2023-03-15 ElasticSearch
ElasticSearch
1.Docker安装ElasticSearch
1.1. es及kibana下载
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
创建映射文件:
mkdir -p /elasticsearch/configmkdir -p /elasticsearch/datamkdir -p /elasticsearch/plugins
在config下执行 vim elasticsearch.yml
network.host: 0.0.0.0
elasticsearch.yml配置文件
1.1、cluster.name: elasticsearch
配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
1.2、node.name:"Franz Kafka"
节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。
1.3、node.master: true
指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
1.4、node.data: true
指定该节点是否存储索引数据,默认为true。
1.5、index.number_of_shards: 5
设置默认索引分片个数,默认为5片。
1.6、index.number_of_replicas: 1
设置默认索引副本个数,默认为1个副本。
1.7、path.conf: /path/to/conf
设置配置文件的存储路径,默认是es根目录下的config文件夹。
1.8、path.data: /path/to/data
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:path.data: /path/to/data1,/path/to/data2
1.9、path.work: /path/to/work
设置临时文件的存储路径,默认是es根目录下的work文件夹。
1.10、path.logs: /path/to/logs
设置日志文件的存储路径,默认是es根目录下的logs文件夹
1.11、path.plugins: /path/to/plugins
设置插件的存放路径,默认是es根目录下的plugins文件夹
1.12、bootstrap.mlockall: true
设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和 ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过ulimit -l unlimited命令。
1.13、network.bind_host: 192.168.0.1
设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
1.14、network.publish_host: 192.168.0.1
设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
1.15、network.host: 192.168.0.1
这个参数是用来同时设置bind_host和publish_host上面两个参数。
1.16、transport.tcp.port: 9300
设置节点间交互的tcp端口,默认是9300。
1.17、transport.tcp.compress: true
设置是否压缩tcp传输时的数据,默认为false,不压缩。
1.18、http.port: 9200
设置对外服务的http端口,默认为9200。
1.19、http.max_content_length: 100mb
设置内容的最大容量,默认100mb
1.20、http.enabled: false
是否使用http协议对外提供服务,默认为true,开启。
1.21、gateway.type: local
gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,Hadoop的HDFS,和amazon的s3服务器。
1.22、gateway.recover_after_nodes: 1
设置集群中N个节点启动时进行数据恢复,默认为1。
1.23、gateway.recover_after_time: 5m
设置初始化数据恢复进程的超时时间,默认是5分钟。
1.24、gateway.expected_nodes: 2
设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。
1.25、cluster.routing.allocation.node_initial_primaries_recoveries: 4
初始化数据恢复时,并发恢复线程的个数,默认为4。
1.26、cluster.routing.allocation.node_concurrent_recoveries: 2
添加删除节点或负载均衡时并发恢复线程的个数,默认为4。
1.27、indices.recovery.max_size_per_sec: 0
设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。
1.28、indices.recovery.concurrent_streams: 5
设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
1.29、discovery.zen.minimum_master_nodes: 1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
1.30、discovery.zen.ping.timeout: 3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
1.31、discovery.zen.ping.multicast.enabled: false
设置是否打开多播发现节点,默认是true。
1.32、discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
下面是一些查询时的慢日志参数设置
index.search.slowlog.level: TRACE
index.search.slowlog.threshold.query.warn: 10s
index.search.slowlog.threshold.query.info: 5s
index.search.slowlog.threshold.query.debug: 2s
index.search.slowlog.threshold.query.trace: 500ms
index.search.slowlog.threshold.fetch.warn: 1s
index.search.slowlog.threshold.fetch.info: 800ms
index.search.slowlog.threshold.fetch.debug:500ms
index.search.slowlog.threshold.fetch.trace: 200ms2.ES启动
docker run --name es -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms128m -Xmx512m" \
-v /dockerData/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /dockerData/elasticsearch/data:/usr/share/elasticsearch/data \
-v /dockerData/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
network.host: 0.0.0.0
Kibana启动
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.25.100:9200 -p 5601:5601 -d kibana:7.4.2
docker start es
docker start kibana
# 如果没有nginx,启动时会自动下载
docker exec -it es /bin/bash
docker run -p 80:80 --name nginx -d nginx:latest
# 将docker容器内部文件拷贝到宿主机
docker container cp nginx:/etc/nginx .
3.9200端口ES查看节点信息
_cat/_cat/nodes 查看所有节点信息/_cat/health 节点健康状况/_cat/master 主节点信息/_cat/indices 查看所有索引
4.索引文档
4.1.put方式发送
PUT news/_doc/1
{"username":"zhangsan","age":10
}
执行结果:
{"_index" : "news","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
4.2.post方式发送
POST news/_doc/2
{"username":"lisi","age":19
}
结果
{"_index" : "news","_type" : "_doc","_id" : "2","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1
}
4.3.查看文档
GET news/_doc/2
结果:
{"_index" : "news","_type" : "_doc","_id" : "2","_version" : 1,"_seq_no" : 1,"_primary_term" : 1,"found" : true,"_source" : {"username" : "lisi","age" : 19}
}
4.4.更新文档
POST news/_doc/1/_update
{"doc":{"username":"aaa"}
}
结果:
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead.
{"_index" : "news","_type" : "_doc","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1
}
使用_update更新文档必须携带doc.
post的_update会有检查功能,如果执行的语句与数据没有变化时是不会更新数据而且任何版本号也不会更新.
4.5.删除文档&索引
删除文档语法:
结果:
删除索引语法:
执行结果:
4.6.批量添加数据_bulk
PUT news/_doc/_bulk
{"index":{"_id":1}}
{"username":"zhangsan1"}
{"address":"Beijing"}
{"index":{"_id":2}}
{"username":"lisi"}
{"index":{"_id":3}}
{"username":"wangwu"}
结果:
{"took" : 6,"errors" : false,"items" : [{"index" : {"_index" : "news","_type" : "_doc","_id" : "1","_version" : 7,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 8,"_primary_term" : 1,"status" : 200}},{"index" : {"_index" : "news","_type" : "_doc","_id" : "2","_version" : 3,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 9,"_primary_term" : 1,"status" : 200}},{"index" : {"_index" : "news","_type" : "_doc","_id" : "3","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 10,"_primary_term" : 1,"status" : 201}}]
}
5.进阶数据检索
5.1.url 检索数据语法
GET bank/_search?q=*&sort=account_number:asc
5.2.Query DLS(查询领域对象语言)
GET bank/_search
{"query": {"match_all": {}}
}
1.查询全部数据并排序
GET bank/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}]
}
2.查询全部数据排序并分页
GET bank/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}],"from": 0,"size": 50
}
3.区间查询
GET bank/_search
{"query": {"range": {"age": {"gte": 10,"lte": 20}}}
}
4.全文检索 match
match会针对text内容进行分词检索
GET bank/_search
{"query": {"match": {"address": "mill"}}
}
5.短语匹配 match_phrase
GET bank/_search
{"query": {"match_phrase": {"address": "mill lane"}}
}
6.multi_match 多字段匹配
要查询的内容为mill 可以设置某几个字段是否包含该值
GET /bank/_search
{"query": {"multi_match": {"query": "mill","fields": ["email","address","city"]}}
}
7.bool复合查询 多个条件进行匹配查询
must是必须满足
must_not必须不满足
GET bank/_search
{"query": {"bool": {"must": [{"match": {"address": "mill"}},{"match": {"gender": "M"}}],"must_not": [{"match": {"state": "KY"}}]}}
}
should 条件可以满足也可以不满足,在查询中如果有满足should的条件就会增加相关性得分.
GET bank/_search
{"query": {"bool": {"must": [{"match": {"address": "mill"}},{"match": {"gender": "M"}}],"must_not": [{"match": {"state": "KY"}}],"should": [{"match": {"state": "IL"}}]}}
}
8.filter结果过滤
区间查询:
GET /bank/_search
{"query": {"bool": {"must": [{"range": {"age": {"gte": 10,"lte": 50}}}]}},"from": 0,"size":44
}
GET /bank/_search
{"query": {"bool": {"filter": {"range": {"age": {"gte": 10,"lte": 50}}}}}
}
9.term 非全文检索
对于数字型的值推荐使用term,但是如果是text进行分词检索的内容不要使用term,当使用term中进行文本内容的全量检索时term不会检索任何内容
查询内容只是为数字时 推荐使用term 进行检索 ,但是 text文本内容进行检索时不要使用term
GET /bank/_search
{"query": {"term": {"age": {"value": "40"}}}
}
//当检索的内容非数字的类型时:不会检索到任何结果
GET /bank/_search
{"query": {"term": {"address": {"value": "990 Mill Road"}}}
}
6.Mapping
查看该索引下的字段映射类型
GET bank/_mapping
在ES中会根据数据自动猜测属性的类型(mapping)
同时可以在创建索引时手动的去维护创建映射的类型,Es如果是自动时 会将一些不需要进行全文检索的字段属性都映射为text
Es会根据索引的内容进行自动推断类型 ,
给索引的数据字段设置类型
当es索引类型后不能更改 映射类型 ,如果需要变更 要新的数据迁移 将原有的index删除掉 在重新导入,
创建新的index设计映射类型 再去将数据进行迁移
6.1.创建索引和字段映射类型
作者来源(精确匹配 keyword)
新闻类型(keyword)
新闻封面图片(不做检索不做索引)
PUT news
{"mappings": {"properties": {"title":{"type": "text"},"author":{"type": "keyword"},"readnum":{"type": "long"}}}
}
在创建映射类型时ES会默认给字段后加入index属性并设置为true,这样就是认为该字段会进行索引也就是能够对该字段进行全文检索,如果一个字段不需进行全文检索就显示的设置为false
6.2.新增映射字段类型
在新增字段映射类型时不能够在原有的语句上继续执行,需要额外编写新的语句
PUT news/_mapping{ "properties":{"admins":{"type":"keyword"}}
}
7.数据迁移
将测试数据bank/account进行设置新的映射类型,将一些不需要全文检索的字段从新设置.
put /newindex{"mappings":{ "properties":{将原来的mapping放进来修改}}
}
数据迁移前先需要创建一个新的索引并且修改映射类型
POST _reindex
{"source": {"index": "bank","type": "account"},"dest": {"index": "newbank"}
}
8.分词
搜索引擎的核心是倒排索引,而倒排索引的基础就是分词。所谓分词可以简单理解为将一个完整的句子切割为一个个单词的过程。在 es 中单词对应英文为 term
实际上 ES 的分词不仅仅发生在文档创建的时候,也发生在搜索的时候
8.1.分词器
ES 中处理分词的部分被称作分词器,英文是Analyzer,它决定了分词的规则。ES 自带了很多默认的分词器,比如Standard、Keyword、Whitespace等等,默认是Standard。当我们在读时或者写时分词时可以指定要使用的分词器
测试hello world 是如何分词的 采用的是 standard 默认分词器
tokenlyzer 分词器
analyzer 分析器
POST _analyze
{"analyzer": "standard", "text": "hello world"
}
8.2.ES中默认分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
查看地址列分词情况:
GET bank/_analyze
{"field": "address","text": "198 mill lane"
}结果:
"tokens" : [{"token" : "198","start_offset" : 0,"end_offset" : 3,"type" : "<NUM>","position" : 0},{"token" : "mill","start_offset" : 4,"end_offset" : 8,"type" : "<ALPHANUM>","position" : 1},{"token" : "lane","start_offset" : 9,"end_offset" : 13,"type" : "<ALPHANUM>","position" : 2}]
}
这些分词器默认都是对英文进行分词,如果是中文就会出现每个汉字进行分词
POST _analyze
{"analyzer": "standard", "text": "xxxx"
}
9.安装IK分词器
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2
docker中挂载ES的插件包中
1.下载后通过文件上传工具将分词器上传到Docker的ES映射挂载目录plugins下
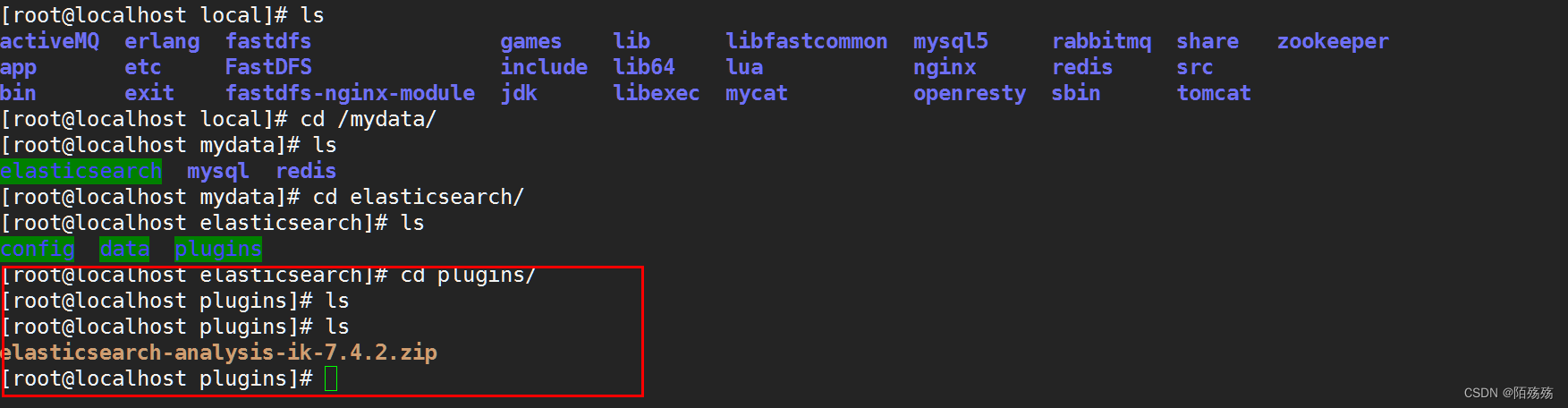
2.解压该文件
yum install -y unziptar gz
unzip elasticsearch-analysis-ik-7.4.2.zip
宿主机内的解压:

进入容器内部查看:
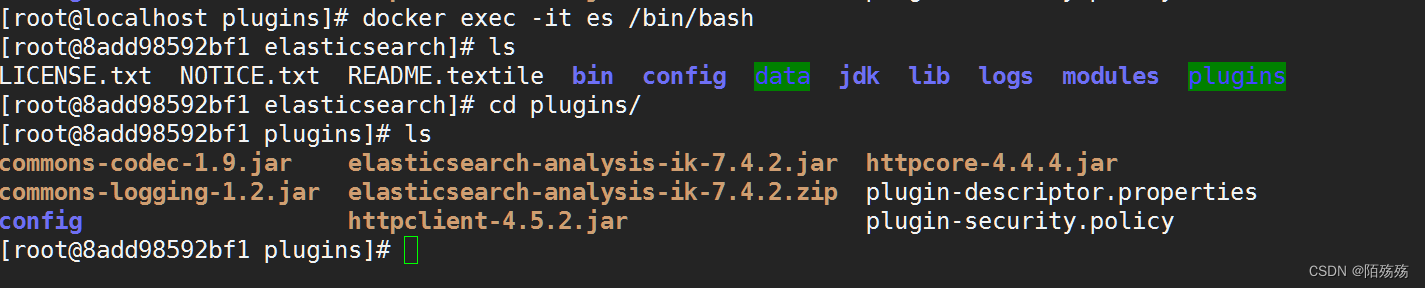
注意:
3.解压后需要在plugins下创建一个ik 的目录将所有文件都移动到ik目录下,不然执行会报异常
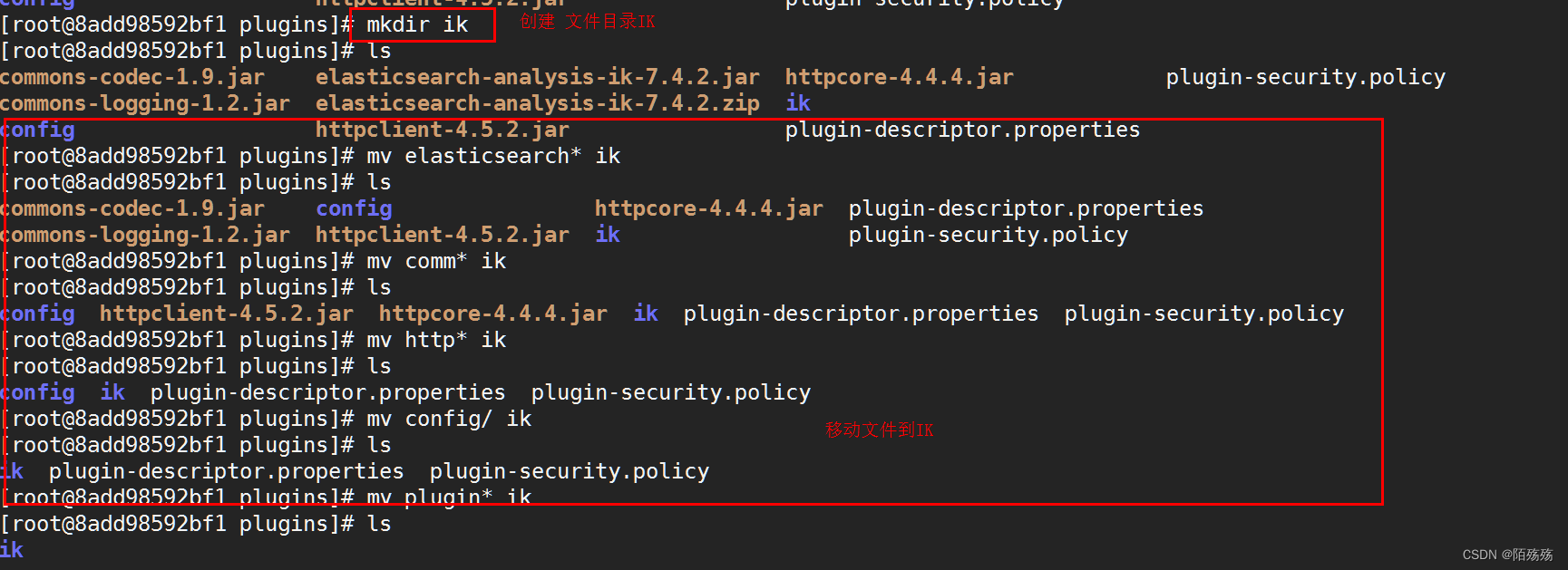
4.执行完成后前往ES的bin路径下通过Es的plugins执行文件查看当前插件是否被启用

5.重启ES与Kibana
9.1.ik_smart分词
ik_smart叫智能分词,会做最粗粒度的拆分
POST _analyze
{"analyzer": "ik_smart", "text": "我是中国人"
}
9.2.ik_max_word
ik_max_word最细粒度拆分
9.3.自定义分词器
1.启动安装nginx容器
启动docker下nginx,启动nginx其实就是为了要里面的配置文件
docker中拉取镜像时 一般情况下 要检索 docker search 镜像资源名称 docker hub上去检索官方镜像
docker pull 镜像名称 拉取镜像到本地 docker run
1.本地中是否有镜像资源 ,如果没有则拉取该镜像
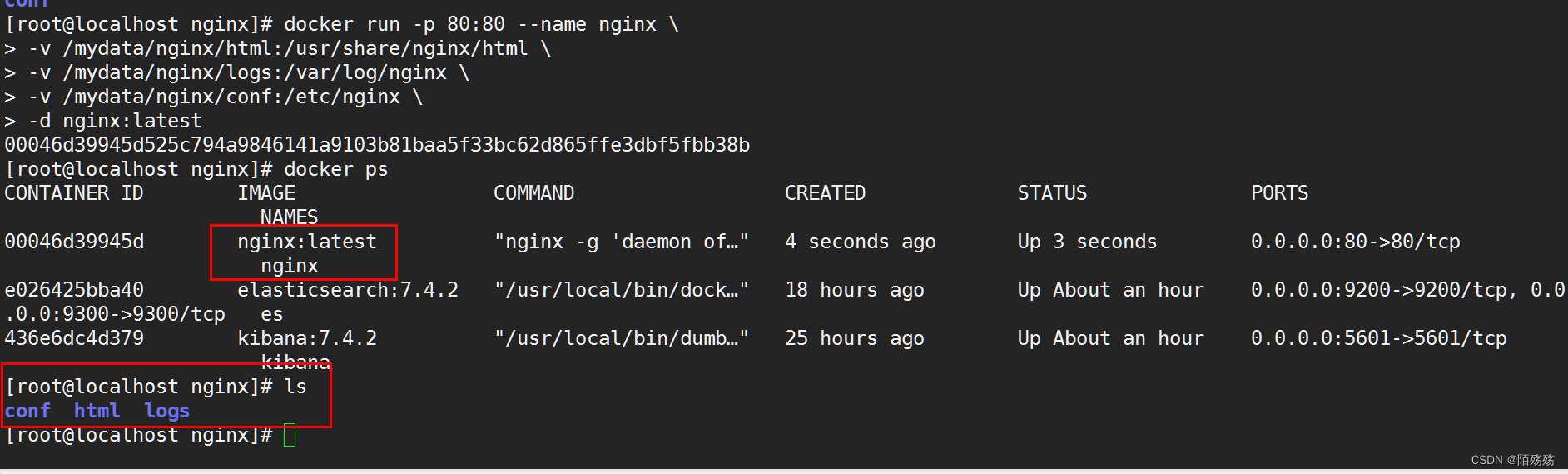
docker run -p 80:80 --name nginx -d nginx:latest
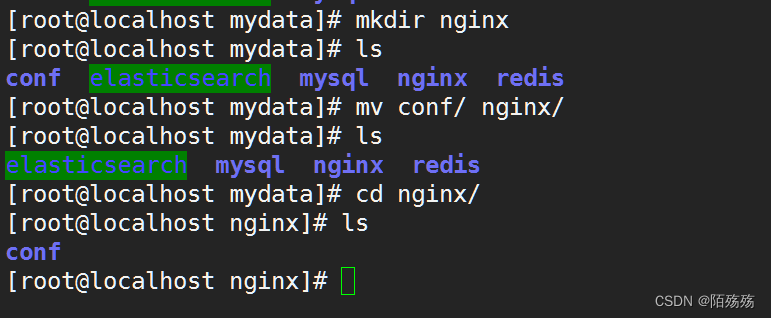
2.创建nginx目录

3.当nginx容器启动后将nginx容器内的文件复制到宿主机中挂载的nginx文件里面
docker container cp nginx:/etc/nginx .
**一定需要注意执行这个命令时是在宿主机挂载的目录下,也就是我们在使用docker时创建的/mydata目录下,需要先创建nginx目录**

4.执行完成后进入nginx 目录查看

5.ngxin -> conf ->文件
复制完文件后就可以停止nginx容器并移除该容器,更改nginx目录名称为conf,然后在创建一个nginx目录将conf/目录移动至nginx目录中.
6.docker stop nginx 停止
7.docker rm nginx 移除
8.创建新的nginx容器并指定挂载目录
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:latest
9.启动完成后进入挂载的nginx目录下html/中创建一个新的文件目录为es然后进入.通过vim创建一个分词文件,录入中文
vim mytokenizer.txt
测试访问,直接通过nginx下的html路径即可
2.修改ik分词配置
1.进入ES挂载的目录找到ik插件位置
cd /mydata/elasticsearch/plugins/ik
2.在这个目录下有个config文件目录进入

3.进入之后编辑修改IkAnalyzer.cfg.xml文件

4.将该文件内容的远程扩展词库打开并编写刚刚测试的地址
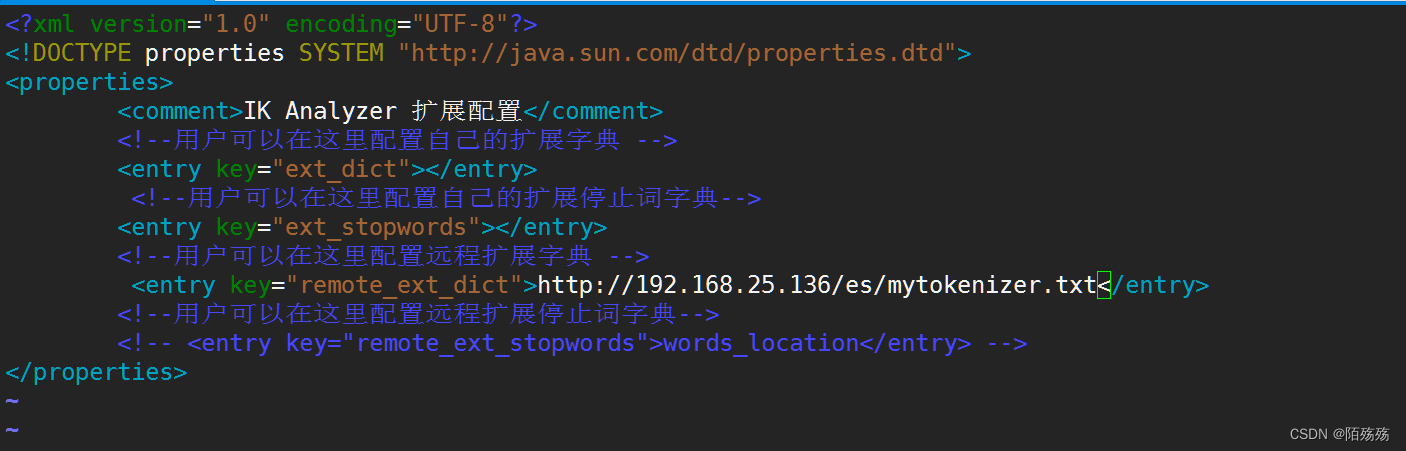
5.更改后保存退出并重启ES测试分词结果
//设置news索引并配置mapping类型与分词策略
PUT news
{"mappings": {"properties": {"title":{"type": "text","analyzer": "ik_max_word"},"category":{"type": "keyword"},"author":{"type": "keyword"},"newsimage":{"type": "keyword","index": false}}}
}
10.springboot集成ElasticSearch
1.使用ElasticSearch-Rest-Client 进行ES操作
http:// 9200
1.创建检索模块导入依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.2</version></dependency>
2.在ES中使用API时还需要额外引入jackson组件包并且版本与父工程不一致需要单独引入
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.8.3</version></dependency><dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-smile</artifactId><version>2.8.3</version></dependency>
3.配置类
@Configuration
public class ElasticSearchConfig {//请求设置项public static final RequestOptions COMMON_OPTIONS;static {//基于默认规则设置RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();COMMON_OPTIONS = builder.build();}@Beanpublic RestHighLevelClient esRestClient(){RestHighLevelClient client=new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.25.100",9200,"http")));return client;}
}4.测试
@Autowiredprivate ElasticSearchConfig elasticSearchConfig;@Testpublic void testEsClient(){System.out.println(elasticSearchConfig.esRestClient());}
5.添加请求默认设置项
//请求设置项public static final RequestOptions COMMON_OPTIONS;static {//基于默认规则设置RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();COMMON_OPTIONS = builder.build();}
1.添加索引数据
@Testpublic void indexTest(){IndexRequest indexRequest=new IndexRequest("users");Users users=new Users(1,"zhangsan","男",new Date());indexRequest.id(users.getId()+"");String json=JSONObject.toJSONString(users);indexRequest.source(json, XContentType.JSON);try {IndexResponse indexResponse=elasticSearchConfig.esRestClient().index(indexRequest,ElasticSearchConfig.COMMON_OPTIONS);System.out.println(indexResponse);} catch (IOException e) {e.printStackTrace();}}
2.检索数据
@Testpublic void searchTest(){//1、创建查询请求,规定查询的索引SearchRequest searchRequest=new SearchRequest();//2.指定索引searchRequest.indices("bank");SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();//3.构建查询条件 searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//指定DSLsearchRequest.source(searchSourceBuilder);try {SearchResponse response = elasticSearchConfig.esRestClient().search(searchRequest, ElasticSearchConfig.COMMON_OPTIONS);System.out.println(response);} catch (IOException e) {e.printStackTrace();}}
3.结果分析中获取数据
@Testpublic void searchTest(){SearchRequest searchRequest=new SearchRequest();//指定索引searchRequest.indices("bank");SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();//构建查询条件searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//指定DSLsearchRequest.source(searchSourceBuilder);try {SearchResponse response = elasticSearchConfig.esRestClient().search(searchRequest, ElasticSearchConfig.COMMON_OPTIONS);//结果分析获取SearchHits hits = response.getHits();SearchHit[] hitsHits = hits.getHits();for (SearchHit hit : hitsHits) {//元信息// hit.getScore() hit.getSeqNo() hit.getShard() hit.getId();//获取数据信息String sourceAsString = hit.getSourceAsString();System.out.println(sourceAsString);}} catch (IOException e) {e.printStackTrace();}}
4.查询结果根据关键字高亮展示
@Testpublic void searchTest(){SearchRequest searchRequest=new SearchRequest();//指定索引searchRequest.indices("bank");SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();//高亮HighlightBuilder highlightBuilder=new HighlightBuilder();highlightBuilder.field("address");highlightBuilder.preTags("<b style='color:red'>"); //高亮设置highlightBuilder.postTags("</b>");searchSourceBuilder.highlighter(highlightBuilder);//构建查询条件searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//指定DSLsearchRequest.source(searchSourceBuilder);try {SearchResponse response = elasticSearchConfig.esRestClient().search(searchRequest, ElasticSearchConfig.COMMON_OPTIONS);//结果分析获取SearchHits hits = response.getHits();SearchHit[] hitsHits = hits.getHits();List<Bank> list=new ArrayList<>();for (SearchHit hit : hitsHits) {String sourceAsString = hit.getSourceAsString();Bank bank=JSONObject.parseObject(sourceAsString,Bank.class);HighlightField highlightField=hit.getHighlightFields().get("address");String highlinghFiled=null;if(highlightField!=null){highlinghFiled=highlightField.getFragments()[0].string();bank.setAddress(highlinghFiled);}list.add(bank);}list.stream().forEach(System.out::println);} catch (IOException e) {e.printStackTrace();}}
//页面中高亮语法
GET /news/_search
{"query": {"match": {"title": "中国"}},"highlight": {"pre_tags": ["<b style='color:red'>"],"post_tags": ["</b>"],"fields": {"title": {}}}
}
2.springboot集成操作
1.pom依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
2.yml配置
spring:data:elasticsearch:client:reactive:connection-timeout: 60000 #连接elasticsearch超时时间endpoints: 192.168.25.100:9300 #连接elasticsearch地址password: ''username: ''cluster-name: data-lakescluster-nodes: 192.168.25.100:9300,192.168.25.100:9301,192.168.25.100:9302repositories:enabled: true #打开elasticsearch仓库,默认trueelasticsearch:rest:uris: http://192.168.25.100:9200
3.查询mapper层接口继承ElasticsearchRepository<x,String>接口
泛型参数,第一个参数是查询到的返回实体对象
4.配置类
@Configuration
public class ElasticsearchConfig {@Beanpublic ElasticsearchTemplate elasticsearchTemplate(Client client) throws UnknownHostException {return new ElasticsearchTemplate(client, new ElasticCustomEntityMapper());}private class ElasticCustomEntityMapper implements EntityMapper {private ObjectMapper mapper;@Autowiredprivate ElasticCustomEntityMapper() {this.mapper = new ObjectMapper();mapper.disable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);mapper.registerModule(new JavaTimeModule());}@Overridepublic String mapToString(Object object) throws IOException {return mapper.writeValueAsString(object);}@Overridepublic <T> T mapToObject(String source, Class<T> clazz) throws IOException {return mapper.readValue(source, clazz);}}
}
5.ElasticsearchRepository接口中的内置方法
<S extends T> S index(S entity);Iterable<T> search(QueryBuilder query);Page<T> search(QueryBuilder query, Pageable pageable);Page<T> search(SearchQuery searchQuery);Page<T> searchSimilar(T entity, String[] fields, Pageable pageable);void refresh();Class<T> getEntityClass();
分别对es的基本查询操作
6.使用时只需注入mapper,调用继承的方法即可
7.也可直接注入
@Resource
private ElasticsearchTemplate elasticsearchTemplate;
8.返回实体对应注解
@Document(indexName ="new",type = "doc",useServerConfiguration = true,createIndex = false)
@Id
@Field(type = FieldType.Keyword)
可选字段
public enum FieldType {Text,Integer,Long,Date,Float,Double,Boolean,Object,Auto,Nested,Ip,Attachment,Keyword
}
@GeoPointField //地理位置类型字段
private GeoPoint location;
@Field(index = false) //不查找的字段
@Field(type = FieldType.Text,analyzer = "ik_max_word")//指定分词器
相关文章:
2023-03-15 ElasticSearch
ElasticSearch 1.Docker安装ElasticSearch 1.1. es及kibana下载 docker pull elasticsearch:7.4.2 docker pull kibana:7.4.2创建映射文件: mkdir -p /elasticsearch/configmkdir -p /elasticsearch/datamkdir -p /elasticsearch/plugins在config下执行 vim elasticsearch…...

指针和数组笔试题解析【下篇】
文章目录👁️6.指针笔试题👀6.1.试题(1)👀6.2.试题(2)👀6.3.试题(3)👀6.4.试题(4)👀6.5.试题(5&am…...
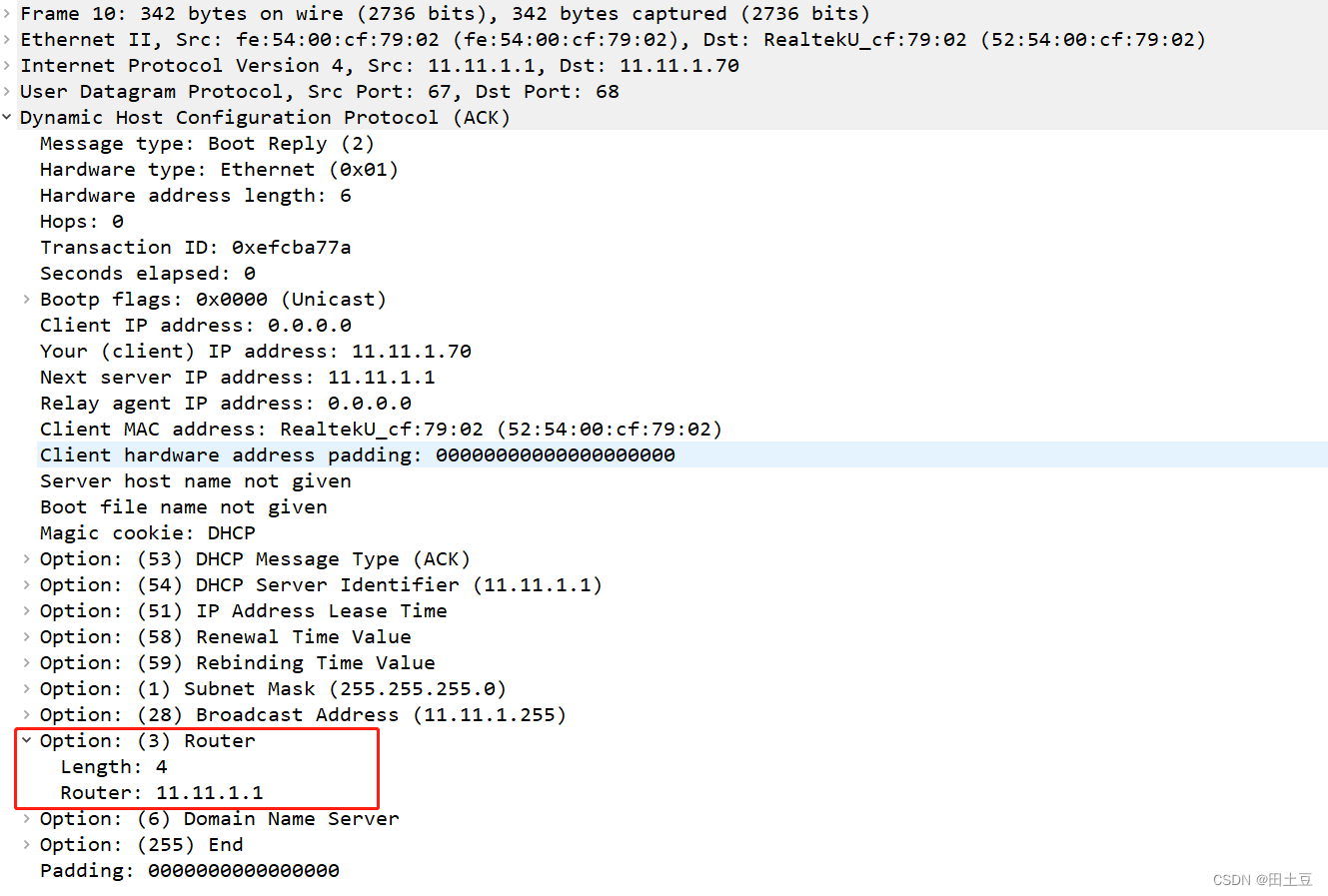
DHCP原理简析及交互实践
环境: os:centos7 dnsmasq:version 2.76 一. dhcp工作原理 首先补充几个dhcp相关的基本概念: 1、动态主机配置协议DHCP(Dynamic Host Configuration Protocol)是一种网络管理协议,用于集中对用…...
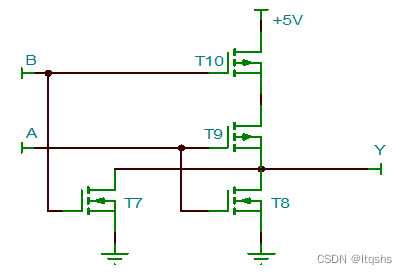
用二极管、三极管和MOS管搭建逻辑门电路
文章目录1. 二极管(1)二极管与门(2)二极管或门2. 三极管(1)三极管非门(2)三极管与门(3)三极管或门(4)三极管与非门(5&…...
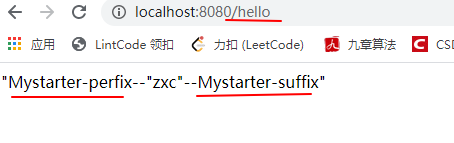
SpringBoot:手写一个 SpringBoot Starter
声明:原文作者:yuan_404 文章目录1. 说明2 . 编写启动器3 . 新建项目测试自己写的启动器1. 说明 启动器模块是一个 空 jar 文件,仅提供辅助性依赖管理,这些依赖可能用于自动装配或者其他类库 命名归约: 官方命名&…...
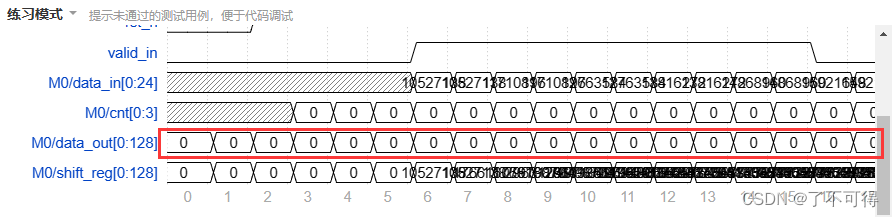
【23】Verilog进阶 - 数位转换【实时处理 + 标志信号】
【初次尝试】VL32 非整数倍数据位宽转换24to128 1 理解题目含义 根据【模块端口】和【题目描述】本题的真实意思是比较清楚啦。但不可大意轻敌! (1)问题1:输出一直为0 猛然间发现计数值也为0,没有增加 去排查cnt的代码,很容易找到到问题,是cnt上电复位的逻辑写错了 …...

常见的HTTP状态码
一.2开头 200:响应成功; 204:响应成功,但是响应头没有数据; 206:部分响应成功,比如分片上传,断点续传; 二.3开头 301:永久重定向; 302&…...

D. Peculiar Movie Preferences(思维 + 一个坑)
Problem - D - Codeforces 米海打算去看电影。他只喜欢回文电影,所以他想跳过一些(可能是零)场景,让电影的其余部分变成回文。给你一个包含n个长度不超过3的非空字符串的列表,代表Mihai的电影场景。如果s的子序列非空,并且子序列中…...
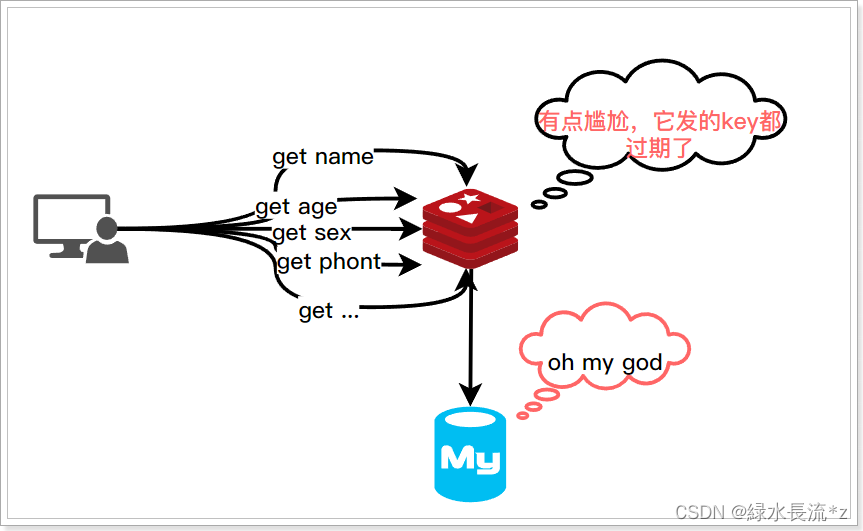
真1分钟搞懂缓存穿透、缓存击穿、缓存雪崩
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...
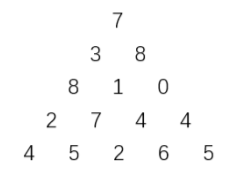
蓝桥刷题总结1
数组三角形 题目描述 上图给出了一个数字三角形。从三角形的顶部到底部有很多条不同的路径。对于每条路径,把路径上面的数加起来可以得到一个和,你的任务就是找到最大的和。 路径上的每一步只能从一个数走到下一层和它最近的左边的那个数或者右 边的那个…...

淘宝商品详情数据接口 关键字搜索接口 请求代码分享
item_get-获得淘宝商品详情item_get_app-获得淘宝app商品详情原数据item_search-按关键字搜索淘宝商品参数说明通用参数说明参数不要乱传,否则不管成功失败都会扣费url说明 https://api-gw.onebound.cn/平台/API类型/ 平台:淘宝,京东等&#…...

【数据结构】链表OJ(二)
Yan-英杰的博客 悟已往之不谏 知来者之可追 目录 一、反转链表 二、合并两个有序链表 三、链表分割 四、链表的回文结构 一、反转链表 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1] 输入:head [1,2] 输出:[2,1] 示例 3…...

Linux系统搭建FTP服务器
安装vsftpdyum -y install vsftpd添加FTP用户方式1、添加只允许通过ftp访问的用户useradd -d /home/ftp ftp_user #-d指定用户登录时的启始目录方式2、允许用户登录操作系统usermod -d /home/ftp -s /bin/bash ftp_user #-s指定用户登入后所使用的shell设置用户登录密码passwd …...

MySQL数据同步到 Redis 缓存的几种方法
1 Mysql查完数据,再同步写入到Redis中缺点1:会对接口造成延迟,因为同步写入redis本身就有延迟,并且还要做重试,如果redis写入失败,还需要重试,那就更费时间了。缺点2:不解耦…...
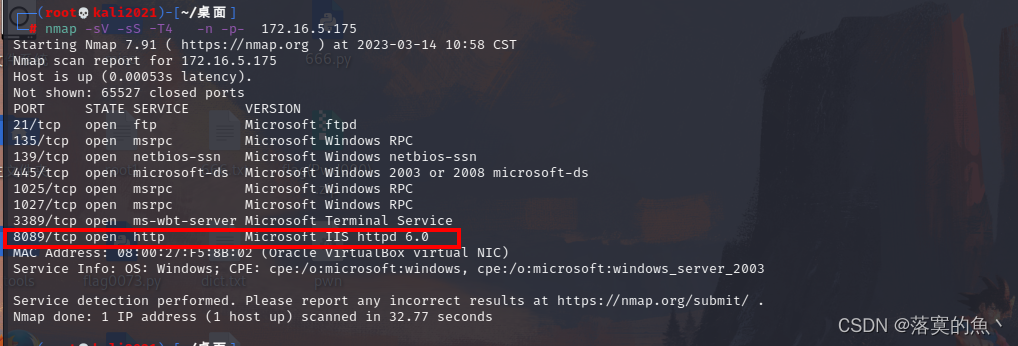
2023年网络安全比赛--CMS网站渗透中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.使用渗透机对服务器信息收集,并将服务器中网站服务端口号作为flag提交; 2.使用渗透机对服务器信息收集,将网站的名称作为flag提交; 3.使用渗透机对服务器渗透,将可渗透页面的名称作为flag提交; 4.使用渗透机对服务器渗透,…...

【蓝桥杯集训·每日一题】AcWing 4309. 消灭老鼠
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴最大公约数一、题目 1、原题链接 4309. 消灭老鼠 2、题目描述 约翰的农场可以看作一个二维平面。 农场中有 n 个老鼠,在毁坏着农田。 第 i 个老鼠的位置坐标为…...

FPGA实现CSI-2 解码MIPI视频 2line 720P分辨率 OV5647采集 提供工程源码和技术支持
目录1、前言2、Xilinx官方主推的MIPI解码方案3、纯Vhdl方案解码MIPI4、vivado工程介绍5、上板调试验证6、福利:工程代码的获取1、前言 FPGA图像采集领域目前协议最复杂、技术难度最高的应该就是MIPI协议了,MIPI解码难度之高,令无数英雄竞折腰…...
)
JS面试题收集(持续更新好中...)
1.JavaScript 中的垃圾回收机制 定义:指一块被分配的内存既不能使用,又不能回收,直到浏览器进程结束。 JavaScript在创建对象时会为它们分配内存,不再使用时会自动释放内存,这个过程称为垃圾收集。 四种常见的内存泄…...

2023携程面试题
Java I/O 面试前需要准备: 1. Java 八股文:了解常考的题型和回答思路; 2. 算法:刷 100-200 道题,记住刷题最重要的是要理解其思想,不要死记硬背,碰上原题很难,但 大多数的解题思…...

CANoe中使用CAPL函数接口调用Vflash文件
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...

CATIA多实体零件自动化拆分:pyCATIA解决复杂几何体管理的技术挑战
CATIA多实体零件自动化拆分:pyCATIA解决复杂几何体管理的技术挑战 【免费下载链接】pycatia python module for CATIA V5 automation 项目地址: https://gitcode.com/gh_mirrors/py/pycatia 在航空航天、汽车制造和复杂机械设计领域,工程师经常面…...

做AI测试,我是怎么从不会到找到方法的
刚开始做AI测试,最大的问题是:不知道从哪里下手。 功能测试还好,有需求文档,有业务逻辑,知道测什么。 但AI产品不一样。模型的输出是概率性的,边界在哪里不清楚,也没有人告诉你哪里容易出问题…...

Python 开发者如何通过 OpenAI 兼容协议快速接入 Taotoken
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者如何通过 OpenAI 兼容协议快速接入 Taotoken 对于使用 Python 的开发者而言,接入多个大模型服务通常意味…...

大疆无人机固件自由下载:5个技巧掌握DankDroneDownloader终极指南 [特殊字符]
大疆无人机固件自由下载:5个技巧掌握DankDroneDownloader终极指南 🚁 【免费下载链接】DankDroneDownloader A Custom Firmware Download Tool for DJI Drones Written in C# 项目地址: https://gitcode.com/gh_mirrors/da/DankDroneDownloader 你…...

SkillLite Channel 与 Gateway 配置完全指南:Webhook、环境变量与桌面助手
摘要:本文说明 SkillLite 如何通过 skilllite channel serve 或 skilllite gateway serve 暴露入站 HTTP(POST /webhook/inbound),以及如何用环境变量 SKILLLITE_CHANNEL_* 将入站内容摘要推送到钉钉、飞书(Lark&#…...
)
手把手教你用Simulink搭建Buck变换器:从元件库搜索到波形分析(MATLAB 2023b)
手把手教你用Simulink搭建Buck变换器:从元件库搜索到波形分析(MATLAB 2023b) 在电力电子领域,Buck变换器作为最基础的DC-DC降压拓扑,其仿真验证是每个工程师的必修课。MATLAB 2023b中的Simulink环境提供了高度可视化的…...
)
从零基础到高薪AI工程师:我的大模型学习路线与转型经验(含收藏必备资源)
从零基础到高薪AI工程师:我的大模型学习路线与转型经验(含收藏必备资源) 本文作者分享从零基础成功转型AI工程师的亲身经历,强调学AI不必死磕算法和公式,企业更看重会用Python搭AI智能体、能用Java迭代项目的实干型人才…...

完全掌握Trainers‘ Legend G:深度解析赛马娘中文本地化插件的5大核心功能
完全掌握Trainers Legend G:深度解析赛马娘中文本地化插件的5大核心功能 【免费下载链接】Trainers-Legend-G 赛马娘本地化插件「Trainers Legend G」 项目地址: https://gitcode.com/gh_mirrors/tr/Trainers-Legend-G Trainers Legend G是一款专为赛马娘Pre…...

从AVR到ARM架构迁移实战:SAMD平台外设编程与性能调优指南
1. 从AVR到ARM:一次架构跃迁的深度解析如果你和我一样,是从Arduino Uno、Nano这类经典的AVR平台一路玩过来的,那么当你第一次拿到一块Adafruit Feather M0或者Arduino Zero时,那种感觉就像是开惯了手动挡的老爷车,突然…...

3个步骤解决OFD转PDF难题:开源工具Ofd2Pdf完全指南
3个步骤解决OFD转PDF难题:开源工具Ofd2Pdf完全指南 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 作为一名财务人员,小张每月都要处理上百份OFD格式的电子发票。这些发票需要…...