python小练习04
三国演义词频统计与词云图绘制
import jieba
import wordcloud
def analysis():txt = open("三国演义.txt",'r',encoding='utf-8').read()words = jieba.lcut(txt)#精确模式counts = {}for word in words:if len(word) == 1:continueelif word =="诸葛亮" or word == "孔明曰":rword = "孔明"elif word == "关公" or word == "云长":rword = "关羽"elif word == "玄德" or word == "玄德曰":rword = "刘备"elif word == "孟德" or word == "丞相曰":rword = "曹操"elif word == "翼德" or word == "翼德曰":rword = "张飞"else:rword =wordcounts[rword] = counts.get(rword,0)+1items = list(counts.items())items.sort(key=lambda x :x[1],reverse=True)txt1 = ''for i in range(10):word,count = items[i]#注意这是一个二维列表print("{0:<10}{1:>5}".format(word,count))analysis()
# GovRptWordCloudV1.py
f = open("三国演义.txt", "r", encoding="utf-8")
txt = f.read()
f.close()
ls = jieba.lcut(txt) # 分词
length = len(ls)
number = 0
for i in range(length): # 筛选一个字的分词并去掉它if len(ls[i - number]) == 1:del ls[i - number]number += 1else:continue
ls = " ".join(ls) # 添加空格分隔符
w = wordcloud.WordCloud(font_path="msyh.ttc", \width=1000, \height=700, \background_color="white", \max_words=100)
w.generate(ls)
w.to_file("三国演义.png")


分析:主要功能是对《三国演义》文本进行中文分词和词频统计,并生成词云图。以下是代码的主要步骤:
import jieba 和 import wordcloud:引入了jieba库用于中文分词,wordcloud库用于生成词云图片。
def analysis() 定义了一个函数,该函数执行以下操作:
a. 读取文件 “三国演义.txt” 并使用UTF-8编码。
b. 使用jieba库的 lcut() 函数对文本进行精确模式的分词,并将结果存储在变量 words 中。
c. 遍历分词结果,对特定人物名字进行替换(如诸葛亮、曹操等),并将计数存入字典 counts。
d. 将字典中的词频按降序排序,并打印出前10个最常见的词语及其频率。
在函数外部,打开文本文件,再次分词并筛选掉单个字符的词语,然后使用 WordCloud 类创建词云图,设置参数后保存为 “三国演义.png” 图片。
雷达图绘制
mport numpy as np
import matplotlib.pyplot as plt
import matplotlib
labels = np.array(['X','KDA','Survival','Damage percentage','Participation rate','Damage_conversion_rate','Injury proportion','Average damage distribution'])
nAttr = 7
data = np.array([7.5,5.0,8.0,6.5,9.0,7.0,5.5])
angles = np.linspace(0,2 * np.pi,nAttr,endpoint = False)
data = np.concatenate((data,[data[0]]))
angles = np.concatenate((angles,[angles[0]]))
fig = plt.figure(facecolor = "white")
plt.subplot(111,polar = True)
plt.plot(angles,data,'bo-',color = 'b',linewidth = 2)
plt.fill(angles,data,facecolor = 'b',alpha = 0.25)
plt.thetagrids(angles*180/np.pi,labels)
plt.grid(True)
plt.savefig('6.2.jpg')
plt.show()
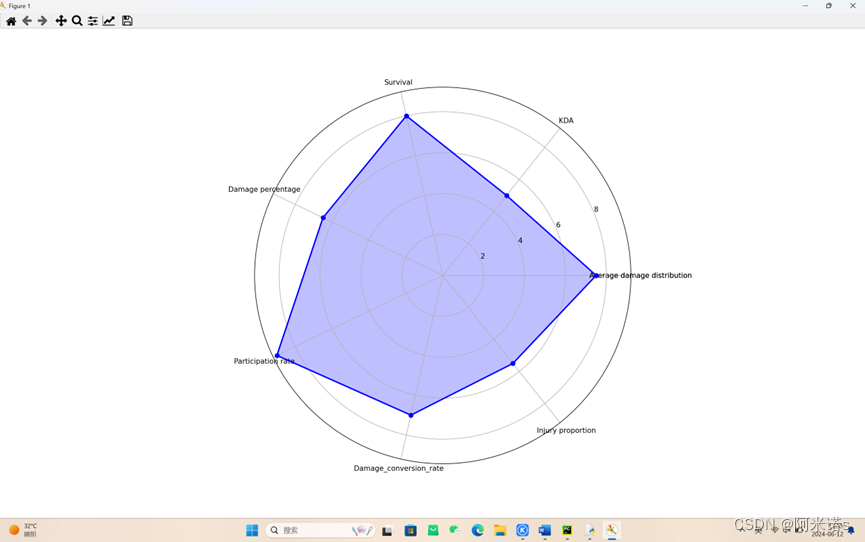
分析:
import numpy as np 和 import matplotlib.pyplot as plt:导入了numpy和matplotlib.pyplot模块,numpy用于数值计算,matplotlib.pyplot用于创建图形。
import matplotlib:这个导入通常是为了使用matplotlib的全部功能,包括颜色、字体等配置。
Labels=np.array(['X','KDA','Survival','Damagepercentage','Participationrate','Damage_conversion_rate','Injuryproportion','Averagedamagedistribution']):定义了一个包含数据标签的数组,表示饼图的各个部分。
nAttr = 7:设置饼图有7个部分。
data = np.array([7.5,5.0,8.0,6.5,9.0,7.0,5.5]):定义了每个部分的数据值。
angles = np.linspace(0, 2 * np.pi, nAttr, endpoint=False):生成一个从0到2π的等分数组,用作饼图的角度。
data = np.concatenate((data,[data])) 和 angles = np.concatenate((angles,[angles])):添加一个完整的圈作为饼图的开始和结束,这样看起来更自然。
fig = plt.figure(facecolor="white"):创建一个新的图形窗口,背景色设为白色。
plt.subplot(111, polar=True):设置子图类型为极坐标,创建一个饼图。
plt.plot(angles,data,'bo-',color='b', linewidth=2):绘制实际的饼图,蓝色圆点连接线。
plt.fill(angles,data,facecolor='b',alpha=0.25):填充饼图区域,带有一定的透明度。
plt.thetagrids(angles * 180 / np.pi, labels):在角度上添加标签,将角度单位从弧度转换为度数。
plt.grid(True):添加网格线。
plt.savefig('6.2.jpg'):保存图像到名为"6.2.jpg"的文件。
plt.show():最后显示创建的图形。
爬取百度翻译结果
题目:
用python实现输入英文单词,爬取百度翻译对此单词的翻译结果并输出
示例:

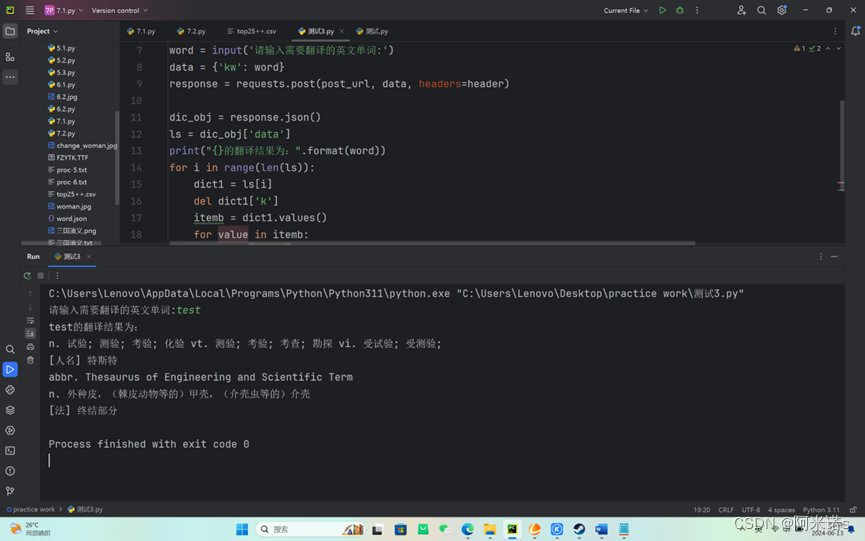
import requestspost_url = 'https://fanyi.baidu.com/sug'
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}word = input('请输入需要翻译的英文单词:')
data = {'kw': word}
response = requests.post(post_url, data, headers=header)dic_obj = response.json()
ls = dic_obj['data']
print("{}的翻译结果为:".format(word))
for i in range(len(ls)):dict1 = ls[i]del dict1['k']itemb = dict1.values()for value in itemb:print(value)
分析:使用了requests模块来实现的功能是发送一个POST请求到百度翻译的API接口(fanyi.baidu.com),post_url 是你想要发送请求的目标网址,这里是百度翻译的搜索服务地址。header 定义了一个HTTP头部,包含User-Agent信息,模拟浏览器客户端以避免被服务端识别为机器人并限制访问。
word 是用户输入的需要翻译的单词。data 是要发送的数据,这里包含关键字kw及其值。response = requests.post(post_url, data, headers=header) 这行代码执行实际的POST请求,并将结果存储在response变量中。response.json() 将接收到的HTTP响应转化为JSON格式的数据。dic_obj['data'] 是从JSON数据中提取出的翻译建议列表。
循环遍历ls(list of dictionaries),去掉每个字典中的键’k’,然后打印剩余的值(翻译结果)。
爬取豆瓣电影网址Top250的前25电影的各种信息并写入csv
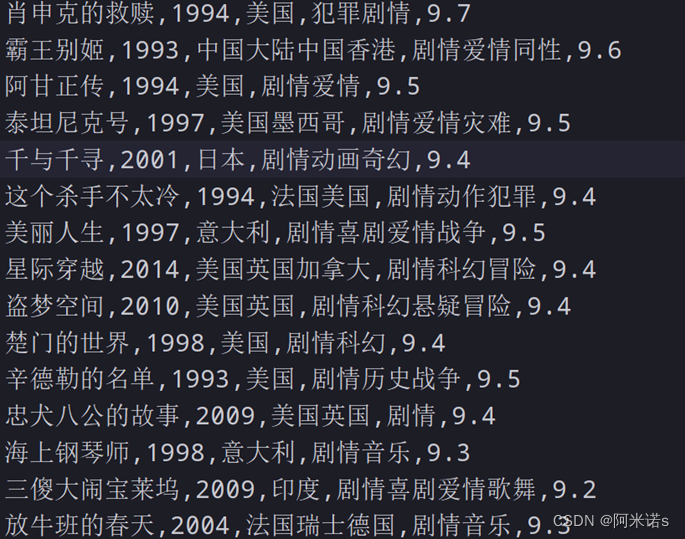
将其电影名称、电影信息以及电影评分写入名为Top25.csv文件中,
电影名称,电影信息以及电影评分三者用“,”隔开(csv文件格式)
示例:
#豆瓣前25电影:名称+时间+国家+类型+评分
import requests
from bs4 import BeautifulSoupf1 = open("top25++.csv",'w+',encoding='utf-8')
head = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}#把爬虫程序伪装成用户
response = requests.get("http://movie.douban.com/top250",headers= head )
html = response.text
soup = BeautifulSoup(html,"html.parser")
items = soup.find_all('div', class_='item')
articles = []
for item in items:title = item.find('span', class_='title').textactors = item.find('div', class_='bd').p.text.split()rating = item.find('span', class_='rating_num').textfor i in range(len(actors)):if ord('1') <= ord(actors[i][0]) <= ord('9'):actors = actors[i::]breakelse:continueyear = actors[0]flag1 = actors.index('/')flag2 = actors.index('/',flag1+1,-1)if flag1+2 == flag2:country = actors[flag1+1]else:country = actors[flag1+1:flag2-1]types = actors[flag2+1::]information = str(title)+','+str(year)+','+str(''.join(country))+','+str(''.join(types))+','+str(rating)articles.append(information+'\n')
f1.writelines(articles)
f1.close()
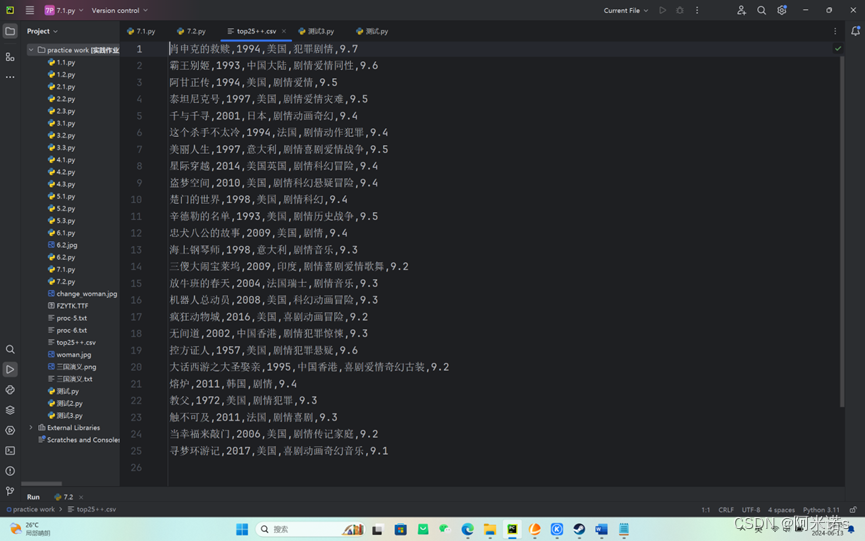
分析:定义了请求头(User-Agent),用来模拟浏览器访问,防止被网站识别为爬虫。使用requests库发送GET请求到豆瓣电影Top 250的URL,并获取响应内容。
使用BeautifulSoup库解析HTML响应,找到包含电影信息的<div>元素,它们具有class='item'的CSS选择器。遍历每个电影条目,提取电影标题、演员(包括年份、国家和类型)、评分等信息。标题:使用span元素的class_='title'查找。年份、国家和类型:通过查找div元素内的文本并根据特定字符分割来提取。评分:使用span元素的class_='rating_num'查找。将提取的信息整理成字符串,格式化为CSV行,然后添加到articles列表中。最后将所有文章写入CSV文件f1,关闭文件。
相关文章:
python小练习04
三国演义词频统计与词云图绘制 import jieba import wordcloud def analysis():txt open("三国演义.txt",r,encodingutf-8).read()words jieba.lcut(txt)#精确模式counts {}for word in words:if len(word) 1:continueelif word "诸葛亮" or word &q…...

小试牛刀-Solana合约账户详解
目录 一.Solana 三.账户详解 3.1 程序账户 3.2 系统所有账户 3.3 程序派生账户(PDA) 3.4 Token账户 四、相关学习文档 五、在线编辑器 Welcome to Code Blocks blog 本篇文章主要介绍了 [Solana合约账户详解] ❤博主广交技术好友,喜欢文章的可以关注一下❤ …...

Spring Boot+Vue项目从零入手
Spring BootVue项目从零入手 一、前期准备 在搭建spring bootvue项目前,我们首先要准备好开发环境,所需相关环境和软件如下: 1、node.js 检测安装成功的方法:node -v 2、vue 检测安装成功的方法:vue -V 3、Visu…...

Vue+Xterm.js+WebSocket+JSch实现Web Shell终端
一、需求 在系统中使用Web Shell连接集群的登录节点 二、实现 前端使用Vue,WebSocket实现前后端通信,后端使用JSch ssh通讯包。 1. 前端核心代码 <template><div class"shell-container"><div id"shell"/>&l…...

用 adb 来模拟手机插上电源和拔掉电源的情形
实用的 ADB 命令 要模拟手机从 USB 充电器上拔掉的情形,你可以使用: adb shell dumpsys battery set usb 0或者,如果你使用的是 Android 6.0 或更高版本的设备,你可以使用: adb shell dumpsys battery unplug要重新…...
【SPIE独立出版】第四届智能交通系统与智慧城市国际学术会议(ITSSC 2024)
第四届智能交通系统与智慧城市国际学术会议(ITSSC 2024)将于2024年8月23-25日在中国西安举行。本次会议主要围绕智能交通、交通新能源、无人驾驶、智慧城市、智能家居、智能生活等研究领域展开讨论, 旨在为该研究领域的专家学者们提供一个分享…...

【Unity数据交互】如何Unity中读取Ecxel中的数据
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 专栏交流🧧&…...

基于深度学习LightWeight的人体姿态检测跌倒系统源码
一. LightWeight概述 light weight openpose是openpose的简化版本,使用了openpose的大体流程。 Light weight openpose和openpose的区别是: a 前者使用的是Mobilenet V1(到conv5_5),后者使用的是Vgg19(前10…...
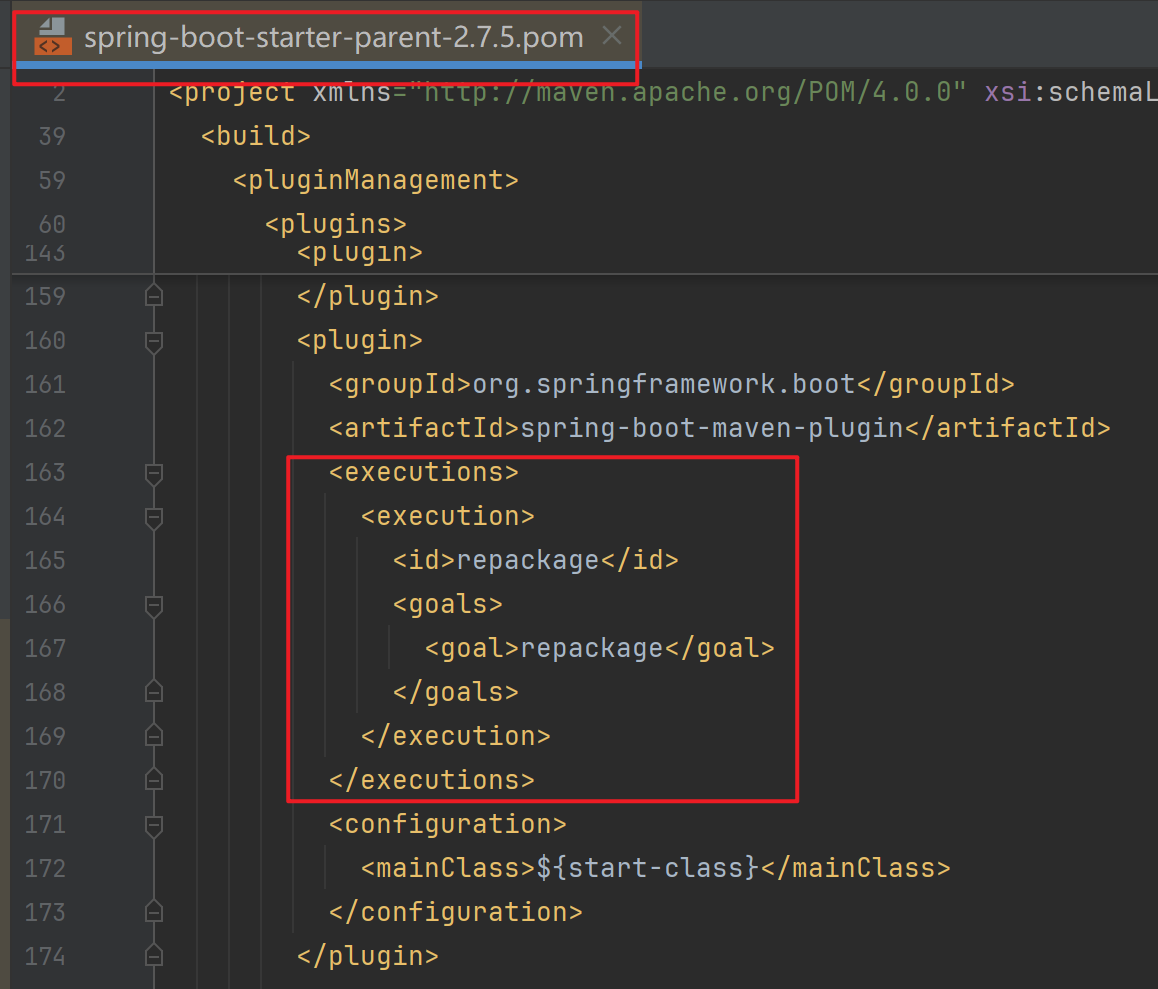
SpringBoot 生产实践:没有父 starter 的打包问题
文章目录 前言一、搜索引擎二、Chat GPT三、官方文档四、小结推荐阅读 前言 今天刚准备写点文章,需要 SpringBoot 项目来演示效果。一时心血来潮,没有采用传统的方式(即通过引入 spring-boot-starter-parent 父工程的方式)。 &l…...

IDEA配Git
目录 前言 1.创建Git仓库,获得可提交渠道 2.选择本地提交的项目名 3.配置远程仓库的地址 4.新增远程仓库地址 5.开始进行commit操作 6.push由于邮箱问题被拒绝的解决方法: 后记 前言 以下操作都是基于你已经下载了Git的前提下进行的,…...
51单片机STC89C52RC——14.1 直流电机调速
目录 目的/效果 1:电机转速同步LED呼吸灯 2 通过独立按键 控制直流电机转速。 一,STC单片机模块 二,直流电机 2.1 简介 2.2 驱动电路 2.2.1 大功率器件直接驱动 2.2.2 H桥驱动 正转 反转 2.2.3 ULN2003D 引脚、电路 2.3 PWM&…...

AI对于高考和IT行业的深远影响
目录 AI对IT行业的冲击及深远影响1. 工作自动化2. 新的就业机会3. 行业融合4. 技术升级和创新5. 数据的重要性 IT行业的冬天要持续多久?大学的软件开发类专业是否还值得报考?其他问题IT行业是否都是加班严重?35岁后就业困难是否普遍现象&…...

C语言下的文件详解
主要内容 文件概述文件指针文件的打开与关闭文件的读写 文件 把输入和输出的数据以文件的形式保存在计算机的外存储器上,可以确保数据能随时使用,避免反复输入和读取数据 文件概述 文件是指一组相关数据的有序集合 文件是存储数据的基本单位&#…...

Oracle PL / SQL块结构
在PL / SQL中,最小的有意义的代码分组被称为块。 块代码为变量声明和异常处理提供执行和作用域边界。 PL / SQL允许您创建匿名块和命名块。 命名块可以是包,过程,函数,触发器或对象类型。 PL / SQL是SQL的过程语言扩展&#x…...

MySQL的安装和启动
安装 版本 1,社区版:免费,不提供任何技术支持 2,商业版:可以试用30天,官方提供技术支持下载 1,下载地址:https://dev.mysql.com/downloads/mysql/ 2,安装:傻…...

Prometheus概述
1.什么是prometheus Prometheus 是一个开源的服务监控系统和时序数据库,其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件Prometheus server会定期从静态配置的监控目标或者基于服务发现自动配置的自标中进行拉取数据,当新拉取到的…...

【SQL】什么是最左前缀原则/最左匹配原则
最左前缀原则(或最左匹配原则)是关系型数据库在使用复合索引时遵循的一条重要规则。该原则指的是,当查询条件使用复合索引时,查询优化器会首先使用索引的最左边的列,依次向右匹配,直到不再满足查询条件为止…...

java项目配置logback日志
在resource目录下添加logback配置文件 <?xml version"1.0" encoding"UTF-8"?> <configuration scan"true" scanPeriod"60 seconds" debug"false"><property name"log_dir" value"/APL/log…...

Python入门 2024/7/6
目录 元组的定义和操作 字符串的定义和操作 字符串 字符串的替换 字符串的分割 字符串的规整操作(去除前后空格) 字符串的规整操作(去掉前后指定字符串) 操作 字符串的替换 字符串的分割 字符串的规整操作 统计字符串的…...

ChatGPT4深度解析:探索智能对话新境界
大模型chatgpt4分析功能初探 目录 1、探测目的 2、目标变量分析 3、特征缺失率处理 4、特征描述性分析 5、异常值分析 6、相关性分析 7、高阶特征挖掘 1、探测目的 1、分析chat4的数据分析能力,提高部门人效 2、给数据挖掘提供思路 3、原始数据…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...