【网络编程】零基础到精通——NIO基础三大组件和ByteBuffer
一. NIO 基础
non-blocking io 非阻塞 IO
1. 三大组件
1.1 Channel & Buffer
channel 有一点类似于 stream,它就是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而之前的 stream 要么是输入,要么是输出,channel 比 stream 更为底层
graph LR
channel --> buffer
buffer --> channel
常见的 Channel 有
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
buffer 则用来缓冲读写数据,常见的 buffer 有
- ByteBuffer
-
- MappedByteBuffer
-
- DirectByteBuffer
-
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
1.2 Selector
selector 单从字面意思不好理解,需要结合服务器的设计演化来理解它的用途
多线程版设计
graph TD
subgraph 多线程版
t1(thread) --> s1(socket1)
t2(thread) --> s2(socket2)
t3(thread) --> s3(socket3)
end
⚠️ 多线程版缺点
- 内存占用高
- 线程上下文切换成本高
- 只适合连接数少的场景
线程池版设计
graph TD
subgraph 线程池版
t4(thread) --> s4(socket1)
t5(thread) --> s5(socket2)
t4(thread) -.-> s6(socket3)
t5(thread) -.-> s7(socket4)
end
⚠️ 线程池版缺点
- 阻塞模式下,线程仅能处理一个 socket 连接
- 仅适合短连接场景
selector 版设计
selector 的作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景(low traffic)
graph TD
subgraph selector 版
thread --> selector
selector --> c1(channel)
selector --> c2(channel)
selector --> c3(channel)
end
调用 selector 的 select() 会阻塞直到 channel 发生了读写就绪事件,这些事件发生,select 方法就会返回这些事件交给 thread 来处理
2. ByteBuffer
有一普通文本文件 data.txt,内容为
1234567890abcd
使用 FileChannel 来读取文件内容
@Slf4j
public class ChannelDemo1 {public static void main(String[] args) {try (RandomAccessFile file = new RandomAccessFile("helloword/data.txt", "rw")) {FileChannel channel = file.getChannel();ByteBuffer buffer = ByteBuffer.allocate(10);do {// 向 buffer 写入int len = channel.read(buffer);log.debug("读到字节数:{}", len);if (len == -1) {break;}// 切换 buffer 读模式buffer.flip();while(buffer.hasRemaining()) {log.debug("{}", (char)buffer.get());}// 切换 buffer 写模式buffer.clear();} while (true);} catch (IOException e) {e.printStackTrace();}}
}
输出
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 读到字节数:10
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 1
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 2
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 3
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 4
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 5
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 6
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 7
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 8
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 9
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 0
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 读到字节数:4
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - a
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - b
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - c
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - d
10:39:03 [DEBUG] [main] c.i.n.ChannelDemo1 - 读到字节数:-1
2.1 ByteBuffer 正确使用姿势
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或 compact() 切换至写模式
- 重复 1~4 步骤
2.2 ByteBuffer 结构
ByteBuffer 有以下重要属性
- capacity
- position
- limit
一开始

写模式下,position 是写入位置,limit 等于容量,下图表示写入了 4 个字节后的状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hIr9DBk0-1678696541291)(null)]
flip 动作发生后,position 切换为读取位置,limit 切换为读取限制
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LW38aE2R-1678696541377)(null)]
读取 4 个字节后,状态
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wDTMcDuj-1678696541347)(null)]
clear 动作发生后,状态

compact 方法,是把未读完的部分向前压缩,然后切换至写模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xl7UwJ06-1678696541320)(null)]
💡 调试工具类
public class ByteBufferUtil {private static final char[] BYTE2CHAR = new char[256];private static final char[] HEXDUMP_TABLE = new char[256 * 4];private static final String[] HEXPADDING = new String[16];private static final String[] HEXDUMP_ROWPREFIXES = new String[65536 >>> 4];private static final String[] BYTE2HEX = new String[256];private static final String[] BYTEPADDING = new String[16];static {final char[] DIGITS = "0123456789abcdef".toCharArray();for (int i = 0; i < 256; i++) {HEXDUMP_TABLE[i << 1] = DIGITS[i >>> 4 & 0x0F];HEXDUMP_TABLE[(i << 1) + 1] = DIGITS[i & 0x0F];}int i;// Generate the lookup table for hex dump paddingsfor (i = 0; i < HEXPADDING.length; i++) {int padding = HEXPADDING.length - i;StringBuilder buf = new StringBuilder(padding * 3);for (int j = 0; j < padding; j++) {buf.append(" ");}HEXPADDING[i] = buf.toString();}// Generate the lookup table for the start-offset header in each row (up to 64KiB).for (i = 0; i < HEXDUMP_ROWPREFIXES.length; i++) {StringBuilder buf = new StringBuilder(12);buf.append(NEWLINE);buf.append(Long.toHexString(i << 4 & 0xFFFFFFFFL | 0x100000000L));buf.setCharAt(buf.length() - 9, '|');buf.append('|');HEXDUMP_ROWPREFIXES[i] = buf.toString();}// Generate the lookup table for byte-to-hex-dump conversionfor (i = 0; i < BYTE2HEX.length; i++) {BYTE2HEX[i] = ' ' + StringUtil.byteToHexStringPadded(i);}// Generate the lookup table for byte dump paddingsfor (i = 0; i < BYTEPADDING.length; i++) {int padding = BYTEPADDING.length - i;StringBuilder buf = new StringBuilder(padding);for (int j = 0; j < padding; j++) {buf.append(' ');}BYTEPADDING[i] = buf.toString();}// Generate the lookup table for byte-to-char conversionfor (i = 0; i < BYTE2CHAR.length; i++) {if (i <= 0x1f || i >= 0x7f) {BYTE2CHAR[i] = '.';} else {BYTE2CHAR[i] = (char) i;}}}/*** 打印所有内容* @param buffer*/public static void debugAll(ByteBuffer buffer) {int oldlimit = buffer.limit();buffer.limit(buffer.capacity());StringBuilder origin = new StringBuilder(256);appendPrettyHexDump(origin, buffer, 0, buffer.capacity());System.out.println("+--------+-------------------- all ------------------------+----------------+");System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), oldlimit);System.out.println(origin);buffer.limit(oldlimit);}/*** 打印可读取内容* @param buffer*/public static void debugRead(ByteBuffer buffer) {StringBuilder builder = new StringBuilder(256);appendPrettyHexDump(builder, buffer, buffer.position(), buffer.limit() - buffer.position());System.out.println("+--------+-------------------- read -----------------------+----------------+");System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), buffer.limit());System.out.println(builder);}private static void appendPrettyHexDump(StringBuilder dump, ByteBuffer buf, int offset, int length) {if (isOutOfBounds(offset, length, buf.capacity())) {throw new IndexOutOfBoundsException("expected: " + "0 <= offset(" + offset + ") <= offset + length(" + length+ ") <= " + "buf.capacity(" + buf.capacity() + ')');}if (length == 0) {return;}dump.append(" +-------------------------------------------------+" +NEWLINE + " | 0 1 2 3 4 5 6 7 8 9 a b c d e f |" +NEWLINE + "+--------+-------------------------------------------------+----------------+");final int startIndex = offset;final int fullRows = length >>> 4;final int remainder = length & 0xF;// Dump the rows which have 16 bytes.for (int row = 0; row < fullRows; row++) {int rowStartIndex = (row << 4) + startIndex;// Per-row prefix.appendHexDumpRowPrefix(dump, row, rowStartIndex);// Hex dumpint rowEndIndex = rowStartIndex + 16;for (int j = rowStartIndex; j < rowEndIndex; j++) {dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);}dump.append(" |");// ASCII dumpfor (int j = rowStartIndex; j < rowEndIndex; j++) {dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);}dump.append('|');}// Dump the last row which has less than 16 bytes.if (remainder != 0) {int rowStartIndex = (fullRows << 4) + startIndex;appendHexDumpRowPrefix(dump, fullRows, rowStartIndex);// Hex dumpint rowEndIndex = rowStartIndex + remainder;for (int j = rowStartIndex; j < rowEndIndex; j++) {dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);}dump.append(HEXPADDING[remainder]);dump.append(" |");// Ascii dumpfor (int j = rowStartIndex; j < rowEndIndex; j++) {dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);}dump.append(BYTEPADDING[remainder]);dump.append('|');}dump.append(NEWLINE +"+--------+-------------------------------------------------+----------------+");}private static void appendHexDumpRowPrefix(StringBuilder dump, int row, int rowStartIndex) {if (row < HEXDUMP_ROWPREFIXES.length) {dump.append(HEXDUMP_ROWPREFIXES[row]);} else {dump.append(NEWLINE);dump.append(Long.toHexString(rowStartIndex & 0xFFFFFFFFL | 0x100000000L));dump.setCharAt(dump.length() - 9, '|');dump.append('|');}}public static short getUnsignedByte(ByteBuffer buffer, int index) {return (short) (buffer.get(index) & 0xFF);}
}
2.3 ByteBuffer 常见方法
分配空间
可以使用 allocate 方法为 ByteBuffer 分配空间,其它 buffer 类也有该方法
Bytebuffer buf = ByteBuffer.allocate(16);
向 buffer 写入数据
有两种办法
- 调用 channel 的 read 方法
- 调用 buffer 自己的 put 方法
int readBytes = channel.read(buf);
和
buf.put((byte)127);
从 buffer 读取数据
同样有两种办法
- 调用 channel 的 write 方法
- 调用 buffer 自己的 get 方法
int writeBytes = channel.write(buf);
和
byte b = buf.get();
get 方法会让 position 读指针向后走,如果想重复读取数据
- 可以调用 rewind 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动读指针
mark 和 reset
mark 是在读取时,做一个标记,即使 position 改变,只要调用 reset 就能回到 mark 的位置
注意
rewind 和 flip 都会清除 mark 位置
字符串与 ByteBuffer 互转
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("你好");
ByteBuffer buffer2 = Charset.forName("utf-8").encode("你好");debug(buffer1);
debug(buffer2);CharBuffer buffer3 = StandardCharsets.UTF_8.decode(buffer1);
System.out.println(buffer3.getClass());
System.out.println(buffer3.toString());
输出
+-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| e4 bd a0 e5 a5 bd |...... |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| e4 bd a0 e5 a5 bd |...... |
+--------+-------------------------------------------------+----------------+
class java.nio.HeapCharBuffer
你好
⚠️ Buffer 的线程安全
Buffer 是非线程安全的
2.4 Scattering Reads
分散读取,有一个文本文件 3parts.txt
onetwothree
使用如下方式读取,可以将数据填充至多个 buffer
try (RandomAccessFile file = new RandomAccessFile("helloword/3parts.txt", "rw")) {FileChannel channel = file.getChannel();ByteBuffer a = ByteBuffer.allocate(3);ByteBuffer b = ByteBuffer.allocate(3);ByteBuffer c = ByteBuffer.allocate(5);channel.read(new ByteBuffer[]{a, b, c});a.flip();b.flip();c.flip();debug(a);debug(b);debug(c);
} catch (IOException e) {e.printStackTrace();
}
结果
+-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 6f 6e 65 |one |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 74 77 6f |two |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 74 68 72 65 65 |three |
+--------+-------------------------------------------------+----------------+
2.5 Gathering Writes
使用如下方式写入,可以将多个 buffer 的数据填充至 channel
try (RandomAccessFile file = new RandomAccessFile("helloword/3parts.txt", "rw")) {FileChannel channel = file.getChannel();ByteBuffer d = ByteBuffer.allocate(4);ByteBuffer e = ByteBuffer.allocate(4);channel.position(11);d.put(new byte[]{'f', 'o', 'u', 'r'});e.put(new byte[]{'f', 'i', 'v', 'e'});d.flip();e.flip();debug(d);debug(e);channel.write(new ByteBuffer[]{d, e});
} catch (IOException e) {e.printStackTrace();
}
输出
+-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 66 6f 75 72 |four |
+--------+-------------------------------------------------+----------------++-------------------------------------------------+| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 66 69 76 65 |five |
+--------+-------------------------------------------------+----------------+
文件内容
onetwothreefourfive
2.6 练习
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔
但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为
- Hello,world\n
- I’m zhangsan\n
- How are you?\n
变成了下面的两个 byteBuffer (黏包,半包)
- Hello,world\nI’m zhangsan\nHo
- w are you?\n
现在要求你编写程序,将错乱的数据恢复成原始的按 \n 分隔的数据
public static void main(String[] args) {ByteBuffer source = ByteBuffer.allocate(32);// 11 24source.put("Hello,world\nI'm zhangsan\nHo".getBytes());split(source);source.put("w are you?\nhaha!\n".getBytes());split(source);
}private static void split(ByteBuffer source) {source.flip();int oldLimit = source.limit();for (int i = 0; i < oldLimit; i++) {if (source.get(i) == '\n') {System.out.println(i);ByteBuffer target = ByteBuffer.allocate(i + 1 - source.position());// 0 ~ limitsource.limit(i + 1);target.put(source); // 从source 读,向 target 写debugAll(target);source.limit(oldLimit);}}source.compact();
}
相关文章:
【网络编程】零基础到精通——NIO基础三大组件和ByteBuffer
一. NIO 基础 non-blocking io 非阻塞 IO 1. 三大组件 1.1 Channel & Buffer channel 有一点类似于 stream,它就是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而之前的 st…...

操作系统 - 1. 绪论
目录操作系统基本概念概念特征功能操作系统的分类与发展手工操作单道批处理系统多道批处理系统分时系统实时系统操作系统的运行环境CPU 运行模式中断和异常的处理系统调用程序的链接与装入程序运行时内存映像和地址空间操作系统的体系结构操作系统的引导操作系统基本概念 概念…...

详谈parameterType与resultType的用法
resultMap 表示查询结果集与java对象之间的一种关系,处理查询结果集,映射到java对象。 resultMap 是一种“查询结果集---Bean对象”属性名称映射关系,使用resultMap关系可将将查询结果集中的列一一映射到bean对象的各个属性&#…...

【Linux】进程概念、fork() 函数 (干货满满)
文章目录📕 前言📕 进程概念📕 Linux下查看进程的两种方法方法一方法二📕 pid() 、ppid() 函数📕 fork() 函数、父子进程初识再理解📕 fork做了什么📕 如何理解 fork 有两个返回值📕…...
【动态规划】最长上升子序列、最大子数组和题解及代码实现
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

Ajax进阶篇02---跨域与JSONP
前言❤️ 不管前方的路多么崎岖不平,只要走的方向正确,都比站在原地更接近幸福 ❤️Ajax进阶篇02---跨域与JSONP一、Ajax进阶篇02---跨域与JSONP(1)同源策略1.1 什么是同源1.2 什么是同源策略(2)跨域2.1 什…...
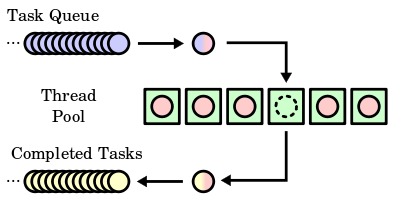
C 语言编程 — 线程池设计与实现
目录 文章目录目录线程池(Thread Pool)tiny-threadpool数据结构设计Task / JobTask / Job QueueWorker / ThreadThread Pool ManagerPublic APIsPrivate Functions运行示例线程池(Thread Pool) 线程池(Thread Pool&am…...

并发编程要点
Java并发编程中的三大特性分别是原子性、可见性和有序性,它们分别靠以下机制实现: 原子性:原子性指的是对于一个操作,要么全部执行,要么全部不执行。Java提供了一些原子性操作,例如AtomicInteger等…...

HDFS黑名单退役服务器
黑名单:表示在黑名单的主机IP地址不可以,用来存储数据。 企业中:配置黑名单,用来退役服务器。 黑名单配置步骤如下: 1)编辑/opt/module/hadoop-3.1.3/etc/hadoop目录下的blacklist文件 添加如下主机名称&…...

基于stm32智能语音电梯消毒系统
这次来分享个最近做的项目,stm32智能语音电梯消毒系统功能说明:在电梯,房间,客道区域内,检测到人,则执行相关动作!例如继电器开关灯,喷洒酒精等行为。手机app/微信小程序可以控制需要…...
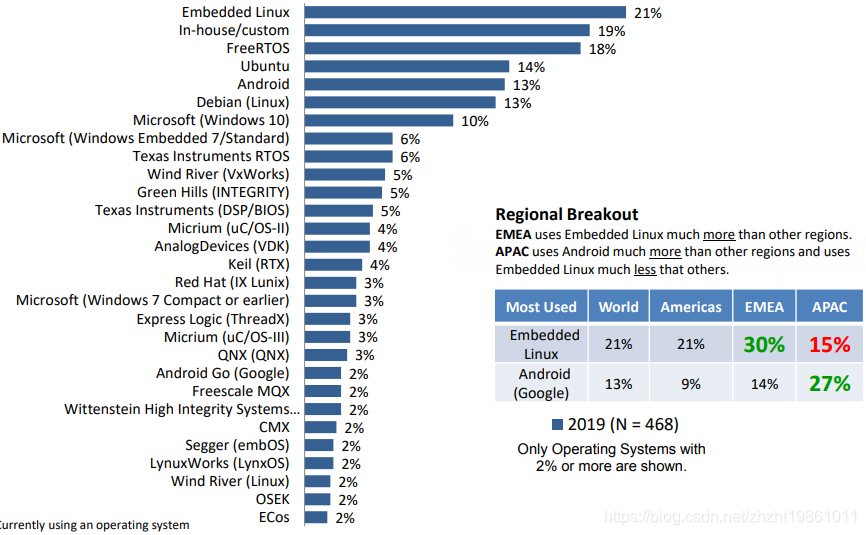
FreeRTOS系列第1篇---为什么选择FreeRTOS?
1.为什么学习RTOS? 作为基于ARM7、Cortex-M3硬件开发的嵌入式工程师,我一直反对使用RTOS。不仅因为不恰当的使用RTOS会给项目带来额外的稳定性风险,更重要的是我认为绝大多数基于ARM7、Cortex-M3硬件的项目,还没复杂到使用RTOS的地…...

基于.NET Core内置浏览器窗体应用程序界面框架
更多开源项目请查看:一个专注推荐.Net开源项目的榜单 平常我们在做项目过程中,桌面软件具备操作高效、利用本地计算机做一些复杂运算、或者设定快捷操作等优势,但是桌面软件也有很多缺点,比如升级问题、系统兼容问题、系统bug排查…...
【数据结构初阶】一文带你学会归并排序(递归非递归)
目录 前言 递归实现 代码实现 非递归实现 代码实现 总结 前言 归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。 作为一种典型的分而治之思想…...
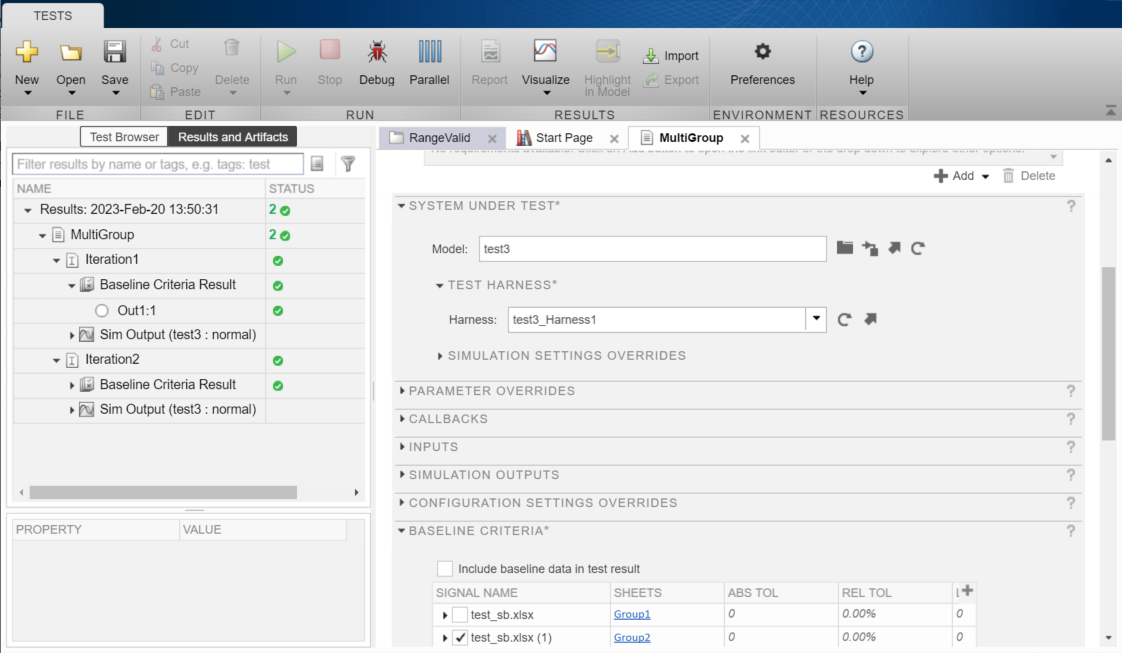
Simulink壁咚(一)——What and How
目录 一、前言 二、Simulink 知多少 三、滤波算法 四、Model Verification 五、Model Coverage 六、Simulink测试实例 七、Simulink Test 八、Test Manager 九、Test Harness 十、 学习 一、前言 Simulink从2017b以后更加工程化和实用化,基于MBD的功能日趋…...
【PyTorch】Pytorch基础第0章
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 这是目录PyTorch的简介PyTorch 构建深度学习模型的步骤搭建pytorch使用环境PyTorch的简介 PyTorch 是一个开源的机器学习框架,由 Facebook 的人工智能研究院(…...

Android学习总结
积累熟练掌握 Java 语言,面向对象分析设计能力,反射原理,自定义注解及泛型,多次采用设计模式重构公司项目;熟练掌握 IVM 原理,反射,动态代理以及对 ClassLoader 热修复有比较深的理解࿱…...

虚拟机ubuntu安装samba服务
安装samba apt-get install samba 新建一个共享目录 mkdir /home/l/work chmod 777 /home/l/work 配置服务 配置 /etc/samba/smb.confsudo smbpasswd -a l(添加用户名名称) 防火墙关闭 Ubuntu中 我们使用命令查看当前防火墙状态; sudo ufw status inactive状态是防火墙关闭…...
开发板中的内存压力测试,你了解多少?
1. 测试目的内存压力测试的目的是评估开发板中的内存子系统性能和稳定性,以确保它能够满足特定的应用需求。开发板通常用于嵌入式系统、物联网设备、嵌入式智能家居等场景,这些场景对内存的要求通常比较高。其内存压力测试的主要目的有:1.对确…...
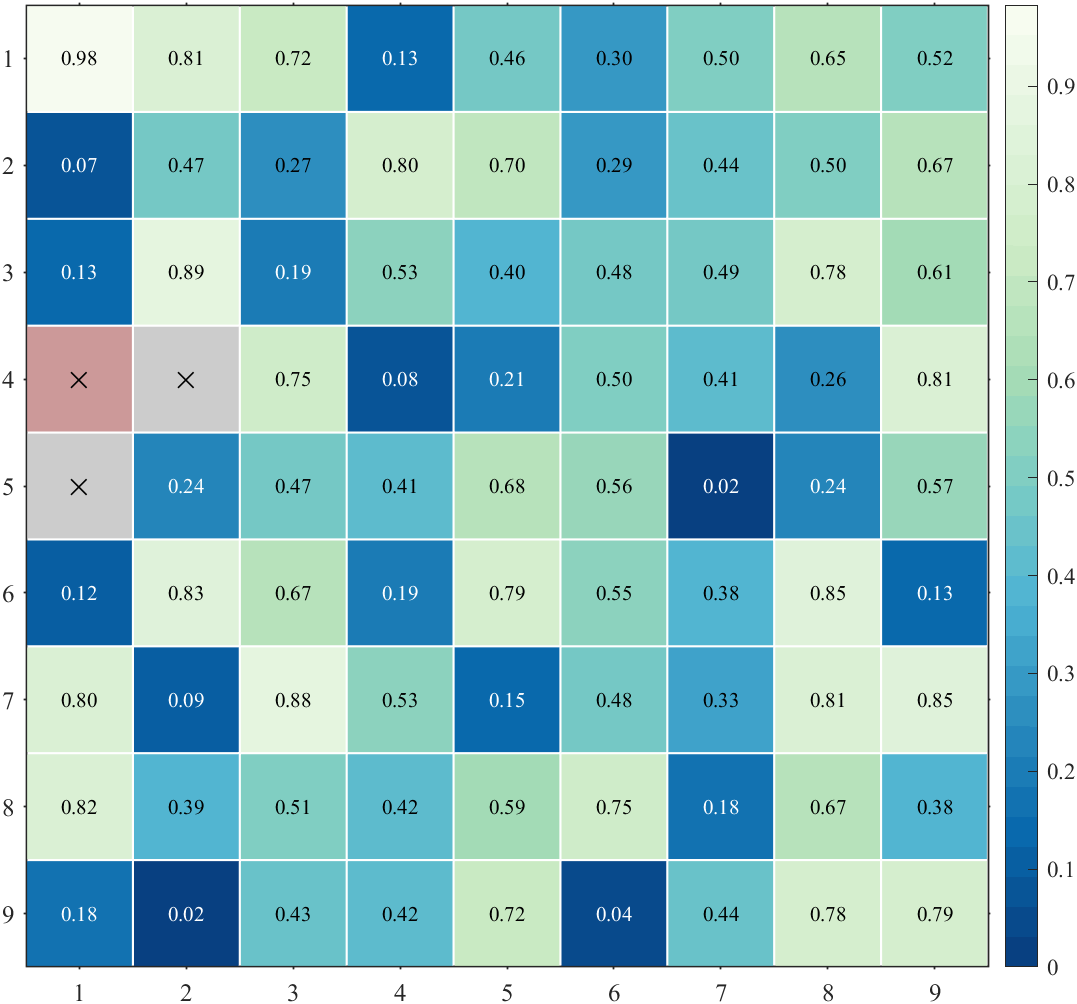
MATLAB | 这些花里胡哨的热图怎么画
好早之前写过一个绘制相关系数矩阵的代码,但是会自动求相关系数,而且画出来的热图只能是方形,这里写一款允许nan值出现,任意形状的热图绘制代码,绘制效果如下: 如遇到bug请后台提出,并去gitee下…...

Java开发的一些编码建议
1、无论是类、方法、字段、变量,尽可能的限制他们的作用范围,可以避免出现不必要的错误;同时虚拟机也能有更大的优化空间。 2、错误越早发现越好,编译时发生错误比在运行时发生错误好。而且编译时错误能更好的定位问题所在。 这…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...

基于开源AI智能名片链动2 + 1模式S2B2C商城小程序的沉浸式体验营销研究
摘要:在消费市场竞争日益激烈的当下,传统体验营销方式存在诸多局限。本文聚焦开源AI智能名片链动2 1模式S2B2C商城小程序,探讨其在沉浸式体验营销中的应用。通过对比传统品鉴、工厂参观等初级体验方式,分析沉浸式体验的优势与价值…...
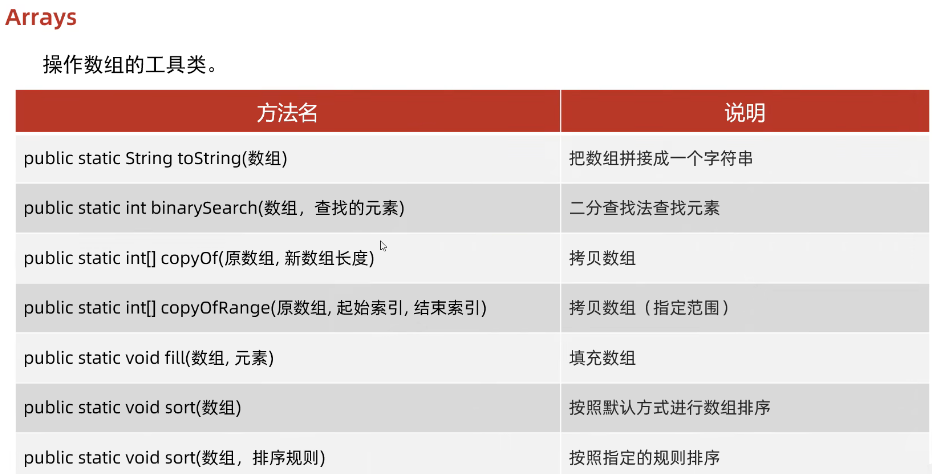
Java数组Arrays操作全攻略
Arrays类的概述 Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。 常用成员方法及代码示例 排序(sort) 对数组进行升序…...