【深度学习】图形模型基础(5):线性回归模型第三部分:线性回归模型拟合
1.引言
本博文专辑的焦点主要集中在回归模型的实用案例和工具上,从简单的单变量线性回归入手,逐步过渡到包含多个预测变量、非线性模型,以及在预测和因果推断中的应用。本文我们将介绍回归模型推断的一些数学结构,并提供一些代数知识以帮助理解线性回归的估计方法。此外,我们还将解释贝叶斯拟合程序stan_glm的使用理由,以及它与传统线性回归的联系。因此,本文为全专辑其余部分使用的数学和计算工具提供了背景和动机。
2. 最小二乘法、最大似然估计和贝叶斯推断
现在我们暂时退后一步,来审视一下推断过程:估计回归模型并评估拟合的不确定性。我们从最小二乘法开始,这是最直接的估计方法,它基于寻找最适合数据的系数 a a a和 b b b的值。然后,我们将讨论最大似然估计,这是一个更普遍的框架,它将最小二乘法作为一个特例。当我们在后面的章节中讨论逻辑回归和广义线性模型时,会再次回到这个框架。接着,我们将转向贝叶斯推断,这是一种更为通用的方法,它允许我们以概率的形式表达先验信息和后验不确定性。
2.1.最小二乘法
在经典线性回归模型中, y i = a + b x i + ϵ i y_i = a + bx_i + \epsilon_i yi=a+bxi+ϵi,系数 a a a和 b b b被估计以最小化误差 ϵ i \epsilon_i ϵi。如果数据点的数量 n n n大于2,通常不可能找到一条完美拟合所有数据点的线,因此,通常的估计目标是选择估计值 a ^ , b ^ \hat{a}, \hat{b} a^,b^,使得残差平方和最小化:
r i = y i − ( a ^ + b ^ x i ) r_i = y_i - (\hat{a} + \hat{b}x_i) ri=yi−(a^+b^xi)
我们区分残差 r i = y i − ( a ^ + b ^ x i ) r_i = y_i - (\hat{a} + \hat{b}x_i) ri=yi−(a^+b^xi)和误差 ϵ i = y i − ( a + b x i ) \epsilon_i = y_i - (a + bx_i) ϵi=yi−(a+bxi)。模型以误差为单位编写,但我们只能处理残差:我们无法计算误差,因为这样做需要知道 a a a和 b b b。
残差平方和为:
RSS = ∑ i = 1 n ( y i − ( a ^ + b ^ x i ) ) 2 (2.1) \text{RSS} = \sum_{i=1}^{n} (y_i - (\hat{a} + \hat{b}x_i))^2\tag{2.1} RSS=i=1∑n(yi−(a^+b^xi))2(2.1)
最小化RSS的 a ^ , b ^ \hat{a}, \hat{b} a^,b^称为最小二乘估计或普通最小二乘OLS估计,可以用矩阵表示法写成:
β ^ = ( X t X ) − 1 X t y , (2.2) \hat{\beta} = (X^t X)^{-1}X^t y,\tag{2.2} β^=(XtX)−1Xty,(2.2)
其中 β = ( a , b ) \beta = (a, b) β=(a,b)是系数向量,X是回归中的预测变量矩阵。在这个表示法中,1代表一列单位值——回归中的常数项——必须被包含,因为我们拟合的模型既有截距也有斜率。
对于只有一个预测变量的回归,我们可以将解决方案写成:
b ^ = ∑ i = 1 n ( x i − x ˉ ) y i ∑ i = 1 n ( x i − x ˉ ) 2 , (2.3) \hat{b} = \frac{\sum_{i=1}^{n} (x_i - \bar{x}) y_i}{\sum_{i=1}^{n} (x_i - \bar{x})^2},\tag{2.3} b^=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)yi,(2.3)
a ^ = y ˉ − b ^ x ˉ . (2.4) \hat{a} = \bar{y} - \hat{b}\bar{x}.\tag{2.4} a^=yˉ−b^xˉ.(2.4)
然后我们可以将最小二乘线写成:
y i = y ˉ + b ^ ( x i − x ˉ ) + r i ; y_i = \bar{y} + \hat{b} (x_i - \bar{x}) + r_i; yi=yˉ+b^(xi−xˉ)+ri;
因此,这条线穿过数据的平均值( x ˉ , y ˉ \bar{x}, \bar{y} xˉ,yˉ)。
公式(2.2)和特殊情况(2.3)-(2.4)可以直接使用微积分推导出来,作为最小化残差平方和问题的解决方案。在实践中,这些计算是使用R或其他软件中的高效矩阵解决方案算法完成的。
2.1.1.估计残差标准差σ
在回归模型中,误差 ϵ i \epsilon_i ϵi来自均值为0、标准差为σ的分布:均值为零是定义上的(任何非零均值都被吸收到截距a中),误差的标准差可以从数据中估计。估计σ的一种自然方法是简单地取残差的标准差,但这样会因为过度拟合而轻微低估σ,因为系数 a ^ \hat{a} a^和 b ^ \hat{b} b^已经根据数据设置,以最小化残差平方和。对此过度拟合的标准校正是将分母中的n替换为n-2,因此:
σ ^ = 1 n − 2 ∑ i = 1 n ( y i − ( a ^ + b ^ x i ) ) 2 . (2.5) \hat{\sigma} = \sqrt{\frac{1}{n - 2} \sum_{i=1}^{n} (y_i - (\hat{a} + \hat{b}x_i))^2}.\tag{2.5} σ^=n−21i=1∑n(yi−(a^+b^xi))2.(2.5)
当n=1或2时,这个表达式没有意义,这是有道理的:用仅有的两个数据点,你可以完全拟合一条线,所以没有办法仅从数据中估计误差。
更一般地,在具有k个预测变量的回归中,表达式变为:
σ ^ = 1 n − k ∑ i = 1 n ( y i − ( X i β ^ ) ) 2 , \hat{\sigma} = \sqrt{\frac{1}{n-k} \sum_{i=1}^{n} (y_i - (X_i \hat{\beta}))^2}, σ^=n−k1i=1∑n(yi−(Xiβ^))2,
分母中使用n-k而不是n,以调整通过最小二乘法拟合的k个系数。
2.1.2.直接计算平方和
可以使用公式(2.2)直接计算系数的最小二乘估计。但是为了加深理解,编写一个R函数来计算平方和,然后尝试不同的a和b值可能会有所帮助。
首先我们编写函数,我们称之为rss,表示“残差平方和”:
rss <- function(x, y, a, b){ # x和y是向量,a和b是标量resid <- y - (a + b*x)return(sum(resid^2))
}
我们编写的函数虽然简单,但仅适合个人探索性分析,并不推荐在生产环境中使用。原因在于,该函数尚未包含对输入数据的基础校验,例如,没有检查输入的x和y是否为等长向量,也没有处理可能存在的缺失数据(即NA值)。如果没有严格按照预期输入参数,函数将完全依赖R语言的默认行为。尽管如此,对于我们自己的探索性分析,这个基础函数已经足够使用。
我们可以通过以下方式尝试使用该函数:
rss(hibbs$growth, hibbs$vote, 46.2, 3.1)
这将计算在最小二乘估计下,参数(a, b)分别为(46.2, 3.1)时的残差平方和。我们可以尝试不同的(a, b)值组合,来检验是否能够获得比当前数据更低的残差平方和。
2.2.最大似然估计
当线性模型的误差项独立且呈正态分布时,即对于每个观测点i, y i y_i yi 服从 normal ( a + b x i , σ ) \text{normal}(a + bx_i, \sigma) normal(a+bxi,σ),此时最小二乘估计同样也是最大似然估计。在回归模型中,似然函数定义为给定参数和预测变量的条件下数据的概率密度。例如:
p ( y ∣ a , b , σ , X ) = ∏ i = 1 n normal ( y i ∣ a + b x i , σ ) (2.6) p(y|a, b, \sigma, X) = \prod_{i=1}^{n} \text{normal}(y_i | a + bx_i, \sigma)\tag{2.6} p(y∣a,b,σ,X)=i=1∏nnormal(yi∣a+bxi,σ)(2.6)
其中, normal ( y ∣ m , σ ) \text{normal}(y | m, \sigma) normal(y∣m,σ) 表示正态概率密度函数:
normal ( y ∣ m , σ ) = 1 2 π σ 2 exp ( − ( y − m ) 2 2 σ 2 ) (2.7) \text{normal}(y | m, \sigma) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y - m)^2}{2\sigma^2}\right)\tag{2.7} normal(y∣m,σ)=2πσ21exp(−2σ2(y−m)2)(2.7)
在拟合回归模型时,σ的最大似然估计为:
1 n ∑ i = 1 n ( y i − ( a ^ + b ^ x i ) ) 2 \frac{1}{n} \sum_{i=1}^{n} (y_i - (\hat{a} + \hat{b}x_i))^2 n1∑i=1n(yi−(a^+b^xi))2
注意,这里没有应用(8.5)节中提到的 1 n − 2 \frac{1}{n-2} n−21 的调整因子。
2.3.贝叶斯推断
贝叶斯推断在考虑模型中每个参数的不确定性时,自动将其他参数的不确定性纳入考量,这一特性对于包含多个预测变量的模型以及更高级和复杂的层次模型尤为重要。
在最大似然估计中,似然函数可以类比为一座山峰,其峰顶对应最大似然估计值。图2.1a展示了一个简单示例中a和b系数的似然函数。尽管模型实际上有三个参数——a、b和σ——但为了简化,我们展示了在给定估计的 σ ^ \hat{\sigma} σ^ 的条件下a和b的似然。

图2.1 (a) 线性回归模型 y = a + b x + error y = a + bx + \text{error} y=a+bx+error 中参数 a a a 和 b b b 的似然函数图,其中 y i y_i yi 表示选举结果, x i x_i xi 表示经济增长。(b) 似然函数的众数(即最大似然估计 ( a ^ , b ^ ) (\hat{a}, \hat{b}) (a^,b^)),每个参数都显示了±1个标准误差条。© 似然函数的众数,用一个椭圆来概括众数处对数似然函数的逆二阶导数矩阵。

图2.2 (a) 重复自图7.2b的选举数据及其线性拟合线, y = 46.3 + 3.0 x y = 46.3 + 3.0x y=46.3+3.0x。(b) 几条与数据大致一致的线。当斜率较高时,截距(即当 x = 0 x=0 x=0时的线值)较低;因此,在似然函数中, a a a 和 b b b 之间存在负相关。
贝叶斯推断不仅结合了先验信息,而且通过概率表达不确定性,这为我们提供了一种灵活的方式来传播不确定性并进行推断。使用stan_glm拟合模型时,我们得到的是一组模拟抽样,这些抽样代表了参数的后验分布,通常我们会使用中位数、中位数绝对偏差(MAD)以及基于这些模拟的不确定性区间来总结后验分布。
2.4.点估计与后验模拟
最小二乘解提供了一个点估计,即最佳拟合数据的系数向量。对于贝叶斯模型,相应的点估计是后验模,它综合了数据和先验分布,提供了最佳的整体拟合。最小二乘或最大似然估计可以视为具有均匀或平坦先验分布的模型的后验模的特例。
我们不仅需要估计值,还需要估计的不确定性。对于单参数模型,不确定性可以用估计值加减标准误差来表示;而对于多参数模型,我们通常使用钟形概率分布来表示不确定性,如图8.1所示。
在后续的博文中,我们将更全面地讨论如何使用基于模的近似或后验分布的模拟来总结不确定性。默认情况下,使用stan_glm拟合模型时,我们得到的后验模拟会通过中位数和mad sd进行总结。
3. 回归拟合中个别数据点的影响
在最小二乘法中,我们通过公式(2.3)和(2.4)得到了 a ^ \hat{a} a^和 b ^ \hat{b} b^,这两个估计的回归系数实际上是原始数据点 y y y的线性函数。我们可以利用这些线性关系来评估每个数据点对回归系数的影响,特别是它们是如何影响斜率 b ^ \hat{b} b^的估计。
我们可以从公式(2.3)看出,数据点 y i y_i yi每增加1个单位,对斜率 b ^ \hat{b} b^的影响与 ( x i − x ˉ ) (x_i - \bar{x}) (xi−xˉ)成正比。具体来说:
- 当 x i = x ˉ x_i = \bar{x} xi=xˉ时,即数据点位于所有数据点的中心位置,它对斜率的影响为零。这是因为中心位置的点上下移动并不会影响拟合线的倾斜程度。
- 当 x i > x ˉ x_i > \bar{x} xi>xˉ时,数据点 i i i对斜率的影响是正向的,且随着 x i x_i xi与均值 x ˉ \bar{x} xˉ的差距增大,其影响力也随之增大。
- 当 x i < x ˉ x_i < \bar{x} xi<xˉ时,数据点 i i i对斜率的影响是负向的,且 x i x_i xi与均值 x ˉ \bar{x} xˉ的差距越大,其负向影响力也越大。
影响力可以通过一个形象的比喻来理解:将拟合的回归线想象为通过橡皮筋与数据点相连的一根杆,当个别数据点上下移动时,我们可以观察到这根杆的位置和方向是如何变化的,如图2.3所示。

图2.3 理解单个数据点对拟合回归线的影响。将垂直线想象成将每个数据点与最小二乘线相连的橡皮筋。取图表左侧的一个点并将其向上移动,线的斜率将会减小。取图表右侧的一个点并将其向上移动,线的斜率将会增加。将图表中心的一个点向上或向下移动,不会影响拟合线的斜率。
对于多元回归模型,我们可以使用矩阵表达式(公式2.2)来计算影响力,这会揭示出估计的回归系数向量 β ^ \hat{\beta} β^是如何作为数据向量 y y y的线性函数。对于广义线性模型,我们可以通过逐个改变数据点后重新拟合回归模型来计算每个点的影响力。
这种分析方法不仅适用于线性回归模型,也可以扩展到更复杂的回归分析中,帮助我们识别和理解哪些数据点对模型的拟合有显著影响,从而对模型的稳健性进行评估。
4. 最小二乘斜率
在前面的博文中,我们讨论了当使用指示变量进行回归分析时,最小二乘估计系数b实际上代表了两组间结果的平均差异。现在,让我们将这一概念扩展到连续变量的情况,将最小二乘估计的斜率视为数据中各对斜率的加权平均。
4.1.基本思想
假设我们有n个数据点 ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) (x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n) (x1,y1),(x2,y2),…,(xn,yn),这些点之间可以形成 n 2 n^2 n2对组合,每对数据点 ( x i , y i ) (x_i, y_i) (xi,yi)和 ( x j , y j ) (x_j, y_j) (xj,yj)可以确定一条直线的斜率,计算公式如下:
[ \text{slope}_{ij} = \frac{y_j - y_i}{x_j - x_i} ]
这里需要注意的是,当 x i = x j x_i = x_j xi=xj时,即两个数据点在x轴上重合时,斜率公式是未定义的。然而,这种情况在我们的计算中会被自然排除。
4.2.加权平均斜率
为了确定最佳拟合的回归斜率,我们可以将所有这些个别的斜率进行平均。但更合理的做法是使用加权平均,即根据两个数据点在x轴上的距离来赋予不同的权重。具体来说,如果两个点在x轴上的距离越远,那么它们之间的斜率在计算平均斜率时所占的权重就越大。
基于这一思想,我们可以将斜率 slope i j \text{slope}_{ij} slopeij乘以 ( x j − x i ) 2 (x_j - x_i)^2 (xj−xi)2作为权重,然后计算加权平均值:
weighted average of slopes = ∑ i , j ( x j − x i ) 2 ⋅ slope i j ∑ i , j ( x j − x i ) 2 \text{weighted average of slopes} = \frac{\sum_{i,j} (x_j - x_i)^2 \cdot \text{slope}_{ij}}{\sum_{i,j} (x_j - x_i)^2} weighted average of slopes=∑i,j(xj−xi)2∑i,j(xj−xi)2⋅slopeij
进一步简化,我们可以将分子和分母中的 ( x j − x i ) (x_j - x_i) (xj−xi)相约去,得到:
weighted average of slopes = ∑ i , j ( x j − x i ) ( y j − y i ) ∑ i , j ( x j − x i ) 2 (2.8) \text{weighted average of slopes} = \frac{\sum_{i,j} (x_j - x_i)(y_j - y_i)}{\sum_{i,j} (x_j - x_i)^2}\tag{2.8} weighted average of slopes=∑i,j(xj−xi)2∑i,j(xj−xi)(yj−yi)(2.8)
4.3.与最小二乘估计的联系
经过仔细的项收集和整理,我们可以证明上述加权平均斜率的表达式实际上与最小二乘估计的斜率 b ^ \hat{b} b^相同(如公式(2.3)所示)。因此,我们可以将估计的系数 b ^ \hat{b} b^理解为数据中的加权平均斜率,同时将参数b视为总体中的加权平均斜率。
这种理解为我们提供了一种新的视角,让我们认识到最小二乘估计不仅仅是一个数学操作,而是在数据中寻找一种平衡,这种平衡体现在对每一对数据点之间斜率的加权平均上。这种方法不仅适用于线性回归,还可以推广到更广泛的统计分析中。
5. 使用lm和stan_glm拟合函数的比较
在R语言中,lm函数是执行线性回归的标准工具,它基于经典最小二乘法进行参数估计并提供标准误差。这与我们在之前关于回归分析的书籍中使用的方法一致,并且几乎所有统计软件都提供了类似的功能。然而,在本书中,我们采用了stan_glm函数,它不仅执行贝叶斯推断,还提供估计值、标准误差和后验模拟。
选择stan_glm的原因有两个。首先,该函数自动计算的模拟结果能够表示不确定性,这不仅可以用于获取当前数据的预测分布,还可以预测未来数据和参数。其次,贝叶斯推断可以整合先验信息,从而得到更稳定的估计和预测结果。我们将在后续的文章中详细讨论贝叶斯推断的这两个方面,并展示如何使用stan_glm进行概率预测和表达回归分析中的先验信息。
对于许多简单问题,经典推断和贝叶斯推断的结果基本相同。例如,在之前的博文中,我们使用stan_glm的默认设置拟合了收入、身高和经济增长等数据的回归模型。如果使用lm,也会得到几乎相同的结果。这是因为stan_glm的默认先验较弱,因此在这些例子中,它与最大似然估计的推断结果相似。默认先验的主要作用是在一些特殊情况下(如接近完全共线性)保持系数估计的稳定性。
然而,当数据较弱或先验信息较强时,贝叶斯推断的差异就更加明显。此外,在高级和层次模型中,经典推断和贝叶斯推断之间的差异更大,因为更复杂的模型可能包含潜在的或弱识别的参数,贝叶斯推断结构可以提供更平滑的估计。高级和多级模型随着样本量的增加而变得更加复杂,因此即使在大型数据集中,贝叶斯推断也可能发挥重要作用。
5.1.使用平直先验和优化重现最大似然估计
下面我们展示如何使用stan_glm在贝叶斯和经典估计之间架起桥梁。对于数据框mydata的默认回归拟合是:
stan_glm(y ~ x, data = mydata)
如果我们希望stan_glm更接近经典推断,可以使用平直先验,这样后验分布就与似然相同。函数调用如下:
stan_glm(y ~ x, data = mydata, prior_intercept = NULL, prior = NULL, prior_aux = NULL)
这里,三个不同的NULL值分别为截距、模型中的其他系数以及σ设置了平直先验。
为了更接近标准回归,我们可以指示Stan执行优化而不是抽样,这将产生最大惩罚似然估计,在平直先验的情况下,它就是最大似然估计:
stan_glm(y ~ x, data = mydata, prior_intercept = NULL, prior = NULL, prior_aux = NULL, algorithm = "optimizing")
如果你只对最大似然估计感兴趣,并且对概率预测没有需求,也可以使用R中的lm函数来拟合回归:
lm(y ~ x, data = mydata)
然而,通常我们更倾向于使用stan_glm,因为它允许我们在参数和数据的函数中传播不确定性。
5.2.置信区间、不确定性区间和兼容性区间
在前文的讨论中,我们讨论了置信区间的基本概念,它是一种表达推断不确定性的方法。基于无偏、正态分布估计的假设,一个估计值加减1个标准误差大约有68%的概率包含被估计量的真实值,而加减2个标准误差大约有95%的概率覆盖真实值。
在线性回归中,残差标准差σ的估计本身也存在误差。如果一个具有k个系数的回归模型拟合到n个数据点,那么就有n-k个自由度。回归系数的置信区间使用 t n − k t_{n-k} tn−k分布来构建。例如,模型 y = a + b x + error y = a + bx + \text{error} y=a+bx+error有两个系数;如果它拟合到10个数据点,那么在R中输入qt(0.975, 8)将得到2.31,因此这些系数的95%置信区间是估计值加减2.31个标准误差。
使用stan_glm拟合模型时,我们可以使用中位数加减1或2个mad sd来获得近似的68%和95%区间,或者我们可以直接从模拟中构建区间。stan_glm的拟合结果产生一个模拟矩阵,每一列对应模型中的一个参数。例如:
x <- 1:10
y <- c(1, 1, 2, 3, 5, 8, 13, 21, 34, 55)
fake <- data.frame(x, y)
fit <- stan_glm(y ~ x, data = fake)
这将产生:
Median MAD_SD
(Intercept) -13.8 6.7
x 5.1 1.1
Auxiliary parameter(s):
Median MAD_SD
sigma 10.0 2.5
然后我们可以提取模拟结果:
sims <- as.matrix(fit)
sims矩阵有三列,包含截距、x的系数和残差标准差σ的模拟。要提取x的系数的95%区间,可以输入:
quantile(sims[, "x"], c(0.025, 0.975))
这将返回区间[2.6, 7.5],与使用中位数和mad sd得到的近似值[5.1 ± 2 × 1.1]相近。
上述讨论的所有置信区间都可以称为“不确定性区间”,因为它们代表了对被估计量的不确定性;或者称为“兼容性区间”,因为它们提供了与观测数据最兼容的参数值范围。
6.文献注释
在统计学和计量经济学的教育领域,有诸多经典教材对最小二乘法和最大似然估计进行了详尽的推导,例如Neter等人的著作(1996年)不仅阐释了这些估计方法,还深入讲解了其背后的矩阵代数基础。随着统计学理论的发展,一些学者开始寻求对传统概念的现代化解释。Gelman和Greenland(2019年)以及Greenland单独的著作(2019年)提出了使用“不确定性区间”和“兼容性区间”来替代传统的“置信区间”,以更准确地传达统计推断中的不确定性。
此外,对于贝叶斯统计学中的后验分布估计,Gelman等人(2013年)在他们的作品中介绍了汉密尔顿蒙特卡洛(Hamiltonian Monte Carlo)抽样方法,这是一种高效的后验模拟技术,以及如何进行收敛性诊断以确保估计的准确性。对于那些对stan_glm函数的具体算法实现细节感兴趣的读者,可以查阅Stan开发团队(2020年)提供的文档。而对于lm函数的背景知识,R核心团队(2019年)的资料提供了全面的解读。
通过这些文献,读者不仅能够获得关于回归分析技术的历史背景和理论基础,还能够了解到当前统计学界在数据处理和推断上的最前沿方法和思考。
相关文章:
【深度学习】图形模型基础(5):线性回归模型第三部分:线性回归模型拟合
1.引言 本博文专辑的焦点主要集中在回归模型的实用案例和工具上,从简单的单变量线性回归入手,逐步过渡到包含多个预测变量、非线性模型,以及在预测和因果推断中的应用。本文我们将介绍回归模型推断的一些数学结构,并提供一些代数…...

【Git 入门】初始化配置与新建仓库
文章目录 前言配置git新建仓库仓库的概念创建仓库命令总结前言 在现代软件开发中,版本控制系统已经成为了不可或缺的工具。其中,Git 是最为广泛使用的版本控制系统之一。Git 不仅可以帮助我们管理和跟踪代码的变化,还可以方便地与他人协作。本文将介绍 Git 的基础知识,包括…...

C语言 求两个整数的最大公约数和最小公倍数
写两个函数,分别求两个整数的最大公约数和最小公倍数,用主函数调用这两个函数,并输出结果。两个整数由键盘输入。 #include <stdio.h>// 求最大公约数 int gcd(int a, int b) {while (b ! 0) {int temp b;b a % b;a temp;}return a; }// 求最小公倍数 int lcm(int a,…...

Linux arm64平台指令替换函数 aarch64_insn_patch_text_nosync
文章目录 前言一、简介1.1 aarch64_insn_patch_text_nosync1.2 aarch64_insn_write1.3 patch_map1.4 set_fixmap_offset1.5 __set_fixmap 二、用途2.1 jump lable2.2 ftrace 参考资料 前言 这篇文章介绍了 Linux x86_64平台指令替换函数 text_poke_smp/bp 接下来介绍arm64平台…...

谷歌浏览器插件开发笔记0.1.033
谷歌浏览器插件开发笔记0.1.000 示例文件manifest.jsonpopup.htmloptions.jsoptions.htmlcontent.jsbackground.js 网页按钮快捷键插件api使用基础参考链接 示例文件 共计有6个常用的文件 manifest.json background字段:随着浏览器的打开而打开,随着浏…...

ETag:Springboot接口如何添加Tag
ETag简介 在Web开发中,ETag(Entity Tag)是一种HTTP头字段,用于标识特定版本的资源。ETag的主要用途是缓存控制和优化,通过比较客户端和服务器资源的ETag值,可以判断资源是否发生变化,从而避免不…...
JavaSe系列二十七: Java正则表达式
正则表达式 为什么要学习正则表达式再提几个问题解决之道-正则表达式正则表达式基本介绍介绍 正则表达式底层实现实例分析 正则表达式语法基本介绍元字符-转义号 \\\\元字符-字符匹配符元字符-选择匹配符元字符-限定符元字符-定位符分组非贪婪匹配 应用实例对字符串进行如下验证…...
Depth Anything V2 复现)
(深度估计学习)Depth Anything V2 复现
Depth Anything V2 复现 一、配置环境二、准备数据1. 权重文件2. 训练数据 三、Test四、Train 代码:https://github.com/DepthAnything/Depth-Anything-V2 一、配置环境 在本机电脑win跑之后依旧爆显存,放到服务器跑:Ubuntu22.04,…...

C语言——printf、scanf、其他输入输出函数
printf函数 1.printf 函数的一般格式: printf 函数的一般格式为printf(格式控制,输出表列) 例如: printf("%d,%c\n",i,c); (1)“格式控制" 是用双撇号括起来的一个字符串,称“转换控制字符串”,简称“格式字符串”。它包括…...

adb 常用的命令总结
1、adb logcat 抓取日志 adb logcat > d:\log.txt Ctrlc 结束日志抓取 adb logcat -c > d:\log.txt 清空旧日志 发生Native Crash 时,抓取错误报告 adb logcat -b crash 抓取筛选后的日志: adb logcat -s AndroidRuntime > d:\log…...

Java发展过程中,JVM的演进
1. 初期的JVM(Java 1.0 到 Java 1.1) Java 1.0 于1996年发布,最初的JVM设计主要是为了跨平台兼容性和基本的垃圾回收功能。早期的JVM以解释执行字节码为主,性能相对较低。 2. 引入即时编译(JIT)ÿ…...

笔记:在Entity Framework Core中如何处理多线程操作DbContext
一、目的: 在使用Entity Framework Core (EF Core) 进行多线程操作时,需要特别注意,因为DbContext类并不是线程安全的。这意味着,你不能从多个线程同时使用同一个DbContext实例进行操作。尝试这样做可能会导致数据损坏、异常或不可…...

RabbitMQ 高级功能
RabbitMQ 是一个广泛使用的开源消息代理,它支持多种消息传递协议,可以在分布式系统中用于可靠的消息传递。除了基本的消息队列功能外,RabbitMQ 还提供了一些高级功能,增强了其在高可用性、扩展性和灵活性方面的能力。以下是一些主…...

软件架构之开发管理
软件架构之开发管理 第 13 章:开发管理13.1 项目的范围、时间与成本13.1.1 项目范围管理13.1.2 项目成本管理13.1.3 项目时间管理 13.2 配置管理与文档管理13.2.1 软件配置管理的概念13.2.2 软件配置管理的解决方案13.2.3 软件文档管理 13.3 软件需求管理13.3.1 需求…...

【Linux 基础】df -h 的输出信息解读
df -h 的输出信息 xxx:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 16G 0 16G 0% /dev tmpfs 3.2G 792K 3.2G 1% /run /dev/sda1 32G 1.7G 30G 6% / tmpfs 16G 0 16G 0% /dev/shm tmp…...

南航秋招指南,线上测评和线下考试
南航秋招简介 南航作为国内一流的航空公司,对人才的需求量非常旺盛,每年也有很多专业对口的工作提供给应届毕业生,对于应届毕业生而言,一定要抓住任何一个应聘机会,并且在规定的范围内进行简历的提交,以便…...
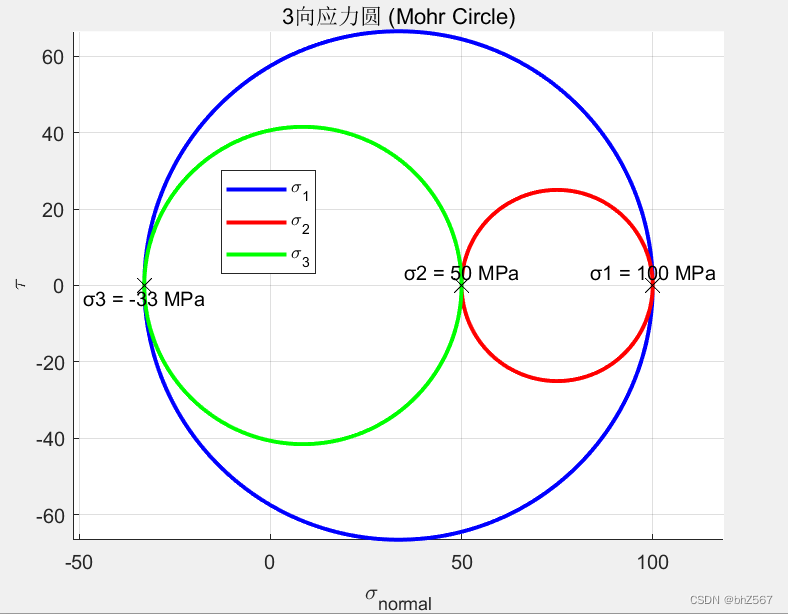
用MATLAB绘制三向应力圆
% 定义主应力值 sigma1 100; % MPa sigma2 50; % MPa sigma3 -33; % MPa sigma_m1(sigma1 sigma3)/2; sigma_m2(sigma1 sigma2)/2; sigma_m3(sigma2 sigma3)/2; % 计算半径 r1 (sigma1 - sigma3) / 2; r2 (sigma1 - sigma2) / 2; r3 (sigma2 - sigma3…...

PyTorch 1-深度学习
深度学习-PyTorch 一: Pytorch1> pytorch简介2> PyTorch 特点&优势3> pytorch简史4> pytorch 库5> PyTorch执行流程6> PyTorch 层次结构二: PyTorch常用的高级API和函数1> 自动求导(Autograd)2> 模型容器(Module)3> 优化器(Optimizer)4&g…...
Hi3861鸿蒙开发环境搭建
1.1 安装配置Visual Studio Code 打开Download Visual Studio Code - Mac, Linux, Windows选择下载安装Windows系统的Visual Studio Code。 下载后进行安装。Visual Studio Code安装完成后,通过内置的插件市场搜索并安装开发所需的插件如图所示: 1.2 安…...

解决RedisTemplate配置JSON序列化后@Cacheable序列化仍然是JDK序列化的问题
问题现象 在参考网上的Redis集成后,配置了RedisTemplate的序列化,配置成功后Cacheable注解的缓存仍然是jdk的序列化,配置无效。 参考配置的类似代码: Bean("redisTemplate") public RedisTemplate<Object, Objec…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...