Linux内核的启动过程(非常详细)零基础入门到精通,收藏这一篇就够了
Linux内核的生成过程
内核的生成步骤可以概括如下:
① 先生成 vmlinux,这是一个elf可执行文件。② 然后 objcopy 成 arch/i386/boot/compressed/vmlinux.bin,去掉了原 elf 文件中一些无用的section等信息。③ gzip 后压缩为 arch/i386/boot/compressed/vmlinux.bin.gz。④ 把压缩文件作为数据段链接成 arch/i386/boot/compressed/piggy.o。⑤ 链接:arch/i386/boot/compressed/vmlinux = head.o+misc.o+piggy.o ,其中 head.o 和 misc.o 是用来解压缩的。⑥ objcopy 成 arch/i386/boot/vmlinux.bin,去掉了原 elf 文件中一些无用的 section等信息。⑦ 用 arch/i386/boot/tools/build.c 工具拼接 bzImage = bootsect+setup+vmlinux.bin。
想要探寻Linux内核的启动,可以先从一个普通的用户态C程序的启动来入手。
C语言程序是如何启动并运行的
首先写一个最简单的C程序 test.c
1 #include <stdio.h\> 2 3 int main() 4 { 5 printf("hello world ...\\n"); 6 return 0; 7 }
我们都知道,C程序的入口时 main 函数,那么下面来深入探索一下为什么是 main 函数,首先使用 gcc 生成可执行文件
gcc test.c \-o test

通过 file 命令我们可以查看到,生成的test是一个 ELF 格式的文件,具体来说是一个x86平台上的64位可执行文件。
使用 objdump 命令对该执行文件反汇编

查看反汇编代码,我们发现汇编代码中多出了很多函数,比如 _strart 函数等,这说明gcc在链接时链接了一些库。

我们重新使用gcc编译一下test.c文件,并显示出编译过程
gcc \-v test.c \-o test

我们可以看到,在编译链接过程中,链接了 /usr/lib/… 下的 crti.o crt1.o 等文件,而刚才提到的 _strart 函数就定义在 crt1.o 文件中。
使用 readelf 命令查看 elf 文件头,section table 和各section信息。

在 ELF Header 中可以看到 Entry point address 一行,也就是程序的入口地址。通过这个信息可以知道,test程序的真正入口地址是0x400440,我们在查看一下反汇编代码

可以看到0x400440地址处正是 _strart 函数。
由此可知,_start 函数才是test程序首先执行的函数,该函数执行完一系列初始化等工作后,经过层层调用,最终调用main()函数。因此,在我们的C程序中,main()函数时开始执行的入口。

_strart调用了__libc_start_main@plt,同样,后面是层层调用的过程到达main()函数。
现在,我们搞明白了为什么main()函数是C程序的入口了,那么test程序具体是如何执行的呢。我们可以通过 strace 跟踪test的执行过程。
strace ./test

可以看到很多函数调用。第一个调用是 execve() 函数,这是一个关键的系统调用,它负责载入test可执行文件并运行。其中最关键的一步就是把用户态的 eip 寄存器(实际上是它在内存中对应的值)设置为elf文件中的入口点址,也就是 _start() 函数。
由此可见,程序从哪里开始执行,取决于在刚开始执行的那一刻 eip 寄存器的值。而这个 eip 是由Linux内核设置的。具体过程如下:① 用户在shell里运行 ./test ;② shell(这里是bash)调用系统调用execve();③ execve() 陷入内核执行 sys_execve(),把用户态的eip设置为_start();
④ 当系统调用执行完毕,test进程开始运行时,就从_start()开始执行;⑤ test进程执行main();
BIOS、MBR、GRUB、setup
通过上面用户态C程序的启动,我们可以看出,程序真正的入口是 _strart ,而main()只是因为被调用了,所以才被看做是C程序的入口,main只是一个符号,如果 _strart 中调用的不是main,那么C程序的入口就不是main了。
同理,内核的真正入口也并不是 strart_kernel() ,真正决定程序执行入口的是载入程序。对于用户态的C程序test来说,Linux内核或者说bash负责设置test的入口点,并且启动执行test程序。
那么谁来启动Linux内核呢,基于KISS(keep it simple and stupid)原则,一个简单的思路就是用一个更简单的内核(或者说一段程序)来启动真正的内核,也就是BIOS(basic input/output system),BIOS通常存储在ROM上。
PC机器刚启动时,x86 CPU 会自动从BIOS开始启动,这是由硬件决定的。刚加电时,寄存器CS里面的值是0xffff,IP寄存器值为0,于是CPU会从0xffff0处开始取指令,通过下面命令可以看到,0xffff0地址位于 System ROM 中,也就是我们的BIOS。

BIOS通过 POST(Power On Self Test,加电自检) 来加载硬件信息,进行内存、CPU、主板等检测,如果硬件设备正常工作,BIOS会寻找硬盘第一个扇区(引导扇区MBR)中存储的数据(512字节),并使用MBR中的数据激活引导加载程序。这就是BIOS的作用,后面的工作将有其它程序负责。
在x86平台上,有两种保护模式,32位页式寻址的保护模式和32位段式寻址的保护模式。32位页式寻址的保护模式要求系统中已经构造好页表。从16位实地址模式直接到32位页式寻址的保护模式是很有难度的,因为要在16位实地址模式下构造页表。所以不妨这样来做,先从16位实地址模式跳到32位段式寻址的保护模式,再从32位段式寻址的保护模式跳到32位页式寻址的保护模式。也就是说,我们需要这样一个程序,负责从16位实地址模式跳到32位段式寻址的保护模式,然后设置eip,启动内核。这个程序就是 arch/i386/boot/setup.S。最后它汇编成setup程序。

事实上,平时所见的压缩内核映象 bzImage 是由三部分组成的。可以从 arch/i386/boot/tools/build.c 中看到。build.c是用户态工具build的源代码,后者用来把 bootsect(MBR),setup辅助程序和vmlinux.bin(压缩过的内核) 拼接成 bzImage。现在有了负责启动内核的setup程序,但是谁来启动setup呢。因为MBR只有512个字节,而且有64个字节来存放主分区表,它的功能是非常有限的。所以,还需要在setup和MBR之间再架一座桥梁。这就是引导程序,引导程序用来引导setup程序。现有的引导程序如grub,lilo不仅功能强大,而且还提供了人机交互的功能。
这样,我们就可以归纳出来一系列流程如下:
① CPU加电,从0xffff0处,执行BIOS(可以理解为“硬件”引导BIOS)。② BIOS执行扫描检测设备的操作,然后将MBR读到物理地址为0x7c00处,然后从MBR头部开始执行(可以理解为BIOS引导MBR)。③ MBR上的代码跳转到引导程序,开始执行引导程序的代码,例如grub(引以理解为BIOS引导boot loader)。④ 引导程序把内核映象(包括bootsect,setup,vmlinux)读到内存中,其中setup位于0x90200处,如果是zImage,则vmlinux.bin位于0x10000(64K)处。如果是bzImage,则vmlinux.bin位于0x100000(1M)处。然后执行setup(可以理解为boot loader引导setup)。⑤ setup负责引导linux内核vmlinux.bin。
BIOS ——> MBR ——> boot loader ——> setup ——> kernel ——> init
下面介绍下上面的这些名词都是什么含义。
BIOS加电自检
-
BIOS全称 Basic Input/Output System,即基本输入输出系统,它是一个被永久刻录在ROM中的软件,加电自检是指 Power On Self Test,POST,属于BIOS的主要组成部分。
-
计算机在接通电源后,BIOS通过POST来加载硬件信息,进行内存、CPU、主板等检测,如果硬件设备正常工作,BIOS会寻找硬盘第一个扇区中存储的数据,并使用MBR中的数据激活引导加载程序。
MBR系统引导
第一个扇区(512字节)称为主引导记录。主引导记录分为3部分,前446byte是引导信息,后64byte是磁盘分区信息,最后2byte是标志位。MBR的作用是找到 boot loader 。
-
MBR全程 Master Boot Recode,是一种磁盘分区格式,也是以此种格式的磁盘中0盘片0扇区中存储的一段记录——主引导记录。磁盘中扇区的大小为512byte,主引导记录MBR占据第一个扇区的前446字节,剩余的空间依次存储一个64字节的磁盘分区表,和一个用于标识MBR是否有效的2字节的模数。
-
主引导记录MBR中包含一个实现引导加载功能的程序——Boot Loader。由于BIOS只能访问很少量的数据,所以MBR中的引导加载程序其实只是一段初始程序的加载程序 Initial Program Loader,IPL,这段程序唯一的功能就是定位并加载 Boot Loader 的主体程序。
-
加载引导分为两个阶段
-
第一阶段,BIOS引导IPL获取 Boot Loader 主题程序在磁盘中的位置,此时系统启动的控制权由BIOS转移到MBR;
-
第二阶段,Boot Loader 主题程序与操作系统对应的内核,定位到内核文件所在的位置,并将其加载到计算机内存中,此时系统启动的控制权由MBR转移到内核。
GRUB
是一种 boot loader ,用于加载kernel核心信息。
kernel
内核。
init进程
内核的第一个程序,分为7个启动级别。
查看启动级别配置文件
cat /etc/inittab #查看启动级别相关的配置文件
inti命令可以切换系统的启动级别
inti 0/1/2/3/4/5/6
-
0表示关机(不能设置为开机默认启动级别)
-
1表示单用户
-
2表示多用户(无网络的3级别)
-
3多用户(命令行模式,字符终端)
-
4用于开发
-
5图形界面,默认启动方式
-
6reboot(不能设置为开机默认启动级别)
runlevel #查看系统的启动级别
vmlinux、vmlinuz、zImage、bzImage
vmlinuz是可引导的、压缩的内核,“vm"代表"Virtual Memory”。Linux 支持虚拟内存,不像老的操作系统比如DOS有640KB内存的限制。Linux能够使用硬盘空间作为虚拟内存,因此得名"vm"。vmlinuz是可执行的Linux内核,它位于 /boot/vmlinuz,它一般是一个软链接。vmlinuz的建立有两种方式。一是编译内核时通过"make zImage"创建,然后通过"cp /usr/src/linux-2.4/arch/i386/linux/boot/zImage /boot/vmlinuz"产生。zImage适用于小内核的情况,它的存在是为了向后的兼容性。二是内核编译时通过命令make bzImage创建,然后通过"cp /usr/src/linux-2.4/arch/i386/linux/boot/bzImage /boot/vmlinuz"产生。bzImage是压缩的内核映像,bz表示"big zImage"。zImage(vmlinuz)和bzImage(vmlinuz)都是用gzip压缩的。它们不仅是一个压缩文件,而且在这两个文件的开头部分内嵌有gzip解压缩代码。所以你不能用gunzip 或 gzip -dc解包vmlinuz。内核文件中包含一个微型的gzip用于解压缩内核并引导它。两者的不同之处在于,老的zImage解压缩内核到低端内存(第一个640K),bzImage解压缩内核到高端内存(1M以上)。如果内核比较小,那么可以采用zImage 或bzImage之一,两种方式引导的系统运行时是相同的。大的内核采用bzImage,不能采用zImage。vmlinux是未压缩的内核,vmlinuz是vmlinux的压缩文件。
vmlinux是一个包含 linux kernel 的静态链接的可执行文件,文件类型是linux接受的可执行文件格式之一(ELF、COFF或a.out)。
vmlinuz是可引导的,压缩的linux内核,“vm”代表的“virtual memory”。vmlinuz是vmlinux经过gzip和 objcopy(*) 制作出来的压缩文件。vmlinuz不仅是一个压缩文件,而且在文件的开头部分内嵌有gzip解压缩代码。

通过file命令可以看到自己的vmlinuz是bzImage。通过前面我们知道,zImage是vmlinuz经过gzip压缩后的文件,适用于小内核(512KB以内),加载到内存的开始640KB处。bzimage(not bzizp but big)是vmlinuz经过gzip压缩后的文件,适用于大内核。在zImage和bzImage都可以通过解压缩提取出vmlinux,只不过提取方法不同。
setup辅助程序
setup辅助程序主要进行了这些操纵,以zImage为例,首先把它从0x10000拷贝到0x1000,调用BIOS功能,查询硬件信息,然后放在内存中供将来的内核使用,然后建立临时的idt和gdt,负责把16位实地址模式转化为32位段式寻址的保护模式。
我们可以查看下 arch/i386/boot/setup.S 中的汇编代码

\# Note that the short jump isn't strictly needed, although there are
\# reasons why it might be a good idea. It won't hurt in any case. movw $1, %ax \# protected mode (PE) bit lmsw %ax \# This is it! jmp flush\_instr flush\_instr: xorw %bx, %bx \# Flag to indicate a boot xorl %esi, %esi \# Pointer to real-mode code movw %cs, %si subw $DELTA\_INITSEG, %si shll $4, %esi \# Convert to 32-bit pointer
\# NOTE: For high loaded big kernels we need a
# jmpi 0x100000,\_\_KERNEL\_CS
#
# but we yet haven't reloaded the CS register, so the default size
# of the target offset still is 16 bit.
\# However, using an operant prefix (0x66), the CPU will properly
# take our 48 bit far pointer. (INTeL 80386 Programmer's Reference
# Manual, Mixing 16-bit and 32-bit code, page 16-6) .byte 0x66, 0xea \# prefix + jmpi-opcode
code32: .long 0x1000 \# will be set to 0x100000 \# for big kernels .word \_\_KERNEL\_CS
x86处理器提供了特殊的手段来访问大于1M的内存,那就是在指令前加前缀0x66(具体可见上面程序块)。由于跳转地址与内核大小相关(zImage和bzImage不一样)所以用一个小技巧,即把该指令当作数据处理。在计算机看来,指令和数据是没什么区别的,只要ip寄存器指向内存中某地址,计算机就把地址中的数据当作指令来看待。
关于我们上面提到的所有包括test,vmlinux,arch/i386/boot/compressed/vmlinux,setup,bootsect有什么区别与联系呢。这几个可执行文件都是由gcc编译生成的,只是格式不一样。其中,test,vmlinux,arch/i386/boot/compressed/vmlinux都是elf32_i386格式的可执行文件;setup,bootsect是binary格式的可执行文件,它们的区别如下
-
text是普通的elf32_i386可执行文件,它的入口是 _start,运行在用户态空间,变量的地址都是32位页式寻址的保护模式的地址,存放在用户态空间,由shell负责装载。
-
vmlinux是未压缩的内核,它的入口是startup_32(0x100000,线性地址),运行在内核态空间,变量的地址是32位页式寻址的保护模式的地址,存放在内核态空间,由内核自解压后启动运行。
-
arch/i386/boot/compressed/vmlinux是压缩后的内核,它的入口地址是startup_32(0x100000,线性地址),运行在32位段式寻址的保护模式下,变量的地址是32位段式寻址的保护模式的地址,由setup启动运行。
-
setup是装载内核的binary格式的辅助程序,它的入口地址是begtext(偏移地址为0,运行时需要把cs段寄存器设置为0x9020),运行在16位实地址模式下。变量的地址等于相对于代码段起始地址的偏移地址。由boot loader启动运行。
-
bootsect是MBR上的引导程序,也为binary格式。它的入口地址是_start(),由于装载到0x7c00处,运行时需要把cs段寄存器设置为0x7c0。运行在16位实地址模式下。变量地址等于相对于代码段起始地址的偏移地址。由BIOS启动运行。
内核解压
在文件arch/i386/boot/compressed/head.S和arch/i386/kernel/head.S中都存在一个startup_32,那么这两个startup_32有什么区别呢,我们从内核的链接过程来看。
从内核的生成过程来看内核的链接主要有三步:第一步是把内核的源代码编译成 .o 文件,然后链接arch/i386/kernel/head.S,生成vmlinux。注意这里的所有变量地址都是32位页寻址方式保护模式下的虚拟地址,通常大小在3G以上。第二步将 vmlinux objcopy 成 arch/i386/boot/compressed/vmlinux.bin,然后压缩,最后作为数据编译成piggy.o。这时候,在编译器看来,piggy.o中还不存在startup_32。第三步,把 head.o,misc.o 和 piggy.o 链接生成 arch/i386/boot/compressed/vmlinux,这一步,链接的是arch/i386/boot/compressed/head.S。这时 arch/i386/kernel/head.S 中的 startup_32 被压缩,作为一段普通的数据,而被编译器忽视。这里的地址都是32位段寻址方式保护模式下的线性地址。setup执行完毕,跳转到vmlinux.bin中的startup_32()是arch/i386/boot/compressed/head.S中的startup_32()这是一段自解压程序,过程和内核生成的过程正好相反。这时,CPU处在32位段寻址方式的保护模式下,寻址范围从1M扩大到4G。只是没有页表。内核解压完毕。位于0x100000即1M处。最后,执行一条跳转指令,执行0x100000处的代码,即 arch/i386/kernel/head.S 中的startup_32()代码。
页面映射
通过setup辅助程序,现在从16位实地址模式过渡到了32位段式寻址保护模式。并且在 arch/i386/boot/compressed/head.S 帮助下实现了内核自解压,从arch/i386/kernel/head.S中的startup_32开始执行。现在,线性地址0x100000(1M) 处开始便是解压后的内核,而startup_32的地址也是0xa00000。但是现在还没有开启页面映射,所以必须引用变量的线性地址,也就是变量的虚拟地址-PAGE_OFFSET。要想解决这个问题,就要建立页表并开启页面映射。
在Linux中,每个进程都拥有一个页表,也就是说每个页表都对应着一个进程。通常情况下,Linux通过fork()系统调用复制原进程来产生一个新的进程,那么问题来了,第一个进程是怎么来的呢。实际上,第一个进程并不是复制出来的,它是以全局变量的方式制造出来的,即 init_thread_union,也就是我们所说的0号进程swapper。swapper进程运行后调用start_kernel(),整个程序就跑起来了。
有了第一个进程,还要为该进程建立页表。为保证可移植性,Linux采用了三级页表(但是x86处理器只使用两级页表),swapper的页表叫做swapper_pg_dir,在arch/i386/kernel/head.S中我们可以看到这样的代码
/\* \* This is initialized to create an identity-mapping at 0-8M (for bootup \* purposes) and another mapping of the 0-8M area at virtual address \* PAGE\_OFFSET. \*/
.org 0x1000
ENTRY(swapper\_pg\_dir) .long 0x00102007 .long 0x00103007 .fill BOOT\_USER\_PGD\_PTRS-2,4,0 /\* default: 766 entries \*/ .long 0x00102007 .long 0x00103007 /\* default: 254 entries \*/ .fill BOOT\_KERNEL\_PGD\_PTRS-2,4,0
这样,便建好了页目录,下面开始映射页表。我们知道,一个页目录最多可以映射1024个页表,每个页表可以映射4M虚拟地址,也就是说总共可以映射4G虚拟地址空间。
由于不同进程的用户空间相互独立,所以用户态进程的地址映射并不是连续的。但是,所有进程共享内核态代码和数据。内核态虚拟地址从3G开始,而内核代码和数据事实上是从物理地址0x100000开始,本着KISS原则,加上3G就作为对应的虚拟地址即可。由此可见,对内核态代码和数据来说:虚拟地址=物理地址+PAGE_OFFSET(3G)。
建表过程可见下面代码
/\* \* Initialize page tables \*/ movl $pg0-\_\_PAGE\_OFFSET,%edi /\* initialize page tables \*/ movl $007,%eax /\* "007" doesn't mean with right to kill, but PRESENT+RW+USER \*/
2: stosl add $0x1000,%eax cmp $empty\_zero\_page-\_\_PAGE\_OFFSET,%edi jne 2b
上面有一条注释 /* “007” doesn’t mean with right to kill, but PRESENT+RW+USER */,由于每个页表项有32位,但其实只需保存物理地址的高20位就够了,所以剩下的低12位可以用来表示页的属性。0x007正好表示PRESENT+RW+USER(在内存中,可读写,用户页面,这样在用户态和内核态都可读写,从而实现平滑过渡)。
下面就要开启分页功能。开启页面映射后,可以直接引用内核中的所有变量了。不过离start_kernel还有点距离,要启动swapper进程,得首先设置内核堆栈。看下面程序
/\* \* Enable paging 开启分页功能 \*/
3: movl $swapper\_pg\_dir-\_\_PAGE\_OFFSET,%eax movl %eax,%cr3 /\* set the page table pointer.. \*/ movl %cr0,%eax orl $0x80000000,%eax movl %eax,%cr0 /\* ..and set paging (PG) bit \*/ jmp 1f /\* flush the prefetch-queue \*/
1: movl $1f,%eax jmp \*%eax /\* make sure eip is relocated \*/
1: /\* Set up the stack pointer \*/ lss stack\_start,%esp #ifdef CONFIG\_SMP orw %bx,%bx jz 1f /\* Initial CPU cleans BSS \*/ pushl $0 popfl jmp checkCPUtype
1:
#endif CONFIG\_SMP
/\* \* start system 32-bit setup. We need to re-do some of the things done \* in 16-bit mode for the "real" operations. \*/ call setup\_idt
call SYMBOL\_NAME(start\_kernel)
链接脚本
在用户态,内核会解析elf可执行文件的各个section,并把它们映射到虚拟地址空间,这些都不需要用户关心。但是,在内核启动的时候,映射section等这些工作都必须要内核自己来完成。除此之外,内核还要负责对BSS段的变量进行初始化(一般会初始化为0),这些都需要内核知道section的具体位置。这就要求,存在那么一个文件来指定各个section的虚拟地址。在内核源码树中,arch/i386/kernel/vmlinux.lds.S 文件就是 linker scripts 连接器脚本。
在链接器脚本中,. 表示当前 location counter 地址计数器的值,默认为0。
#ifdef CONFIG\_X86\_32 . \= LOAD\_OFFSET + LOAD\_PHYSICAL\_ADDR; phys\_startup\_32 \= ABSOLUTE(startup\_32 - LOAD\_OFFSET);
#else . \= \_\_START\_KERNEL; phys\_startup\_64 \= ABSOLUTE(startup\_64 - LOAD\_OFFSET);
#endif
. = __START_KERNEL; 表示地址计数器从__KERNEL_START(0xc00100000) 开始。
下面代码描述了 .text section 包含了哪些section
/\* Text and read-only data \*/ .text : AT(ADDR(.text) - LOAD\_OFFSET) { \_text \= .; \_stext \= .; /\* bootstrapping code \*/ HEAD\_TEXT TEXT\_TEXT SCHED\_TEXT CPUIDLE\_TEXT LOCK\_TEXT KPROBES\_TEXT SOFTIRQENTRY\_TEXT
#ifdef CONFIG\_RETPOLINE \_\_indirect\_thunk\_start \= .; \*(.text.\_\_x86.\*) \_\_indirect\_thunk\_end \= .;
#endif STATIC\_CALL\_TEXT ALIGN\_ENTRY\_TEXT\_BEGIN ENTRY\_TEXT ALIGN\_ENTRY\_TEXT\_END \*(.gnu.warning) } :text \=0xcccc
. = ALIGN(PAGE_SIZE); 表示对齐方式。
链接器脚本指定了各个section的起始位置和结束位置。它还允许程序员在脚本中对变量进行赋值。这使内核可以通过 __initcall_start 和 __initcall_end之类的变量获得段的起始地址和结束地址,从而对某些段进行操作。
下面是两个比较重要的section:
-
bss section,存放在代码里未初始化的全局变量,最后初始化为0。
-
init sections,所有只在初始化时调用的函数和变量,包括所有在内核启动时调用的函数,以及内核模块初始化时调用的函数。其中最特别的是.initcall .init section。通过__initcall_start和__initcall_end,内核可以调用里面所有的函数。这些section在使用一次后就可以释放,从而节省内存。
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
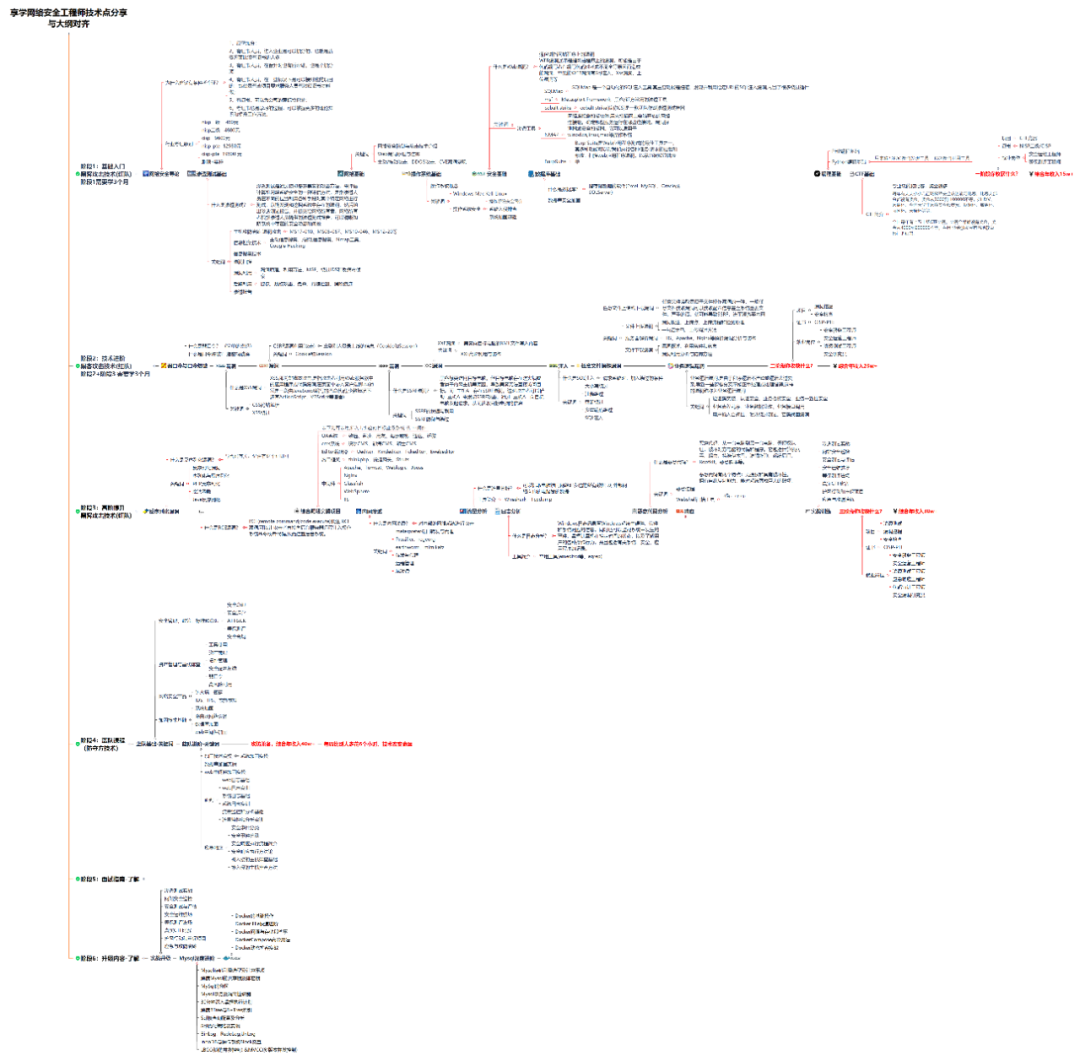
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
相关文章:
Linux内核的启动过程(非常详细)零基础入门到精通,收藏这一篇就够了
Linux内核的生成过程 内核的生成步骤可以概括如下: ① 先生成 vmlinux,这是一个elf可执行文件。② 然后 objcopy 成 arch/i386/boot/compressed/vmlinux.bin,去掉了原 elf 文件中一些无用的section等信息。③ gzip 后压缩为 arch/i386/boot…...

相关分析 - 肯德尔系数
肯德尔系数(Kendall’s Tau)是一种非参数统计方法,用于衡量两个变量之间的相关性。它是由统计学家莫里斯肯德尔(Maurice Kendall)在1938年提出的。肯德尔系数特别适用于有序数据,可以用来评估两个有序变量之…...

【咨询】企业数字档案馆(室)建设方案-模版范例
导读:本模版来源某国有大型医药行业集团企业数字档案馆(室)建设方案(一期300W、二期250W),本人作为方案的主要参与者,总结其中要点给大家参考。 目录 1、一级提纲总览 2、项目概述 3、总体规…...

selfClass 与 superClass 的区别
在 Objective-C 中,[self class] 和 [super class] 都用于获取对象的类信息,但它们在运行时的行为略有不同。理解它们的区别有助于更好地掌握 Objective-C 的消息传递机制和继承关系。让我们详细解释这两个调用的区别。 [self class] 当你在一个对象方…...
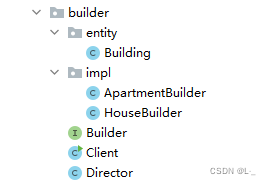
秒懂设计模式--学习笔记(6)【创建篇-建造者模式】
目录 5、建造者模式5.1 介绍5.2 建造步骤的重要性5.3 地产开发商的困惑5.4 建筑施工方5.5 工程总监5.6 项目实施5.7 建造者模式的各角色定义5.8 建造者模式 5、建造者模式 5.1 介绍 建造者模式(Builder)又称为生成器模式,主要用于对复杂对象…...
领略超越王勃的AI颂扬艺术:一睹其惊艳夸赞风采
今日,咱也用国产AI技术,文心一言3.5的文字生成与可灵的图像创作,自动生成一篇文章,提示语文章末下载。 【玄武剑颂星际墨侠】 苍穹为布,星辰织锦,世间万象,皆入我玄武剑公众号之浩瀚画卷。此号…...

Linux走进网络
走进网络之网络解析 目录 走进网络之网络解析 一、认识计算机 1.计算机的发展 2.传输介质 3.客户端与服务器端的概念 交换机 路由器 二、计算机通信与协议 1. 协议的标准化 2. 数据包的传输过程 OSI 协议 ARP协议 3. TCP/IP:四层模型 4. TCP三次握手和四次挥手…...

go语言Gin框架的学习路线(六)
gin的路由器 Gin 是一个用 Go (Golang) 编写的 Web 框架,以其高性能和快速路由能力而闻名。在 Gin 中,路由器是框架的核心组件之一,负责处理 HTTP 请求并将其映射到相应的处理函数上。 以下是 Gin 路由器的一些关键特性和工作原理的简要解释…...

Java面经知识点汇总版
Java面经知识点汇总版 算法 14. 最长公共前缀(写出来即可) Java 计算机基础 数据库 基础 SQL SELECT first_name, last_name, salary FROM employees WHERE department Sales AND salary > (SELECT AVG(salary)FROM employeesWHERE department Sal…...

详细分析Sql Server中的declare基本知识
目录 前言1. 基本知识2. Demo3. 拓展Mysql4. 彩蛋 前言 实战探讨主要来源于触发器的Demo 1. 基本知识 DECLARE 语句用于声明变量 声明的变量可以用于存储临时数据,并在 SQL 查询中多次引用 声明变量:使用 DECLARE 语句声明一个或多个变量变量命名&a…...

Perl 语言入门:编写并执行你的第一个脚本
摘要 Perl 是一种高级、通用的、解释型、动态编程语言,以其强大的文本处理能力而闻名。本文将指导初学者如何编写和执行他们的第一个 Perl 脚本,包括 Perl 的基本概念、脚本的基本结构、运行 Perl 脚本的方法以及一些简单的 Perl 语法。 引言 Perl&am…...

python库 - missingno
missingno 是一个用于可视化和分析数据集中缺失值的 Python 库。它提供了一系列简单而强大的工具,帮助用户直观地理解数据中的缺失模式,从而更好地进行数据清洗和预处理。missingno 库特别适用于数据分析和数据科学项目,尤其是在处理缺失数据…...

VPN的限制使得WinSCP无法直接连接到FTP服务器解决办法
由于VPN的限制使得WinSCP无法直接连接到FTP服务器,并且堡垒机的文件上传限制为500M,因此我们需要找到一种绕过这些限制的方法。以下是几个可行的方案: 方法1:通过分割文件上传 分割文件: 使用文件分割工具(…...

PCI DSS是什么?
PCI DSS,全称为Payment Card Industry Data Security Standard(支付卡行业数据安全标准),是由支付卡行业安全标准委员会(PCI Security Standards Council)制定的一套安全标准,旨在保护信用卡信息…...

DeepMind的JEST技术:AI训练速度提升13倍,能效增强10倍,引领绿色AI革命
谷歌旗下的人工智能研究实验室DeepMind发布了一项关于人工智能模型训练的新研究成果,声称其新提出的“联合示例选择”(Joint Example Selection,简称JEST)技术能够极大地提高训练速度和能源效率,相比其他方法ÿ…...

如何使用 pytorch 创建一个神经网络
我已发布在:如何使用 pytorch 创建一个神经网络 SapientialM.Github.io 构建神经网络 1 导入所需包 import os import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets, transforms2 检查GPU是否可用 dev…...
Java版Flink使用指南——定制RabbitMQ数据源的序列化器
大纲 新建工程新增依赖数据对象序列化器接入数据源 测试修改Slot个数打包、提交、运行 工程代码 在《Java版Flink使用指南——从RabbitMQ中队列中接入消息流》一文中,我们从RabbitMQ队列中读取了字符串型数据。如果我们希望读取的数据被自动化转换为一个对象&#x…...

CV每日论文--2024.7.8
1、DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents 中文标题:DisCo-Diff:利用离散潜伏增强连续扩散模型 简介:这篇文章提出了一种新型的离散-连续潜变量扩散模型(DisCo-Diff),旨在改善传统扩散模型(DMs)存在的问…...

【AI大模型】赋能儿童安全:楼层与室内定位实践与未来发展
文章目录 引言第一章:AI与室内定位技术1.1 AI技术概述1.2 室内定位技术概述1.3 楼层定位的挑战与解决方案 第二章:儿童定位与安全监控的需求2.1 儿童安全问题的现状2.2 智能穿戴设备的兴起 第三章:技术实现细节3.1 硬件设计与选择传感器选择与…...

云服务器linux系统安装配置docker
在我们拿到一个纯净的linux系统时,我需要进行一些基础环境的配置 (如果是云服务器可以用XShell远程连接,如果连接不上可能是服务器没开放22端口) 下面是配置环境的步骤 sudo -s进入root权限:退出使用exit sudo -i进入…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...