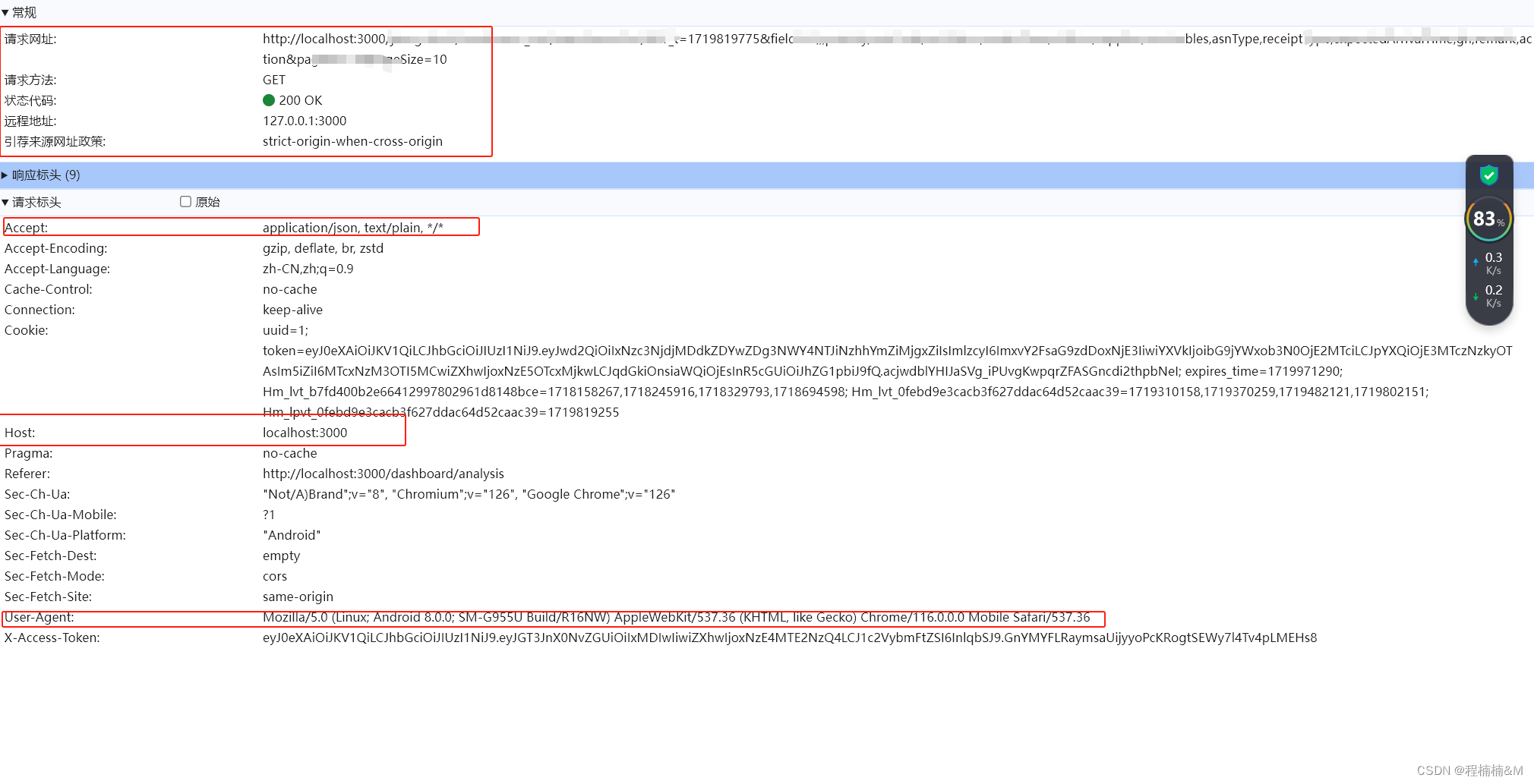
vue3.0(十六)axios详解以及完整封装方法
文章目录 axios简介1. promise2. axios特性3. 安装4. 请求方法5. 请求方法别名6. 浏览器支持情况7. 并发请求 Axios的config的配置信息1.浏览器控制台相关的请求信息:2.配置方法3.默认配置4.配置的优先级5.axios请求响应结果 Axios的拦截器1.请求拦截2.响应拦截3.移…...

Python用于处理 DNS 查询库之Dnspython 使用详解
概要 Dnspython 是一个开源的 Python 库,专门用于处理 DNS 查询。它被设计为既简单易用又功能强大,可以满足从简单到复杂的各种 DNS 相关需求。无论是进行基础的 DNS 查询还是进行高级的 DNS 服务器管理,dnspython 都能提供相应的功能。 这个库支持包括 A、AAAA、MX、TXT …...

Django ORM 中过滤 JSON 数据
简介 首先,我们假设您有一个名为 MyModel 的 Django 模型,它包含一个 JSONField 类型的字段,名为 data。这个 data 字段可以存储各种 JSON 格式的数据。 过滤 JSON 字段中的键值对 您可以使用双下划线 __ 语法来访问 JSON 字段中的嵌套键值对。例如: # 过滤 data 字段中 &qu…...

深入探索C语言中的结构体:定义、特性与应用
🔥 个人主页:大耳朵土土垚 目录 结构体的介绍结构体定义结构成员的类型结构体变量的定义和初始化结构体成员的访问结构体传参 结构体的介绍 在C语言中,结构体是一种用户自定义的数据类型,它允许开发者将不同类型的变量组合在一起…...
)
EDEM-FLUENT耦合报错几大原因总结(持续更新)
写在前面,本篇内容主要是来源于自己做仿真时的个人总结,以及付费请教专业老师。每个人由于工况不一样,所以报错原因千奇百怪,不能一概而论,本篇内容主要是为本专栏读者在报错时提供大致的纠错方向,从而达到少走弯路的效果,debug的过程需要大家一点点试算。问题解答在文 …...
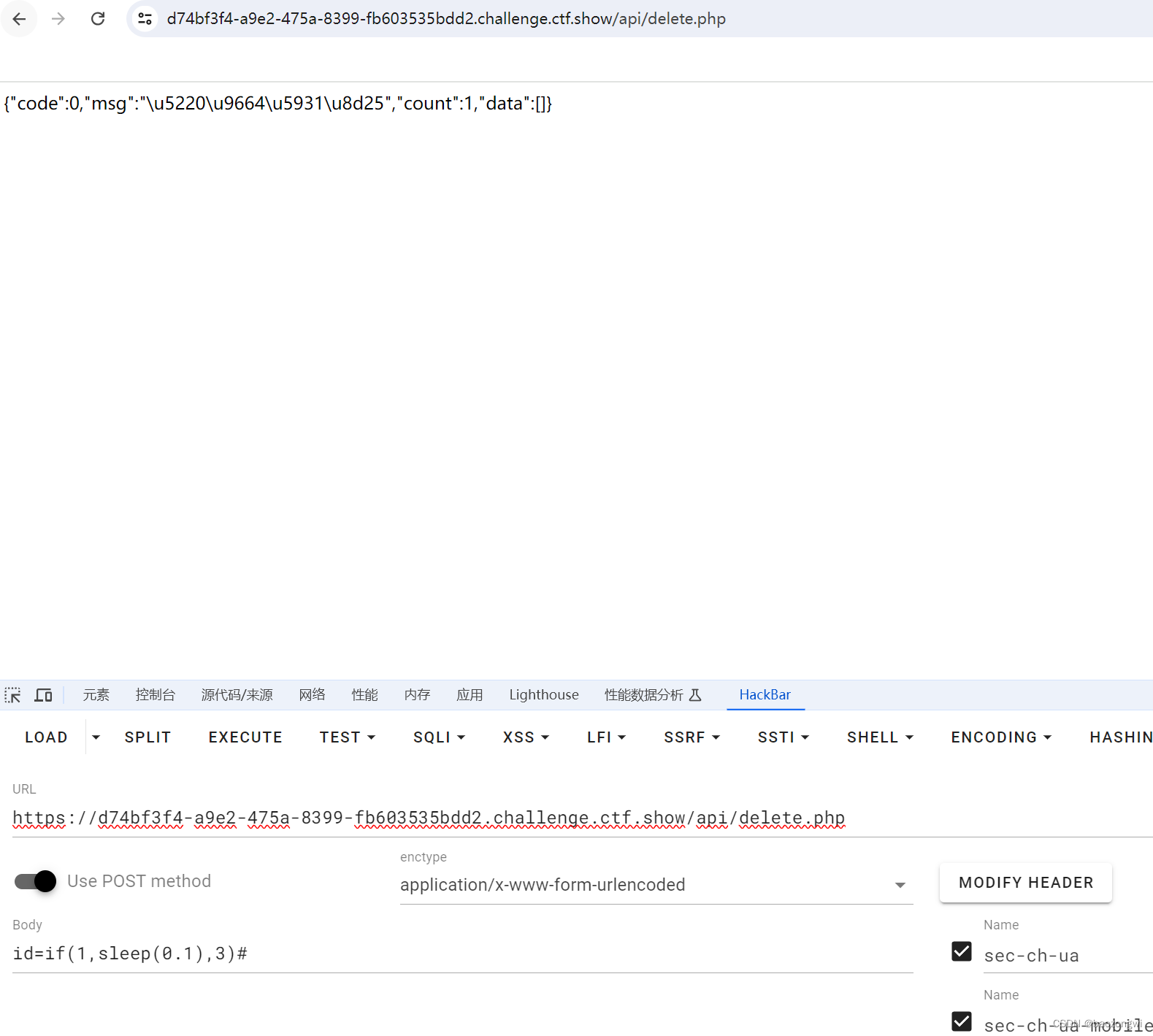
ctfshow sql注入 web234--web241
web234 $sql "update ctfshow_user set pass {$password} where username {$username};";这里被过滤了,所以我们用\转义使得变为普通字符 $sql "update ctfshow_user set pass \ where username {$username};";那么这里的话 pass\ where…...

Python的招聘数据分析与可视化管理系统-计算机毕业设计源码55218
摘要 随着互联网的迅速发展,招聘数据在规模和复杂性上呈现爆炸式增长,对数据的深入分析和有效可视化成为招聘决策和招聘管理的重要手段。本论文旨在构建一个基于Python的招聘数据分析与可视化管理系统。 该平台以主流招聘平台为数据源,利用Py…...

使用ChatGPT写学术论文的技巧和最佳实践指南
大家好,感谢关注。我是七哥,一个在高校里不务正业,折腾学术科研AI实操的学术人。关于使用ChatGPT等AI学术科研的相关问题可以和作者七哥(yida985)交流,多多交流,相互成就,共同进步&a…...

多模态图像引导手术导航进展
**摘要:**对多模态图像分割建模、手术方案决策、手术空间位姿标定与跟踪、多模态图像配准、图像融合与显示等多模态图像引导手术导航的关键技术进行总结和分析,提出其进一步发展面临的挑战并展望其未来发展趋势。 **外科手术的发展历程:**从最…...
)
小程序 全局数据共享 getApp()
在小程序中,可以通过 getApp() 方法获取到小程序全局唯一的App实例 因此在App() 方法中添加全局共享的数据、方法,从而实现页面、组件的数据传值 在 app.js 文件中定义 App({// 全局共享的数据globalData:{token:},// 全局共享的方法setToken(token){//…...
)
第一次面试的经历(java开发实习生)
面试官的问题 我想问一下你这边有做过什么项目吗?你方便讲一下你做过的那些项目吗,用了什么技术栈,包括你负责开发的内容是什么?(项目经验)八大基本数据类型是什么?(基础)你说一下…...

GitHub Copilot API
1. 引言 GitHub Copilot:智能编程的革新者 在软件开发的浩瀚宇宙中,GitHub Copilot犹如一颗璀璨的新星,以其独特的魅力引领着智能编程的新纪元。作为GitHub与OpenAI合作推出的革命性工具,Copilot不仅仅是一个简单的代码补全插件…...

CobaltStrike的内网安全
1.上线机器的Beacon的常用命令 2.信息收集和网站克隆 3.钓鱼邮件 4.CS传递会话到MSF 5.MSF会话传递到CS 1上线机器的Beacon的常用命令 介绍:CobaltStrike分为服务端和客户端,一般我们将服务端放在kali,客户端可以在物理机上面࿰…...
Linux之进程控制(下)
目录 进程替换的概念 进程替换的函数 execl编辑 execlp execle execv execvp execve 上期,我们学习了进程创建,进程终止和进程等待,今天我们要学习的是进程控制中相对重要的板块------进程替换。 进程替换的概念 在进程创建时&…...
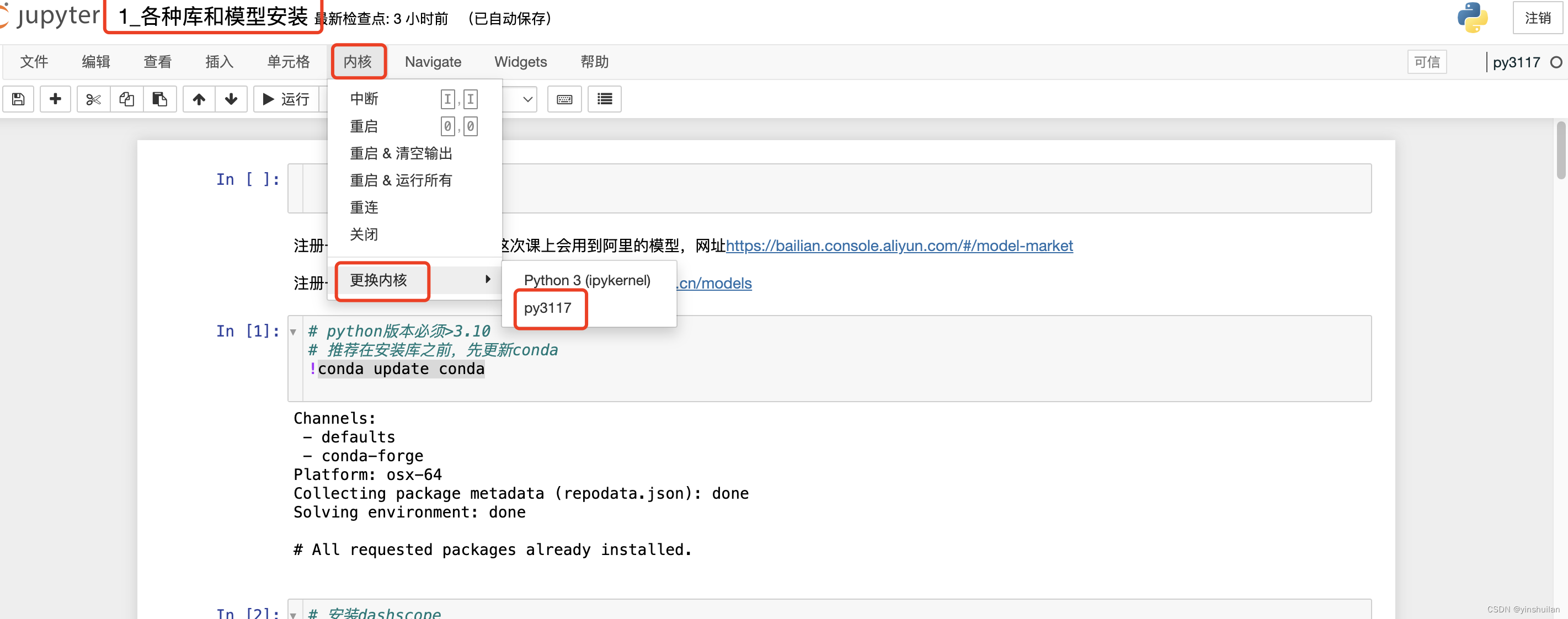
Mac搭建anaconda环境并安装深度学习库
1. 下载anaconda安装包 根据自己的操作系统不同,选择不同的安装包Anaconda3-2024.06-1-MacOSX-x86_64.pkg,我用的还是旧的intel所以下载这个,https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/,如果mac用的是M1࿰…...

Linux:文件系统与日志分析
一、block与inode 1.1、概述 文件是存储在硬盘上的,硬盘的最小存储单位叫做“扇区”(sector),每个扇区存储512字节。 一般连续八个扇区组成一个"块”(block),一个块是4K大小,是文件存取的最小单位。 文件数据包括实际数据…...
迈阿密色主题学科 HTML5静态导航源码
源码介绍 迈阿密色主题学科 HTML5静态导航源码,源码直接上传可用,有技术的可以拿去写个后端搜索调用百度接口,也可用于做引导页下面加你网址添加一个A标签就行了,很简单,需要的朋友就拿去吧 界面预览 源码下载 迈阿…...
)
别再买错卡了!手把手教你用Arduino Uno和MFRC522模块DIY智能门禁(附完整代码和避坑指南)
从零搭建Arduino RFID门禁:硬件选购、代码优化与避坑全指南 第一次接触Arduino和RFID技术时,我被琳琅满目的硬件选择和复杂的代码搞得晕头转向。特别是当兴冲冲买回一堆组件后,发现卡片根本无法被识别——原来是因为忽略了频率匹配这个关键细…...

intv_ai_mk11开源可部署指南:下载镜像、启动服务、浏览器访问、安全注意事项全涵盖
intv_ai_mk11开源可部署指南:下载镜像、启动服务、浏览器访问、安全注意事项全涵盖 1. 项目概述 intv_ai_mk11是一款基于Llama架构的AI对话机器人,拥有7B参数规模,能够运行在GPU服务器上提供智能对话服务。这个开源项目可以帮助开发者快速部…...

MelonLoader完全解决方案:Unity游戏Mod加载实战指南
MelonLoader完全解决方案:Unity游戏Mod加载实战指南 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 当你兴致勃勃地…...
)
大规模数据清洗效率提升300%的Polars 2.0实战方案(内存泄漏避坑全图谱)
第一章:Polars 2.0大规模数据清洗的范式跃迁 Polars 2.0 不再是 Pandas 的轻量替代品,而是一次面向现代硬件与真实数据工程场景的底层重构。其核心跃迁体现在三重解耦:计算图与执行引擎分离、内存布局与逻辑 Schema 解耦、以及 I/O 层与处理层…...

丹青幻境·Z-Image Atelier部署教程:Docker Compose一键启停方案
丹青幻境Z-Image Atelier部署教程:Docker Compose一键启停方案 1. 学习目标与前置准备 本教程将手把手教你如何使用Docker Compose快速部署丹青幻境Z-Image Atelier数字艺术创作平台。通过本教程,你将学会: 如何在5分钟内完成环境搭建如何…...

OpenClaw替代方案:当Qwen3-4B不可用时降级策略
OpenClaw替代方案:当Qwen3-4B不可用时降级策略 1. 为什么需要降级策略 上周三凌晨3点,我的OpenClaw自动化脚本突然停止了工作。原本定时执行的周报生成任务卡在了模型调用环节——Qwen3-4B服务因网络波动暂时不可用。这次意外让我意识到:依…...

C语言函数返回值的设计哲学与实践
1. C语言函数返回值的本质与设计哲学在嵌入式开发领域摸爬滚打十几年,我见过太多因为函数返回值设计不当导致的"血案"。记得刚入行时调试一个串口通信模块,就因为误判了第三方库的返回值逻辑,整整浪费了两天时间。C语言的函数返回值…...
)
3行代码实现微信级扫码:OpenCV wechat_qrcode 实战全解(c++实现)
文章目录前言一、wechat_qrcode 核心优势1.模块定位2.核心技术优势二、环境准备与模块部署1.版本要求2.环境安装3.模型下载与路径配置三、核心代码实战(c)1.单张图片解码2.摄像头实时流解码总结前言 日常开发中,传统二维码解码方案总会遇到各类难题&…...

如何用UAV-Flow实现语音控制无人机?手把手教你搭建环境与避坑指南
如何用UAV-Flow实现语音控制无人机?从环境搭建到实战避坑全指南 当无人机遇上自然语言处理,会擦出怎样的火花?去年接触UAV-Flow时,我正为一个农业巡检项目头疼——传统摇杆控制需要专业飞手,而农户们更习惯说"绕着…...

嵌入式开发中的寄存器操作与函数指针应用
1. 嵌入式开发中的寄存器操作技巧在嵌入式系统开发中,直接操作硬件寄存器是最基础也是最核心的技能之一。寄存器是CPU与外围设备交互的窗口,通过读写特定内存地址的寄存器,我们可以控制硬件的行为。下面我将详细介绍几种常见的寄存器操作方法…...