【机器学习】在【Pycharm】中的实践教程:使用【逻辑回归模型】进行【乳腺癌检测】
目录
案例背景
具体问题
1. 环境准备
小李的理解
知识点
2. 数据准备
2.1 导入必要的库和数据集
小李的理解
知识点
2.2 数据集基本信息
小李的理解
知识点
注意事项
3. 数据预处理
3.1 划分训练集和测试集
小李的理解
知识点
注意事项
3.2 数据标准化
小李的理解
知识点
注意事项
4. 模型训练
4.1 初始化和训练逻辑回归模型
运行结果
编辑
小李的理解
知识点
注意事项
5. 模型评估
5.1 预测结果
小李的理解
知识点
注意事项
5.2 计算准确率
小李的理解
知识点
注意事项
5.3 混淆矩阵
小李的理解
知识点
注意事项
5.4 分类报告
小李的理解
知识点
注意事项
6. 结果可视化
6.1 绘制混淆矩阵
小李的理解
知识点
注意事项
完整代码
结论


专栏:机器学习笔记
pycharm专业版免费激活教程见资源,私信我给你发
python相关库的安装:pandas,numpy,matplotlib,statsmodels
总篇:学习路线
第一卷:线性回归模型
逻辑回归(Logistic Regression)是一种适用于二分类问题的机器学习方法。本文将围绕一个具体的乳腺癌检测案例,详细讲解如何在PyCharm中使用逻辑回归模型进行预测。我们将从数据准备、数据预处理、模型训练、模型评估和结果可视化几个方面进行详细说明,并通过完整的代码示例展示每个步骤。
案例背景
在本案例中,我们将使用经典的乳腺癌数据集(Breast Cancer Dataset)进行乳腺癌检测预测。该数据集包含569个样本,每个样本有30个特征,并标记为良性(0)或恶性(1)。我们的目标是使用这些特征训练一个逻辑回归模型,预测新的样本是良性还是恶性。
具体问题
我们需要解决以下几个具体问题:
- 如何加载并理解乳腺癌数据集。
- 如何对数据进行预处理以适合逻辑回归模型的训练。
- 如何训练逻辑回归模型并进行预测。
- 如何评估模型的性能。
- 如何对结果进行可视化以便于解释。
1. 环境准备
首先,确保你的开发环境中已经安装了必要的Python库:
pip install numpy pandas scikit-learn matplotlib seaborn
小李的理解
安装库是机器学习的基础步骤。我们需要安装一些流行的Python库,如numpy、pandas、scikit-learn、matplotlib和seaborn,这些库分别用于数值计算、数据处理、机器学习模型、绘图和数据可视化。
知识点
- 库的安装:使用
pip install命令安装所需的Python库。- 常用库:了解并熟悉常用的机器学习和数据处理库。
2. 数据准备
2.1 导入必要的库和数据集
我们使用scikit-learn库中的乳腺癌数据集。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer# 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target
小李的理解
scikit-learn提供了很多常用的数据集,load_breast_cancer()是用来加载乳腺癌数据集的方法。X是特征数据,y是目标标签(0表示良性,1表示恶性)。
知识点
- 数据集加载:使用
scikit-learn中的方法加载内置数据集。- 特征与标签:特征数据用于模型训练,目标标签用于分类。
2.2 数据集基本信息
将数据转换为Pandas DataFrame格式以便查看和处理,并打印数据集的前几行进行初步了解。
# 将数据转换为DataFrame格式
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y# 查看数据集的基本信息
print("数据集前五行:\n", df.head())
print("\n数据集描述统计信息:\n", df.describe())
print("\n数据集信息:")
df.info()
运行结果

小李的理解
我们使用pandas库将数据转换为DataFrame格式,这样可以方便地查看和处理数据。使用head()查看数据的前几行,使用describe()查看数据的描述统计信息,使用info()查看数据的基本信息,包括每列的数据类型和非空值数量。
知识点
- DataFrame:
pandas的核心数据结构,类似于电子表格,可以方便地操作和分析数据。- 数据描述:通过
head()、describe()和info()方法快速了解数据的基本情况。
注意事项
- 数据完整性:在加载数据时,确保数据没有缺失值。本数据集没有缺失值。
- 数据类型:特征值都是浮点型,而目标值是整数型。逻辑回归适用于这些数据类型。
3. 数据预处理
3.1 划分训练集和测试集
将数据集划分为训练集和测试集,以便后续模型的训练和评估。
from sklearn.model_selection import train_test_split# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 打印训练集和测试集的大小
print(f'训练集样本数: {X_train.shape[0]}')
print(f'测试集样本数: {X_test.shape[0]}')
运行结果
小李的理解
我们将数据集分为训练集和测试集,训练集用于训练模型,测试集用于评估模型的性能。train_test_split函数将数据按70%训练集和30%测试集的比例进行划分,并使用random_state=42保证每次运行结果一致。
知识点
- 数据划分:使用
train_test_split函数将数据集分为训练集和测试集。- 随机种子:
random_state参数保证结果的可重复性。
注意事项
- 随机种子:
random_state=42保证每次运行结果一致,方便调试和复现。- 测试集比例:通常使用70%的数据进行训练,30%的数据进行测试,但具体比例可以根据实际情况调整。
3.2 数据标准化
由于不同特征的取值范围不同,需要对数据进行标准化处理,使每个特征的取值范围相同。
from sklearn.preprocessing import StandardScaler# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 打印标准化后的部分数据
print(f'标准化后的训练数据前五行:\n {X_train[:5]}')
运行结果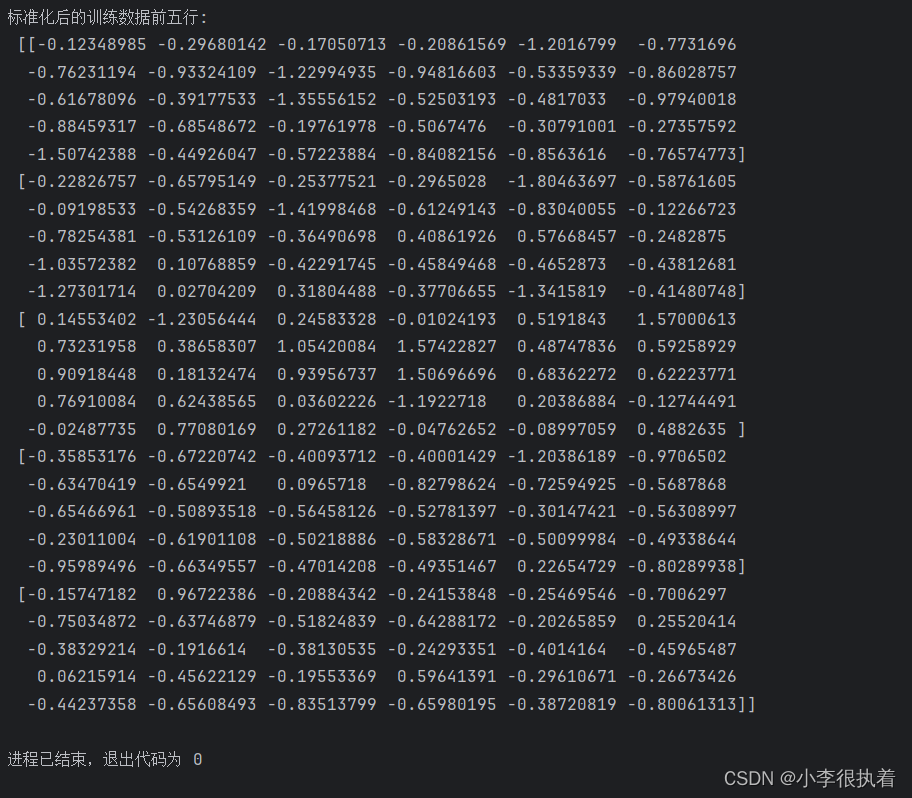
小李的理解
标准化是将每个特征缩放到均值为0、标准差为1的范围内,这样可以消除不同特征之间的量纲差异,使模型训练更加稳定。我们使用StandardScaler进行标准化,只对训练数据拟合,然后对训练和测试数据进行转换。
知识点
- 标准化:使用
StandardScaler将数据标准化,以消除特征之间的量纲差异。- 数据泄漏:在标准化时,只对训练数据进行拟合,然后对训练和测试数据进行转换。
注意事项
- 标准化方法:我们使用
StandardScaler将每个特征缩放到均值为0、标准差为1的范围内。- 数据泄漏:在标准化时,我们仅对训练数据拟合(fit),然后对训练和测试数据进行转换(transform),以避免数据泄漏。
4. 模型训练
4.1 初始化和训练逻辑回归模型
使用scikit-learn库中的逻辑回归模型对训练数据进行拟合。
from sklearn.linear_model import LogisticRegression# 初始化逻辑回归模型
model = LogisticRegression(max_iter=10000)# 训练模型
model.fit(X_train, y_train)# 打印模型的训练结果
print("逻辑回归模型训练完成")
运行结果

小李的理解
我们使用LogisticRegression类来初始化逻辑回归模型,并设置最大迭代次数为10000,以确保模型能够收敛。然后,我们使用训练数据拟合模型。
知识点
- 逻辑回归模型:
LogisticRegression类用于初始化逻辑回归模型。- 最大迭代次数:
max_iter参数用于设置模型的最大迭代次数,以确保模型能够收敛。
注意事项
- 最大迭代次数:
max_iter=10000确保模型能够收敛,即使数据集较大或特征较多。- 默认参数:初学者可以先使用默认参数,之后可以尝试调整参数以优化模型性能。
5. 模型评估
5.1 预测结果
使用训练好的模型对测试集进行预测。
# 预测
y_pred = model.predict(X_test)# 打印预测结果的前十个
print(f'预测结果前十个: {y_pred[:10]}')
运行结果

小李的理解
我们使用predict方法对测试数据进行预测,得到每个样本的预测标签。然后,我们打印预测结果的前十个样本。
知识点
- 模型预测:使用
predict方法对测试数据进行预测。- 预测标签:
predict方法返回每个样本的预测标签。
注意事项
- 预测输出:
predict方法输出每个样本的预测标签。- 预测概率:可以使用
predict_proba方法获取每个样本属于每个类别的概率。
5.2 计算准确率
计算模型在测试集上的准确率。
from sklearn.metrics import accuracy_score# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
运行结果
小李的理解
准确率是模型正确预测的样本数占总样本数的比例,是评估模型性能的一个重要指标。
知识点
- 准确率:使用
accuracy_score函数计算模型的准确率。- 模型评估:准确率是评估模型性能的一个重要指标。
注意事项
- 准确率定义:准确率是正确预测的样本数占总样本数的比例。
- 适用场景:对于类别不平衡的问题,仅使用准确率可能会导致误导,应结合其他指标。
5.3 混淆矩阵
生成并打印混淆矩阵,混淆矩阵可以直观地显示模型的分类性能。
from sklearn.metrics import confusion_matrix# 混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
运行结果

小李的理解
混淆矩阵是一个矩阵,用来评价分类模型的性能。矩阵的每一行表示实际类别,每一列表示预测类别。
知识点
- 混淆矩阵:使用
confusion_matrix函数生成混淆矩阵。- 矩阵解读:混淆矩阵的每一行表示实际类别,每一列表示预测类别。
注意事项
- 混淆矩阵解读:
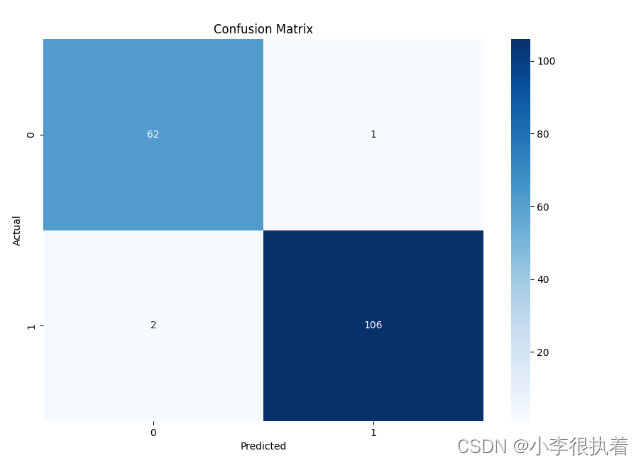
- 左上(TP):正确预测为正类的数量
- 右上(FP):错误预测为正类的数量
- 左下(FN):错误预测为负类的数量
- 右下(TN):正确预测为负类的数量
- 评估模型:通过混淆矩阵可以计算精确度、召回率等指标。
5.4 分类报告
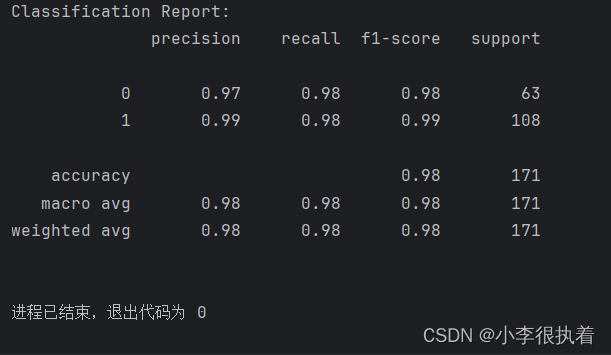
生成并打印分类报告,报告包括精确度、召回率和F1分数等指标。
from sklearn.metrics import classification_report# 分类报告
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)
运行结果
小李的理解
分类报告提供了每个类别的精确度、召回率和F1分数,以及整体的宏平均(macro avg)和加权平均(weighted avg)指标。这些指标可以帮助我们更全面地评估模型的性能。
知识点
- 分类报告:使用
classification_report函数生成分类报告。- 评估指标:分类报告包括精确度、召回率和F1分数等指标。
注意事项
- 精确度(Precision):预测为正类的样本中实际为正类的比例。
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例。
- F1分数(F1-score):精确度和召回率的调和平均数,综合考虑模型的准确性和召回能力。
6. 结果可视化
6.1 绘制混淆矩阵
使用Seaborn库对混淆矩阵进行可视化。
import matplotlib.pyplot as plt
import seaborn as sns# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
可视化结果
小李的理解
通过绘制混淆矩阵,我们可以直观地看到模型的分类效果。seaborn库提供了简洁的绘图方法,使得可视化更加美观和易于理解。
知识点
- 数据可视化:使用
seaborn库进行数据可视化。- 混淆矩阵图:通过绘制混淆矩阵图,可以直观地展示模型的分类效果。
注意事项
- 图像解释:混淆矩阵图表提供了直观的分类性能展示。
- 颜色选择:可以根据需要调整颜色映射,以便于区分不同类别。
完整代码
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns# 1. 加载数据集
data = load_breast_cancer()
X = data.data
y = data.target# 2. 数据准备
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y# 查看数据集的基本信息
print("数据集前五行:\n", df.head())
print("\n数据集描述统计信息:\n", df.describe())
print("\n数据集信息:")
df.info()# 3. 数据预处理
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 打印训练集和测试集的大小
print(f'训练集样本数: {X_train.shape[0]}')
print(f'测试集样本数: {X_test.shape[0]}')# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 打印标准化后的部分数据
print(f'标准化后的训练数据前五行:\n {X_train[:5]}')# 4. 模型训练
# 初始化逻辑回归模型
model = LogisticRegression(max_iter=10000)# 训练模型
model.fit(X_train, y_train)# 打印模型的训练结果
print("逻辑回归模型训练完成")# 5. 模型评估
# 预测
y_pred = model.predict(X_test)# 打印预测结果的前十个
print(f'预测结果前十个: {y_pred[:10]}')# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')# 混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)# 分类报告
class_report = classification_report(y_test, y_pred)
print('Classification Report:')
print(class_report)# 6. 结果可视化
# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()

结论
通过本文的讲解,在PyCharm中使用逻辑回归模型进行乳腺癌检测的预测。从数据准备、数据预处理、模型训练到结果评估与可视化,提供了详细的步骤和代码示例。通过这些步骤,你可以掌握如何应用逻辑回归模型进行疾病预测,并根据模型的评估结果优化和改进模型。
相关文章:
【机器学习】在【Pycharm】中的实践教程:使用【逻辑回归模型】进行【乳腺癌检测】
目录 案例背景 具体问题 1. 环境准备 小李的理解 知识点 2. 数据准备 2.1 导入必要的库和数据集 小李的理解 知识点 2.2 数据集基本信息 小李的理解 知识点 注意事项 3. 数据预处理 3.1 划分训练集和测试集 小李的理解 知识点 注意事项 3.2 数据标准化 小李…...
【搭建Nacos服务】centos7 docker从0搭建Nacos服务
前言 本次搭建基于阿里云服务器系统为(CentOS7 Linux)、Nacos(2.0.3)、Docker version 26.1.4 本次搭建基于一个新的云服务器 安装java yum install -y java-1.8.0-openjdk.x86_64安装驱动以及gcc等前置需要的命令 yum install …...

将 build.gradle 配置从 Groovy 迁移到 Kotlin
目录 时间轴 常用术语 脚本文件命名 转换语法 为方法调用添加圆括号 为分配调用添加 转换字符串 重命名文件扩展名 将 def 替换为 val 或 var 为布尔值属性添加 is 前缀 转换列表和映射 配置 build 类型 从 buildscript 迁移到插件块 查找插件 ID 执行重构 转…...
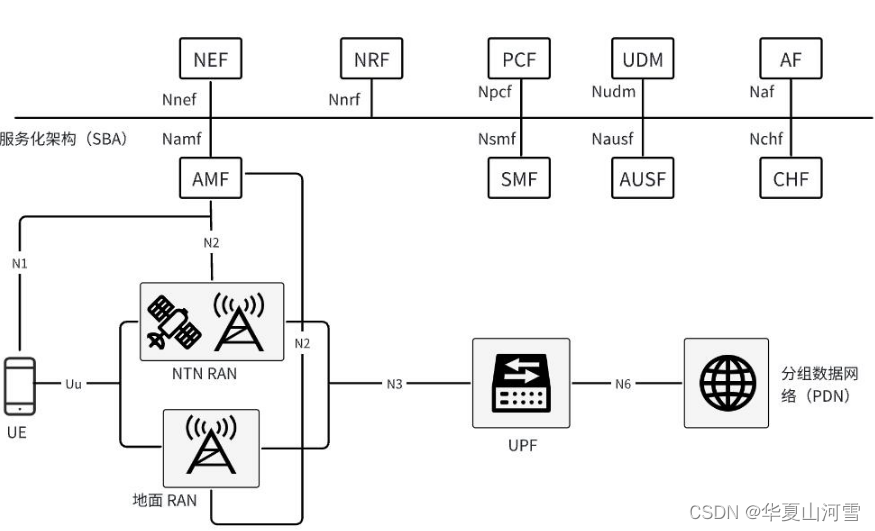
5G(NR) NTN 卫星组网架构
5G(NR) NTN 卫星组网架构 参考 3GPP TR 38.821 5G NTN 技术适用于高轨、低轨等多种星座部署场景,是实现星地网络融合发展的可行技术路线。5G NTN 网络分为用户段、空间段和地面段三部分。其中用户段由各种用户终端组成,包括手持、便携站、嵌入式终端、车…...

WEB安全-文件上传漏洞
1 需求 2 接口 3 MIME类型 在Web开发中,MIME(Multipurpose Internet Mail Extensions)类型用于标识和表示文档的格式。这些类型在HTTP请求和响应头中扮演着重要的角色,告诉浏览器如何解释和处理接收到的资源12。 以下是一些Web开发…...
Python函数 之 函数基础
print() 在控制台输出 input() 获取控制台输⼊的内容 type() 获取变量的数据类型 len() 获取容器的⻓度 (元素的个数) range() ⽣成⼀个序列[0, n) 以上都是我们学过的函数,函数可以实现⼀个特定的功能。我们将学习⾃⼰如何定义函数, 实现特定的功能。 1.函数是什么…...
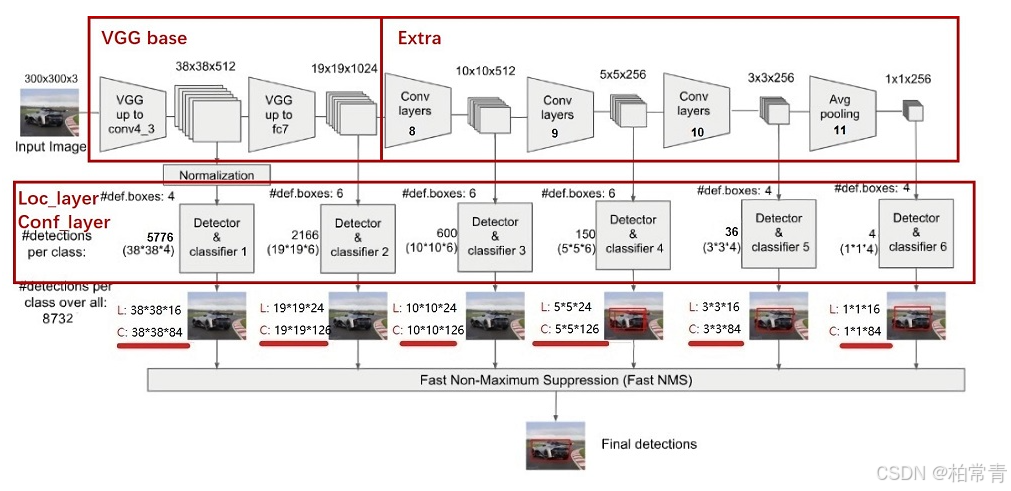
昇思25天学习打卡营第11天|SSD目标检测
SSD网络 目标检测问题可以分为以下两个问题:1)分类:所有类别的概率;2)定位: 4个值(中心位置x,y,宽w,高h) Single Shot MultiBox Detector,SSD:单阶段的目标检测算法,通过卷积神经网络进行特征…...

MySQL篇五:基本查询
文章目录 前言1. Create1.1 单行数据 全列插入1.2 多行数据 指定列插入1.3 插入否则更新1.4 替换 2. Retrieve2.1 SELECT 列2.1.1 全列查询2.1.2 指定列查询2.1.3 查询字段为表达式2.1.4 为查询结果指定别名2.1.5 结果去重 2.2 WHERE 条件2.2.1 练习 2.3 结果排序2.3.1 练习 …...
FreeBSD@ThinkPad x250因电池耗尽关机后无法启动的问题存档
好几次碰到电池耗尽FreeBSD关机,再启动,网络通了之后到了该出Xwindows窗体的时候,屏幕灭掉,网络不通,只有风扇在响,启动失败。关键是长按开关键后再次开机,还是启动失败。 偶尔有时候重启到单人…...

pdfplumber vs PyMuPDF:PDF文本、图像和表格识别的比较
pdfplumber vs PyMuPDF:PDF文本、图像和表格识别的比较 1. 文本提取pdfplumberPyMuPDF 2. 图像提取pdfplumberPyMuPDF 3. 表格提取pdfplumberPyMuPDF 总结 在处理PDF文件时,提取文本、图像和表格是常见的需求。本文将比较两个流行的Python PDF处理库:pdfplumber和PyMuPDF(fitz)…...

深入Django系列
Django简介与环境搭建 引言 在这个系列的第一天,我们将从Django的基本概念开始,逐步引导你搭建一个Django开发环境,并运行你的第一个Django项目。 Django简介 Django是一个开源的Web框架,它鼓励快速开发和干净、实用的设计。D…...

【Python】找Excel重复行
【背景】 找重复行虽然可以通过Excel实现,但是当数据量巨大时光是找结果就很费时间,所以考虑用Python实现。 【代码】 import pandas as pd# 读取Excel文件 file_path = your excel file path df = pd.read_excel(file_path)# 查找重复行 # 这里假设要检查所有列的重复项 …...

重读AI金典算法模型-GPT系列
2023年对于AI来说,可以算是一个里程碑式的年份,随着OpenAI的chatGPT的大火,遍地的生成式AI应用应运而生。在这些上层应用大放异彩的时候,我们需要了解一些底层的算法模型,并从中窥探出为什么时代选择了OpenAI的chatGPT…...

仙人掌中的SNMP检测不到服务器
登录有问题的服务器1.检测snmp localhost:~ # ps -ef|grep snmp root 55180 1 0 08:37 ? 00:00:08 /usr/sbin/snmpd -r -A -LF n /var/log/net-snmpd.log -p /var/run/snmpd.pid root 58436 53989 0 09:44 pts/0 00:00:00 grep --colorauto snmp2.检测…...
git只列出本地分支
git只列出本地分支 git branch --list git强制删除本地分支 git branch -D_error: the branch dlx-test is not fully merged. -CSDN博客文章浏览阅读648次。git branch -d 可以通过: git branch 查看所有本地分支及其名字,然后删除特定分支。git删除远程remote分支…...

算力狂飙|WAIC 2024上的服务器
7月7日,2024世界人工智能大会暨人工智能全球治理高级别会议(WAIC 2024)在上海落下帷幕。这场备受瞩目的AI盛宴与热辣夏日碰撞,吸引了全球科技、产业及学术界的广泛关注,线下参观人数突破30万人次,线上流量突…...
)
uniapp app端跳转第三方app(高德地图/百度地图为例)
1.先写一个picker选择器 <picker change"bindPickerChange" :value"index" :range"array"><view class"uni-input">{{array[index] || 打开第三方app }}</view></picker> 2.在data中定义好高德地图/百度地图…...
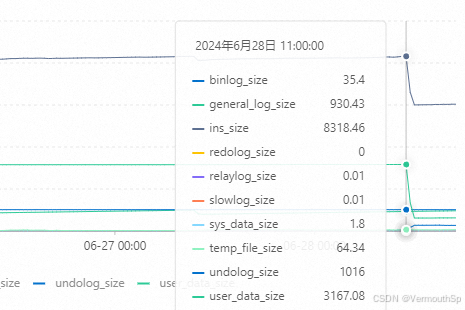
阿里云RDS云数据库库表恢复操作
最近数据库中数据被人误删了,记录一下恢复操作方便以后发生时进行恢复. 1.打开控制台,进入云数据库实例. 2.进入实例后 ,点击右侧的备份恢复,然后看一下备份时间点,中间这边都是阿里云自动备份的备份集,基本都是7天一备…...
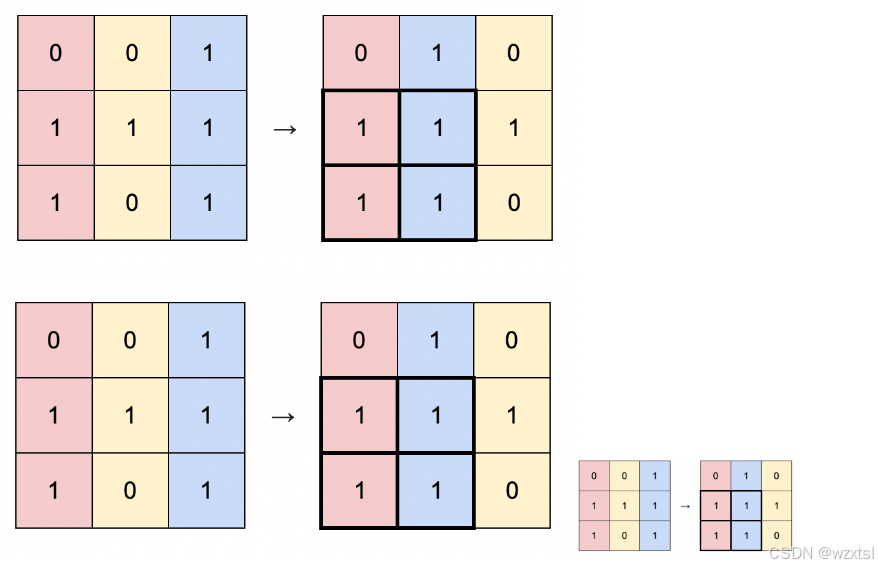
来一场栈的大模拟(主要是单调栈)
一.栈模拟 二.单调栈求最大矩形面积 通常,直方图用于表示离散分布,例如,文本中字符的频率。 现在,请你计算在公共基线处对齐的直方图中最大矩形的面积。 图例右图显示了所描绘直方图的最大对齐矩形。 输入格式 输入包含几个测…...
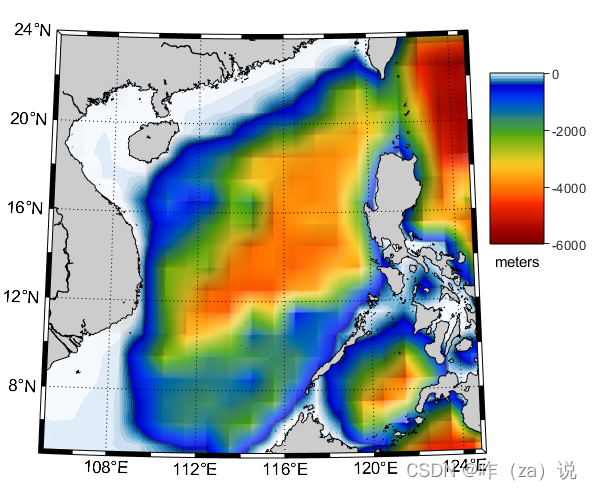
13 - matlab m_map地学绘图工具基础函数 - 介绍创建管理颜色映射的函数m_colmap和轮廓图绘制颜色条的函数m_contfbar
13 - matlab m_map地学绘图工具基础函数 - 介绍创建管理颜色映射的函数m_colmap和轮廓图绘制颜色条的函数m_contfbar 0. 引言1. 关于m_colmap2. 关于m_contfbar3. 结语 0. 引言 本篇介绍下m_map中用于创建和管理颜色映射函数(m_colmap)和 为轮廓图绘制颜…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...
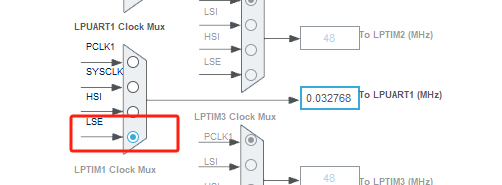
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...
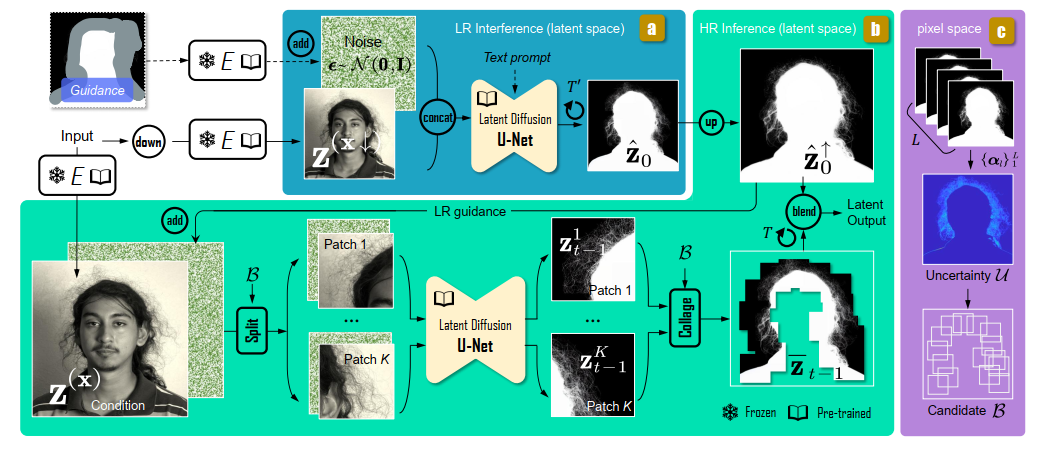
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...