Linux-scheduler之负载均衡(二)
四、调度域
SDTL结构
linux内核使用SDTL结构体来组织CPU的层次关系
struct sched_domain_topology_level {sched_domain_mask_f mask; //函数指针,用于指定某个SDTL的cpumask位图sched_domain_flags_f sd_flags; //函数指针,用于指定某个SDTL的标志位int flags; int numa_level;struct sd_data data;
#ifdef CONFIG_SCHED_DEBUGchar *name;
#endif
};
标志位
#define SD_BALANCE_NEWIDLE 0x0001 /* Balance when about to become idle */
#define SD_BALANCE_EXEC 0x0002 /* Balance on exec */
#define SD_BALANCE_FORK 0x0004 /* Balance on fork, clone */
#define SD_BALANCE_WAKE 0x0008 /* Balance on wakeup */
#define SD_WAKE_AFFINE 0x0010 /* Wake task to waking CPU */
#define SD_ASYM_CPUCAPACITY 0x0020 /* Domain members have different CPU capacities */
#define SD_SHARE_CPUCAPACITY 0x0040 /* Domain members share CPU capacity */
#define SD_SHARE_POWERDOMAIN 0x0080 /* Domain members share power domain */
#define SD_SHARE_PKG_RESOURCES 0x0100 /* Domain members share CPU pkg resources */
#define SD_SERIALIZE 0x0200 /* Only a single load balancing instance */
#define SD_ASYM_PACKING 0x0400 /* Place busy groups earlier in the domain */
#define SD_PREFER_SIBLING 0x0800 /* Prefer to place tasks in a sibling domain */
#define SD_OVERLAP 0x1000 /* sched_domains of this level overlap */
#define SD_NUMA 0x2000 /* cross-node balancing */
| SD_BALANCE_NEWIDLE | 当CPU变为空闲后做负载均衡调度 |
| SD_BALANCE_EXEC | 进程调用exec是会重新选择一个最优的CPU的来执行,参考sched_exec()函数 |
| SD_BALANCE_FORK | fork出新进程后会选择最优CPU,参考wake_up_new_task()函数 |
| SD_BALANCE_WAKE | 唤醒时负载均衡,参考wake_up_process()函数 |
| SD_WAKE_AFFINE | 支持wake affine特性 |
| SD_ASYM_CPUCAPACITY | 该调度域有不同架构的CPU,如大/小核cpu |
| SD_SHARE_CPUCAPACITY | 调度域中的CPU都是可以共享CPU资源的,描述SMT调度层级 |
| SD_SHARE_POWERDOMAIN | 该调度域中的CPU可以共享电源域 |
| SD_SHARE_PKG_RESOURCES | 该调度域中的CPU可以共享高速缓存 |
| SD_ASYM_PACKING | 描述SMT调度层级相关的一些例外 |
| SD_NUMA | 描述NUMA调度层级 |
| SD_SERIALIZE | |
| SD_OVERLAP | |
| SD_PREFER_SIBLING |
调度组是负载均衡的最小单位。
五、CPU调度域拓扑
CPU的调度域拓扑结构可以参考以下三张图(图来自互联网)



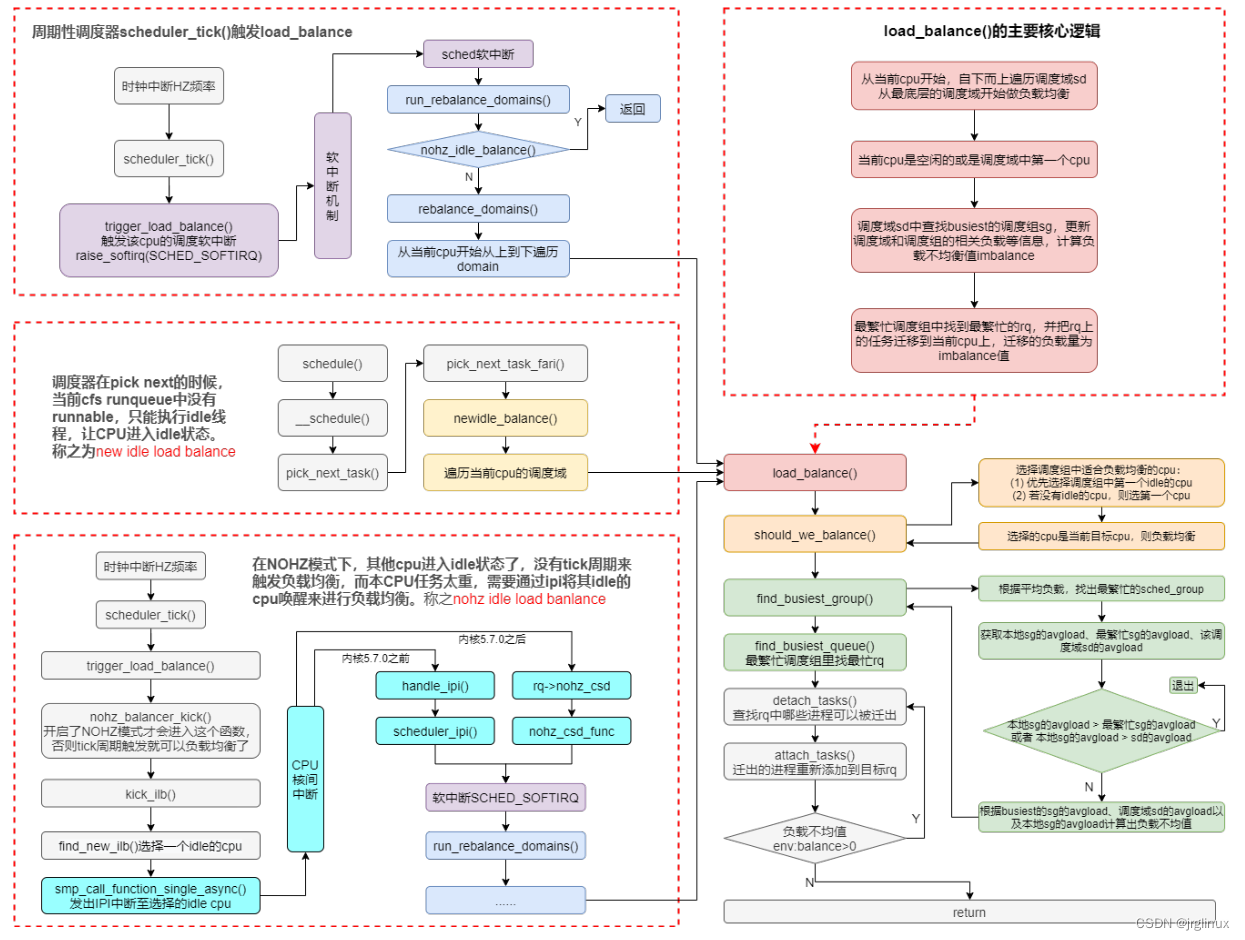
六、负载均衡
load-balance的逻辑比较复杂,可以参考我整理的如下图的整体逻辑框架:
lb_env()结构体
struct lb_env {struct sched_domain *sd;struct rq *src_rq;int src_cpu;int dst_cpu;struct rq *dst_rq;struct cpumask *dst_grpmask;int new_dst_cpu;enum cpu_idle_type idle;long imbalance;/* The set of CPUs under consideration for load-balancing */struct cpumask *cpus;unsigned int flags;unsigned int loop;unsigned int loop_break;unsigned int loop_max;enum fbq_type fbq_type;enum migration_type migration_type;struct list_head tasks;
};
| 类型 | 成员 | 作用 | |
|---|---|---|---|
| struct sched_domain * | sd | 指向当前调度域 | |
| int | dst_cpu | 当前CPU(后续可能要把任务迁移到该CPU上) | |
| struct rq* | dst_rq | 当前CPU对应的就绪度列 | |
| struct cpumask * | dst_grpmask | 当前调度域里的第一个调度组的CPU位图 | |
| unsigned int | loop_break | 表示本地最多迁移32个进程(sched_nr_migrate_break默认值是32) | |
| struct cpumask * | cpus | load_balance_mask位图 |
find_busiest_group()函数
首先是两个数据结构:
sd_lb_stats 用于描述调度域里的相关信息,以及sg_lb_stats用于描述调度组里的相关信息
/** sd_lb_stats - Structure to store the statistics of a sched_domain* during load balancing.*/
struct sd_lb_stats {struct sched_group *busiest; /* Busiest group in this sd */struct sched_group *local; /* Local group in this sd */unsigned long total_load; /* Total load of all groups in sd */unsigned long total_capacity; /* Total capacity of all groups in sd */unsigned long avg_load; /* Average load across all groups in sd */unsigned int prefer_sibling; /* tasks should go to sibling first */struct sg_lb_stats busiest_stat;/* Statistics of the busiest group */struct sg_lb_stats local_stat; /* Statistics of the local group */
};/** sg_lb_stats - stats of a sched_group required for load_balancing*/
struct sg_lb_stats {unsigned long avg_load; /*Avg load across the CPUs of the group */unsigned long group_load; /* Total load over the CPUs of the group */unsigned long group_capacity;unsigned long group_util; /* Total utilization over the CPUs of the group */unsigned long group_runnable; /* Total runnable time over the CPUs of the group */unsigned int sum_nr_running; /* Nr of tasks running in the group */unsigned int sum_h_nr_running; /* Nr of CFS tasks running in the group */unsigned int idle_cpus;unsigned int group_weight;enum group_type group_type;unsigned int group_asym_packing; /* Tasks should be moved to preferred CPU */unsigned long group_misfit_task_load; /* A CPU has a task too big for its capacity */
#ifdef CONFIG_NUMA_BALANCINGunsigned int nr_numa_running;unsigned int nr_preferred_running;
#endif
};
6.1 负载均衡机制的触发
负载均衡机制是从注册软中断开始的
6.1.1 软中断注册
__init void init_sched_fair_class(void)
{
#ifdef CONFIG_SMPopen_softirq(SCHED_SOFTIRQ, run_rebalance_domains);#ifdef CONFIG_NO_HZ_COMMONnohz.next_balance = jiffies;nohz.next_blocked = jiffies;zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT);
#endif
#endif /* SMP */
}void open_softirq(int nr, void (*action)(struct softirq_action *))
{softirq_vec[nr].action = action;
}
注册了SCHED_SOFTIRQ的软中断,中断处理函数是run_rebalance_domains。
6.1.2 软中断触发
由scheduler_tick()在每个时钟节拍中会去检查是否需要load balance。
/** Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing.*/
void trigger_load_balance(struct rq *rq)
{/* Don't need to rebalance while attached to NULL domain */if (unlikely(on_null_domain(rq)))return;if (time_after_eq(jiffies, rq->next_balance)) //需要判断是否到了负载均衡的时间点raise_softirq(SCHED_SOFTIRQ);nohz_balancer_kick(rq); //该函数作用是什么?
}
nohz_balancer_kick用来触发nohz idle balance的,这是后面两个章节要仔细描述的内容。这里看起似乎注释不对,因为这个函数不但触发的周期性均衡,也触发了nohz idle balance。然而,其实nohz idle balance本质上也是另外一种意义上的周期性负载均衡,只是因为CPU进入idle,无法产生tick,因此让能产生tick的busy CPU来帮忙触发tick balance。而实际上tick balance和nohz idle balance都是通过SCHED_SOFTIRQ的软中断来处理,最后都是执run_rebalance_domains这个函数。
七、exec进程
/** sched_exec - execve() is a valuable balancing opportunity, because at* this point the task has the smallest effective memory and cache footprint.*/
void sched_exec(void)
{struct task_struct *p = current;unsigned long flags;int dest_cpu;raw_spin_lock_irqsave(&p->pi_lock, flags); //这里获取了p->pi_lock,后面migration_cpu_stop中会涉及该锁dest_cpu = p->sched_class->select_task_rq(p, task_cpu(p), SD_BALANCE_EXEC, 0); //这里选择目的cpuif (dest_cpu == smp_processor_id()) //如果dest_cpu就是当前cpu,可以释放锁并返回goto unlock;if (likely(cpu_active(dest_cpu))) {struct migration_arg arg = { p, dest_cpu };raw_spin_unlock_irqrestore(&p->pi_lock, flags);stop_one_cpu(task_cpu(p), migration_cpu_stop, &arg); //这里进行目的cpu的进程迁移return;}
unlock:raw_spin_unlock_irqrestore(&p->pi_lock, flags);
}
stop_one_cpu(task_cpu(p), migration_cpu_stop, &arg);这句函数的作用是什么。
stop_one_cpu是停止某个cpu的运行,非SMP和SMP下实现不一样。非SMP下,stop_one_cpu的实现其实就是关抢占、执行函数、开抢占。
SMP架构下,stop_one_cpu实现:
该函数是在执行完函数fn之后再返回,但是不能保证执行fn的时候cpu还一直在线。
int stop_one_cpu(unsigned int cpu, cpu_stop_fn_t fn, void *arg)
{struct cpu_stop_done done;struct cpu_stop_work work = { .fn = fn, .arg = arg, .done = &done };cpu_stop_init_done(&done, 1);if (!cpu_stop_queue_work(cpu, &work))return -ENOENT;/** In case @cpu == smp_proccessor_id() we can avoid a sleep+wakeup* cycle by doing a preemption:*/cond_resched();wait_for_completion(&done.completion);return done.ret;
}
migration_cpu_stop函数
主要是两个拿锁的地方,未能理解为何需要那样的判断,rq->lock以及p->pi_lock
/** migration_cpu_stop - this will be executed by a highprio stopper thread* and performs thread migration by bumping thread off CPU then* 'pushing' onto another runqueue.*/
static int migration_cpu_stop(void *data)
{struct migration_arg *arg = data;struct task_struct *p = arg->task;struct rq *rq = this_rq();struct rq_flags rf;/** The original target CPU might have gone down and we might* be on another CPU but it doesn't matter.*/local_irq_disable();/** We need to explicitly wake pending tasks before running* __migrate_task() such that we will not miss enforcing cpus_ptr* during wakeups, see set_cpus_allowed_ptr()'s TASK_WAKING test.*/flush_smp_call_function_from_idle();raw_spin_lock(&p->pi_lock);rq_lock(rq, &rf);/* 这个地方为何一定要task_rq == rq才能去迁移呢?rq是当前正在执行任务的cpu的rq,其rq->lock拿着,与task_rq(p) != rq有何冲突?没能理解。会不会是迁移操作时需要获取p所在rq的lock,以及目标rq的lock,那样的话假设task_rq(p)不等于rq,拿两个rq->lock不就好了?* If task_rq(p) != rq, it cannot be migrated here, because we're* holding rq->lock, if p->on_rq == 0 it cannot get enqueued because* we're holding p->pi_lock.*/if (task_rq(p) == rq) { //必须是p所在的rq与当前cpu的rq是同一个才能迁移if (task_on_rq_queued(p)) //必须p是on rq才能迁移rq = __migrate_task(rq, &rf, p, arg->dest_cpu);elsep->wake_cpu = arg->dest_cpu;}rq_unlock(rq, &rf);raw_spin_unlock(&p->pi_lock);local_irq_enable();return 0;
}
八、fork进程
/** wake_up_new_task - wake up a newly created task for the first time.** This function will do some initial scheduler statistics housekeeping* that must be done for every newly created context, then puts the task* on the runqueue and wakes it.*/
void wake_up_new_task(struct task_struct *p)
{struct rq_flags rf;struct rq *rq;raw_spin_lock_irqsave(&p->pi_lock, rf.flags);p->state = TASK_RUNNING;
#ifdef CONFIG_SMP/** Fork balancing, do it here and not earlier because:* - cpus_ptr can change in the fork path* - any previously selected CPU might disappear through hotplug** Use __set_task_cpu() to avoid calling sched_class::migrate_task_rq,* as we're not fully set-up yet.*/p->recent_used_cpu = task_cpu(p);rseq_migrate(p);__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
#endifrq = __task_rq_lock(p, &rf);update_rq_clock(rq);post_init_entity_util_avg(p);activate_task(rq, p, ENQUEUE_NOCLOCK);trace_sched_wakeup_new(p);check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMPif (p->sched_class->task_woken) {/** Nothing relies on rq->lock after this, so its fine to* drop it.*/rq_unpin_lock(rq, &rf);p->sched_class->task_woken(rq, p);rq_repin_lock(rq, &rf);}
#endiftask_rq_unlock(rq, p, &rf);
}
相关文章:
Linux-scheduler之负载均衡(二)
四、调度域 SDTL结构 linux内核使用SDTL结构体来组织CPU的层次关系 struct sched_domain_topology_level {sched_domain_mask_f mask; //函数指针,用于指定某个SDTL的cpumask位图sched_domain_flags_f sd_flags; //函数指针,用于指定某个SD…...
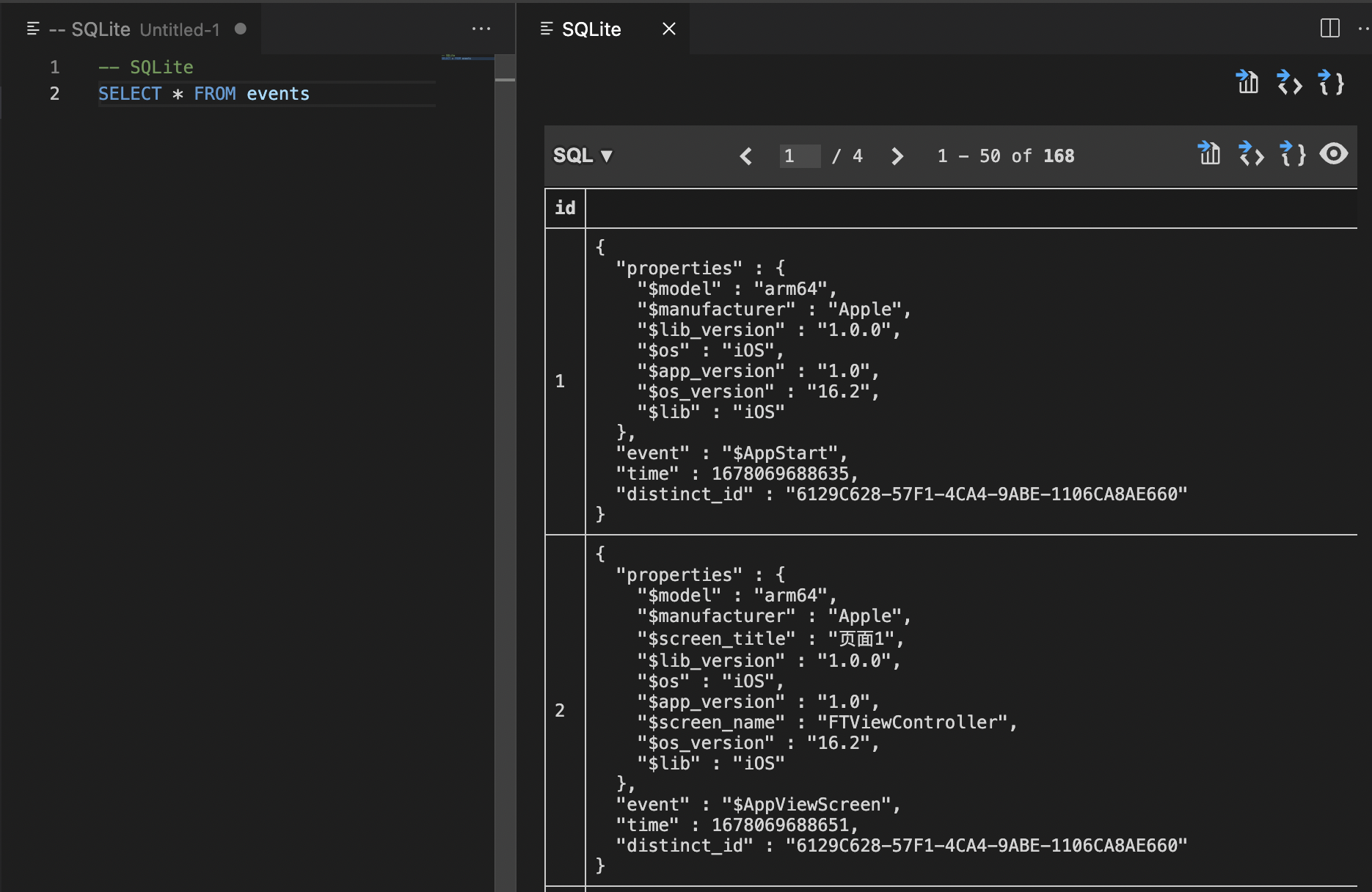
VScode第三方插件打开sqlite数据库
文章目录前言对比1.文本文件、表格软件打开2.专业软件3.pythonVScode 第三方库打开数据库1. 下载第三方库插件2.打开sqlite新建查询3.输入查询内容前言 最近在做的东西涉及SQLite数据库(一种常用在移动端的数据库类型,和mysql这些主流数据库也差不多&am…...

Kafka 监控
Kafka 监控主机监控JVM 监控集群监控监控 Kafka 客户端主机监控 主机监控 : 监控 Kafka 集群 Broker 所在的节点机器的性能 主机监控指标 : 机器负载 (Load) , CPU 使用率内存使用率 (空闲内存 , 已使用内存 (Used Memory) )磁盘 I/O 使用率 (读使用率/ 写使用率) , 网络 I/…...
MultipartFile与File的互转
MultipartFile与File的互转前言MultipartFile转File1.FileUtils.copyInputStreamToFile转换2.multipartFile.transferTo(tempFile);3. (推荐)FileUtils.writeByteArrayToFile(file, multipartFile.getBytes());File转MultipartFile前言 需求是上传Excel文件并读取E…...
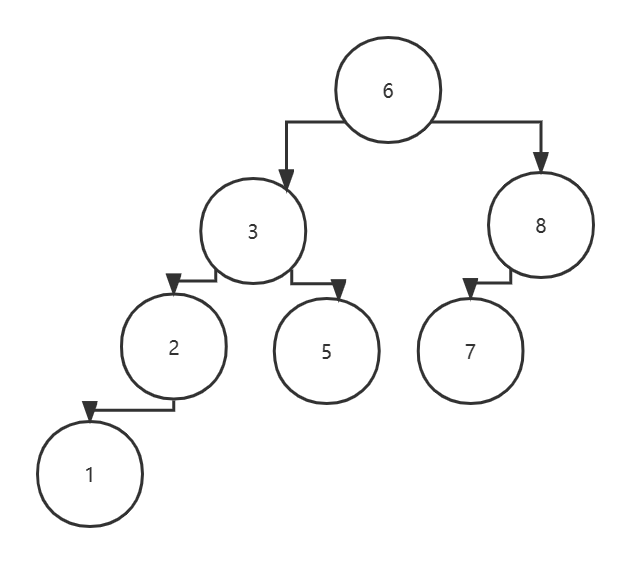
数据结构与算法基础-学习-15-二叉树
一、二叉树定义二叉树是N(N>0)个节点的有限集,它可能是空集或者由一个根节点及两棵互不相交的分别称作这个根的左子树和右子树的二叉树组成。二、二叉树特点1、每个节点最多两个孩子。(也就是二叉树的度小于等于2)2…...
接口测试要测试什么?
一. 什么是接口测试?为什么要做接口测试? 接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互…...

2023.03.12学习总结
项目部分写了内外菜单栏的伸缩,更新了导航栏,新增配置,scss变量 提交记录 学习了scss的使用和配置 ,设置了scss全局变量,组件样式 给element-plus配置了主题颜色,配置到了全局 http://t.csdn.cn/FhZYa …...

数据结构入门6-1(图)
目录 注 图的定义 图的基本术语 图的类型定义 图的存储结构 邻接矩阵 1. 邻接矩阵表示法 2. 使用邻接矩阵表示法创建无向网 3. 邻接矩阵表示法的优缺点 邻接表 1. 邻接表表示法 2. 通过邻接表表示法创建无向图 3. 邻接表表示法的优缺点 十字链表(有向…...
把C#代码上传到NuGet,大佬竟是我自己!!!
背景 刚发表完一篇博客总结自己写标准化C#代码的心历路程,立马就产生一个问题,就是我写好标准化代码后,一直存放磁盘的话,随着年月增加,代码越来越多,项目和版本的管理就会成为一个令我十分头疼的难题&…...

解决前端“\n”不换行问题
在日常开发过程中,换行显示是一种很常见的应用需求,但是偶然发现,有时候使用 "\n"并不会换行显示,只会被识别为空格,如下图。 通过上图可以看出,"\n"它被识别成了一个空格显示&#…...
Python打包成exe,文件太大问题解决办法(比保姆级还保姆级)
首先我要说一下,如果你不在乎大小,此篇直接别看了,因为我写过直接打包的,就多20M而已,这篇就别看了,点击查看不在乎大小直接打包这篇我觉得简单的令人发指 不废话,照葫芦画瓢就好 第1步&#…...

CSS弹性布局flex属性整理
1.align-items align-items属性:指定弹性布局内垂直方向的对齐方向。 常用属性: center 垂直居中展示 flex-start 头部对齐 flex-end 底部对齐 2. justify-content justify-content属性:属性(水平)对齐弹…...

14个你需要知道的实用CSS技巧
让我们学习一些实用的 CSS 技巧,以提升我们的工作效率。这些 CSS 技巧将帮助我们开发人员快速高效地构建项目。 现在,让我们开始吧。 1.CSS :in-range 和 :out-of-range 伪类 这些伪类用于在指定范围限制之内和之外设置输入样式。 (a) : 在范围内 如…...

【Flutter从入门到入坑之四】构建Flutter界面的基石——Widget
【Flutter从入门到入坑】Flutter 知识体系 【Flutter从入门到入坑之一】Flutter 介绍及安装使用 【Flutter从入门到入坑之二】Dart语言基础概述 【Flutter从入门到入坑之三】Flutter 是如何工作的 WidgetWidget 是什么呢?Widget 渲染过程WidgetElementRenderObjectR…...

中职网络空间安全windows渗透
目录 B-1:Windows操作系统渗透测试 1.通过本地PC中渗透测试平台Kali对服务器场景Windows进行系统服务及版本扫描渗透测试,并将该操作显示结果中Telnet服务对应的端口号作为FLAG提交;编辑 2.通过本地PC中渗透测试平台Kali对服务器场景Wind…...
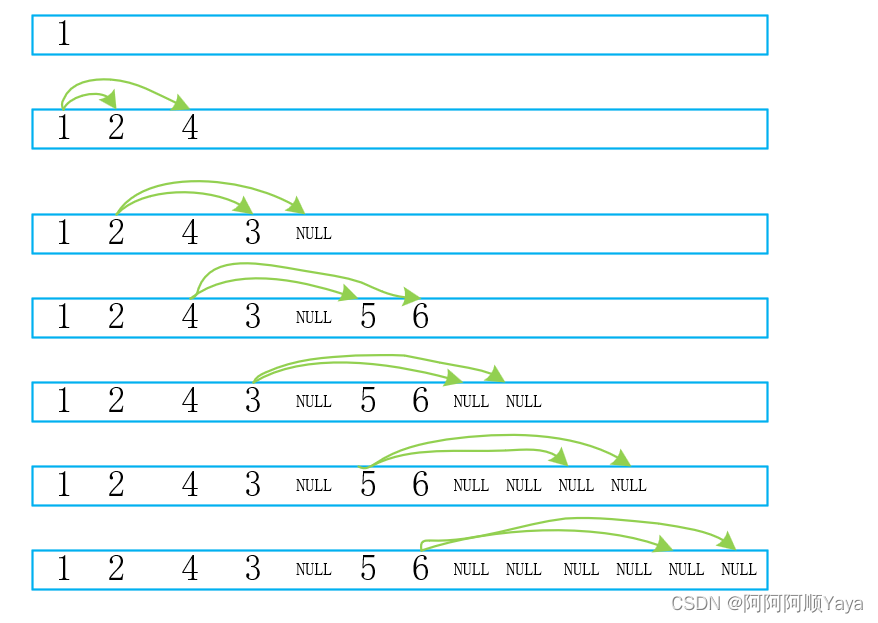
普通二叉树的操作
普通二叉树的操作1. 前情说明2. 二叉树的遍历2.1 前序、中序以及后序遍历2.1.1 前序遍历2.1.2 中序遍历、后序遍历2.2 题目练习2.2.1 求一棵二叉树的节点个数2.2.2 求一棵二叉树的叶节点个数2.2.3 求一棵二叉树第k层节点的个数2.2.4 求一棵二叉树的深度2.2.5 在一棵二叉树中查找…...

Oracle:递归树形结构查询功能
概要树状结构通常由根节点、父节点(PID)、子节点(ID)和叶节点组成。查询语法SELECT [LEVEL],* FROM table_name START WITH 条件1 CONNECT BY PRIOR 条件2 WHERE 条件3 ORDER BY 排序字段说明:LEVEL—伪列࿰…...

MongoDB数据库性能监控详解
目录一、MongoDB启动超慢1、启动日常卡住,根本不用为了截屏而快速操作,MongoDB启动真的超级慢~~2、启动MongoDB配置服务器,间歇性失败。3、查看MongoDB日志,分析“MongoDB启动慢”的原因。4、耗时“一小时”,MongoDB启…...

python不要再使用while死循环,使用定时器代替效果更佳!
在python开发的过程中,经常见到小伙伴直接使用while True的死循环sleep的方式来保存程序的一直运行。 这种方式虽然能达到效果,但是说不定什么时候就直接崩溃了。并且,在Linux环境中在检测到while True的未知进程就会直接干掉。 面对这样的…...
什么是接口测试?十年阿里测试人教你怎样做接口测试
一 什么是接口? 接口测试主要用于外部系统与系统之间以及内部各个子系统之间的交互点,定义特定的交互点,然后通过这些交互点来,通过一些特殊的规则也就是协议,来进行数据之间的交互。接口测试主要用于外部系统与系统之…...

python智能ai技术的智慧城市便民服务管理中心平台_668r7c05
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心技术功能模块应用场景优势与创新项目技术支持获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目…...

开源项目治理:ECC 社区贡献指南与协作模式
作者注:本文基于 ECC 项目的开源治理实践,帮助中国开发者理解如何参与大型开源项目并建立有效的协作流程。项目开源地址:github.com/affaan-m/ECC摘要 ECC(Everything Claude Code)是一个拥有 170 贡献者、28K Forks 的…...

北航毕业论文LaTeX模板:3天掌握专业排版,告别格式焦虑
北航毕业论文LaTeX模板:3天掌握专业排版,告别格式焦虑 【免费下载链接】BUAAthesis 北航毕设论文LaTeX模板 项目地址: https://gitcode.com/gh_mirrors/bu/BUAAthesis 还在为毕业论文格式反复修改而焦虑吗?每年毕业季,无数…...

抖音内容保存技术方案:开源下载工具深度解析与应用实践
抖音内容保存技术方案:开源下载工具深度解析与应用实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

Windows热键侦探:一键揪出占用你快捷键的“元凶“
Windows热键侦探:一键揪出占用你快捷键的"元凶" 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

职场新人不会写自我介绍怎么办?AI三分钟帮你搞定,面试邀约直接翻倍!
嘿,各位刚踏入职场的小萌新、想跳槽但又苦于没新项目亮点的打工人!你是不是也遇到过这种尴尬:辛辛苦苦写完简历,最后却卡在“自我介绍”或者“个人总结”那块? 要么就是寥寥几句套话,像“本人性格开朗&…...

AI专著生成神器来袭!用AI写专著,20万字专著轻松到手!
创新是学术专著的核心,也是写作中最具挑战性的部分。一部合格的专著不能仅仅是已有成果的简单堆叠,而是需要展现贯穿整本书的独到见解、理论框架或者研究方法。面对浩如烟海的学术文献,寻找那些尚未被挖掘的研究空白实属不易——有时选题已经…...

如何利用 AI Agent 优化日常办公自动化流程?
用 AI Agent 优化办公自动化,核心是把高频重复、规则清晰、跨系统搬运的工作交给 Agent,人专注决策与创意;先试点、再打通数据、最后规模化,通常能把事务性时间压减 50%–80%。下面从落地框架、核心场景、搭建步骤、工具选型与避坑…...
)
保姆级教程:在Vue3项目中用ZLMediaKit+WebRTC实现超低延迟监控直播(附完整代码)
Vue3WebRTC超低延迟监控直播实战指南 在实时视频监控领域,延迟是衡量系统性能的核心指标之一。传统RTSP流媒体方案在Web端实现时,往往面临秒级甚至更长的延迟,这在对实时性要求极高的安防监控、工业检测等场景中成为致命短板。本文将深入探讨…...
)
告别串口助手:用Python脚本实现YMODEM协议自动升级嵌入式固件(附源码)
告别串口助手:用Python脚本实现YMODEM协议自动升级嵌入式固件(附源码) 在嵌入式设备量产测试和远程维护场景中,传统的手动串口工具操作已成为效率瓶颈。每次固件升级都需要人工介入,不仅耗时费力,还容易因…...