Transformer中的编码器和解码器结构有什么不同?
Transformer背后的核心概念:注意力机制;编码器-解码器结构;多头注意力等;

例如:The cat sat on the mat;
1、嵌入:
首先,模型将输入序列中的每个单词嵌入到一个高维向量中表示,这个嵌入过程允许模型捕捉单词之间的语义相似性。
2、查询,键,和值向量;
接下来,模型为序列中的每个单词计算向量:查询向量、键和值向量。在训练过程中,模型学习这些向量,每个向量都有不同的作用。查询向量表示单词的查询,即模型在序列中寻找的内容。键向量表示单词的键,即序列中其他单词应该注意的内容。值向量表示单词的值,即单词对输出所贡献的信息。
3、注意力分数;
一旦模型计算了每个单词的查询、键和值向量,它就会为序列中的每一对单词计算注意力分数。这通常通过取查询向量和键向量的点积来实现,以评估单词之间的相似性。
4、softmax归一化:
然后,使用 softmax 函数对注意力分数进行归一化,以获得注意力权重。这些权重表示每个单词应该关注序列中其他单词的程度。注意力权重较高的单词被认为对正在执行的任务更为关键。
5、加权求和:
最后,使用注意力权重计算值向量的加权和。这产生了每个序列中单词的自注意力机制输出,捕获了来自其他单词的上下文信息。

代码举例:
# 导入库
import torch
import torch.nn.functional as F# 示例输入序列
input_sequence = torch.tensor([[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]])# 生成 Key、Query 和 Value 矩阵的随机权重
random_weights_key = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
random_weights_query = torch.randn(input_sequence.size(-1), input_sequence.size(-1))
random_weights_value = torch.randn(input_sequence.size(-1), input_sequence.size(-1))# 计算 Key、Query 和 Value 矩阵
key = torch.matmul(input_sequence, random_weights_key)
query = torch.matmul(input_sequence, random_weights_query)
value = torch.matmul(input_sequence, random_weights_value)# 计算注意力分数
attention_scores = torch.matmul(query, key.T) / torch.sqrt(torch.tensor(query.size(-1), dtype=torch.float32))# 使用 softmax 函数获得注意力权重
attention_weights = F.softmax(attention_scores, dim=-1)# 计算 Value 向量的加权和
output = torch.matmul(attention_weights, value)print("自注意力机制后的输出:")
print(output)Transformer基础:
1、编码器-解码器结构:
在transforemr的核心是编码器-解码器结构;两个关键组件之间的共生关系;分别负责输入序列和生成输出序列;编码器和解码器中的每一层都包含相同的子层;包括自注意力机制和前馈网络;这种架构不仅有助于全面理解输入序列,而且能够生成上下文丰富的输出序列;
2、位置编码
尽管Transformer模型具有强大的功能,但它缺乏对元素顺序的内在理解——这是位置编码所解决的一个缺点。通过将输入嵌入与位置信息结合起来,位置编码使模型能够区分序列中元素的相对位置。这种细致的理解对于捕捉语言的时间动态和促进准确理解至关重要。
3、多头注意力
Transformer模型的一个显著特征是它能够同时关注输入序列的不同部分——这是多头注意力实现的。通过将查询、键和值向量分成多个头,并进行独立的自注意力计算,模型获得了对输入序列的细致透视,丰富了其表示,带有多样化的上下文信息。
4、前馈网络
与人类大脑能够并行处理信息的能力类似,Transformer模型中的每一层都包含一个前馈网络——一种能够捕捉序列中元素之间复杂关系的多功能组件。通过使用线性变换和非线性激活函数,前馈网络使模型能够在语言的复杂语义景观中航行,促进文本的稳健理解和生成。
Transformer 组件的详细说明代码:
要实现,首先运行位置编码、多头注意力机制和前馈网络的代码,然后是编码器、解码器和Transformer架构。
import math
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F1、位置编码;
在Transformer模型中,位置编码是一个关键组件,它将关于标记位置的信息注入到输入嵌入中。
与循环神经网络(RNNs)或卷积神经网络(CNNs)不同,Transformer 模型由于其结构性质,缺乏对序列中标记位置的内在知识。这是因为 Transformer 主要依赖于自注意力机制,该机制在处理输入序列时是置换不变的。这意味着自注意力机制本身无法区分序列中标记的位置,也就是说,它对输入序列的排列顺序不敏感。
1、问题:缺乏位置信息:RNNs 通过其递归结构自然地捕捉序列的顺序信息,因为它们逐步处理输入序列的每个元素。CNNs 则通过卷积核和池化层在空间上逐步缩小范围,保留局部空间关系。相比之下,Transformers 的自注意力机制在处理序列时可以在任意位置之间建立依赖关系,这种特性使得它们缺乏对输入标记位置的内在感知。
2、解决办法:位置编码:为了使 Transformer 模型能够感知输入序列中的位置信息,研究人员引入了位置编码(Positional Encoding)。位置编码是一种向量,添加到输入序列的每个标记的嵌入向量中,以提供位置信息。这些位置编码使模型能够区分序列中不同位置的标记,并按照正确的顺序处理序列。(可学习的位置编码是将位置编码作为模型参数进行学习。与固定位置编码不同,可学习的位置编码在训练过程中会根据数据自动调整,从而可能更适应特定任务和数据集。)
3、位置编码的作用:位置编码的主要作用是将位置信息显式地注入到输入序列中,使得 Transformer 模型能够正确处理和理解序列顺序。这使得 Transformer 可以处理各种序列任务,例如机器翻译、文本生成和时间序列预测。
代码:
import torch
import torch.nn as nn
import mathclass PositionalEncoding(nn.Module):def __init__(self, embed_size, max_len=5000):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_len, embed_size)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-math.log(10000.0) / embed_size))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):x = x + self.pe[:x.size(0), :]return x# 使用示例
embed_size = 512
max_len = 100
pos_encoder = PositionalEncoding(embed_size, max_len)
input_tensor = torch.randn(max_len, 1, embed_size) # (sequence length, batch size, embed size)
output_tensor = pos_encoder(input_tensor)
print(output_tensor.shape) # 应输出 torch.Size([100, 1, 512])
在这个示例中,PositionalEncoding 类定义了位置编码,并在 forward 方法中将位置编码添加到输入张量上。这样,输入序列的每个标记都会有一个唯一的位置编码,使得模型能够感知和利用位置信息。
总结:位置编码通过为 Transformer 模型提供位置信息,解决了其缺乏对序列位置的内在感知的问题。通过将位置信息注入到输入序列中,位置编码使得 Transformer 能够正确处理序列任务,并在各种自然语言处理任务中取得了显著的效果。
位置编码的概念
通常在将输入嵌入传入Transformer模型之前,会将位置编码添加到嵌入中。它由一组具有不同频率和相位的正弦函数组成,允许模型根据它们在序列中的位置区分标记。
位置编码的公式如下:

不同的位置编码方案:
在Transformer中使用了各种位置编码方案,每种方案都有其优点和缺点:
-
固定位置编码:在这种方案中,位置编码是预定义的,并对所有序列固定不变。虽然简单高效,但固定位置编码可能无法捕捉序列中的复杂模式。
-
学习位置编码:另一种选择是在训练过程中学习位置编码,使模型能够自适应地从数据中捕捉位置信息。学习位置编码提供了更大的灵活性,但需要更多的参数和计算资源。
2、多头注意力机制
在Transformer架构中,多头注意力机制是一个关键组件,它使模型能够同时关注输入序列的不同部分。它允许模型捕捉序列内的复杂依赖关系和关联,从而提高了语言翻译、文本生成和情感分析等任务的性能;

多头注意力机制的重要性:
多头注意力机制具有几个优点:
-
并行化:通过同时关注输入序列的不同部分,多头注意力显著加快了计算速度,使其比传统的注意力机制更加高效。
-
增强表示:每个注意力头都关注输入序列的不同方面,使模型能够捕捉各种模式和关系。这导致输入的表示更丰富、更强大,增强了模型理解和生成文本的能力。
-
改进泛化性:多头注意力使模型能够关注序列内的局部和全局依赖关系,从而提高了跨不同任务和领域的泛化性。
多头注意力的计算:
让我们分解计算多头注意力所涉及的步骤:
-
线性变换:输入序列经历可学习的线性变换,将其投影到多个较低维度的表示,称为“头”。每个头关注输入的不同方面,使模型能够捕捉各种模式。
-
缩放点积注意力:每个头独立地计算输入序列的查询、键和值表示之间的注意力分数。这一步涉及计算令牌及其上下文之间的相似度,乘以模型深度的平方根进行缩放。得到的注意力权重突出了每个令牌相对于其他令牌的重要性。
-
连接和线性投影:来自所有头的注意力输出被连接并线性投影回原始维度。这个过程将来自多个头的见解结合起来,增强了模型理解序列内复杂关系的能力
-
代码:
# 多头注意力的代码实现
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()self.num_heads = num_headsself.d_model = d_modelassert d_model % num_heads == 0self.depth = d_model // num_heads# 查询、键和值的线性投影self.query_linear = nn.Linear(d_model, d_model)self.key_linear = nn.Linear(d_model, d_model)self.value_linear = nn.Linear(d_model, d_model)# 输出线性投影self.output_linear = nn.Linear(d_model, d_model)def split_heads(self, x):batch_size, seq_length, d_model = x.size()return x.view(batch_size, seq_length, self.num_heads, self.depth).transpose(1, 2)def forward(self, query, key, value, mask=None):# 线性投影query = self.query_linear(query)key = self.key_linear(key)value = self.value_linear(value)# 分割头部query = self.split_heads(query)key = self.split_heads(key)value = self.split_heads(value)# 缩放点积注意力scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.depth)# 如果提供了掩码,则应用掩码if mask is not None:scores += scores.masked_fill(mask == 0, -1e9)# 计算注意力权重并应用softmaxattention_weights = torch.softmax(scores, dim=-1)# 应用注意力到值attention_output = torch.matmul(attention_weights, value)# 合并头部batch_size, _, seq_length, d_k = attention_output.size()attention_output = attention_output.transpose(1, 2).contiguous().view(batch_size,seq_length, self.d_model)# 线性投影attention_output = self.output_linear(attention_output)return attention_output# 示例用法
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048# 多头注意力
multihead_attn = MultiHeadAttention(d_model, num_heads)# 示例输入序列
input_sequence = torch.randn(5, max_len, d_model)# 多头注意力
attention_output= multihead_attn(input_sequence, input_sequence, input_sequence)
print("attention_output shape:", attention_output.shape)3、前馈网络
在Transformer的背景下,前馈网络在处理信息和从输入序列中提取特征方面发挥着关键作用。它们是模型的支柱,促进了不同层之间表示的转换。
前馈网络的作用:
每个Transformer层内的前馈网络负责对输入表示应用非线性变换。它使模型能够捕捉数据中的复杂模式和关系,促进了高级特征的学习。
前馈层的结构和功能:
前馈层由两个线性变换组成,两者之间通过一个非线性激活函数(通常是ReLU)分隔。让我们来解析一下结构和功能:
-
线性变换1:使用可学习的权重矩阵将输入表示投影到更高维度的空间中。
-
非线性激活:第一个线性变换的输出通过非线性激活函数(例如ReLU)传递。这引入了模型的非线性,使其能够捕捉数据中的复杂模式和关系。
-
线性变换2:激活函数的输出然后通过另一个可学习的权重矩阵投影回原始的维度空间中。
# 前馈网络的代码实现
class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super(FeedForward, self).__init__()self.linear1 = nn.Linear(d_model, d_ff)self.linear2 = nn.Linear(d_ff, d_model)self.relu = nn.ReLU()def forward(self, x):# 线性变换1x = self.relu(self.linear1(x))# 线性变换2x = self.linear2(x)return x# 示例用法
d_model = 512
max_len = 100
num_heads = 8
d_ff = 2048# 多头注意力
multihead_attn = MultiHeadAttention(d_model, num_heads)# 前馈网络
ff_network = FeedForward(d_model, d_ff)# 示例输入序列
input_sequence = torch.randn(5, max_len, d_model)# 多头注意力
attention_output= multihead_attn(input_sequence, input_sequence, input_sequence)# 前馈网络
output_ff = ff_network(attention_output)
print('input_sequence',input_sequence.shape)
print("output_ff", output_ff.shape)4、编码器:
在Transformer模型中起着至关重要的作用,其主要任务是将输入序列转换为有意义的表示,捕捉输入的重要信息。

每个编码器层的结构和功能:
编码器由多个层组成,每个层依次包含以下组件:输入嵌入、位置编码、多头自注意力机制和位置逐点前馈网络。
-
输入嵌入:我们首先将输入序列转换为密集向量表示,称为输入嵌入。我们使用预训练的词嵌入或在训练过程中学习的嵌入,将输入序列中的每个单词映射到高维向量空间中。
-
位置编码:我们将位置编码添加到输入嵌入中,以将输入序列的顺序信息合并到其中。这使得模型能够区分序列中单词的位置,克服了传统神经网络中缺乏顺序信息的问题。
-
多头自注意力机制:在位置编码之后,输入嵌入通过一个多头自注意力机制。这个机制使编码器能够根据单词之间的关系权衡输入序列中不同单词的重要性。通过关注输入序列的相关部分,编码器可以捕捉长距离的依赖关系和语义关系。
-
位置逐点前馈网络:在自注意力机制之后,编码器对每个位置独立地应用位置逐点前馈网络。这个网络由两个线性变换组成,两者之间通过一个非线性激活函数(通常是ReLU)分隔。它有助于捕捉输入序列中的复杂模式和关系。
代码:
# 编码器的代码实现
class EncoderLayer(nn.Module):def __init__(self, d_model, num_heads, d_ff, dropout):super(EncoderLayer, self).__init__()self.self_attention = MultiHeadAttention(d_model, num_heads)self.feed_forward = FeedForward(d_model, d_ff)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):# 自注意力层attention_output= self.self_attention(x, x,x, mask)attention_output = self.dropout(attention_output)x = x + attention_outputx = self.norm1(x)# 前馈层feed_forward_output = self.feed_forward(x)feed_forward_output = self.dropout(feed_forward_output)x = x + feed_forward_outputx = self.norm2(x)return xd_model = 512
max_len = 100
num_heads = 8
d_ff = 2048# 多头注意力
encoder_layer = EncoderLayer(d_model, num_heads, d_ff, 0.1)# 示例输入序列
input_sequence = torch.randn(1, max_len, d_model)# 多头注意力
encoder_output= encoder_layer(input_sequence, None)
print("encoder output shape:", encoder_output.shape)在 Transformer 模型中,掩码(mask)有几个关键的用途,主要是为了确保模型正确处理输入序列中的特定位置,防止不相关的信息影响注意力机制的计算。下面解释掩码的具体原因和作用:
填充掩码(Padding Mask):
原因: 在处理变长序列时,为了使得序列长度一致,我们通常会在较短的序列末尾添加填充标记(padding tokens)。这些填充标记并不包含有用的信息,因此在计算注意力权重时需要忽略这些位置。
作用: 填充掩码用于屏蔽填充位置,确保这些位置的值不会对注意力计算产生影响。这可以防止模型在训练时将填充位置误认为有意义的数据,从而提高模型的性能和稳定性。
示例: 假设输入序列 [A, B, C, <PAD>, <PAD>],其中 <PAD> 表示填充标记。掩码会确保注意力计算时忽略 <PAD> 位置,只考虑实际数据 [A, B, C]。
序列掩码(Sequence Mask)
在自回归任务(如文本生成、翻译等)中,解码器在生成每个位置的输出时,只能使用之前生成的标记,而不能看到未来的标记。
作用: 序列掩码用于屏蔽解码器中未来位置的信息,确保在生成第 t 个标记时,只能使用第 1 到第 t-1 个标记。这可以防止模型在训练过程中作弊,从而提高生成任务的性能。
示例: 假设解码器在生成序列 ['X1', 'X2', 'X3'] 时,在生成 X2 时只能看到 X1,而不能看到 X3。
这样,通过使用掩码,我们可以确保模型在处理序列数据时正确忽略填充位置,只关注实际的数据,避免不相关信息的干扰,提高模型的性能和稳定性。
5、解码器
在Transformer模型中,解码器在基于输入序列的编码表示生成输出序列方面起着至关重要的作用。它接收来自编码器的编码输入序列,并将其用于生成最终的输出序列。

解码器的功能:
解码器的主要功能是生成输出序列,同时注意到输入序列的相关部分和先前生成的标记。它利用输入序列的编码表示来理解上下文,并对生成下一个标记做出明智的决策。
解码器层及其组件:
解码器层包括以下组件:
-
输出嵌入右移:在处理输入序列之前,模型将输出嵌入向右移动一个位置。这确保解码器中的每个标记在训练期间都能从先前生成的标记接收到正确的上下文。解释:(在序列生成任务中(例如机器翻译、文本生成等),我们希望模型能够逐步生成序列中的每一个标记。假设我们有一个目标序列
[y1, y2, y3, y4],在生成标记yt时,我们希望模型只能使用之前生成的标记[y1, ..., yt-1]作为上下文,而不能看到未来的标记[yt+1, ..., y4]。在训练过程中,我们一次性提供整个目标序列[y1, y2, y3, y4]给模型。训练过程中的问题:如果不做任何处理,模型在生成每个标记时都可以看到整个目标序列,这与实际推理过程不符,因为在推理过程中,模型生成每个标记时只能依赖之前生成的标记。解决方案:右移目标序列:为了模拟推理时逐步生成的过程,我们在训练时将目标序列右移一个位置,形成一个新的输入序列。这样,模型在生成第t个标记时,只能看到前面的t-1个标记,而看不到第t个及后面的标记。具体操作:假设目标序列是[BOS, y1, y2, y3, EOS],其中BOS是序列开始标记,EOS是序列结束标记。实际操作中的示例
假设我们有一个目标序列
[1, 2, 3, 4],模型在训练时需要生成该序列。原始目标序列:[1, 2, 3, 4]。右移后的序列:[<BOS>, 1, 2, 3]。模型输入和目标输出,模型输入:[<BOS>, 1, 2, 3],目标输出:[1, 2, 3, 4];通过这种方式,模型在生成每个标记时,只能看到前面的标记。例如:在生成
1时,只能看到<BOS>。在生成2时,只能看到<BOS>和1。在生成3时,只能看到<BOS>、1和2。在生成4时,只能看到<BOS>、1、2和3。) -
位置编码:与编码器类似,模型将位置编码添加到输出嵌入中,以合并标记的顺序信息。这种编码帮助解码器根据标记在序列中的位置进行区分。
-
掩码的多头自注意力机制:解码器采用掩码的多头自注意力机制,以便注意输入序列的相关部分和先前生成的标记。在训练期间,模型应用掩码以防止注意到未来的标记,确保每个标记只能注意到前面的标记。(在 Transformer 模型中,掩码的多头自注意力机制是一个关键组件,尤其是在解码器部分。它通过引入掩码,确保每个标记在生成过程中只能关注到之前生成的标记,而不会看到未来的标记。这对于确保模型在训练和推理过程中行为一致至关重要。多头自注意力机制允许模型在输入序列中不同位置之间建立依赖关系。然而,为了确保模型在生成序列时只关注之前的标记,我们引入了掩码(mask)。)总结:输出嵌入右移:确保输入序列在每一步生成时只包含之前的标记。掩码:进一步确保注意力计算时,只关注到之前的位置。
-
编码器-解码器注意力机制:除了掩码的自注意力机制外,解码器还包括编码器-解码器注意力机制。这种机制使解码器能够注意到输入序列的相关部分,有助于生成受输入上下文影响的输出标记。
-
位置逐点前馈网络:在注意力机制之后,解码器对每个标记独立地应用位置逐点前馈网络。这个网络捕捉输入和先前生成的标记中的复杂模式和关系,有助于生成准确的输出序列。
5、Transformer 模型架构

Transformer模型概述;
在其核心,Transformer模型由编码器和解码器模块堆叠在一起,用于处理输入序列并生成输出序列。以下是架构的高级概述:
编码器
-
编码器模块处理输入序列,提取特征并创建输入的丰富表示。
-
它由多个编码器层组成,每个层包含自注意力机制和前馈网络。
-
自注意力机制允许模型同时关注输入序列的不同部分,捕捉依赖关系和关联。
-
我们将位置编码添加到输入嵌入中,以提供有关序列中标记位置的信息。
解码器
-
解码器模块以编码器的输出作为输入,并生成输出序列。
-
与编码器类似,它由多个解码器层组成,每个层包含自注意力、编码器-解码器注意力和前馈网络。
-
除了自注意力外,解码器还包含编码器-解码器注意力,以在生成输出时关注输入序列。
-
与编码器类似,我们将位置编码添加到输入嵌入中,以提供位置信息。
连接和标准化
-
在编码器和解码器模块的每一层之间,都有残差连接后跟层标准化。
-
这些机制有助于在网络中流动梯度,并有助于稳定训练。
6、模型的训练与评估
训练Transformer模型涉及优化其参数以最小化损失函数,通常使用梯度下降和反向传播。一旦训练完成,就会使用各种指标评估模型的性能,以评估其解决目标任务的有效性。
训练过程:
-
在训练期间,将输入序列输入模型,并生成输出序列。
-
将模型的预测与GT进行比较,涉及使用损失函数(例如交叉熵损失)来衡量预测值与实际值之间的差异。
-
梯度下降用于更新模型的参数,使损失最小化的方向。
-
优化器根据这些梯度调整参数,迭代更新它们以提高模型性能。
学习率调度:
-
可以应用学习率调度技术来动态调整训练期间的学习率。
-
常见策略包括热身计划,其中学习率从低开始逐渐增加,以及衰减计划,其中学习率随时间降低。
评估指标
困惑度:
-
困惑度是用于评估语言模型性能的常见指标,包括Transformer。
-
它衡量模型对给定标记序列的预测能力。
-
较低的困惑度值表示更好的性能,理想值接近词汇量大小。
BLEU分数:
-
BLEU(双语评估研究)分数通常用于评估机器翻译文本的质量。
-
它将生成的翻译与一个或多个由人类翻译人员提供的参考翻译进行比较。
-
BLEU分数范围从0到1,较高的分数表示更好的翻译质量。
Ref:一文彻底搞懂 Transformer(图解+手撕)
相关文章:
Transformer中的编码器和解码器结构有什么不同?
Transformer背后的核心概念:注意力机制;编码器-解码器结构;多头注意力等; 例如:The cat sat on the mat; 1、嵌入: 首先,模型将输入序列中的每个单词嵌入到一个高维向量中表示&…...

【深度学习】第5章——卷积神经网络(CNN)
一、卷积神经网络 1.定义 卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理具有网格状拓扑结构数据的深度学习模型,特别适用于图像和视频处理。CNN 通过局部连接和权重共享机制,有效地减少了参数数量&#x…...

fluwx插件实现微信支付
Flutter开发使用fluwx插件实现微信支付,代码量不多,复杂的是安卓和iOS的各种配置。 在 pubspec.yaml 文件中添加fluwx依赖 fluwx: ^4.5.5 使用方法 通过fluwx注册微信Api await Fluwx().registerApi(appId: wxea7a1c53d9e5849d, universalLink: htt…...

k8s核心操作_Deployment的扩缩容能力_Deployment自愈和故障转移能力---分布式云原生部署架构搭建022
然后我们上面说了k8s中的deployment的多副本能力 然后,我们再来看 k8s中的deployment的扩缩容能力 可以看到,对于扩容,要使用 kubectl scale 命令 对于缩容 要使用kubectl scale 命令都是使用这个命令对吧 来试试,可以看到上面命令 首先看看 kubectl get pod 可以看到有…...

P8306 【模板】字典树
题目描述 给定 n 个模式串 s1,s2,…,sn 和 q 次询问,每次询问给定一个文本串 ti,请回答 s1∼sn 中有多少个字符串 sj 满足 ti 是 sj 的前缀。 一个字符串 t 是 s 的前缀当且仅当从 s 的末尾删去若干个(可以为 0 个&#…...

面试官:讲一下如何终止一个 Promise 继续执行
我们知道 Promise 一旦实例化之后,状态就只能由 Pending 转变为 Rejected 或者 Fulfilled, 本身是不可以取消已经实例化之后的 Promise 了。 但是我们可以通过一些其他的手段来实现终止 Promise 的继续执行来模拟 Promise 取消的效果。 Promise.race …...

linux之常见的coredump原因都有哪些
Core dump通常发生在程序遇到严重错误时,操作系统会生成core文件来记录程序崩溃时的内存、寄存器状态、栈信息等。下面是一些常见的导致core dump的原因: 段错误(Segmentation Fault): 当程序尝试访问不允许访问的内存…...

低资源低成本评估大型语言模型(LLMs)
随着新的大型语言模型(LLMs)的持续发展,从业者发现自己面临着众多选择,需要从数百个可用选项中选择出最适合其特定需求的模型、提示[40]或超参数。例如,Chatbot Arena基准测试平台积极维护着近100个模型,以…...

什么是RPC?有哪些RPC框架?
定义 RPC(Remote Procedure Call,远程过程调用)是一种允许运行在一台计算机上的程序调用另一台计算机上子程序的技术。这种技术屏蔽了底层的网络通信细节,使得程序间的远程通信如同本地调用一样简单。RPC机制使得开发者能够构建分…...

HTTP有哪些请求方式?
GET:请求指定的资源。例如,用于获取网页内容。POST:向指定资源提交数据(例如表单提交)。POST请求的数据通常在请求体中。PUT:将请求体中的数据放置到请求URI指定的位置,如果该资源不存在则创建&…...
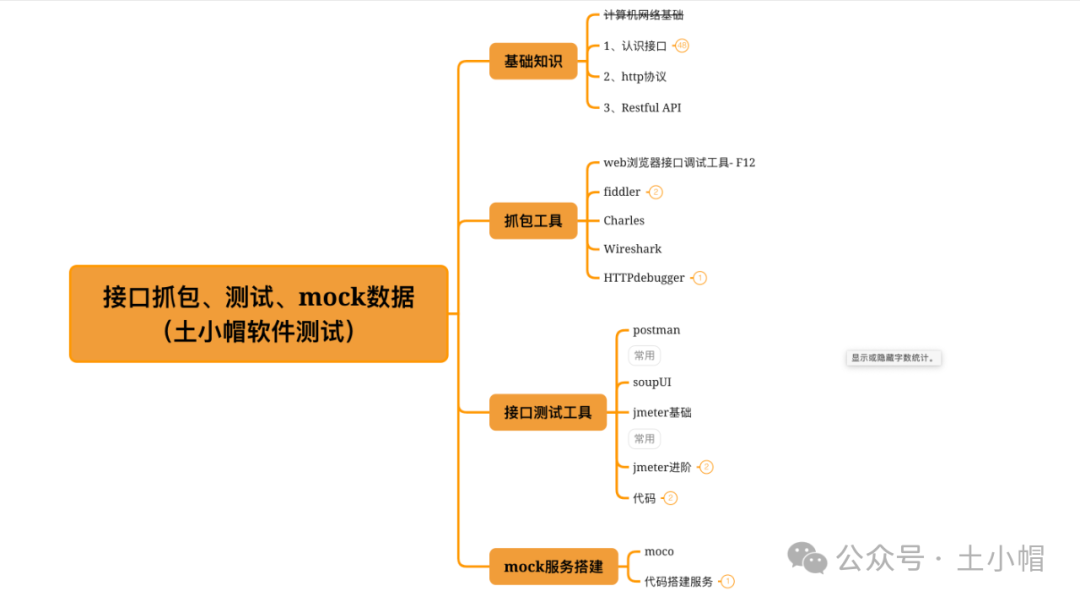
接口测试课程结构
课程大纲 如图,接下来的阶段课程,依次专项讲解如下专题,能力级别为中级,进阶后基本为中高级: 1.接口基础知识; 2.抓包工具; 3.接口工具; 4.mock服务搭建(数据模拟服务&am…...

leetcode--从中序与后序遍历序列构造二叉树
leeocode地址:从中序与后序遍历序列构造二叉树 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder …...

西瓜杯CTF(1)
#下班之前写了两个题,后面继续发 Codeinject <?php#Author: h1xaerror_reporting(0); show_source(__FILE__);eval("var_dump((Object)$_POST[1]);"); payload 闭合后面的括号来拼接 POST / HTTP/1.1 Host: 1dc86f1a-cccc-4298-955d-e9179f026d54…...

Kafka 典型问题与排查以及相关优化
Kafka 是一个高吞吐量的分布式消息系统,但在实际应用中,用户经常会遇到一些性能问题和消息堆积的问题。本文将介绍 Kafka 中一些典型问题的原因和排查方法,帮助用户解决问题并优化 Kafka 集群的性能。 一、Topic 消息发送慢,并发性…...
)
C# 策略模式(Strategy Pattern)
策略模式定义了一系列的算法,并将每一个算法封装起来,使它们可以相互替换。策略模式让算法的变化独立于使用算法的客户。 // 策略接口 public interface IStrategy { void Execute(); } // 具体策略A public class ConcreteStrategyA : IStra…...

【初阶数据结构】1.算法复杂度
文章目录 1.数据结构前言1.1 数据结构1.2 算法1.3 如何学好数据结构和算法 2.算法效率2.1 复杂度的概念2.2 复杂度的重要性 3.时间复杂度3.1 大O的渐进表示法3.2 时间复杂度计算示例3.2.1 示例13.2.2 示例23.2.3 示例33.2.4 示例43.2.5 示例53.2.6 示例63.2.7 示例7 4.空间复杂…...

(图文详解)小程序AppID申请以及在Hbuilderx中运行
今天小编给大家带来了如何去申请APPID,如果你是小程序的开发者,就必须要这个id。 申请步骤 到小程序注册页面,注册一个小程序账号 微信公众平台 填完信息后提交注册 会在邮箱收到 链接激活账号 确认。邮箱打开链接后,会输入实…...

科技创新引领水利行业升级:深入分析智慧水利解决方案的核心价值,展望其在未来水资源管理中的重要地位与作用
目录 引言 一、智慧水利的概念与内涵 二、智慧水利解决方案的核心价值 1. 精准监测与预警 2. 优化资源配置 3. 智能运维管理 4. 公众参与与决策支持 三、智慧水利在未来水资源管理中的重要地位与作用 1. 推动水利行业转型升级 2. 保障国家水安全 3. 促进生态文明建设…...

ExcelVBA运用Excel的【条件格式】(三)
ExcelVBA运用Excel的【条件格式】(三)前面知识点回顾1. 访问 FormatConditions 集合 Range.FormatConditions2. 添加条件格式 FormatConditions.Add 方法语法表达式。添加 (类型、 运算符、 Expression1、 Expression2)其中 TextOperator:***&am…...

coco数据集格式计算mAP的python脚本
目录 背景说明COCOeval 计算mAPtxt文件转换为coco json 格式自定义数据集标注 背景说明 在完成YOLOv5模型移植,运行在板端后,通常需要衡量板端运行的mAP。 一般需要两个步骤 步骤一:在板端批量运行得到目标检测结果,可保存为yol…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...