深度学习部署(十六): CUDA RunTime API _vector-add 使用cuda核函数实现向量加法
1. 知识点
- nthreads的取值,不能大于block能取值的最大值。一般可以直接给512、256,性能就是比较不错的
- (input_size + block_size - 1) / block_size;是向上取整
- 对于一维数组时,采用只定义layout的x维度,若处理的是二维,则可以考虑定义x、y维度,例如处理的是图像
- 关于把数据视作一维时,索引的计算
- 以下是通用的计算公式
Pseudo code: position = 0 for i in range(6):position *= dims[i]position += indexs[i]- 例如当只使用x维度时,实际上dims = [1, 1, gd, 1, 1, bd],indexs = [0, 0, bi, 0, 0, ti]
- 因为0和1的存在,上面的循环则可以简化为:idx = threadIdx.x + blockIdx.x * blockDim.x
- 即:idx = ti + bi * bd
2. main.cpp文件
#include <cuda_runtime.h>
#include <stdio.h>#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){if(code != cudaSuccess){ const char* err_name = cudaGetErrorName(code); const char* err_message = cudaGetErrorString(code); printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message); return false;}return true;
}void vector_add(const float* a, const float* b, float* c, int ndata);int main(){const int size = 3;float vector_a[size] = {2, 3, 2};float vector_b[size] = {5, 3, 3};float vector_c[size] = {0};float* vector_a_device = nullptr;float* vector_b_device = nullptr;float* vector_c_device = nullptr;checkRuntime(cudaMalloc(&vector_a_device, size * sizeof(float)));checkRuntime(cudaMalloc(&vector_b_device, size * sizeof(float)));checkRuntime(cudaMalloc(&vector_c_device, size * sizeof(float)));checkRuntime(cudaMemcpy(vector_a_device, vector_a, size * sizeof(float), cudaMemcpyHostToDevice));checkRuntime(cudaMemcpy(vector_b_device, vector_b, size * sizeof(float), cudaMemcpyHostToDevice));vector_add(vector_a_device, vector_b_device, vector_c_device, size);checkRuntime(cudaMemcpy(vector_c, vector_c_device, size * sizeof(float), cudaMemcpyDeviceToHost));for(int i = 0; i < size; ++i){printf("vector_c[%d] = %f\n", i, vector_c[i]);}checkRuntime(cudaFree(vector_a_device));checkRuntime(cudaFree(vector_b_device));checkRuntime(cudaFree(vector_c_device));return 0;
}
先定义三个数组: a, b, c 再用cudaMalloc()在GPU上开辟三个内存,在GPU上让a + b 并且让结果存储进c上,再把c的内存从GPU上放到Host上输出
3. 案例.cu文件
#include <stdio.h>
#include <cuda_runtime.h>__global__ void vector_add_kernel(const float* a, const float* b, float* c, int ndata){int idx = threadIdx.x + blockIdx.x * blockDim.x;if(idx >= ndata) return;/* dims indexsgridDim.z blockIdx.zgridDim.y blockIdx.ygridDim.x blockIdx.xblockDim.z threadIdx.zblockDim.y threadIdx.yblockDim.x threadIdx.xPseudo code:position = 0for i in 6:position *= dims[i]position += indexs[i]*/c[idx] = a[idx] + b[idx];
}void vector_add(const float* a, const float* b, float* c, int ndata){const int nthreads = 512;int block_size = ndata < nthreads ? ndata : nthreads; // 如果ndata < nthreads 那block_size = ndata就够了int grid_size = (ndata + block_size - 1) / block_size; // 其含义是我需要多少个blocks可以处理完所有的任务printf("block_size = %d, grid_size = %d\n", block_size, grid_size);vector_add_kernel<<<grid_size, block_size, 0, nullptr>>>(a, b, c, ndata);// 在核函数执行结束后,通过cudaPeekAtLastError获取得到的代码,来知道是否出现错误// cudaPeekAtLastError和cudaGetLastError都可以获取得到错误代码// cudaGetLastError是获取错误代码并清除掉,也就是再一次执行cudaGetLastError获取的会是success// 而cudaPeekAtLastError是获取当前错误,但是再一次执行cudaPeekAtLastError或者cudaGetLastErro拿到的还是那个错cudaError_t code = cudaPeekAtLastError();if(code != cudaSuccess){ const char* err_name = cudaGetErrorName(code); const char* err_message = cudaGetErrorString(code); printf("kernel error %s:%d test_print_kernel failed. \n code = %s, message = %s\n", __FILE__, __LINE__, err_name, err_message); }
}
两个注意的点
-
像这个案例他就三个数相加,其实启动三个线程就足够了,但是一般block给的是512, 256,所以要设定一下,如果数组的长度小于256/512, 就直接用数组的长度的线程数就好。这里就是3个线程
-
如果线程索引大于了数组的长度就直接返回了,不然就访问了不知道在哪里的内存了
相关文章:
: CUDA RunTime API _vector-add 使用cuda核函数实现向量加法)
深度学习部署(十六): CUDA RunTime API _vector-add 使用cuda核函数实现向量加法
1. 知识点 nthreads的取值,不能大于block能取值的最大值。一般可以直接给512、256,性能就是比较不错的 (input_size block_size - 1) / block_size;是向上取整 对于一维数组时,采用只定义layout的x维度,若处理的是二维ÿ…...

堆结构的两个应用
堆排序 堆结构很大的一个用处,就是用于堆排序了,堆排序的时间复杂度是O(n∗log2n)O(n*log_2n)O(n∗log2n)量级的,在众多排序算法中所处的地位也是高手级别的了。 但很多人在使用堆排序的时候,首先认为我必须得有一个堆数据结构…...

Java中的 static
1 static 静态变量 1.1 静态变量的使用 static变量也称作静态变量,也叫做类变量 静态变量被所有的对象所共享,在内存中只有一个副本 当且仅当在类初次加载时会被初始化 静态变量属于类 通过类名就可以直接调用静态变量 也可以通过对象名.静态变量…...

基于Vision Transformer的图像去雾算法研究与实现(附源码)
基于Vision Transformer的图像去雾算法研究与实现 0. 服务器性能简单监控 \LOG_USE_CPU_MEMORY\文件夹下的use_memory.py文件可以实时输出CPU使用率以及内存使用率,配合nvidia-smi监控GPU使用率 可以了解服务器性能是否足够;运行时在哪一步使用率突然…...

服务器相关常用的命令
cshell语法 https://www.doc88.com/p-4985161471426.html domainname命令 1)查看当前系统域名 domainname2)设置并查看当前系统域名 domainname example.com3)显示主机ip地址 domainname -Iwhich命令 which 系统命令在 PATH 变量指定的…...
今天是国际数学日,既是爱因斯坦的生日又是霍金的忌日
目录 一、库函数计算 π 二、近似值计算 π 三、无穷级数计算 π 四、割圆术计算 π 五、蒙特卡罗法计算 π 六、计算800位精确值 从2020年开始,每年的3月14日又被定为国际数学日,是2019年11月26日联合国教科文组织第四十届大会上正式宣布…...

Qt Quick - StackLayout 堆布局
StackLayout 堆布局一、概述二、attached 属性三、例子1. 按钮切换 StackLayout 页面一、概述 StackLayout 其实就是说,在同一个时刻里面,只有一个页面是展示出来的,类似QStackWidget 的功能,主要就是切换界面的功能。这个类型我…...
C/C++网络编程笔记Socket
https://www.bilibili.com/video/BV11Z4y157RY/?vd_sourced0030c72c95e04a14c5614c1c0e6159b上面链接是B站的博主教程,源代码来自上面视频,侵删,这里只是做笔记,以供复习和分享。上一篇博客我记录了配置环境并且跑通了࿰…...

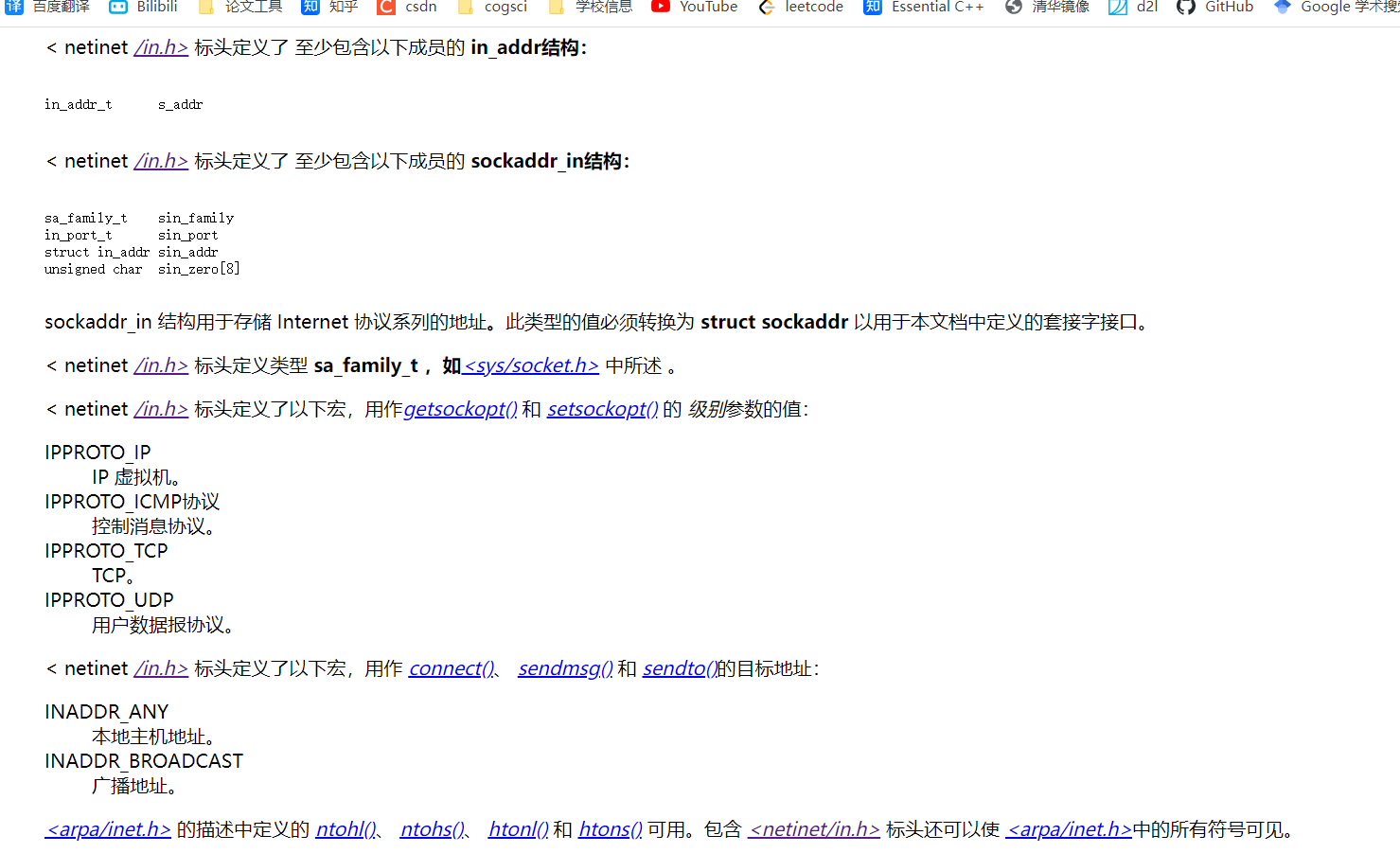
RK3568平台开发系列讲解(网络篇)什么是Socket套接字
🚀返回专栏总目录 文章目录 一、什么是socket ?二、socket 理解为电话机三、socket 的发展历史四、套接字地址格式4.1、通用套接字地址格式4.2、IPv4 套接字格式地址4.3、IPv6 套接字地址格式4.4、几种套接字地址格式比较沉淀、分享、成长,让自己和他人都能有所收获!😄 …...
网络安全竞赛试题——渗透测试解析(详细))
2022年全国职业院校技能大赛(中职组)网络安全竞赛试题——渗透测试解析(详细)
渗透测试 任务环境说明: 服务器场景:Server9服务器场景操作系统:未知(关闭连接)系统用户名:administrator密码:123456通过本地PC中渗透测试平台Kali对靶机场景进行系统服务及版本扫描渗透测试,以xml格式向指定文件输出信息(使用工具Nmap),将以xml格式向指定文件输出…...

尚融宝03-mybatis-plus基本CRUD和常用注解
目录 一、通用Mapper 1、Create 2、Retrieve 3、Update 4、Delete 二、通用Service 1、创建Service接口 2、创建Service实现类 3、创建测试类 4、测试记录数 5、测试批量插入 三、自定义Mapper 1、接口方法定义 2、创建xml文件 3、测试条件查询 四、自定义Serv…...

vue多行显示文字展开
这几天项目里面有一个需求,多行需要进行展开文字,类似实现这种效果 难点就在于页面布局 一开始就跟无头苍蝇似的,到处百度 ,后面发现网上的都不适合自己,最终想到了解决方案 下面是思路: 需求是超过3行&a…...
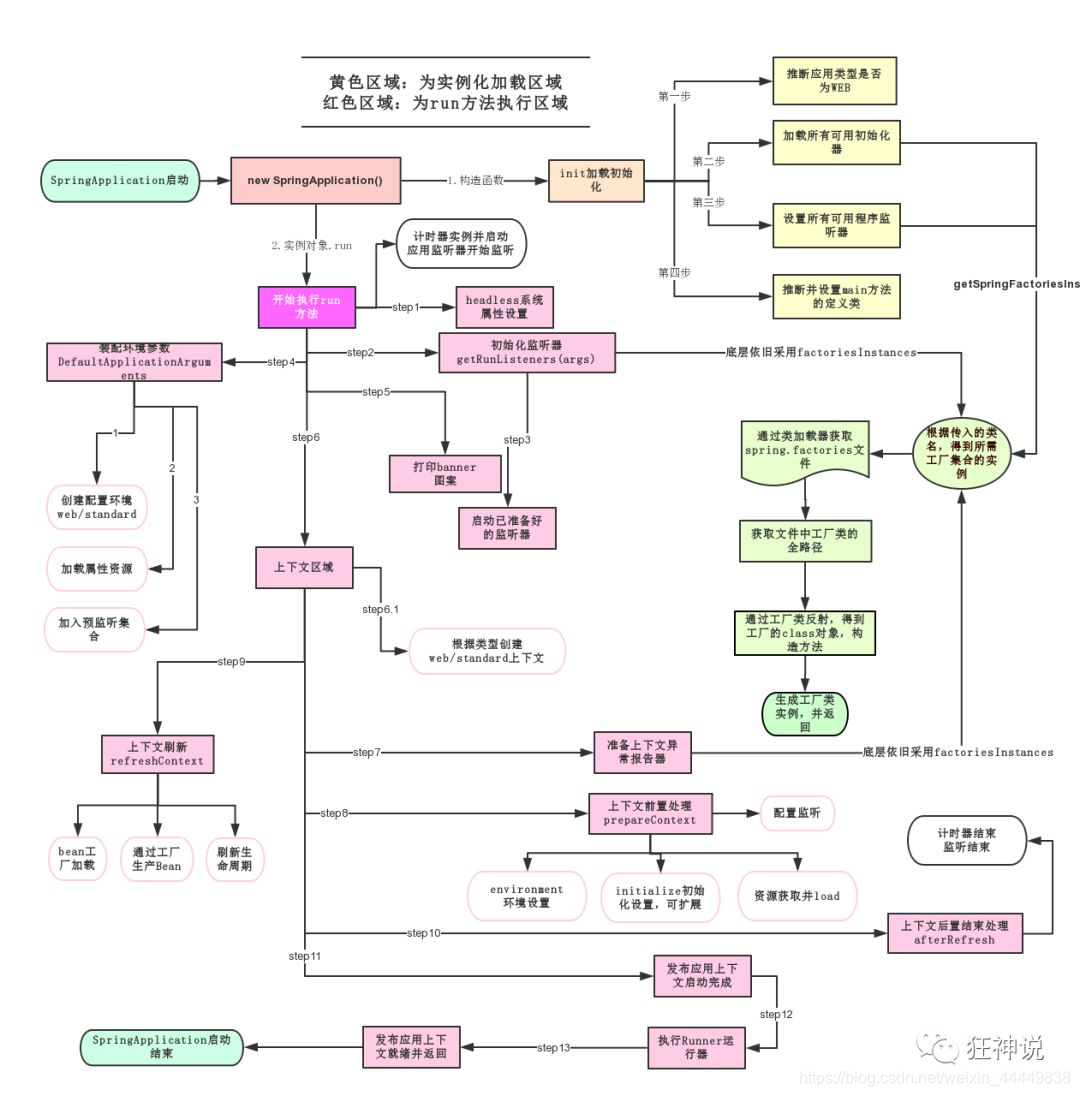
SpringBoot:SpringBoot 的底层运行原理解析
声明原文出处:狂神说 文章目录1. pom.xml1 . 父依赖2 . 启动器 spring-boot-starter2. 主启动类的注解1. 默认的主启动类2. SpringBootApplication3. ComponentScan4. SpringBootConfiguration5. SpringBootApplication 注解6. spring.factories7. 结论8. 简单图解3…...

哪些场景会产生OOM?怎么解决?
文章目录 堆内存溢出方法区(运行时常量池)和元空间溢出直接内存溢出栈内存溢出什么时候会抛出OutOfMemery异常呢?初看好像挺简单的,其实深究起来考察的是对整个JVM的了解,而这个问题从网上可以翻到一些乱七八糟的答案,其实在总结下来基本上4个场景可以概括下来。 堆内存溢出…...

金三银四、金九银十 面试宝典 Spring、MyBatis、SpringMVC面试题 超级无敌全的面试题汇总(超万字的面试题,让你的SSM框架无可挑剔)
Spring、MyBatis、SpringMVC 框架 - 面试宝典 又到了 金三银四、金九银十 的时候了,是时候收藏一波面试题了,面试题可以不学,但不能没有!🥁🥁🥁 一个合格的 计算机打工人 ,收藏夹里…...
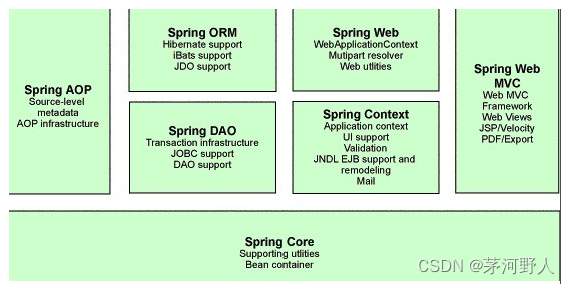
JAVA开发(Spring框架详解)
javaweb项目几乎已经离不开spring框架了,spring 是一个典型的分层架构框架,它包含一系列的功能并被分为多个功能模块,springboot对spring框架又做了一层封装,以至于很多人对原来的spring框架越来越不了解。 要谈Spring的历史&…...

自学大数据第八天~HDFS命令(二)
嗨喽,好久不见,最近抽空复习了一下hadoop,书读百遍,其意自现这句话还真是; 继续学习HDFS常用命令 改变文件 拥有者~chown hdfs dfs -chown -R hadoop /user/hadoop使用 -R 将使改变在目录结构下递归进行。命令的使用者必须是超级用户。 改变文件所属组-chgrp hdfs dfs -chgr…...
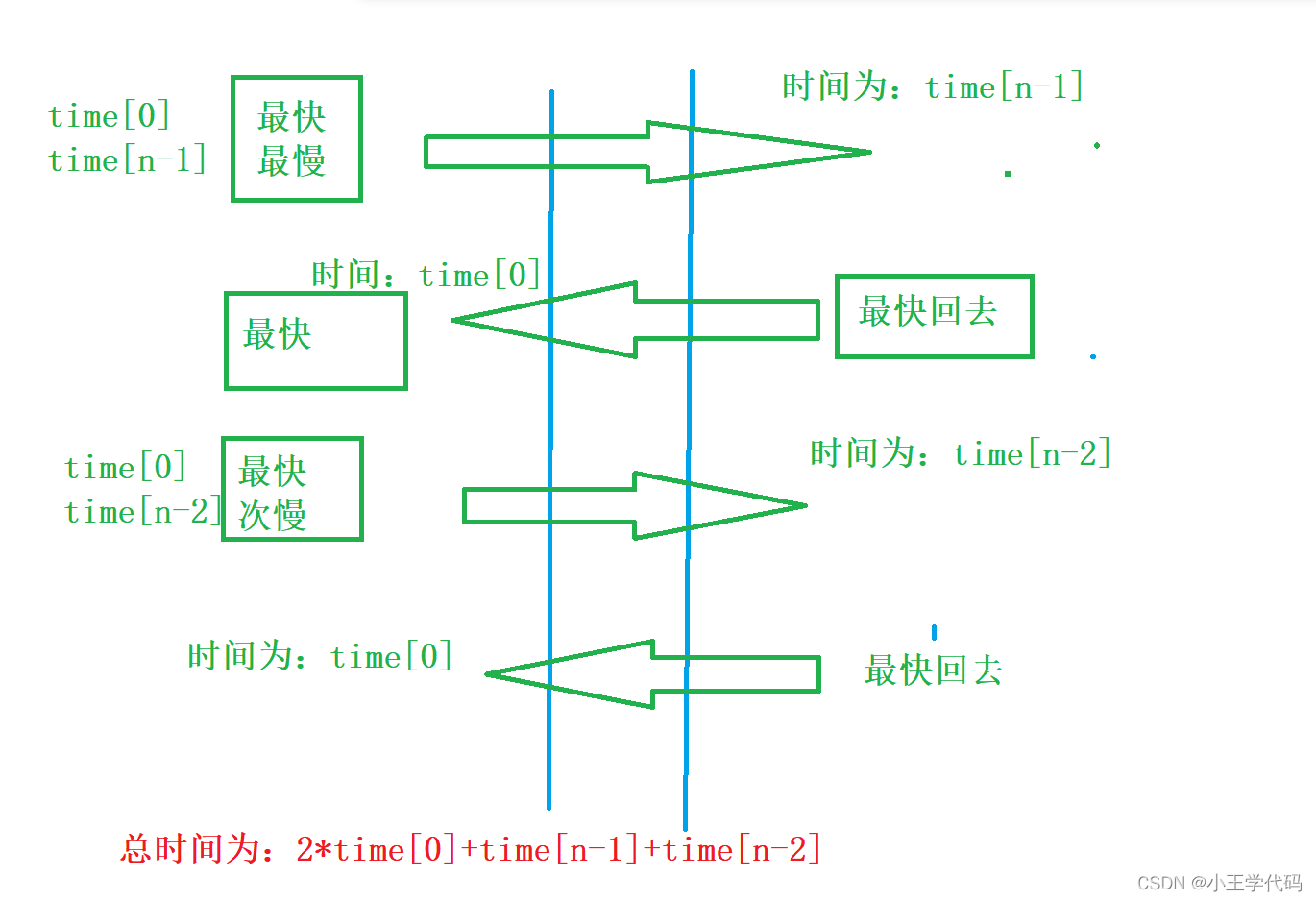
贪心算法(几种常规样例)
贪心算法(几种常规样例) 贪心算法,指在对问题进行求解的时候,总是做出当前看来是最好的选择。也就是说不从整体上最优上考虑,算法得到的结果是某种意义上的局部最优解 文章目录贪心算法(几种常规样例&…...

【数据结构】基础知识总结
系列综述: 💞目的:本系列是个人整理为了数据结构复习用的,由于牛客刷题发现数据结构方面和王道数据结构的题目非常像,甚至很多都是王道中的,所以将基础知识进行了整理,后续会将牛客刷题的错题一…...
宣布推出 .NET 社区工具包 8.1!
我们很高兴地宣布 .NET Community Toolkit 8.1 版正式发布!这个新版本包括呼声很高的新功能、bug 修复和对 MVVM 工具包源代码生成器的大量性能改进,使开发人员在使用它们时的用户体验比以往更好! 就像在我们之前的版本中一样,我…...

数据库初识与安装
一、数据库初识1. 什么是数据库?数据库(Database)是长期存储在计算机内、有组织、可共享的大量数据的集合,它能高效地对数据进行增、删、改、查操作。2. 常见数据库分类关系型数据库(RDBMS):以表…...

2FAuth企业级应用场景:团队协作、权限管理和安全审计全攻略
2FAuth企业级应用场景:团队协作、权限管理和安全审计全攻略 【免费下载链接】2FAuth A Web app to manage your Two-Factor Authentication (2FA) accounts and generate their security codes 项目地址: https://gitcode.com/gh_mirrors/2f/2FAuth 在数字化…...

Deepagents多语言支持:构建全球化的AI代理系统
Deepagents多语言支持:构建全球化的AI代理系统 【免费下载链接】deepagents Deepagents is an agent harness built on langchain and langgraph. Deep agents are equipped with a planning tool, a filesystem backend, and the ability to spawn subagents - mak…...

红黑树介绍
红黑树(Red-Black Tree)是一种自平衡的二叉查找树,它是由 Rudolf Bayer 在 1972 年发明的。它在每个节点上增加一个存储位表示节点的颜色,可以是红色或黑色,通过对任何一条从根到叶子的路径上各个节点的颜色进行约束&a…...

Chatbot Copilot 在AI辅助开发中的实战应用与性能优化
Chatbot Copilot 在AI辅助开发中的实战应用与性能优化 在当前的软件开发浪潮中,AI辅助工具正从“锦上添花”逐渐变为“雪中送炭”。作为一名开发者,我深切体会到,一个得力的AI助手不仅能加速编码,更能启发思路,甚至重…...
+情感韵律自然表达展示)
Qwen3-TTS语音合成惊艳效果:中文方言(粤语/川话)+情感韵律自然表达展示
Qwen3-TTS语音合成惊艳效果:中文方言(粤语/川话)情感韵律自然表达展示 1. 引言:当AI开口说方言,声音有了“灵魂” 想象一下,你正在开发一款面向全国用户的智能助手。当一位广东用户用粤语问“今日天气点样…...

震惊!最新会员卡印刷企业排名新鲜出炉!
在商业竞争日益激烈的当下,会员卡作为商家维系客户、促进消费的重要工具,其印刷质量和设计水平愈发重要。近期,一份最新的会员卡印刷企业排名新鲜出炉,引发了广泛关注。会员卡印刷行业现状行业报告显示,近年来…...

大模型微调新选择:Llama Factory可视化工具使用体验分享
大模型微调新选择:Llama Factory可视化工具使用体验分享 1. 工具概览 Llama Factory是一款专为大模型微调设计的可视化工具,它让原本复杂的模型训练过程变得简单直观。这个工具最大的特点就是"零代码"——用户不需要编写任何代码就能完成从数…...

WSL2新手必看:VcXsrv配置xfce4图形界面的5个常见错误及解决方法
WSL2图形化实战:避开VcXsrv与xfce4配置的五大深坑 第一次在WSL2中看到xfce4桌面环境成功加载时的兴奋,很快被接踵而至的报错信息冲淡——这可能是许多开发者的真实写照。作为连接Windows与Linux生态的桥梁,WSL2的图形界面配置过程中暗藏着不…...

风格化上色探索:调整DeOldify参数生成复古与赛博朋克色调
风格化上色探索:调整DeOldify参数生成复古与赛博朋克色调 你印象中的老照片上色,是不是就是让黑白照片变回它原本的、写实的彩色模样?今天,我想带你玩点不一样的。我们不满足于“还原”,而是想“创造”——用DeOldify…...