昇思25天学习打卡营第19天 | RNN实现情感分类
RNN实现情感分类
概述
情感分类是自然语言处理中的经典任务,是典型的分类问题。本节使用MindSpore实现一个基于RNN网络的情感分类模型,实现如下的效果:
输入: This film is terrible
正确标签: Negative
预测标签: Negative输入: This film is great
正确标签: Positive
预测标签: Positive
数据准备
本节使用情感分类的经典数据集IMDB影评数据集,数据集包含Positive和Negative两类,下面为其样例:
| Review | Label |
|---|---|
| “Quitting” may be as much about exiting a pre-ordained identity as about drug withdrawal. As a rural guy coming to Beijing, class and success must have struck this young artist face on as an appeal to separate from his roots and far surpass his peasant parents’ acting success. Troubles arise, however, when the new man is too new, when it demands too big a departure from family, history, nature, and personal identity. The ensuing splits, and confusion between the imaginary and the real and the dissonance between the ordinary and the heroic are the stuff of a gut check on the one hand or a complete escape from self on the other. | Negative |
| This movie is amazing because the fact that the real people portray themselves and their real life experience and do such a good job it’s like they’re almost living the past over again. Jia Hongsheng plays himself an actor who quit everything except music and drugs struggling with depression and searching for the meaning of life while being angry at everyone especially the people who care for him most. | Positive |
此外,需要使用预训练词向量对自然语言单词进行编码,以获取文本的语义特征,本节选取Glove词向量作为Embedding。
数据下载模块
为了方便数据集和预训练词向量的下载,首先设计数据下载模块,实现可视化下载流程,并保存至指定路径。数据下载模块使用requests库进行http请求,并通过tqdm库对下载百分比进行可视化。此外针对下载安全性,使用IO的方式下载临时文件,而后保存至指定的路径并返回。
tqdm和requests库需手动安装,命令如下:pip install tqdm requests
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
# !pip uninstall mindspore -y
# !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by:
import os
import shutil
import requests
import tempfile
from tqdm import tqdm
from typing import IO
from pathlib import Path# 指定保存路径为 `home_path/.mindspore_examples`
cache_dir = Path.home() / '.mindspore_examples'def http_get(url: str, temp_file: IO):"""使用requests库下载数据,并使用tqdm库进行流程可视化"""req = requests.get(url, stream=True)content_length = req.headers.get('Content-Length')total = int(content_length) if content_length is not None else Noneprogress = tqdm(unit='B', total=total)for chunk in req.iter_content(chunk_size=1024):if chunk:progress.update(len(chunk))temp_file.write(chunk)progress.close()def download(file_name: str, url: str):"""下载数据并存为指定名称"""if not os.path.exists(cache_dir):os.makedirs(cache_dir)cache_path = os.path.join(cache_dir, file_name)cache_exist = os.path.exists(cache_path)if not cache_exist:with tempfile.NamedTemporaryFile() as temp_file:http_get(url, temp_file)temp_file.flush()temp_file.seek(0)with open(cache_path, 'wb') as cache_file:shutil.copyfileobj(temp_file, cache_file)return cache_path
完成数据下载模块后,下载IMDB数据集进行测试(此处使用华为云的镜像用于提升下载速度)。下载过程及保存的路径如下:
imdb_path = download('aclImdb_v1.tar.gz', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/aclImdb_v1.tar.gz')
imdb_path
'/home/nginx/.mindspore_examples/aclImdb_v1.tar.gz'
加载IMDB数据集
下载好的IMDB数据集为tar.gz文件,我们使用Python的tarfile库对其进行读取,并将所有数据和标签分别进行存放。原始的IMDB数据集解压目录如下:
├── aclImdb│ ├── imdbEr.txt│ ├── imdb.vocab│ ├── README│ ├── test│ └── train│ ├── neg│ ├── pos...
数据集已分割为train和test两部分,且每部分包含neg和pos两个分类的文件夹,因此需分别train和test进行读取并处理数据和标签。
import re
import six
import string
import tarfileclass IMDBData():"""IMDB数据集加载器加载IMDB数据集并处理为一个Python迭代对象。"""label_map = {"pos": 1,"neg": 0}def __init__(self, path, mode="train"):self.mode = modeself.path = pathself.docs, self.labels = [], []self._load("pos")self._load("neg")def _load(self, label):pattern = re.compile(r"aclImdb/{}/{}/.*\.txt$".format(self.mode, label))# 将数据加载至内存with tarfile.open(self.path) as tarf:tf = tarf.next()while tf is not None:if bool(pattern.match(tf.name)):# 对文本进行分词、去除标点和特殊字符、小写处理self.docs.append(str(tarf.extractfile(tf).read().rstrip(six.b("\n\r")).translate(None, six.b(string.punctuation)).lower()).split())self.labels.append([self.label_map[label]])tf = tarf.next()def __getitem__(self, idx):return self.docs[idx], self.labels[idx]def __len__(self):return len(self.docs)
完成IMDB数据加载器后,加载训练数据集进行测试,输出数据集数量:
imdb_train = IMDBData(imdb_path, 'train')
len(imdb_train)
25000
将IMDB数据集加载至内存并构造为迭代对象后,可以使用mindspore.dataset提供的Generatordataset接口加载数据集迭代对象,并进行下一步的数据处理,下面封装一个函数将train和test分别使用Generatordataset进行加载,并指定数据集中文本和标签的column_name分别为text和label:
import mindspore.dataset as dsdef load_imdb(imdb_path):imdb_train = ds.GeneratorDataset(IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True, num_samples=10000)imdb_test = ds.GeneratorDataset(IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False)return imdb_train, imdb_test
加载IMDB数据集,可以看到imdb_train是一个GeneratorDataset对象。
imdb_train, imdb_test = load_imdb(imdb_path)
imdb_train
<mindspore.dataset.engine.datasets_user_defined.GeneratorDataset at 0xffff8c3d6310>
加载预训练词向量
预训练词向量是对输入单词的数值化表示,通过nn.Embedding层,采用查表的方式,输入单词对应词表中的index,获得对应的表达向量。
因此进行模型构造前,需要将Embedding层所需的词向量和词表进行构造。这里我们使用Glove(Global Vectors for Word Representation)这种经典的预训练词向量,
其数据格式如下:
| Word | Vector |
|---|---|
| the | 0.418 0.24968 -0.41242 0.1217 0.34527 -0.044457 -0.49688 -0.17862 -0.00066023 … |
| , | 0.013441 0.23682 -0.16899 0.40951 0.63812 0.47709 -0.42852 -0.55641 -0.364 … |
我们直接使用第一列的单词作为词表,使用dataset.text.Vocab将其按顺序加载;同时读取每一行的Vector并转为numpy.array,用于nn.Embedding加载权重使用。具体实现如下:
import zipfile
import numpy as npdef load_glove(glove_path):glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')if not os.path.exists(glove_100d_path):glove_zip = zipfile.ZipFile(glove_path)glove_zip.extractall(cache_dir)embeddings = []tokens = []with open(glove_100d_path, encoding='utf-8') as gf:for glove in gf:word, embedding = glove.split(maxsplit=1)tokens.append(word)embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=' '))# 添加 <unk>, <pad> 两个特殊占位符对应的embeddingembeddings.append(np.random.rand(100))embeddings.append(np.zeros((100,), np.float32))vocab = ds.text.Vocab.from_list(tokens, special_tokens=["<unk>", "<pad>"], special_first=False)embeddings = np.array(embeddings).astype(np.float32)return vocab, embeddings
由于数据集中可能存在词表没有覆盖的单词,因此需要加入<unk>标记符;同时由于输入长度的不一致,在打包为一个batch时需要将短的文本进行填充,因此需要加入<pad>标记符。完成后的词表长度为原词表长度+2。
下面下载Glove词向量,并加载生成词表和词向量权重矩阵。
glove_path = download('glove.6B.zip', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/glove.6B.zip')
vocab, embeddings = load_glove(glove_path)
len(vocab.vocab())
400002
使用词表将the转换为index id,并查询词向量矩阵对应的词向量:
idx = vocab.tokens_to_ids('the')
embedding = embeddings[idx]
idx, embedding
(0,array([-0.038194, -0.24487 , 0.72812 , -0.39961 , 0.083172, 0.043953,-0.39141 , 0.3344 , -0.57545 , 0.087459, 0.28787 , -0.06731 ,0.30906 , -0.26384 , -0.13231 , -0.20757 , 0.33395 , -0.33848 ,-0.31743 , -0.48336 , 0.1464 , -0.37304 , 0.34577 , 0.052041,0.44946 , -0.46971 , 0.02628 , -0.54155 , -0.15518 , -0.14107 ,-0.039722, 0.28277 , 0.14393 , 0.23464 , -0.31021 , 0.086173,0.20397 , 0.52624 , 0.17164 , -0.082378, -0.71787 , -0.41531 ,0.20335 , -0.12763 , 0.41367 , 0.55187 , 0.57908 , -0.33477 ,-0.36559 , -0.54857 , -0.062892, 0.26584 , 0.30205 , 0.99775 ,-0.80481 , -3.0243 , 0.01254 , -0.36942 , 2.2167 , 0.72201 ,-0.24978 , 0.92136 , 0.034514, 0.46745 , 1.1079 , -0.19358 ,-0.074575, 0.23353 , -0.052062, -0.22044 , 0.057162, -0.15806 ,-0.30798 , -0.41625 , 0.37972 , 0.15006 , -0.53212 , -0.2055 ,-1.2526 , 0.071624, 0.70565 , 0.49744 , -0.42063 , 0.26148 ,-1.538 , -0.30223 , -0.073438, -0.28312 , 0.37104 , -0.25217 ,0.016215, -0.017099, -0.38984 , 0.87424 , -0.72569 , -0.51058 ,-0.52028 , -0.1459 , 0.8278 , 0.27062 ], dtype=float32))
数据集预处理
通过加载器加载的IMDB数据集进行了分词处理,但不满足构造训练数据的需要,因此要对其进行额外的预处理。其中包含的预处理如下:
- 通过Vocab将所有的Token处理为index id。
- 将文本序列统一长度,不足的使用
<pad>补齐,超出的进行截断。
这里我们使用mindspore.dataset中提供的接口进行预处理操作。这里使用到的接口均为MindSpore的高性能数据引擎设计,每个接口对应操作视作数据流水线的一部分,详情请参考MindSpore数据引擎。
首先针对token到index id的查表操作,使用text.Lookup接口,将前文构造的词表加载,并指定unknown_token。其次为文本序列统一长度操作,使用PadEnd接口,此接口定义最大长度和补齐值(pad_value),这里我们取最大长度为500,填充值对应词表中<pad>的index id。
除了对数据集中
text进行预处理外,由于后续模型训练的需要,要将label数据转为float32格式。
import mindspore as mslookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transforms.TypeCast(ms.float32)
完成预处理操作后,需将其加入到数据集处理流水线中,使用map接口对指定的column添加操作。
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=['label'])imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=['label'])
由于IMDB数据集本身不包含验证集,我们手动将其分割为训练和验证两部分,比例取0.7, 0.3。
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])
[WARNING] ME(49995:281473341991216,MainProcess):2024-07-05-10:40:25.898.932 [mindspore/dataset/engine/datasets.py:1203] Dataset is shuffled before split.
最后指定数据集的batch大小,通过batch接口指定,并设置是否丢弃无法被batch size整除的剩余数据。
调用数据集的
map、split、batch为数据集处理流水线增加对应操作,返回值为新的Dataset类型。现在仅定义流水线操作,在执行时开始执行数据处理流水线,获取最终处理好的数据并送入模型进行训练。
imdb_train = imdb_train.batch(64, drop_remainder=True)
imdb_valid = imdb_valid.batch(64, drop_remainder=True)
模型构建
完成数据集的处理后,我们设计用于情感分类的模型结构。首先需要将输入文本(即序列化后的index id列表)通过查表转为向量化表示,此时需要使用nn.Embedding层加载Glove词向量;然后使用RNN循环神经网络做特征提取;最后将RNN连接至一个全连接层,即nn.Dense,将特征转化为与分类数量相同的size,用于后续进行模型优化训练。整体模型结构如下:
nn.Embedding -> nn.RNN -> nn.Dense
这里我们使用能够一定程度规避RNN梯度消失问题的变种LSTM(Long short-term memory)做特征提取层。下面对模型进行详解:
Embedding
Embedding层又可称为EmbeddingLookup层,其作用是使用index id对权重矩阵对应id的向量进行查找,当输入为一个由index id组成的序列时,则查找并返回一个相同长度的矩阵,例如:
embedding = nn.Embedding(1000, 100) # 词表大小(index的取值范围)为1000,表示向量的size为100
input shape: (1, 16) # 序列长度为16
output shape: (1, 16, 100)
这里我们使用前文处理好的Glove词向量矩阵,设置nn.Embedding的embedding_table为预训练词向量矩阵。对应的vocab_size为词表大小400002,embedding_size为选用的glove.6B.100d向量大小,即100。
RNN(循环神经网络)
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的神经网络。下图为RNN的一般结构:
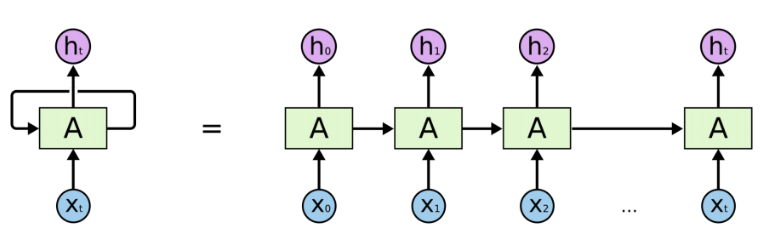
图示左侧为一个RNN Cell循环,右侧为RNN的链式连接平铺。实际上不管是单个RNN Cell还是一个RNN网络,都只有一个Cell的参数,在不断进行循环计算中更新。
由于RNN的循环特性,和自然语言文本的序列特性(句子是由单词组成的序列)十分匹配,因此被大量应用于自然语言处理研究中。下图为RNN的结构拆解:
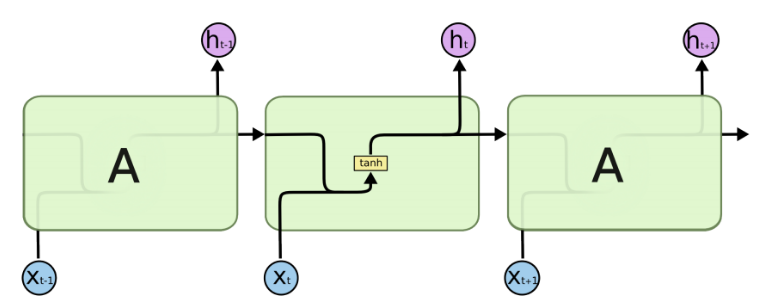
RNN单个Cell的结构简单,因此也造成了梯度消失(Gradient Vanishing)问题,具体表现为RNN网络在序列较长时,在序列尾部已经基本丢失了序列首部的信息。为了克服这一问题,LSTM(Long short-term memory)被提出,通过门控机制(Gating Mechanism)来控制信息流在每个循环步中的留存和丢弃。下图为LSTM的结构拆解:
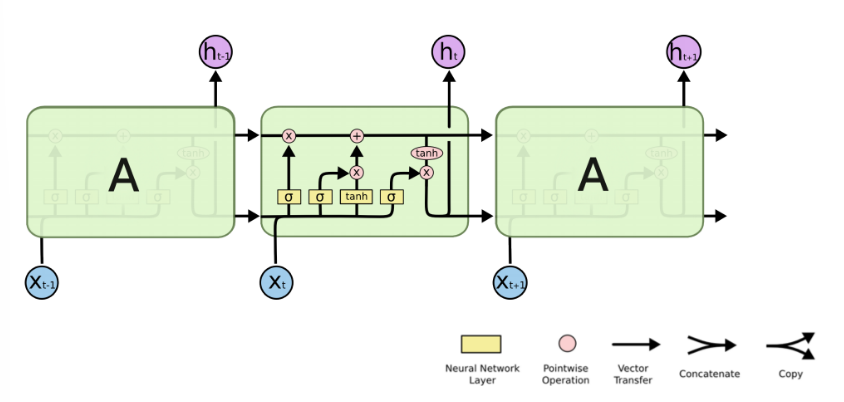
本节我们选择LSTM变种而不是经典的RNN做特征提取,来规避梯度消失问题,并获得更好的模型效果。下面来看MindSpore中nn.LSTM对应的公式:
h 0 : t , ( h t , c t ) = LSTM ( x 0 : t , ( h 0 , c 0 ) ) h_{0:t}, (h_t, c_t) = \text{LSTM}(x_{0:t}, (h_0, c_0)) h0:t,(ht,ct)=LSTM(x0:t,(h0,c0))
这里nn.LSTM隐藏了整个循环神经网络在序列时间步(Time step)上的循环,送入输入序列、初始状态,即可获得每个时间步的隐状态(hidden state)拼接而成的矩阵,以及最后一个时间步对应的隐状态。我们使用最后的一个时间步的隐状态作为输入句子的编码特征,送入下一层。
Time step:在循环神经网络计算的每一次循环,成为一个Time step。在送入文本序列时,一个Time step对应一个单词。因此在本例中,LSTM的输出 h 0 : t h_{0:t} h0:t对应每个单词的隐状态集合, h t h_t ht和 c t c_t ct对应最后一个单词对应的隐状态。
Dense
在经过LSTM编码获取句子特征后,将其送入一个全连接层,即nn.Dense,将特征维度变换为二分类所需的维度1,经过Dense层后的输出即为模型预测结果。
import math
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Uniform, HeUniformclass RNN(nn.Cell):def __init__(self, embeddings, hidden_dim, output_dim, n_layers,bidirectional, pad_idx):super().__init__()vocab_size, embedding_dim = embeddings.shapeself.embedding = nn.Embedding(vocab_size, embedding_dim, embedding_table=ms.Tensor(embeddings), padding_idx=pad_idx)self.rnn = nn.LSTM(embedding_dim,hidden_dim,num_layers=n_layers,bidirectional=bidirectional,batch_first=True)weight_init = HeUniform(math.sqrt(5))bias_init = Uniform(1 / math.sqrt(hidden_dim * 2))self.fc = nn.Dense(hidden_dim * 2, output_dim, weight_init=weight_init, bias_init=bias_init)def construct(self, inputs):embedded = self.embedding(inputs)_, (hidden, _) = self.rnn(embedded)hidden = ops.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)output = self.fc(hidden)return output
损失函数与优化器
完成模型主体构建后,首先根据指定的参数实例化网络;然后选择损失函数和优化器。针对本节情感分类问题的特性,即预测Positive或Negative的二分类问题,我们选择nn.BCEWithLogitsLoss(二分类交叉熵损失函数)。
hidden_size = 256
output_size = 1
num_layers = 2
bidirectional = True
lr = 0.001
pad_idx = vocab.tokens_to_ids('<pad>')model = RNN(embeddings, hidden_size, output_size, num_layers, bidirectional, pad_idx)
loss_fn = nn.BCEWithLogitsLoss(reduction='mean')
optimizer = nn.Adam(model.trainable_params(), learning_rate=lr)
训练逻辑
在完成模型构建,进行训练逻辑的设计。一般训练逻辑分为一下步骤:
- 读取一个Batch的数据;
- 送入网络,进行正向计算和反向传播,更新权重;
- 返回loss。
下面按照此逻辑,使用tqdm库,设计训练一个epoch的函数,用于训练过程和loss的可视化。
def forward_fn(data, label):logits = model(data)loss = loss_fn(logits, label)return lossgrad_fn = ms.value_and_grad(forward_fn, None, optimizer.parameters)def train_step(data, label):loss, grads = grad_fn(data, label)optimizer(grads)return lossdef train_one_epoch(model, train_dataset, epoch=0):model.set_train()total = train_dataset.get_dataset_size()loss_total = 0step_total = 0with tqdm(total=total) as t:t.set_description('Epoch %i' % epoch)for i in train_dataset.create_tuple_iterator():loss = train_step(*i)loss_total += loss.asnumpy()step_total += 1t.set_postfix(loss=loss_total/step_total)t.update(1)
评估指标和逻辑
训练逻辑完成后,需要对模型进行评估。即使用模型的预测结果和测试集的正确标签进行对比,求出预测的准确率。由于IMDB的情感分类为二分类问题,对预测值直接进行四舍五入即可获得分类标签(0或1),然后判断是否与正确标签相等即可。下面为二分类准确率计算函数实现:
def binary_accuracy(preds, y):"""计算每个batch的准确率"""# 对预测值进行四舍五入rounded_preds = np.around(ops.sigmoid(preds).asnumpy())correct = (rounded_preds == y).astype(np.float32)acc = correct.sum() / len(correct)return acc
有了准确率计算函数后,类似于训练逻辑,对评估逻辑进行设计, 分别为以下步骤:
- 读取一个Batch的数据;
- 送入网络,进行正向计算,获得预测结果;
- 计算准确率。
同训练逻辑一样,使用tqdm进行loss和过程的可视化。此外返回评估loss至供保存模型时作为模型优劣的判断依据。
在进行evaluate时,使用的模型是不包含损失函数和优化器的网络主体;
在进行evaluate前,需要通过model.set_train(False)将模型置为评估状态,此时Dropout不生效。
def evaluate(model, test_dataset, criterion, epoch=0):total = test_dataset.get_dataset_size()epoch_loss = 0epoch_acc = 0step_total = 0model.set_train(False)with tqdm(total=total) as t:t.set_description('Epoch %i' % epoch)for i in test_dataset.create_tuple_iterator():predictions = model(i[0])loss = criterion(predictions, i[1])epoch_loss += loss.asnumpy()acc = binary_accuracy(predictions, i[1])epoch_acc += accstep_total += 1t.set_postfix(loss=epoch_loss/step_total, acc=epoch_acc/step_total)t.update(1)return epoch_loss / total
模型训练与保存
前序完成了模型构建和训练、评估逻辑的设计,下面进行模型训练。这里我们设置训练轮数为5轮。同时维护一个用于保存最优模型的变量best_valid_loss,根据每一轮评估的loss值,取loss值最小的轮次,将模型进行保存。为节省用例运行时长,此处num_epochs设置为2,可根据需要自行修改。
num_epochs = 5
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'sentiment-analysis.ckpt')for epoch in range(num_epochs):train_one_epoch(model, imdb_train, epoch)valid_loss = evaluate(model, imdb_valid, loss_fn, epoch)if valid_loss < best_valid_loss:best_valid_loss = valid_lossms.save_checkpoint(model, ckpt_file_name)
Epoch 0: 0%| | 0/109 [00:00<?, ?it/s]-Epoch 0: 100%|██████████| 109/109 [10:13<00:00, 5.63s/it, loss=0.673]
Epoch 0: 100%|██████████| 46/46 [00:23<00:00, 1.95it/s, acc=0.652, loss=0.626]
Epoch 1: 100%|██████████| 109/109 [01:27<00:00, 1.24it/s, loss=0.67]
Epoch 1: 100%|██████████| 46/46 [00:14<00:00, 3.25it/s, acc=0.653, loss=0.633]
Epoch 2: 100%|██████████| 109/109 [01:30<00:00, 1.20it/s, loss=0.612]
Epoch 2: 100%|██████████| 46/46 [00:13<00:00, 3.33it/s, acc=0.74, loss=0.543]
Epoch 3: 100%|██████████| 109/109 [01:29<00:00, 1.22it/s, loss=0.559]
Epoch 3: 100%|██████████| 46/46 [00:13<00:00, 3.37it/s, acc=0.749, loss=0.529]
Epoch 4: 100%|██████████| 109/109 [01:29<00:00, 1.22it/s, loss=0.518]
Epoch 4: 100%|██████████| 46/46 [00:13<00:00, 3.36it/s, acc=0.751, loss=0.523]
可以看到每轮Loss逐步下降,在验证集上的准确率逐步提升。
模型加载与测试
模型训练完成后,一般需要对模型进行测试或部署上线,此时需要加载已保存的最优模型(即checkpoint),供后续测试使用。这里我们直接使用MindSpore提供的Checkpoint加载和网络权重加载接口:1.将保存的模型Checkpoint加载到内存中,2.将Checkpoint加载至模型。
load_param_into_net接口会返回模型中没有和Checkpoint匹配的权重名,正确匹配时返回空列表。
param_dict = ms.load_checkpoint(ckpt_file_name)
ms.load_param_into_net(model, param_dict)
([], [])
对测试集打batch,然后使用evaluate方法进行评估,得到模型在测试集上的效果。
imdb_test = imdb_test.batch(64)
evaluate(model, imdb_test, loss_fn)
Epoch 0: 100%|█████████▉| 390/391 [01:29<00:00, 4.56it/s, acc=0.696, loss=0.575]\
\
Epoch 0: 100%|██████████| 391/391 [01:40<00:00, 3.88it/s, acc=0.696, loss=0.575]0.5750424911451462
自定义输入测试
最后我们设计一个预测函数,实现开头描述的效果,输入一句评价,获得评价的情感分类。具体包含以下步骤:
- 将输入句子进行分词;
- 使用词表获取对应的index id序列;
- index id序列转为Tensor;
- 送入模型获得预测结果;
- 打印输出预测结果。
具体实现如下:
score_map = {1: "Positive",0: "Negative"
}def predict_sentiment(model, vocab, sentence):model.set_train(False)tokenized = sentence.lower().split()indexed = vocab.tokens_to_ids(tokenized)tensor = ms.Tensor(indexed, ms.int32)tensor = tensor.expand_dims(0)prediction = model(tensor)return score_map[int(np.round(ops.sigmoid(prediction).asnumpy()))]
最后我们预测开头的样例,可以看到模型可以很好地将评价语句的情感进行分类。
predict_sentiment(model, vocab, "This film is terrible")
'Negative'
predict_sentiment(model, vocab, "This film is great")
'Positive'
相关文章:
昇思25天学习打卡营第19天 | RNN实现情感分类
RNN实现情感分类 概述 情感分类是自然语言处理中的经典任务,是典型的分类问题。本节使用MindSpore实现一个基于RNN网络的情感分类模型,实现如下的效果: 输入: This film is terrible 正确标签: Negative 预测标签: Negative输入: This fil…...

【VUE基础】VUE3第三节—核心语法之ref标签、props
ref标签 作用:用于注册模板引用。 用在普通DOM标签上,获取的是DOM节点。 用在组件标签上,获取的是组件实例对象。 用在普通DOM标签上: <template><div class"person"><h1 ref"title1">…...

生物化学笔记:电阻抗基础+电化学阻抗谱EIS+电化学系统频率响应分析
视频教程地址 引言 方法介绍 稳定:撤去扰动会到原始状态,反之不稳定,还有近似稳定的 阻抗谱图形(Nyquist和Bode图) 阻抗谱图形是用于分析电化学系统和材料的工具,主要有两种类型:Nyquist图和B…...

SQL使用join查询方式找出没有分类的电影id以及名称
系列文章目录 文章目录 系列文章目录前言 前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。 描述 现有电影信息…...

对MsgPack与JSON进行序列化的效率比较
序列化是将对象转换为字节流的过程,以便在内存或磁盘上存储。常见的序列化方法包括MsgPack和JSON。以下将详细探讨MsgPack和JSON在序列化效率方面的差异。 1. MsgPack的效率: 优点: 高压缩率: MsgPack采用高效的二进制编码格式&…...

Unix\Linux 执行shell报错:“$‘\r‘: 未找到命令” 解决
linux执行脚本sh xxx.sh报错:$xxx\r: 未找到命令 原因:shell脚本在Windows编写导致的换行问题: Windows 的换行符号为 CRLF(\r\n),而 Unix\Linux 为 LF(\n)。 缩写全称ASCII转义说…...

动态路由--RIP配置(思科cisco)
一、简介 RIP协议(Routing Information Protocol,路由信息协议)是一种基于距离矢量的动态路由选择协议。 在RIP协议中,如果路由器A和网络B直接相连,那么路由器A到网络B的距离被定义为1跳。若从路由器A出发到达网络B需要…...

python - 函数 / 字典 / 集合
一.函数 形参和实参: >>> def MyFirstFunction(name): 函数定义过程中的name是叫形参 ... print(传递进来的 name 叫做实参,因为Ta是具体的参数值!) print前面要加缩进tab,否则会出错。 >>> MyFirstFun…...

connect to github中personal access token生成token方法
一、问题 执行git push时弹出以下提示框 二、解决方法 去github官网生成Token,步骤如下 选择要授予此 令牌token 的 范围 或 权限 要使用 token 从命令行访问仓库,请选择 repo 。 要使用 token 从命令行删除仓库,请选择 delete_repo 其他根…...
Appium启动APP时报错Security exception: Permission Denial
报错内容Security exception: Permission Denial: starting Intent 直接通过am命令尝试也是同样的报错 查阅资料了解到:android:exported | App quality | Android Developers exported属性默认false,所以android:exported"false"修改为t…...

ubuntu22 使用ufw防火墙
专栏总目录 一、安装 sudo apt update sudo apt install ufw 二、启动防火墙 (一)启动命令 sudo ufw enable (二)重启命令 sudo ufw reload 三、配置规则 #允许SSH连接 sudo ufw allow ssh #如果sshd服务端口指定到了8888&a…...

初识STM32:开发方式及环境
STM32的编程模型 假如使用C语言的方式写了一段程序,这段程序首先会被烧录到芯片当中(Flash存储器中),Flash存储器中的程序会逐条的进入CPU里面去执行。 CPU相当于人的一个大脑,虽然能执行运算和执行指令,…...

详解Amivest 流动性比率
详解Amivest 流动性比率 Claude-3.5-Sonnet Poe Amivest流动性比率是一个衡量证券市场流动性的重要指标。这个比率主要用于评估在不对价格造成重大影响的情况下,市场能够吸收多少交易量。以下是对Amivest流动性比率的详细解释: 定义: Amivest流动性比率是交易额与绝对收益率的…...

pycharm小游戏制作
以下是一个使用 Python 和 PyGame库在 PyCharm中创建一个简单的小游戏(贪吃蛇游戏)的示例代码,希望对您有所帮助: import pygame import random# 基础设置 # 屏幕高度 SCREEN_HEIGHT 480 # 屏幕宽度 SCREEN_WIDTH 600 # 小方格…...

昇思11天
基于 MindSpore 实现 BERT 对话情绪识别 BERT模型概述 BERT(Bidirectional Encoder Representations from Transformers)是由Google于2018年开发并发布的一种新型语言模型。BERT在许多自然语言处理(NLP)任务中发挥着重要作用&am…...

AI绘画Stable Diffusion【图生图教程】:图片高清修复的三种方案详解,你一定能用上!(附资料)
大家好,我是画画的小强 今天给大家分享一下用AI绘画Stable Diffusion 进行 高清修复(Hi-Res Fix),这是用于提升图像分辨率和细节的技术。在生成图像时,初始的低分辨率图像会通过放大算法和细节增强技术被转换为高分辨…...

适用于Mac和Windows的最佳iPhone恢复软件
本文将指导您选择一款出色的iPhone数据恢复软件来检索您的宝贵数据。 市场上有许多所谓的iPhone恢复程序。各种程序很难选择并选择其中之一。一旦您做出了错误的选择,您的数据就会有风险。 最好的iPhone数据恢复软件应包含以下功能。 1.安全可靠。 2.恢复成功率高…...

64.ThreadLocal造成的内存泄漏
内存泄漏 程序中已动态分配的堆内存,由于某种原因程序为释放和无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。内存泄漏的堆积终将导致内存溢出。 内存溢出 没有足够的内存提供申请者使用。 ThreadLocal出现内存泄漏的真实原因 内存泄漏的发…...
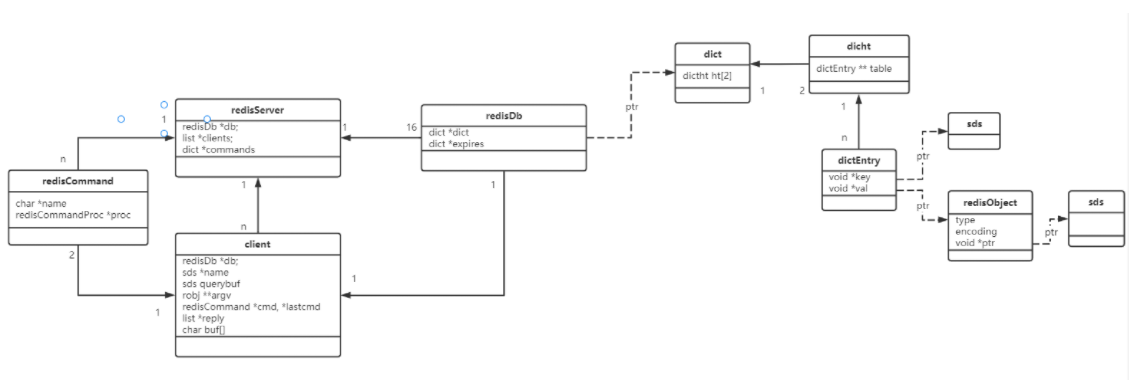
深入刨析Redis存储技术设计艺术(二)
三、Redis主存储 3.1、存储相关结构体 redisServer:服务器 server.h struct redisServer { /* General */ pid_t pid; /* Main process pid. */ pthread_t main_thread_id; /* Main thread id */ char *configfile; /* Absolut…...

python读取写入txt文本文件
读取 txt 文件 def read_txt_file(file_path):"""读取文本文件的内容:param file_path: 文本文件的路径:return: 文件内容"""try:with open(file_path, r, encodingutf-8) as file:content file.read()return contentexcept FileNotFoundError…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...
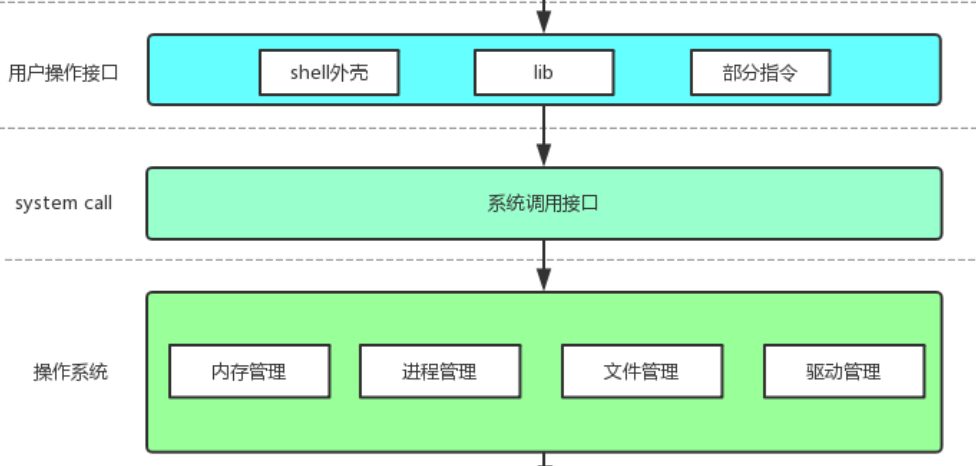
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...