Java之深度优先(DFS)和广度优先(BFS)及相关题目
目录
一.深度优先遍历和广度优先遍历
1.深度优先遍历
2.广度优先遍历
二.图像渲染
1.题目描述
2.问题分析
3代码实现
1.广度优先遍历
2.深度优先遍历
三.岛屿的最大面积
1.题目描述
2.问题分析
3代码实现
1.广度优先遍历
2.深度优先遍历
四.岛屿的周长
1.题目描述
2.问题分析
3代码实现
1.广度优先遍历
2.深度优先遍历
一.深度优先遍历和广度优先遍历
1.深度优先遍历
图的深度优先搜索(Depth First Search) .
1) 深度优先遍历,从初始访问结点出发,初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点,可以这样理解:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
2)我们可以看到,这样的访问策略是优先往纵向挖掘深入而不是对一个结点的所有邻接结点进行横向访问。
3)显然,深度优先搜索是一个递归的过程(可以用栈来模拟)

例如这个图进行深度优先遍历:V1--->V2--->V5--->V3--->V6-->V4
具体的代码实现
public class Graph { public ArrayList<String> vertexList;//存储顶点的集合public int[][] edges; //存储图对应的邻接矩阵public int numOfEdges; //表示边的数目public boolean[] isVisted; //记录某个节点是否被访问//初始化public Graph(int n) {edges = new int[n][n];vertexList = new ArrayList<>(n);isVisted = new boolean[n];}//得到第一个邻接节点的下标w//如果存在就返回对应的下标,否则就返回-1public int getFirstNeighbor(int index) {for (int i = 0; i < getNumOfVertex(); i++) {if (edges[index][i] > 0) {return i;}}return -1;}//根据前一个邻接节点的下标来获取下一个邻接节点public int getNextNeighbor(int v1, int v2) {for (int i = v2 + 1; i < getNumOfVertex(); i++) {if (edges[v1][i] > 0) {return i;}}return -1;}//返回结点i对应的数据public String getValueByIndex(int i) {return vertexList.get(i);}//深度优先遍历算法//对dfs进行重载,遍历所有的结点,并进行dfs//避免不连通的情况出现public void dfs() {isVisted = new boolean[getNumOfVertex()];//遍历所有的结点for (int i = 0; i < getNumOfVertex(); i++) {if (!isVisted[i]) {dfs(i);}}}public void dfs(int i) {//首先访问此结点,输出System.out.print(getValueByIndex(i) + "-->");//将该结点设置成已经访问过isVisted[i] = true;//查找i结点的第一个邻接节点int w = getFirstNeighbor(i);while (w != -1) {//存在if (!isVisted[w]) {dfs(w);}//如果w结点已经被访问过了w = getNextNeighbor(i, w);}}
}2.广度优先遍历
图的广度优先搜索(Breadth First Search) .
1)广度优先遍历,从初始访问结点出发,初始访问结点可能有多个邻接结点,广度优先遍历的策略就是首先访问第一个邻接结点,然后依次访问初始访问结点的相邻接点,然后访问初始节点的第一个邻接结点的邻接顶点,初始节点第二个邻接结点的邻接节点.....,
2)广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点
例如这个图进行广度优先遍历:V1--->V2--->V4--->V5--->V6-->V3
具体的代码实现
public class Graph { public ArrayList<String> vertexList;//存储顶点的集合public int[][] edges; //存储图对应的邻接矩阵public int numOfEdges; //表示边的数目public boolean[] isVisted; //记录某个节点是否被访问//初始化public Graph(int n) {edges = new int[n][n];vertexList = new ArrayList<>(n);isVisted = new boolean[n];}//得到第一个邻接节点的下标w//如果存在就返回对应的下标,否则就返回-1public int getFirstNeighbor(int index) {for (int i = 0; i < getNumOfVertex(); i++) {if (edges[index][i] > 0) {return i;}}return -1;}//根据前一个邻接节点的下标来获取下一个邻接节点public int getNextNeighbor(int v1, int v2) {for (int i = v2 + 1; i < getNumOfVertex(); i++) {if (edges[v1][i] > 0) {return i;}}return -1;}//返回结点i对应的数据public String getValueByIndex(int i) {return vertexList.get(i);}//深度优先遍历算法//对dfs进行重载,遍历所有的结点,并进行dfs//避免不连通的情况出现public void dfs() {isVisted = new boolean[getNumOfVertex()];//遍历所有的结点for (int i = 0; i < getNumOfVertex(); i++) {if (!isVisted[i]) {dfs(i);}}}public void bfs(int i) {int u; //表示队列头结点对应的下标int w; //邻接节点w//队列,记录结点访问的顺序LinkedList<Integer> queue = new LinkedList<>();System.out.print(getValueByIndex(i) + "-->");//标记为已访问isVisted[i] = true;queue.offer(i);while (!queue.isEmpty()) {//取出队列的头结点下标u = queue.poll();w = getFirstNeighbor(u);while (w != -1) {//找到存在的//是否访问过if (!isVisted[w]) {System.out.print(getValueByIndex(w) + "-->");//标记访问过isVisted[w] = true;queue.add(w);}//以u为前驱节点找w后面的下一个邻接点w = getNextNeighbor(u, w);//体现出广度优先}}}
}二.图像渲染
1.题目描述
有一幅以
m x n的二维整数数组表示的图画image,其中image[i][j]表示该图画的像素值大小。你也被给予三个整数
sr,sc和newColor。你应该从像素image[sr][sc]开始对图像进行 上色填充 。为了完成 上色工作 ,从初始像素开始,记录初始坐标的 上下左右四个方向上 像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应 四个方向上 像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为
newColor。最后返回 经过上色渲染后的图像 。
力扣: 力扣
2.问题分析
这是一道典型的BFS和DFS的问题,
先来考虑广度优先遍历的方法:我们可以先把初始点像素相同的的上下左右点全部涂完色,然后再把第一次涂上色的格子的上下左右点涂上色,以此类推,直到没有可以涂色的格子
假设所有格子都可以涂色,那么广度优先的涂色顺序如下图所示进行涂色处理,这个过程中我们需要使用一个队列进行模拟,每一次寻找上下左右可以涂色的位置(不越界,像素值相同)进行涂色,并且入队列,把像素值替换为color

再来考虑深度优先遍历,深度优先遍历自然就是使用递归来实现,每一次我们访问上方的格子(默认的访问顺序是上下左右),直到不能访问,然后访问不能访问上班的格子的下边的格子,此格子不能访问再访问左边格子,不能访问再访问右边格子,一层一层的递归下去.......
3代码实现
1.广度优先遍历
int[] dx = {-1, 1, 0, 0};int[] dy = {0, 0, -1, 1};public int[][] floodFill(int[][] image, int sr, int sc, int color) {int m = image.length;int n = image[0].length;int curColor = image[sr][sc];if (image[sr][sc] == color) {return image;}LinkedList<int[]> queue = new LinkedList<>();queue.offer(new int[]{sr, sc});image[sr][sc] = color;while (!queue.isEmpty()) {int[] poll = queue.poll();int x = poll[0], y = poll[1];for (int i = 0; i < 4; ++i) {int mx = x + dx[i], my = y + dy[i];//没有越界,并且像素值和初始像素值相同if (mx >= 0 && mx < m && my >= 0 && my < n && image[mx][my] == curColor) {queue.offer(new int[]{mx, my});image[mx][my] = color;}}}return image;}2.深度优先遍历
int[] dx = {-1, 1, 0, 0};int[] dy = {0, 0, -1, 1};public int[][] floodFill(int[][] image, int sr, int sc, int color) {int currColor = image[sr][sc];if (currColor != color) {dfs(image, sr, sc, currColor, color);}return image;}public void dfs(int[][] image, int x, int y, int curColor, int color) {if (image[x][y] == curColor) {image[x][y] = color;}for (int i = 0; i < 4; ++i) {int mx = x + dx[i], my = y + dy[i];if (mx >= 0 && mx < image.length && my >= 0 && my < image[0].length && image[mx][my] == curColor) {dfs(image, mx, my, curColor, color);}}}三.岛屿的最大面积
1.题目描述
给你一个大小为
m x n的二进制矩阵grid。岛屿 是由一些相邻的
1(代表土地) 构成的组合,这里的「相邻」要求两个1必须在 水平或者竖直的四个方向上 相邻。你可以假设grid的四个边缘都被0(代表水)包围着。岛屿的面积是岛上值为
1的单元格的数目。计算并返回
grid中最大的岛屿面积。如果没有岛屿,则返回面积为0。
力扣:力扣
2.问题分析
这一题上一题相似,上一题是把像素相同的格子全部涂上颜色,这一题是寻找面积最大的岛屿,把能涂的格子全部涂上颜色,这一题是把一个岛屿的面积全部遍历从而求出面积,在给出的海域中有很多的岛屿,我们只需要每次记录面积最大的岛屿的面积,最后直接返回即可
广度优先遍历:遍历整个矩阵grid,找到为陆地(1),然后在这片陆地上进行遍历,把遍历到的陆地格子置为0,也就是海洋,队列中没有陆地格子了,说明这个岛屿全部都遍历完了,和记录的最大面积对比,最终直到全部的矩阵格子遍历完成,返回最大的面积
深度优先遍历:和广度优先的思路一样,唯一不一样的点就是找到岛屿后的遍历顺序,具体看代码
3代码实现
1.广度优先遍历
public int maxAreaOfIsland(int[][] grid) {int ans = 0;int[] dx = {-1, 1, 0, 0};int[] dy = {0, 0, -1, 1};for (int i = 0; i < grid.length; ++i) {for (int j = 0; j < grid[0].length; ++j) {if (grid[i][j] == 0)continue;LinkedList<int[]> queue = new LinkedList<>();queue.offer(new int[]{i, j});int count = 1;grid[i][j] = 0;while (!queue.isEmpty()) {int[] poll = queue.poll();for (int z = 0; z < 4; ++z) {int mx = poll[0] + dx[z], my = poll[1] + dy[z];if (mx >= 0 && my >= 0 && mx < grid.length && my < grid[0].length && grid[mx][my] != 0) {count++;grid[mx][my] = 0;queue.offer(new int[]{mx, my});}}}ans = Math.max(ans, count);}}return ans;}2.深度优先遍历
public int maxAreaOfIsland(int[][] grid) {int ans = 0;for (int i = 0; i < grid.length; ++i) {for (int j = 0; j < grid[0].length; ++j) {ans = Math.max(ans, dfs(grid, i, j));}}return ans;}public int dfs(int[][] grid, int x, int y) {if (x < 0 || y < 0 || x >= grid.length || y >= grid[0].length || grid[x][y] == 0)return 0;grid[x][y] = 0;int[] dx = {-1, 1, 0, 0};int[] dy = {0, 0, -1, 1};int ans = 1;for (int i = 0; i < 4; ++i) {int mx = x + dx[i], my = y + dy[i];ans += dfs(grid, mx, my);}return ans;}四.岛屿的周长
1.题目描述
给定一个
row x col的二维网格地图grid,其中:grid[i][j] = 1表示陆地,grid[i][j] = 0表示水域。网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
力扣:力扣
2.问题分析
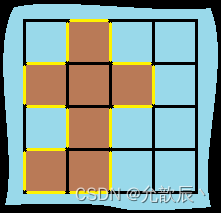
求面积我们可以求出来,但是求周长确实不容易想出来.但是经过我们仔细观察,我们就可以发现,如果岛屿的一边是水或者是边界地区的话,那么这一条边就可以作为周长的一部分(周长+1)
广度优先遍历:这一道题使用这个方法,没必要创建队列,我们只需要把这个二维数组遍历完成,判断每一块陆地的周长,这样我们就可以求出总的边长了,如果这一道题是有很多个岛屿,求周长最大的岛屿的周长,我们还是需要用到队列的
深度优先遍历:深度优先遍历和上边的几题一样的思路,具体看代码
3代码实现
1.广度优先遍历
static int[] dx = {0, 1, 0, -1};static int[] dy = {1, 0, -1, 0};public int islandPerimeter(int[][] grid) {int m = grid.length, n = grid[0].length;int ans = 0;for (int i = 0; i < m; ++i) {for (int j = 0; j < n; ++j) {if (grid[i][j] == 1) {for (int x = 0; x < 4; ++x) {int mx = i + dx[x], my = j + dy[x];if (mx < 0 || my < 0 || mx >= m || my >= n || grid[mx][my] == 0) {ans++;}}}}}return ans;}2.深度优先遍历
static int[] dx = {0, 1, 0, -1};static int[] dy = {1, 0, -1, 0};public int islandPerimeter(int[][] grid) {int m = grid.length, n = grid[0].length;int ans = 0;for (int i = 0; i < m; ++i) {for (int j = 0; j < n; ++j) {if (grid[i][j] == 1) {ans += dfs(i, j, grid, m, n);return ans;}}}return ans;}public int dfs(int x, int y, int[][] grid, int m, int n) {if (x < 0 || y < 0 || x >= m || y >= n || grid[x][y] == 0)return 1;if (grid[x][y] == 2)return 0;grid[x][y] = 2;int sum = 0;for (int i = 0; i < 4; ++i) {int mx = x + dx[i], my = y + dy[i];sum += dfs(mx, my, grid, m, n);}return sum;}相关文章:
Java之深度优先(DFS)和广度优先(BFS)及相关题目
目录 一.深度优先遍历和广度优先遍历 1.深度优先遍历 2.广度优先遍历 二.图像渲染 1.题目描述 2.问题分析 3代码实现 1.广度优先遍历 2.深度优先遍历 三.岛屿的最大面积 1.题目描述 2.问题分析 3代码实现 1.广度优先遍历 2.深度优先遍历 四.岛屿的周长 1.题目描…...

【链表OJ题(四)】反转链表
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录链表OJ题(四)1. 反转…...
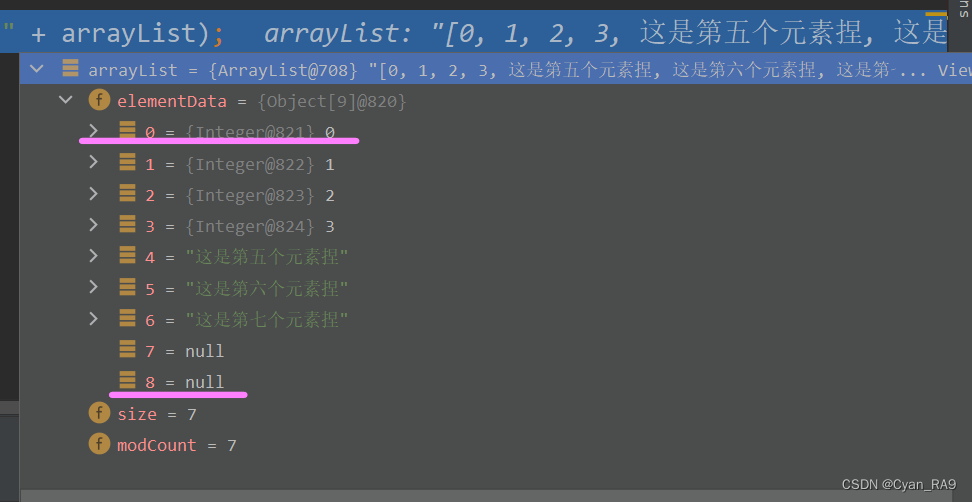
java ArrayList源码分析(深度讲解)
ArrayList类的底层实现ArrayList类的断点调试空参构造的分步骤演示(重要)带参构造的分步骤演示一、前言大家好,本篇博文是对单列集合List的实现类ArrayList的内容补充。之前在List集合的万字详解篇,我们只是拿ArrayList演示了List…...

【网络编程】零基础到精通——NIO基础三大组件和ByteBuffer
一. NIO 基础 non-blocking io 非阻塞 IO 1. 三大组件 1.1 Channel & Buffer channel 有一点类似于 stream,它就是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而之前的 st…...

操作系统 - 1. 绪论
目录操作系统基本概念概念特征功能操作系统的分类与发展手工操作单道批处理系统多道批处理系统分时系统实时系统操作系统的运行环境CPU 运行模式中断和异常的处理系统调用程序的链接与装入程序运行时内存映像和地址空间操作系统的体系结构操作系统的引导操作系统基本概念 概念…...

详谈parameterType与resultType的用法
resultMap 表示查询结果集与java对象之间的一种关系,处理查询结果集,映射到java对象。 resultMap 是一种“查询结果集---Bean对象”属性名称映射关系,使用resultMap关系可将将查询结果集中的列一一映射到bean对象的各个属性&#…...

【Linux】进程概念、fork() 函数 (干货满满)
文章目录📕 前言📕 进程概念📕 Linux下查看进程的两种方法方法一方法二📕 pid() 、ppid() 函数📕 fork() 函数、父子进程初识再理解📕 fork做了什么📕 如何理解 fork 有两个返回值📕…...
【动态规划】最长上升子序列、最大子数组和题解及代码实现
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

Ajax进阶篇02---跨域与JSONP
前言❤️ 不管前方的路多么崎岖不平,只要走的方向正确,都比站在原地更接近幸福 ❤️Ajax进阶篇02---跨域与JSONP一、Ajax进阶篇02---跨域与JSONP(1)同源策略1.1 什么是同源1.2 什么是同源策略(2)跨域2.1 什…...
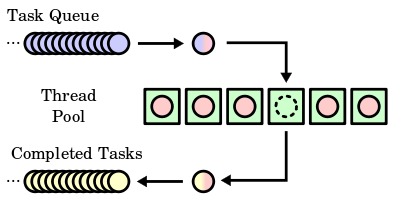
C 语言编程 — 线程池设计与实现
目录 文章目录目录线程池(Thread Pool)tiny-threadpool数据结构设计Task / JobTask / Job QueueWorker / ThreadThread Pool ManagerPublic APIsPrivate Functions运行示例线程池(Thread Pool) 线程池(Thread Pool&am…...

并发编程要点
Java并发编程中的三大特性分别是原子性、可见性和有序性,它们分别靠以下机制实现: 原子性:原子性指的是对于一个操作,要么全部执行,要么全部不执行。Java提供了一些原子性操作,例如AtomicInteger等…...

HDFS黑名单退役服务器
黑名单:表示在黑名单的主机IP地址不可以,用来存储数据。 企业中:配置黑名单,用来退役服务器。 黑名单配置步骤如下: 1)编辑/opt/module/hadoop-3.1.3/etc/hadoop目录下的blacklist文件 添加如下主机名称&…...

基于stm32智能语音电梯消毒系统
这次来分享个最近做的项目,stm32智能语音电梯消毒系统功能说明:在电梯,房间,客道区域内,检测到人,则执行相关动作!例如继电器开关灯,喷洒酒精等行为。手机app/微信小程序可以控制需要…...
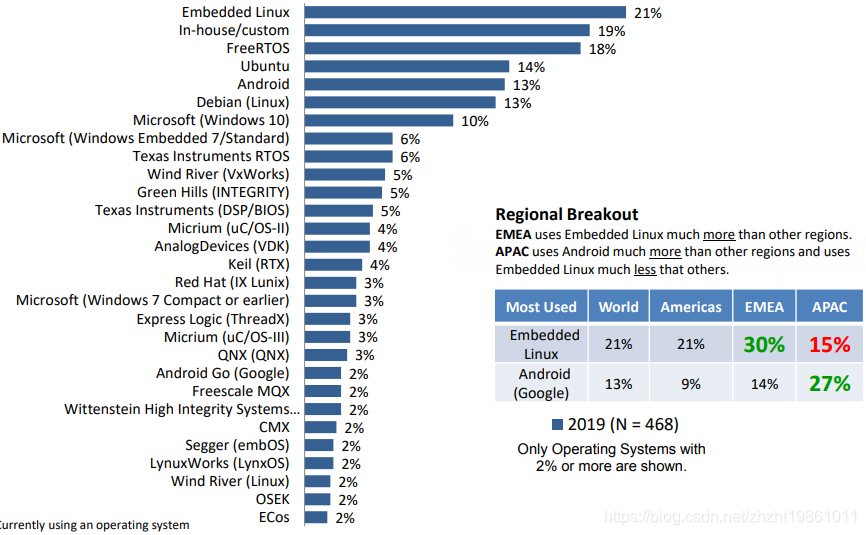
FreeRTOS系列第1篇---为什么选择FreeRTOS?
1.为什么学习RTOS? 作为基于ARM7、Cortex-M3硬件开发的嵌入式工程师,我一直反对使用RTOS。不仅因为不恰当的使用RTOS会给项目带来额外的稳定性风险,更重要的是我认为绝大多数基于ARM7、Cortex-M3硬件的项目,还没复杂到使用RTOS的地…...

基于.NET Core内置浏览器窗体应用程序界面框架
更多开源项目请查看:一个专注推荐.Net开源项目的榜单 平常我们在做项目过程中,桌面软件具备操作高效、利用本地计算机做一些复杂运算、或者设定快捷操作等优势,但是桌面软件也有很多缺点,比如升级问题、系统兼容问题、系统bug排查…...
【数据结构初阶】一文带你学会归并排序(递归非递归)
目录 前言 递归实现 代码实现 非递归实现 代码实现 总结 前言 归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。 作为一种典型的分而治之思想…...
Simulink壁咚(一)——What and How
目录 一、前言 二、Simulink 知多少 三、滤波算法 四、Model Verification 五、Model Coverage 六、Simulink测试实例 七、Simulink Test 八、Test Manager 九、Test Harness 十、 学习 一、前言 Simulink从2017b以后更加工程化和实用化,基于MBD的功能日趋…...
【PyTorch】Pytorch基础第0章
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052 这是目录PyTorch的简介PyTorch 构建深度学习模型的步骤搭建pytorch使用环境PyTorch的简介 PyTorch 是一个开源的机器学习框架,由 Facebook 的人工智能研究院(…...

Android学习总结
积累熟练掌握 Java 语言,面向对象分析设计能力,反射原理,自定义注解及泛型,多次采用设计模式重构公司项目;熟练掌握 IVM 原理,反射,动态代理以及对 ClassLoader 热修复有比较深的理解࿱…...

虚拟机ubuntu安装samba服务
安装samba apt-get install samba 新建一个共享目录 mkdir /home/l/work chmod 777 /home/l/work 配置服务 配置 /etc/samba/smb.confsudo smbpasswd -a l(添加用户名名称) 防火墙关闭 Ubuntu中 我们使用命令查看当前防火墙状态; sudo ufw status inactive状态是防火墙关闭…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...