基于B站视频评论的文本分析,采用包括文本聚类分析、LDA主题分析、网络语义分析
研究主题
本研究旨在通过对B站视频评论数据进行文本分析,揭示用户评论的主题、情感倾向和语义结构,助力商业决策。主要技术手段包括Python爬虫、LDA主题分析、聚类分析和语义网络分析。首先,利用Python爬虫采集大量评论数据并进行预处理。运用LDA模型提取主要讨论话题,通过聚类分析识别用户评论模式。构建语义网络图展示关键词之间的关系,揭示评论中的语义结构。
商业价值体现
内容优化:视频创作者可以根据用户评论调整和优化内容,提高用户满意度和观看时长,从而增加广告收入和会员转化率。
精准营销:通过分析用户评论中的热门话题和情感倾向,品牌和广告商可以制定更有针对性的营销策略,提高广告投放效果。
用户需求洞察:平台运营者能够更好地了解用户需求和偏好,优化推荐算法,提升用户活跃度和留存率。
市场趋势分析:通过识别评论中的趋势和热点,帮助企业及时把握市场动向,调整产品和服务策略,提升竞争力。
主要解决商业问题
用户需求捕捉
问题:准确捕捉和理解用户需求和反馈,帮助内容创作者和平台改进产品和服务。
解决方案:通过LDA主题分析提取主要讨论话题,结合情感分析了解用户态度和需求。
市场趋势识别
问题:及时识别和分析市场趋势,帮助企业调整营销和产品策略。
解决方案:利用聚类分析和语义网络分析,识别评论中的热门话题和关键词,洞察市场趋势。
广告效果优化
问题:提高广告投放的精准度和效果,增加广告收益。
解决方案:通过分析用户评论中的情感和话题偏好,制定精准的广告投放策略,提高广告点击率和转化率。
内容优化与推荐
问题:提升内容推荐的精准度和用户满意度,增加平台粘性。
解决方案:利用主题和聚类分析结果,优化内容推荐算法,提供个性化内容推荐。
用户行为分析
问题:深度分析用户行为,提升平台运营效率和用户体验。
解决方案:结合评论分析与用户行为数据,挖掘用户行为模式,优化平台功能和用户体验。
1 研究背景介绍
随着互联网和移动通信技术的迅猛发展,在线视频平台已经成为人们获取信息、娱乐和互动的重要渠道。其中,哔哩哔哩(简称B站)作为中国领先的视频分享网站,以其丰富的内容和活跃的社区氛围吸引了大量用户。B站的视频评论功能不仅提供了观众之间交流互动的平台,还积累了大量具有研究价值的文本数据。本文旨在基于B站视频评论进行文本分析,以体育类视频如何提速800米1000米为例,利用Python爬虫技术、LDA主题分析、聚类分析和语义网络分析等方法,探讨视频评论中的潜在信息和用户行为模式。
1. 视频评论的研究价值
视频评论作为用户观看视频后的即时反馈,具有高度的时效性和真实感。通过对评论文本的分析,可以了解用户的兴趣偏好、情感倾向以及社群互动等信息。这些数据不仅对平台运营和内容创作具有指导意义,也为社会科学研究提供了新的数据源。例如,通过评论分析,可以识别热门话题、预测用户需求,甚至探讨文化传播和社会现象。
2. Python爬虫技术的应用
为了获取B站视频评论数据,本文将采用Python爬虫技术。Python具有丰富的第三方库,如Requests,可以高效地抓取网页数据。通过编写爬虫程序,能够自动化地获取大量视频评论,解决手动收集数据的效率低下问题。同时,爬虫技术还可以定期更新数据,保证分析结果的时效性。
3. LDA主题分析
LDA(Latent Dirichlet Allocation)是一种常用的主题模型,用于从大规模文本数据中发现潜在的主题结构。通过对视频评论进行LDA主题分析,可以识别出评论中的主要话题及其演变趋势。这有助于了解用户关注的热点问题,指导内容创作者进行精准创作,提高视频的吸引力和用户粘性。
4. 聚类分析
聚类分析是一种将数据对象按相似性分组的方法。在文本分析中,通过将相似评论聚类,可以发现用户的不同兴趣群体和观点倾向。本文将利用K-means等聚类算法,对评论文本进行聚类分析,揭示用户群体的多样性和复杂性,助力平台进行精细化运营和精准推荐。
5. 语义网络分析
语义网络分析是一种基于图论的方法,用于分析词汇之间的关系和结构。通过构建评论文本的语义网络,可以直观地展示评论中的关键词及其关联关系,揭示用户讨论的核心内容和逻辑结构。本文将使用NetworkX等库,绘制语义网络图,深入解析评论中的语义信息。
本研究通过对B站视频评论的文本分析,旨在发掘评论数据中的潜在信息,揭示用户行为和兴趣倾向。结合Python爬虫技术、LDA主题分析、聚类分析和语义网络分析等方法,不仅可以为平台提供运营和内容创作的参考,还能够丰富学术界对网络文化和社会现象的理解。这种多技术融合的研究方法,将为视频评论的文本分析开辟新的视角和路径。
2 相关技术
2.1爬虫技术
网络爬虫(Web Crawler),也称为网络蜘蛛(Web Spider)或网络机器人(Web Robot),是一种自动化的脚本或程序,用于自动地在互联网上浏览和提取数据。爬虫主要用于搜索引擎索引网站内容,以便用户可以通过搜索引擎找到相关信息。

爬虫的工作原理
种子URL:爬虫从一组初始的URL(种子URL)开始,这些URL通常是用户指定的。
抓取页面:爬虫访问种子URL,并下载这些页面的内容。
解析页面:爬虫解析下载的页面,从中提取新的URL(链接)以及其他有用的信息。
重复过程:爬虫将新提取的URL添加到待抓取的URL队列中,并重复上述过程。
爬虫的挑战
反爬机制:许多网站采用各种技术限制或阻止爬虫,如使用CAPTCHA、机器人检测等。
动态内容:现代网页通常包含大量动态内容(如JavaScript生成的内容),需要更复杂的技术处理。
2.2kmeans聚类技术
K-Means 聚类是一种常见的无监督机器学习算法,用于将数据集划分为K个互不重叠的簇(Clusters)。每个簇由一个质心(Centroid)代表,数据点根据其与各质心的距离进行分配,使得同一簇内的数据点彼此之间的相似性最大,而不同簇的数据点相似性最小。

工作原理
初始化:随机选择K个初始质心。
分配簇:将每个数据点分配给最近的质心,形成K个簇。
更新质心:计算每个簇内数据点的平均值,将其作为新的质心。
重复:重复步骤2和3,直到质心不再发生显著变化或达到预设的迭代次数。
优点
简单易理解:算法步骤简单,容易实现和理解。
效率高:计算复杂度较低,适用于大规模数据集。
缺点
需预设K值:需要事先指定簇的数量K,这在实际应用中可能不直观。
初始质心敏感:不同的初始质心可能导致不同的结果,可能陷入局部最优。
簇形状限制:假设簇是球形且大小相似,对复杂形状的簇效果较差。
应用领域
图像分割:用于将图像像素分组以实现图像分割。
市场细分:识别客户群体,进行个性化营销。
文档分类:将文本数据聚类,应用于信息检索和推荐系统。
2.3LDA主题分析
LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)是一种生成式统计模型,用于发现文档集合中隐藏的主题结构。LDA 假设每个文档是由若干主题混合生成的,而每个主题则由一组词语分布构成。
工作原理
主题分布:为每个文档分配一个主题分布,表示文档中各主题出现的概率。
词语分布:为每个主题分配一个词语分布,表示主题中各词语出现的概率。
生成过程:
对于每篇文档中的每个词,从该文档的主题分布中抽取一个主题。
从选定的主题的词语分布中抽取一个词,生成该文档中的一个词语。
模型参数
α(Alpha):控制文档-主题分布的稀疏性,α值小,文档包含的主题越少。
β(Beta):控制主题-词语分布的稀疏性,β值小,主题包含的词语越少。
优点
可解释性强:能够提供文档的主题分布和每个主题的关键词,易于解释。
无监督学习:无需预先标注数据,适合大规模文本数据处理。
缺点
参数敏感:模型对初始参数较敏感,需通过实验调整。
复杂度高:对大规模数据计算开销较大。
应用领域
文本分类:根据文档的主题分布进行分类。
信息检索:根据主题相关性进行文档检索。
推荐系统:基于用户历史行为的主题分布进行个性化推荐。
2.4网络语义分析
网络语义分析(Web Semantic Analysis)是一种技术,通过理解和解析网页内容的语义信息,实现对互联网数据的更深入理解和处理。其核心目标是从大量的网页数据中提取有意义的语义信息,以便进行更智能的搜索、推荐和数据挖掘。
工作原理
数据抓取:使用爬虫技术从互联网上收集大量网页数据。
预处理:对抓取到的数据进行清洗、去噪和标准化处理。
特征提取:使用自然语言处理(NLP)技术,提取文本中的关键特征,如词频、词向量等。
语义分析:应用语义技术,如词嵌入(Word Embedding)、主题模型(LDA)等,理解文本的语义结构。
知识图谱:构建知识图谱,将语义信息进行结构化表示,便于后续的查询和推理。
优点
理解深度:能够深入理解文本的语义信息,而不仅仅是表面的关键词匹配。
应用广泛:适用于搜索引擎优化、智能推荐系统、舆情分析等多个领域。
信息整合:通过语义分析,可以将分散的信息进行有效整合,提升信息利用效率。
缺点
计算复杂:语义分析需要大量计算资源,对硬件和算法优化有较高要求。
数据依赖:需要大量高质量的训练数据,数据的缺失或偏差会影响分析结果的准确性。
语言多样性:不同语言的复杂性和多样性增加了语义分析的难度。
应用领域
搜索引擎:通过理解用户查询的意图,提高搜索结果的相关性和准确性。
推荐系统:基于用户历史行为和语义分析,提供个性化推荐内容。
舆情分析:实时监控和分析网络舆情,帮助企业和政府了解公众意见和情绪。
3数据采集实现
数据采集从Bilibili体育类视频如何提速800米1000米的评论区中抓取评论数据,并将其保存到本地文件中。它通过模拟用户请求,获取评论数据,解析并提取有用信息,然后将其写入CSV文件中,共采集字段:楼层、时间、点赞数、uid、用户名、性别、评论内容、地区、会员等级,一千多条数据进行分析。
3.1整体思路

3.2爬虫思路

3.3分析网页
要想写好爬虫,一定要先把网页结构分析透彻。
3.3.1.分析网页加载方式
我们要爬取用户信息和评论,所以先打开一个视频。

鼠标右击 查看源代码 ,在源代码中搜索相关评论内容,并没有找到相关数据,可以判断此页面为ajax异步加载数据渲染出来的。

3.3.2分析数据接口
回到视频页面F12打开开发者工具,刷新一下,ctrl+f搜索一下,发现评论数据都在这个json中。

这个json指向了下面这个接口地址:
https://api.bilibili.com/x/v2/reply/wbi/main?oid=1205203240&type=1&mode=3&pagination_str=%7B%22offset%22:%22%7B%5C%22type%5C%22:1,%5C%22direction%5C%22:1,%5C%22session_id%5C%22:%5C%221762048102472848%5C%22,%5C%22data%5C%22:%7B%7D%7D%22%7D&plat=1&web_location=1315875&w_rid=1599f0936636a2ac47a04de0bdb2e8d4&wts=1720750296
查看这个json可以看到用户信息在member里,评论信息在message里。回到这个接口,此接口需要传以下参数:


callback: jQuery1720631904798407396_1605664873948 #经测试可以不传
jsonp: jsonp #经测试可以不传
pn: 1 #页码标识
type: 1 #所属类型
oid: 248489241 #视频标识,现在确定为视频av号
sort: 2 #所属分类
_: 1605664874976 #当前时间戳,经测试可以不传
通过分析发现关键参数为oid和pn,sort,个人猜测oid为视频标识,pn为评论所在页数,sort为类别,我们要获取到oid。
3.3.3获取oid
如果视频url类似https://www.bilibili.com/video/BV1wv41157Rr
则需要将BV号转化为av号,如果视频url类似https://www.bilibili.com/video/av248489241直接使用字符串切割出av后面的数字就可以啦。
3.4具体代码实现
3.4.1. 视频有效性检查
首先,代码检查视频的有效性。在visit函数中,通过构建视频的URL并发送GET请求来确认视频是否存在。若返回状态码为404或页面包含错误提示,则判断视频不存在。
def visit(bv):
...
response = requests.get(url, headers = headers)
...
if response.status_code == 404 or """<div class="error-text">啊叻?视频不见了?</div>""" in response.text:
print('视频不存在!')
return 0
else:
return 1
3.4.2. BV号和AV号转换
Bilibili视频有两种标识符:BV号和AV号。代码通过Bta函数将BV号转换为AV号,以便后续接口调用。这是基于Bilibili的编号转换算法实现的。
def Bta(bv):
...
return str((sum(bv) - 100618342136696320) ^ 177451812)
3.4.3. 获取父评论
send_f函数通过调用Bilibili的API获取父评论数据。函数构建请求参数,包括视频ID、评论排序模式(楼层、时间或热度)等,并发送请求获取评论的JSON数据。
def send_f(bv, nexts=0, mode=1):
...
response = requests.get(r_url, headers = headers, params = data)
...
c_json = json.loads(response.text)
...
return c_json
3.4.4. 获取子评论
send_r函数专门用于获取某条父评论下的子评论。它接受视频ID和父评论ID作为参数,并分页获取子评论数据。
def send_r(bv, rpid, pn=1):
...
response = requests.get(r_url, headers = headers, params=data)
...
cr_json = json.loads(response.text)
...
return cr_json
3.4.5. 解析评论
parse_comment_f函数负责解析父评论的JSON数据,将有用的信息提取并格式化为CSV格式。若父评论包含子评论,则调用parse_comment_r函数进一步解析子评论。
def parse_comment_f(bv):
...
if c_list:
for i in range(len(c_list)):
...
comment_temp = {
...
}
...
if replies:
csv += parse_comment_r(bv, rpid)
...
return csv, all_json
3.4.6. 数据存储
解析后的评论数据以CSV格式保存在指定路径。若路径不存在,代码会自动创建相应目录。首次写入时会创建CSV文件并写入标题,后续数据以追加方式写入。
if not os.path.exists(dir_csv):
with open(dir_csv, 'w', encoding='utf-8-sig') as fp:
fp.write('楼层,时间,点赞数,uid,用户名,性别,评论内容,地区,会员等级\n')
...
with open(dir_csv, 'a', encoding='utf-8') as fp:
fp.write(csv)
最终存储结果如下图所示:

4kmeans聚类分析实现
对Bilibili评论数据的有效聚类分析。整个过程不仅包括数据预处理、文本向量化和降维,还结合了不同方法确定最佳聚类数,为后续的数据分析和可视化奠定了基础。这样的聚类分析可以帮助识别评论中的主题和模式,为进一步的用户行为分析、意见挖掘和市场调研提供有力支持。通过科学的方法和精细的处理,代码不仅实现了对海量文本数据的有效处理,还为提升分析结果的准确性和可靠性提供了保障。具体实现步骤如下:
4.1数据预处理
使用pandas库导入评论数据,并对数据进行去重处理,确保每条评论内容唯一。如下图

通过正则表达式过滤除中英文及数字以外的其他字符,保留一些标点符号,以保证数据的一致性和纯净性。如下图

然后,利用jieba库对评论进行中文分词,并去除停用词,使文本内容更加简洁和有意义。如下图:


4.2关键词向量化
使用CountVectorizer将分词后的文本转换为词频矩阵。这一步骤是文本向量化的关键,旨在将文本数据转化为机器学习模型可处理的数值形式。为了减少特征空间的维度,提高聚类算法的效率和效果,代码使用TruncatedSVD进行降维,并结合标准化处理,以确保数据的均匀性和稳定性。如下图

通过TfidfTransformer将词频矩阵转换为TF-IDF矩阵,获取词的重要性权重。这一步骤旨在突出重要词语的贡献,降低常见词语的影响,从而提高聚类的准确性。如下图

4.3确定最优聚类数
聚类数的确定阶段。为了选择最佳聚类数,代码分别使用手肘法和轮廓系数法进行验证。在手肘法中,代码计算不同聚类数下的inertia值,并绘制手肘法图,通过观察图中的折点来选择合适的聚类数。如下图所示,手肘法最优聚类数为4.

轮廓系数法则通过计算不同聚类数下的轮廓系数,并绘制轮廓系数图,选择轮廓系数最高的聚类数作为最佳聚类数。如下图所示轮廓系数法最优聚类数为9

4.4聚类可视化
通过使用T-SNE算法对TF-IDF权重进行降维,实现了文本聚类的可视化展示。首先,指定了将文本分成4个类别的KMeans聚类器,并对TF-IDF权重进行聚类操作。如下图:

然后,通过TSNE算法将高维的TF-IDF权重数据降至3维,以便于在三维空间中展示不同文本样本的聚类情况。在可视化过程中,绘制了散点图来展示降维后的数据分布情况,其中每个点代表一个文本样本。不同颜色和标记符号代表着不同的文本簇,帮助区分和识别不同的聚类群体。通过这种方式,可以直观地观察到文本数据在降维空间中的分布情况,以及不同文本簇之间的关联性和差异性。如下图:



结果分析:
中心点坐标分析:
中心点坐标提供了各簇样本的平均特征,可以帮助我们理解每个簇的主要特征和差异,从而进一步细化内容和营销策略。例如,簇1中的样本集中反映了用户的训练成果和期望,簇3中的样本集中反映了推广活动和非主题相关的讨论。
效果评估值分析:
inertia值提供了对聚类效果的整体评价。当前的inertia值表明聚类效果较好,但在具体应用中,我们还需结合其他评估指标,如轮廓系数(Silhouette Coefficient)等,进一步验证聚类结果的合理性和稳定性。
簇0:主要评论内容集中在对其他用户回复、提及过去视频内容。
簇1:主要评论内容集中在分享个人训练成果和期望,表达对训练效果的关注和希望。
簇2:主要评论内容集中在庆祝和表达幽默,可能与里程碑或成就相关。
簇3:主要评论内容集中在推广活动和其他非主题相关讨论。
根据聚类结果可知,内容优化方面:视频创作者可以通过分析簇1中的评论,了解用户的训练需求和期望,进而优化视频内容,提高用户满意度和观看时长,增加广告收入和会员转化率。
精准营销方面:品牌和广告商可以根据簇0和簇3中的讨论,识别出潜在的广告投放机会,制定更有针对性的营销策略,提高广告投放效果。
用户需求洞察方面:平台运营者能够通过簇1中的详细反馈,了解用户的具体需求和困难,优化推荐算法,提升用户活跃度和留存率。
市场趋势分析方面:通过簇2中的庆祝和幽默评论,企业可以及时把握用户的成就感和里程碑,调整产品和服务策略,提升竞争力。
5LDA主题分析实现
本文展示了如何利用LDA(Latent Dirichlet Allocation)主题模型对文本进行主题分析。LDA是一种常用的无监督学习算法,用于发现文档集合中隐藏的主题结构,并将每个文档映射到这些主题上。涉及了数据预处理、困惑度和一致性评估、词频统计、词云图绘制、先验分布计算、TF-IDF 提取关键词、LDA建模和可视化展示等多个环节。通过这些步骤,有效地揭示了文本数据中隐藏的主题结构和关键词信息,为深入理解文本数据提供了重要支持。
5.1数据预处理
首先,文本数据经过预处理,包括分词、去除停用词、过滤不符合条件的词语(如单个字符、包含数字和特殊符号等),然后将处理后的文本保存到Excel文件中,以便后续分析和处理。如下图

5.2困惑度和一致性评估
使用Gensim库中的corpora和models模块,将预处理后的文本转换为词袋模型(bag of words),并创建单词ID映射。通过TF-IDF模型对词袋进行加权处理,得到加权后的语料库。然后,利用LDA模型对加权后的语料库进行训练,设置主题数为10,迭代5次,设定超参数alpha和eta,来推断文档和主题之间的关系。通过计算困惑度和一致性来确定最佳主题数,并绘制了困惑度和一致性曲线。根据效果评估值选择了最佳的主题数。如下图所示最佳主题数为9

5.3词频统计和词云
进行了词频统计,并绘制了词云图,直观展示了内容词语的分布情况。如下图

5.4先验分布计算和TF-IDF 提取关键词
先验分布计算,使用 Gensim 库中的 Dictionary 和 corpora 模块实现。如下图


然后利用 TF-IDF 提取关键词,获取文本的关键词,并输出前30个关键词。如下图所示:

5.5LDA建模和可视化展示
接着进行 LDA 建模,得到主题和主题下的关键词。通过 PyLDAvis 进行可视化并生成 HTML 文件,方便展示和共享分析结果。此外,还创建了空的 DataFrame 用于存储关键词和权重,并将DataFrame保存为 Excel 文件,以便后续分析和可视化。如下图所示



根据对B站体育类视频(如如何提速800米1000米视频)的评论进行LDA主题分析,得出如下结论。这些结论不仅展示了观众对视频内容的反应,还揭示了潜在的商业价值和问题解决的方向。
5.6结论分析
主题一(感觉、回复、分钟、微笑等)
主要关注用户对视频内容的直观感受,如训练过程中可能出现的身体反应(嗓子、嘴里、恶心等)。
商业价值:可以通过改进视频内容,加入更详细的训练指导,或开发相应的训练辅助产品,如提升运动体验的饮品或装备。针对新手和训练过程中常见问题(如弓箭步的正确姿势),可以制作更详细的教程或FAQ。
主题二(回复、哈哈哈、谢谢、呼吸等)
观众互动性强,评论中出现大量的幽默和感谢,表明观众对视频内容的接受度较高。
商业价值:开发更多互动性强的内容,鼓励用户生成内容(UGC),如分享个人训练经历,形成社区效应。加强与用户的互动,通过定期举办直播问答或社区活动,提升用户粘性。
主题三(回复、呼吸、鼻子、感觉等)
讨论呼吸方法和跑步技巧,显示出观众对提高跑步效率的兴趣。
商业价值:可以开发关于呼吸训练的专门课程或App,帮助用户优化训练效果。提供专业的跑步和呼吸训练指导,如邀请专业教练进行指导视频拍摄。
主题四(现在、无语、可以、中考等)
关注中考体育考试,显示出学生观众群体的存在。
商业价值:推出针对中考体育训练的专项课程或辅导服务,帮助学生提高成绩。提供详细的中考体育训练计划和相关建议,缓解学生的训练压力。
主题五(大哭、回复、下肢、特别等)
讨论下肢训练和考试满分的相关内容,显示出观众对特定训练方法的关注。
商业价值:开发针对下肢训练的产品,如跑鞋、护膝等,并结合视频进行推广。提供科学的下肢训练方法和注意事项,防止受伤,提高训练效果。
主题六(回复、口水、但是、每天等)
观众关注日常训练的持续性和效果,如每天的跑步时间、耐力等。
商业价值:开发日常训练跟踪工具,如运动手环或应用程序,帮助用户记录和分析训练数据。提供个性化的训练建议,帮助用户制定合理的训练计划,提升训练效果。
主题七(老师、可以、心肺、回复等)
强调老师和训练建议,表明观众对专业指导的需求。
商业价值:推出在线训练课程,由专业教练提供指导,满足用户的需求。通过视频详细讲解训练技巧和方法,帮助用户提高心肺功能和耐力。
主题八(回复、满分、贺电、体育等)
强调中考体育成绩,显示出观众对考试结果的重视。
商业价值:开发针对体育考试的模拟测试和训练方案,帮助学生提高考试成绩。提供详细的考试准备指南和注意事项,帮助学生克服考试压力。
主题九(回复、就是、然后、系列等)
讨论系列视频内容和个人感受,表明观众对持续内容的兴趣。
商业价值:创建系列化的训练视频,逐步引导观众完成系统性的训练计划。提供完整的训练体系,从基础到高级,帮助用户逐步提高跑步成绩。
总结
通过对B站体育类视频评论的文本分析,可以发现观众不仅关注训练方法和效果,还渴望获得更多互动和指导。商业上,可以通过开发相关产品和服务来满足用户需求,并加强用户互动,形成良好的社区氛围。同时,通过提供专业、详细的训练指导和个性化的建议,可以帮助用户更好地解决训练中的问题,提高训练效果。
6 网络语义分析实现
利用了 NetworkX 和 Matplotlib 库创建了一个网络语义图,通过对文本数据的关键词进行分析和展示,展现了关键词之间的语义关联关系。可以清晰地观察关键词之间的关联情况,帮助用户更好地理解文本数据的内在含义和关联程度,为进一步的文本分析和挖掘提供了有力的工具和支持。
具体实现步骤如下:
6.1词频矩阵构建
首先,使用 CountVectorizer 对文本数据进行词频矩阵的计算,得到每个单词在文本中出现的频率。然后利用 TruncatedSVD 进行降维处理,将高维的词频矩阵转换为低维空间,以便于后续的关键词提取和网络构建。如下图所示:

6.2提取关键词及其频率信息
接着,提取了关键词及其频率信息,选取了出现频率最高的前50个关键词。这些关键词被视为网络语义图中的节点,节点的大小与关键词的频率相关。如下图所示

6.3构建网络图
随后,根据关键词的频率构建了网络语义图,采用了无向图的形式。其中每个关键词作为一个节点,边的权重表示两个关键词之间的语义联系强度。这里使用了最小频率来作为边的权重,以保持网络图的连通性和可视化效果。利用 NetworkX 和 Matplotlib 库绘制了关键词网络语义图。节点的位置通过 Spring Layout 算法确定,节点的大小反映了关键词的频率,边的粗细则表示了语义联系的强弱。整个过程展现了关键词之间的语义关联关系,为理解文本数据的语义结构提供了直观的可视化展示。效果图如下图所示

结果分析
基于对B站体育类视频《如何提速800米1000米》评论的语义网络分析结果,我们可以得出以下结论,涵盖了观众的反馈以及潜在的商业价值和问题解决方向。
1. 高频关键词:回复、呼吸、训练
观众反馈: 观众对视频内容的回复次数高,表明视频互动性强。同时,呼吸和训练是讨论的重点,说明观众对跑步技术和训练方法的关注。
商业价值: 可以开发专门的呼吸训练课程和应用,帮助用户提升跑步技巧。通过增强视频互动性,推出更多互动性强的内容,如实时直播和问答环节,进一步提高用户粘性。 提供详细的呼吸和训练指导视频,并在评论区积极与观众互动,解答常见问题,提升用户的体验。
2. 情感词汇:大哭、加油、哈哈哈
观众反馈: 评论中包含大量情感词汇,表明观众对视频内容有强烈的情感反应,既有积极的鼓励(如加油),也有可能是训练过程中的艰辛(如大哭)。
商业价值: 推出更多激励性质的内容,如成功案例分享和心理建设指导,帮助用户克服训练中的困难。在视频内容中加入更多的正能量元素,激励观众持续训练。同时,提供心理辅导和支持,帮助用户缓解训练压力。
3. 考试相关:满分、中考、体测、体考
观众反馈: 许多评论提到中考和体测,显示出大量学生观众关注体育考试成绩。
商业价值: 开发针对中考和体测的专项训练课程,提供个性化辅导服务,帮助学生提高考试成绩。 提供详细的中考和体测训练计划,并定期更新内容,帮助学生系统地准备考试。
4. 跑步技术:跑步、动作、速度、冲刺
观众反馈: 观众对跑步技术和动作的讨论较多,表明他们希望通过视频学习提高跑步速度和技巧。
商业价值: 开发跑步技术训练工具和设备,如智能跑步鞋和动作捕捉设备,结合视频推广,吸引用户购买。提供详细的跑步技术指导和分步骤教程,帮助观众掌握正确的跑步动作和提高速度。
5. 训练细节:时间、肌肉、心肺
观众反馈: 观众对训练时间、肌肉锻炼和心肺功能的讨论较多,显示出对训练效果的关注。
商业价值: 推出个性化训练计划和记录工具,如运动手环和健身应用,帮助用户跟踪训练进度和效果。 提供科学的训练计划和建议,帮助用户合理安排训练时间,并关注心肺功能和肌肉的全面锻炼。
6. 特殊需求:女生、脱单
观众反馈: 评论中提到女生和脱单,表明部分观众有特殊需求,希望通过跑步和训练提高自身吸引力。
商业价值: 开发针对不同用户群体(如女生)的专门训练课程和产品,满足他们的需求。 提供多样化的训练方案,满足不同用户的需求,并在视频中加入关于健康和自信的内容,帮助用户提升自身魅力。
总结
通过对B站《如何提速800米1000米》视频评论的语义网络分析,可以发现观众不仅关注跑步技术和训练方法,还渴望获得更多的互动和支持。商业上,可以通过开发相关产品和服务,如专门的训练课程、智能设备和个性化辅导,满足用户需求。同时,通过提供详细的指导和积极的互动,帮助用户更好地解决训练中的问题,提高训练效果。
总结与不足
总结
基于对B站体育类视频《如何提速800米1000米》评论的文本分析,利用Python爬虫、LDA主题分析、聚类分析和语义网络分析技术,我们能够深入理解观众的需求和反应,进而发现潜在的商业价值和问题解决方向。
互动性与用户参与
分析结果: 评论中高频出现“回复”“哈哈哈”“加油”等词汇,表明观众互动性强,参与度高。
商业价值: 可以通过推出更多互动内容,如直播问答、观众训练分享等,增强社区互动,提高用户粘性。
不足: 目前视频的互动形式较为单一,需增加多样化互动方式。
跑步技巧与训练方法
分析结果: 观众关注呼吸、训练、动作、速度等关键词,说明他们希望通过视频提高跑步技术。
商业价值: 开发专业的跑步训练课程和相关装备,如智能跑鞋、跑步动作矫正器等,结合视频推广。
不足: 视频内容在技术细节方面的指导仍不够全面,需增加更多实用性和专业性强的教程。
考试与成绩提升
分析结果: 大量评论提到中考、体测、满分等词汇,显示出学生观众对体育考试成绩的关注。
商业价值: 推出针对中考和体测的专项训练课程和辅导服务,帮助学生提高体育成绩。
不足: 目前针对考试的专项内容较少,需增加系统化、个性化的训练计划和模拟测试。
情感反应与心理支持
分析结果: 评论中出现“大哭”“真的”“难受”等词汇,表明观众在训练中有较强的情感反应。
商业价值: 推出心理辅导和激励内容,如成功案例分享、心理建设课程,帮助用户克服训练中的心理障碍。
不足: 目前视频缺乏对观众情感支持的内容,需增加更多激励和心理辅导的环节。
用户群体多样化需求
分析结果: 观众群体中包含女生、学生等特定群体,他们对训练有不同需求。
商业价值: 开发针对不同群体的专门训练课程和产品,如女生专属跑步训练、学生体育考试辅导等。
不足: 目前视频内容较为通用,未能充分考虑到不同用户群体的特定需求。
不足
内容深度不足
视频中的训练指导和技术细节仍需进一步深挖和细化,提供更多专业性强、实用性高的内容。
互动形式单一
视频互动形式较为单一,缺乏多样化的互动方式,需要通过直播、观众分享等方式增强互动性。
缺乏系统化训练计划
针对学生体育考试的系统化、个性化训练计划较少,需要提供更全面的考试准备内容。
情感支持不足
目前视频内容中缺乏对观众情感的支持,需增加心理辅导和激励内容,帮助用户克服训练中的心理障碍。
通过优化内容深度、丰富互动形式、增加系统化训练计划和情感支持,可以更好地满足观众需求,提升用户体验,并在商业上获得更大的成功。
相关文章:
基于B站视频评论的文本分析,采用包括文本聚类分析、LDA主题分析、网络语义分析
研究主题 本研究旨在通过对B站视频评论数据进行文本分析,揭示用户评论的主题、情感倾向和语义结构,助力商业决策。主要技术手段包括Python爬虫、LDA主题分析、聚类分析和语义网络分析。首先,利用Python爬虫采集大量评论数据并进行预处理。运…...

【Qt】xml Dom复制
1. 功能 将A.xml文件中的copyNode节点全部复制到B.xml中的testRoot节点。 2. 代码 #include <QDomDocument> #include <QFile> #include <QIODevice> #include <QtXml>void copyNodeXml() {// 源文件DOMQDomDocument ADoc;// 加载源文件QFile fileA(…...

MySQL联合索引最左匹配原则
MySQL中的联合索引(也叫组合索引)遵循最左匹配原则,即在创建联合索引时,查询条件必须从索引的最左边开始,否则索引不会被使用。在联合索引的情况下,数据是按照索引第一列排序,第一列数据相同时才会按照第二列排序。 例…...
)
2024最新最全面的软件测试自动化面试题(含答案)
1.如何把自动化测试在公司中实施并推广起来的? 选择长期的有稳定模块的项目 项目组调研选择自动化工具并开会演示demo案例,我们主要是演示selenium和robot framework两种。 搭建自动化测试框架,在项目中逐步开展自动化。 把该项目的自动化…...

Linux磁盘-MBRGPT
作者介绍:简历上没有一个精通的运维工程师。希望大家多多关注作者,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。 Linux磁盘涉及到的命令不是很多,但是在实际运维中的作用却很大,因为Linux系统及业务都会承载到硬盘上…...

kind kubernetes(k8s虚拟环境)使用本地docker的镜像
kubernetes中,虽然下载镜像使用docker,但是存储在docker image里的镜像是不能被k8s直接使用的,但是kind不同,可以使用下面的方法,让kind kubernetes环境使用docker image里的镜像。 kind – Quick Start 例如&#x…...

kafka发送消息流程
配置props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class); public Map<String,Object> producerConfigs(){Map<String,Object> props new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServers…...

使用Godot4组件制作竖版太空射击游戏_2D卷轴飞机射击-敌人生成器(八)
文章目录 开发思路敌人生成器代码分析属性配置 使用Godot4组件制作竖版太空射击游戏_2D卷轴飞机射击(一) 使用Godot4组件制作竖版太空射击游戏_2D卷轴飞机射击-激光组件(二) 使用Godot4组件制作竖版太空射击游戏_2D卷轴飞机射击-飞…...

Allegro中show elements不弹窗问题
今天allegro用的好好的,刚刚还可以正常使用show elements进行对象的详细信息查看的,突然就不好使了,具体表现为不弹窗。 找了好久找到一个类似问题的,具体的解决方法是: D:\Allegro\Cadence\SPB_Data\pcbenv在allegro的…...

【C++】继承最全解析(什么是继承?继承有什么用?)
目录 一、前言 二、什么是继承 ? 💢继承的概念💢 💢继承的定义💢 🥝定义格式 🍇继承权限 三、基类与派生类对象的赋值转换 四、继承的作用域 五、派生类中的默认成员函数 💢…...

STM32-外部中断浅析
本篇解释了STM32中断原理 MCU为什么需要中断 中断,是嵌入式系统中很重要的一个功能,在系统运行过程中,当出现需要立刻处理的情况时,暂停当前任务,转而处理紧急任务,处理完毕后,恢复之前的任务…...

Spring-Data-Elasticsearch
简介 Spring Data for Elasticsearch 是 Spring Data 项目的一部分,该项目旨在为新数据存储提供熟悉且一致的基于 Spring 的编程模型,同时保留特定于存储的特性和功能。 Spring Data Elasticsearch 项目提供了与 Elasticsearch 搜索引擎的集成。Spring…...

代码随想录二刷7.22|977.有序数组的平方
暴力解法: ——如果想暴力解决这个问题的话,可以像题目那样,先将每一个元素平方,然后再排序 双指针: ——从题目中找到的信息:这是一个非递减顺序的整数数组,从例子中,可以容易看…...

redis介绍与布署
redis remote dictionary server(远程字典服务器) 是一个开源的,使用c语言编写的非关系型数据库,支持内存运行并持久化,采用key-value的存储形式。 单进程模型意味着可以在一台服务器上启动多个redis进程,…...

PMON的解读和开发
提示:龙芯2K1000PMON相关记录 文章目录 1 PMON的发展和编译环境PMONPMON2000 2 PMON2000的目录结构3 Targets目录的组成4 PMON编译环境的建立5 PMON2000的框架6 异常向量表7 Pmon的空间分配8 PMON的汇编部分(starto.S或sbdreset.S)的解读Start.SC代码部分dbginit 9 …...

初识c++(构造函数,析构函数,拷贝构造函数,赋值运算符重载)
一、类的默认函数 默认成员函数就是用户没有显式实现,编译器会自动生成的成员函数称为默认成员函数。 #include<iostream> using namespace std; class Date { public:Date(){_year 1;_month 1;_day 1;cout << _year << "/" <&…...

CANoe:为什么两个VLAN接口不能设置同一个网络的IP地址呢?
经常玩CANoe的人应该配置过TCP/IP Stack中网络节点的网卡信息,基本的信息包含:MAC地址、IP地址、子网掩码、默认网关、MTU值、IPv6地址。 如果你想让发送出去的报文携带VLAN tag,可以在网卡上添加VLAN tag信息。 此时你就能得到两个新的网卡V…...

SpringBoot新手快速入门系列教程七:基于一个低配centoos服务器,如何通过宝塔面板部署一个SpringBoot项目
1,如何打包一个项目 通过IDEA自带的命令行,执行 ./gradlew clean build 2,检查生成的JAR文件 进入 build/libs 目录,你应该会看到一个类似 helloredis-0.0.1-SNAPSHOT.jar 的文件。 3:运行生成的JAR文件 你可以在…...
(二))
性能测试的流程(企业真实流程详解)(二)
性能测试的流程 1.需求分析以及需求确定(指标值,场景,环境,人员) 一般提出需求的人员有:客户,产品经理,项目组领导等 2.性能测试计划和方案制定 基准测试: 负觋测试: 压力测试: 稳定性测试: 其他:配置测试…...

使用sklearn的基本流程
scikit-learn,通常简称为 sklearn,是一个开源的Python库,是基于 Python 编程语言的一个非常流行的机器学习库。它建立在 NumPy 和 SciPy 这两个科学计算库之上,并与 Matplotlib 配合使用,为数据预处理、模型训练、评估…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...
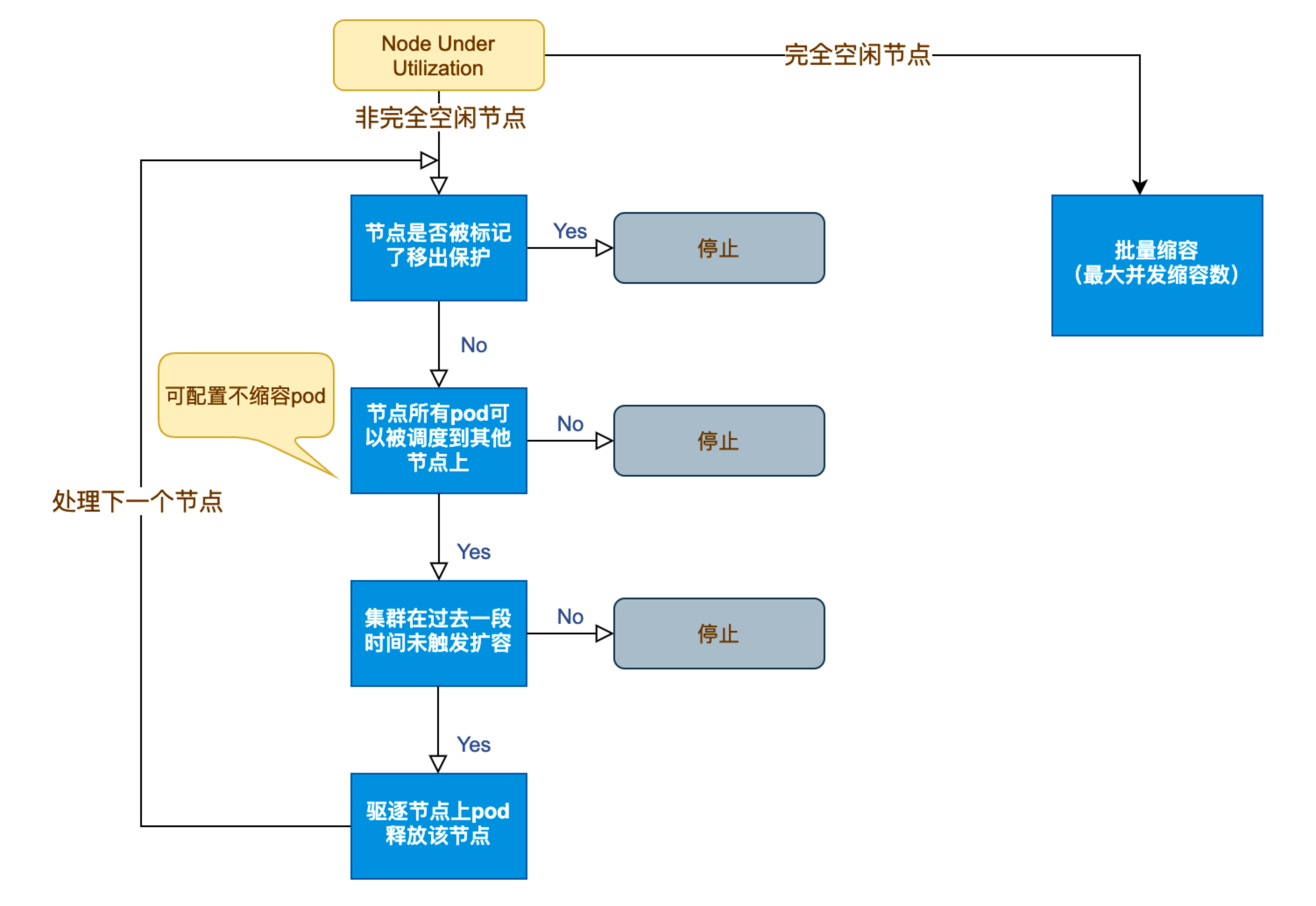
Kubernetes 节点自动伸缩(Cluster Autoscaler)原理与实践
在 Kubernetes 集群中,如何在保障应用高可用的同时有效地管理资源,一直是运维人员和开发者关注的重点。随着微服务架构的普及,集群内各个服务的负载波动日趋明显,传统的手动扩缩容方式已无法满足实时性和弹性需求。 Cluster Auto…...