菜鸟的进阶--手写一个小型dubbo框架
1.rpc调用流程
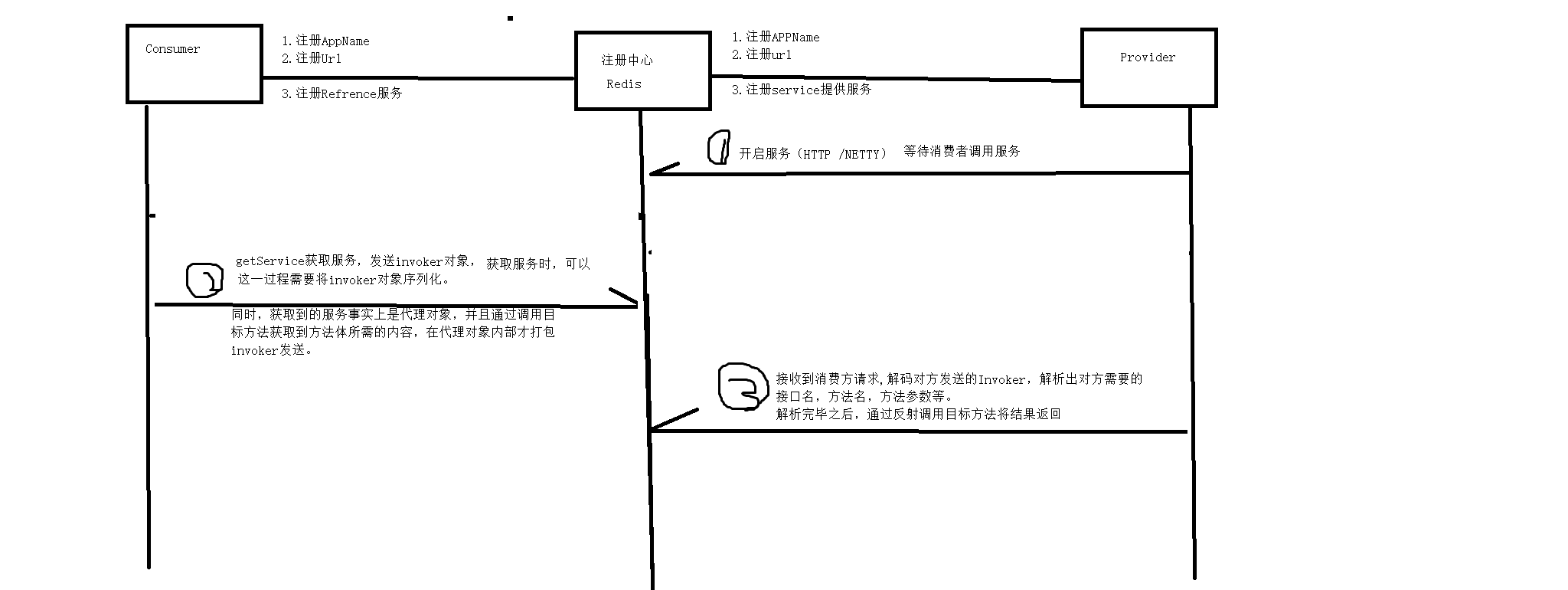
2.组件
1.Redis注册中心
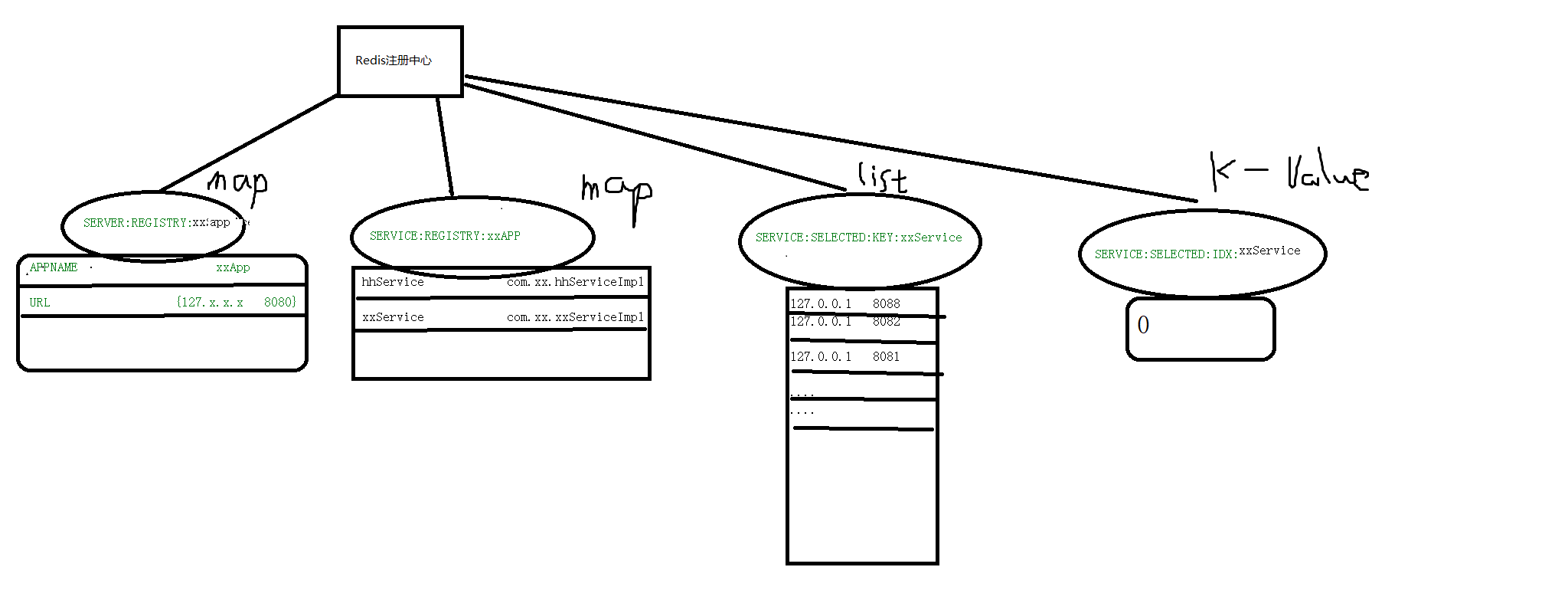
3.编解码/序列化
在本例的Netty通信中,由于每次调用rpc服务都要发送同一个类对象invoker,所以可以使用Protobuf。但是在接受方法调用结果的时候就不行了,因为我们无法提前确定对方方法返回结果的类型,所以在发送result的时候需要使用序列化将object 变成 byte [] ;接收 result的时候需要使用反序列化将 byte [] 变成 object
invoker
publicclassInvokerimplementsSerializable {
privateStringinterfaceName;privateStringmethodName;privateClass[] paramsType;privateObject[] params;
}
序列化
序列化/反序列化可以使用数据流完成,也就是jdk的那一套序列化 / 反序列化操作。
publicstaticObjectByteToObject(byte[] bytes) {Objectobj=null;try {// bytearray to objectByteArrayInputStreambi=newByteArrayInputStream(bytes);ObjectInputStreamoi=newObjectInputStream(bi);
obj=oi.readObject();bi.close();oi.close();} catch (Exceptione) {System.out.println("translation"+e.getMessage());e.printStackTrace();}returnobj;
}
publicstaticbyte[] ObjectToByte(Objectobj) {byte[] bytes=null;try {// object to bytearrayByteArrayOutputStreambo=newByteArrayOutputStream();ObjectOutputStreamoo=newObjectOutputStream(bo);oo.writeObject(obj);
bytes=bo.toByteArray();
bo.close();oo.close();} catch (Exceptione) {System.out.println("translation"+e.getMessage());e.printStackTrace();}
returnbytes;
}但是这一套操作的性能比较堪忧,我又测试了一遍json序列化反序列化的性能.
json的性能明显要好于jdk的性能。
private static void testJson() throwsIOException {//10w次 序列化 / 反序列化 耗时238Personperson=newPerson();person.setName("tom");person.setAge(17);ObjectMapperobjectMapper=newObjectMapper();longstart=System.currentTimeMillis();for (inti=0; i<100000; i++) {person.setAge(i);Strings=objectMapper.writeValueAsString(person);objectMapper.readValue(s, Person.class);}longend=System.currentTimeMillis();System.out.println("json / 耗时: "+(end-start));
}
private static void testJdk(){//10w次 序列化/反序列化耗时: 599msPersonperson=newPerson();person.setName("tom");person.setAge(17);longstart=System.currentTimeMillis();
for (inti=0; i<100000; i++) {person.setAge(i+1);byte[] bys=BytesUtils.ObjectToByte(person);Objectp=BytesUtils.ByteToObject(bys);}longend=System.currentTimeMillis();System.out.println("jdk / 耗时: "+(end-start));}最终敲定,编解码采用protobuf+json的方式
当然我还提供了Jdk的方式

4.负载均衡策略
1.加权轮询策略
加权轮询为每个服务器设置了优先级,每次请求过来时会挑选优先级最高的服务器进行处理。
比如服务器 1~3 分配了优先级{3,1,1}
当请求到来时,先访问服务器1,此时服务器1优先级变为2.
再来请求,还是访问服务器1,此时服务器1优先级变为1.
再来请求,还是服务器1,此时服务器1优先级变为0.
再来就是服务器2,3,1.。。。。
加权轮询可以定制化地为运算能力较强的服务器多分配点请求,能有效的提高服务器资源利用率。
加权轮询策略的优点就是,实现简单,且对于请求所需开销差不多时,负载均衡效果比较明显,同时加权轮询策略还考虑了服务器节点的异构性,即可以让性能更好的服务器具有更高的优先级,从而可以处理更多的请求,使得分布更加均衡。
但轮询策略的缺点是,每次请求到达的目的节点不确定,不适用于有状态请求的场景。并且,轮询策略主要强调请求数的均衡性,所以不适用于处理请求所需开销不同的场景。
不过我们可以使用轮询策略作为默认选项,因为对于rpc来说,我们在调用A服务器的helloService 或者B服务器的helloService 所需要的运算资源是大体一致的。
public class RoundRobinLoadBalance implements LoadBalance {private final Map<String,RoundRobinSelector>selectorMap=new ConcurrentHashMap<>();@Overridepublic Url selectUrl(Invoker invoker) {String interfaceName = invoker.getInterfaceName();if (!selectorMap.containsKey(interfaceName)){selectorMap.put(interfaceName,new RoundRobinSelector(interfaceName));}String url = selectorMap.get(interfaceName).rrAddWeight();Url url0 = null;try {url0 = RedisRegistry.getUrlForStr(url);} catch (IOException e) {e.printStackTrace();}return url0;}public void deleteUrl(Invoker invoker,Url url){String interfaceName = invoker.getInterfaceName();selectorMap.get(interfaceName).deleteUrl(url);}private static class RoundRobinSelector{private final LinkedHashMap<String,Integer> weights=new LinkedHashMap<>();private final LinkedHashMap<String,Integer>currents=new LinkedHashMap<>();;private final LinkedHashMap<String,Integer>effectives=new LinkedHashMap<>();private final ObjectMapper objectMapper=new ObjectMapper();private int totalWeights;private final int maxFails=3;//最大失败次数private final int ERROR_WEIGHT=-127;public RoundRobinSelector(String interfaceName) {int sum=0;Map<String, String> mp = RedisRegistry.getUrlForWeights(interfaceName);for (Map.Entry<String, String> e : mp.entrySet()) {String key = e.getKey();int wi=Integer.parseInt(e.getValue());weights.put(key,wi);currents.put(key,wi);effectives.put(key,wi);sum+=wi;}totalWeights=sum;}private String rrAddWeight() {if (currents.size()<=1){for (String url : currents.keySet()) {return url;}}checkFail();checkError();int max=0;String maxKey=null;for (Map.Entry<String, Integer> e : currents.entrySet()) {if (e.getValue()!=ERROR_WEIGHT && max<e.getValue()){max=e.getValue();maxKey=e.getKey();}else if (e.getValue()==ERROR_WEIGHT){System.out.println("检测到错误链接: "+e.getKey());}}
// //拿到最大key,去减totalif (maxKey!=null){int newCurr = currents.get(maxKey) - totalWeights;currents.put(maxKey,newCurr);}System.out.println("选择连接: "+maxKey+" 权值: "+max);
// //遍历+efffor (String k : currents.keySet()) {if (ERROR_WEIGHT==currents.get(k))continue;currents.put(k,currents.get(k)+effectives.get(k));}return maxKey;}private void checkError() {List<String> urls=new ArrayList<>(16);for (Map.Entry<String, Integer> e : currents.entrySet()) {String url = e.getKey();if (RedisRegistry.isError(url)){urls.add(url);}}for (String url : urls) {currents.remove(url);effectives.remove(url);totalWeights-=weights.get(url);weights.remove(url);}}private void checkFail() {if (!RedisRegistry.containFails()){resetEffectives();return;}Map<String, String> failMap = RedisRegistry.getFailMap();for (Map.Entry<String, Integer> e : effectives.entrySet()) {String url = e.getKey();Integer wt = e.getValue();if (failMap.containsKey(url)){int newEff = (wt - weights.get(url)) / maxFails;effectives.put(url,newEff);}}}private void resetEffectives() {for (Map.Entry<String, Integer> e : effectives.entrySet()) {Integer wt = weights.get(e.getKey());if (e.getValue()!= wt){effectives.put(e.getKey(), wt);}}}public void deleteUrl(Url url){try {String urls = objectMapper.writeValueAsString(url);weights.remove(urls);currents.remove(urls);effectives.remove(urls);} catch (JsonProcessingException e) {e.printStackTrace();}}
}}
2.一致性哈希
个人认为,一致性哈希算法并不是太适合作为远程服务调用的负载均衡策略,因为它的性能并不是多么优秀,而且它天生就占用了挺大的内存。它的更好归宿应该是用于针对缓存方面的负载均衡,用以解决数据不一致时出现的缓存穿透问题。但是dubbo里提供了这一策略,所以我也模仿它实现了一下该策略。
这个算法的大体思路是这样的:
构建一个环形的散列表,该散列表根据key值有序排列,所以这里可以选择TeeMap作为它的实现(dubbo也是这样做的)。
环形散列表上的key是服务提供者的信息和方法调用接口的信息,我个人使用了服务提供者的url+interface+methodName。
当消费方选择服务的时候,先通过一样的哈希算法计算出本次方法调用的hash值,然后从环形散列表上中找出比这个值小并且离它最近的那个主机。这个主机就是我们想要找的主机。
为了解决数据倾斜问题——主机数量过少时,大量的请求都是打到同一台主机上面的问题,我们需要在环形散列表上面添加虚拟节点,dubbo实现时默认选用了160个虚拟节点,我也参考了这个值。
算法的思路其实不复杂,只不过在不清楚它的具体作用时,还是比较难理解的。
//一致性哈希负载均衡策略
public class ConsistentHashLoadBalance implements LoadBalance {private final Map<String, ConsistentHashSelector> selectorMap=new ConcurrentHashMap<>();@Overridepublic Url selectUrl(Invoker invoker) {Url[] urls=RedisRegistry.getProviderUrlsByIntefaceName(invoker.getInterfaceName());//检查url列表是否变动过以及当前selector是否不存在.int providerCount = RedisRegistry.getProviderCount(invoker.getInterfaceName());String key=invoker.getInterfaceName()+"."+invoker.getMethodName();ConsistentHashSelector selector = selectorMap.get(key);if (null == selector || providerCount!=selector.providerCount){System.out.println("重建treeMap");selector = new ConsistentHashSelector(providerCount,urls,invoker);selectorMap.put(key,selector);}return selector.select(invoker);}private static class ConsistentHashSelector{private final int providerCount;private final TreeMap<Long,Url>virtualInvokers;private final int replicaNumber;private final static int DEFAULT_REPLICANUMBER=160;//构造一致性散列表。public ConsistentHashSelector(int providerCount, Url[] urls, Invoker invoker) {this.providerCount=providerCount;this.virtualInvokers=new TreeMap<>();this.replicaNumber=DEFAULT_REPLICANUMBER;String interfaceName = invoker.getInterfaceName();String methodName = invoker.getMethodName();for (Url url : urls) {String key=url.getHost()+":"+url.getPort()+":"+interfaceName+"."+methodName;for (int i = 0; i < replicaNumber / 4; i++) {//md5计算出16个字节的数组byte[] digest = md5(key + i);for (int h = 0; h < 4; h++) {//四次散列,分别是0-3位,4-7位....long m = hash(digest, h);//放进treeMapvirtualInvokers.put(m,url);}}}}private long hash(byte[] digest, int number) {return (((long) (digest[3 + number * 4] & 0xFF) << 24)| ((long) (digest[2 + number * 4] & 0xFF) << 16)| ((long) (digest[1 + number * 4] & 0xFF) << 8)| (digest[number * 4] & 0xFF))& 0xFFFFFFFFL;}private byte[] md5(String value) {MessageDigest md5;try {md5 = MessageDigest.getInstance("MD5");} catch (NoSuchAlgorithmException e) {throw new IllegalStateException(e.getMessage(), e);}md5.reset();byte[] bytes = null;try {bytes = value.getBytes("UTF-8");} catch (UnsupportedEncodingException e) {throw new IllegalStateException(e.getMessage(), e);}md5.update(bytes);return md5.digest();}public Url select(Invoker invoker) {String key = tokey(invoker);byte[] digest = md5(key);Map.Entry<Long, Url> e = virtualInvokers.tailMap(hash(digest, 0), true).firstEntry();if (null==e){e=virtualInvokers.firstEntry();}return e.getValue();}private String tokey(Invoker invoker) {StringBuilder sb=new StringBuilder();sb.append(invoker.getInterfaceName()).append(invoker.getMethodName());for (Object param : invoker.getParams()) {sb.append(param.toString());}return sb.toString();}}
}
3.加权随机
顾名思义,该算法就是体现随机二字。但是并不是简单的随机选择。
由于有了权值,所以在随机的过程中可以稍微地"大小眼"
举例说明: 例如说有这样一个服务列表 :{4,2,1,1}
那么此时完成加权随机就可以这样做:
创建一个列表,权值高的服务给他多分配几个(拷贝),权值低的分配少一点
例如本例,创建一个服务列表可以这样
{服务1,服务1,服务1,服务1,服务2,服务2,服务3,服务3,}
然后通过random函数获取随机数,这个随机数最大不超过这个列表的长度,这样就可以完成加权随机了。
不过我们可以在这一基础上做点优化,将服务实例换成其他占空间更小的元素,节省内存空间。
本例中选择了一个整数值来替换服务实例,这样就不需要拷贝多个服务实例了。
代码:
private static class RandomSelector{private final ConcurrentHashMap<Integer,String>selectUrlMap=new ConcurrentHashMap<>(16);private final ConcurrentHashMap<Integer,Integer>selectHelpMap=new ConcurrentHashMap<>(16);private final Map<String,Integer>urlToWeight;private final int providerCount;private final int total;private final Random random=new Random();public RandomSelector(int providerCount,Invoker invoker) {this.providerCount=providerCount;urlToWeight=new HashMap<>();int sum=0;int idx=0;Map<String, String> mp = RedisRegistry.getUrlForWeights(invoker.getInterfaceName());for (Map.Entry<String, String> e : mp.entrySet()) {String url = e.getKey();int weight=Integer.parseInt(e.getValue());selectUrlMap.put(idx++,url);urlToWeight.put(url,weight);sum+=weight;}total=sum;idx=0;for (Map.Entry<Integer, String> e : selectUrlMap.entrySet()) {int index = e.getKey();String url = e.getValue();int weight = urlToWeight.get(url);for (int i = idx; i < idx+weight; i++) {selectHelpMap.put(i,index);}idx+=weight;}}public String select(){int idx = random.nextInt(total);int index = selectHelpMap.get(idx);return selectUrlMap.get(index);}
}
5.基本心跳机制
本项目的心跳检测机制是通过Redsi注册中心来完成的。
简单概括一下:
当服务注册进来的时候,此时为它建立一个HEART_BEAT key,值是什么无所谓,因为它仅仅代表一个状态。
然后为它设定一个ttl值,本例中默认是12s
开启一个子线程,该子线程会循环地刷新这个ttl值,以保持它的新鲜。循环间隔在本例中是10s。
当负载均衡的时候未检测到对应服务的HEART_BEAT,表示目标服务已经下线。此时要从负载均衡列表中剔除该服务。
对应的代码部分:
package MicroRpc.framework.redis.Registry.core;public class RedisRegistry {
....//服务注册public static void registUrl(String appName, Url url) {String urls = null;try (Jedis jedis = jedisPool.getResource()){urls=objmapper.writeValueAsString(url);jedis.hset(SERVER_REGISTRY_KEY+appName,URL,urls);jedis.set(URL_MAP_KEY+urls,appName);} catch (JsonProcessingException e) {e.printStackTrace();}String finalUrls = urls;new Thread(()->{while (true){try (Jedis jedis = jedisPool.getResource()){String key = buildHeartBeatKey(appName, finalUrls);jedis.set(key,"1");jedis.expire(key,12);Thread.sleep(10*1000);} catch (InterruptedException e) {e.printStackTrace();}}},"heartbeat-thread").start();}
}//loadBalanceboolean tiktok = checkHeartBeat(appName, url);if (tiktok)url0 = RedisRegistry.getUrlForStr(url);else {System.out.println("目标url无心跳,稍等重试..");Thread.sleep(1000);selectUrl(invoker);
}
6.压力测试
测试采用HelloService的say方法,该业务特别简单,仅仅返回一个字符串。
public String say(String msg) {return "hello! this is from provider1 "+msg;}注意: 以下的测试结果均选取最高TPS的记录结果。
在本次测试中的最好成绩是:
单机环境下,并发发起请求,配置是使用了 TCP协议+随机加权负载均衡策略
TPS:14998
单机环境
单提供者单线程(单线程发起20W个请求):
代码:
private final static AtomicInteger sum=new AtomicInteger(0);
public static void main(String[] args) throws ClassNotFoundException {AbstractApplicationContext context=new DefaultDubboApplicationContext(ProtocolTypes.DUBBO, LoadBalance.RANDAM_WEIGHT);context.refresh();System.out.println("刷新完毕");HelloService helloService = context.getProtocol().getService(HelloService.class);log.info("预热一下..");for (int i = 0; i < 10; i++) {helloService.say("a");}log.info("预热完毕..");long start = System.currentTimeMillis();for (int j = 0; j < 200000; j++) {String test = helloService.say("test");if (StringUtils.hasText(test))sum.incrementAndGet();}log.info("任务完成! 总耗时: {} 完成了 {} 个服务调用",(System.currentTimeMillis()-start),sum.get());}测试结果
HTTP: 任务完成! 总耗时: 37600 完成了 200000 个服务调用
TPS= 5319
TCP : 任务完成! 总耗时: 17712 完成了 200000 个服务调用
TPS = 11291
可以看到本例中TCP长连接秒杀HTTP短连接,当然也可能是因为我HTTP采用了汤姆猫的原因,或许采用其他的服务器实现会有更优的表现,这里我也不敢下定论说HTTP就一定比TCP差。
单提供者多线程(1000个线程发起1000个请求,测试20W个请求的完成耗时时间):
代码:
private final static ExecutorService exePool= Executors.newFixedThreadPool(1000);private final static AtomicInteger sum=new AtomicInteger(0);public static void main(String[] args) throws ClassNotFoundException, IOException {System.out.println("任意键开始...");System.in.read();AbstractApplicationContext context =new DefaultDubboApplicationContext(ProtocolTypes.DUBBO, LoadBalance.RANDAM_WEIGHT);context.refresh();System.out.println("刷新完毕");HelloService helloService = context.getProtocol().getService(HelloService.class);log.info("预热一下..");for (int i = 0; i < 10; i++) {helloService.say("a");}log.info("预热完毕..");long start = System.currentTimeMillis();for (int i = 0; i < 1000; i++) {exePool.submit(() -> {for (int j = 0; j < 1000; j++) {String test = helloService.say("test");if (StringUtils.hasText(test)) {sum.incrementAndGet();}}});}while (true){int get = sum.get();if (get>=200000)break;}log.info("任务完毕 总耗时{}ms,共完成{}个任务调用 ", (System.currentTimeMillis() - start), sum.get());}测试结果(TCP):
任务完毕 任务完毕 总耗时13335ms,共完成200000个任务调用
计算TPS = 20000/ (13335/1000) ==> 14998
分布式环境
这里我在本地环境下使用了三个服务提供者来进行模拟分布式环境下的服务能力
由于本地测试环境并不能做到模拟真正的分布式环境,因为一台机器要肩负三台机器的任务,所以分布式环境的测试结果仅供参考。
代码仍然选用上面的测试代码,测试仍然分为单线程以及多线程的测试,这里我仅测试TCP协议。
单线程:
任务完成! 总耗时: 34573 完成了 200000 个服务调用
任务完成! 总耗时: 26859 完成了 200000 个服务调用
任务完成! 总耗时: 28397 完成了 200000 个服务调用
多线程:
任务完毕 总耗时21077ms,共完成200001个任务调用
任务完毕 总耗时20129ms,共完成200001个任务调用
任务完毕 总耗时21612ms,共完成200001个任务调用
单机的成绩明显要好于这里的分布式环境,原因有几个:
一台机器模拟三台机器,CPU能力打了折扣。
这里的业务逻辑比较简单,无法体现分布式的优势。
由于以上原因,负载均衡反倒成了累赘,因为在单机情况下根本不需要走复杂的负载均衡逻辑,仅仅需要返回唯一的服务提供商即可。
7.服务管理界面
为了直观的观察服务,我这边开发了一个简陋的管理界面。

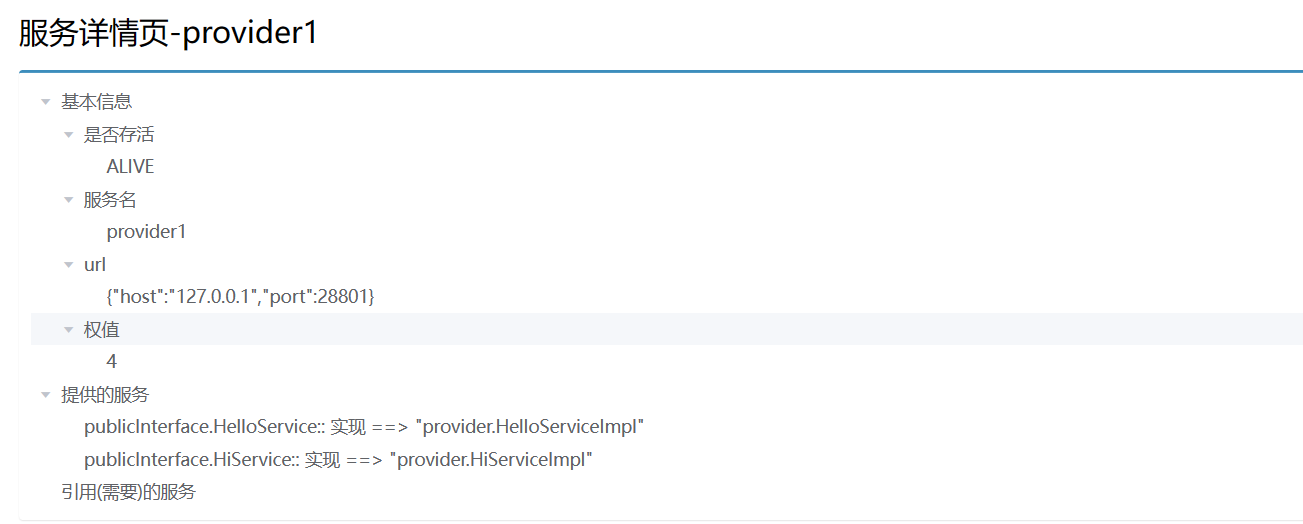
仓库地址(gitee),里面有readme文档 看看就懂得怎么玩了。
看到这里,如果觉得对你有帮助,请帮我点个赞 感谢。
相关文章:
菜鸟的进阶--手写一个小型dubbo框架
1.rpc调用流程2.组件1.Redis注册中心3.编解码/序列化在本例的Netty通信中,由于每次调用rpc服务都要发送同一个类对象invoker,所以可以使用Protobuf。但是在接受方法调用结果的时候就不行了,因为我们无法提前确定对方方法返回结果的类型&#…...
js逆向爬取某音乐网站某歌手的歌曲
js逆向爬取某音乐网站某歌手的歌曲一、分析网站1、案例介绍2、寻找列表页Ajax入口(1)页面展示图。(2)寻找部分歌曲信息Ajax的token。(3)寻找歌曲链接(4)获取歌曲名称和id信息3、寻找…...

为什么软件测试面试了几个月都没有offer,从HR角度分析
首先,我觉得你在软件测试面试的过程中,逻辑比较混乱的最大一个原因是,说明你没有形成一个一个整体的体系。 导致你说的时候很多东西都杂乱无章。 我个人认为软件测试,其实开始首先进行的是一些需求的分析工作,之后呢…...

DC-7 靶场学习
文章目录信息搜集账号密码获取修改密码反弹shell得到flag信息搜集 首先获取目标ip。 arp-scan -l nmap -sP 192.168.28.0/24得到目标ip为: 192.168.28.139先访问页面。 翻译一下。 欢迎来到 DC-7DC-7引入了一些“新”概念,但我会让你弄清楚它们是什么…...

深入理解JavaScript的事件冒泡与事件捕获
前言JavaScript中提供了很多操作DOM的API。事件冒泡和事件捕获是指浏览器中处理DOM元素上事件的两种不同方式。事件冒泡和事件捕获都是JavaScript事件模型中的一部分,可以用来处理事件。对于这个问题,在实际开发中,并不是非常重要,…...
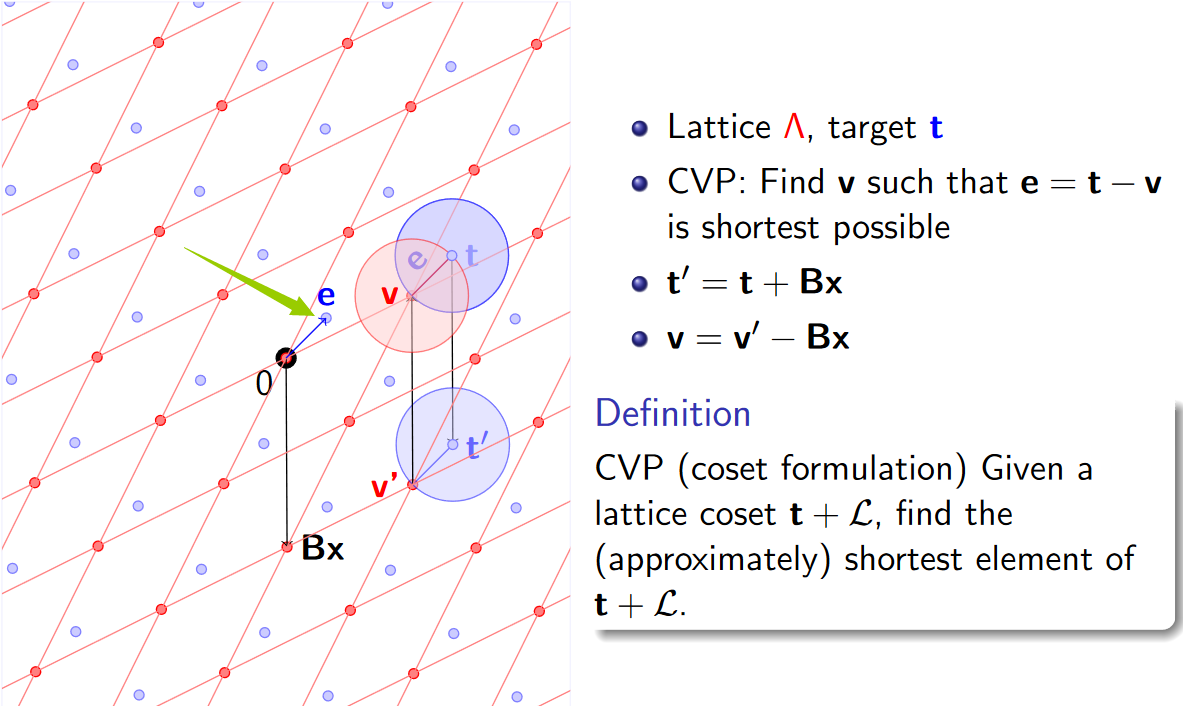
格密码学习笔记(六):格中模运算
文章目录格中取模运算CVP和格的陪集致谢格中取模运算 定义(格的基本区域) P⊂Rn:{Px∣x∈L}\mathcal{P} \subset \mathbb{R}^n : \{ \mathcal{P} \bm{x} | \bm{x} \in \mathcal{L} \}P⊂Rn:{Px∣x∈L}是Rn\mathbb{R}^nRn的一种划分。 用P\mathcal{P}P对…...

【C++】非常重要的——多态
凡是面向对象的语言,都有三大特性,继承,封装和多态,但并不是只有这三个特性,是因为者三个特性是最重要的特性,那今天我们一起来看多态! 目录 1.多态的概念 1.1虚函数 1.2虚函数的重写 1.3虚…...

发票账单很多?python助你批量完成数据提取
每天面对成堆的发票,无论是税务发票还是承兑单据,抑或是其他各类公司数据要从照片、PDF等不同格式的内容中提取,我们都有必要进行快速办公的能力提升。因此,我们的目标要求就十分明显了,首先要从图片中获取数据&#x…...

[闪存2.1] NAND FLASH特性串烧 | 不了解闪存特性,你能用好闪存产品吗?
前言 为了利用好闪存, 发挥闪存的优势, 以达到更好的性能和使用寿命, 那自然要求了解闪存特性。 闪存作为一种相对较新的存储介质, 有很多特别的特性。 一.闪存的特性 凡是采用Flash Memory的存储设备,可以统称为闪存存储。我们经常谈的固态硬盘(SSD),可以由volatile/…...

面试官问我按钮级别权限怎么控制,我说v-if,面试官说再见
最近的面试中有一个面试官问我按钮级别的权限怎么控制,我说直接v-if啊,他说不够好,我说我们项目中按钮级别的权限控制情况不多,所以v-if就够了,他说不够通用,最后他对我的评价是做过很多东西,但…...

阿里云服务器使用教程:CentOS 7安装nginx详细步骤
目录 1、下载nginx压缩包 2、配置nginx安装所需环境 3、解压nginx压缩包 4、编译安装nginx 5、nginx启动...

Android JNI浅析、Java和Native通信对象的传值和回调
简单了解一下jni JNI是一个本地编程接口,它允许运行在Java虚拟机的Java代码与用其他语言(如C,C和汇编)编写的库交互。 jni函数签名 首先看一下java类型对应的jni类型: Java类型符号BooleanZByteBCharCShortSIntILongJFloatFDo…...
linux目录/usr/lib/systemd/system目录详解
文章目录前言一. systemd介绍二. service 脚本详解2.1 [Unit] 区块2.2 [Service] 区块2.3 [Install] 区块总结前言 init的进化经历了这么几个阶段: CentOS 5: SysV init,串行 CentOS 6:Upstart,并行,借鉴ubuntu CentOS 7:Syste…...

408考研计算机之计算机组成与设计——知识点及其做题经验篇目4:CPU的功能和基本结构
随着考研的慢慢复习,我们逐渐进入了计算机组成与设计的第五章中央处理器。它原名为CPU。姓C,名PU,字中央处理器,号计组难点,乃计算机之中心与核心部件,小编称之曰能算能控,赐名曰九天宏教普济生…...
等级考试试卷(五级)解析)
2022-12-10青少年软件编程(C语言)等级考试试卷(五级)解析
2022-12-10青少年软件编程(C语言)等级考试试卷(五级)解析T1、漫漫回国路 2020年5月,国际航班机票难求。一位在美国华盛顿的中国留学生,因为一些原因必须在本周内回到北京。现在已知各个机场之间的航班情况,求问他回不回得来(不考虑转机次数和机票价格)。 时间限制:10…...

刷题专练之链表(一)
文章目录前言一、 移除链表元素1.题目介绍2.思路3.代码二、反转链表1.题目介绍2.思路3.代码三、链表的中间结点1.题目介绍2.思路3.代码四、链表的中间结点1.题目介绍2.思路3.代码前言 以下是链表经常考的面试题,我在这里进行归纳和讲解,采取的是循序渐进…...

elasticsearch高级查询api
yml配置 #es配置 spring:elasticsearch:rest:uris: 192.168.16.188:9200添加依赖 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId> </dependency>使用编程的形式…...

力扣-股票的资本损益
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:1393. 股票的资本损益二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其他…...

蓝桥杯刷题冲刺 | 倒计时26天
作者:指针不指南吗 专栏:蓝桥杯倒计时冲刺 🐾马上就要蓝桥杯了,最后的这几天尤为重要,不可懈怠哦🐾 文章目录1.路径2.特别数的和3.MP3储存4.求和1.路径 题目 链接: 路径 - 蓝桥云课 (lanqiao.cn…...

嵌入式软件开发之Linux 用户权限管理
目录 Ubuntu 用户系统 权限管理 权限管理命令 权限修改命令 chmod 文件归属者修改命令 chown Ubuntu 用户系统 Ubuntu 是一个多用户系统,我们可以给不同的使用者创建不同的用户账号,每个用户使用各自的账号登陆,使用用户账号的目的一是方便…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...
【51单片机】4. 模块化编程与LCD1602Debug
1. 什么是模块化编程 传统编程会将所有函数放在main.c中,如果使用的模块多,一个文件内会有很多代码,不利于组织和管理 模块化编程则是将各个模块的代码放在不同的.c文件里,在.h文件里提供外部可调用函数声明,其他.c文…...

深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀”
深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀” 在JavaScript中,我们经常需要处理文本、数组、对象等数据类型。但当我们需要处理文件上传、图像处理、网络通信等场景时,单纯依赖字符串或数组就显得力不从心了。这时ÿ…...
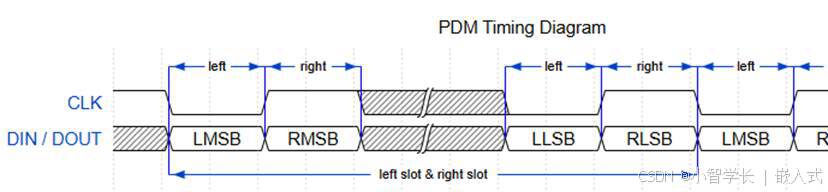
SOC-ESP32S3部分:30-I2S音频-麦克风扬声器驱动
飞书文档https://x509p6c8to.feishu.cn/wiki/SKZzwIRH3i7lsckUOlzcuJsdnVf I2S简介 I2S(Inter-Integrated Circuit Sound)是一种用于传输数字音频数据的通信协议,广泛应用于音频设备中。 ESP32-S3 包含 2 个 I2S 外设,通过配置…...