知识图谱入门笔记
自学参考:
视频:斯坦福CS520 | 知识图谱
最全知识图谱综述
详解知识图谱的构建全流程
知识图谱构建(概念,工具,实例调研)
一、基本概念
-
知识图谱(Knowledge graph):由结点和边组成,是结构化的语义知识库。
- 结点可以是实体,如一个人、一本书等,或是抽象的概念,如人工智能、知识图谱等。
- 边可以是实体的属性,如成绩、书名,或者是实体之间的关系,如朋友、家人。
- 理解为图状具有关联性的知识集合,可以由三元组(实体-关系-实体)表示。
- 通过知识图谱能把web上的信息、数据以及连接关系聚集为知识,使信息资源更易于计算、理解以及评价,并实现知识的快速响应和推理。
-
根据覆盖范围而言,知识图谱可以分为开放域通用知识图谱和垂直行业知识图谱。
- 开放通用知识图谱:注重广度,强调融合更多的实体,相较于垂直行业知识图谱而言,其准确度不够高,并且受概念范围的影响,很难借助本体库对公理、规则以及约束条件的支持能力规范其 实体、属性、实体间关系等。
通用知识图谱主要应用于智能搜索等领域。 - 行业知识图谱:通常需要依靠特定行业的数据来构建,具有特定的行业意义。在行业知识图谱中,实体的属性和数据模型往往比较丰富,需要考虑到不同的业务场景和使用人员。
- 开放通用知识图谱:注重广度,强调融合更多的实体,相较于垂直行业知识图谱而言,其准确度不够高,并且受概念范围的影响,很难借助本体库对公理、规则以及约束条件的支持能力规范其 实体、属性、实体间关系等。
-
知识库(Knowledge Base):顾名思义,一个知识数据库,包含了知识的本体和知识。Freebase是一个知识库(结构化),维基百科也可以视为一个知识库(半结构化)。知识图谱可以视为由图数据库存储的知识库。目前知名度较高的一些大规模知识库:

-
本体vs实体
- 本体:(可理解为面向对象编程里的类)概念的集合,这些概念能够描述某个具体的领域里的一切事物的共有特征,而且概念间也有一定的关系,所有构成一个具有层级特征的结构。
- 实体:是本体、实例及关系的整合。
例如“研究牲”是本体框中的一个概念,概念中也规定了相关属性比如“研究方向”,小陌是一个具体的研究牲,叫做实例,则小陌也有研究方向。小陌以及体现小陌的本体概念“研究牲”以及相关属性,叫做一个实体(某种角度上:本体+实例)
-
本体:定义了组成领域的词汇表的基本术语及其关系,以及结合这些术语和关系来定义词汇表外延的规则。
-
领域:一个本体描述的是一个特定的领域
-
术语:指给定领域中的重要概念
-
基本术语之间的关系:包括类的层次结构,其中包括并列关系、上下位关系等
-
词汇表外延的规则:包括属性值约束、不相交描述
-
知识图谱的构建技术
- 自顶向下构建(top-down)
- 先为知识图谱定义好 本体和数据模式,再把实体加入到知识库。该构建方式需利用一些现有的结构化知识库作为其 基础知识库,例如Freebase项目就是采用该方式,它的绝大部分数据是从维基百科中得到的。
- 借助百科类网站等结构化数据源,从高质量数据中提取本体和模式信息,加入到知识库里。
- 领域知识图谱多采用自顶向下的方法来构建本体。一方面,相比于开放域知识图谱,领域知识图谱涉及的概念和范围都是固定或者可控的;另一方面,对于领域知识图谱,要求其满足较高的精度。自顶向下是先为知识图谱定义好本体和数据模式,再将实体加入到知识库。该构建方式需利用一些现有的结构化知识库作为其基础知识库。
- 自底向上构建(bottom-up)
- 从一些开放链接数据中提取出实体,选择其中置信度较高的加入到知识库,再构建顶层的本体模式。目前,大多数知识图谱都采用自底向上的方式进行构建,其中最典型的是google的Knowledge Vault和微软的Satori知识库。也符合互联网数据内容知识产生的特点。
- 借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。
- 开放域知识图谱的本体构建通常采用自底向上的方法,自动地从知识图谱中抽取概念、概念层次和概念之间的关系。
- 自顶向下构建(top-down)

- “实体-关系-实体”三元组:知识图谱的基本单位,是“实体(entity)-关系(relationship)-实体(entity)”构成的三元组,这也是知识图谱的核心哦

- 知识图谱的原始数据类型(三种):
- 结构化数据Structed Data,如关系数据库、链接数据
- 半结构化数据Semi-Structured Data,如XML,JSON,百科
- 非结构化数据Unstructured Data,如图片,音频,视频

- 知识图谱的两种存储方式:
-
基于RDF结构的存储方式
RDF(Resource Description FrameWork,资源描述框架),RDF是使用XML语法来表示的数据模型。RDF的功能是用以三元组的形式于描述资源的特性以及资源之间的关系,一种以文本的形式逐行存储三元组数据。
-
基于免费开源的图数据库存储,例如Neo4j、JanusGraph、Nebula Graph等
图数据库是以图的方式来保存的,图数据库的优点在于查询和搜索的速度比较快 ,并且在图数据库中实体节点可以保留属性,这就意味着实体可以保留更多的信息,此外图数据库像其他的关系数据库一样有完整的查询语句,支持大多数的图挖掘算法。目前使用范围最广的图数据库为Neo4j。
-

从技术上来说,用关系数据库来存储知识图谱(尤其是简单结构的知识图谱)是木得问题的。但是当知识图谱变复杂,用传统的关系数据存储,查询效率会显著低于图数据库。
在一些涉及到2、3度的关联查询场景,图数据库能把查询效率提升几千倍甚至几百万倍。
而且基于图的存储在设计上会非常灵活,一般只需要局部的改动即可。当场景数据规模较大时,建议直接用图数据库来进行存储。
二、知识图谱的架构
- 知识图谱的架构包括自身的逻辑结构和构建知识图谱所采用的技术(体系)架构

逻辑架构
在逻辑上,通常把知识图谱划分为两个层次:数据层和模式层
- 模式层:在数据层之上,是知识图谱的核心,存储经过提炼的知识,通常本体库来管理知识图谱的模式层(本体库可以理解为面向对象里的“类”这一概念,本体库就存储着知识图谱的类)。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,且冗余程度较小。
- 数据层:存储真实的数据。
主要是由一系列的事实组成。若用(实体1,关系,实体2)、(实体,属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的Neo4j,Twitter的FlockDB、sones的GraphDB等。
例如eg,
模式层:实体-关系-实体,实体-属性-属性值
数据层:小明-导师-李华,小明-研究牲-克莱尔大学
技术架构

知识图谱的整体架构如上图所示,其中虚线框内的部分是知识图谱的构建过程,也包含知识图谱更新的过程。
- 图中的大致思路是:
- 首先,我们有很多数据,这些数据可能是结构化的、非结构化的以及半结构化的
- 然后,我们基于这些数据来构建知识图谱,这一步主要是通过一些列自动化或半自动化的技术手段,来从原始数据中提取出知识要素,即一堆实体关系,并将其存入我们的知识库的模式层和数据层。
知识图谱构建从最原始的数据(包括结构化、半结构化、非结构化数据)出发,采用一系列自动或半自动的技术手段,从原始数据库和第三方数据库中提取知识事实,并将其存入知识库的数据层和模式层,这一过程包含:信息抽取、知识表示、知识融合、知识推理四个过程,每一次更新迭代包含这四个阶段。
三、知识图谱构建步骤
本文中以自底向上的构建技术为例。
- 构建知识图谱是一个迭代更新的过程,根据知识获取的逻辑,每一轮迭代包含三个阶段:
- 信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达
- 知识融合:在获得新知识后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应多个不同的实体等。
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与鉴别),才能将合格的部分加入到知识库中,以确保知识库的质量。

3.1 知识抽取(information acquisition)
知识抽取是知识图谱构建的第一步,其中的关键问题是:如何从异构数据源中自动抽取信息得到候选指示单元。
信息抽取是一种自动化地从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息的技术,在此基础上形成本体化的。涉及的关键技术包括:实体抽取、关系抽取和属性抽取

实体抽取
实体抽取也称为命名实体学习(named entity learning)或命名实体识别(named entity recognition),指的是从原始语料中自动识别命名实体。
由于实体是知识图谱中的最基本元素,其抽取的完整性、准确率、召回率等将直接影响到知识图谱构建的质量。

- 实体抽取的方法可以分为四种:
- 基于百科站点或垂直站点提取
从百科类站点(如维基百科、百度百科、互动百科等)的标题和链接中提取实体名。
和一般性通用的网站相比,垂直类站点的实体提取可以获取特定领域的实体。例如从豆瓣各频道(音乐、读书、电影等)获取各种实体列表。这种方法主要是基于爬取技术来实现和获取。
基于百科类站点或垂直类站点是一种最常规和基本的方法。- 优:可以得到开放互联网中最常见的实体名
- 缺:对于中低频的覆盖率低。
- 基于规则和词典的实体提取方法
早期的实体抽取是在限定文本领域、限定语义单元类型的条件下进行的,主要采用的是基于规则和词典的方法。例如使用已定义的规则,抽取出文本中的人名、地名、组织机构名、特定时间等实体。首次实现的能够抽取公司名称的实体抽取系统,其中主要用到了启发式算法和规则模板相结合的方法。- 缺:不仅需要依靠大量的专家来编写规则或模板,覆盖的领域范围有限,且很难适应数据变化的新需求
- 基于统计机器学习的实体抽取方法
鉴于基于规则和词典实体的局限性,为更具有可扩展性,相关研究人员将机器学习中的监督学习算法用于命名实体的抽取问题上。例如利用KNN算法和条件随机场模型,实现了对Twitter文本数据中实体的识别。单纯的监督学习算法在性能上不仅受到训练集合的限制,并且算法的准确率和召回率都不理想。
相关研究者认识到监督学习算法的制约后,尝试将监督学习算法和规则相互结合,取得了一定的成果。例如基于字典,使用最大熵算法在Medline论文摘要的GENIA数据集上进行了实体抽取实验,实验的准确率和召回率都在70%以上。近年来随着深度学习的兴起应用,基于深度学习的命名实体识别得到广泛应用,例如基于双向LSTM深度神经网络和条件随机场的识别方法,在测试数据上取得最好的的表现结果。 - 面向开放域的实体抽取方法
针对如何从少量实体实例中自动发现具有区分力的模式,进而扩展到海量文本去给实体做分类和聚类的问题。
例如通过迭代方式扩展实体语料库的解决方案,其基本思想是通过少量的实体实例建立特征模型,再通过该模型应用于新的数据集得到新的命名实体。
例如基于无监督学习的开放域聚类算法,其基本思想是基于已知实体的语义特征去搜索日志中识别命名的实体,再进行聚类。
- 基于百科站点或垂直站点提取
- 主要应用:
- 命名实体作为索引和超链接
- 情感分析的准备步骤,再情感分析的文本中需要识别公司和产品,才能进一步为情感词归类
- 关系抽取的准备步骤
- QA系统(问答系统),大多数答案都是命名实体。
- 主要实现方法和工具
- DeepDive-斯坦福大学开源知识抽取工具(三元组抽取):从更少的结构化数据和统计推断中提取结构化的知识而无需编写任何复杂的机器学习代码
- FudanNLP:主要是为中文自然语言处理而开发的工具包,也包含为实现这些任务的机器学习算法和数据集。可以实现中文分词,词性标注,实体名识别,句法分析,时间表达式识别,信息检索,文本分类,新闻聚类等
- NLPIR分词(中科院):主要功能包括中文分词,英文分词,词性标注,命名实体识别,新词识别,关键词提取,支持用户专业词典和微博分析。NLPIR系统支持多种编码、多种OS、多种开发语言和平台。
- LTP(哈工大):语言技术平台(Language Technology Platform,LTP)提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等工作

- 实体抽取,实体链接(两个实体同一个含义需要规整),目前最主流的算法是CNN+LSTM+CRF进行实体识别
关系抽取
文本语料经过实体抽取之后得到的是一系列离散的命名实体(结点),为了得到语义信息,还需要从相关的语料中提取出实体之间的关联关系(边),才能将多个实体或概念联系起来,形成网状的知识结构。研究关系抽取技术,即研究如何解决从文本预料中抽取实体间的关系。
-
根据对标注数据的依赖程度,实体关系抽取方法可分为有监督方法、半监督方法、无监督学习方法和开放式抽取方法
- 有监督的实体关系抽取
有监督学习方法是最基本的实体关系抽取方法,其主要思想是在已标注的训练数据的基础上训练机器学习模型,然后对测试数据的关系类型进行识别。有监督学习方法包括有以下三种方法:- 基于规则的方法
根据待处理语料涉及领域的不同,通过人工或机器学习的方法总结归纳出相应的规则或模板,然后用模板匹配方法进行实体关系抽取 - 基于特征的方法
一种简单、有效的实体关系抽取方法,其主要思想是从关系句子实例的上下文中提取有用信息(包括词法信息、语法信息)作为特征,构造特征向量,通过计算特征向量的相似度来训练实体关系抽取模型。该方法的关键在于寻找类间有区分度的特征,形成多维加权特征向量,再采用合适的分类器进行分类。 - 基于核函数的方法
包括词序列核函数方法、依存树核函数方法、最短路径依存树核函数方法、卷积树核函数方法以及它们的组合核函数方法和基于特征的实体关系抽取方法可以相互补充。
- 基于规则的方法
- 半监督的实体关系抽取
- 基于Bootstrapping的半监督实体关系抽取方法从包含关系种子的上下文中总结出实体关系序列模式,再利用关系序列模式去发现更多的关系种子实例,形成新的关系种子集合
- 基于系统学习(co-learning)方法,该方法利用两个条件独立的特征集来提供不同且互补的信息,从而减少标注错误
- 无监督的实体关系抽取
无监督实体关系抽取方法无需依赖实体关系标注语料,其实现包括关系实例聚类和关系类型词选择两个过程。首先根据实体对出现的上下文将相似度高的实体对聚为一类,再选择具有代表性的词语来标记这种关系。 - 开放式实体关系抽取
该方法能避免针对特定关系类型人工构建语料库,可以自动完成关系类型发现和关系抽取任务。通过借助外部领域无关的实体知识库(如DBPedia、YAGO、OpenCyc、FreeBase或其他领域知识库)将高质量的实体关系实例映射到大规模文本中,根据文本对齐方法从中获得训练数据,然后使用监督学习方法来解决关系抽取问题。
- 有监督的实体关系抽取
-
主要实现方法和工具
- Piece-Wise-CNN和LSTM+Attention:是实体间关系抽取,拿到知识图谱最小单元三元组的经典算法
- DeepKE:基于深度学习的开源中文关系抽取工具
- DeepDive:是斯坦福大学开发的信息抽取系统,能处理文本、表格、图表、图片等多种格式的无结构数据,从中抽取结构化的信息。系统集成了文件分析、信息提取、信息整合、概率预测等功能。Deepdive的主要应用是特定领域的信息抽取,系统构建至今,已在交通、考古、地理、医疗等多个领域的项目实践中取得了良好的效果;在开放领域的应用。
- Standford NLP:提供了开放信息抽取OpenIE功能用于提取三元组SPO(Subject-Predicate-Object),所以使用Standford NLP更贴合知识图谱构建任务
- Reverd :是华盛顿大学研发的开放三元组抽取工具,可以从英文句子中抽取形如(argument1,relation,argument2)的三元组。它不需要提前指定关系,支持全网规模的信息抽取
- SOFIE:抽取链接本体和本体间关系。SOFIE是一个自动化本体扩展系统,由max planck institute开发。它可以解析自然语言文件,从文本中抽取基于本体的事件,将它们链接到本体上,并基于逻辑推理进行消歧
- OLLIE:开放三元组知识抽取工具。华盛顿大学研发的知识库三元组抽取组件,OLLIE是第二代提取系统。Reverb的抽取建立在文本系列上,而OLLIE则支持基于语法依赖树的关系抽取,对于长线依赖效果更好。
属性抽取
属性抽取的目标是从不同信息源中采集特定实体的属性信息,如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。

属性提取的任务是为每个本体语义类构造属性列表(如城市的属性包括特色菜、地位位置、人口等),而属性值提取则为一个语义类的实体附加属性值。属性和属性值的抽取能够形成完整的实体概念的知识图谱维度。常见的属性和属性值抽取方法包括从百科类站点中提取,从垂直网站中进行包装器归纳,从网页表格中提取,以及利用手工定义或自动生成的模式从句子和查询日志中提取。
常见的语义类/实体的常见属性/属性值可以通过解析百科类站点中的半结构化信息(如维基百科的信息盒和百度百科的属性表格)而获得。尽管通过这种简单手段能够得到高质量的属性,但同时需要采用其他方法来增加覆盖率(即为语义类增加更多属性以及为更多的实体添加属性值)。
- 基于规则匹配的抽取方法
基于模式匹配的抽取方法也叫基于规则的抽取方法,就是基于事先构造一系列规则来抽取文本中实体-属性的方法。这种方法首先定义相关抽取规则,如定义相关规范的tag标或人工编写正则表达式,再把这些规则与文本进行匹配,通过匹配的结果得到抽取的实体及其属性。基于规则的抽取系统一般由两部分组成,一个是一系列关于抽取规则的集合,另一个是一系列定义匹配策略的集合。 - 基于模式匹配的实体-属性抽取方法
基于模式匹配的方法根据其定义模式的方法可以分成三种 :- 基于手工定义的抽取
具有通过相关领域专业知识的人员进行人工的定义一系列模式 - 基于有监督学习的抽取
首先收集相关语料组成大规模的语料库,再通过人工标准的非结构化例子训练自动获得模式,构建具有大量实体-属性的知识库 - 基于迭代的抽取
首先定义模板元组,再对这些模板元组进行迭代,自动产生模式,从而进行对实体-属性的抽取。
- 基于手工定义的抽取
- 基于关系分类的实体-属性抽取方法
把属性抽取问题转化为关系分类问题。
首先把抽取的两个实体视为一个样本,实体直接的关系视为标签,再通过手工的方式构建样本特征,最后依据这些特征对样本进行分类,分类的结果是实体之间的关系,也就是属性。
通常借助机器学习的方法进行,如支持向量机(SVM)、神经网络等,通过对大量语料库的训练来学习分类模型,从而对实体-属性进行抽取。
按照其语料库的建设方式可以分为远程监督的方法和全监督的方法。- 基于远程监督的方法基本由机器构建语料库
- 基于全监督的方法则由人工构建语料库。
由于由人工来构建语料库耗费大量的时间和精力,通常目前更热衷于使用远程监督的方法来构建语料库。
- 基于聚类的实体-属性抽取方法
把属性抽取问题转化为聚类问题。
首先构建实体特征向量,再基于相关方法对这些特征向量进行聚类,最后得到的聚类就是实体的属性。例如对于类别属性可以采用弱监督的聚类方法,对应产品属性可以采用无监督的聚类方法等。

3.2知识表示
传统的知识表示方法主要是以RDF(Resource Description Framework资源描述框架)的三元组SPO来符号性描述实体之间的关系。则会中表示方法通用简单,受到广泛认可,但是其在计算效率、数据稀疏性等方面面临诸多问题。近年来,以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要意义。
- 知识表示学习的代表模型有
-
距离模型
距离模型提出了知识库中实体以及关系的结构化表示方法,其基本思想是:首先将实体用向量进行表示,再通过关系矩阵将实体投影到与实体关系对的向量空间中,最后通过计算投影向量之间的距离来判断实体间已存在的关系的置信度。由于距离模型中的关系矩阵是两个不同的矩阵,使得协同性较差。 -
单层神经网络模型
针对上述提到的距离模型中的缺点,提出了采用单层神经网络的非线性模型(single layer model,SLM),模型为知识库中每个三元组(h, r, t) , 定义了以下形式的评价函数:
其中,
是关系r的向量化表示。
g()为tanh函数;

是通过关系r定义的两个矩阵。单层神经网络模型的非线性操作虽然能够进一步刻画实体在关系下的语义相关性,但在计算开销上却大大增加。 -
双线性模型
双线性模型又叫隐变量模型(latent factor model,LFM)
模型为知识库中每个三元组(h, r, t)定义的评价函数具有如下形式:
其中,
是通过关系r定义的双线性变换矩阵。

是三元组中头实体和尾实体的向量化表示。双线性模型主要是通过基于实体间关系的双线性变换来刻画实体在关系下的语义相关性。模型不仅形式简单、易于计算,而且还能有效刻画实体间的协同性。基于上述工作,尝试将双线性变换矩阵r M 变换为对角矩阵,提出了DISTMULT模型,不仅简化了计算的复杂度,而且实验效果得到了显著提升 -
神经张量模型
基本思想是:在不同的维度下,把实体联系起来,表示实体间复杂的语义联系。模型为知识库中的每个三元组(h,r, t)定义了以下形式的评价函数:
其中
是关系r的向量化表示;
g()是tanh函数。

是一个三阶张量

是通过关系r定义的两个矩阵
神经张量模型在构建实体的向量表示时,是把该实体中的所有单词的向量取平均值,一方面可以重复使用单词向量构建实体,另一方面将有利于增强低维向量的稠密程度以及实体和关系的语义计算。 -
矩阵分解模型
通过矩阵分解的方式可得到低维的向量表示,故不少研究者提出可采用该方式进行知识表示学习,其中的典型代表是RESACL模型。在RESACL模型中,知识库中的三元组(h,r,t)集合被表示为一个三阶张量,若该三元组存在,张量中对应位置的元素被置为1,否则置为0。通过张量分解算法,可将张量中每个三元组(h,r,t)对应的张量值解为双线性模型中的知识表示形式
并使
尽量小 -
翻译模型
受到平移不变现象的启发,提出了TransE模型,即把知识库中实体之间的关系看成是冲实体间的某种平移,并用向量表示。关系lr可以看作是从头实体向量lh到尾实体向量lt的翻译。对于知识库中的每个三元组(h,r,t),TransE都希望满足以下关系
其损失函数为:
-
该模型的参数较少,计算的复杂度显著降低。同时,TransE模型在大规模稀疏知识库上也同样具有较好的性能和可扩展性。
3.3知识融合(knowledge fusion)
经由知识抽取后的信息单元间的关系是扁平化的,缺乏层次性和逻辑性,同时存在大量冗余甚至错误的信息碎片。知识融合旨在解决如何将关于同一实体或概念的多源描述信息融合起来,把多个知识库中的知识进行整合,形成一个知识库的过程,在这个过程中,主要关键技术包含指代 消解、实体消歧、实体链接

关键问题及解决
(1)实体统一(共指消解)
多源异构数据在集成的过程中,通常会出现一个现实世界实体对应多个表象的现象,导致这种现象发生的原因可能是:拼写错误、命名规则不同、名称变体、缩写等。而这种现象会导致集成后的数据存在大量冗余数据、不一致数据等问题,从而降低了集成后数据的质量,进而影响了基于集成后的数据做分析挖掘的结果,分辨多个实体表象是否对应同一个实体的问题即为实体统一。如重名现象,马云(杰克马)。
-
基于两者混用的方法

-
模式匹配
模式匹配主要是发现不同关联数据源中属性之间的映射关系,主要解决三元组中谓词之间的冲突问题。换言之,解决不同关联数据源对相同属性采用不同标识符的问题,从而实现异构数据源的集成。

-
宾语冲突消解
宾语冲突消解是解决多源关联数据宾语不一致问题。

(2)实体消歧
实体消歧的本质在于一个词有多个可能的语义,即在不同的上下文中所表达的含义不同。例如我的手机是苹果。我喜欢吃苹果。
- 基于词典的语义消歧
基于词典的词义消歧方法研究的早期代表工作是Lesk于1986的工作。给定某个待消解词及其上下文,该工作的思想是计算语义词典中各个词义的定义和上下文之间的覆盖度,选择覆盖度最大的作为待消解词在其上下文中的正确词义。但由于词典中语义的定义通常比较简洁,这使得与待消解词的上下文得到的覆盖度为0,造成消歧性能不高。 - 有监督语义消歧
有监督的消歧方法使用词义标注语料来建立消歧模型,研究的重点在于特征的表示。常见的上下文特征可归纳为三个类型:- 词汇特征通常指待消解词上下窗口内出现的词及其词性
- 句法特征利用待消解词在上下文中的句法关系特征,如动-宾关系、是否带主/宾语、主/宾语组块类型、主/宾语中性词等
- 语义特征在句法关系的基础上添加了语义类信息,如主/宾语中心词的语义类,甚至还可以是语义角色标注类信息。
- 无监督和半监督语义消歧
虽然有监督的消歧方法能够取得较好的消歧性能,但需要大量的人工标注语料,费时费力。为克服对大规模语料的需要,半监督或无监督方法仅需要少量或不需要人工标注语料。一般来说,虽然半监督或无监督方法不需要大量的人工标注数据,但依赖于一个大规模的未标注语料,以及在该语料上的句法分析结果。
(3)实体链接(Entity Linking)
实体对齐 (entity alignment) 也称为实体匹配 (entity matching)或实体解析(entity resolution)或者实体链接(entity linking),指对于从非结构化数据(如文本)或半结构化数据(如表格)中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,再通过相似度计算把指称项连接到正确的实体对象,通过打分的方法对指称项最高的实体作为目标实体。
实体指称项是在具体上下文中出现的待消歧实体名,是实体消歧任务的基本单位。
-
向量空间模型
相似度计算依据:实体指称项上下文和目标实体上下文特征的共现信息来确定- 过程:实体概念和实体指称项都被表示为上下文中Term组成的向量(Term通常为词,还可能包括概念、类别等)。基于Term向量表示,向量空间模型通过计算两个向量之间的相似度对实体概念和指称项之间的一致性进行打分。
- 研究重点
- 如何抽取有效的特征表示:上下文中的词、上下文抽取的概念和实体、从知识源获取实体指称项的额外信息
- 如何更有效地计算向量之间的相似度:Cosine相似度、上下文词重合度、分类器等机器学习方法
-
主题一致性模型
一致性依据:实体指标项的候选实体概念和指称项上下文中的其他实体概念的一致性程度。
计算一致性打分时,通常考虑如下两方面因素:- 上下文实体的重要程度:与主题的相关程度。传统方法使用实体和文本内其他实体的语义关联的平均值作为重要程度的打分。

其中,O是实体指称项上下文中所有实体的结合,sr(e,ei)是实体e和实体ei之间的语义关联值,通常基于知识资源计算 - 如何计算一致性:大部分使用目标实体和上下文中其他实体的加权语义关联作为一致性打分

其中,o是实体指称项,w(e,o)是实体e的权重,而sr(e.ei)是实体之间的语义关联度。
- 上下文实体的重要程度:与主题的相关程度。传统方法使用实体和文本内其他实体的语义关联的平均值作为重要程度的打分。
-
协同实体链接
以上两种方法忽略了单篇文档内所有实体指标项的目标实体之间的关系。
方法:把单篇文档的协同实体链接看成一个优化任务,其优化任务的目标函数由以下公式决定:
其中ys指的是实体指标项s的目标实体,So是单篇文档内所有实体指称项的集合,r(ys,ys’)是目标实体之间的语义关联,fs(ys)是实体指标项s和其目标实体ys的一致性打分。- 第一部分:对单篇文档内所有实体指称项的目标实体之间的关系进行建模
- 第二部分:对单篇文档内实体指称项和其目标实体之间的一致性进行建模
-
基于神经网络的实体消歧方法
卷积网络等
知识融合的流程和步骤
知识 融合

数据预处理
原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤。常用的数据预处理有:
- 语法正则化
- 语法匹配:如联系电话的表示方式
- 综合属性:如家庭地址的表达方式
- 数据正则化
- 移除空格、《》、“”、-等符号
- 输入错误类的拓扑错误
- 用正式名字替换昵称和缩写等
记录链接
假设两个实体的记录x和y,x和y在第i个属性上的值是< script type=“math/tex” id=“MathJax-Element-8”>x_i,y_i< /script>,则通过如下两步进行记录连接
- 属性相似度:综合单个属性相似度得到属性相似度向量
- 实体相似度:根据属性相似度向量得到一个实体的相似度
(1)属性相似度的计算
属性相似度的计算有多种方法,常用的有编辑距离、集合相似度计算、基于向量的相似度计算等
- 编辑距离:Levenstein、Wagner and Fisher、Edit Distance with Afine Gaps
- 集合相似度计算:Jaccard系数、Dice
- 基于向量的相似度计算:Cosine相似度、TFIDF相似度
(2)实体相似度的计算
实体关系发现框架 Limes
- 聚合
- 加权平均:对相似度得分向量的各个分量进行加权求和,得到最终的实体相似度
- 手动制定规则:给每一个相似度向量的分量设置一个阈值,若超过该阈值则将两实体相连
- 分类器:采用无监督/半监督训练生成训练集合分类
- 聚类
- 层次聚类:通过计算不同类别数据点之间的相似度对在不同的层次的数据进行划分,最终形成树状的聚类结构
- 相关性聚类:使用最小的代价找到一个聚类方案
- Canopy+K-means:无需提前指定K值进行聚类

- 知识表示学习-知识嵌入
把知识图谱中的实体和关系都映射低维空间向量,直接用数学表达式来计算各个实体之间相似度。这类方法不依赖任何的文本信息,获取到的都是数据的深度特征。
把两个知识图谱映射到同一空间的方法有多种,它们的桥梁是预连接实体对(训练数据),具体可以看详细论文。
关于完成映射后如何进行实体连接:KG向量训练达到稳定状态之后,对于KG1每一个没有找到链接的实体,在KG2中找到与之距离最近的实体向量进行链接,距离计算方法可采用任何向量之间的距离计算,例如欧氏距离或Cosine距离
分块
分块(Blocking)是从给定的知识库中的所有实体对中,选出潜在匹配的记录对作为候选项,并将候选项的大小尽可能的缩小。之所以如此,是因为数据太多了,我们很难去一一连接。
- 常用的分块方法有
- 基于Hash函数的分块
常见的Hash函数有:- 字符串的前n个字
- n-grams
- 结合多个简单的hash函数等
- 邻近分块
邻近分块算法包含Canopy聚类、排序邻居算法、Red-Blue Set Cover等。
- 基于Hash函数的分块
负载均衡
- 负载均衡(Load Balance)来保证所有块中的实体数目相当,从而保证分块对性能的提升程度。最简单的方法是多次Map-Reduce操作。
知识融合实现工具
-
本体对齐工具-Falcon-AO
Falcon-AO是一个自动的本体匹配系统,已经成为RDF(S)和OWL所表达的Web本体相匹配的一种实用和流行的选择。编程语言为Java。
匹配算法库包含V-Doc、I-sub、GMO、PBM四个算法。- V-Doc即基于虚拟文档的语言学匹配,它是将实体及其周围的实体、名词、文本等信息作一个集合形成虚拟文档的形式。可以用TD-IDF等算法进行操作。
- I-Sub是基于编辑距离的字符串匹配。
I-Sub和V-Doc都是基于字符串或文本级别的处理。更进一步的就有了GMO - GMO是对RDF本体的图结构上做的匹配。
- PBM基于分而治之的思想
首先经由PBM进行分而治之,后进入到V-Doc和I-Sub,GMO接收两者的输出做进一步处理,GMO的输出连同V-Doc和I-Sub的输出经由最终的贪心算法进行选取。

-
Limes实体匹配
Limes是一个基于度量空间的实体匹配发现框架,适合于大规模数据链接,编程语言是Java。其整体框架为:

-
Sematch(开源2017)
用于知识图谱的语义相似性的开发、评价和应用的集成框架。Sematch支持对概念、词和实体的语义相似度的计算,并给出得分。Sematch专注于基于特定知识的语义相似度量,它依赖于分类(比如深度、路径长度)中的结构化知识和统计信息内容(语料库和语义图谱) -
基于Neo4j图数据库的知识图谱的实体对齐(目前最常用)
计算相关性的基本步骤分为三步:- 链接neo4j数据库,并且读取出里面的数据
- 对齐算法运算
- 拿到运算结果设定一个阈值,来判断大于阈值的就是相关
实体对齐基础:基于Neo4j 图数据库的知识图谱的关联对齐-最小编辑距离-jacard算法
python爬虫neo4j知识图谱实体的属性补全
- 使用jieba完成实体统一
jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个的词语,jieba是优秀的中文分词第三方库,需要额外安装,jieba库提供三种分词模式,最简单只需掌握一个函数
- TF-IDF
Term Frequency-inverse Document Frequency是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。这种计算方式有效避免常用词对关键词的影响,提高了关键词和文章之间的相关性。 - 基于Silk的知识融合
Silk是一个集成异构数据源的开源框架。编程语言为python。提供了专门的Silk-LSL语言来进行具体处理。提供了图形化用户界面Silk Workbench,用户可以很方便的进行记录链接。
Silk的整体框架为:

- 使用Dedupe包实现实体匹配
dedupe是一个python包,在知识融合领域有着重要作用,主要就是用来实体匹配。dedupe是一个用于fuzzy matching,record deduplication和entity-resolution的python库。它基于active learning的方法,只需用户标注它在计算过程选择的少量数据,即可有效地训练出复合的blocking方法和record间相似性的计算方法,并通过聚类完成匹配。dedupe支持多种灵活的数据类型和自定义类型。
3.4知识加工(knowledge processing)
海量数据在经信息抽取、知识融合之后得到一系列基本的事实表达,但这并不等同于知识,要想获得结构化、网络化的知识体系,还需要经过质量评估之后(部分需要人工参与鉴别),才能将合格的部分纳入知识体系中以确保知识库的质量,这就是知识加工的过程。知识加工主要包括三方面内容:本体构建、知识推理和质量评估。

本体构建
本体是某个领域中抽象概念的集合、概念框架,如“人”、“事”、“物”等。本体可以采用人工编辑的方式手动构建(借助本体编辑软件),也可以以数据驱动的自动化方式构建本体。因为人工方式工作量巨大,且很难找到符合要求的专家,因此当前主流的全局本体库产品,都是从一些面向特定领域的现有本体库出发,采用自动构建技术逐步扩展得到的。
- 自动化本体构建过程包含三个阶段:
- 实体并列关系相似度计算
- 实体上下位关系抽取
- 本体的生成

如上图所示,当知识图谱最初得到“战狼2”,“流浪地球”,“北京文化”这三个实体时,可能会认为它们三个之间并没有什么差别。但当它去计算三个实体之间的相似度后,会发现,“战狼2”和“流浪地球”之间可能更相似,与“北京文化”差别更大一些
具体而言,
- 第一步下来,知识图谱实际上还没有一个上下层的概念。它并不知道,“流浪地球”和“北京文化”不隶属于一个类型,无法比较
- 第二步 实体上下位关系抽取 需要去完成这样的工作,从而生成第三步的本体
- 当三步结束后,知识图谱可能就会明白,“战狼2”和“流浪地球”是“电影”这个实体下的细分实体。它们和“北京文化”这家公司并不是一类。
知识推理
完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱之间大多数关系都是残缺的,缺失值非常严重,可以使用知识推理技术,去完成进一步的知识发现。知识推理就是指从知识库中已有的实体关系数据出发,经过计算机推理,建立实体间的新关联,从而扩展和丰富知识网络。

当然知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等,例如:
- 推理属性值:已知某实体的生日属性,可通过推理得到该实体的年龄属性
- 推理概念:已知(老虎,科,猫科)和(猫科,目,食肉目)
知识推理的算法主要可分为三类:
- 基于知识表达的关系推理技术
- 基于概率图模型的关系推理技术路线示意图
- 基于深度学习的关系推理技术路线示意图

- 知识推理常用工具
- 单调推理机
单调推理机montony-inference是一个基于perl语言的内存计算框架的单调语义推理软件。
输入为两部分:- 事实抽取出三元组
- 自定义的一套规则语法的三元组。输出为推理后得出的事实三元组,使用排列组合算法产生新事实加入内存再次迭代计算,已知没有新的事实产生输出
- RacerPro:OWL推理器和推理服务器RacerPro
RacerPro是语义网的OWL推理器和推理服务器。RACER代表Renamed ABox和Concept Expression Reasoner。RacerPro是软件的商业名称。 - Jena:建立链接数据的java框架Jena
Jena用来构建语义Web和关联数据的免费开源的Java框架。它为RDF、RDFS和OWL、SPARQL、GRDDL提供了一个编程环境,并且包括基于规则的推理引擎 - RDFox:牛津大学的知识库推理工具
RDFox是一个高度可扩展的内存RDF三元组存储,支持共享内存并行OWL2 RL推理。它是用c++编写的跨平台软件,带有一个java包装器,运行和任何基于java的解决方案(包括OWL API)轻松集成 - Virtuoso:老牌的知识库查询存储推理技术平台
Virtuoso是一个可扩展的跨平台服务器,把关系、图形和文档数据管理与Web应用程序服务器和Web服务平台功能相结合。Virtouso也是一个OWL推理者。Virtuoso直接提供RDB2RDF(以前称为SQL2RDF)通过Sponger及其墨盒,还可以从GRDDL、RDFa、微格式和更多输入提供RDF - GraphDB:语义数据查询推理引擎
GraphDB(前OWLIM)是最可扩展的语义库。它包括三元组存储、推理引擎和SPARQL查询引擎。它被封装为Sesame RDF 数据库的存储和推理层(SAIL)。GraphDB使用TRREE引擎执行RDFS、OWL DLP、OWL Horst推理和OWL 2 RL。最支持的表达式语言是OWL 2 RL ,包含RDFS。GraphDB提供可配置的推理支持和性能。 - Hermit:OWL推理机
Hermit是使用OWL编写的本体论的推理者。给定一个OWL文件,HermiT可以确定本体是否一致,识别类之间的包含关系等等。HermiT是第一个公开可用的OWL推理器,基于一种新颖的“超高级”演算,提供比任何先前已知的算法更有效的推理。以前需要几分钟或几小时进行分类的本体通常可以通过HermiT分类只需几秒,且HermiT是能够对一些本体进行分类的第一推理器,这些本体以前被证明对于任何可用系统来说太复杂。 - FaCT++:OWL DL推理器
FaCT++是一个在C++中实现的OWL DL推理器。它是一个基于tableaux的表达式描述逻辑(DL)的推理器。它涵盖OWL和OWL 2(不支持关键约束和一些数据类型)基于DL的本体语言。它可以用作独立的DIG推理器,或作为OWL API的应用程序的后端推理器。现在它被用作ProtegeOWL编辑器中的默认推理器之一。
- 单调推理机
质量评估
质量评估是知识库构建技术的重要组成部分,这一部分存在的意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
更新和维护
在知识图谱更新过程中,根据知识表达的方法可以发现一些新出现的实体、属性以及关系。在构建的一般步骤包括关系属性的抽取,实体关系的抽取以及实体关系的推理过程中,需要把海量的实体、属性、关系转化为机器能够读懂的知识表示方法(XML/OWL)。知识图谱的更新包含数据模式层更新和数据层更新,又可以按照层次进行划分定义为实体属性的更新和推理过程的更新。在知识图谱更新过程中,根据知识表达的方法可以发现一些新出现的实体、属性。

(1)模式层更新
模式层是知识图谱体系中最为重要的一个层次,是数据的整理和实体关系存储的管理层面。在模式层,以语义网的形式存储着大量实体、实体的一般属性。在知识图谱的更新过程中,掌握着更新层次的主体推理算法。若更新时间小于上一次数据库同步的时间,便可以利用算法对实体进行更新,对实体属性进行增加修改操作。若推理算法可扩展性强,还可以对实体间关系进行预测补全。
- 现阶段在模式层的更新过程中,一般采用两种方式进行更新操作
- 整体数据替换的方式,在数据集成存储中整体下载成规模的结构性数据并进行符合当前知识图谱本体规则的重塑
- 借助网络众包的形式进行碎片化知识整理
(2)数据层更新
知识图谱的数据更新方式和传统数据库的数据更新有所不同。传统的数据更新只关注数据的本身操作,更注重数据的更新时间或有无脏读等模式化操作,并未考虑整体的结构。知识图谱的更新和维护中,需要寻找待更新实体以及持续补充实体间的关联,采用良好的实体显示模式,可以判断两个实体间的关联,这叫做知识图谱的补全。
在不同角度解决复杂关系模型的问题上,可选取较为简单准确的Trans E推理模型加以改进,得出更新过程中需要改进的最大实体数,作为关联更新算法的数据源加以利用。确定更新算法,采用知识表示模型对知识图谱中实体进行增加、修改操作。确定实体间关系后,谨慎处理实体间删除操作。增加时间戳并且限定更新空间,估算更新频率,改进更新关联算法。使得知识图谱在最短的时间效率内更新最大化实体,考虑更新频率的优化问题,单位时间内减少更新次数。

信息孤岛:相互之间在功能上不关联互助、信息不共享互换以及信息与业务流程和应用相互脱节的信息系统。
- 知识图谱的内容更新有两种方式
- 全面更新:指以更新后的全部数据为输入,从零开始构建知识图谱。
- 优:方法简单
- 缺:资源消耗大且需要耗费大量人力资源进行系统维护
- 增量更新:以当前新增数据为输入,向现有知识图谱中添加新增知识
- 优:资源消耗小
- 缺:目前仍需要大量人工干预(定义规则等),因此实施起来十分困难
- 全面更新:指以更新后的全部数据为输入,从零开始构建知识图谱。
四、知识图谱分析工具&开源项目
-
知识图谱搜索引擎Magi
Magi是由Peak Labs研发的基于机器学习的信息抽取和检索系统,它能将任何领域的自然语言文本中的知识提取成结构化的数据,通过终身学习持续聚合和纠错,进而为人类用户和其他人工智能提供可解析、可检索、可溯源的知识体系。

-
中文知识图谱资源库
- OpenKG开放资源共享平台,包含16类的知识图谱,70个知识图谱相关工具,此外经常发布知识图谱论文解读
- 中文开放知识图谱Schema
- 中文开放知识图谱众包平台
-
Github上不错的知识图谱项目
- 利用网络上公开的数据构建一个小型的证券知识图谱/知识库
- 医疗保险领域知识图谱
- 农业知识图谱(AgriKG):主要功能包括命名实体识别、实体查询、关系查询、农业知识分类、农业知识问答
- 漫威英雄的知识图谱
- 基于知识图谱的《红楼梦》人物关系可视化及问答系统
- 小型金融知识图谱构建流程
- 中式菜谱知识图谱可视化(CookBook-KG)
- 从无到有构建一个电影知识图谱,并基于该KG,开发一个简易的KBOA程序
- 上市公司高管图谱
- 通用领域知识图谱
- 免费1.5亿实体通用领域知识图谱
相关文章:
知识图谱入门笔记
自学参考: 视频:斯坦福CS520 | 知识图谱 最全知识图谱综述 详解知识图谱的构建全流程 知识图谱构建(概念,工具,实例调研) 一、基本概念 知识图谱(Knowledge graph):由结…...

常见的气体流量计有哪些?
1.气体涡轮流量计 适用场合:流量变化小,脉动流频率小,中低压洁净天然气优点 1.精度高,重复性好 2.测量范围广,压损小,安装维修方便 3.具有较高的抗电磁干扰和抗震动能力缺点:分辨率低ÿ…...
:2024.07.01-2024.07.05)
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.07.01-2024.07.05
文章目录~ 1.LLM Internal States Reveal Hallucination Risk Faced With a Query2.Fine-Tuning with Divergent Chains of Thought Boosts Reasoning Through Self-Correction in Language Models3.Investigating Decoder-only Large Language Models for Speech-t…...

Android IP地址、子网掩码、默认网关、首选DNS服务器、备用DNS服务器校验
Android IP地址、子网掩码、默认网关、首选DNS服务器、备用DNS服务器校验 public String isIP(String ip) {String regex = "(25[0-5]|2[0-4]\\d|1\\d{2}|[1-9]?\\d)(\\.(25[0-5]|2[0-4]\\d|1\\d{2}|[1-9]?\\d)){3}";Pattern p = Pattern.compile(regex)...

铁威马NAS教程丨为什么修复文件系统、为卷扩容、增加及删除 SSD 缓存等操作失败?
适用机型: 所有 TNAS 型号 适用版本: 所有 TOS 版本 问题现象: 在尝试修复文件系统、为卷扩容、增加或删除 SSD 缓存时(TOS 5),可能因卷被其他进程占用而操作失败。 解决方法: 为了成功执行上述操作,您…...

【深度学习】第3章——回归模型与求解分析
一、回归分析 1.定义 分析自变量与因变量之间定量的因果关系,根据已有的数据拟合出变量之间的关系。 2.回归和分类的区别和联系 3.线性模型 4.非线性模型 5.线性回归※ 面对回归问题,通常分三步解决 第一步:选定使用的model,…...

Maven的基本使用
引入依赖 1.引入Maven仓库存在的依赖,直接引入,刷新Maven <dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>5.2.12.RELEASE</version> </dependency…...

【笔记】finalshell中使用nano编辑器GNU
ctrl O 保存 enter 确定 ctrl X 退出 nano编辑 能不用就不用吧 因为我真用不习惯 nano编辑的文件也可以用vim编辑的...

markdown文件转pdf
步骤:md转html转pdf pom引入 <!--markdown 转pdf--><dependency><groupId>com.vladsch.flexmark</groupId><artifactId>flexmark-all</artifactId><version>0.64.8</version></dependency><dependency&g…...
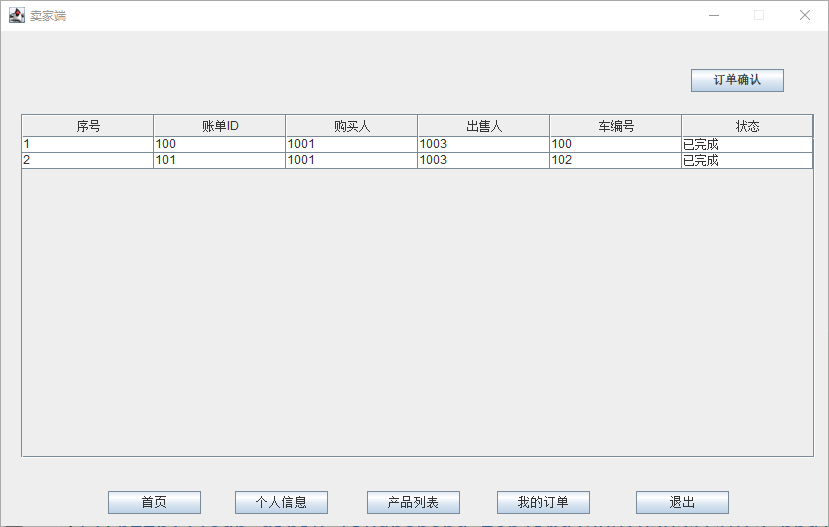
课设:二手车交易管理系统(Java+MySQL)
简易数据库课程设计~分享 技术栈 本项目使用以下技术栈构建: Java: 作为主要编程语言,负责业务逻辑的实现。MySQL: 用于数据存储,管理用户、车辆和订单信息。JDBC: 用于Java与MySQL数据库之间的连接和操作。Swing GUI: 提供用户图形界面&am…...

vue3实现无缝滚动 列表滚动 vue3-seamlessscroll
vue3框架内使用无缝滚动,使用一个插件比较合适(gitee地址): vue3-seamless-scroll: Vue3.0 无缝滚动组件 具体更多配置请看: 组件配置 | vue3-scroll-seamless 1. 安装: npm install vue3-seamless-sc…...

Python酷库之旅-第三方库Pandas(012)
目录 一、用法精讲 28、pandas.HDFStore.keys函数 28-1、语法 28-2、参数 28-3、功能 28-4、返回值 28-5、说明 28-6、用法 28-6-1、数据准备 28-6-2、代码示例 28-6-3、结果输出 29、pandas.HDFStore.groups函数 29-1、语法 29-2、参数 29-3、功能 29-4、返回…...

SpringCloud集成nacos之jasypt配置中心的密码加密的自动解密
目录 1.引入相关的依赖 2.nacos的yaml的相关配置,配置密码和相关算法 3.配置数据源连接 3.1 数据库连接配置 4.连接数据库配置类详解(DataSourceConfig)。 5.完整的配置类代码如下 1.引入相关的依赖 <dependency><groupId>…...

Python 中将字典内容保存到 Excel 文件使用详解
概要 在数据处理和分析的过程中,经常需要将字典等数据结构保存到Excel文件中,以便于数据的存储、共享和进一步分析。Python提供了丰富的库来实现这一功能,其中最常用的是pandas和openpyxl。本文将详细介绍如何使用这些库将字典内容保存到Excel文件中,并包含具体的示例代码…...

libaom 编码器 aomenc 使用文档介绍
使用方法:./aomenc <选项> -o 目标文件名 源文件名 使用 --help 查看完整的选项列表。 选项: --help 显示使用选项并退出-c <参数>, --cfg<参数> 使用配置文件-D, --debug 调试模式(使输出确定性)-o <参数&g…...

速盾:cdn 缓存图片
现如今,互联网已经成为我们日常生活中不可或缺的一部分。在我们使用互联网时,经常会遇到图片加载缓慢、文章打开慢等问题。为了解决这些问题,CDN(内容分发网络)应运而生。CDN 是一种通过将数据缓存在世界各地的服务器上…...
移动应用开发课设——原神小助手文档(2)
2023年末,做的移动应用开发课设,分还算高,项目地址:有帮助的话,点个赞和星呗~ GitHub - blhqwjs/-GenShin_imp: 2023年移动应用开发课设 本文按照毕业论文要求来写,希望对大家有所帮助。 接上文:…...

智能聊天机器人:使用PyTorch构建多轮对话系统
使用PyTorch构建多轮对话系统的示例代码。这个示例项目包括一个简单的Seq2Seq模型用于对话生成,并使用GRU作为RNN的变体。以下是代码的主要部分,包括数据预处理、模型定义和训练循环。 数据预处理 首先,准备数据并进行预处理。这部分代码假…...

昇思25天学习打卡营第16天 | 文本解码原理-以MindNLP为例
基于 MindSpore 实现 BERT 对话情绪识别 上几章我们学习过了基于MindSpore来实现计算机视觉的一些应用,那么从这期开始要开始一个新的领域——LLM 首先了解一下什么是LLM LLM 是 “大型语言模型”(Large Language Model)的缩写。LLM 是一种…...

Unity之Text组件换行\n没有实现+动态中英互换
前因:文本中的换行 \n没有换行而是打印出来了,解决方式 因为unity会默认把\n替换成\\n 面板中使用富文本这个选项啊 没有用 m_text.text m_text.text.Replace("\\n", "\n"); ###动态中英文互译 using System.Collections; using…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...