代码随想录算法训练营Day64|拓扑排序(卡码网117)、dijkstra朴素版
拓扑排序
117. 软件构建 (kamacoder.com)
拓扑排序简单的说是将一个有向图转为线性的排序。
它将图中的所有结点排序成一个线性序列,使得对于任何的边uv,结点u在序列中都出现在结点v之前,这样的序列满足图中所有的前驱-后继关系。
拓扑排序通常用于任务调度、项目计划、编译依赖分析等场景,其中活动或任务之间存在依赖关系,需要确定一个合理的执行顺序。
拓扑排序的算法步骤如下:
- 选择一个没有前驱的结点(即入度为0的结点),将其加入到拓扑排序的序列中,并从图中删除该节点及其所有出边。
- 重复步骤1,直到所有的结点都被加入拓扑排序序列中或者途中不再存在无前驱的结点。
- 如果所有的结点都被加入序列中,则完成了拓扑排序;若图中还存在结点,则说明图中存在环,无法进行拓扑排序。
由于拓扑排序的结果可能不唯一,当图中存在多个入度为0的结点,可以任意选择一个结点进行删除。
在实际应用中,拓扑排序通常和深度优先搜索或广度优先搜素结合使用。例如,使用广度优先搜索(拓扑排序的广度优先搜索实现通常被称为Kahn算法)进行拓扑排序的算法流程如下:
-
计算所有节点的入度:遍历图中的所有节点,计算每个节点的入度(即有多少边指向该节点)。
-
初始化队列:创建一个空队列,将所有入度为0的节点加入队列。这些节点是没有前置依赖的节点,可以开始执行。
-
处理队列:只要队列不为空,就重复以下步骤:
- 从队列中取出一个节点(称为当前节点),并将其添加到拓扑排序的结果序列中。
- 减少当前节点的所有出边指向的节点的入度(因为这些节点的依赖减少了)。
- 如果某个节点的入度在减少后变为0,则将其加入队列,因为它现在没有前置依赖了。
-
检查是否有未处理的节点:当队列为空时,如果所有的节点都已经添加到拓扑排序的结果序列中,则拓扑排序成功完成。如果还有节点未添加到结果序列中,则说明图中存在环,因此无法进行拓扑排序。
伪代码
拓扑排序(图 G):初始化入度为0的队列 Q初始化拓扑排序的结果序列 L// 计算所有节点的入度对于每个节点 v in G:v.入度 = G 中指向 v 的边的数量如果 v.入度 == 0:Q.enqueue(v)// 处理队列当 Q 不为空时:当前节点 u = Q.dequeue()L.add(u) // 将 u 添加到拓扑排序的结果序列中// 减少所有出边的目标节点的入度对于每个节点 v,其中存在边 u -> v:v.入度 = v.入度 - 1如果 v.入度 == 0:Q.enqueue(v)// 检查是否所有节点都已处理如果 L 中的节点数量不等于 G 中的节点数量:返回 "图 G 包含环,无法进行拓扑排序"否则:返回 L 作为拓扑排序的结果序列
C++代码参考代码随想录代码随想录 (programmercarl.com)
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;int main() {int N, M; // N个文件存在M条依赖关系cin >> N >> M;vector<int> inDegree(N, 0); // 记录每个点的入度unordered_map<int, vector<int>> umap;// 读取M条依赖关系for (int i = 0; i < M; i++) {int s, t;cin >> s >> t;// t依赖于s,因此t的入度加1inDegree[t]++;umap[s].push_back(t);}queue<int> Queue;// 将所有入度为0的节点加入队列for (int i = 0; i < N; i++) {if (inDegree[i] == 0)Queue.push(i);}vector<int> path; // 存储拓扑排序结果while (!Queue.empty()) {int cur = Queue.front();Queue.pop();path.push_back(cur);// 遍历当前节点的所有后继节点for (int next : umap[cur]) {inDegree[next]--;if (inDegree[next] == 0)Queue.push(next);}}// 检查是否所有的节点都被处理了if (path.size() == N) {for (int i = 0; i < N - 1; i++) {cout << path[i] << " ";}cout << path[N - 1];} else {// 如果不是所有的节点都被处理,说明存在环cout << -1 << endl;}return 0;
}
在时间复杂度上,初始化入度数组O(N),读取依赖关系并构建邻接表O(M)(M条依赖关系),将入度为0结点加入队列,O(N),BFS的时间复杂度为O(N+M)(每个结点最多访问一次,每个结点被加入队列后移除,每条边会被访问一次来减少相邻结点的入度)时间复杂度为O(N+M)
空间复杂度 入度数组O(N),邻接表最差情况下O(N^2),队列和路径数组都为O(N),最差情况下空间复杂度为O(N^2),但实际应用中,若图比较稀疏,则空间复杂度为O(M+N)。
dijkstra
47. 参加科学大会(第六期模拟笔试) (kamacoder.com)
Dijkatra算法是一种著名的图搜索算法,它用于在加权图中找到从一源节点到其余所有结点的最短路径。
算法步骤:
- 初始化:需要一个最短路径估计的容器(优先队列,通常是最小堆)存储所有结点及其当前的最短路径估计值,除源节点设置为0外,将所有结点的最短路径估计值设置为无穷大。
- 访问源结点:将源结点加入优先队列。
- 循环处理队列:当优先队列非空时,重复以下步骤:
从优先队列中取出具有最小估计值的节点,称为当前节点。
对于当前节点的每个邻接节点,执行以下操作:
- 计算通过当前节点到达邻接节点的路径长度。
- 如果这个路径长度比已知的最短路径估计值更短,则更新邻接节点的最短路径估计值,并更新它的前驱节点为当前节点。
- 将邻接节点及其新的最短路径估计值加入优先队列。
- 标记完成:当一个结点从优先队列取出时,意味着它的最短路径已经确定,可以将其标记为完成。
- 构建最短路径树:当算法结束时,可以从源结点开始,通过每个结点的前驱结点信息,构造出从源结点到所有其他结点的最短路径树。
需要注意的几个点:
- Dijkstra算法不能处理带有负权边的图,因为在有负权边的图中,可能存在一条路径,其总权重随着经过的边数增加而减少,导致无法正确找到最短路径。
- Dijkstra算法的时间复杂度为O(V^2),V为图中结点的数量,使用优先队列可以优化到O(E+VlogV),E为边的数量、
- Dijkstra可以用于有向图和无向图。
代码随想录 (programmercarl.com)
#include <iostream>
#include <vector>
#include <climits>
using namespace std;int main() {int N, M; // N个文件存在M条依赖关系cin >> N >> M;vector<vector<int>> grid(N+1, vector<int>(N+1, INT_MAX)); // 创建一个N+1xN+1的二维数组,用于存储节点之间的权重,初始化为INT_MAXint v1, v2, val;for (int i = 0; i < M; i++) { // 读取M条依赖关系cin >> v1 >> v2 >> val; // 读取两个节点v1和v2以及它们之间的权重valgrid[v1][v2] = val; // 更新权重矩阵,表示v1到v2有边,权重为val}int start = 1; // 定义起始节点为1int end = N; // 定义目标节点为Nvector<int> minDist(N+1, INT_MAX); // 创建一个长度为N+1的数组,用于存储从起始节点到其他节点的最短路径估计值,初始化为INT_MAXvector<int> visited(N+1, 0); // 创建一个长度为N+1的数组,用于标记节点是否被访问过,0表示未访问,1表示已访问minDist[start] = 0; // 起始节点到自身的最短路径为0for (int i = 0; i <= N; i++) { // 循环,找到未访问的最短路径节点int minVal = INT_MAX; // 初始化最小值为INT_MAXint cur = 1; // 初始化当前节点为1for (int v = 1; v <= N; v++) { // 遍历所有节点,找到未访问且最短路径估计值最小的节点if (!visited[v] && minDist[v] < minVal) { // 如果节点v未访问且最短路径估计值小于minValminVal = minDist[v]; // 更新最小值cur = v; // 更新当前节点为v}}visited[cur] = 1; // 标记当前节点为已访问for (int v = 1; v <= N; v++) { // 遍历所有节点,更新从当前节点出发到其他节点的最短路径估计值if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {// 如果节点v未访问,且当前节点到节点v有边,且通过当前节点到达v的路径更短minDist[v] = minDist[cur] + grid[cur][v]; // 更新节点v的最短路径估计值}}}if (minDist[end] == INT_MAX) // 如果目标节点的最短路径估计值仍然是INT_MAX,表示没有路径到达目标节点cout << -1 << endl; // 输出-1elsecout << minDist[end] << endl; // 否则输出从起始节点到目标节点的最短路径长度return 0;
}
算法的时间复杂度为O(N^2),空间复杂度这里也是O(N^2)(没有用上最小堆等优先队列)
相关文章:
、dijkstra朴素版)
代码随想录算法训练营Day64|拓扑排序(卡码网117)、dijkstra朴素版
拓扑排序 117. 软件构建 (kamacoder.com) 拓扑排序简单的说是将一个有向图转为线性的排序。 它将图中的所有结点排序成一个线性序列,使得对于任何的边uv,结点u在序列中都出现在结点v之前,这样的序列满足图中所有的前驱-后继关系。 拓扑排…...

neo4j 图数据库:Cypher 查询语言、医学知识图谱
neo4j 图数据库:Cypher 查询语言、医学知识图谱 Cypher 查询语言创建数据查询数据查询并返回所有节点查询并返回所有带有特定标签的节点查询特定属性的节点及其所有关系和关系的另一端节点查询从名为“小明”的节点到名为“小红”的节点的路径 更新数据更新一个节点…...

数据结构基础--------【二叉树基础】
二叉树基础 二叉树是一种常见的数据结构,由节点组成,每个节点最多有两个子节点,左子节点和右子节点。二叉树可以用来表示许多实际问题,如计算机程序中的表达式、组织结构等。以下是一些二叉树的概念: 二叉树的深度&a…...

数据开源 | Magic Data大模型高质量十万轮对话数据集
能够自然的与人类进行聊天交谈,是现今的大语言模型 (LLM) 区别于传统语言模型的重要能力之一,近日OpenAI推出的GPT-4o给我们展示了这样的可能性。 对话于人类来说是与生俱来的,但构建具备对话能力的大模型是一项不小的挑战,收集高…...

webpack之ts打包
tsconfig.json配置 // 是否对js文件进行编译,默认false"allowJs": true,// 是否检查js代码是否符合语法规范,默认false(引入的外部文件有可能语法有问题)"checkJs": true, allowJs和checkJs基本是同时出现,因为有了allowJs 这个检查…...

MATLAB数据统计描述和分析
描述性统计就是搜集、整理、加工和分析统计数据, 使之系统化、条理化,以显示出数据资料的趋势、特征和数量关系。它是统计推断的基础,实用性较强,在数学建模的数据描述部分经常使用。 目录 1.频数表和直方图 2 .统计量 3.统计…...
设计分享—国外后台界面设计赏析
国外后台界面设计将用户体验放在首位,通过直观易懂的布局和高效的交互设计,提升用户操作效率和满意度。 设计不仅追求美观大方,还注重功能的实用性和数据的有效展示,通过图表和图形化手段使数据更加直观易懂。 采用响应式布局&a…...
)
最小生成树(算法篇)
算法之最小生成树 最小生成树 概念: 最小生成树是一颗连接图G所有顶点的边构成的一颗权最小的树,最小生成树一般是在无向图中寻找。最小生成树共有N-1条边(N为顶点数)。 算法: Prim算法 概念: Prim(普里姆)算法是生成最小生…...
教师管理小程序的设计
管理员账户功能包括:系统首页,个人中心,教师管理,个人认证管理,课程信息管理,课堂记录管理,课堂统计管理,留言板管理 微信端账号功能包括:系统首页,课程信息…...

Selenium 等待
环境: Python 3.8 selenium3.141.0 urllib31.26.19 Chromium 109.0.5405.0 (32 位) # 1 固定等待(time) # 固定待是利用python语言自带的time库中的sleep()方法,固定等待几秒。 # 这种方式会导致这个脚本运…...

安装easy-handeye
一、aruco_ros配置 mkdir -p ~/ros_ws/src cd ~/ros_ws/src git clone -b melodic-devel https://github.com/pal-robotics/aruco_ros.git cd .. catkin_make 二、visp配置(需要联外网下载东西,不然会一直出问题) sudo apt-get install ros-melodic-…...
)
【面试题】MySQL 索引(第二篇)
1.索引 索引是数据库中的一个核心概念,它对于提高数据库查询效率至关重要。以下是索引的详细概念解析: 一、索引的定义 基本定义:索引是一个排序的列表,其中存储着索引的值和包含这些值的数据所在行的物理地址(或逻…...

4. 小迪安全v2023笔记 javaEE应用
4. 小迪安全v2023笔记 javaEE应用 大体上跟随小迪安全的课程,本意是记录自己的学习历程,不能说是完全原创吧,大家可以关注一下小迪安全。 若有冒犯,麻烦私信移除。 默认有java基础。 文章目录 4. 小迪安全v2023笔记 javaEE应…...

anaconda修改安装的默认环境
📚博客主页:knighthood2001 ✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下) 🎃知识星球:【认知up吧|成长|副业】介绍 ❤️如遇文章付费,可先看…...

MySQL 9.0 正式发行Innovation创新版已支持向量
从 MySQL 8.1 开始,官方启用了新的版本模型:MySQL 创新版 (Innovation) 和长期支持版 (LTS)。 根据介绍,两者的质量都已达到可用于生产环境级别。区别在于: 如果希望尝试最新的功能和改进,并喜欢与最新技术保持同步&am…...

基于Java+SpringMvc+Vue技术的智慧校园系统设计与实现
博主介绍:硕士研究生,专注于信息化技术领域开发与管理,会使用java、标准c/c等开发语言,以及毕业项目实战✌ 从事基于java BS架构、CS架构、c/c 编程工作近16年,拥有近12年的管理工作经验,拥有较丰富的技术架…...

【蔬菜网元宇宙】—— 探索农业的未来之旅
在数字化时代的浪潮中,技术和创新不断塑造着我们的生活方式。现在,这种变革已经延伸到了农业领域。蔬菜网,一个专注于农产品供应链的领先平台,自豪地宣布我们正式迈入元宇宙的世界——一个全新的虚拟空间,旨在彻底改变…...

淘宝商品历史价格查询(免费)
当前资料来源于网络,禁止用于商用,仅限于学习。 淘宝联盟里面就可以看到历史价格 并且没有加密 淘宝商品历史价格查询可以通过以下步骤进行: 先下载后,登录app注册账户 打开淘宝网站或淘宝手机App。在搜索框中输入你想要查询的商…...

14-47 剑和诗人21 - 2024年如何打造AI创业公司
2024 年,随着人工智能继续快速发展并融入几乎所有行业,创建一家人工智能初创公司将带来巨大的机遇。然而,在吸引资金、招聘人才、开发专有技术以及将产品推向市场方面,人工智能初创公司也面临着相当大的挑战。 让我来…...

WPF界面设计-更改按钮样式 自定义字体图标
一、下载图标文件 iconfont-阿里巴巴矢量图标库 二、xaml界面代码编辑 文件结构  对应的图标代码 Fonts/#iconfont 对应文件位置 <Window.Resources><ControlTemplate TargetType"Button" x:Key"CloseButtonTemplate"…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
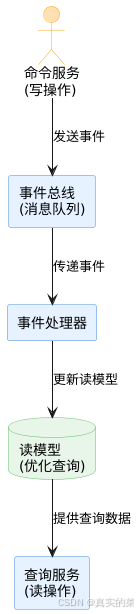
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...