Python酷库之旅-第三方库Pandas(013)
目录
一、用法精讲
31、pandas.read_feather函数
31-1、语法
31-2、参数
31-3、功能
31-4、返回值
31-5、说明
31-6、用法
31-6-1、数据准备
31-6-2、代码示例
31-6-3、结果输出
32、pandas.DataFrame.to_feather函数
32-1、语法
32-2、参数
32-3、功能
32-4、返回值
32-5、说明
32-6、用法
32-6-1、数据准备
32-6-2、代码示例
32-6-3、结果输出
33、pandas.read_parquet函数
33-1、语法
33-2、参数
33-3、功能
33-4、返回值
33-5、说明
33-6、用法
33-6-1、数据准备
33-6-2、代码示例
33-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
31、pandas.read_feather函数
31-1、语法
# 31、pandas.read_feather函数
pandas.read_feather(path, columns=None, use_threads=True, storage_options=None, dtype_backend=_NoDefault.no_default)
Load a feather-format object from the file path.Parameters:
pathstr, path object, or file-like object
String, path object (implementing os.PathLike[str]), or file-like object implementing a binary read() function. The string could be a URL. Valid URL schemes include http, ftp, s3, and file. For file URLs, a host is expected. A local file could be: file://localhost/path/to/table.feather.columnssequence, default None
If not provided, all columns are read.use_threadsbool, default True
Whether to parallelize reading using multiple threads.storage_optionsdict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open. Please see fsspec and urllib for more details, and for more examples on storage options refer here.dtype_backend{‘numpy_nullable’, ‘pyarrow’}, default ‘numpy_nullable’
Back-end data type applied to the resultant DataFrame (still experimental). Behaviour is as follows:"numpy_nullable": returns nullable-dtype-backed DataFrame (default)."pyarrow": returns pyarrow-backed nullable ArrowDtype DataFrame.New in version 2.0.Returns:
type of object stored in file31-2、参数
31-2-1、path(必须):文件路径(字符串或路径对象),指向要读取的Feather格式文件。
31-2-2、columns(可选,默认值为None):指定要读取的列名列表,如果为None(默认值),则读取文件中的所有列,这可以用于减少内存使用,特别是当只需要文件中的部分列时。
31-2-3、use_threads(可选,默认值为True):是否使用多线程来加速读取过程,默认为True,意味着将尝试使用多线程来加速读取,但这可能取决于底层系统和Python解释器的实现,在某些情况下,关闭多线程(use_threads=False)可能会提供更好的性能。
31-2-4、storage_options(可选,默认值为None):用于文件系统的额外选项,比如S3或Google Cloud Storage等,这些选项将传递给底层的文件系统对象。对于大多数用户来说,这个参数可能不需要设置,除非你在处理存储在特殊存储系统中的Feather文件。
31-2-5、dtype_backend(可选):内部调用,通常不需要用户直接设置。
31-3、功能
用于从文件路径中加载Feather格式的对象。
31-4、返回值
返回值是存储在Feather文件中的对象类型,通常是pandas.DataFrame。如果Feather文件中存储的是DataFrame类型的数据,那么read_feather函数就会读取这些数据并返回一个DataFrame对象。
31-5、说明
Feather格式是一种二进制文件格式,专为pandas DataFrame的高效读写而设计,它相比其他文本格式(如CSV)具有更快的读写速度和更小的文件大小,因此,这个函数非常适合于需要快速加载大型数据集的场景。
31-6、用法
31-6-1、数据准备
无31-6-2、代码示例
# 31、pandas.read_feather函数
# 运行此程序,务必确保你已经安装了pyarrow或fastparquet库
import pandas as pd
import numpy as np
# 创建一个简单的DataFrame
df = pd.DataFrame({'A': np.random.randn(100), # 生成100个正态分布的随机数'B': np.random.randint(1, 100, 100) # 生成100个1到99之间的随机整数
})
# 保存到Feather文件
file_path = 'example.feather'
try:df.to_feather(file_path)print(f"DataFrame 已成功保存到 {file_path}")
except Exception as e:print(f"保存 Feather 文件时发生错误: {e}")
# 读取Feather文件
try:df_read = pd.read_feather(file_path)print("读取 Feather 文件成功!")# 显示读取的数据print(df_read.head()) # 只显示前几行,以避免打印太多数据
except FileNotFoundError:print(f"文件 {file_path} 未找到,请确保文件存在!")
except Exception as e:print(f"读取 Feather 文件时发生错误: {e}")31-6-3、结果输出
# 31、pandas.read_feather函数
# DataFrame 已成功保存到 example.feather
# 读取 Feather 文件成功!
# A B
# 0 -0.425313 48
# 1 -1.915324 72
# 2 -0.391787 97
# 3 -0.014345 48
# 4 1.813109 5332、pandas.DataFrame.to_feather函数
32-1、语法
# 32、pandas.DataFrame.to_feather函数
DataFrame.to_feather(path, **kwargs)
Write a DataFrame to the binary Feather format.Parameters:
path
str, path object, file-like object
String, path object (implementing os.PathLike[str]), or file-like object implementing a binary write() function. If a string or a path, it will be used as Root Directory path when writing a partitioned dataset.**kwargs
Additional keywords passed to pyarrow.feather.write_feather(). This includes the compression, compression_level, chunksize and version keywords.NotesThis function writes the dataframe as a feather file. Requires a default index. For saving the DataFrame with your custom index use a method that supports custom indices e.g. to_parquet.32-2、参数
32-2-1、path(必须):文件路径(字符串或路径对象),指定输出文件的路径,可以是相对路径或绝对路径,如果文件已经存在,它会被覆盖。
32-2-2、**kwargs(可选):传递给PyArrow Feather写入器的额外关键字参数。虽然Pandas的文档可能不直接列出所有可能的参数,但PyArrow的Feather写入器支持一些有用的选项,例如压缩和元数据。以下是一些可能的有用参数(请注意,这些参数的可用性和具体行为可能随 PyArrow 的版本而异):
32-2-2-1、compression(可选,默认值为None):指定用于压缩文件的压缩算法,可选值包括'lz4', 'zstd', 'uncompressed'和'snappy'(注意:并非所有算法在所有平台上都可用)。
32-2-2-2、compression_level:int(对于某些压缩算法),指定压缩级别,较高的值通常会导致更好的压缩比,但也会增加压缩和解压缩的计算成本。
32-2-2-3、version:int(默认是最新支持的版本),指定要写入的Feather文件的版本,这通常不需要手动指定,除非你有特定的兼容性要求。
32-2-2-4、metadata(可选):一个字典,允许你为文件附加自定义元数据,这些数据将作为文件的元数据存储,可以在读取文件时检索。
32-3、功能
用于将DataFrame保存为Feather格式的文件。
32-4、返回值
本身不返回任何值(即返回None),它的主要作用是将DataFrame保存到指定的文件路径中,而不是生成一个新的DataFrame或其他对象。
32-5、说明
无
32-6、用法
32-6-1、数据准备
无32-6-2、代码示例
# 32、pandas.DataFrame.to_feather函数
# 运行此程序,务必确保你已经安装了pyarrow或fastparquet库
import pandas as pd
# 创建一个示例 DataFrame
df = pd.DataFrame({'A': [1, 2, 3],'B': ['a', 'b', 'c']
})
# 将DataFrame保存为Feather文件
df.to_feather('example.feather')
# 注意:这里不会显示任何返回值,因为 to_feather() 不返回任何内容
# 但是,你可以通过检查文件系统来验证文件是否已被创建
# 稍后,你可以使用pd.read_feather()来重新加载数据
df_loaded = pd.read_feather('example.feather')
print(df_loaded)32-6-3、结果输出
# 32、pandas.DataFrame.to_feather函数
# A B
# 0 1 a
# 1 2 b
# 2 3 c33、pandas.read_parquet函数
33-1、语法
# 33、pandas.read_parquet函数
pandas.read_parquet(path, engine='auto', columns=None, storage_options=None, use_nullable_dtypes=_NoDefault.no_default, dtype_backend=_NoDefault.no_default, filesystem=None, filters=None, **kwargs)
Load a parquet object from the file path, returning a DataFrame.Parameters:
pathstr, path object or file-like object
String, path object (implementing os.PathLike[str]), or file-like object implementing a binary read() function. The string could be a URL. Valid URL schemes include http, ftp, s3, gs, and file. For file URLs, a host is expected. A local file could be: file://localhost/path/to/table.parquet. A file URL can also be a path to a directory that contains multiple partitioned parquet files. Both pyarrow and fastparquet support paths to directories as well as file URLs. A directory path could be: file://localhost/path/to/tables or s3://bucket/partition_dir.engine{‘auto’, ‘pyarrow’, ‘fastparquet’}, default ‘auto’
Parquet library to use. If ‘auto’, then the option io.parquet.engine is used. The default io.parquet.engine behavior is to try ‘pyarrow’, falling back to ‘fastparquet’ if ‘pyarrow’ is unavailable.When using the 'pyarrow' engine and no storage options are provided and a filesystem is implemented by both pyarrow.fs and fsspec (e.g. “s3://”), then the pyarrow.fs filesystem is attempted first. Use the filesystem keyword with an instantiated fsspec filesystem if you wish to use its implementation.columnslist, default=None
If not None, only these columns will be read from the file.storage_optionsdict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open. Please see fsspec and urllib for more details, and for more examples on storage options refer here.New in version 1.3.0.use_nullable_dtypesbool, default False
If True, use dtypes that use pd.NA as missing value indicator for the resulting DataFrame. (only applicable for the pyarrow engine) As new dtypes are added that support pd.NA in the future, the output with this option will change to use those dtypes. Note: this is an experimental option, and behaviour (e.g. additional support dtypes) may change without notice.Deprecated since version 2.0.dtype_backend{‘numpy_nullable’, ‘pyarrow’}, default ‘numpy_nullable’
Back-end data type applied to the resultant DataFrame (still experimental). Behaviour is as follows:"numpy_nullable": returns nullable-dtype-backed DataFrame (default)."pyarrow": returns pyarrow-backed nullable ArrowDtype DataFrame.New in version 2.0.filesystemfsspec or pyarrow filesystem, default None
Filesystem object to use when reading the parquet file. Only implemented for engine="pyarrow".New in version 2.1.0.filtersList[Tuple] or List[List[Tuple]], default None
To filter out data. Filter syntax: [[(column, op, val), …],…] where op is [==, =, >, >=, <, <=, !=, in, not in] The innermost tuples are transposed into a set of filters applied through an AND operation. The outer list combines these sets of filters through an OR operation. A single list of tuples can also be used, meaning that no OR operation between set of filters is to be conducted.Using this argument will NOT result in row-wise filtering of the final partitions unless engine="pyarrow" is also specified. For other engines, filtering is only performed at the partition level, that is, to prevent the loading of some row-groups and/or files.New in version 2.1.0.**kwargs
Any additional kwargs are passed to the engine.Returns:
DataFrame33-2、参数
33-2-1、path(必须):Parquet文件的路径,可以是相对路径或绝对路径。
33-2-2、engine(可选,默认值为'auto'):指定用于读取Parquet文件的底层库,'auto'会自动选择(通常基于已安装的库),'pyarrow'和'fastparquet'是两个流行的Parquet库。
33-2-3、columns(可选,默认值为None):要读取的列名列表,如果指定,则只读取这些列,这可以显著减少内存使用和数据加载时间。
33-2-4、storage_options(可选,默认值为None):传递给文件系统的额外选项,如认证信息或配置设置,这通常用于处理存储在云存储(如AWS S3、Google Cloud Storage)上的Parquet文件。
33-2-5、use_nullable_dtypes(可选):如果为True,则使用Pandas的可空数据类型(如pd.Int64Dtype()、pd.StringDtype())来读取数据,这可以提高数据的准确性和性能,尤其是在处理大型数据集时;如果未指定,则根据Pandas的版本和配置自动选择。
33-2-6、dtype_backend(可选):内部调用,通常不需要用户手动设置。
33-2-7、filesystem(可选,默认值为None):用于读取Parquet文件的文件系统实例,这通常与storage_options一起使用,以处理存储在特定存储系统上的文件。
33-2-8、filters(可选,默认值为None):用于在读取Parquet文件时应用过滤器的表达式列表,这可以显著减少需要加载到内存中的数据量,过滤器的具体语法取决于底层Parquet引擎。
33-2-9、**kwargs(可选):其他关键字参数将传递给底层的Parquet读取器,这些参数可能因使用的引擎而异,因此请参考相应引擎的文档以获取更多信息。
33-3、功能
从指定的文件路径加载Parquet格式的数据,并返回一个Pandas DataFrame对象。
33-4、返回值
返回一个Pandas DataFrame对象,该对象包含了从Parquet文件中读取的数据。
33-5、说明
33-5-1、在处理大型Parquet文件时,建议合理使用columns和filters参数,以减少加载到内存中的数据量,提高读取效率。
33-5-2、如果Parquet文件存储在云存储上,需要确保已经正确设置了storage_options和(如果需要)filesystem参数,以便能够成功访问和读取文件。
33-5-3、use_nullable_dtypes和dtype_backend参数提供了对数据类型处理的精细控制,但通常不需要手动设置,除非在特定情况下需要优化性能或兼容性。
33-5-4、Parquet是一种列式存储的文件格式,非常适合于大数据的存储和高效读写,通过这个函数,用户可以轻松地将存储在Parquet文件中的数据加载到Pandas DataFrame中,以便进行进一步的数据分析或处理。
33-6、用法
33-6-1、数据准备
无33-6-2、代码示例
# 33、pandas.read_parquet函数
# 运行此程序,务必确保你已经安装了pyarrow或fastparquet库
import pandas as pd
# 创建一个Pandas DataFrame
data = {'id': [1, 2, 3, 4],'name': ['Alice', 'Bob', 'Charlie', 'David'],'age': [25, 30, 35, 40],'city': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)
# 指定Parquet文件的保存路径
parquet_path = 'example.parquet'
# 将DataFrame保存为Parquet文件
df.to_parquet(parquet_path, engine='pyarrow', compression='snappy')
print(f"Parquet文件已成功保存到:{parquet_path}")
# 读取Parquet文件
df_read = pd.read_parquet(parquet_path, engine='pyarrow')
# 显示读取的DataFrame以验证数据
print("读取的Parquet文件内容:")
print(df_read)33-6-3、结果输出
# 33、pandas.read_parquet函数
# Parquet文件已成功保存到:example.parquet
# 读取的Parquet文件内容:
# id name age city
# 0 1 Alice 25 New York
# 1 2 Bob 30 Los Angeles
# 2 3 Charlie 35 Chicago
# 3 4 David 40 Houston二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-第三方库Pandas(013)
目录 一、用法精讲 31、pandas.read_feather函数 31-1、语法 31-2、参数 31-3、功能 31-4、返回值 31-5、说明 31-6、用法 31-6-1、数据准备 31-6-2、代码示例 31-6-3、结果输出 32、pandas.DataFrame.to_feather函数 32-1、语法 32-2、参数 32-3、功能 32-4、…...

Linux 高级 Shell 脚本编程:掌握 Shell 脚本精髓,提升工作效率
【Linux】 高级 Shell 脚本编程:掌握 Shell 脚本精髓,提升工作效率 Shell 脚本编程是 Linux 系统管理员和开发人员的必备技能。通过学习高级 Shell 脚本编程,你可以编写更高效、更灵活和更易于维护的脚本。本文将介绍 Shell 脚本编程中的函数…...

【ARMv8/v9 GIC 系列 1.5 -- Enabling the distribution of interrupts】
请阅读【ARM GICv3/v4 实战学习 】 文章目录 Enabling the distribution of interruptsGIC Distributor 中断组分发控制CPU Interface 中断组分发控制Physical LPIs 的启用Summary Enabling the distribution of interrupts 在ARM GICv3和GICv4体系结构中,中断分发…...

《mysql篇》--索引事务
索引 索引的介绍 索引是帮助MySQL高效获取数据的数据结构,是一种特殊的文件,包含着对数据表里所有记录的引用指针,因为索引本身也比较大,所以索引一般是存储在磁盘上的,索引的种类有很多,不过如果没有特殊…...

科研绘图系列:R语言STAMP图(STAMP Plot)
介绍 STAMP图(STAMP plot)并非一个广泛认知的、具有特定名称的图表类型,而是可能指在STAMP(Statistical Analysis of Metagenomic Profiles:“STAMP: statistical analysis of taxonomic and functional profiles”)软件使用过程中生成的各种统计和可视化图表的总称。ST…...

运维团队如何应对动环监控与IT监控分离的挑战
IT与机房动环监控的一体化是当下及未来的必然趋势,这一模式显著节省了运维过程中的时间与成本。一体化平台不仅消除了频繁切换系统的繁琐,更在一个统一界面上实现了多元化的管理运维功能,极大地提升了工作效率。 在机房升级或新建项目中&…...

深入解析大数据核心概念:数据平台、数据中台、数据湖与数据仓库的异同与应用
大数据领域内的诸多概念常常让人困惑,其中数据平台、数据中台、数据湖和数据仓库是最为关键的几个。 1. 数据平台 定义: 数据平台是一个综合性的技术框架,旨在支持整个数据生命周期的管理和使用。它包含数据采集、存储、处理、分析和可视化…...

开发指南040-业务操作日志
平台所有业务操作都存储在核心库,以便统一分析处理。各业务微服务通过feign调用核心日志服务。底层提供了API: <dependency><groupId>org.qlm</groupId><artifactId>qlm-api</artifactId><version>1.0-SNAPSHOT<…...
如何构建数据驱动的企业?爬虫管理平台是关键桥梁吗?
一、数据驱动时代:为何选择爬虫管理平台? 在信息爆炸的今天,数据驱动已成为企业发展的核心战略之一。爬虫管理平台,作为数据采集的第一站,它的重要性不言而喻。这类平台通过自动化手段,从互联网的各个角落…...

多线程Thread
线程Thread简介 任务、线程、金城、多线程 多任务:短时间切换不同得任务 多线程:通过同一条道路,增加道多条道路,提高使用率,解决堵塞问题 普通方法调多线程只有主线一台执行路径是主线程调run()方法,方…...

计算机网络之WPAN 和 WLAN
上一篇文章内容:无线局域网 1.WPAN(无线个人区域网) WPAN 是以个人为中心来使用的无线个人区域网,它实际上就是一个低功率、小范围、低速率和低价格的电缆替代技术。 (1) 蓝牙系统(Bluetooth) &#…...

TikTok海外运营,云手机多种变现方法
从现阶段来看,TikTok 的用户基数不断增长,已然成为全球创业者和品牌的全新竞争舞台。其用户数量近乎 20 亿,年轻用户占据主导,市场渗透率也逐年提高。不管是大型企业、著名品牌,还是个体创业者,都绝不能小觑…...

kubekey在ubuntu24实现kubernetes快速安装
基于Ubunut24.04安装 设置主机名 hostnamectl set-hostname kkmain hostnamectl set-hostname kknode1 hostnamectl set-hostname kknode2关闭swap sudo swapoff -a sudo sed -i s/.*swap.*/#&/ /etc/fstab安装kubekey export KKZONEcn curl -sfL https://get-kk.kubes…...
)
根据关键词query获取google_img(api方式)
文章目录 说明代码第一部分:链接保存为Json第二部分:链接转换为img 说明 根据关键词query获取google_img USERNAME “xxx” PASSWORD “xxx” 官网申请。 代码 首先获取图片链接,保存为json之后下载。 第一部分:链接保存为…...

西安明德理工学院师生莅临泰迪智能科技开展参观见习活动
为进一步深化校企合作,落实高校应用型人才培养。7月8日,西安明德理工学院与广东泰迪智能科技股份有限公司联合开展学生企业见习活动。西安明德理工学院金融产业学院副院长刘敏、金融学专业负责人张莉萍、金融学专业教师曹艳飞、赵浚妤、泰迪智能科技董事…...

通用机器人里程碑!MIT提出策略组合框架PoCo,解决数据源异构难题,实现机器人多任务灵活执行
18 位人形机器人充当「迎宾」人员,整齐划一向嘉宾挥手,这是 2024 世界人工智能大会上的一个震撼场景,让人们直观感受到了今年机器人的飞速发展。 图源:甲子光年 1954 年,世界上第一台可编程机器人「尤尼梅特」在通用汽…...
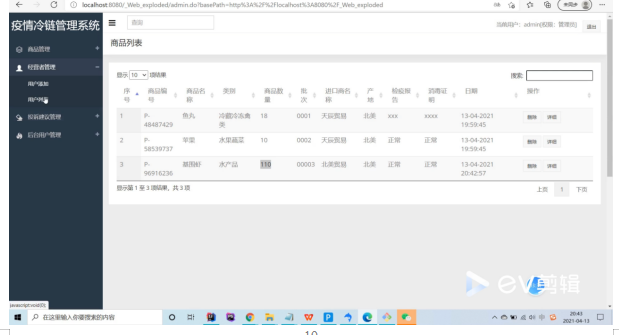
基于Java中的SSM框架实现疫情冷链追溯系统项目【项目源码+论文说明】
基于Java中的SSM框架实现疫情冷链追溯系统演示 摘要 近几年随着城镇化发展和居民消费水平的不断提升,人们对健康生活方式的追求意识逐渐加强,生鲜食品逐渐受到大众青睐,诸如盒马鲜生、7-fresh等品牌生鲜超市,一时间如雨后春笋般迅…...

想在vue中预览doxc,excel,pdf文件? vue-office提供包支持
在浩瀚的Vue生态中,vue-office犹如一颗璀璨的星辰,以其独特的魅力照亮了开发者处理多种文件格式的预览之路。这款精心打造的Vue组件库,不仅拥抱了Vue2的经典,也紧密跟随Vue3的步伐,展现了卓越的技术前瞻性和兼容性。它…...

PostgreSQL16安装Mac(brew)
问题 最近需要从MySQL切换到PostgreSQL。我得在本地准备一个PostgreSQL。 步骤 使用brew安装postgresql16: arch -arm64 brew install postgresql16启动postgresql16: brew services start postgresql16配置postgresql环境变量,打开环境变量文件: …...

【语音识别算法】深度学习语音识别算法与传统语音识别算法的区别、对比及联系
深度学习语音识别算法与传统语音识别算法在理论基础、实现方式、性能表现等方面存在显著区别,同时也有一些联系。下面将从几个方面详细比较这两种方法,并给出应用实例和代码示例。 一、理论基础与实现方式 1.传统语音识别算法: 特征提取&a…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...