从零开始实现大语言模型(一):概述
1. 前言
大家好,我是何睿智。我现在在做大语言模型相关工作,我用业余时间写一个专栏,给大家讲讲如何从零开始实现大语言模型。
从零开始实现大语言模型是了解其原理及领域大语言模型实现路径的最好方法,没有之一。已有研究证明,为特定任务定制或使用领域数据训练的大语言模型能在领域相关的评价指标上超过ChatGPT这样的通用大语言模型。
本专栏将从零开始讲解大语言模型理论原理step-by-step,提供一整套工业级文本数据处理,大语言模型构建、预训练、监督微调及指令微调,并行计算与分布式训练代码,并且从零开始解释实现代码line-by-line。
2. 大语言模型的模型结构
2017年,文章Attention is all you need提出了一种用于机器翻译的sequence-to-sequence架构模型Transformer。Transformer包含一个编码器(encoder)和一个解码器(decoder),编码器提取输入文本中的上下文信息,将其转变成多个向量,并传递给解码器。解码器接收编码器生成的向量,生成输出序列。
2018年,文章BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding使用 [MASK] 单词预测任务和句子前后顺序预测任务预训练Transformer模型的编码器,预训练后的模型被称为BERT(Bidirectional Encoder Representations from Transformers)。BERT模型的编码器架构及训练策略,使其非常擅长情感预测、文档分类等文本分类任务。
句子前后顺序预测任务,最初是预测两句话是否在原始预训练语料中相邻,后续改进为原始预训练语料中的两个相邻句子是否被交换顺序。
同年,OpenAI的文章Improving Language Understanding by Generative Pre-Training通过生成式预训练任务(根据一段话的前文预测后文)训练Transformer模型的解码器,预训练后的模型被称为GPT(Generative Pretrained Transformers)。GPT模型的解码器架构及训练策略,使其非常擅长机器翻译、文本摘要、编写计算机代码等文本生成任务。

Transformer、BERT及上述GPT模型网络结构核心是自注意力机制(self-attention)。自注意力机制可以让模型判断输入文本序列中不同token之间的相关性,使模型能够捕获输入文本数据中长距离依赖关系及上下文关系,因而比传统基于RNN等结构的模型具备更强的自然语言理解能力,生成的内容更加连贯且与上下文相关性更强。
token是指对文本分割处理后得到的最小单位,也是模型处理文本时的基本单元。训练数据处理时常提到的tokenization,即把自然语言文本处理成连续的token。Token可以是一个单词,一个字符,一个词组等等,取决于对训练数据做tokenization时采用的方法。
相比较于上面OpenAI的文章介绍的GPT-1模型,GPT-3模型结构没有做任何调整。GPT-3可以视为GPT-1模型的拓展,其模型层数更多,Embedding向量维度更高,参数量更大,并且使用了更大的预训练数据集。ChatGPT是通过OpenAI的InstructGPT论文中的方法在一个大的指令数据集(instruction dataset)上微调GPT-3而产生的。Meta的LLaMA等绝大部分大语言模型结构与GPT基本相同或仅仅做了非常微小的修改。
与Transformer模型相比,大语言模型GPT的结构非常简单,本质上它只是Transformer模型的解码器。但是GPT-3比原始Transformer模型解码器要大的多,原始Transformer模型解码器仅包含6个Transformer Block,但是GPT-3包含96个Transformer Block,共1750亿参数。GPT生成文本时每次仅预测下一个token,因此它也被视为一种自回归模型(autoregressive model)。

尽管GPT只相当于Transformer模型的解码器,而不是像Transformer那样明确被用于解决机器翻译任务的sequence-to-sequence模型,且训练模型的下一个token预测任务也不是专门针对机器翻译的任务,但是它也能够执行机器翻译任务,且大语言模型机器翻译效果比一般机器翻译模型都相对好。
大语言模型这种能够执行没有被明确训练的能力被称为“涌现(emerging property)”。涌现是一种没有使用相同任务明确训练,而是模型在学习了大量各种各样语言的语料之后自然而然出现的能力。大语言模型中的这种涌现现象证明了其具备非常强大的能力,部分专家学者认为其具备一定的通用人工智能雏形,截止目前大家已经发现并认可了大语言模型的广阔应用前景。
3. 大语言模型的训练方法
如下图所示,大语言模型的训练方法通常包含预训练(pretraining)和微调(finetuning)。
预训练是指使用大量无标签的、多样化的文本数据(raw text),通过下一个token预测任务(next token prediction task)训练模型,使模型能够了解自然语言文本中的语法及知识。预训练后的模型被称为基础模型(base model or foundational model),如GPT-3(ChatGPT对应的基础模型)。基础模型一般具有比较强的文本补全(text completion)及小样本学习(few-shot learning)能力。
文本补全是指模型能够根据用户输入的上文,完成相应的下文。小样本学习是指不用大量训练数据训练或微调模型,而是提供几个具体任务的示例,模型也能够输出比较不错的结果。
可以使用针对特定任务或具体领域的小数据集微调模型参数,使基础模型具备如ChatGPT这样的对话能力。最流行的两类微调大语言模型的方法为指令微调(instruction-finetuning)和监督微调(finetuning for classification tasks)。指令微调是指使用如下所示的带标签的(指令-答案)数据集继续训练基础模型,监督微调是指使用(文本-类别标签)这样的带标签数据集继续训练基础模型。
{"instruction": "请把下面的中文翻译成英文:\n我爱你。","answer": "I love you."
}

“raw"的意思为"原始的”,是指用于预训练模型的数据不包含任何使用监督学习方法训练传统机器学习模型或深度学习模型时用到的标签信息。预训练大语言模型的方法被称为自监督学习(self-supervised learning),预训练模型的标签数据使用一定的规则从输入文本中自动生成。
使用raw text训练模型并不意味着不对用于预训练的文本数据做任何处理。如在预训练之前,通常会使用一系列文本预处理方法对文本数据进行过滤。已有研究表明,预训练大语言模型的文本质量越高,则模型能力越强。
4. 大语言模型的训练数据
预训练GPT-3的数据来自5个不同的数据集,共包含3000亿tokens。其中CommonCrawl (filtered)是采用一定规则从CommonCrawl数据集过滤得到的一个质量相对高的子集,WebText2是Reddit网站上获得3个及以上点赞的帖子中的外部链接所包含的网页文本(外部链接指向其他网页,WebText2收集了这些链接指向网页的文本内容),Books1可能来自古腾堡计划(Project Gutenberg,古腾堡计划是一个数字化图书馆,致力于向公众提供免费的电子书),Books2可能来自Libgen(Libgen是一个知名的免费图书共享平台,用户可以通过该平台获取各种电子书、学术论文和期刊等资源),Wikipedia数据集由英文维基百科组成。
| 数据集名称 | 描述 | token数量 | 在训练数据集中的比例 |
|---|---|---|---|
| CommonCrawl (filtered) | Web crawl data | 410 billion | 60% |
| WebText2 | Web crawl data | 19 billion | 22% |
| Books1 | Internet-based book corpus | 12 billion | 8% |
| Books2 | Internet-based book corpus | 55 billion | 8% |
| Wikipedia | High-quality text | 3 billion | 3% |
GPT-3之后的大语言模型进一步拓展了训练模型的数据集,如Meta的LLaMA还使用了Arxiv网站中的论文数据集(92GB)及StackExchange网站中与代码相关的问答数据集(78GB)。国内的大语言模型也针对性地增加了训练集中的中文训练数据占比。
GPT-3论文作者没有公开他们用到的训练数据集,但是有个类似的开源数据集The Pile,该数据集的信息可以点击链接查看详情:https://pile.eleuther.ai/。
训练GPT-3时并没有使用上表提到的5个数据集中的全部数据,而是从每个数据集中抽取了一部分数据,共同组成了训练模型的包含3000亿tokens的训练数据集。抽取数据的原则是:质量越高的数据集采样比例越高,质量越低的数据集采样比例越低。如CommonCrawl数据集共包含4100亿tokens,但是只从中抽取了1800亿tokens,WebText2虽然只包含190亿tokens,但是从中共抽取了660亿tokens,相当于将WebText2数据集重复了3.47遍。
5. 大语言模型的实现流程
从零开始实现大语言的流程共三阶段:构建大语言模型、预训练大语言模型、微调大语言模型。

大语言模型构建部分将详细介绍文本数据处理方法,构建训练大语言模型的Dataset及DataLoader;从零开始一步步解释并实现简单自注意力机制(simplified self-attention)、缩放点积注意力机制(scaled dot-product attention)、因果注意力机制(causal attention)、多头注意力机制(multi-head attention);并最终构建出OpenAI的GPT系列大语言模型GPTModel。
预训练部分将介绍并行计算与分布式机器学习方法原理,实现使用无标签文本数据训练大语言模型的方法,以及介绍大语言模型效果评估的基本方法。使用GPT-3同量级数据集预训练大语言模型的计算代价非常大,如果换算成相应云计算资源价值,预训练GPT-3大约需耗费460万美元。因此,该部分同时会介绍使用构建好的大语言模型加载开源大语言模型(如GPT-2)权重的方法。
虽然训练GPT-3的计算资源换算成相应云计算资源价值约460万美元,但如果已经具备一个足够大的GPU计算集群,训练GPT-3消耗的电费远远不需要460万美元。
第三阶段分别使用监督微调及指令微调方法,微调基础模型参数,使大语言模型具备文本分类及回答问题能力。
6. 结束语
从零开始实现大语言模型系列专栏旨在详细解释大语言模型的理论原理,并提供一套工业级实践代码。本文从一个高的视角概述了大语言模型的模型结构、训练方法及训练数据,并且介绍了从零开始实现大语言模型的流程。
大语言模型具备强大的自然语言理解及生成能力,短短一年时间,自然语言处理领域已经翻天覆地。实践证明,在大量无标签的自然语言文本上使用简单的生成式预训练任务能够产生强大到不可思议的模型,在大量无标签视频数据上使用生成式预训练任务是否也能够产生非常惊艳的模型呢?
2024年2月16日,OpenAI发布了首个视频生成模型Sora,能生成长达1分钟流畅且连贯的高清视频。看来,大模型要一统天下了!
相关文章:
从零开始实现大语言模型(一):概述
1. 前言 大家好,我是何睿智。我现在在做大语言模型相关工作,我用业余时间写一个专栏,给大家讲讲如何从零开始实现大语言模型。 从零开始实现大语言模型是了解其原理及领域大语言模型实现路径的最好方法,没有之一。已有研究证明&…...
科普文本分类背后的数学原理——最新版《数学之美》第14、15章读书笔记
新闻分类,或广义上的文本分类,其核心任务是根据文本内容将相似文本聚合在同一类别中。在新闻领域,这意味着将报道划分为财经、体育、军事等不同主题。人类执行此任务时,通过阅读和理解新闻的主旨来进行归类。然而,作者…...

华为云生态和快速入门
华为云生态 新技术催生新物种,新物种推动新生态 数字技术催生各类运营商去重塑并颠覆各行业的商业模式 从业务层面看,企业始终如一的目标是业务增长和持续盈利,围绕这些目标衍生出提质、增效、降本、安全、创新和合规的业务诉求,…...

卷积神经网络——LeNet——FashionMNIST
目录 一、整体结构二、model.py三、model_train.py四、model_test.py GitHub地址 一、整体结构 二、model.py import torch from torch import nn from torchsummary import summaryclass LeNet(nn.Module):def __init__(self):super(LeNet,self).__init__()self.c1 nn.Conv…...

k8s-第十二节-DaemonSet
DaemonSet是什么? DaemonSet 是一个确保全部或者某些节点上必须运行一个 Pod的工作负载资源(守护进程),当有node(节点)加入集群时, 也会为他们新增一个 Pod。 下面是常用的使用案例: 可以用来部署以下进程的pod 集群守护进程,如Kured、node-problem-detector日志收集…...

Mysql-内置函数
一.什么是函数? 函数是指一段可以直接被另外一段程序调用的程序或代码。 mysql内置了很多的函数,我们只需要调用即可。 二.字符串函数 MySQL中内置了很多字符串函数: 三.根据需求完成以下SQL编写 由于业务需求变更,企业员工的工号,统一为5位数,目前不足5位数的全…...

新浪API系列:支付API打造无缝支付体验,畅享便利生活(3)
在当今数字化时代,支付功能已经成为各类应用和平台的必备要素之一。作为开发者,要构建出安全、便捷的支付解决方案,新浪支付API是你不可或缺的利器。新浪支付API提供了全面而强大的接口和功能,帮助开发者轻松实现在线支付的集成和…...

终于弄明白了什么是EI!
EI是Engineering Index的缩写,中文意为“工程索引”,是由美国工程信息公司(Engineering Information, Inc.)编辑出版的著名检索工具。它始创于1884年,拥有超过一个世纪的历史,是全球工程界最权威的文献检索系统之一。EI虽然名为“…...

微信小程序常见页面跳转方式
1. wx.navigateTo() 保留当前页,跳转到不是 tabbar 的页面,会新增页面到页面栈。通过返回按钮或 wx.navigateBack()返回上一个页面。 2. wx.redirectTo() 跳转到不是 tabbar 的页面,替换当前页面。不能返回。 3. wx.switchTab() 跳转到 …...

Vim常用整理快捷键
一、光标跳转 参数释义w下一行首字符e下一行尾字符0跳至行首$跳至行尾gg跳至文首5gg跳至第五行gd标记跳转到当前光标所在的变量的定义位置fn找当前行后的n字符,跳转到n字符位置 二、修改类操作 参数释义D删除光标之后的字符dd删除整行x删除当前字符yy复制一行p向…...

【docker 把系统盘空间耗没了!】windows11 更改 ubuntu 子系统存储位置
系统:win11 ubuntu 22 子系统,docker 出现问题:系统盘突然没空间了,一片红 经过排查,发现 AppData\Local\packages\CanonicalGroupLimited.Ubuntu22.04LTS_79rhkp1fndgsc\ 这个文件夹竟然有 90GB 下面提供解决办法 步…...

前端如何让网页页面完美适配不同大小和分辨率屏幕
推荐使用postcss插件,它会自动将项目所有的px单位统一转换为vw等单位(包括npm安装的第三方组件),从而实现适配,具体配置规则可参考官网或npm网站介绍。 另外对于大屏的适配,需要缩放网页,可使用…...

gitlab-runner安装部署CI/CD
手动安装 卸载旧版: gitlab-runner --version gitlab-runner stop yum remove gitlab-runner下载gitlab对应版本的runner # https://docs.gitlab.com/runner/install/bleeding-edge.html#download-any-other-tagged-releasecurl -L --output /usr/bin/gitlab-run…...

数据分析案例-2024 年全电动汽车数据集可视化分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

H桥驱动器芯片详解
H桥驱动器芯片详解 上一篇文章讲解了H桥驱动器的控制原理,本文以汽车行业广泛应用的DRV8245芯片为例,详细讲解基于集成电路的H桥驱动器芯片。 1.概述 DRV824x-Q1系列器件是德州仪器(TI)的一款专为汽车应用设计的全集成H桥驱动器…...

哪个充电宝口碑比较好?怎么选充电宝?2024年口碑优秀充电宝推荐
在如今快节奏的生活中,充电宝已然成为我们日常生活中的必备品。然而,市场上充电宝品牌众多,质量参差不齐,如何选择一款安全、可靠且口碑优秀的充电宝成为了消费者关注的焦点。安全性能不仅关系到充电宝的使用寿命,更关…...

Memcached 介绍与详解及在Java Spring Boot项目中的使用与集成
Memcached 介绍 Memcached 是一种高性能的分布式内存对象缓存系统,主要用于加速动态Web应用以减少数据库负载,从而提高访问速度和性能。作为一个开源项目,Memcached 被广泛应用于许多大型互联网公司,如Facebook、Twitter 和 YouT…...

淮北在选择SCADA系统时,哪些因素会影响其稳定性?
关键字:LP-SCADA系统, 传感器可视化, 设备可视化, 独立SPC系统, 智能仪表系统,SPC可视化,独立SPC系统 在选择SCADA系统时,稳定性是一个关键因素,因为它直接影响到生产过程的连续性和安全性。以下是一些影响SCADA系统稳定性的因素: 硬件质量…...

Linux: 命令行参数和环境变量究竟是什么?
Linux: 命令行参数和环境变量究竟是什么? 一、命令行参数1.1 main函数参数意义1.2 命令行参数概念1.3 命令行参数实例 二、环境变量2.1 环境变量概念2.2 环境变量:PATH2.2.1 如何查看PATH中的内容2.2.2 如何让自己的可执行文件不带路径运行 2.3 环境变量…...

数学系C++ 类与对象 STL(九)
目录 目录 面向对象:py,c艹,Java都是,但c是面向过程 特征: 对象 内敛成员函数【是啥】: 构造函数和析构函数 构造函数 复制构造函数/拷贝构造函数: 【……】 实参与形参的传递方式:值…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...
java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流 前情提要文章介绍一、函数伊始1.1 合格的函数1.2 有形的函数2. 函数对象2.1 函数对象——行为参数化2.2 函数对象——延迟执行 二、 函数编程语法1. 函数对象表现形式1.1 Lambda表达式1.2 方法引用(Math::max) 2 函数接口…...
鸿蒙Navigation路由导航-基本使用介绍
1. Navigation介绍 Navigation组件是路由导航的根视图容器,一般作为Page页面的根容器使用,其内部默认包含了标题栏、内容区和工具栏,其中内容区默认首页显示导航内容(Navigation的子组件)或非首页显示(Nav…...
Axure零基础跟我学:展开与收回
亲爱的小伙伴,如有帮助请订阅专栏!跟着老师每课一练,系统学习Axure交互设计课程! Axure产品经理精品视频课https://edu.csdn.net/course/detail/40420 课程主题:Axure菜单展开与收回 课程视频:...
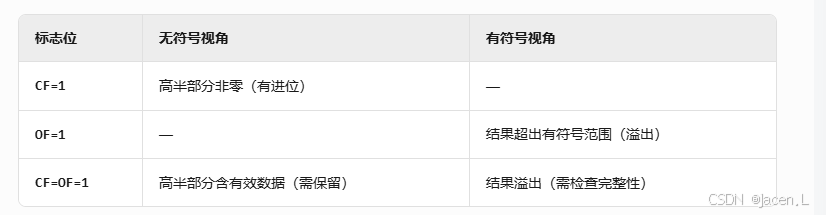
【汇编逆向系列】六、函数调用包含多个参数之多个整型-参数压栈顺序,rcx,rdx,r8,r9寄存器
从本章节开始,进入到函数有多个参数的情况,前面几个章节中介绍了整型和浮点型使用了不同的寄存器在进行函数传参,ECX是整型的第一个参数的寄存器,那么多个参数的情况下函数如何传参,下面展开介绍参数为整型时候的几种情…...