视觉语言模型导论:这篇论文能成为你进军VLM的第一步
近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。
这些模型之前基本都局限于文本输入,但现在也正在具备处理视觉输入的能力。如果能将视觉与语言打通,那么势必能造就多种多样的应用 —— 这实际上也正是当前 AI 技术革命的关键方向。
即便现在已有不少研究将大型语言模型扩展到了视觉领域,但视觉与语言之间的连接尚未被彻底打通。举些例子,大多数模型都难以理解空间位置关系或计数 —— 这还需要复杂的工程设计并依赖额外的数据标注。许多视觉语言模型(VLM)依然难以理解属性和顺序。它们往往会忽略输入 prompt 的某些部分,因此为了得到理想结果,用户常常需要在提示工程上费心费力。还有些模型会产生幻觉,产出无用或不相关的内容。因此,人们依然在大力开发稳定的模型。
如果你是有志这一行业的学生或爱好者或想要从其它 AI 领域转战此方向,那么请一定不要错过我们今天要介绍的这篇《视觉语言模型导论》。

- 论文标题:An Introduction to Vision-Language Modeling
- 论文地址:arxiv.org/pdf/2405.17…
这篇导论来自 Meta 和蒙特利尔大学等多所研究机构的数十位研究者,将解释 VLM 是什么、它们是如何训练的以及如何基于不同研究目标有效地评估它们。
该团队表示,这篇论文的目标是帮助读者轻松理解 VLM 并着重说明这一领域的有效实践,而不是提供 VLM 研究成果的详尽综述或完整指南。
多种多样的 VLM
得益于深度学习的发展,计算机视觉和自然语言处理领域都取得了令人瞩目的进展,也因此已经有不少研究团队尝试过将这两个领域连接到一起。
这篇论文关注的重点是最近期的基于 Transformer 的技术。
该团队将尝试打通这两大领域的研究成果,按训练范式分成了四类,见图 1。

第一类是对比式训练(contrastive training),这是一种使用正例和负例对来训练模型的常用策略。VLM 的训练目标是为正例对预测相似的表征,为负例对预测不同的表征。
第二类是掩码(masking),其方法是根据某些未被遮掩的文本来重建被遮掩的图块。类似地,通过遮掩描述中的词,也可以让 VLM 根据未被遮掩的图像来重建这些被遮掩的词。
另一类是基于预训练骨干网络来训练 VLM,这往往是使用 Llama 等开源 LLM 来学习图像编码器(也可能是预训练的)和 LLM 之间的映射关系。相比于从头开始训练文本和图像编码器,学习预训练模型之间的映射关系的计算成本往往更低。
大部分这类方法都是使用中间表征或部分重建,而生成式 VLM 则能生成图像或描述。有鉴于这类模型的性质,它们的训练成本通常是最高的。
需要说明:这些范式并不是互斥的,很多方法都混合使用了对比、掩码和生成范式。文中为每种范式都提供了一两个模型进行说明,以帮助读者了解这些模型的设计思路。
基于 Transformer 的 VLM 早期研究
通过使用 Transformer 架构,BERT(使用 Transformer 的双向编码器表征)一诞生,就超过了当时所有的语言建模方法。之后不久,BERT 就被扩展用来处理视觉数据。visual-BERT 和 ViLBERT 是其中两个代表,它们的做法是将文本与图像 token 组合到一起。
这些模型有两个训练目标:1) 经典的掩码建模任务,目标是预测给定输入中缺失的部分;2) 句子 - 图像预测任务,目标是预测图像标注是否描述了图像内容。
通过利用这两个目标,这些模型在多种视觉 - 语言任务上表现出色,这主要是得益于 Transformer 模型有能力学会通过注意力机制将词与视觉线索关联起来。
基于对比的 VLM
基于对比的训练往往能通过基于能量的模型(EBM)更好地解释,即模型的训练目标是为观察到的变量分配低能量,为未被观察到的变量分配高能量。来自目标分布的数据的能量应该较低,其它数据点的能量应该较高。
使用掩码目标的 VLM
在深度学习研究中,掩码是一种常用技术。它可被视为一种特定形式的去噪自动编码器,其中的噪声有一种空间结构。它也与修复(inpainting)策略有关,该策略曾被用于学习强大的视觉表征。BERT 也在训练阶段使用了掩码式语言建模(MLM)来预测句子中缺失的 token。掩码方法非常适合 Transformer 架构,因此输入信号的 token 化使得随机丢弃特定的输入 token 变得更容易。
已经有一些研究在图像方面探索这一方法,即掩码式图像建模(MIM),具体案例包括 MAE 和 I-JEPA。
很自然地,也有人将这两者组合起来训练 VLM。其一是 FLAVA,其使用了掩码在内的多种训练策略来学习文本和图像表征。另一个是 MaskVLM,这是一种独立模型。
基于生成的 VLM
上面的训练范式主要是操作隐含表征来构建图像或文本抽象,之后再在它们之间映射,生成范式则不同,它考虑文本和 / 或图像的生成。
CoCa 等一些方法会学习一个完整的文本编码器和解码器来描述图像 Chameleon Team 和 CM3leon 等另一些方法则是多模态的生成模型,其训练目标就包括生成文本和图像。最后,还有些模型的目标是基于文本生成图像,比如 Stable Diffusion、Imagen 和 Parti。但是,即便它们是为生成图像而生的,它们也能被用于解决一些视觉 - 语言理解任务。
用预训练骨干网络构建的 VLM
VLM 的一个缺点是从头开始训练的成本很高。这通常需要成百上千台 GPU,同时还必须使用上亿对图像和文本。因此,也有很多研究者探索使用已有的 LLM 和 / 或视觉提取器,而不是从头开始训练模型。
这种做法的另一个优势是可以利用现在很多开源且易用的 LLM。
通过使用这样的模型,有可能学习到仅在文本模态和图像模态之间的映射。通过学习这样的映射,仅需要少量计算资源就可让 LLM 有能力回答视觉问题。
该团队在论文中说明了这类模型的两个代表:一是首个使用预训练 LLM 的模型 Frozen,二是 Mini-GPT。详见原论文。
VLM 训练指南
有一些研究揭示了进一步扩大深度神经网络规模的重要性。受这些 scaling law 的激励,最近不少项目都在通过增加计算量和扩大模型规模来学习更好的模型。这就催生了 CLIP 等模型 —— 其训练使用了 4 亿张图像,计算预算自然也非常高。就算是其开源实现 OpenCLIP,根据模型大小的不同,训练也使用了 256 到 600 台 GPU,耗时数天到几周。
但是,又有一项研究表明通过精心的数据整编,有可能战胜 scaling law。这一节首先将讨论训练模型时数据的重要性,并会给出一些用于构建 VLM 训练数据集的方法。
然后会讨论常用的软件、工具和技巧,它们可帮助实践者更高效地训练 VLM。
由于训练 VLM 有多种不同方法,所以文中还会讨论特定情形下应该选用什么类型的模型。
之后,该团队还会给出一些提升定基(grounding,即正确映射文本与视觉线索的能力)的技巧,并介绍使用人类偏好提升对齐的技术。
VLM 常被用于阅读和翻译文本,所以他们也会分享一些用于进一步提升 VLM 的 OCR 能力的技术。
最后是一些常用的微调方法。

训练数据
为了评估预训练数据集的质量,DataComp 提出了一个基准,其中 CLIP 的模型架构和预训练超参数都是固定的。其评估重点是设计出能在 38 个下游任务上取得优良零样本和检索性能的图像 - 文本数据集。DataComp 提供了多个有噪声网页数据集池,规模从小型(1.28M)到超大型(12.8B)不等。针对每个池,都有多个过滤策略被提出和评估。DataComp 表明:为了训练出高效高性能的 VLM,数据剪枝是一个关键步骤。
用于 VLM 的数据剪枝方法可以分为三大类:(1) 启发式方法,可以清除低质量数据对;(2) bootstrapping 方法,使用预训练的 VLM 评估图像和文本的多模态对齐程度,然后丢弃其中对齐较差的数据对;(3) 用于创建多样化和平衡数据集的方法。具体的措施包括:
- 使用合成数据来提升训练数据
- 使用数据增强
- 交错式的数据整编
- 评估多模态数据质量
- 利用人类专业知识:数据标注的力量
软件
这一小节讨论了现有的可用于评估和训练 VLM 的软件以及训练它们所需的资源。
- 使用现有的公共软件库
- 我需要多少台 GPU?
- 为训练加速
- 其它超参数的重要性
使用什么模型?
前面已经提到,训练 VLM 的方法有好几种。一些是使用简单的对比训练方案,一些则是使用掩码策略来预测缺失的文本或图块,还有一些模型使用的是自回归或扩散等生成范式。也有可能使用 Llama 或 GPT 等预训练的视觉或文本骨干网络。在这种情况下,构建 VLM 模型仅需学习 LLM 和视觉编码器表征之间的映射。
那么,应该如何选择这些方法呢?我们需要像 CLIP 一样从头开始训练视觉和文本编码器,还是像 Flamingo 或 MiniGPT 一样从预训练的 LLM 开始训练?
- 何时使用 CLIP 这样的对比模型?
- 何时使用掩码?
- 何时使用生成模型?
- 何时使用 LLM 作为预训练骨干网络?
提升定基
在 VLM 和生成模型文献中,定基(grounding)是一个关键难题。定基的目标主要是解决模型不能很好理解文本 prompt 的问题,这个问题既可能导致模型忽视 prompt 中的某些部分,也可能导致其产生幻觉,想象出 prompt 中没有的内容。
解决这些难题需要理解关系,比如确定一个物体是在左边还是右边、否定、计数、理解属性(如颜色或纹理)。
提升定基这个研究领域很活跃,而目前还尚未出现一种能解决此难题的单一简单方法。尽管如此,在提升定基性能方面,还是有一些技巧可用:
- 使用边界框标注
- 否定描述
提升对齐
受语言领域指令微调的成功的启发视觉语言模型也开始整合指令微调和根据人类反馈的强化学习(RLHF)来提升多模态聊天能力以及将输出与期望响应对齐。
指令微调涉及到在一个包含指令、输入和期望响应的监督式数据集上对视觉语言模型进行微调。通常来说,指令微调数据集的规模远小于预训练数据集 —— 指令微调数据集的规模从少量到数十万不等。整合了指令微调的视觉语言模型包括 LLaVa、InstructBLIP、OpenFlamingo。
RLHF 的另一个目标是对齐模型输出与人类偏好。使用 RLHF 时,需要训练一个奖励模型来匹配人类偏好 —— 即人类认为一个模型响应是好是坏。尽管指令微调需要监督训练样本(收集成本较高),但 RLHF 则可使用辅助式奖励模型来模拟人类偏好。然后再使用该奖励模型来微调主模型(不管是语言模型还是视觉语言模型),使其输出与人类偏好对齐。LLaVa-RLFH 就是一个视觉语言模型整合 RLHF 的突出案例,其能通过事实信息来提升模型的输出对齐。
提升对富含文本的图像的理解
在我们的日常生活中,视觉感知中有一大关键部分:理解文本。多模态大型语言模型(MLLM)的成功可让 VLM 以零样本方式应用于多种应用,并且其中许多已经可用于真实世界场景。
有研究表明 MLLM 具备卓越的零样本光学字符识别(OCR)能力,无需专门使用特定于 OCR 领域的数据进行训练。但是,当涉及到数据类型之间的复杂关系时,这些模型往往难以解读图像中的文本,原因是它们的训练数据中包含大量自然图像。
下面列出了一些在文本理解方面的常见难题以及试图解决该难题的模型:
- 使用细粒度的富含文本的数据进行指令微调:LLaVAR
- 处理高分辨率图像中的细粒度文本:Monkey
- 分立式场景文本识别模块和 MM-LLM:Lumos
参数高效型微调
事实已经证明,在跨领域视觉和语言任务上,VLM 的效果很好。但是,随着预训练模型大小持续增长,由于计算限制,微调这些模型的全体参数集将变得不切实际。
为了解决这一难题,参数高效型微调(PEFT)方法诞生了,其目标是解决与微调大规模模型相关的高计算成本问题。这些方法关注的重点是训练部分参数来使模型适应下游任务,而不是重新训练全体模型。现有的 PEFT 方法可以分为四大类:
- 基于低秩适配器(LoRa)的方法
- 基于 prompt 的方法
- 基于适应器的方法
- 基于映射的方法
实现负责任 VLM 评估的方法
VLM 的主要能力是实现文本与图像的映射,因此度量其视觉语言能力就非常关键了,因为这能确保词与视觉线索真正实现了映射。
在评估 VLM 方面,早期的评估任务包括图像描述和视觉问答(VQA)。
现在还有以文本为中心的 VQA(text-centric VQA)任务,其评估的是模型理解和阅读图像中的文本的能力。
Radford et al. [2021] 也提出了一种常用的评估方法,该方法是基于零样本预测,比如 ImageNet 分类任务。这样的分类任务可以评估 VLM 是否具备足够的世界知识。
Winoground 是一个更近期的基准,其度量的是模型的视觉 - 语言组合推理能力。
另外,我们已经知道 VLM 会表现出偏见和幻觉,因此对这两方面进行评估也非常重要。

将 VLM 扩展用于视频
之前谈到的 VLM 基本都是在静态视觉数据(图像)上训练和评估的。但是,视觉数据还有动态的,即视频。
对 VLM 而言,视频数据既能带来新挑战,也有望为其带来新能力,比如理解物体的运动和动态或在空间和时间中定位物体和动作。用文本检索视频、视频问答和视频生成正在快速成为基础的计算机视觉任务。
视频的时间属性对存储、CPU 内存来说都是一个巨大挑战(如果把每一帧都视为一张图像,那么帧率越高,成本就越高)。于是对于处理视频的 VLM 而言,就需要考虑多个权衡因素,比如数据加载器中动态视频解码器的压缩格式、基于图像编码器来初始化视频编码器、为视频编码器使用时空池化 / 掩码机制、非端到端 VLM。
与图像 - 文本模型类似,早期的视频 - 文本模型也是使用自监督指标来从头开始训练视觉和文本组件。但不同于图像模型,对比式视频 - 文本模型并非首选方法,早期时人们更喜欢融合和时间对齐方法,因为相比于计算视频的全局表征,让表征中有更多时间粒度更重要。
近段时间,视频 - 语言模型领域出现了图像 - 语言模型领域类似的趋势:使用预训练 LLM 并将其与视频编码器对齐,从而增强 LLM 的视频理解能力。视觉指令微调等现代技术也被广泛使用并被适配用于视频。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
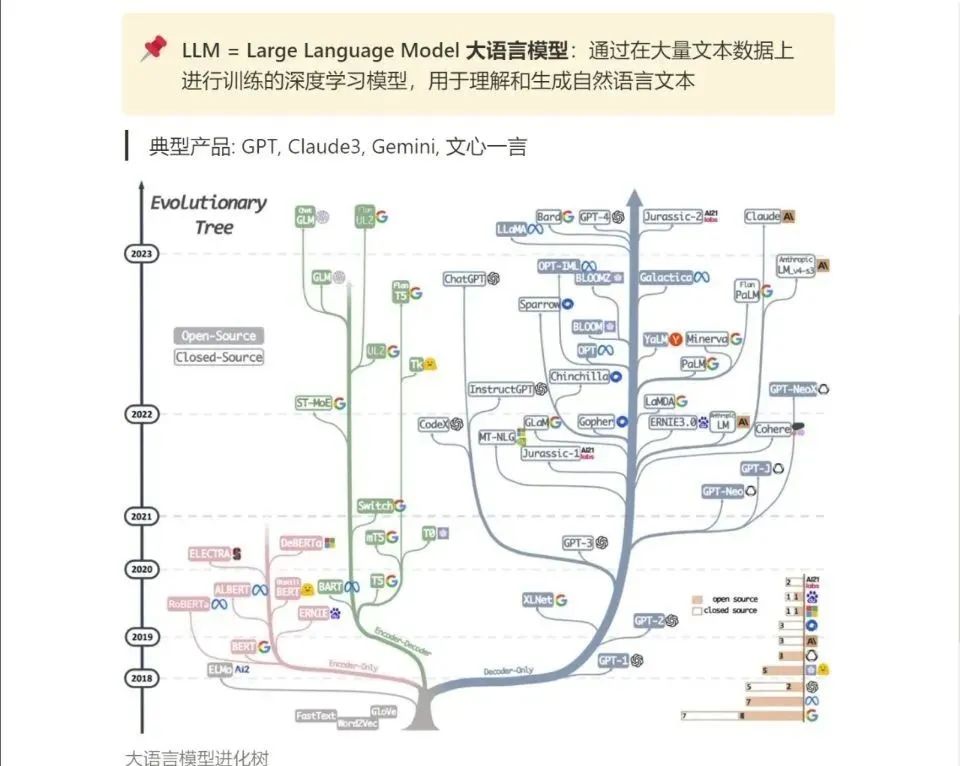
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!
相关文章:
视觉语言模型导论:这篇论文能成为你进军VLM的第一步
近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。 这些模型之前基本都局限于文本输入,但现在也正在具备处理视觉输入的能力。如果…...

Postman工具基本使用
一、安装及基本使用 安装及基本使用参见外网文档:全网最全的 postman 工具使用教程_postman使用-CSDN博客 建议版本:11以下,比如10.x.x版本。11版本以后貌似是必须登录使用 二、禁止更新 彻底禁止postman更新 - 简书 host增加࿱…...

uni-app三部曲之三: 路由拦截
1.引言 路由拦截,个人理解就是在页面跳转的时候,增加一级拦截器,实现一些自定义的功能,其中最重要的就是判断跳转的页面是否需要登录后查看,如果需要登录后查看且此时系统并未登录,就需要跳转到登录页&…...

专注于国产FPGA芯片研发的异格技术Pre-A+轮融资,博将控股再次投资
近日,苏州异格技术有限公司(以下简称“异格技术”)宣布成功完成数亿元的Pre-A轮融资,由博将控股在参与Pre-A轮投资后,持续投资。这标志着继2022年获得经纬中国、红点中国、红杉中国等机构数亿元天使轮融资后࿰…...

【python】QWidget父子关系,控件显示优先级原理剖析与应用实战演练
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

CTF php RCE(三)
0x07 日志文件包含 判断类型 使用kali curl -I urlF12 打开F12开发者工具,选中之后F5刷新查看server类型即可 配置文件 直接包含或者访问如果有回显就是, NGINX:NGINX 的配置文件通常位于 /etc/nginx/ 目录下,具体的网站配…...

Android 注解的语法原理和使用方法
Android 注解的语法原理和使用方法 关于我 在 Android 开发中,注解(Annotation)是一种强大的工具,用于在代码中添加元数据。注解可以简化代码、提高可读性、减少样板代码,并且在一定程度上增强编译时的类型检查。本文…...

YOLOv10改进 | Conv篇 | 利用FasterBlock二次创新C2f提出一种全新的结构(全网独家首发,参数量下降70W)
一、本文介绍 本文给大家带来的改进机制是利用FasterNet的FasterBlock改进特征提取网络,将其用来改进ResNet网络,其旨在提高计算速度而不牺牲准确性,特别是在视觉任务中。它通过一种称为部分卷积(PConv)的新技术来减少…...

实验-ENSP实现防火墙区域策略与用户管理
目录 实验拓扑 自己搭建拓扑 实验要求 实验步骤 整通总公司内网 sw3配置vlan 防火墙配置IP 配置安全策略(DMZ区内的服务器,办公区仅能在办公时间内(9: 00- 18:00)可以访问,生产区的设备全天可以访问) 配置nat策…...

【游戏客户端】大话slg玩法架构(二)背景地图
【游戏客户端】大话slg玩法架构(二)背景地图 大家好,我是Lampard家杰~~ 今天我们继续给大家分享SLG玩法的实现架构,关于SLG玩法的介绍可以参考这篇上一篇文章:【游戏客户端】制作率土之滨Like玩法 PS:和之前…...

git-工作场景
1. 远程分支为准 强制切换到远程分支并忽略本地未提交的修改 git fetch origin # 获取最新的远程分支信息 git reset --hard origin/feature_server_env_debug_20240604 # 强制切换到远程分支,并忽略本地修改 2. 切换分支 1. **查看所有分支:**…...
)
coco dataset标签数据结构(json文件)
COCO数据集现在有3种标注类型:object instances(目标实例), object keypoints(目标上的关键点), 和image captions(看图说话),使用json文件存储。 NameImagesLabelstrain linkhttp:…...

GaussDB关键技术原理:高性能(四)
GaussDB关键技术原理:高性能(三)从查询重写RBO、物理优化CBO、分布式优化器、布式执行框架、轻量全局事务管理GTM-lite等五方面对高性能关键技术进行了解读,本篇将从USTORE存储引擎、计划缓存计划技术、数据分区与分区剪枝、列式存…...

总结之企业微信(一)——创建外部群二维码,用户扫码入群
创建外部群 企微接口中没有直接通过服务端API接口创建外部群 可以通过jssdk创建外部群:引用jssdk调用会话接口wx.openEnterpriseChat https://work.weixin.qq.com/api/doc/90000/90136/90511 创建外部群二维码 需要通过企业微信的应用,并且配置客户联…...

透视数据治理:企业如何衡量数据治理的效果?
在企业运营中,各个业务部门的成功与否都是直观且易于量化的,像销售部门卖了多少产品又为企业带来多少盈利,这些都能用具体的数字来说话。但当谈到数据治理的成效时,许多企业与决策者却感到迷茫。 数据治理的重要性不言而喻&#…...

ERC20查询操作--获取ERC20 Token的余额
获取ERC20 Token的余额 https://blog.csdn.net/wypeng2010/article/details/81362562 通过REST查询 curl -X POST --data-binary {"jsonrpc":"2.0","method":"eth_call","params":[{"from": "0x954d1a58c7a…...

Linux运维:MySQL中间件代理服务器,mycat读写分离应用实验
Mycat适用的场景很丰富,以下是几个典型的应用场景: 1.单纯的读写分离,此时配置最为简单,支持读写分离,主从切换 2.分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片 3.多租户应…...

css文字自适应宽度动态出现省略号...
前言 在列表排行榜中通常会出现的一个需求:从左到右依次是名次、头像、昵称、徽标、分数。徽标可能会有多个或者没有徽标,徽标长度是动态的,昵称如果过长要随着有无徽标进行动态截断出现省略号。如下图布局所示(花里胡哨的底色是…...

边缘计算盒子_B100_Jetson Nano (aarch64)开发环境搭建
目录 一、刷机步骤1、搭建刷机环境2、进入刷机模式3、开始刷机 二、系统迁移到TF卡 或者 U盘1、迁移脚本2、提前插入U盘或者TF卡3、 开始迁移 三、搭建miniconda 环境1、下载安装 四、jetpack开发套件环境1、版本查看2、apt 更换国内源3、安装Jetson-stats管理工具 一、刷机步骤…...

【Superset】dashboard 自定义URL
URL设置 在发布仪表盘(dashboard)后,可以通过修改看板属性中的SLUG等,生成url 举例: http://localhost:8090/superset/dashboard/test/ 参数设置 以下 URL 参数可用于修改仪表板的呈现方式:此处参考了官…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...
JDK 17 序列化是怎么回事
如何序列化?其实很简单,就是根据每个类型,用工厂类调用。逐个完成。 没什么漂亮的代码,只有有效、稳定的代码。 代码中调用toJson toJson 代码 mapper.writeValueAsString ObjectMapper DefaultSerializerProvider 一堆实…...

比较数据迁移后MySQL数据库和ClickHouse数据仓库中的表
设计一个MySQL数据库和Clickhouse数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
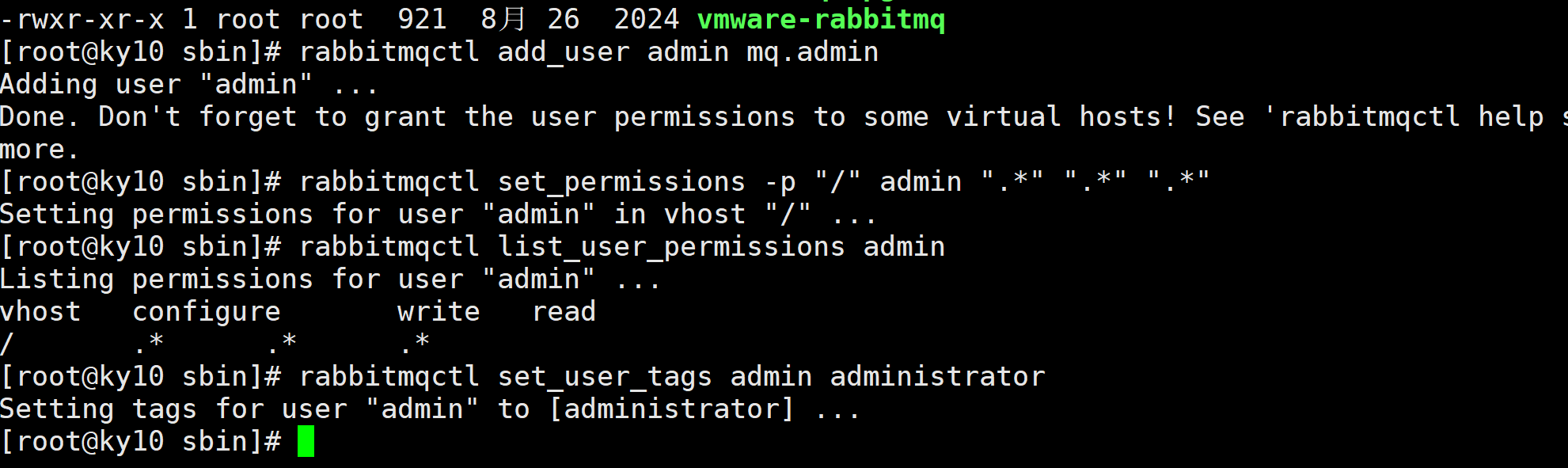
mq安装新版-3.13.7的安装
一、下载包,上传到服务器 https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.13.7/rabbitmq-server-generic-unix-3.13.7.tar.xz 二、 erlang直接安装 rpm -ivh erlang-26.2.4-1.el8.x86_64.rpm不需要配置环境变量,直接就安装了。 erl…...