shark云原生-日志体系-filebeat高级配置(适用于生产)-更新中

文章目录
- 1. filebeat.inputs 静态日志收集器
- 2. filebeat.autodiscover 自动发现
- 2.1. autodiscover 和 inputs
- 2.2. 如何配置生效
- 2.3. Providers 提供者
- 2.4. Providers kubernetes
- 2.5. 配置 templates
- 2.5.1. kubernetes 自动发现事件中的变量字段
- 2.5.2 配置 templates
- 2.6. 基于提示(hints)的自动发现
- 2.6.1 支持的 **hints**的完整列表:
- 2.6.2. kubernetes 启用 hints
- 2.6.3. Appenders
- 3. processors 处理器
- 3.1. 定义处理器
- 3.2. 常用处理器
- 3.2.1. 去除日志中的某些行
- 3.2.2. 向输出的数据中添加某些自定义字段
- 3.2.3. 从事件中删除某些字段
- 3.3. Condition 条件
- 4. 配置索引生命周期管理
- 4.1. 配置选项
- 5. 配置Elasticsearch索引模板加载
- 6. parsers 解析器
- 7. 勘探者 prospector
- 7.1. scanner 扫描器
- 7.1.1. symlinks 软链接
- 7.1..2. fingerprint 指纹
- 8. file_identity 文件标识
- 8.1. fingerprint
此文档中主要是针对 configmap 对象中关于 filebeat 配置文件内容针对生产环境如何配置的说明。
1. filebeat.inputs 静态日志收集器
在 kubernetes 环境中,有可能你需要同时收集集群中每个节点(服务器)的系统日志,比如 /var/log/ 目录下的日志,这些日志文件级别都是静态的,文件名称固定的,因此这里有必要介绍手动指定的方式: filebeat.inputs
这里主要介绍的是 Filebeat 配置文件中 filebeat.inputs 的配置。
filebeat.inputs 配置项的作用就是告诉 Filebeat 程序可以从哪儿获取需要读取的数据。支持多种输入模块,比如普通文件中、redis 中、kafka 中等,路径的配置可以使用通配符进行模糊匹配。
配置示例:
filebeat.inputs:
- type: logpaths:- /var/log/system.log- /var/log/wifi.log# 支持通配符- /log/spms-*[a-z].log
# 可以写多个
- type: filestreampaths:- "/var/log/apache2/*"
loglog 输入模块适用于普通文本日志文件、syslog 格式的日志。filestreamfilestream 输入模块是 Filebeat 7.13.0 版本中引入的新输入模块,用于从文件中读取结构化数据。filestream 输入模块支持读取 JSON 格式、NDJSON 格式等结构化数据文件,它可以更高效地处理结构化数据文件,并提供更好的性能。
不同的输入模块支持不同的配置项,在 filestream 下可以配置如下选项(这些配置项同时支持 log 输入模块)。
- type: filestream# id 是集群中的唯一标识id: sys-logspaths:# 日志收集的路径- /var/log/*.logparsers:# 解析器- syslog: ~prospector:# 勘探者scanner:symlinks: trueprocessors:# 处理器名称- add_host_metadata:parsers 解析器,主要对输入的数据进行解析,不同的数据有不同的格式,比如docker容器的日志格式一般是 json, 就需要使用 container 解析器进行解析处理。
prospector 勘探者,主要是控制 Filebeat 对日志文件进行读取的时候如何处理,比如扫描文件的时候是否支持软连接的文件路径,是否对日志文件进行计算密文,以便更好的识别是否是同一个文件。
parsers 和 prospector 后面内容有详细介绍。也可以参考官方文档
processors 处理器,主要会把每次日志事件内容进行处理,比如添加某些字段,删除某些字段,删除这个事件等。处理器可以给每个 inputs 的输入模块配置不同的处理器,后面章节有专门的详解介绍。
还有几个值得注意的配置项:
harvester_buffer_size 每个采集器在获取文件时使用的缓冲区的大小(以字节为单位)。默认值为16384。
max_bytes 单个日志消息可以具有的最大字节数。max_bytes之后的所有字节都将被丢弃而不发送。此设置对于多行日志消息特别有用,因为多行日志信息可能会变大。默认值为10MB(10485760)。
close_inactive指定在文件不再更新的情况下多久后关闭文件句柄。我们建议您将close_inactive设置为一个大于日志文件最不频繁更新的值。例如,如果日志文件每隔几秒钟更新一次,则可以安全地将 close_inactive 设置为1m。如果存在更新率非常不同的日志文件,则可以使用具有不同值的多个配置。
2. filebeat.autodiscover 自动发现
当您在容器上运行应用程序时,它们会成为监控系统的移动目标。自动发现允许您跟踪它们,并在发生更改时调整设置。
2.1. autodiscover 和 inputs
在Filebeat中,自动发现 filebeat.autodiscover和 file.inputs 存在一些区别。
-
filebeat.inputs指定带通配符的路径:当你使用filebeat.inputs指定带通配符的路径时,Filebeat会根据通配符匹配的规则来收集符合条件的日志文件。这种方式适用于静态的日志路径,例如指定某个固定目录下的所有日志文件。但是它并不会动态地适应新创建的容器日志。 -
filebeat.autodiscover:Filebeat 的自动发现功能允许它动态地发现和收集新创建的容器日志。当容器启动时,Filebeat 可以检测到新的容器日志源,并自动开始收集这些日志。这使得在容器动态创建和销毁时,Filebeat可以及时地调整以收集新的日志。
所以,带通配符的路径的 filebeat.inputs 并不能收集到新创建的容器日志,这时就需要使用自动发现功能来实现动态收集新创建的容器日志。
2.2. 如何配置生效
您可以在filebeat.yml配置文件的 `filebeat.autodiscover`部分定义自动发现设置。并且必须配置一个提供者程序列表。就像下面这样:data:filebeat.yml: |-filebeat.autodiscover.providers:- type: kubernetes...- type: docker...
可以配置多个,就像上面的一样。也可以配置一个就像下面的一样:
data:filebeat.yml: |-filebeat.autodiscover.providers:- type: kubernetes...
要想启用 provider 或者说让他们真正有效工作起来,还需要进一步配置。
有两种方案:
- 给每个 provider 配置
templates,并指定被收集日志的路径。
data:filebeat.yml: |-filebeat.autodiscover.providers:- type: kubernetestemplates:- config:- type: containerpaths:- "/var/lib/docker/containers/${data.kubernetes.container.id}/*.log"
- 容器方式运行的 Filebeat,不建议使用 /var/log/container 和 /var/log/pods 目录,这两个都是软连接,而实际收集日志的时候需要找到实际的日志文件,于是就需要挂载到容器里面多个目录。
- 如果是非容器部署,那就可以使用这两个目录。
- 给每个 provider 配置基于 hints 的自动发现,hints 是 Elasticsearch 的提示系统 。并配置一个默认配置
hints.default_config,或者使用templates,并指定被收集日志的路径。hints.default_config和templates可以结合起来使用,具体细节后面章节有详细介绍。
data:filebeat.yml: |-filebeat.autodiscover.providers:- type: kuberneteshints.enabled: truehints.default_config:type: filestreamid: kubernetes-container-logs-${data.kubernetes.pod.name}-${data.container.id}paths:- /var/lib/docker/containers/${data.container.id}/*.log
templates的路径paths中需要使用data.kubernetes.container.id;hins.default_config中使用如下两个都可以:
data.container.iddata.kubernetes.container.id
版本差异
经过实验,Filebea 8.11.x 及以下的版本,在 docker 为容器运行时的环境中,支持如下简单的配置,就可以收集到在目录 /var/lib/docker/container/ 下的所有容器的日志。
arm64 架构不受影响
data:filebeat.yml: |-filebeat.autodiscover.providers:- type: kuberneteshints.enabled: true
2.3. Providers 提供者
自动发现 Providers 的工作方式是监视系统上的事件,并将这些事件转换为具有通用格式的内部自动发现事件。
配置 Providers 时,您可以选择使用自动发现事件中的字段来设置条件,当满足条件时,会启动特定的配置。
启动时,Filebeat 将扫描现有容器并为它们启动适当的配置。然后它将监视新的开始/停止事件。这样可以确保您不必担心状态,而只需定义所需的配置。
经常使用的有如下两种 Providers:
-
docker Docker 自动发现 provider 监视Docker容器的启动和停止。
-
kubernetes Kubernetes自动发现提供程序监视Kubernete node、pod 和 service 的启动、更新和停止。
因为此专栏主要是云原生,所以只介绍 kubernetes 的 providers,docker 的请参考官方文档
2.4. Providers kubernetes
kubernetes自动发现提供程序具有以下配置设置:
node
(可选)指定要将filebeat定位到的节点,以防无法准确检测到,例如在主机网络模式下运行filebeat时。就是指定一个这个 Filebeat 运行在哪个kubernetes 工作节点上。
data:filebeat.yml: |-filebeat.autodiscover.providers:- type: kubernetesnode: ${NODE_NAME} # 一般不用明确设置一般设置值是一个 Pod 的环境变量 NODE_NAME,而这个变量的值是从 Pod 运行是 spec.nodeName 字段的值获取的。
env:- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeNamenamespace
(可选)选择要从中收集元数据的命名空间。如果未设置,处理器将从所有命名空间收集元数据。默认情况下未设置。命名空间配置仅适用于命名空间范围内的kubernetes资源。这个只能同时配置一个命名空间,建议使用条件判断替代。
cleanup_timeout
当容器在一段时间内没有产生任何活动时(即没有日志产生或文件变化),Filebeat会停止监视该容器的配置。这可以帮助节省资源并避免不必要的日志收集。你可以根据实际需求,通过配置来调整这个时间,以满足你对日志收集的要求。默认 60s。
kube_config
(可选)使用给定的配置文件作为Kubernetes客户端的配置。它默认为KUBECONFIG环境变量(如果存在)。
使用此选项,有几个条件:
- 删除了关于 Filebeat daemonset对象使用的 rbac 相关资源对象。删除 Filebeat 关于 daemonset 对象yaml文件中
serviceAccountName: filebeat的配置。 - kube_config 指定的配置文件路径是真的 Filebeat Pod 内的路径,因此需要把配置文件映射到 Filebeat Pod 中。
这需要再 daemonset 对象的 yaml 文件中添加如下配置:
volumeMounts:- name: kubeconfigmountPath: /root/.kube/configreadOnly: truevolumes:- name: kubeconfighostPath:path: /root/.kube/config
此示例我使用了默认的 kubernetes admin 的认证文件,实际生产中你应该自己创建一个有合适权限的认证文件。
- 最后在 configmap 的yaml 文件中设置。
data:filebeat.yml: |-filebeat.autodiscover.providers:- type: kuberneteskube_config: /root/.kube/config
resource
(可选)选择要进行发现的资源。目前支持的Kubernetes资源有 pod、service 和node。如果未配置,则资源默认为pod。
scope
(可选)指定需要在何种级别执行自动发现。scope 可以将 node 或 cluster 作为值。node 作用域允许发现指定节点(服务器)中的资源。cluster 作用域允许集群范围内的发现。在 node 范围内只能发现pod和节点资源。
2.5. 配置 templates
通过定义配置模板(templates),自动发现子系统可以在服务开始运行时对其进行监控。
2.5.1. kubernetes 自动发现事件中的变量字段
配置模板可以包含自动发现事件中的变量。这些变量可以在 data 命名空间下访问,例如访问Pod IP: ${data.kubernetes.pod.ip}。
下面是 templates 中可用的字段。提供者程序 kubernetes 会在每个日志事件中添加 kubernetes.* 字段:
如下是一个日志事件的输入示例
{"@timestamp": "2024-07-05T03:38:37.974Z","@metadata": {"beat": "filebeat","type": "_doc","version": "8.14.1"},"host": {"name": "k8s-node1"},"message": "{\"log\":\"\\u003cjemalloc\\u003e: Unsupported system page size\\n\",\"stream\":\"stderr\",\"time\":\"2024-07-05T03:38:34.86180604Z\"}","input": {"type": "filestream"},"kubernetes": {"pod": {"name": "fluent-bit-ftwlr",...},"namespace": "kubesphere-logging-system","namespace_uid": "bd47727c-53d7-4132-a4e1-c29886116ceb","namespace_labels": {"kubernetes_io/metadata_name": "kubesphere-logging-system",...},"daemonset": {"name": "fluent-bit"},"labels": {"app_kubernetes_io/name": "fluent-bit",...},"container": {"name": "fluent-bit"},"node": {"labels": {"beta_kubernetes_io/arch": "arm64",...},"hostname": "k8s-node1","name": "k8s-node1","uid": "e05fe0cf-2042-4d02-bedc-789ad567aea6"}},"container": {"id": "a57df33b6a61dac0593bc177f0a31b14683ec485e3ee9981f302c8a3c30c80cb","runtime": "docker","image": {"name": "dockerhub.kubekey.local/kubesphere/fluent-bit:v1.9.4"}},...
}
如果 include_annotations 配置被添加到提供程序配置,那么配置中存在的注解列表将被添加到事件中。
如果 include_labels 配置被添加到提供程序配置,那么配置中存在的标签列表将被添加到事件中。
如果将 exclude_labels 配置添加到提供程序配置中,则该配置中存在的标签列表将从事件中排除。
如果在提供程序配置中将 labels.dot-config设置为 true,那么 Labels 中的 . 将替换为 _。默认情况下为 true。
如果在提供程序配置中将 annotations.dedot-config 设置为 true,那么 Annotations . 中将替换为_。默认情况下为 true。
2.5.2 配置 templates
Filebeat 的 templates 可以配置 input 和 module ,还可以使用条件 condition。
示例配置:
如下配置启动了一个用于在 kube-system 命名空间中运行的所有pod容器的 docker 输入模块: container。
filebeat.autodiscover:providers:- type: kubernetestemplates:- condition:equals:kubernetes.namespace: kube-systemconfig:- type: containerpaths:- /var/lib/docker/containers/${data.kubernetes.container.id}/${data.kubernetes.container.id}-json.logexclude_lines: ["^\\s+[\\-`('.|_]"] # drop asciiart lines
正则表达式 ^\s+[\-`('.|_]

如果你希望使用 modules 来进一步处理容器中的日志,可以使用 docker 输入模块来替换默认的 输入模块。如下是配置示例:
filebeat.autodiscover:providers:- type: kubernetestemplates:- condition:equals:kubernetes.container.image: "redis"config:- module: redislog:input:type: containerpaths:- /var/lib/docker/containers/${data.kubernetes.container.id}/*.log
上面配置的意思是,当容器的镜像名是 redis 时,使用日志处理模块 redis 对日志进一步的处理。
常用的条件运算符
在条件配置中,除了 equals 运算符,还有一些其他条件运算符可供使用。以下是一些常见的条件运算符列表:
equals:等于not_equals:不等于contains:包含not_contains:不包含regexp:正则表达式匹配startswith:以某字符串开头endswith:以某字符串结尾in:在给定的列表中not_in:不在给定的列表中range:范围匹配
这些条件运算符可以帮助你更精细地定义 autodiscover 的规则,以便根据不同的条件来匹配和处理日志文件。
例如下面的配置实现,指对命名空间开头是 sahrk-standard 或 shark-bluespace 的Pod日志进行收集。
指定某些命名空间
data:filebeat.yml: |-filebeat.autodiscover:providers:- type: kubernetestemplates:- condition:regexp:kubernetes.namespace: "^shark-standard|^shark-bluespace"config:- type: containerpaths:- /var/lib/docker/containers/${data.kubernetes.container.id}/${data.kubernetes.container.id}-json.log2.6. 基于提示(hints)的自动发现
Filebeat支持基于 hints 程序提示的自动发现。
-
默认配置
首先,只要有效配置了 hints(怎么算有效,参考章节: 2.2. 如何配置生效 )
此时所有 Pod 容器的日志会被自动收集。如果不希望某些 Pod 容器日志不希望被收集,可以在annotations中添加如下配置表示不收集Filebeat Pod 的日志。apiVersion: apps/v1 kind: DaemonSet metadata:name: filebeatnamespace: defaultlabels:k8s-app: filebeatannotations:co.elastic.logs/enabled: "false" ... -
进阶配置实现更多功能
提示系统在Kubernetes Pod annotations或 Docker labels 中查找前缀为co.elastic.log的 hints。
一旦容器启动,Filebeat 就会检查它是否包含任何 hints,并启动相应的配置。 从而hints会告诉Filebeat如何获取给定容器的日志。
docker-compose 示例:
version: "3.9"
services:nginx:labels:co.elastic.logs/module: nginxco.elastic.logs/fileset.stdout: accessco.elastic.logs/fileset.stderr: errorrestart: alwaysimage: nginx:1.20.2-alpine-upstreamkubernetes 示例:
apiVersion: apps/v1
kind: <kind name>
metadata:annotations:co.elastic.logs/json.message_key: "log"co.elastic.logs/json.add_error_key: "true"
默认情况下,将使用 filestream 的输入模块从容器中检索日志。您可以通过配置不同的 hints (即 annotations)来修改此行为。
2.6.1 支持的 hints的完整列表:
co.elastic.logs/enabled
Filebeat默认情况下从所有容器获取日志,您可以将此提示设置为 "false" 以忽略容器的输出。Filebeat不会从中读取或发送日志。
co.elastic.logs/multiline.*
多行设置。有关所有支持选项的完整列表,请参阅多行消息。
就是 Java 程序抛出异常的日志,一条日志信息别保存为连续的多行。
co.elastic.logs/json.*
JSON设置。如果是 type: filestream(默认)输入模块,请参阅ndjson以获取所有支持选项的完整列表。如果是 type: container 或 type: log 输入模块,请参阅json以获取所有支持选项的完整列表。
例如,以下带有json选项的提示:
co.elastic.logs/json.message_key: "log"
co.elastic.logs/json.add_error_key: "true"
这转化为如下 yaml 配置
- filestream
parsers:- ndjson:message_key: "log"add_error_key: "true"
- log
json.message_key: "log"
json.add_error_key: "true"
co.elastic.logs/include_lines
希望Filebeat包含的行,包含的行需要和一个正则表达式列表相匹配。
co.elastic.logs/exclude_lines
与要Filebeat排除的行匹配的正则表达式列表。
co.elastic.logs/module
指定用于解析容器中日志的 module,而不是使用原始docker inuput。
例如,处理nginx日志,有 nginx module,处理mysql日志有专门的 mysql module。
有关支持的模块列表,请参阅模块。
co.elastic.logs/fileset
配置模块后,将容器日志映射到模块处理器。您可以这样配置哪些容器的日志使用该模块进行智能地处理:
co.elastic.logs/fileset: access
或者在容器中为每个流配置一个文件集(stdout和stderr):
co.elastic.logs/fileset.stdout: access
co.elastic.logs/fileset.stderr: error
co.elastic.logs/processors
定义要添加到Filebeat input/module 配置的处理器。
如果处理器配置使用列表数据结构,则必须枚举对象字段。例如,下面的 rename 处理器配置 hints:
processors:- rename:fields:- from: "a.g"to: "e.d"fail_on_error: true
将看起来像:
co.elastic.logs/processors.rename.fields.0.from: "a.g"
co.elastic.logs/processors.rename.fields.1.to: "e.d"
co.elastic.logs/processors.rename.fail_on_error: 'true'
如果处理器配置使用映射数据结构,则不需要枚举。例如,等效于下面的add_fields配置
processors:- add_fields:target: projectfields:name: myproject
转换为 annotations 后:
co.elastic.logs/processors.1.add_fields.target: "project"
co.elastic.logs/processors.1.add_fields.fields.name: "myproject"
为了提供处理器定义的排序,可以提供数字。如果没有,提示生成器将执行任意排序:
# 有的
co.elastic.logs/processors.1.dissect.tokenizer: "%{key1} %{key2}"# 没有的
co.elastic.logs/processors.dissect.tokenizer: "%{key2} %{key1}"
在上述示例中,将首先执行标记为1的处理器定义。
2.6.2. kubernetes 启用 hints
基础配置
Kubernetes自动发现提供程序要启用 hints,只需设置hints.enabled:
filebeat.autodiscover:providers:- type: kuberneteshints.enabled: true
Filebeat 的 8.12.x 及以上版本还应该同时配置 hints.default_config。
arm64 架构的版本不存在这样的差异
当看到新容器时将启动的默认配置,如下所示:
filebeat.autodiscover:providers:- type: kuberneteshints.enabled: "true"hints.default_config:type: containerpaths:- /var/lib/docker/containers/${data.container.id}/${data.container.id}.log # CRI path
之后,就可以用适合自己需求、有用的信息,对 Kubernetes Pods 进行注解,比如可以设置适应多行(Java的报错异常日志):
annotations:co.elastic.logs/multiline.pattern: '^\['co.elastic.logs/multiline.negate: "true"co.elastic.logs/multiline.match: after
还有启用Filebeat 输入或 module:
annotations:co.elastic.logs/module: "nginx"
限定名称空间
如果你希望只对某些刚兴趣的名称空间中的Pod日志进行收集。
data:filebeat.yml: |-filebeat.autodiscover:providers:- type: kuberneteshints.enabled: "true"templates:- condition:regexp:kubernetes.namespace: "^spms-standard|^spms-bluespace"config:- type: containerpaths:- /var/lib/docker/containers/${data.kubernetes.container.id}/${data.kubernetes.container.id}-json.log并且在这种情况下,你仍然可以通过在命名空间不符合正则表达式 ^spms-standard|^spms-bluespace的Pod 中添加注解 co.elastic.logs/enabled: "true" 实现日志的收集。如下示例所示:
apiVersion: apps/v1
kind: DaemonSet
metadata:name: filebeatnamespace: defaultlabels:k8s-app: filebeatannotations:co.elastic.logs/enabled: "true"多容器Pod
当一个pod有多个容器时,除非在提示中输入容器名称,否则设置是共享的。例如,这些提示为pod中的所有容器配置多行设置,但为名为 sidecar 的容器设置特定的 exclude_lines hint。
annotations:co.elastic.logs/multiline.pattern: '^\['co.elastic.logs/multiline.negate: "true"co.elastic.logs/multiline.match: afterco.elastic.logs.sidecar/exclude_lines: '^DBG'
多组 hints
当容器需要在其上定义多个 input 时,可以为 annotations 集提供数字前缀。如果有没有数字前缀的提示,那么它们会被分组到一个配置中。
annotations:co.elastic.logs/exclude_lines: '^DBG'co.elastic.logs/1.include_lines: '^DBG'co.elastic.logs/1.processors.dissect.tokenizer: "%{key2} %{key1}"
上述配置将生成两个 input 配置。第一个 input 只处理调试日志,并将其传递给一个 dissect.tokenizer。第二个 input 处理除调试日志以外的所有内容。
可以在命名空间的注解上配置 hints,当 Pod 级别的注解缺失时,可以在 Namespace 的注解上配置 hints 作为默认值。生成的提示是 Pod 注解和 Namespace 注解的组合,其中 Pod 的优先级更高。要启用 Namespace 默认值,请按照以下方式为 Namespace 对象配置 add_resource_metadata。
filebeat.autodiscover:providers:- type: kuberneteshints.enabled: trueadd_resource_metadata:namespace:include_annotations: ["nsannotation1"]
2.6.3. Appenders
配置附加器可以在模板或构建器生成的配置之上应用配置。只要提供的条件匹配,就会应用配置。如果没有提供任何条件,它总是应用的。所应用的配置类型特定于每个附加程序。
filebeat.autodiscover:providers:- type: kubernetestemplates:...appenders:- type: configcondition.equals:kubernetes.namespace: "prometheus"config:# 向事件中添加字段fields:type: monitoring
3. processors 处理器
3.1. 定义处理器
在将数据发送到配置的输出之前,可以使用处理器对数据进行过滤和增强。要定义处理器,请指定处理器名称、可选条件和一组参数:
processors:- <processor_name>:when:<condition><parameters>- <processor_name>:when:<condition><parameters>...
-
<processor_name>指定执行某种操作的处理器,例如选择要删除的字段或向事件添加元数据。
-
<condition>指定一个可选条件。如果条件存在,则仅当条件满足时此处理器才执行操作。如果未设置任何条件,则此处理器始终执行操作。
-
<parameters>是要传递给处理器的参数列表,比如指定要添加哪些字段,添加到哪个字段内。
处理更复杂的情况
更复杂的条件处理可以通过使用if-then-else处理器配置来完成。这允许基于单个条件执行多个处理器。
processors:- if:<condition>then: - <processor_name>:<parameters>- <processor_name>:<parameters>...else: - <processor_name>:<parameters>- <processor_name>:<parameters>...
-
then
必须包含单个处理器或一个或多个处理器的列表,以便在条件计算为true时执行。 -
else
是可选的。当条件求值为false时,它可以包含要执行的单个处理器或处理器列表。
处理器工作方式
每个处理器都接收一个事件,对该事件应用已定义的操作,然后返回该事件。如果定义处理器列表,则将按照在Filebeat配置文件中定义的顺序执行它们。
处理器在哪里配置有效
在配置的顶层。处理器应用于Filebeat收集的所有数据。
filebeat.autodiscover:
...
filebeat.inputs:
...
output.elasticsearch:...
# 处理器,让数据更丰富
processors:- add_host_metadata:when.not.contains.tags: forwarded...
在特定输入模块下。处理器应用于为该输入收集的数据。
- type: <input_type>processors:- <processor_name>:when:<condition><parameters>
...
处理器优先级 特别重要******
这里说的优先级,可以理解为那个处理器最先使用,也就是说数据先进入哪个处理器被处理,优先级主要是对配置在某个输入模块配置的处理器和配置在顶层的处理器来说的。
日志数据 > 输入模块处理器列表 > 顶层配置的(全局)处理器列表
也就是数据是先由每个输入模块中的处理器列表处理后,最后再由配置在顶层(全局)的处理器列表处理。
基于上面优先级规则,再处理器中使用 when 时指定的字段就要慎重。避免使用没有处理器添加的字段。
例如,在全局顶层处理器中可以使用输入模块中处理器添加到事件的字段。而在输入模块中的处理器无法使用全局处理器添加的字段。
正确示例:
filebeat.autodiscover:providers:- type: kubernetes...
processors:- drop_event:when.not.regexp:kubernetes.namespace: '^spms.*'
在上面的正确示例中的全局处理器 drop_event 中使用了字段 kubernetes.namespace ,这个字段是由自动发现中输入模块 kubernetes 生成。
当然在 output.xxx 输出模块中也可以使用已经存在的资源,因为这里是最后的出口,所有处理器处理后的数据都会到这里。
例如如下示例中使用的字段 kubernetes.namespace:
output.elasticsearch:hosts: ['${ELASTICSEARCH_HOST:elastic.efk.svc}:${ELASTICSEARCH_PORT:9200}']indices:- index: "%{[kubernetes.namespace]}-%{[agent.version]}-%{+yyyy.MM.dd}"when.regexp:kubernetes.namespace: '^spms.*'
下面是我在学习中遇到的经典错误示例。
场景是这样的,在 kubernetes 集群中运行了很多 Pod,但是我希望之针对某几个名称空间的 Pod, 使用处理器 add_kubernetes_metadata。而其他名称空间的日志事件都删除,不传输给 Elasticsearch。
错误配置:
configmap 的 yaml ,实验的名称空间是 shark-test
apiVersion: v1
kind: ConfigMap
metadata:name: filebeat-confignamespace: kube-systemlabels:k8s-app: filebeat
data:filebeat.yml: |-filebeat.inputs:- type: filestream...processors:- drop_event:when.not.regexp:kubernetes.namespace: '^shark.*'- add_kubernetes_metadata:运行的结果是没有任何日志事件输出,都被删除了。主要原因有两个:
- 虽然处理器被配置在顶层,但是输入模块中并没有处理器
add_kubernetes_metadata, 因此全局处理器列表中的第一个处理器drop_event使用的字段并不存在。 - 当使用
not这样的操作符的时候,条件匹配和给的的字段不存在都被视为最终条件满足,为true。因此,处理器drop_event被执行了,所有的日志事件被删除。
正确配置为调整全局处理器的两个处理器的位置:
processors:- add_kubernetes_metadata:- drop_event:when.not.regexp:kubernetes.namespace: '^shark.*'或者把处理器 add_kubernetes_metadata 配置在输入模块中,处理器 drop_event 配置在全局中。
apiVersion: v1
kind: ConfigMap
metadata:name: filebeat-confignamespace: kube-systemlabels:k8s-app: filebeat
data:filebeat.yml: |-filebeat.inputs:- type: filestreamprocessors:- add_kubernetes_metadata:...processors:- drop_event:when.not.regexp:kubernetes.namespace: '^shark.*'
或者都放在输入模块中,但是注意顺序:
- type: filestreamprocessors:- add_kubernetes_metadata:- drop_event:when.not:or:- contains:kubernetes.namespace: 'spms-cloud'- contains:kubernetes.namespace: 'spms-standard'上面的配置表示名称空间不含有 spms-cloud 或者不含有 spms-standard 的事件删除。
又或者使用正则表达式:
- type: filestreamprocessors:- add_kubernetes_metadata:- drop_event:when.not:regexp:kubernetes.namespace: '^spms-cloud|^spms-standard'3.2. 常用处理器
- drop_event
- drop_fields
- add_docker_metadata
- add_host_metadata
- add_kubernetes_metadata
官方完整的处理器列表:点我查看目前支持的所以处理器列表
3.2.1. 去除日志中的某些行
配置位置在 filebeat.yml 文件中。
考虑这样的场景:
在一个服务器上,使用 docker 运行了应用的 Pod 的容器 ,也运行了 docker-compose 管理的 容器,并且 Pod 有的是应用程序(需要收集的日志),有的Pod是监控系统、日志收集系统等(不要求收集日志)。
从这么多的容器中要过滤出只要求收集的日志,就可以使用处理器 drop_event,再配合 when 条件判断过滤。
删除所有以 DBG: 开头的行
processors:- drop_event:when.regexp:message: "^DBG:"
3.2.2. 向输出的数据中添加某些自定义字段
add_fields 处理器将额外的字段添加到事件中。字段可以是标量值、数组、字典,也可以是它们的任何嵌套组合。add_fields 处理器将覆盖目标字段(如果它已经存在)。
默认情况下,您指定的字段将分组在事件中的 fields 子字典下。要将字段分组到不同的子词典下,请使用 target 设置。若要将字段存储为顶级字段,请设置目 target: ''。
processors:- add_fields:target: projectfields:name: myprojectid: '574734885120952459'
- 将自定义字段添加到此目标字段内,这个字段会被自定创建。
- 将要添加的字段和值
输出效果如下图所示:

3.2.3. 从事件中删除某些字段
processors:- drop_fields:when:conditionfields: ["field1", "field2", ...]ignore_missing: false
condition 是一个条件,当条件满足时,才会删除定义的字段。这个是可选的,不设置条件,则会都删除。
以上配置,将删除字段: field1 和 field2
ignore_missing 的值为 false 表示,字段名不存在则会返回错误。为 true 不会返回错误。
⚠️ 注意: 事件中的 "@timestamp 和 type 字段是无法删除的。
下面的配置示例是删除顶级字段 input 和 顶级字段 ecs 中的 version 字段。
- drop_fields:fields: ['input', "ecs.version"]
删除之前⬇️
{..."input": {"type": "log"},..."ecs": {"version": "1.5.0"},...
}
删除之后⬇️
{..."ecs": {},...
}
3.3. Condition 条件
每个条件都接收日志事件中的一个字段进行比较。通过在字段之间使用AND,可以在相同条件下指定多个字段(例如,field1 AND field2)。
对于每个字段,可以指定一个简单的字段名或字段的嵌套映射,例如host.name。
不同的处理器导出不同的字段,每个处理器导出的字段可以参考官方文档
支持的条件:
- equals
- contains
- regexp
- range
- network
- has_fields
- or
- and
- not
equals 等于
使用等于条件,可以比较字段是否具有某个值。该条件只接受一个整数或字符串值。
例如,以下条件检查HTTP事务的响应代码是否为200:
equals:http.response.code: 200
contains 包含
包含条件,检查给定字段实际值的是否包含配置的值。字段可以是字符串或字符串数组。该条件只接受字符串值。
例如,以下条件检查名称空间中是否含有 shark-test 对应值的一部分:
contains:kubernetes.namespace: "shark-test"
regexp 正则表达式
正则表达式条件根据正则表达式检查字段。该条件只接受字符串。
例如,以下条件检查进程名称是否以foo开头:
regexp:system.process.name: "^foo.*"
has_fields
has_fields 条件检查事件中是否存在所有给定字段。该条件接受表示字段名称的字符串值列表。
例如,以下条件检查事件中是否存在 http.response.code字段。
has_fields: ['http.response.code']
or
接收一个条件列表,满足列表中任意一个条件即可。
or:- <condition1>- <condition2>- <condition3>...
配置示例:
or:- equals:http.response.code: 304- equals:http.response.code: 404
and
接收一个条件列表,必须同时满足列表中的所有条件。
and:- <condition1>- <condition2>- <condition3>...
配置示例:
and:- equals:http.response.code: 200- equals:status: OK
or 和 and 还可以嵌套使用:
or:- <condition1>- and:- <condition2>- <condition3>
not
not运算符接收到要求反的条件。
not:<condition>
配置示例:
not:equals:status: OK
特别注意:
在使用 not 条件运算符时候,除了条达匹配视为最终条件达成,给定用于判断的字段不存在也视为最终添加达成。
例如下面的配置效果是一样的:
when.not.contains:host.name: 'k8s-node1'when.not.contains:# 错误字段host.namespa: 'k8s-node1'
其他添加的 not 也是一样的:
when.not.regexp:host.name: '^k8s.*'when.not.regexp:# 错误字段host.namespace: '^k8s.*'
4. 配置索引生命周期管理
使用Elasticsearch中的索引生命周期管理(ILM)功能来管理您的Filebeat,它们在数据流老化时作为数据流的备份索引。
Filebeat 会自动加载默认策略,并将其应用于Filebeat创建的任何数据流。
您可以在Kibana的索引生命周期策略UI中查看和编辑策略。有关使用UI的更多信息,请参阅索引生命周期策略。
4.1. 配置选项
可以在 filebeat.yml 配置文件的 setup.ilm 部分指定以下设置:
setup.ilm.enabled
对Filebeat创建的任何新索引启用或禁用索引生命周期管理。有效值为 true 和false。
setup.ilm.policy_name
用于生命周期策略的名称。默认值为 filebeat。
setup.ilm.policy_file
JSON文件的路径,该文件包含生命周期策略配置。使用此设置可以加载您自己的生命周期策略。
有关生命周期策略的更多信息,请参阅Elasticsearch参考中的设置索引生命周期管理策略。
setup.ilm.check_exists
如果设置为 false,则禁用对现有生命周期策略的检查。默认值为 true。如果连接到安全群集的Filebeat用户没有 read_ilm 权限,则需要禁用此检查。
如果将此选项设置为 false,则即使 setup.ilm.overwrite 设置为 true,也不会安装生命周期策略。
setup.ilm.overwrite
当设置为 true 时,生命周期策略将在启动时被覆盖。默认值为 false。
5. 配置Elasticsearch索引模板加载
filebeat.yml 配置文件的 setup.template 部分指定用于在Elasticsearch中设置映射的索引模板。如果启用了模板加载(默认),Filebeat会在成功连接到Elasticsearch后自动加载索引模板。
加载索引模板需要连接到Elasticsearch。如果配置的输出不是Elasticsearch(或Elasticsearch service),则必须手动加载模板。
您可以调整以下设置以加载自己的模板或覆盖现有模板。
setup.template.enabled
设置为false可禁用模板加载。如果设置为 false,则必须手动加载模板。
setup.template.name
模版的名字,默认是 filebeat。 Filebeat 版本总会追加到给定的名字后,因此最终的名字是 filebeat-%{[agent.version]}。
setup.template.pattern
要应用于默认索引设置的模板模式。默认模式为 filebeat。Filebeat版本总是包含在模式中,因此最终的模式是 Filebeat-%{[agent.version]}。
示例:
setup.template.name: "filebeat"
setup.template.pattern: "filebeat"
setup.template.pattern 允许您定义一个模式,该模式将用于匹配将应用模板的索引名称。例如,如果您将 setup.template.pattern 设置为 "myindex-*",那么 Filebeat 将尝试将模板应用于所有以 "myindex-" 开头的索引。
这个选项的作用在于,它允许您根据特定的索引名称模式来自动应用索引模板,从而确保新创建的索引能够按照您的要求进行配置。
总而言之,setup.template.pattern 允许您定义一个模式,以便 Filebeat 可以自动将索引模板应用于匹配该模式的索引。
setup.template.overwrite
一个布尔值,用于指定是否覆盖现有模板。默认值为 false。如果同时启动多个Filebeat实例,请不要启用此选项。发送过多的模板更新请求可能会使Elasticsearch过载。
setup.template.settings
通过 setup.template.settings,您可以指定要应用于索引模板的设置,例如分片和副本的数量、索引的分片设置、索引的刷新间隔等。这些设置可以确保新创建的索引与您的要求一致,并且具有适当的性能和配置。
以下是一个示例设置 setup.template.settings 的配置:
setup.template.settings:index.number_of_shards: 3index.number_of_replicas: 2
一个完整的示例
setup.template.enabled: true
setup.template.overwrite: false
setup.template.name: "spms"
setup.template.pattern: "spms*"
setup.template.settings:index.number_of_shards: 3index.number_of_replicas: 26. parsers 解析器
此选项需要一个日志行必须经过的解析器列表。
可以使用的解析器:
- multiline
- ndjson
- container
- syslog
multiline
控制Filebeat如何处理跨越多行的日志消息的选项。
ndjson
这些选项使Filebeat能够解码构造为JSON消息的日志。Filebeat逐行处理日志,因此只有当每条消息有一个JSON对象时,JSON解码才有效。
解码发生在行过滤之前。如果设置message_key选项,可以将JSON解码与过滤相结合。这在应用程序日志被封装在JSON对象中的情况下很有帮助,比如在使用Docker时。
配置示例:
- ndjson:target: ""add_error_key: truemessage_key: log
- target 新JSON对象的名称,该对象应包含已解析的键值对。如果将其留空,则新 key 将进入顶级之下。
- add_error_key 如果启用此设置,Filebeat会在json解组错误或配置中定义了
message_key但无法使用时添加"error.message"和"error.type:json"key。 - message_key 一个可选的配置设置,用于指定要应用行筛选和多行设置的JSON键。如果指定了该键,则该键必须位于JSON对象的顶级,并且与该键关联的值必须是字符串,否则将不会发生筛选或多行聚合。
container
使用 container 解析器从容器日志文件中提取信息。它将行解析为通用消息行,并提取时间戳。
7. 勘探者 prospector
探矿者正在运行一个文件系统观察器,该观察器查找路径选项中指定的文件。目前只支持简单的文件系统扫描。
7.1. scanner 扫描器
扫描仪监视配置的路径。它会定期扫描文件系统,并将文件系统事件返回到“浏览”。
7.1.1. symlinks 软链接
符号链接选项允许Filebeat除了获取常规文件外,还可以获取符号链接。在获取符号链接时,Filebeat会打开并读取原始文件,即使它报告了符号链接的路径。
当您为获取配置符号链接时,请确保排除原始路径。如果将单个输入配置为同时获取符号链接和原始文件,Filebeat将检测到问题并只处理它找到的第一个文件。但是,如果配置了两个不同的输入(一个读取符号链接,另一个读取原始路径),则会获取两个路径,导致Filebeat发送重复数据,并且输入会覆盖彼此的状态。
如果指向日志文件的符号链接在文件名中有其他元数据,并且您希望在Logstash中处理元数据,则符号链接选项可能很有用。例如,Kubernetes日志文件就是这样。
由于此选项可能会导致数据丢失,因此默认情况下会禁用此选项。
配置示例:
prospector:scanner:symlinks: true7.1…2. fingerprint 指纹
fingerprint 可以让 Filebeat 根据文件的内容字节范围来识别文件。
在比较文件时,不依赖设备ID和inode值(Filebeat默认行为),而是比较文件的给定字节范围的哈希值。
如果由于文件系统提供的文件标识符不稳定而导致数据丢失或数据重复,请启用此选项。
以下是可能发生这种情况的一些场景:
-
一些文件系统(即Docker中)缓存和重用inode
例如,如果你:
a. Create a file (touch x)
b. Check the file’s inode (ls -i x)
c. Delete the file (rm x)
d. 立即创建新文件(touch y)
e. 检查新文件的索引节点(ls -i y)
对于这两个文件,您可能会看到相同的 inode 值,尽管文件名不同。 -
非Ext文件系统可以更改 inodes:
Ext文件系统将索引节点号存储在i_ino文件中,该文件位于结构索引节点内,并写入磁盘。在这种情况下,如果文件是相同的(而不是另一个具有相同名称的文件),则inode编号保证是相同的。
如果文件系统不是Ext,则inode编号由文件系统驱动程序定义的inode操作生成。由于他们不知道inode是什么,所以他们必须模仿inode的所有内部字段以符合VFS,因此在重新启动后,甚至在再次关闭和打开文件后(理论上),这个数字可能会有所不同。 -
一些文件处理工具更改inode值。
有时用户会使用rsync或sed等工具无意中更改inode。 -
某些操作系统在重新启动后更改设备ID
根据装载方法的不同,设备ID(也用于比较文件)可能会在重新启动后更改。
启用指纹模式会延迟接收新文件,直到它们的大小至少增加到偏移量+长度字节,以便对其进行指纹打印。在此之前,这些文件将被忽略。
通常,日志行包含时间戳和其他应该能够使用指纹模式的唯一字段,但在每个用例中,用户都应该检查日志,以确定 offset 和 length 参数的适当值。默认偏移量为0,默认长度为1024或1 KB。长度不能小于64。
默认 Fingerprint 方法是禁用的,如下所示。
fingerprint:enabled: falseoffset: 0length: 1024
在 docker 的 容器环境中,应该配置开启。
prospector:scanner:fingerprint.enabled: true8. file_identity 文件标识
可以配置不同的 file_identity 方法,以适应收集日志消息的环境。
8.1. fingerprint
根据文件的内容字节范围来识别文件。
低版本有可能不支持,此文档用的是 8.14.1。
为了使用此文件标识选项,您必须在扫描仪中启用指纹选项。
prospector:scanner:fingerprint.enabled: true启用此文件标识后,更改指纹配置(offset, length 或其他设置)将导致全局重新接收与输入的路径配置匹配的所有文件。
filebeat.yml: |-filebeat.autodiscover:providers:- type: kuberneteshints.enabled: "true"hints.default_config:type: filestreamid: kubernetes-container-logs-${data.kubernetes.pod.name}-${data.container.id}paths:- /var/lib/docker/containers/${data.container.id}/*.logparsers:- container: ~prospector:scanner:fingerprint.enabled: truesymlinks: truefile_identity.fingerprint: ~ # 这里配置生效后会在事件中 log 字段中添加字段 fingerprint ,如下示例所示:
"log": {"offset": 492145,"file": {"inode": "71016582","fingerprint": "89956086127d21774ecb978f8166294a94ddb81df2b8fe79a84cd0666c073a92","path": "xxxjson-.log","device_id": "64770"}},相关文章:
shark云原生-日志体系-filebeat高级配置(适用于生产)-更新中
文章目录 1. filebeat.inputs 静态日志收集器2. filebeat.autodiscover 自动发现2.1. autodiscover 和 inputs2.2. 如何配置生效2.3. Providers 提供者2.4. Providers kubernetes2.5. 配置 templates2.5.1. kubernetes 自动发现事件中的变量字段2.5.2 配置 templates 2.6. 基于…...

响应式设计的双璧:WebKit 支持 CSS Flexbox 和 Grid 布局深度解析
响应式设计的双璧:WebKit 支持 CSS Flexbox 和 Grid 布局深度解析 在现代网页设计中,响应式布局是实现跨设备兼容性的关键。CSS Flexbox 和 Grid 作为 CSS 布局的两大支柱,提供了强大的工具来构建灵活和复杂的用户界面。WebKit,作…...

Linux软件包管理
一、软件包管理 1.什么是软件包 一般在window系统的.exe是软件按转包 2.linux系统下的软件包安装方式 PRM 软件包安装 软件名称.rpmYUM 包管理工具 yum intall 软件名称 -y源码安装 下载源代码---编译---安装 很麻烦,稳定 3.二进制软件包 二进制 4.获取*.rpm…...

如何分辨AI生成的内容?AI生成内容检测工具对比实验
检测人工智能生成的文本对各个领域的组织都提出了挑战,包括学术界和新闻界等。生成式AI与大语言模型根据短描述来进行内容生成的能力,产生了一个问题:这篇文章/内容/作业/图像到底是由人类创作的,还是AI创作的?虽然 LL…...

Clion中怎么切换不同的程序运行
如下图,比如这个文件夹下面有那么多的项目: 那么我想切换不同的项目运行怎么办呢?如果想通过下图的Edit Configurations来设置是不行的: 解决办法: 如下图,选中项目的CMakeLists.txt,右键再点击…...

【C++初阶】C++入门(下)
【C初阶】C入门(下) 🥕个人主页:开敲🍉 🥕所属专栏:C🥭 🌼文章目录🌼 6. 引用 6.1 引用的概念 6.2 引用特性 6.3 常引用 6.4 使用场景 6.5 传值、传引用效率…...

【3】迁移学习模型
【3】迁移学习模型 文章目录 前言一、安装相关模块二、训练代码2.1. 管理预训练模型2.2. 模型训练代码2.3. 可视化结果2.4. 类别函数 总结 前言 主要简述一下训练代码 三叶青图像识别研究简概 一、安装相关模块 #xingyun的笔记本 print(xingyun的笔记本) %pip install d2l %…...

【工具分享】FOFA——网络空间测绘搜索引擎
文章目录 FOFA介绍FOFA语法其他引擎 FOFA介绍 FOFA官网:https://fofa.info/ FOFA(Fingerprinting Organizations with Advanced Tools)是一款网络空间测绘的搜索引擎,它专注于帮助用户收集和分析互联网上的设备和服务信息。FOFA…...

[嵌入式 C 语言] 按位与、或、取反、异或
若协议中如下图所示: 注意: 长度为1,表示1个字节,也就是0xFF,也就是 1111 1111 (这里0xFF只是单纯表示一个数,也可以是其他数,这里需要注意的是1个字节的意思) 一、按位…...

Android --- 运行时Fragment如何获取Activity中的数据,又如何将数据传递到Activity中呢?
1.通过 getActivity() 方法获取 Activity 实例: 在 Fragment 中,可以通过 getActivity() 方法获取当前 Fragment 所依附的 Activity 实例。然后可以调用 Activity 的公共方法或者直接访问 Activity 的字段来获取数据。 // 在 Fragment 中获取 Activity…...
-- Java8 stream的 orElse(null) 和 orElseGet(null))
Java后端开发(十三)-- Java8 stream的 orElse(null) 和 orElseGet(null)
orElse(null)表示如果一个都没找到返回null。【orElse()中可以塞默认值。如果找不到就会返回orElse中你自己设置的默认值。】 orElseGet(null)表示如果一个都没找到返回null。【orElseGet()中可以塞默认值。如果找不到就会返回orElseGet中你自己设置的默认值。】 区别就…...

L2 LangGraph_Components
参考自https://www.deeplearning.ai/short-courses/ai-agents-in-langgraph,以下为代码的实现。 这里用LangGraph把L1的ReAct_Agent实现,可以看出用LangGraph流程化了很多。 LangGraph Components import os from dotenv import load_dotenv, find_do…...

09.C2W4.Word Embeddings with Neural Networks
往期文章请点这里 目录 OverviewBasic Word RepresentationsIntegersOne-hot vectors Word EmbeddingsMeaning as vectorsWord embedding vectors Word embedding processWord Embedding MethodsBasic word embedding methodsAdvanced word embedding methods Continuous Bag-…...
硅谷甄选二(登录)
一、登录路由静态组件 src\views\login\index.vue <template><div class"login_container"><!-- Layout 布局 --><el-row><el-col :span"12" :xs"0"></el-col><el-col :span"12" :xs"2…...

scipy库中,不同应用滤波函数的区别,以及FIR滤波器和IIR滤波器的区别
一、在 Python 中,有多种函数可以用于应用 FIR/IIR 滤波器,每个函数的使用场景和特点各不相同。以下是一些常用的 FIR /IIR滤波器应用函数及其区别: from scipy.signal import lfiltery lfilter(fir_coeff, 1.0, x)from scipy.signal impo…...

简谈设计模式之建造者模式
建造者模式是一种创建型设计模式, 旨在将复杂对象的构建过程与其表示分离, 使同样的构建过程可以构建不同的表示. 建造者模式主要用于以下情况: 需要创建的对象非常复杂: 这个对象由多个部分组成, 且这些部分需要一步步地构建不同的表示: 通过相同的构建过程可以生成不同的表示…...

力扣 hot100 -- 动态规划(下)
目录 💻最长递增子序列 AC 动态规划 AC 动态规划(贪心) 二分 🏠乘积最大子数组 AC 动规 AC 用 0 分割 🐬分割等和子集 AC 二维DP AC 一维DP ⚾最长有效括号 AC 栈 哨兵 💻最长递增子序列 300. 最长递增子序列…...
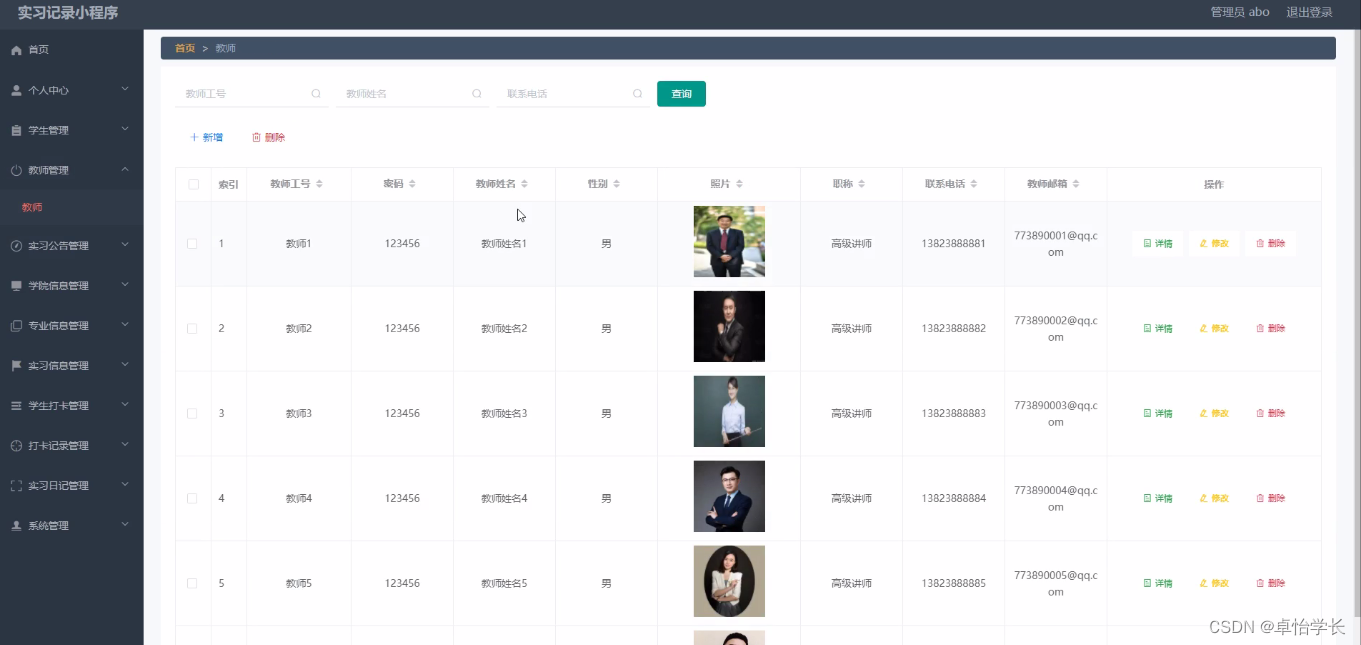
【计算机毕业设计】018基于weixin小程序实习记录
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

力扣之有序链表去重
删除链表中的重复元素,重复元素保留一个 p1 p2 1 -> 1 -> 2 -> 3 -> 3 -> null p1.val p2.val 那么删除 p2,注意 p1 此时保持不变 p1 p2 1 -> 2 -> 3 -> 3 -> null p1.val ! p2.val 那么 p1,p2 向后移动 p1 …...

Apache配置与应用(优化apache)
Apache配置解析(配置优化) Apache链接保持 KeepAlive:决定是否打开连接保持功能,后面接 OFF 表示关闭,接 ON 表示打开 KeepAliveTimeout:表示一次连接多次请求之间的最大间隔时间,即两次请求之间…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...

全面解析数据库:从基础概念到前沿应用
在数字化时代,数据已成为企业和社会发展的核心资产,而数据库作为存储、管理和处理数据的关键工具,在各个领域发挥着举足轻重的作用。从电商平台的商品信息管理,到社交网络的用户数据存储,再到金融行业的交易记录处理&a…...

GeoServer发布PostgreSQL图层后WFS查询无主键字段
在使用 GeoServer(版本 2.22.2) 发布 PostgreSQL(PostGIS)中的表为地图服务时,常常会遇到一个小问题: WFS 查询中,主键字段(如 id)莫名其妙地消失了! 即使你在…...
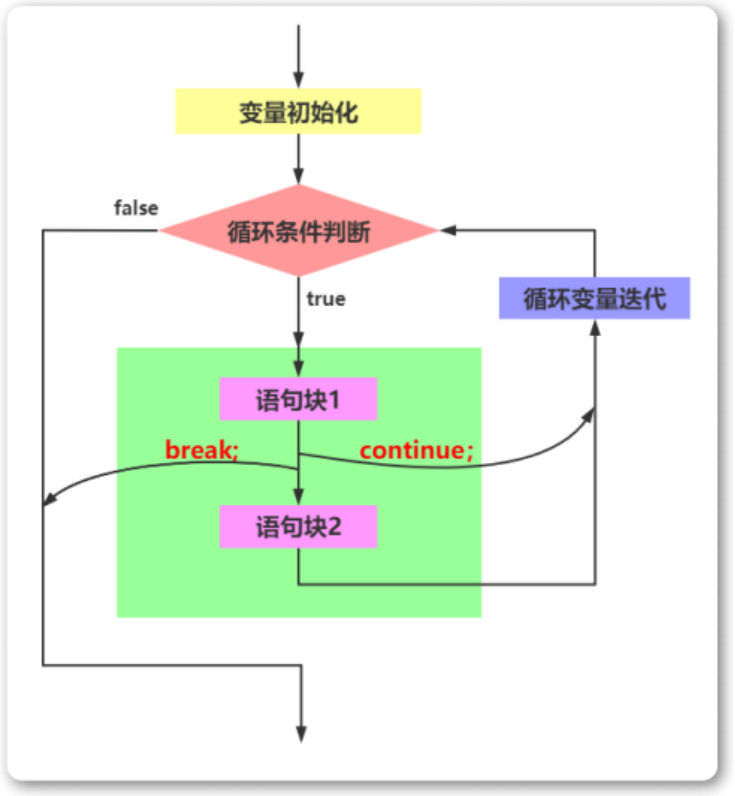
break 语句和 continue 语句
break语句和continue语句都具有跳转作用,可以让代码不按既有的顺序执行 break break语句用于跳出代码块或循环 1 2 3 4 5 6 for (var i 0; i < 5; i) { if (i 3){ break; } console.log(i); } continue continue语句用于立即终…...

ABB馈线保护 REJ601 BD446NN1XG
配电网基本量程数字继电器 REJ601是一种专用馈线保护继电器,用于保护一次和二次配电网络中的公用事业和工业电力系统。该继电器在一个单元中提供了保护和监控功能的优化组合,具有同类产品中最佳的性能和可用性。 REJ601是一种专用馈线保护继电器…...