2023携程面试题
Java I/O
面试前需要准备:
1. Java 八股文:了解常考的题型和回答思路;
2. 算法:刷 100-200 道题,记住刷题最重要的是要理解其思想,不要死记硬背,碰上原题很难,但
大多数的解题思路是相通的。
3. 项目:主要准备最近一家公司所负责的业务和项目:l 项目的背景,为啥要做这个项目; 系统的演进之路,有哪几个阶段,每个阶段主要做了什么;
项目中的技术选型,在项目中使用一些工具和框架时的调研,为啥选这个;
项目的亮点:就是你在项目中做过最牛逼的事,复杂的需求方案设计、性能优化、线上问题处理、项目重构等等;
4. 架构设计:主要是平台化的一些思想、DDD 领域驱动设计思想,随着经验的增加,这块会越来越
重要。
5. 项目管理:主要是在主导跨团队的项目时,如何高效的协调好各个团队的工作,使用哪些方法来
保障项目的按时交付。在项目遇到困难时,作为项目负责人如何应对等等。跟架构设计一样,这
块也是随着经验的增加越来越重要。
6. 通用问题:几个比较容易被问到的问题是:1)为什么离职;2)在上家公司哪些能力得到了成
长;3)平时怎么学习的?
7. 问面试官:每次面试最后面试官一般会问有没有什么想问的,如果不知道问什么,可以问下团队
当前负责的业务是什么?主要面临的挑战是什么?
1、I/O 流的分类
按照读写的单位大小来分:
字符流:以字符为单位,每次次读入或读出是 16 位数据。其只能读取字符类型数据。
(Java 代码接收数据为一般为 char 数组,也可以是别的)
字节流:以字节为单位,每次次读入或读出是 8 位数据。可以读任何类型数据,图片、文件、音乐视频等。 (Java 代码接收数据只能为 byte 数组)
按照实际 IO 操作来分:
输出流:从内存读出到文件。只能进行写操作。
输入流:从文件读入到内存。只能进行读操作。
注意:输出流可以帮助我们创建文件,而输入流不会。
按照读写时是否直接与硬盘,内存等节点连接分:
节点流:直接与数据源相连,读入或读出。
处理流:也叫包装流,是对一个对于已存在的流的连接进行封装,通过所封装的流的功能调用实现数据读写。如添加个 Buffering 缓冲区。(意思就是有个缓存区,等于软件和mysql 中的 redis)
注意:为什么要有处理流?主要作用是在读入或写出时,对数据进行缓存,以减少 I/O的次数,以便下次更好更快的读写文件,才有了处理流。
2、字节流如何转为字符流?
字节输入流转字符输入流通过 InputStreamReader 实现,该类的构造函数可以传入InputStream 对象。
字节输出流转字符输出流通过 OutputStreamWriter 实现,该类的构造函数可以传入OutputStream 对象。
3、字节流和字符流,你更喜欢使用哪一个?
个人来说,更喜欢使用字符流,因为他们更新一些。许多在字符流中存在的特性,字节流中不存在。比如使用BufferedReder 而不是 BufferedInputStreams 或DataInputStream,使用 newLine()方法来读取下一行,但是在字节流中我们需要做额外的操作。
4、System.out.println 是什么?
println 是 PrintStream 的一个方法。out 是一个静态 PrintStream 类型的成员变量,System 是一个 java.lang 包中的类,用于和底层的操作系统进行交互。
5、什么是 Filter 流?
Filter Stream 是一种 IO 流主要作用是用来对存在的流增加一些额外的功能,像给目标文件增加源文件中不存在的行数,或者增加拷贝的性能。
5、有哪些可用的 Filter 流?
在 java.io 包中主要由 4 个可用的 filter Stream。两个字节 filter stream,两个字符 filterstream. 分别是FilterInputStream, FilterOutputStream, FilterReader and FilterWriter.这些类是抽象类,不能被实例化的。
6、有哪些 Filter 流的子类?
LineNumberInputStream 给目标文件增加行号
DataInputStream 有些特殊的方法如 readInt(), readDouble()和 readLine() 等可以读取一个 int, double 和一个 string一次性的,l BufferedInputStream 增加性能 PushbackInputStream 推送要求的字节到系统中
7、NIO 和 I/O 的主要区别
面向流与面向缓冲
Java IO 和 NIO 之间第一个最大的区别是,IO 是面向流的,NIO 是面向缓冲区的。
Java IO 面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO 的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
阻塞与非阻塞 IO
Java IO 的各种流是阻塞的。这意味着,当一个线程调用 read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO 的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。线程通常将非阻塞 IO 的空闲时间用于在其它通道上执行 IO 操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
选择器(Selectors)
Java NIO 的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
NIO 提供了与标准 IO 不同的 IO 工作方式:Channels and Buffers(通道和缓冲区):标准的 IO 基于字节流和字符流进行操作的,而 NIO 是基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
Asynchronous IO(异步 IO):Java NIO 可以让你异步的使用 IO,例如:当线程从通道读取数据到缓冲区时,线程还是可以进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。
Selectors(选择器):Java NIO 引入了选择器的概念,选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。
8、BIO、NIO、AIO 有什么区别?
BIO (Blocking I/O):同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机 1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO (New I/O): NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO框架,对应 java.nio 包,提供了Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。NIO提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应 de 的 SocketChannel 和ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。
阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步 IO 的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO 操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty之前也尝试使用过 AIO,不过又放弃了。
9、NIO 有哪些核心组件?
Channel Buffer Selector
Channel 和流有点类似。通过 Channel,我们即可以从 Channel 把数据写到 Buffer中,也可以把数据冲 Buffer 写入到 Channel,每个 Channel 对应一个 Buffer 缓冲区,Channel 会注册到 Selector。Selector 根据 Channel 上发生的读写事件,将请求交由某个空闲的线程处理,Selector 对应一个或多个线程,Channnel 和 Buffer 是可读可写的。
10、select、poll 和 epoll 什么区别
它们是 NIO 多路复用的三种实现机制,是有 Linux 系统提供。
select:无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作,会维护一个文件描述符 FD 的集合 fd_set,将 fd_set 从用户空间复制到内核空间。x86fd_set 是数组结构 poll:与 select 机制相似,fd_set 结构进行优化,突破操作系统限制,pollfd 代替fd_set,链表结构l epoll:不再扫描所以 fd,只将用户关心的事件放在内核的一个事件表中,减少用户空间和内核空间的数据拷贝。epoll 可以理解为 event poll,不同于忙轮询和无差别轮询,epoll 会把哪个流发生了怎样的 I/O 事件通知我们。
11、什么是 Java 序列化,如何实现 Java 序列化?
序列化就是一种用来处理对象流的机制,将对象的内容进行流化。可以对流化后的对象进行读写操作,可以将流化后的对象传输于网络之间。
序列化是为了解决在对象流读写操作时所引发的问题 序列化的实现:将需要被序列化的类实现 Serialize 接口,没有需要实现的方法,此接口只是为了标注对象可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个 ObjectOutputStream(对象流)对象,再使用 ObjectOutputStream 对象的 write(Object obj)方法就可以将参数 obj的对象写出。
12、如何实现对象克隆?
有两种方式:
1. 实现 Cloneable 接口并重写 Object 类中的 clone()方法;
2. 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
13、什么是缓冲区?有什么作用?
缓冲区就是一段特殊的内存区域,很多情况下当程序需要频繁地操作一个资源(如文件或数据库)则性能会很低,所以为了提升性能就可以将一部分数据暂时读写到缓存区,以后直接从此区域中读写数据即可,这样就可以显著的提升性能。
对于 Java 字符流的操作都是在缓冲区操作的,所以如果我们想在字符流操作中主动将缓冲区刷新到文件则可以使用flush() 方法操作。
14、什么是阻塞 IO?什么是非阻塞 IO?
IO 操作包括:对硬盘的读写、对 socket 的读写以及外设的读写。
当用户线程发起一个 IO 请求操作(本文以读请求操作为例),内核会去查看要读取的数据是否就绪,对于阻塞 IO 来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;对于非阻塞 IO 来说,如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的 IO 读请求操作,也就是说一个完整的 IO 读请求操作包括两个阶段:
查看数据是否就绪;
进行数据拷贝(内核将数据拷贝到用户线程)。
那么阻塞(blocking IO)和非阻塞(non-blocking IO)的区别就在于第一个阶段,如果数据没有就绪,在查看数据是否就绪的过程中是一直等待,还是直接返回一个标志信息。
Java 中传统的 IO 都是阻塞 IO,比如通过 socket 来读数据,调用 read()方法之后,如果数据没有就绪,当前线程就会一直阻塞在 read 方法调用那里,直到有数据才返回;而如果是非阻塞 IO 的话,当数据没有就绪,read()方法应该返回一个标志信息,告知当前线程数据没有就绪,而不是一直在那里等待。
15、请说一下 PrintStream BufferedWriter PrintWriter 有什么不同?
PrintStream 类的输出功能非常强大,通常如果需要输出文本内容,都应该将输出流包装成 PrintStream 后进行输出。它还提供其他两项功能。与其他输出流不同,PrintStream 永远不会抛出 IOException;而是,异常情况仅设置可通过checkError 方法测试的内部标志。
另外,为了自动刷新,可以创建一个 PrintStreamBufferedWriter:将文本写入字符输出流,缓冲各个字符从而提供单个字符,数组和字符串的高效写入。通过 write()方法可以将获取到的字符输出,然后通过 newLine()进行换行操作。BufferedWriter 中的字符流必须通过调用 flush 方法才能将其刷出去。并且BufferedWriter 只能对字符流进行操作。如果要对字节流操作,则使用BufferedInputStream。
PrintWriter 的 println 方法自动添加换行,不会抛异常,若关心异常,需要调用checkError 方法看是否有异常发生,PrintWriter 构造方法可指定参数,实现自动刷新缓存(autoflush)。
-
Kafka
1、Kafka 是什么?主要应用场景有哪些?
Kafka 是一个分布式流式处理平台。
流平台具有三个关键功能:
消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
容错的持久方式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
Kafka 主要有两大应用场景:
消息队列 :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
数据处理: 构建实时的流数据处理程序来转换或处理数据流。
2、和其他消息队列相比,Kafka 的优势在哪里?
我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它跟 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下: 极致的性能 :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
生态系统兼容性无可匹敌 :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
实际上在早期的时候 Kafka 并不是一个合格的消息队列,早期的 Kafka 在消息队列领域就像是一个衣衫褴褛的孩子一样,功能不完备并且有一些小问题比如丢失消息、不保证消息可靠性等等。当然,这也和 LinkedIn 最早开发 Kafka 用于处理海量的日志有很大关系,哈哈哈,人家本来最开始就不是为了作为消息队列滴,谁知道后面误打误撞在消息队列领域占据了一席之地。
3、什么是 Producer、Consumer、Broker、Topic、Partition?
Kafka 将生产者发布的消息发送到 Topic(主题) 中,需要这些消息的消费者可以订阅这些 Topic(主题)。Kafka 比较重要的几个概念:
Producer(生产者) : 产生消息的一方。
Consumer(消费者) : 消费消息的一方。
Broker(代理) : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个Kafka Cluster。
Topic(主题) : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的Topic(主题) 来消费消息。
Partition(分区) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。这正如我上面所画的图一样。
4、Kafka 的多副本机制了解吗?
Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader的家伙,其他副本称为 follower。我们发送的消息会被发送到leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。当 leader 副本发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选。
5、Kafka 的多分区(Partition)以及多副本(Replica)机制有什么好处呢?
Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker上, 这样便能提供比较好的并发能力(负载均衡)。
Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
6、Zookeeper 在 Kafka 中的作用知道吗?
l Broker 注册 :在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 /brokers/ids 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去l Topic 注册 : 在 Kafka 中,同一个 Topic 的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这93些文件夹:/brokers/topics/my-topic/Partitions/0、/brokers/topics/mytopic/Partitions/1
负载均衡 :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition可以分布在不同的 Broker上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
7、Kafka 如何保证消息的消费顺序?
我们在使用消息队列的过程中经常有业务场景需要严格保证消息的消费顺序,比如我们同时发了 2 个消息,这 2 个消息对应的操作分别对应的数据库操作是:
更改用户会员等级。
根据会员等级计算订单价格。
假如这两条消息的消费顺序不一样造成的最终结果就会截然不同。
Kafka 中 Partition(分区)是真正保存消息的地方,我们发送的消息都被放在了这里。而我们的 Partition(分区) 又存在于 Topic(主题) 这个概念中,并且我们可以给特定 Topic 指定多个 Partition。
每次添加消息到 Partition(分区) 的时候都会采用尾加法,如上图所示。 Kafka 只能为我们保证 Partition(分区) 中的消息有序。
消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。Kafka 通过偏
移量(offset)来保证消息在分区内的顺序性。
所以,我们就有一种很简单的保证消息消费顺序的方法:1 个 Topic 只对应一个Partition。这样当然可以解决问题,但是破坏了 Kafka 的设计初衷。
Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了Partition 的话,所有消息都会被发送到指定的 Partition。
并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id来作为 key
总结一下,对于如何保证 Kafka 中消息消费的顺序,有了下面两种方法:
1 个 Topic 只对应一个 Partition。
发送消息的时候指定 key/Partition。
8、Kafka 如何保证消息不丢失?
生产者丢失消息的情况
生产者(Producer) 调用 send 方法发送消息之后,消息可能因为网络问题并没有发送过去。所以,我们不能默认在调用 send 方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果,但是这样也让它变为了同步操作 。
消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。
偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
9、Kafka 判断一个节点是否还活着有那两个条件?
节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连接;
如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久。
10、producer 是否直接将数据发送到 broker 的 leader(主节点)?
producer 直接将数据发送到 broker 的 leader(主节点),不需要在多个节点进行分发,为了帮助 producer 做到这点,所有的 Kafka 节点都可以及时的告知:哪些节点是活动的,目标topic 目标分区的 leader 在哪。这样 producer 就可以直接将消息发送到目的地了。
11、Kafa consumer 是否可以消费指定分区消息吗?
Kafa consumer 消费消息时,向 broker 发出"fetch"请求去消费特定分区的消息,consumer 指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer 拥有了 offset 的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的。
12、Kafka 高效文件存储设计特点是什么?
l Kafka 把 topic 中一个 parition 大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
通过索引信息可以快速定位 message 和确定 response 的最大大小。
通过 index 元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。
通过索引文件稀疏存储,可以大幅降低 index 文件元数据占用空间大小。
13、partition 的数据如何保存到硬盘?
topic 中的多个 partition 以文件夹的形式保存到 broker,每个分区序号从 0 递增,且消息有序。
Partition 文件下有多个 segment(xxx.index,xxx.log)segment 文件里的 大小和配置文件大小一致可以根据要求修改,默认为 1g。如果大小大于 1g 时,会滚动一个新的 segment 并且以上一个 segment 最后一条消息的偏移量命名。
14、kafaka 生产数据时数据的分组策略是怎样的?
生产者决定数据产生到集群的哪个 partition 中,每一条消息都是以(key,value)格式,Key 是由生产者发送数据传入,所以生产者(key)决定了数据产生到集群的哪个partition。
15、consumer 是推还是拉?
customer 应该从 brokes 拉取消息还是 brokers 将消息推送到 consumer,也就是 pull还 push。在这方面,Kafka 遵循了一种大部分消息系统共同的传统的设计:producer 将消息推送到 broker,consumer 从 broker 拉取消息。
push 模式,将消息推送到下游的 consumer。这样做有好处也有坏处:由 broker 决定消息推送的速率,对于不同消费速率的 consumer 就不太好处理了。消息系统都致力于让consumer 以最大的速率最快速的消费消息,但不幸的是,push 模式下,当 broker 推送的速率远大于 consumer 消费的速率时,consumer 恐怕就要崩溃了。最终 Kafka 还是选取了传统的 pull 模式。
16、kafka 维护消费状态跟踪的方法有什么?大部分消息系统在 broker 端的维护消息被消费的记录:一个消息被分发到 consumer 后
broker 就马上进行标记或者等待 customer 的通知后进行标记。这样也可以在消息在消费后立马就删除以减少空间占用。
-
MySQL
1、据库三大范式是什么
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我们经常会为了性能而妥协数据库的设计。
2、MySQL 有关权限的表都有哪几个?
MySQL 服务器通过权限表来控制用户对数据库的访问,权限表存放在 mysql 数据库里,由 mysql_install_db 脚本初始化。这些权限表分别 user,db,table_priv,columns_priv 和 host。下面分别介绍一下这些表的结构和内容:
user 权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
db 权限表:记录各个帐号在各个数据库上的操作权限。
table_priv 权限表:记录数据表级的操作权限。
columns_priv 权限表:记录数据列级的操作权限。
host 权限表:配合 db 权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受 GRANT 和 REVOKE语句的影响。
3、MySQL 的 Binlog 有有几种录入格式?分别有什么区别?
有三种格式,statement,row 和 mixed。
statement 模式下,每一条会修改数据的 sql 都会记录在 binlog 中。不需要记录每一行的变化,减少了 binlog 日志量,节约了 IO,提高性能。由于 sql 的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
row 级别下,不记录 sql 语句上下文相关信息,仅保存哪条记录被修改。记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如 altertable),因此这种模式的文件保存的信息太多,日志量太大。
mixed,一种折中的方案,普通操作使用 statement 记录,当无法使用 statement 的时候使用 row。
4、MySQL 存储引擎 MyISAM 与 InnoDB 区别
锁粒度方面:由于锁粒度不同,InnoDB 比 MyISAM 支持更高的并发;InnoDB 的锁粒度为行锁、MyISAM 的锁粒度为表锁、行锁需要对每一行进行加锁,所以锁的开销更大,但是能解决脏读和不可重复读的问题,相对来说也更容易发生死锁l 可恢复性上:由于 InnoDB 是有事务日志的,所以在产生由于数据库崩溃等条件后,可以根据日志文件进行恢复。而 MyISAM 则没有事务日志。
查询性能上:MylSAM 要优于 InnoDB 因为 InnoDB 在查询过程中,是需要维护数据缓存,而且查询过程是先定位到行所在的数据块,然后在从数据块中定位到要查找的行;而MyISAM 可以直接定位到数据所在的内存地址,可以直接找到数据。
表结构文件上:MyISAM 的表结构文件包括:frm(表结构定义),.MYI(索引),.MYD(数据);而InnoDB 的表数据文件为:ibd 和frm(表结构定义)。
5、MyISAM 索引与 InnoDB 索引的区别?
InnoDB 索引是聚簇索引,MyISAM 索引是非聚簇索引。
相关文章:

2023携程面试题
Java I/O 面试前需要准备: 1. Java 八股文:了解常考的题型和回答思路; 2. 算法:刷 100-200 道题,记住刷题最重要的是要理解其思想,不要死记硬背,碰上原题很难,但 大多数的解题思…...

CANoe中使用CAPL函数接口调用Vflash文件
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...
三天吃透计算机网络面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址:https://github.com/…...
shp数据添加wkt字段并导出成csv,leaflet绘制使用
准备的东西:软件2跟软件3具体怎么有这些软件需要自行百度postgresql postgis相关 1.shp数据 2.软件2 3.软件3 1.数据导入 首先你得有软件2的数据库,即postgresql数据库,然后通过postgis的插件进行连接并导入数据, 导入数据…...
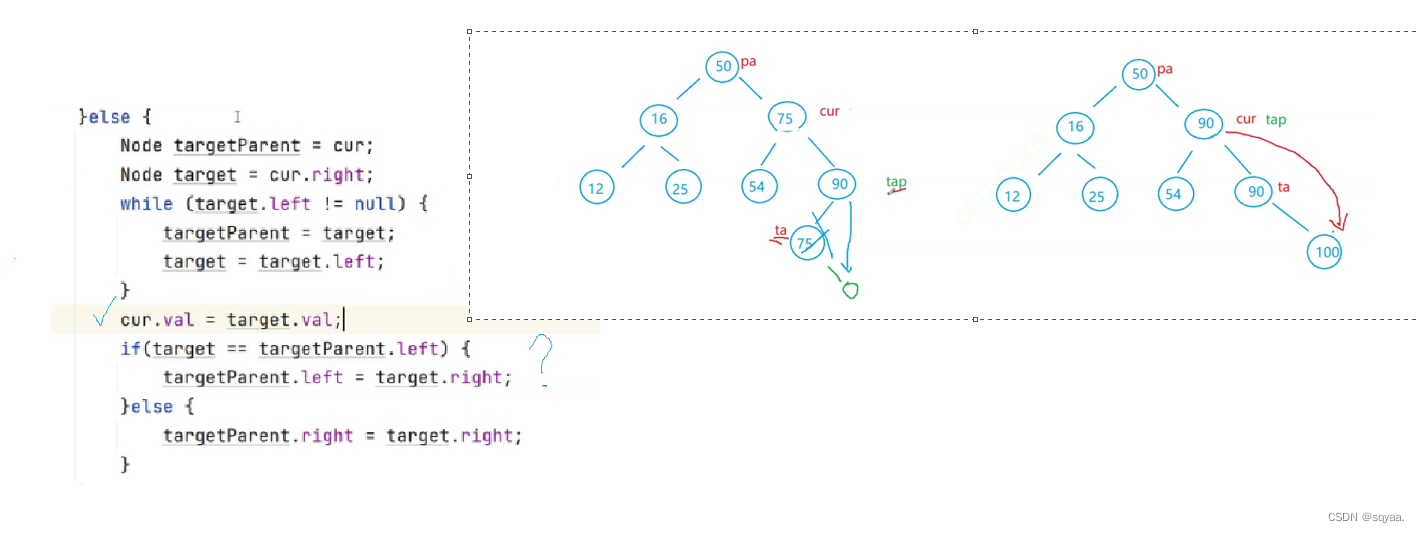
Java——二叉树的最近公共祖先及二叉搜索树介绍
目录 二叉树的最近公共祖先 题目 思路一:如果给定的是一颗二叉搜索树, 思路二:假设是孩子双亲表示法 二叉搜索树 定义Node类 查找 删除 插入 二叉树的最近公共祖先 题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百…...

Stable Diffusion加chilloutmixni真人图片生成模型,AI绘图杀疯了
上期图文教程,我们分享过AI绘图大模型Stable Diffusion以及中文版本文心AI绘画大模型的基础知识以及代码实现,截至到目前为止。Stable Diffusion模型已经更新到了V2.1版本,其文生图大模型也越来越火,其在2022年底,由AI绘制的图片被荣为国际大奖,让大家对AI绘画大模型也越…...

Matplotlib 绘图实用大全
本文只介绍最简单基本的画图方法 预设 要想画出来的图有些逼格,首先应该进行如下设置 plt.rcParams[font.sans-serif][SimHei] #画图时显示中文字体 plt.rcParams[axes.unicode_minus] False #防止因修改成中文字符,导致某些 unicode 字符不能…...
MyBatis源码用了哪些设计模式?
MyBatis源码用了哪些设计模式?前言一、创建型模式工厂模式单例模式建造者模式二、结构型模式适配器模式代理模式组合模式装饰器模式三、行为型模式模板模式策略模式迭代器模式总结前言 在 MyBatis 的两万多行的框架源码中,使用了大量的设计模式对工程架…...

【16.整数转罗马数字】
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例…...

前端小技巧
1.html 1.1 网站自动刷新 应用场景: 网页定期自动刷新(现在基本淘汰了,采用ajax);自动跳转到指定页面,这个自动跳转的好处就是不需要JS调用,属于纯html网页自动跳转 v7-网站自动刷新 你可以…...
Servlet2.0
文章目录更方便的部署方式安装插件使用插件验证程序常见访问出错的解决方案404错误405错误500错误空白页面无法访问此网站在文章 TomcatServlet初识中,我们通过七个大的步骤才可以完成一个简单的Servlet程序,这个过程无疑是非常繁琐的,那么我…...

【c++】继承
目录 一、继承的表现 子类对父类成员的访问权限 二、父类与子类之间的相互赋值 三、继承的作用域 如果是父类和子类构成隐藏呢? 四、子类的成员函数怎么写 1.default构造函数 2.析构函数 所以析构函数不需要我们显式调用。 五、继承与友元函数 六、继承与静…...

minio安装配置和使用(二)客户端安装
安装minio客户端mcli 命令如下: dnf install https://dl.minio.org.cn/client/mc/release/linux-amd64/mcli-20230128202938.0.0.x86_64.rpm 安装完成,在/usr/local/bin/下新增了mcli命令 mcli是对minio进行管理的命令。功能丰富, 基本格式…...

【如何使用Arduino设置GRBL和控制CNC机床】
【如何使用Arduino设置GRBL和控制CNC机床】 前言1. 什么是GRBL?2. 所需硬件3. 如何安装GRBL4. GRBL 配置5. GRBL 控制器5.1 如何使用通用 G 代码发送器5.2 波特率5.3 电机方向5.4 步进比例系数5.5 限位开关5.6 数控机床的归位设置6. 结论前言 如果您正在考虑或正在制造自己的…...
项目测试——博客系统
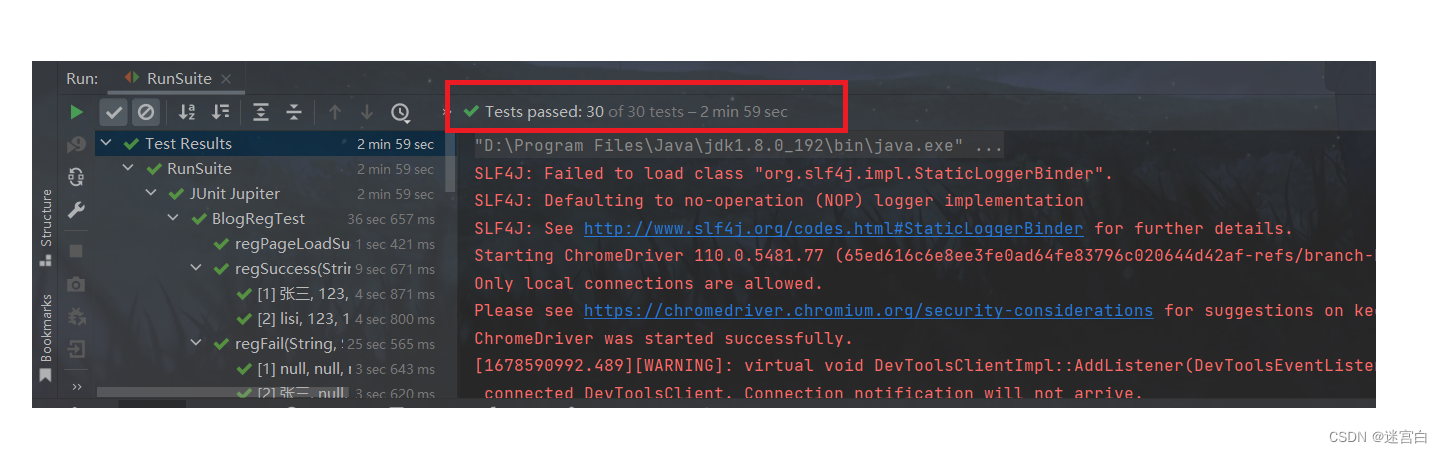
文章目录项目测试——博客系统项目简介项目功能测试计划web自动化测试1. 测试用例2.web自动化测试说明项目测试——博客系统 项目简介 博客系统主要分为8大模块,分别是注册页,登录页,编辑页,修改页,个人主页…...
【C习题】经典数组与指针面试题(万字)
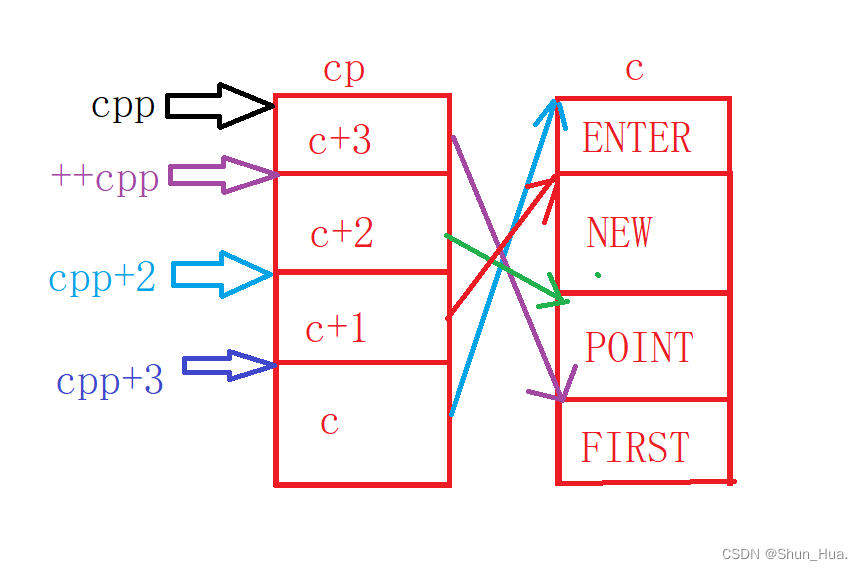
文章目录一. 一维数组二.字符数组三.字符指针四.二维数组五.指针笔试题一. 一维数组 首先说明:需熟记以下三个规则。 规则1.&数组名指的是取出整个数组的地址。 规则2.数组名被单独放在sizeof内部,计算的是整个数组的大小。 说明:这里的单…...
【ArcGIS Pro二次开发】(13):ProWindow的用法
ProWindow是ArcGIS Pro SDK中的一个WPF控件,具有以下特点: 可扩展性:ProWindow提供了丰富的API和样式,可以轻松地扩展和自定义ArcGIS Pro应用程序的UI。 可定制性:ProWindow支持多种UI控件和布局方式,可以…...

HTML/CSS/JS 基本语法
前端一、HTNL1、文件结构2、文本标签(1)块元素:div(2)行内元素:span(3)格式标签3、图片、音频、视频(1)图片(2)音频< audio >&a…...

对于从事芯片行业的人来说,有哪些知识是需要储备的?
近两年芯片行业大火,不少同学想要转行,却不知道该如何下手,需要学习哪些基础知识,下面就来看看资深工程师怎么说? 随着工艺的发展,芯片肯定是尺寸越来越小,至于小到什么样的程度是极限…...

测试场景设计
测试场景设计 又叫做场景法。其实对于场景法是测试用例中面临最多的,但是这种模式不是很容易总结,有时候是基于经验,有时候是我们对系统的了解。所以在这种情况下,我们强硬的用场景法对其进行规范。 场景法原理 现在的软件几乎…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...