Scikit Learn - 建模手册(02)--- 数据表示、估算器
Scikit Learn - 数据表示

文章目录
- 一、说明
- 二、数据表格
- 2.1 数据作为特征矩阵
- 2.2 数据作为目标数组
- 三、什么是 Estimator API
- 四、Estimator API 的使用
- 五、指导原则
- 六、使用 Estimator API 的步骤
- 七、监督学习示例
- 八、无监督学习示例
一、说明
众所周知,机器学习即将从数据中创建模型。为此,计算机必须首先理解数据。接下来,我们将讨论表示数据以便计算机理解的各种方法。后面,我们将介绍估算器的使用。
二、数据表格
在 Scikit-learn 中表示数据的最佳方式是以表格的形式。表表示数据的二维网格,其中行表示数据集的各个元素,列表示与这些单个元素相关的数量。
例
通过下面给出的示例,我们可以借助 python seaborn 库以 Pandas DataFrame 的形式下载鸢尾花数据集。
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
输出
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
从上面的输出中,我们可以看到数据的每一行代表观察到的花朵,行数代表数据集中的花朵总数。通常,我们将矩阵的行称为样本。
另一方面,数据的每一列都代表描述每个样本的定量信息。通常,我们将矩阵的列称为特征。
2.1 数据作为特征矩阵
特征矩阵可以定义为表格布局,其中信息可以被视为二维矩阵。它存储在名为 X 的变量中,并假定为二维,形状为 [n_samples, n_features]。大多数情况下,它包含在 NumPy 数组或 Pandas DataFrame 中。如前所述,样本始终表示数据集描述的单个对象,特征表示以定量方式描述每个样本的不同观测值。
探索我们最新的在线课程,按照自己的节奏学习新技能。注册并成为认证专家,以提升您的职业生涯。
2.2 数据作为目标数组
除了用 X 表示的特征矩阵外,我们还有目标数组。它也被称为标签。它用 y 表示。标签或目标数组通常是一维的,长度为 n_samples。它通常包含在 NumPy 数组或 Pandas 系列中。目标数组可以同时具有连续数值和离散值。
目标数组与功能列有何不同?
我们可以通过一点来区分两者,即目标数组通常是我们想要从数据中预测的数量,即在统计术语中,它是因变量。
例
在下面的示例中,我们从鸢尾花数据集中根据其他测量值预测花的种类。在这种情况下,物种列将被视为要素。
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);
输出

X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
输出
(150,4)
(150,)
三、什么是 Estimator API
它是 Scikit-learn 实现的主要 API 之一。它为各种 ML 应用程序提供了一致的接口,这就是为什么 Scikit-Learn 中的所有机器学习算法都是通过 Estimator API 实现的。从数据中学习(拟合数据)的对象是估计器。它可以与任何算法一起使用,如分类、回归、聚类,甚至可以与从原始数据中提取有用特征的转换器一起使用。
为了拟合数据,所有估算器对象都公开了一个拟合方法,该方法采用如下所示的数据集 -
estimator.fit(data)
接下来,当估计器被相应的属性实例化时,可以设置它的所有参数,如下所示。
estimator = Estimator (param1=1, param2=2)
estimator.param1
上述的输出为 1。
一旦数据与估计器拟合,就会根据手头的数据估计参数。现在,所有估计参数都将是估计器对象的属性,以下列标结尾:
estimator.estimated_param_
四、Estimator API 的使用
估算器的主要用途如下:
模型的估计和解码
Estimator 对象用于模型的估计和解码。此外,该模型被估计为以下确定性函数 −
对象构造中提供的参数。
如果估计器的 random_state 参数设置为 none,则全局随机状态 (numpy.random)。
传递给最近调用以拟合、fit_transform或fit_predict的任何数据。
在一系列调用中传递给partial_fit的任何数据。
将非矩形数据表示映射到矩形数据
它将非矩形数据表示映射到矩形数据中。简单来说,它接受每个样本未表示为固定长度的类似数组对象的输入,并为每个样本生成一个类似数组的特征对象。
核心样品和外围样品的区别
它使用以下方法对核心样本和外围样本之间的区别进行建模 -
适合
fit_predict如果转导
预测是否感应
探索我们最新的在线课程,按照自己的节奏学习新技能。注册并成为认证专家,以提升您的职业生涯。
五、指导原则
在设计 Scikit-Learn API 时,请牢记以下指导原则 -
一致性
该原则指出,所有对象都应共享从一组有限方法中提取的公共接口。文档也应保持一致。
有限的对象层次结构
这个指导原则说——
算法应由 Python 类表示
数据集应以标准格式表示,如 NumPy 数组、Pandas DataFrames、SciPy 稀疏矩阵。
参数名称应使用标准 Python 字符串。
组成
众所周知,ML算法可以表示为许多基本算法的序列。Scikit-learn 在需要时会使用这些基本算法。
合理的默认值
根据这一原则,每当 ML 模型需要用户指定的参数时,Scikit-learn 库都会定义一个适当的默认值。
检查
根据此指导原则,每个指定的参数值都作为 pubic 属性公开。
六、使用 Estimator API 的步骤
以下是使用 Scikit-Learn 估算器 API 的步骤 −
第 1 步:选择模型类别
在第一步中,我们需要选择一类模型。这可以通过从 Scikit-learn 导入相应的 Estimator 类来完成。
步骤 2:选择模型超参数
在这一步中,我们需要选择类模型超参数。这可以通过使用所需值实例化类来完成。
第 3 步:排列数据
接下来,我们需要将数据排列成特征矩阵(X)和目标向量(y)。
第 4 步:模型拟合
现在,我们需要将模型拟合到您的数据中。这可以通过调用模型实例的 fit() 方法来完成。
步骤 5:应用模型
拟合模型后,我们可以将其应用于新数据。对于监督学习,请使用 predict() 方法预测未知数据的标签。对于无监督学习,请使用 predict() 或 transform() 来推断数据的属性。
七、监督学习示例
在这里,作为此过程的一个示例,我们采用将一条线拟合到 (x,y) 数据的常见情况,即简单线性回归。
首先,我们需要加载数据集,我们使用的是虹膜数据集 −
例
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
输出
(150, 4)
例
y_iris = iris['species']
y_iris.shape
输出
(150,)
例
现在,对于这个回归示例,我们将使用以下示例数据 −
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
输出

因此,我们的线性回归示例有上述数据。
现在,有了这些数据,我们可以应用上述步骤。
选择一类模型
在这里,为了计算一个简单的线性回归模型,我们需要导入线性回归类,如下所示 -
from sklearn.linear_model import LinearRegression
选择模型超参数
一旦我们选择了一类模型,我们就需要做出一些重要的选择,这些选择通常表示为超参数,或者在模型拟合数据之前必须设置的参数。在这里,对于这个线性回归的例子,我们希望通过使用fit_intercept超参数来拟合截距,如下所示 -
例
model = LinearRegression(fit_intercept = True)
model
输出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)
排列数据
现在,正如我们所知,我们的目标变量 y 是正确的形式,即 1-D 数组n_samples长度。但是,我们需要重塑特征矩阵 X,使其成为大小为 [n_samples, n_features] 的矩阵。可以按如下方式完成 -
例
X = x[:, np.newaxis]
X.shape
输出
(40, 1)
模型拟合
一旦我们安排了数据,就该拟合模型了,即将我们的模型应用于数据。这可以在 fit() 方法的帮助下完成,如下所示 -
例
model.fit(X, y)
输出
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)
在 Scikit-learn 中,fit() 进程有一些尾随下划线。
对于此示例,以下参数显示了数据的简单线性拟合的斜率 −
例
model.coef_
输出
array([1.99839352])
以下参数表示对数据的简单线性拟合的截距 −
例
model.intercept_
输出
-0.9895459457775022
将模型应用于新数据
训练模型后,我们可以将其应用于新数据。由于监督机器学习的主要任务是基于不属于训练集的新数据来评估模型。它可以在 predict() 方法的帮助下完成,如下所示 -
例
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);

完整的工作/可执行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as snsiris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shaperng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shapemodel.fit(X, y)
model.coef_
model.intercept_xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);
八、无监督学习示例
在这里,作为此过程的一个示例,我们以降低 Iris 数据集的维数的常见情况为例,以便我们可以更轻松地将其可视化。在此示例中,我们将使用主成分分析 (PCA),这是一种快速线性降维技术。
与上面给出的示例一样,我们可以加载并绘制虹膜数据集中的随机数据。之后,我们可以按照以下步骤操作 -
选择一类模型
from sklearn.decomposition import PCA
选择模型超参数
例
model = PCA(n_components=2)
model
输出
PCA(copy = True, iterated_power = ‘auto’, n_components = 2, random_state = None,
svd_solver = ‘auto’, tol = 0.0, whiten = False)
模型拟合
例
model.fit(X_iris)
输出
PCA(copy = True, iterated_power = ‘auto’, n_components = 2, random_state = None,
svd_solver = ‘auto’, tol = 0.0, whiten = False)
将数据转换为二维
例
X_2D = model.transform(X_iris)
现在,我们可以将结果绘制如下:
输出
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);
输出

完整的工作/可执行示例
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as snsiris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCAmodel = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);
相关文章:
Scikit Learn - 建模手册(02)--- 数据表示、估算器
Scikit Learn - 数据表示 文章目录 一、说明二、数据表格2.1 数据作为特征矩阵2.2 数据作为目标数组 三、什么是 Estimator API四、Estimator API 的使用五、指导原则六、使用 Estimator API 的步骤七、监督学习示例八、无监督学习示例 一、说明 众所周知,机器学习…...

【鸿蒙学习笔记】通过用户首选项实现数据持久化
官方文档:通过用户首选项实现数据持久化 目录标题 使用场景第1步:源码第2步:启动模拟器第3步:启动entry第6步:操作样例2 使用场景 Preferences会将该数据缓存在内存中,当用户读取的时候,能够快…...

LabVIEW航空发动机试验器数据监测分析
1. 概述 为了适应航空发动机试验器的智能化发展,本文基于图形化编程工具LabVIEW为平台,结合航空发动机试验器原有的软硬件设备,设计开发了一套数据监测分析功能模块。主要阐述了数据监测分析功能设计中的设计思路和主要功能,以及…...

快速上手:前后端分离开发(Vue+Element+Spring Boot+MyBatis+MySQL)
文章目录 前言项目简介环境准备第一步:初始化前端项目登录页面任务管理页面 第二步:初始化后端项目数据库配置数据库表结构实体类和Mapper服务层和控制器 第三步:连接前后端总结 🎉欢迎来到架构设计专栏~探索Java中的静态变量与实…...
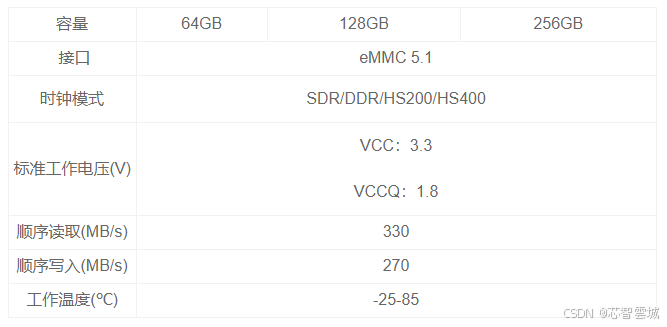
产品推荐| 长江存储eMMC嵌入式储存 YMTC EC230
产品详情 EC230是基于长江存储晶栈Xtacking3.0三维闪存架构打造的新一代eMMC 5.1嵌入式存储产品。EC230的最大顺序读取速度达330MB/s,支持动态SLC缓存,为终端设备提供稳定高性能;支持自动后台/自动节能等操作,减少设备延迟&#…...

【Linux】IP地址与主机名
文章目录 1.IP地址2.特殊IP地址3.主机名4.域名解析 1.IP地址 每一台联网的电脑都会有一个地址,用于和其它计算机进行通讯 IP地址主要有2个版本,V4版本和V6版本 IPv4版本的地址格式是:a.b.c.d,其中abcd表示0~255的数字,如192.168.…...

ros2--colcon
colcon ros2的编译工具,用于编译ros2项目; 需要在工作空间,也就是src上一级目录colcon build; 很明显colcon作为构建工具,通过调用CMake、Python setuptools完成构建。 小鱼文档 构建参数 --packages-select 仅构…...

PyCharm 2023.3.2 关闭时一直显示正在关闭项目
文章目录 一、问题描述二、问题原因三、解决方法 一、问题描述 PyCharm 2023.3.2 关闭时一直显示正在关闭项目 二、问题原因 因为PyCharm还没有加载完索引导致的 三、解决方法 方法一: 先使用任务管理器强制关闭,下次关闭时注意要等待PyCharm加载完索…...

VS2022 git拉取/推送代码错误
第一步:打开VS2022 第二步:工具->选项->源代码管理->Git 全局设置 第三步:加密网络提供程序设置为:OpenSSL 完结:...

【Vue】vue3中使用swipe竖直方向上滚动
安装 npm install swipe使用 import swiper/css; import swiper/css/mousewheel; import { Swiper, SwiperSlide } from swiper/vue; import { Mousewheel } from swiper/modules;containerHeight 是容器的高度,一定要设置竖直方向上滚动高度,不然会非…...

搭建基于 ChatGPT 的问答系统
搭建基于 ChatGPT 的问答系统 📣1.简介📣2.模型,范式和 token📣3.检查输入-分类📣4.检查输入-监督📣5.思维链推理📣6.提示链📣7.检查输入📣8.评估(端到端系统…...

C++运行时类型识别
目录 C运行时类型识别A.What(什么是运行时类型识别RTTI)B.Why(为什么需要RTTI)C.dynamic_cast运算符Why(dynamic_cast运算符的作用)How(如何使用dynamic_cast运算符) D.typeid运算符…...

在微信上怎么制作一个商城链接
在这个快节奏的时代,每一分每一秒都显得尤为珍贵。随着移动互联网的飞速发展,我们的生活方式正经历着前所未有的变革,其中,微信作为国民级社交应用,早已超越了简单的聊天功能,成为了集社交、支付、生活服务…...

怎么搭建微信商城
在当今这个数字化时代,微信已成为人们日常生活中不可或缺的一部分,它不仅改变了我们的社交方式,更引领了商业营销的新潮流。微信商城作为微信生态内的一个重要组成部分,正以其独特的优势助力商家们实现线上销售的突破。本文将带您…...

【每日一练】python的类.对象.成员.行为.方法传参综合实例(保姆式教学)
运行结果: 本节课程内容:类的使用 1.掌握类的定义和使用方法 2.掌握类的成员的方法使用 3.掌握self关键字的作用 4.定义在类里的函数是类的一种行为,叫方法 5.带传参的行为使用方法 类基本分两部分组成:1.属性,2.方法 类的使用语法…...

Windows 如何打开表情符号面板并使用?
打开面板的方法 想要打开表情符号面板其实非常简单,只需要使用快捷键“Win.”或者“Win;”即可。按下快捷键之后就可以调用出表情符号键盘。 在面板中我们可以看见顶部的三个选项,分别是表情符号、颜文字和符号,表情符号就是上面…...

编程语言里的双斜杠:深入解析其神秘面纱
编程语言里的双斜杠:深入解析其神秘面纱 在编程语言的广阔天地中,双斜杠(//)这一看似简单的符号,实则蕴含着丰富的内涵和用途。它既是注释的标识,又是特定语法结构的组成部分,甚至在某些情况下…...
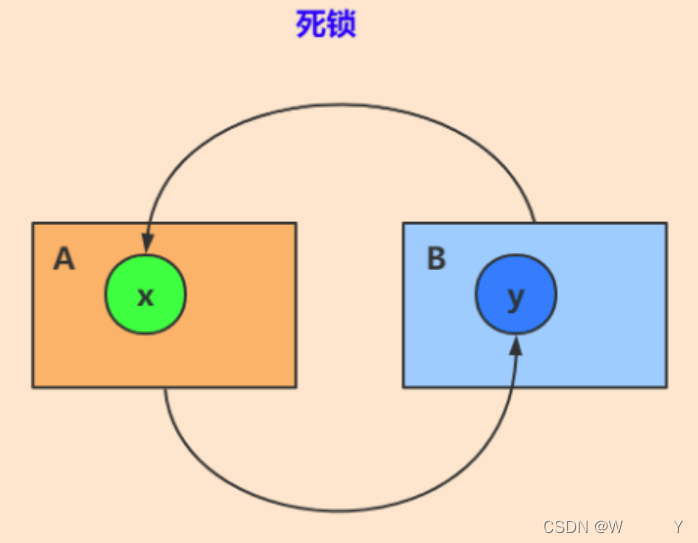
【架构-20】死锁
什么是死锁? 死锁(Deadlock)是指两个或多个线程/进程在执行过程中,由于资源的互相占用和等待,而陷入一种互相等待的僵局,无法继续往下执行的情况。 产生死锁的四个必要条件: (1)互斥条件(Mutual Exclusion):至少有一个资源是非共享…...

Chat2DB:AI引领下的全链路数据库管理新纪元
一、引言 随着数据驱动决策成为现代企业和组织的核心竞争力,数据库管理工具的重要性日益凸显。然而,传统的数据库管理工具往往存在操作复杂、功能单一、不支持多类型数据库管理等问题,限制了数据的有效利用。为了打破这一局面,Ch…...

数据库的学习(5)
题目: 1、新增员工表emp和部门表dept create table dept (deptl int,dept name varchar(11)) charsetutf8; create table emp (sid int,name varchar(11),age int,worktime start date,incoming int,dept2 int) charsetutf8; insert into dept values (101,财务), (…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...