万字学习——DCU编程实战
参考资料
2.1 DCU软件栈(DCU ToolKit, DTK) · DCU 开发与使用文档 (hpccube.com)
DCU软件栈
DCU的软件栈—DCU Toolkit(DTK)

-
HIP(Heterogeneous-Compute Interface for Portability)是AMD公司在2016年提出的符合CUDA编程模型的、自由的、开源的C++编程接口和核函数语言。
在目前的DTK中,使用HIP编程是进行DCU应用开发最主要的方式。
-
OpenMP(Open Multi-Processing)是共享内存的多处理器并行应用编程接口,它通过在C/C++或Fortran代码中加入编译器导语(directive)的方式让编译器将指定代码段并行化,此外还包含一系列函数形式的编程接口。
使用OpenMP是进行DCU应用开发便捷有效的方式。
-
OpenACC(Open ACCelerators)可以看作OpenMP针对异构设备的开发分支。
在目前的DTK中,支持在C/C++中使用OpenACC的部分功能。
数学库
| HIP库 | CUDA库 | 功能 |
|---|---|---|
| hipBLAS | cuBLAS | 基础线性代数库 |
| hipFFT | cuFFT | 快速傅里叶变换库 |
| hipRAND | cuRAND | 随机数生成库 |
| hipSOLVER | cuSOLVER | 矩阵求解库 |
| hipSPARSE | cuSPARSE | 稀疏矩阵线性代数库 |
| Thrust | Thrust | C++STL形式的并行算法库 |
| hipCUB | CUB | HIP形式的并行算法库 |
| RCCL | NCCL | 多DCU的通讯库 |
| MIOpen | cuDNN | 深度学习基础数学库 |
| HIP RTC | NVRTC | 运行时编译库 |
DTK中包含针对DCU开发的llvm编译器套件,DTK中对于HIP、OpenMP、OpenACC的支持都是由这套编译器套件提供。为方便编译HIP代码,DTK中还提供了脚本工具hipcc,hipcc可以在内部帮助开发者完成预编译器、编译器、链接器的参数配置与调用,使开发者只需要使用简单的编译命令即可完成编译。
- 性能分析工具hipprof
- 调试工具hipgdb
- DCU状态监控工具rocm-smi。
使用C/C++编写DCU程序
初识并行计算
对2G个x计算y=ax^2+bx+c
代码
#include <cstdio>
#include <cstdlib>
int main()
{int N = 256 * 1024 * 1024; // 数组长度256Mint size = N * sizeof(float); // 内存空间1GB// 分配内存空间float *x = (float *) malloc(size);float *y = (float *) malloc(size);// 初始化a,b,cfloat a = 2.5, b = 2.0, c = 1.0;// 循环8次完成for (int j = 0; j < 8; j++) {// 初始化xfor (int i = 0; i < N; i++) {x[i] = 2.0;}// 计算y = ax^2 + bx + c;for (int i = 0; i < N; i++) {y[i] = a * x[i] * x[i] + b * x[i] + c;}// 检查结果bool correct = true;for (int i = 0; i < N; i++) {if (y[i] != 15.0) {correct = false;break;}}if (correct) {printf("Loop %d: Correct results.\n", j+1);} else {printf("Loop %d: Wrong results.\n", j+1);}}// 释放空间free(x);free(y);return 0;
}
运行
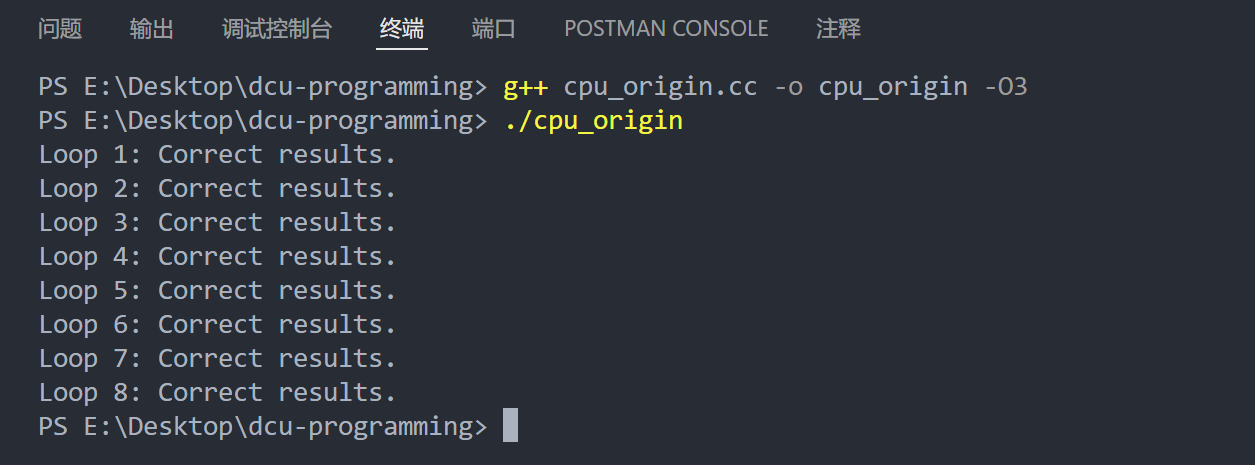
添加计时器,先创建timer.h
#ifndef TIMER_H
#define TIMER_H
#include <sys/time.h>
struct my_timer
{timeval ts, te; //起始时刻,终止时刻float dt; // 时间间隔,单位毫秒(ms)void start(){gettimeofday(&ts, NULL);}void stop(){gettimeofday(&te, NULL);long int dt_sec = te.tv_sec - ts.tv_sec;long int dt_usec = te.tv_usec - ts.tv_usec;dt = dt_sec * 1.0e3 + dt_usec / 1.0e3;}
};
#endif
在源程序添加计时器
#include <cstdio>
#include <cstdlib>
#include "timer.h"
int main()
{int N = 256 * 1024 * 1024; // 数组长度256Mint size = N * sizeof(float); // 内存空间1GB// 计时器my_timer timer;double t_init = 0.0;double t_calc = 0.0;double t_chck = 0.0;// 分配内存空间float *x = (float *) malloc(size);float *y = (float *) malloc(size);// 初始化a,b,cfloat a = 2.5, b = 2.0, c = 1.0;// 循环8次完成for (int j = 0; j < 8; j++) {// 初始化xtimer.start();for (int i = 0; i < N; i++) {x[i] = 2.0;}timer.stop();t_init += timer.dt;// 计算y = ax^2 + bx + c;timer.start();for (int i = 0; i < N; i++) {y[i] = a * x[i] * x[i] + b * x[i] + c;}timer.stop();t_calc += timer.dt;// 检查结果timer.start();bool correct = true;for (int i = 0; i < N; i++) {if (y[i] != 15.0) {correct = false;break;}}if (correct) {printf("Loop %d: Correct results.\n", j+1);} else {printf("Loop %d: Wrong results.\n", j+1);}timer.stop();t_chck += timer.dt;}printf("Initialization took %8.3f ms.\n", t_init);printf("Calculation took %8.3f ms.\n", t_calc);printf("Validation took %8.3f ms.\n", t_chck);// 释放空间free(x);free(y);return 0;
}
运行
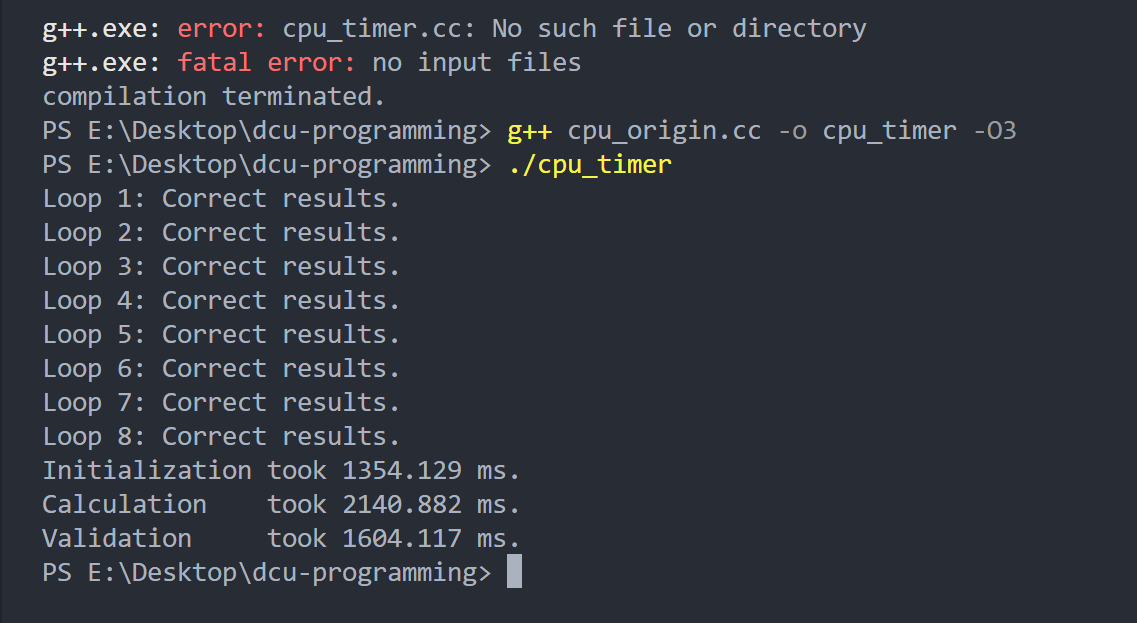
使用多核来优化运行速度,通过OpenMP实现
#pragma omp parallel for
for (int i = 0; i < N; i++) {x[i] = 2.0;
}
重新运行需要加上-fopenmp
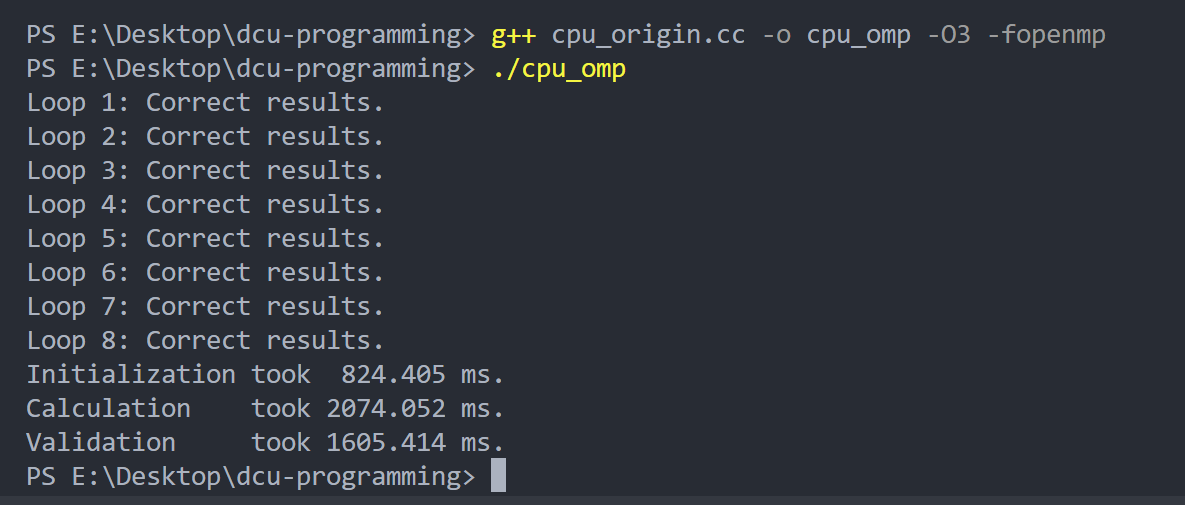
初始化过程变快了
OMP_NUM_THREADS为3,分配3个核心工作看看
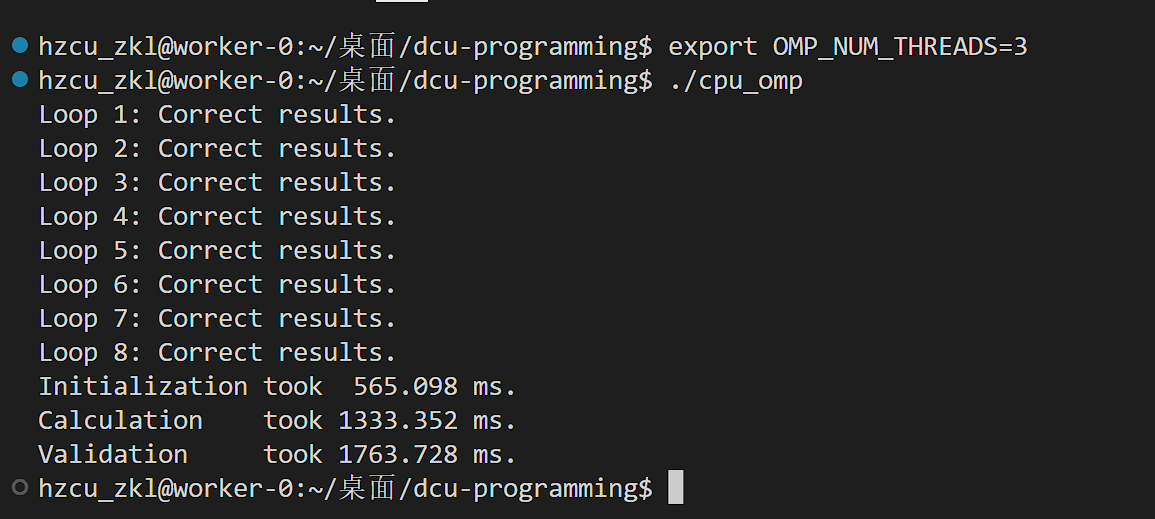
可以看到更快了
为DCU编写代码
#include <hip/hip_runtime.h>
#include <cstdio>
#include <cstdlib>
#include "timer.h"//编写for的核函数
__global__ void init(float *x,int N){int i = blockIdx.x*blockDim.x+threadIdx.x;//一维线程索引if(i<N){x[i] = 2.0;}
}__global__ void calculate(float *x, float *y, float a,float b, float c, int N)
{int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < N) {y[i] = a * x[i] * x[i] + b * x[i] + c;}
}int main()
{int N = 256 * 1024 * 1024; // 数组长度256Mint size = N * sizeof(float); // 内存空间1GB// 分配内存空间//float *x = (float *)malloc(size);float *y = (float *)malloc(size);//DCU内存管理float *dx,*dy;hipMalloc(&dx,size);hipMalloc(&dy,size);// 计时器my_timer timer;double t_init = 0.0;double t_calc = 0.0;double t_chck = 0.0;// 初始化a,b,cfloat a = 2.5, b = 2.0, c = 1.0;// 循环8次完成for (int j = 0; j < 8; j++){//初始化x//调用核函数int blockSize=256;int numBlocks=(N+blockSize-1)/blockSize;timer.start();init<<<numBlocks,blockSize>>>(dx,N);timer.stop();t_init += tiemr.dt;// 计算y = ax^2 + bx + c;timer.start();calculate<<<numBlocks, blockSize>>>(dx,dy,a,b,c,N);timer.stop();t_calc += timer.dt;// 检查结果timer.start();bool correct = true;hipMemcpy(y, dy, size, hipMemcpyDeviceToHost);for (int i = 0; i < N; i++) {if (y[i] != 15.0) {correct = false;break;}}if (correct) {printf("Loop %d: Correct results.\n", j+1);} else {printf("Loop %d: Wrong results.\n", j+1);}timer.stop();t_chck += timer.dt;}printf("Initialization took %8.3f ms.\n", t_init);printf("Calculation took %8.3f ms.\n", t_calc);printf("Validation took %8.3f ms.\n", t_chck);// 释放空间hipFree(dx);hipFree(dy);free(y);return 0;
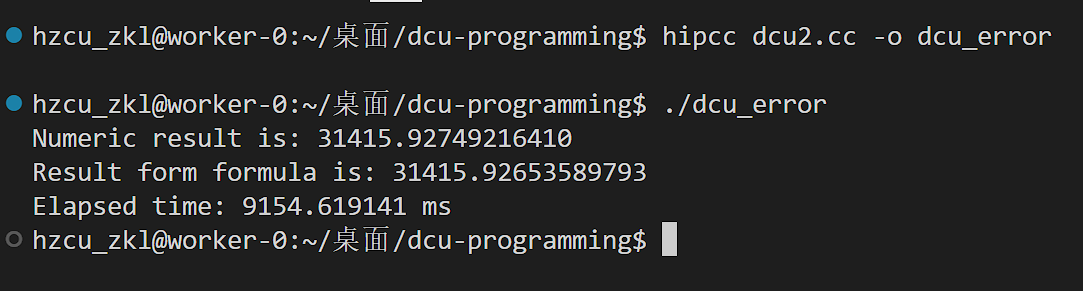
}运行
这里我们的计时器显示的结果是有问题的。我们用DTK软件栈中的性能分析工具来看看真实的性能。
hipprof ./dcu
多了两张表格,表格里记录了我们调用的HIP编程接口的耗时以及核函数的耗时。
计时器为什么不准呢?这是因为DCU执行核函数与CPU执行其他部分是异步的。意思也就是,CPU把任务丢给DCU后就stop了,所以前两个阶段时间很短。
为了让计时器记录准确的核函数执行时间,我们需要在timer.stop()之前让CPU与DCU同步,通过调用HIP运行时编程接口hipDeviceSynchronize()
对于init和caculate都修改一下
timer.start();init<<<numBlocks, blockSize>>>(dx,N);hipDeviceSynchronize();timer.stop();
当CPU执行到这个接口时会等待DCU上的现有的任务执行完毕后再继续。
重新编译运行
DCU编程概述
程序是用两种处理器执行的,这称为异构计算(heterogeneous computing)。CPU和DCU的关系是主从关系,会用一个抽象的概念主机(host)来指代CPU,设备(device)来指代DCU。
对于设备端执行的核函数,我们需要单独编写代码,并在核函数前加__global__修饰符以区分,核函数中还可以调用在设备端执行的函数,这些函数前需要加__device__修饰符。主机调用核函数后会继续执行后面的主机端代码,而设备端则会根据配置启动多个线程同时执行核函数。
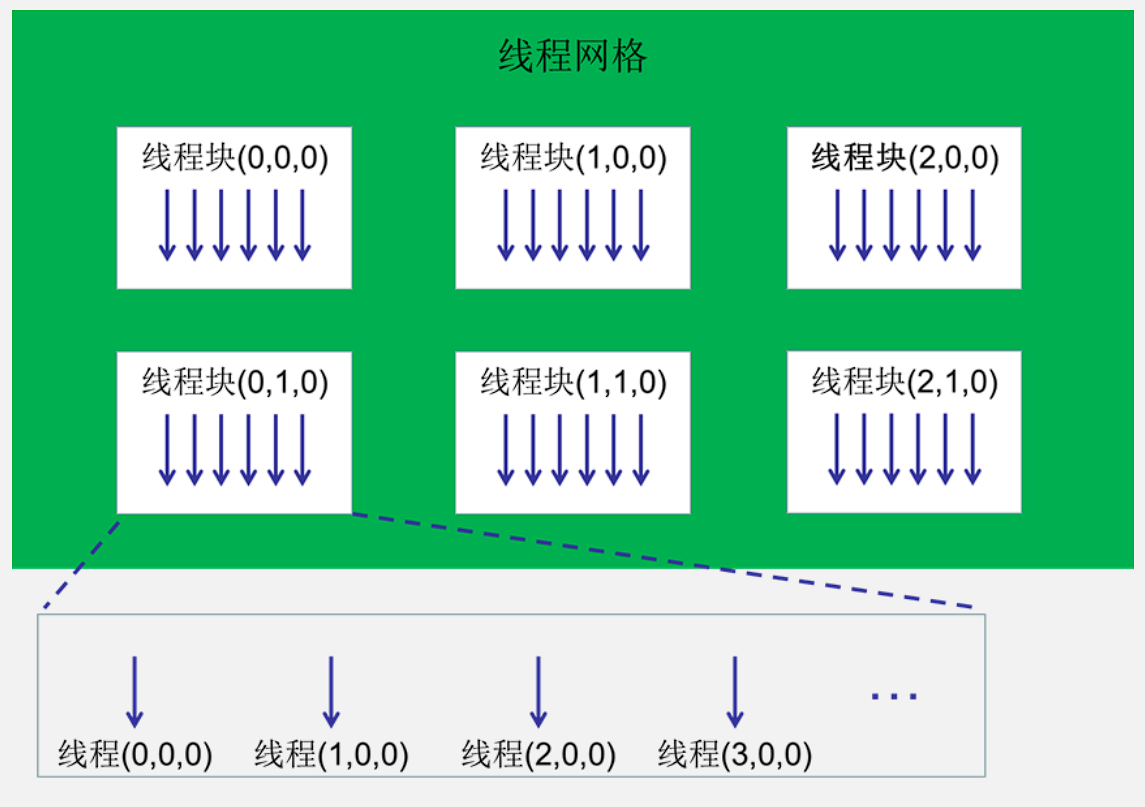
核函数启动参数(Kernel launch configuration),我们通过将它们置于核函数后的三个尖括号之中,让设备以这样的线程组织结构,启动256M个线程,每个线程都执行一遍init函数,换言之将init函数执行了256M次。
线程网格包含的线程块数目(gridDim)、线程块在线程网格中的编号/索引(blockIdx)、线程块包含的线程数(blockDim)、线程在线程块中的编号/索引(threadIdx)
内存的层次结构
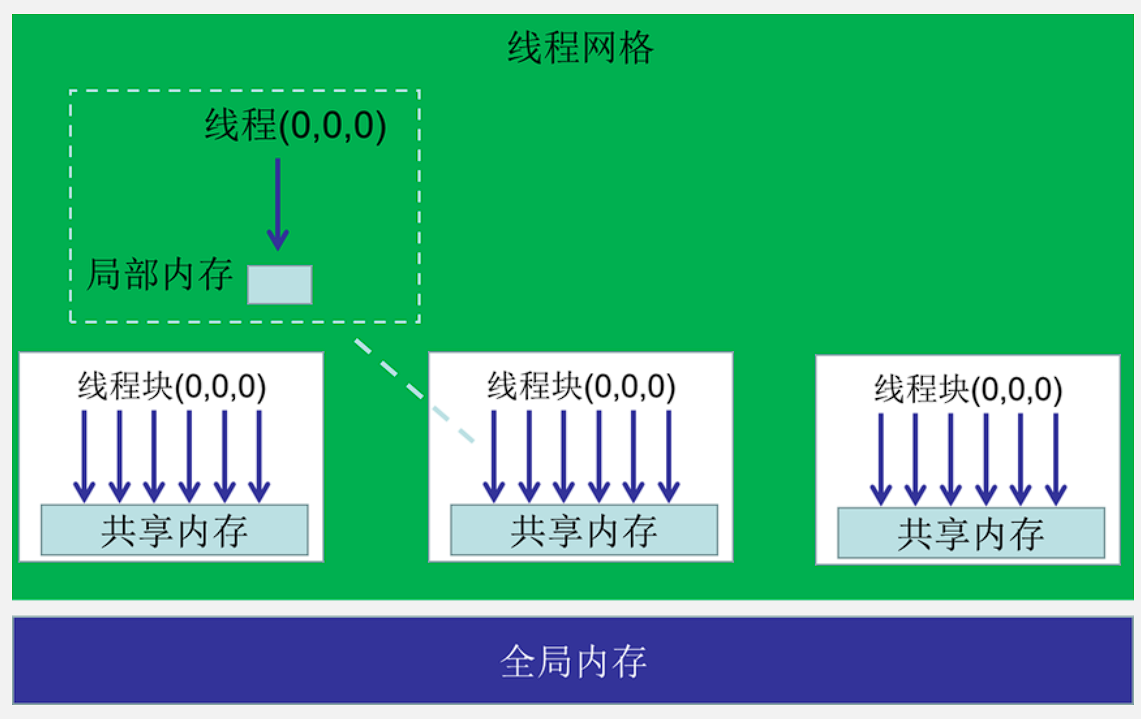
也就是另一篇博客里的私有局部内存、共享内存、全局内存。
从模型到硬件就像另一篇里的
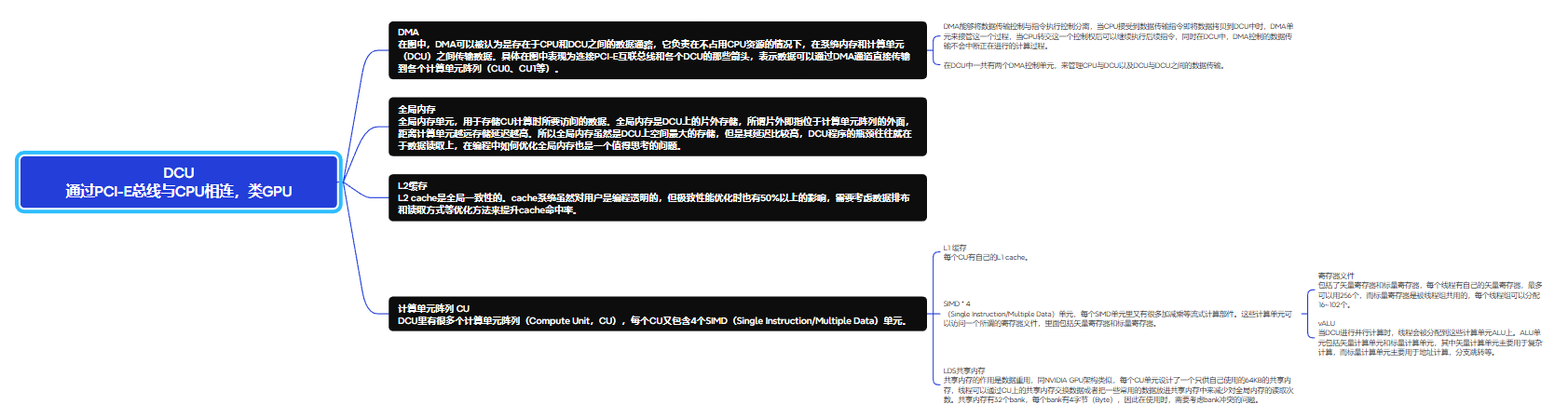
单个线程块中的线程有唯一的ID,按以下公式计算:
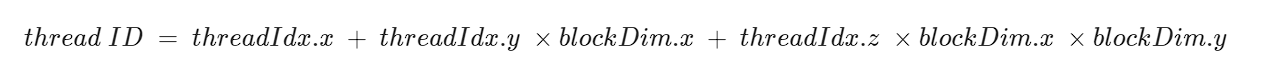
这个公式怎么出来的?
偏移:偏移是指线程相对于某个起点的距离。在这里,偏移的目的是计算线程在一维线性内存中的位置。
我们需要将三维索引 threadIdx(x, y, z) 转换成一维索引(线性索引),以便在一维线性内存中访问。
所以转换之后是这样的,像是三维数组转为一维数组
-
x维
threadIdx.x直接表示线程在 x 维度上的位置,它不需要乘其他尺寸。 -
y维
threadIdx.y * blockDim.x -
z维
threadIdx.z * blockDim.x * blockDim.y
程按线程ID以64个为一组划分在不同的线程束中,比如对于一维的(128,1,1)线程块,threadIdx.x为0到63的线程在同一线程束,64到127的在另一线程束;对于二维的(16,16,1)线程块,按threadIdx.y从0到3,4到7,8到11,12到15划分在4个线程束上。
这段话什么意思?
一个DCU中线程束是64个线程,所以对于一维来说,128个分为两个线程束;对于二维来说,16*16=256个线程,每4行就是一个线程束。
并行规约
计算积分公式,计算一个从0到40000π的积分

#include <cstdio>
#include "timer.h"
#include <cmath>
// 定义精度
#ifdef DOUBLE_PREC
typedef double real;
#define SIN(x) sin(x)
#define COS(x) cos(x)
#else
typedef float real;
#define SIN(x) sinf(x)
#define COS(x) cosf(x)
#endif// 用积分公式计算
double F(double x)
{double F = x/4 + sin(2*x)/16 - sin(4*x)/16 -sin(6*x)/48;return F;
}int main()
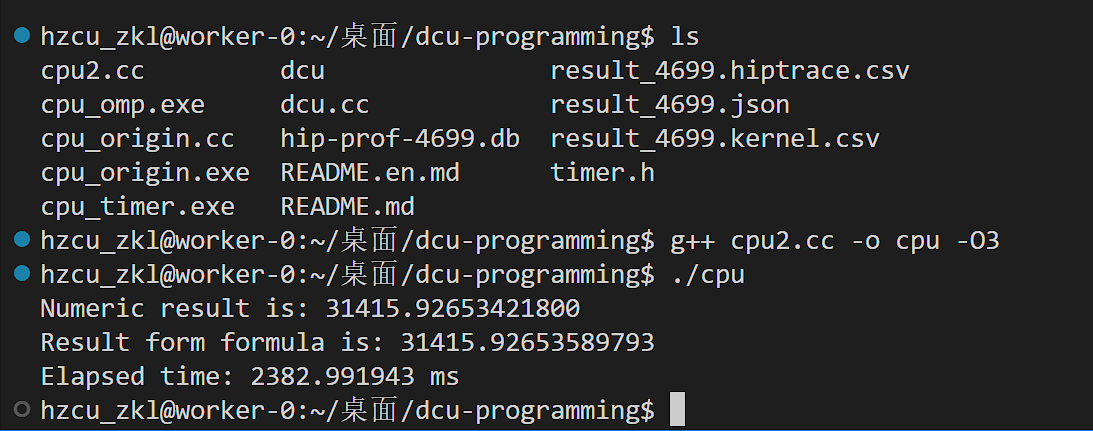
{double lower_bound = 0.0;double upper_bound = 40000 * acos(-1); //acos(-1) = piint N = 1e8;real dx = (upper_bound - lower_bound) / N;double Integral = 0.0;my_timer timer;timer.start();// 数值计算 \int sin^2(2x)*cos^2(2x) dxfor (int i = 0; i < N; i++) {real x = (i + 0.5) * dx;// 减少乘法次数real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;Integral += sin_2x * cos_x * dx;}timer.stop();printf("Numeric result is: %.11f\n", Integral);printf("Result form formula is: %.11f\n",F(upper_bound) - F(lower_bound));printf("Elapsed time: %8.6f ms\n",timer.dt);return 0;
}
单精度版本编译运行
双精度版本编译运行

改为DCU版本的代码
#include <cstdio>
#include "timer.h"
#include <cmath>
#include <hip/hip_runtime.h>
// 定义精度
#ifdef DOUBLE_PREC
typedef double real;
#define SIN(x) sin(x)
#define COS(x) cos(x)
#else
typedef float real;
#define SIN(x) sinf(x)
#define COS(x) cosf(x)
#endif
//前面都一样// 用积分公式计算
double F(double x)
{double F = x/4 + sin(2*x)/16 - sin(4*x)/16 -sin(6*x)/48;return F;
}// DCU 核函数
__global__
void integral_kernel(double* Integral, double lb, int N, real dx)
{int i = blockIdx.x * blockDim.x + threadIdx.x;int tid = threadIdx.x;if (i < N) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;*Integral += sin_2x * cos_x * dx;}
}int main()
{double lower_bound = 0.0;double upper_bound = 40000 * acos(-1); //acos(-1) = piint N = 1e8;real dx = (upper_bound - lower_bound) / N;double Integral = 0.0;//申请内存double* d_Integral;hipMalloc(&d_Integral,sizeof(double));// 核函数启动配置int blockSize = 256;int numBlocks = (N + blockSize - 1) / blockSize;// 开始计时my_timer timer;timer.start();//d_Integral是DCU中的指针,Integral是CPU中的变量hipMemcpy(d_Integral,&Integral,sizeof(double),hipMemcpyHostToDevice);//lower_bound积分下限integral_kernel<<<numBlocks, blockSize>>>(d_Integral,lower_bound,N,dx);hipMemcpy(&Integral,d_Integral,sizeof(double),hipMemcpyDeviceToHost);timer.stop();printf("Numeric result is: %.11f\n", Integral);printf("Result form formula is: %.11f\n",F(upper_bound) - F(lower_bound));printf("Elapsed time: %8.6f ms\n",timer.dt);hipFree(d_Integral);return 0;
}
运行
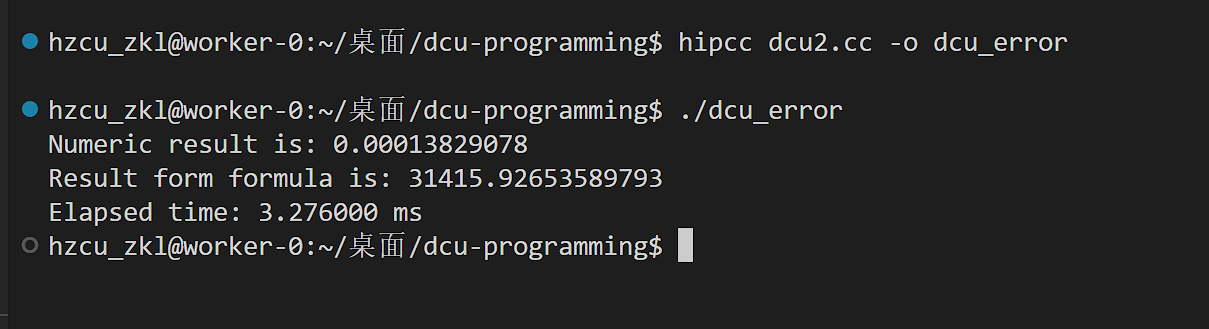
但是这个结果是错误的,因为并行规约问题
并行规约:让多个线程并行做计算,但最后需要把所有结果归并为一个值,这类问题被称为并行规约问题。
在上面的代码中,多个线程会同时从d_Integral(所保存的地址)中取值,把本线程的结果加到这个值上再存回d_Integral中。以两个线程为例,假设此时d_Integral的值还是0,线程1算出结果dF1,线程2算出结果dF2,线程1从d_Integral处取值0,0加上dF1还是dF1,此时线程1把dF1写回d_Integral;如果线程1还没完成写回,线程2就从d_Integral处取值,仍然得到0,0加dF2等于dF2,线程将dF2写回d_Integral。这种情况下如果线程1先完成写回,d_Integral最终就是dF1,如果线程2先完成写回,结果就是dF2,但无论如何不是正确的结果dF1+dF2。
感觉有点像读者-写者问题。
解决办法使用原子操作:所谓“原子”的意思是上面叙述的一个线程对d_Integral的读-加-写回这三个动作是不可分的,借用了“原子”这个词不可再分的原意。当一个线程执行这个操作时,必须得把读-加-写回这三个操作全部做完,在此期间别的线程不能执行此操作。
#include <cstdio>
#include "timer.h"
#include <cmath>
#include <hip/hip_runtime.h>
// 定义精度
#ifdef DOUBLE_PREC
typedef double real;
#define SIN(x) sin(x)
#define COS(x) cos(x)
#else
typedef float real;
#define SIN(x) sinf(x)
#define COS(x) cosf(x)
#endif
//前面都一样// 用积分公式计算
double F(double x)
{double F = x/4 + sin(2*x)/16 - sin(4*x)/16 -sin(6*x)/48;return F;
}// DCU 核函数
__global__
void integral_kernel(double* Integral, double lb, int N, real dx)
{int i = blockIdx.x * blockDim.x + threadIdx.x;int tid = threadIdx.x;if (i < N) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;//修改*Integral += sin_2x * cos_x * dx;atomicAdd(Integral,sin_2x * cos_x * dx);}
}int main()
{double lower_bound = 0.0;double upper_bound = 40000 * acos(-1); //acos(-1) = pi//修改int N = 1e8;int N = 1e6;real dx = (upper_bound - lower_bound) / N;double Integral = 0.0;//申请内存double* d_Integral;hipMalloc(&d_Integral,sizeof(double));// 核函数启动配置int blockSize = 256;int numBlocks = (N + blockSize - 1) / blockSize;// 开始计时my_timer timer;timer.start();//d_Integral是DCU中的指针,Integral是CPU中的变量hipMemcpy(d_Integral,&Integral,sizeof(double),hipMemcpyHostToDevice);//lower_bound积分下限integral_kernel<<<numBlocks, blockSize>>>(d_Integral,lower_bound,N,dx);hipMemcpy(&Integral,d_Integral,sizeof(double),hipMemcpyDeviceToHost);timer.stop();printf("Numeric result is: %.11f\n", Integral);printf("Result form formula is: %.11f\n",F(upper_bound) - F(lower_bound));printf("Elapsed time: %8.6f ms\n",timer.dt);hipFree(d_Integral);return 0;
}
运行结果
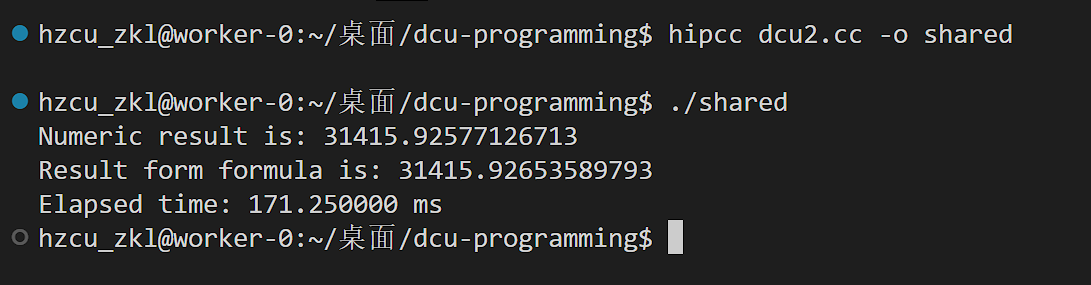
利用共享内存优化
也就是把之前调用全局内存中的数据优化到LDS,从而提升速度。
核函数修改
__global__
void integral_kernel(double* Integral, double lb, int N, real dx)
{int i = blockIdx.x * blockDim.x + threadIdx.x;int tid = threadIdx.x;//线程ID的变量__shared__ double tmp_sh;//让线程初始化if (tid == 0) tmp_sh = 0.0;//让线程ID为0的线程(tid == 0)将其初始化为0。__syncthreads();//内置函数,作用是令线程块同步,即等待线程ID为0的线程初始化tmp_sh之后,所有线程才能继续往下执行。if (i < N) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;atomicAdd(&tmp_sh,sin_2x * cos_x * dx);}//所有线程向共享内存做原子加__syncthreads();if (tid == 0 ) atomicAdd(Integral,tmp_sh);//由线程ID为0的线程对全局内存中的d_Integral做一次原子加即可。
}
N改回1e8
#include <cstdio>
#include "timer.h"
#include <cmath>
#include <hip/hip_runtime.h>
// 定义精度
#ifdef DOUBLE_PREC
typedef double real;
#define SIN(x) sin(x)
#define COS(x) cos(x)
#else
typedef float real;
#define SIN(x) sinf(x)
#define COS(x) cosf(x)
#endif
//前面都一样// 用积分公式计算
double F(double x)
{double F = x/4 + sin(2*x)/16 - sin(4*x)/16 -sin(6*x)/48;return F;
}// DCU 核函数
// __global__
// void integral_kernel(double* Integral, double lb, int N, real dx)
// {
// int i = blockIdx.x * blockDim.x + threadIdx.x;
// int tid = threadIdx.x;
// if (i < N) {
// real x = lb + (i + 0.5) * dx;
// real sin_2x = SIN(2 * x);
// sin_2x *= sin_2x;
// real cos_x = COS(x);
// cos_x *= cos_x;
// //修改*Integral += sin_2x * cos_x * dx;
// atomicAdd(Integral,sin_2x * cos_x * dx);
// }
// }
__global__
void integral_kernel(double* Integral, double lb, int N, real dx)
{int i = blockIdx.x * blockDim.x + threadIdx.x;int tid = threadIdx.x;//线程ID的变量__shared__ double tmp_sh;//让线程初始化if (tid == 0) tmp_sh = 0.0;//让线程ID为0的线程(tid == 0)将其初始化为0。__syncthreads();//内置函数,作用是令线程块同步,即等待线程ID为0的线程初始化tmp_sh之后,所有线程才能继续往下执行。if (i < N) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;atomicAdd(&tmp_sh,sin_2x * cos_x * dx);}//所有线程向共享内存做原子加__syncthreads();if (tid == 0 ) atomicAdd(Integral,tmp_sh);//由线程ID为0的线程对全局内存中的d_Integral做一次原子加即可。
}int main()
{double lower_bound = 0.0;double upper_bound = 40000 * acos(-1); //acos(-1) = piint N = 1e8;//int N = 1e6;real dx = (upper_bound - lower_bound) / N;double Integral = 0.0;//申请内存double* d_Integral;hipMalloc(&d_Integral,sizeof(double));// 核函数启动配置int blockSize = 256;int numBlocks = (N + blockSize - 1) / blockSize;// 开始计时my_timer timer;timer.start();//d_Integral是DCU中的指针,Integral是CPU中的变量hipMemcpy(d_Integral,&Integral,sizeof(double),hipMemcpyHostToDevice);//lower_bound积分下限integral_kernel<<<numBlocks, blockSize>>>(d_Integral,lower_bound,N,dx);hipMemcpy(&Integral,d_Integral,sizeof(double),hipMemcpyDeviceToHost);timer.stop();printf("Numeric result is: %.11f\n", Integral);printf("Result form formula is: %.11f\n",F(upper_bound) - F(lower_bound));printf("Elapsed time: %8.6f ms\n",timer.dt);hipFree(d_Integral);return 0;
}
运行后发现优化了很多
为什么tmp_sh是共享内存?
使用了 __shared__ 关键字。共享内存是一种特殊类型的存储器,可以在同一个线程块(block)内的所有线程之间共享。
现在是每个线程块会有一次原子加,继续优化的话要减少线程块个数。
一个自然的想法是增加线程块的大小。将blockSize修改为1024。但是结果却反而耗时更长。
为什么?
将 blockSize 增加到 1024 后反而使得程序运行时间变长,这可能是由于以下几个原因:
- 资源竞争:每个 CUDA 核函数执行需要使用一定数量的硬件资源,如寄存器和共享内存。增加线程块的大小会增加每个线程块对这些资源的需求。如果超出了设备的资源限制,会导致无法同时调度足够多的线程块,从而降低并行度和性能。
- 共享内存冲突:虽然共享内存访问比全局内存访问快,但增加线程块的大小会增加共享内存的使用频率,可能导致银行冲突(bank conflicts)。共享内存是分成多个银行的,如果多个线程访问同一个银行中的数据,就会导致访问冲突,从而增加延迟。
- 线程调度开销:每个多处理器(Streaming Multiprocessor, SM)上可以并行执行的线程块数目是有限的,取决于线程块的大小和使用的资源量。增大线程块大小可能会减少能够同时调度的线程块数,从而减少并行度和效率。
- 内存带宽瓶颈:即使共享内存的使用优化了某些方面的性能,但总体计算仍需大量访问全局内存。增大线程块大小可能导致更多的线程同时访问全局内存,增加了内存带宽压力,反而会使得内存访问变慢。
感觉大概率是银行冲突。
是否有办法优化对共享内存的原子加呢?
一种方法是线程束洗牌函数(warp shuffle)的内置函数来实现。它们的作用是让线程获取到线程束内其他线程的局部变量的值,从硬件层面讲仍然是利用共享内存实现的。
核函数修改(感觉像是减少LDS读取)
__global__ __launch_bounds__(1024)
void integral_kernel(double* Integral, double lb, int N, real dx)
{int i = blockIdx.x * blockDim.x + threadIdx.x;int tid = threadIdx.x;double tmp = 0.0;__shared__ double tmp_sh;if (tid == 0) tmp_sh = 0.0;__syncthreads();if (i < N) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;tmp += sin_2x * cos_x * dx;int delta = 1;for (int j = 0; j < 6; j++) {tmp += __shfl_down(tmp,delta,64);delta += delta;}if (tid%64==0) atomicAdd(&tmp_sh,tmp);__syncthreads();if (tid == 0 ) atomicAdd(Integral,tmp_sh);}
}
使用了__shfl_down这个函数,它的作用是使一个线程束内,线程ID为id的线程,获取到线程ID为(id+delta)的线程的局部变量tmp的值,64是一个线程束中线程的个数,对于线程id+delta超过64的线程,还是得到自己的tmp值。
举例来说,当delta=1时,对于线程0,这个函数返回线程1的tmp;对于线程2,这个函数返回线程3的tmp;对于线程63,这个函数则返回自己的tmp。当delta=2时,对于线程0,此时它的tmp已是进行洗牌前的线程0和线程1的tmp之和,再用__shfl_down把线程2的tmp(洗牌前的线程2和线程3的tmp之和)传给它,加在一起就是洗牌前线程0-3的tmp之和。当delta=4时,会把线程4的tmp(洗牌前线程4-7的tmp之和)传给线程0,加在一起是洗牌前线程0-7的tmp之和。
以此类推,随着j不断循环,delta=8时,线程0的tmp为洗牌前线程0-15的tmp之和,delta=16时,是线程0-31的tmp之和,delta=32时,是线程0-63的tmp之和。

通过调用6次__shfl_down,线程束内的线程0的tmp为所有线程的tmp之和,然后再由每个线程束中的线程0(tid模64为0)将tmp值原子加到共享内存tmp_sh中,这样就把每个线程束中64个线程一起对tmp_sh做原子加改成了6次__shfl_down之后由一个线程对tmp_sh做原子加。
假设初始时每个线程的tmp值如下:
- 线程0:
tmp[0] - 线程1:
tmp[1] - 线程2:
tmp[2] - 线程3:
tmp[3] - 线程4:
tmp[4] - 线程5:
tmp[5] - …
在第一次循环 (delta = 1) 后,每个线程的tmp值变为:
- 线程0:
tmp[0] + tmp[1] - 线程1:
tmp[1] + tmp[2] - 线程2:
tmp[2] + tmp[3] - 线程3:
tmp[3] + tmp[4] - 线程4:
tmp[4] + tmp[5] - …
在第二次循环 (delta = 2) 后,每个线程的tmp值变为:
- 线程0:
tmp[0] + tmp[1] + tmp[2] + tmp[3] - 线程1:
tmp[1] + tmp[2] + tmp[3] + tmp[4] - 线程2:
tmp[2] + tmp[3] + tmp[4] + tmp[5] - 线程3:
tmp[3] + tmp[4] + tmp[5] + tmp[6] - 线程4:
tmp[4] + tmp[5] + tmp[6] + tmp[7] - …
是否还有其他办法优化对共享内存的原子加呢
使用分块原子加
使用warp shuffle函数
使用分层原子加
使用分布式原子加
进一步优化
可以进一步减少线程数量,虽然减少没有足够线程执行N次核函数,但是可以多跑几次。
核函数
__global__ __launch_bounds__(1024)
void integral_kernel(double* Integral, double lb, int N, real dx)
{int index = blockIdx.x * blockDim.x + threadIdx.x;int stride = gridDim.x * blockDim.x;int tid = threadIdx.x;double tmp = 0.0;__shared__ double tmp_sh;if (tid == 0) tmp_sh = 0.0;__syncthreads();for (int i = index; i < N; i += stride) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;tmp += sin_2x * cos_x * dx;}int delta = 1;for (int j = 0; j < 6; j++) {tmp += __shfl_down(tmp,delta,64);delta += delta;}if (tid%64==0) atomicAdd(&tmp_sh,tmp);__syncthreads();if (tid == 0 ) atomicAdd(Integral,tmp_sh);
}
核函数中,CPU版本的for循环又回来了,但这次循环计数i并不是从0开始每次递增1,而是对于每个线程来说从index开始,每次递增stride,index是线程在这个核函数启动的所有线程中的索引,stride是这个核函数启动的总线程数。当核函数启动的总线程数少于循环次数N时,每个线程就从循环计数为index的循环开始,负责循环计数相差stride的所有循环,直到把N次循环全部做完。
用空间换时间
还有一种可行的思路,既然对全局内存做原子加比较慢,我们可以申请长度为线程总数的数组,这样每个线程可以把计算结果保存在不同的位置,避免多个线程对同一位置的原子加,之后再单独对这个数组中的元素求和。这是一种用空间换时间的方法,同样是一种权衡。
核函数
__global__
void integral_kernel(double* res_warp, double lb, int N,real dx)
{int index = blockIdx.x * blockDim.x + threadIdx.x;int stride = gridDim.x * blockDim.x;int tid = threadIdx.x;double tmp = 0.0;for (int i = index; i < N; i += stride) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;tmp += sin_2x * cos_x * dx;}int delta = 1;for (int j = 0; j < 6; j++) {tmp += __shfl_down(tmp,delta,64);delta += delta;}if (tid == 0) res_warp[blockIdx.x] = tmp;
}
主函数
int main()
{double lower_bound = 0.0;double upper_bound = 40000 * acos(-1); //acos(-1) = piint N = 1e8;real dx = (upper_bound - lower_bound) / N;double Integral = 0.0;// 核函数启动配置int blockSize = 64;int numBlocks = (N / 100 + blockSize - 1) / blockSize;// 用于存储每个warp的结果int size = numBlocks * sizeof(double);double* res_warp = (double *) malloc(size);double* d_res_warp;hipMalloc(&d_res_warp,size);// 开始计时my_timer timer;timer.start();integral_kernel<<<numBlocks, blockSize>>>(d_res_warp,lower_bound,N,dx);hipMemcpy(res_warp,d_res_warp,size,hipMemcpyDeviceToHost);for (int i = 0; i < numBlocks; i++) {Integral += res_warp[i];}timer.stop();printf("Numeric result is: %.11f\n", Integral);printf("Result form formula is: %.11f\n",F(upper_bound) - F(lower_bound));printf("Elapsed time: %8.6f ms\n",timer.dt);hipFree(d_res_warp);free(res_warp);return 0;
}
CPU求和也可以用核函数
__global__
void sum_kernel(double* res_warp, int numBlocks,double* Integral)
{int index = blockIdx.x * blockDim.x + threadIdx.x;int stride = gridDim.x * blockDim.x;int tid = threadIdx.x;double tmp = 0.0;
#if 1index *= 2;stride *= 2;// 如果numBlocks是奇数// 用0号线程把res_warp[numBlocks-1]单独读取if (numBlocks%2==1) {if (tid==0) tmp = res_warp[numBlocks-1];numBlocks -= 1;}for (int i = index; i < numBlocks; i += stride) {// 从全局内存一条指令读取128位,即两个double型tmp += res_warp[i] + res_warp[i+1];}
#elsefor (int i = index; i < numBlocks; i += stride) {tmp += res_warp[i];}
#endifint delta = 1;for (int j = 0; j < 6; j++) {tmp += __shfl_down(tmp,delta,64);delta += delta;}if (tid == 0) *Integral = tmp;
}
在主机代码中,现在不再需要主机内存中的空间res_warp,仅在设备端为d_res_warp分配内存即可,但这次最终的积分结果d_Integral需要拷贝回主机。至于sum_kernel,我们只使用一个线程束来执行,这样在核函数的最后直接用线程0对d_Integral赋值即可。
但是我最后运行的elapsed time还是挺久的,不知道为啥
异步并发执行
主要了解流水线技术,使用代码
#include <cstdio>
#include "timer.h"
#include <cmath>
#include <hip/hip_runtime.h>
// 定义精度
#ifdef DOUBLE_PREC
typedef double real;
#define SIN(x) sin(x)
#define COS(x) cos(x)
#else
typedef float real;
#define SIN(x) sinf(x)
#define COS(x) cosf(x)
#endif
double F(double x)
{double F = x/4 + sin(2*x)/16 - sin(4*x)/16 -sin(6*x)/48;return F;
}
__global__
void integral_kernel(double* res_warp, double lb, int N,real dx)
{int index = blockIdx.x * blockDim.x + threadIdx.x;int stride = gridDim.x * blockDim.x;int tid = threadIdx.x;double tmp = 0.0;for (int i = index; i < N; i += stride) {real x = lb + (i + 0.5) * dx;real sin_2x = SIN(2 * x);sin_2x *= sin_2x;real cos_x = COS(x);cos_x *= cos_x;tmp += sin_2x * cos_x * dx;}int delta = 1;for (int j = 0; j < 6; j++) {tmp += __shfl_down(tmp,delta,64);delta += delta;}if (tid == 0) res_warp[blockIdx.x] = tmp;
}int main()
{double lower_bound = 0.0;double upper_bound = 40000 * acos(-1); //acos(-1) = pidouble range = upper_bound - lower_bound;int N = 1e8;real dx = range / N;int numIntervals = 8;double Integral = 0.0;// 核函数启动配置int blockSize = 64;int numBlocks = (N + blockSize - 1) / blockSize;// 用于存储每个warp的结果int size = numBlocks * sizeof(double);double* res_warp = (double *) malloc(size);double* d_res_warp;hipMalloc(&d_res_warp,size);// 开始计时my_timer timer;timer.start();for (int j = 0; j < numIntervals; j++) {integral_kernel<<<numBlocks, blockSize>>>(d_res_warp,lower_bound,N,dx);hipMemcpy(res_warp,d_res_warp,size,hipMemcpyDeviceToHost);for (int i = 0; i < numBlocks; i++) {Integral += res_warp[i];}lower_bound += range;}timer.stop();printf("Numeric result is: %.11f\n", Integral);printf("Result form formula is: %.11f\n",F(range*numIntervals) - F(0));printf("Elapsed time: %8.6f ms\n",timer.dt);hipFree(d_res_warp);free(res_warp);return 0;
}
使用性能分析工具
打开chrome://tracing分析json文件
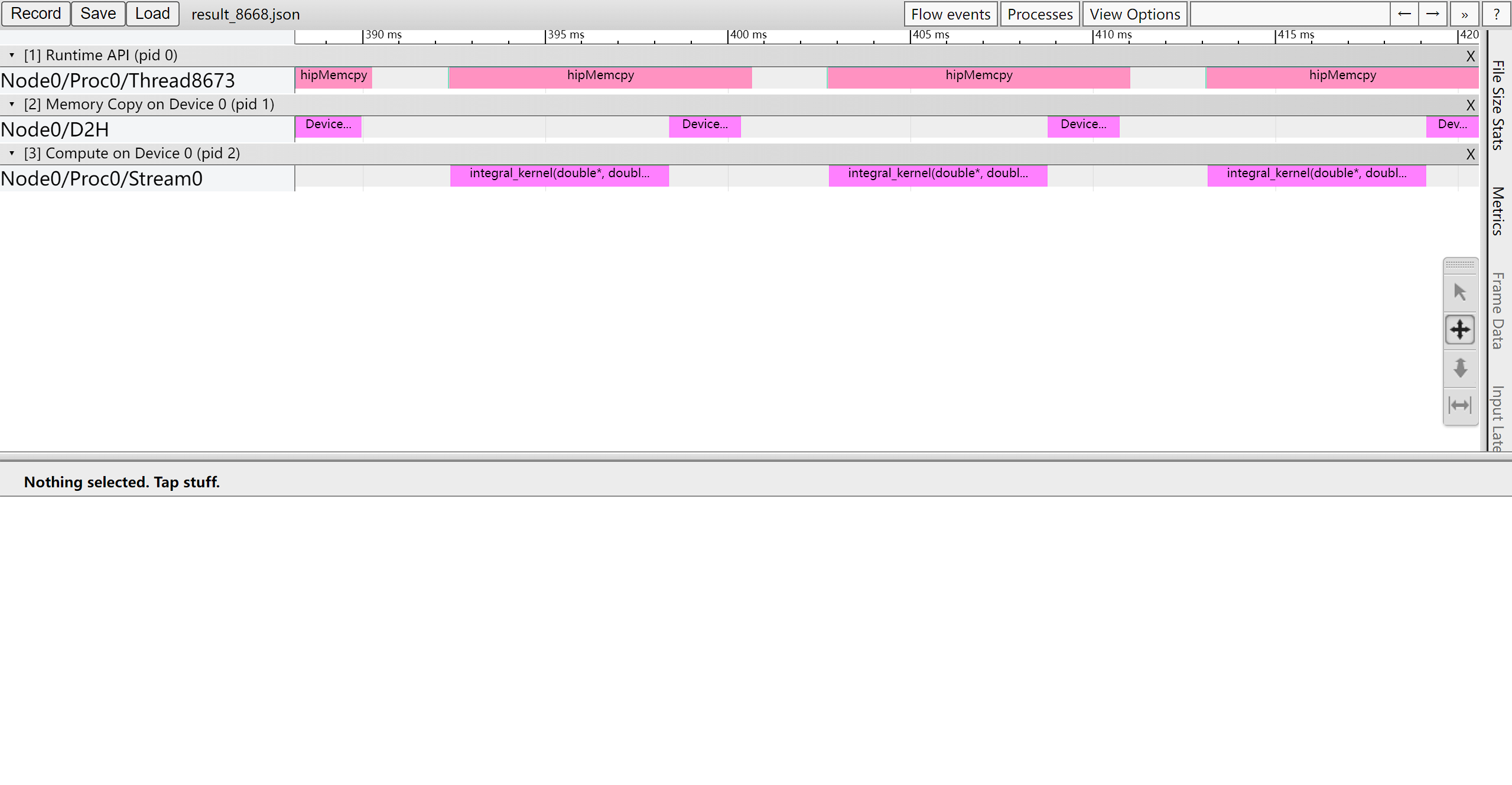
第一行是主机API,第二行是拷贝,第三行则是核函数。
可以看到执行integral核函数,device到主机host,hipMemcpy完成。但是中间有一段时间空着。
DCU等待这段时间是没有必要的,它可以立刻继续执行核函数integral_kernel,这只会改变设备上d_res_warp的内容而不会改变主机上res_warp的内容;在DCU执行核函数的同时主机来做对Integral的累加,完成后再将DCU新计算的d_res_warp的结果拷贝过来,这样才更有效率。
当前的代码无法实现这种想法,因为主机是串行执行,只有在当前循环的累加执行完毕后,才能做下一次循环中的核函数调用。为此,一种思路是使用主机的多线程并行,一个线程负责累加,另一个线程调用核函数。但其实使用一个主机也可以完成,修改主机代码
timer.start();// 对第一个区间计算并拷贝后,不立刻在主机端求和// 而是先启动下一个区间计算的核函数integral_kernel<<<numBlocks, blockSize>>>(d_res_warp,lower_bound,N,dx);hipMemcpy(res_warp,d_res_warp,size,hipMemcpyDeviceToHost);lower_bound += range;for (int j = 1; j < numIntervals; j++) {// 启动核函数计算当前区间integral_kernel<<<numBlocks, blockSize>>>(d_res_warp,lower_bound,N,dx);// 主机端同时对上一个区间求和for (int i = 0; i < numBlocks; i++) {Integral += res_warp[i];}// 求和完毕后,拷贝当前区间的结果hipMemcpy(res_warp,d_res_warp,size,hipMemcpyDeviceToHost);lower_bound += range;}// 最后一个区间的求和for (int i = 0; i < numBlocks; i++) {Integral += res_warp[i];}timer.stop();
这样修改后就有重叠时间了,在空白等待时候也可以计算
进一步优化的想法理所应当是让相邻区间的计算时间有更多的重叠,可以让多个核函数一部执行。
在DCU编程中,可以创建被称为“流(stream)”的设备端队列,并将拷贝以及核函数发布在流上。同一个流上的任务是按入列的顺序串行执行的,不同流上的任务则是异步并发的,当然如果一个流的任务已占据了所需的软硬件资源,另一个流的任务则需要等待。
如何将拷贝和核函数发布在指定流上。此前我们使用的拷贝API是hipMemcpy,它有一个异步版本hipMemcpyAsync,相比同步版本多一个流参数。对于核函数,在前面的例子中三个尖括号“<<<>>>”中的核函数启动配置仅包含线程网格和线程块的配置,但启动配置还包括动态共享内存的大小以及流,分别是三个尖括号中的第三和第四个参数。
使用双缓冲方法为每个区间分配不同d_res_wrap
定义缓冲结构体Buffer
struct Buffer
{double* res_warp;double* d_res_warp;hipStream_t stream;void alloc(int size) {hipHostMalloc(&res_warp,size);hipMalloc(&d_res_warp,size);hipStreamCreate(&stream);}void dealloc() {hipHostFree(res_warp);hipFree(d_res_warp);hipStreamDestroy(stream);}
};
将res_warp和d_res_warp都包含在Buffer中,此外还有流变量stream。在Buffer中还有两个成员函数alloc和dealloc,用于申请/释放空间以及创建/销毁流。对于使用hipMalloc和hipFree申请和释放设备内存无需多言;对于主机内存,这里使用了hipHostMalloc和hipHostFree,而非之前的malloc和free,原因是对于涉及主机端内存的拷贝,如果想要异步,则主机端内存必须是页锁定的(page-locked),否则即使使用异步版本的拷贝hipMemcpyAsync,拷贝仍然是同步的。目前用到的hipHostMalloc和hipHostFree是专门用来申请与释放页锁定主机内存的API。剩下的hipStreamCreate和hipStreamDestory两个API则是关于流的,分别用于创建与销毁。
修改之后就是多个流

主机-设备间拷贝与页锁定内存
在流中可以插入事件:
- 处理两个流之间的依赖问题
- 计时
核函数并发执行
矩阵乘法
好像和前面差不多
使用DTK库计算—>编写核函数->LDS优化->使用更多矩阵元
共享内存的bank冲突
相关文章:
万字学习——DCU编程实战
参考资料 2.1 DCU软件栈(DCU ToolKit, DTK) DCU 开发与使用文档 (hpccube.com) DCU软件栈 DCU的软件栈—DCU Toolkit(DTK) HIP(Heterogeneous-Compute Interface for Portability)是AMD公司在2016年提出…...

Neo4j 图数据库 高级操作
Neo4j 图数据库 高级操作 文章目录 Neo4j 图数据库 高级操作1 批量添加节点、关系1.1 直接使用 UNWIND 批量创建关系1.2 使用 CSV 文件批量创建关系1.3 选择方法 2 索引2.1 创建单一属性索引2.2 创建组合属性索引2.3 创建全文索引2.4 列出所有索引2.5 删除索引2.6 注意事项 3 清…...

《RWKV》论文笔记
原文出处 [2305.13048] RWKV: Reinventing RNNs for the Transformer Era (arxiv.org) 原文笔记 What RWKV(RawKuv):Reinventing RNNs for the Transformer Era 本文贡献如下: 提出了 RWKV 网络架构,结合了RNNS 和Transformer 的优点,同…...
——显色指数(Ra))
相机光学(二十九)——显色指数(Ra)
显指Ra是衡量光源显色性的数值,表示光源对物体颜色的还原能力。显色性是指光源对物体颜色的呈现能力,即光源照射在同一颜色的物体上时,所呈现的颜色特性。通常用显色指数(CRI)来表示光源的显色性,而显指Ra是…...

【Swoole 的生命周期,文件描述符,协程数量,以及默认值】
目录 Swoole 的生命周期 Swoole 文件描述符(FD)缓存 Swoole设置协程的数量 Swoole 默认值 Swoole 是一个基于 PHP 的高性能网络通信引擎,它采用 C 编写,提供了协程和高性能的网络编程支持。Swoole 支持多种网络服务器和客户端…...

“不要卷模型,要卷应用”之高考志愿填报智能体
摘要:李总的发言深刻洞察了当前人工智能领域的发展趋势与核心价值所在,具有高度的前瞻性和实践性。“大家不要卷模型,要卷应用”这一观点强调了在当前人工智能领域,应该更加注重技术的实际应用而非单纯的技术竞赛或模型优化。个性…...

k8s离线部署芋道源码后端
目录 概述实践Dockerfilek8s部署脚本 概述 本篇将对 k8s离线部署芋道源码后端 进行详细的说明,对如何构建 Dockerfile,如何整合 Nginx,如何整合 ingress 进行实践。 相关文章:[nacos在k8s上的集群安装实践] k8s离线部署芋道源码前…...
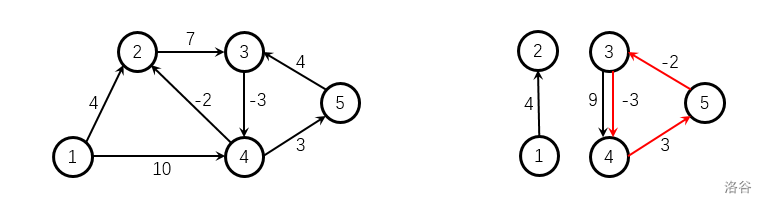
图论·Day01
P3371 P4779 P3371 【模板】单源最短路径(弱化版) 注意的点: 边有重复,选择最小边!对于SPFA算法容易出现重大BUG,没有负权值的边时不要使用!!! 70分代码 朴素板dijsk…...

hutool ExcelUtil 导出导入excel
引入依赖 <dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.15</version></dependency>文件导入 public void savelist(String filepath,String keyname){ExcelReader reader Exce…...

打卡第7天-----哈希表
继续坚持✊,我现在看到leetcode上的题不再没有思路了,真的是思路决定出路,在做题之前一定要把思路梳理清楚。 一、四数相加 leetcode题目编号:第454题.四数相加II 题目描述: 给定四个包含整数的数组列表 A , B , C , …...
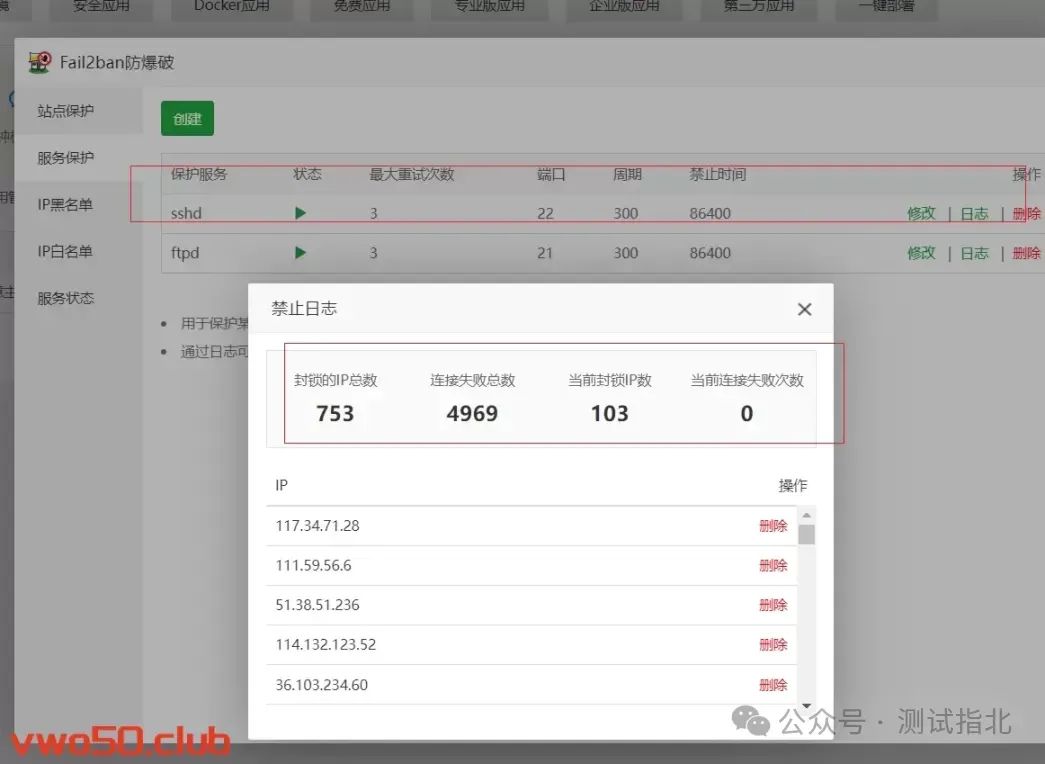
【Linux】WEB网站网络防火墙(WAF软件)Fail2ban:保护服务器免受恶意攻击的必备工具
随着互联网的迅速发展,服务器的安全性日益成为用户和管理员关注的焦点。恶意攻击者不断寻找机会侵入服务器,窃取敏感信息、破坏数据或者滥用系统资源。为了抵御这些威胁,许多安全工具应运而生,其中一款备受推崇的工具就是 Fail2ba…...

妙笔生词智能写歌词软件:创新助力还是艺术之殇?
在音乐创作日益普及和多样化的当下,各种辅助工具层出不穷,妙笔生词智能写歌词软件便是其中之一。那么,它到底表现如何呢? 妙笔生词智能写歌词软件(veve522)的突出优点在于其便捷性和高效性。对于那些灵感稍…...

力扣hot100-普通数组
文章目录 题目:最大子数组和方法1 动态规划方法2 题目:合并区间题解 题目:轮转数组方法1-使用额外的数组方法2-三次反转数组 题目:除自身以外数组的乘积方法1-用到了除法方法2-前后缀乘积法 题目:最大子数组和 原题链…...
深入浅出Transformer:大语言模型的核心技术
引言 随着自然语言处理(NLP)领域的不断发展,Transformer模型逐渐成为现代大语言模型的核心技术。无论是BERT、GPT系列,还是最近的T5和Transformer-XL,这些模型的背后都离不开Transformer架构。本文将详细介绍Transfor…...

MacOS隐藏文件打开指南
MacOS隐藏文件打开指南 方法一: 直接按下键盘上的【commandshift.】,这时候就可以在mac系统中就会自动显示隐藏的文件夹了 方法二: 在终端查看 ls -la...

grafana数据展示
目录 一、安装步骤 二、如何添加喜欢的界面 三、自动添加注册客户端主机 一、安装步骤 启动成功后 可以查看端口3000是否启动 如果启动了就在浏览器输入IP地址:3000 账号密码默认是admin 然后点击 log in 第一次会让你修改密码 根据自定义密码然后就能登录到界面…...

53-4 内网代理6 - frp搭建三层代理
前提:53-3 内网代理5 - frp搭建二级代理-CSDN博客 三级网络代理 在办公区入侵后,发现需要进一步渗透核心区网络(192.168.60.0/24),并登录域控制器的远程桌面。使用FRP在EDMZ区、办公区与核心区之间建立三级网络的SOCKS5代理,以便访问核心区的域控制器。 VPS上的FRP服…...

SQLite 命令行客户端 + HTA 实现简易UI
SQLite 命令行客户端 HTA 实现简易UI SQLite 客户端.hta目录结构参考资料 仅用于探索可行性,就只实现了 SELECT。 SQLite 客户端.hta <!DOCTYPE html> <html> <head><meta http-equiv"Content-Type" content"text/html; cha…...

TikTok小店推出“百万英镑俱乐部”,实力宠卖家!
TikTok Shop近期在英国市场重磅推出了“百万英镑俱乐部”激励计划,这一举措旨在通过一系列诱人福利,助力商家在TikTok平台上实现销售飞跃。该计划不仅彰显了TikTok Shop对于商家成长的深切关怀,更以实际行动诠释了“实力宠卖家”的承诺。 我…...

路径规划 | 基于蚁群算法的三维无人机航迹规划(Matlab)
目录 效果一览基本介绍程序设计参考文献 效果一览 基本介绍 基于蚁群算法的三维无人机航迹规划(Matlab)。 蚁群算法(Ant Colony Optimization,ACO)是一种模拟蚂蚁觅食行为的启发式算法。该算法通过模拟蚂蚁在寻找食物时…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...