GCN、GIN
# 使用TuDataset 中的PROTEINS数据集。
# 里边有1113个蛋白质图,区分是否为酶,即二分类问题。# 导包
from torch_geometric.datasets import TUDataset
from torch_geometric.data import DataLoader
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Linear,Sequential,BatchNorm1d,ReLU,Dropout
from torch_geometric.nn import GCNConv,GINConv
from torch_geometric.nn import global_mean_pool,global_add_pool# 导入数据集
dataset = TUDataset(root='',name='PROTEINS').shuffle()
# 观测图数据
print(f'Dataset:{dataset}')
print(f'Number of graphs:{len(dataset)}')
print(f'Number of nodes:{dataset[1].x.shape[0]}') # 这是针对于第一个图来说,每个图的节点数会不同
print(f'Number of features:{dataset.num_features}')
print(f'Number of classes:{dataset.num_classes}')# 一个大的数据集进行拆分,按照 8 :1 :1的比列分为训练集,验证集和测试集
train_dataset = dataset[:int(len(dataset)*0.8)]
val_dataset = dataset[int(len(dataset)*0.8):int(len(dataset)*0.9)]
test_dataset = dataset[int(len(dataset)*0.9):]
# 打印验证:
print('----------------------------------------------')
print(f'training set ={len(train_dataset)} graphs') # 890
print(f'validation set ={len(val_dataset)} graphs')# 111
print(f'test set ={len(test_dataset)} graphs')# 112
# 进行批处理,每个批次最多64个图
train_loader = DataLoader(train_dataset,batch_size=64,shuffle=True)
val_loader = DataLoader(val_dataset,batch_size=64,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=64,shuffle=True)# 打印验证一下:
print('------------------------------------------------')
print('\nTrain Loader')
for i,batch in enumerate(train_loader):print(f'-Batch{i}:{batch}')
print('\nVadidation Loader')
for i,batch in enumerate(val_loader):print(f'-Batch{i}:{batch}')
print('\nTest Loader')
for i,batch in enumerate(test_loader):print(f'-Batch{i}:{batch}')# 来咯,构建GCN模型,进行分类
class GCN(nn.Module):def __init__(self,dim_h):super().__init__()self.conv1 = GCNConv(dataset.num_features,dim_h)self.conv2 = GCNConv(dim_h,dim_h)self.conv3 = GCNConv(dim_h,dim_h)self.lin = Linear(dim_h,dataset.num_classes)def forward(self,x,edge_index,batch):h = self.conv1(x,edge_index)h = h.relu()h = self.conv2(h,edge_index)h = h.relu()h = self.conv3(h,edge_index)# global_mean_pool 适合用于一些数据分布不平衡的数据hG = global_mean_pool(h,batch)# 分类h = F.dropout(hG,p=0.5,training=self.training)h = self.lin(h)return F.log_softmax(h,dim=1)# 定义GIN模型
class GIN(nn.Module):def __init__(self,dim_h):super().__init__()self.conv1 = GINConv(Sequential(Linear(dataset.num_features,dim_h),BatchNorm1d(dim_h),ReLU(),Linear(dim_h,dim_h),ReLU()))self.conv2 = GINConv(Sequential(Linear(dim_h, dim_h),BatchNorm1d(dim_h),ReLU(),Linear(dim_h, dim_h),ReLU()))self.conv3 = GINConv(Sequential(Linear(dim_h, dim_h),BatchNorm1d(dim_h),ReLU(),Linear(dim_h, dim_h),ReLU()))# 进行分类# 看论文中的公式可知,计算后是讲三个特征concat在一起self.lin1 = Linear(dim_h*3,dim_h*3)self.lin2 = Linear(dim_h*3,dataset.num_classes)def forward(self,x,edge_index,batch):h1 = self.conv1(x,edge_index)h2 = self.conv2(h1,edge_index)h3 = self.conv3(h2,edge_index)# 求和全局池化相比与其他两种池化技术(Mean global Pooling 和Max global Pooling)更具有表达能力,# 要考虑所有的结构信息,就必须考虑GNN每一层产生的嵌入信息# 将GNN的k个层中每层产生的节点嵌入求和后串联起来h1 = global_add_pool(h1,batch)h2 = global_add_pool(h2,batch)h3 = global_add_pool(h3,batch)h = torch.cat((h1,h2,h3),dim=1)# 分类h = self.lin1(h)h = h.relu()h = F.dropout(h,p=0.5,training=self.training)h = self.lin2(h)return F.log_softmax(h,dim=1)# 开始训练咯
def train(model,loader):# 设置为训练模式model.train()# 损失函数criterion = nn.CrossEntropyLoss()# 优化函数optimizer = torch.optim.Adam(model.parameters(),lr=0.01)epochs = 100for epoch in range(epochs+1):total_loss = 0acc = 0val_loss = 0val_acc = 0for data in loader:# 梯度清零optimizer.zero_grad()# 训练out = model(data.x,data.edge_index,data.batch)# 计算该批次的损失值loss = criterion(out,data.y)# 总损失total_loss += loss / len(loader)# 计算该批次的准确率acc = accuracy(out.argmax(dim=1),data.y) / len(loader)# 反向传播loss.backward()# 参数更细optimizer.step()# 验证val_loss,val_acc = test(model,val_loader)# Print metrics every 20 epochsif (epoch % 20 == 0):print(f'Epoch {epoch:>3} | Train Loss: {total_loss:.2f} | Train Acc: {acc * 100:>5.2f}% | Val Loss: {val_loss:.2f} | Val Acc: {val_acc * 100:.2f}%')return modeldef accuracy(pred_y,y):return ((pred_y == y).sum() / len(y)).item()def test(model,loader):criterion = torch.nn.CrossEntropyLoss()model.eval()loss = 0acc = 0for data in loader:out = model(data.x,data.edge_index,data.batch)loss += criterion(out,data.y) / len(loader)acc += accuracy(out.argmax(dim=1),data.y) / len(loader)return loss,acc# 开始训练
print('GCN Training')
gcn = GCN(dim_h=32)
gcn = train(gcn,train_loader)
print('GIN Training')
gin = GIN(dim_h=32)
gin = train(gin,train_loader)test_loss, test_acc = test(gcn, test_loader)
print(f'GCN test Loss: {test_loss:.2f} | GCN test Acc: {test_acc*100:.2f}%')test_loss, test_acc = test(gin, test_loader)
print(f'Gin test Loss: {test_loss:.2f} | Gin test Acc: {test_acc*100:.2f}%')GCN 思想::
通过卷积操作来聚合每个节点以及其邻居的特征。
计算公式如下:
H l + 1 = σ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H l W l ) H^{l+1}=\sigma(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}H^{l}W^{l}) Hl+1=σ(D~−1/2A~D~−1/2HlWl)
GIN 思想:
目的:增强图神经网络的区分能力,能够更好地区分不同的图,引入了更加强大的聚合函数。
计算公式如下:
h v k = M L P k ( ( 1 + ε ) ⋅ h v k − 1 + ∑ u ∈ N ( v ) h u k − 1 ) h_{v}^{k}=MLP^{k}((1+\varepsilon)\cdot h_{v}^{k-1} + \sum_{u\in\mathcal{N}_(v)}h_{u}^{k-1} ) hvk=MLPk((1+ε)⋅hvk−1+∑u∈N(v)huk−1)
ε \varepsilon ε 是一个可学习的或固定的超参数,用于调节自环的贡献。
相关文章:

GCN、GIN
# 使用TuDataset 中的PROTEINS数据集。 # 里边有1113个蛋白质图,区分是否为酶,即二分类问题。# 导包 from torch_geometric.datasets import TUDataset from torch_geometric.data import DataLoader import torch import torch.nn as nn import torch.…...

Web控件进阶交互
Web控件进阶交互 测试时常需要模拟键盘或鼠标操作,可以用Python的ActionChains来模拟。ActionChains是Selenium提供的一个子类,用于生成和执行复杂的用户交互操作,允许将一系列操作链接在一起,然后一次性执行。 from selenium im…...
基于SpringBoot的校园疫情防控系统
你好,我是专注于计算机科学与技术的研究者。如果你对我的工作感兴趣或有任何问题,欢迎随时联系我。 开发语言:Java 数据库:MySQL 技术:SpringBoot框架,B/S架构 工具:Eclipse,Mav…...

elasticsearch 查询超10000的解决方案
前言 默认情况下,Elasticsearch集群中每个分片的搜索结果数量限制为10000。这是为了避免潜在的性能问题。 但是我们 在实际工作过程中时常会遇到 需要深度分页,以及查询批量数据更新的情况 问题:当请求form size >10000 时,…...

SpringCloud集成kafka集群
目录 1.引入kafka依赖 2.在yml文件配置配置kafka连接 3.注入KafkaTemplate模版 4.创建kafka消息监听和消费端 5.搭建kafka集群 5.1 下载 kafka Apache KafkaApache Kafka: A Distributed Streaming Platform.https://kafka.apache.org/downloads.html 5.2 在config目录下做…...

Macos 远程登录 Ubuntu22.04 桌面
这里使用的桌面程序为 xfce, 而 gnome 桌面则测试失败。 1,安装 在ubuntu上,安装 vnc server与桌面程序xfce sudo apt install xfce4 xfce4-goodies tightvncserver 2,第一次启动和配置 $ tightvncserver :1 设置密码。 然后修改配置:…...

第十届MathorCup高校数学建模挑战赛-A题:无车承运人平台线路定价问题
目录 摘 要 1 问题重述 1.1 研究背景 1.2 研究问题 2 符号说明与模型假设 2.1 符号说明 2.2 模型假设 3 问题一:模型建立与求解 3.1 问题分析与思路 3.2 模型建立 3.2.1 多因素回归模型 3.3 模型求解 3.3.1 数据预处理 3.3.2 重要度计算 4 问题二:模型建立与求…...

在分布式环境中,怎样保证 PostgreSQL 数据的一致性和完整性?
文章目录 在分布式环境中保证 PostgreSQL 数据的一致性和完整性一、数据一致性和完整性的重要性二、分布式环境对数据一致性和完整性的挑战(一)网络延迟和故障(二)并发操作(三)数据分区和复制 三、保证 Pos…...

RabbitMq如何保证消息的可靠性和稳定性
RabbitMq如何保证消息的可靠性和稳定性 rabbitMq不会百分之百让我们的消息安全被消费,但是rabbitMq提供了一些机制来保证我们的消息可以被安全的消费。 消息确认 消息者在成功处理消息后可以发送确认(ACK)给rabbitMq,通知消息已…...

druid(德鲁伊)数据线程池连接MySQL数据库
文章目录 1、druid连接MySQL2、编写JDBCUtils 工具类 1、druid连接MySQL 初学JDBC时,连接数据库是先建立连接,用完直接关闭。这就需要不断的创建和销毁连接,会消耗系统的资源。 借鉴线程池的思想,数据连接池就这么被设计出来了。…...

观察者模式的实现
引言:观察者模式——程序中的“通信兵” 在现代战争中,通信是胜利的关键。信息力以网络、数据、算法、算力等为底层支撑,在现代战争中不断推动感知、决策、指控等各环节产生量变与质变。在软件架构中,观察者模式扮演着类似的角色…...

Eureka: Netflix开源的服务发现框架
在微服务架构中,服务发现是一个关键组件,它允许服务实例之间相互发现并进行通信。Eureka是由Netflix开源的服务发现框架,它是Spring Cloud体系中的核心组件之一。Eureka提供了服务注册与发现的功能,支持区域感知和自我保护机制&am…...

go-基准测试
基准测试 Demo // fib_test.go package mainimport "testing"func BenchmarkFib(b *testing.B) {for n : 0; n < b.N; n {fib(30) // run fib(30) b.N times} }func fib(n int) int {if n 0 || n 1 {return n}return fib(n-2) fib(n-1) }benchmark 和普通的单…...

线性代数|机器学习-P23梯度下降
文章目录 1. 梯度下降[线搜索方法]1.1 线搜索方法,运用一阶导数信息1.2 经典牛顿方法,运用二阶导数信息 2. hessian矩阵和凸函数2.1 实对称矩阵函数求导2.2. 线性函数求导 3. 无约束条件下的最值问题4. 正则化4.1 定义4.2 性质 5. 回溯线性搜索法 1. 梯度…...

SQL,python,knime将数据混合的文字数字拆出来,合并计算实战
将下面将数据混合的文字数字拆出来,合并计算 一、SQL解决: ---创建表插入数据 CREATE TABLE original_data (id INT AUTO_INCREMENT PRIMARY KEY,city VARCHAR(255),value DECIMAL(10, 2) );INSERT INTO original_data (city, value) VALUES (上海0.5…...

mac ssh连接工具
在Mac上,有多个SSH连接工具可供选择,这些工具根据其功能和适用场景的不同,可以满足不同用户的需求。以下是一些推荐的SSH客户端软件:12 iTerm2:这是一款功能强大的终端应用程序,提供了丰富的功能和定制选项…...
阿里通义音频生成大模型 FunAudioLLM 开源
简介 近年来,人工智能(AI)技术的进步极大地改变了人类与机器的互动方式,特别是在语音处理领域。阿里巴巴通义实验室最近开源了一个名为FunAudioLLM的语音大模型项目,旨在促进人类与大型语言模型(LLMs&…...
通用详情页的打造
背景介绍 大家都知道,详情页承载了站内的核心流量。它的量级到底有多大呢? 我们来看一下,日均播放次数数亿次,这么大的流量,其重要程度可想而知。 在这样一个页面,每一个功能都是大量业务的汇总点。 作为…...

java内部类的本质
定义在类内部,可以实现对外部完全隐藏,可以有更好的封装性,代码实现上也往往更为简洁。 内部类可以方便地访问外部类的私有变量,可以声明为private从而实现对外完全隐藏。 在Java中,根据定义的位置和方式不同…...

vue3 学习笔记08 -- computed 和 watch
vue3 学习笔记08 – computed 和 watch computed computed 是 Vue 3 中用于创建计算属性的重要 API,它能够根据其它响应式数据动态计算出一个新的值,并确保在依赖数据变化时自动更新。 基本用法 squaredCount 是一个计算属性,它依赖于 count…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...
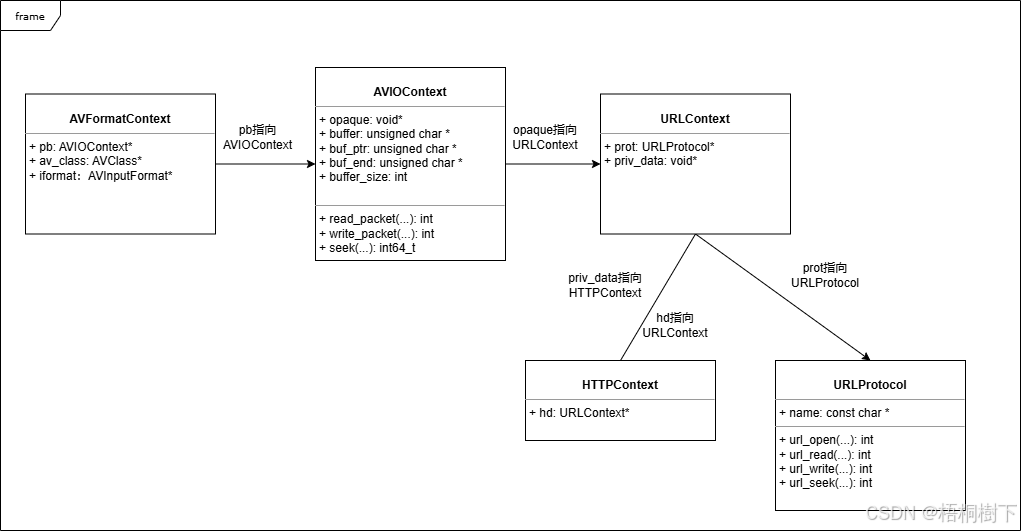
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...
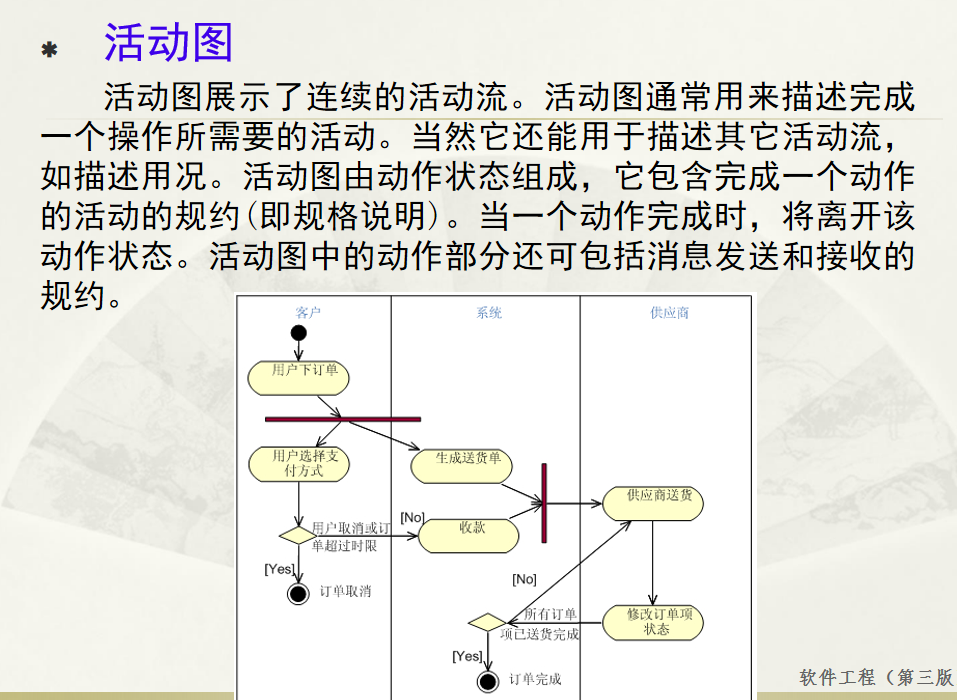
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...

高效的后台管理系统——可进行二次开发
随着互联网技术的迅猛发展,企业的数字化管理变得愈加重要。后台管理系统作为数据存储与业务管理的核心,成为了现代企业不可或缺的一部分。今天我们要介绍的是一款名为 若依后台管理框架 的系统,它不仅支持跨平台应用,还能提供丰富…...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...
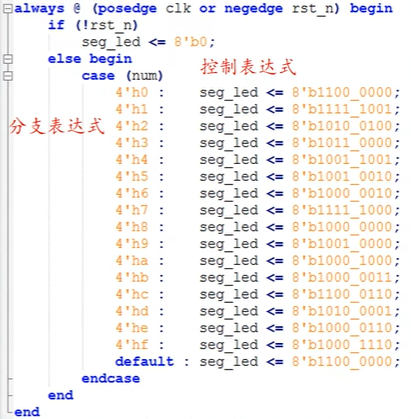
ZYNQ学习记录FPGA(二)Verilog语言
一、Verilog简介 1.1 HDL(Hardware Description language) 在解释HDL之前,先来了解一下数字系统设计的流程:逻辑设计 -> 电路实现 -> 系统验证。 逻辑设计又称前端,在这个过程中就需要用到HDL,正文…...
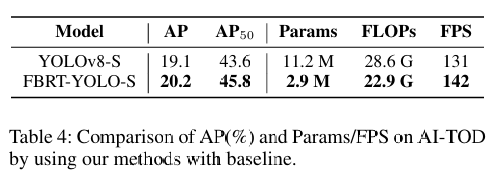
Yolo11改进策略:Block改进|FCM,特征互补映射模块|AAAI 2025|即插即用
1 论文信息 FBRT-YOLO(Faster and Better for Real-Time Aerial Image Detection)是由北京理工大学团队提出的专用于航拍图像实时目标检测的创新框架,发表于AAAI 2025。论文针对航拍场景中小目标检测的核心难题展开研究,重点解决…...
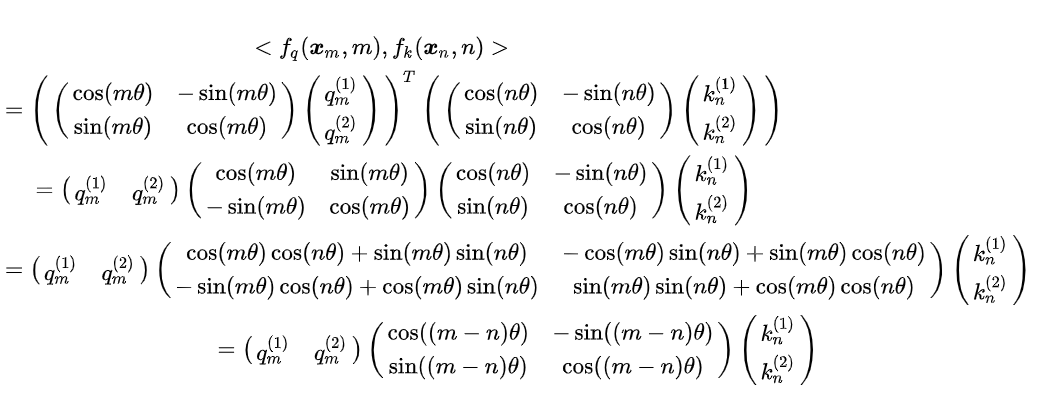
多模态学习路线(2)——DL基础系列
目录 前言 一、归一化 1. Layer Normalization (LN) 2. Batch Normalization (BN) 3. Instance Normalization (IN) 4. Group Normalization (GN) 5. Root Mean Square Normalization(RMSNorm) 二、激活函数 1. Sigmoid激活函数(二分类&…...
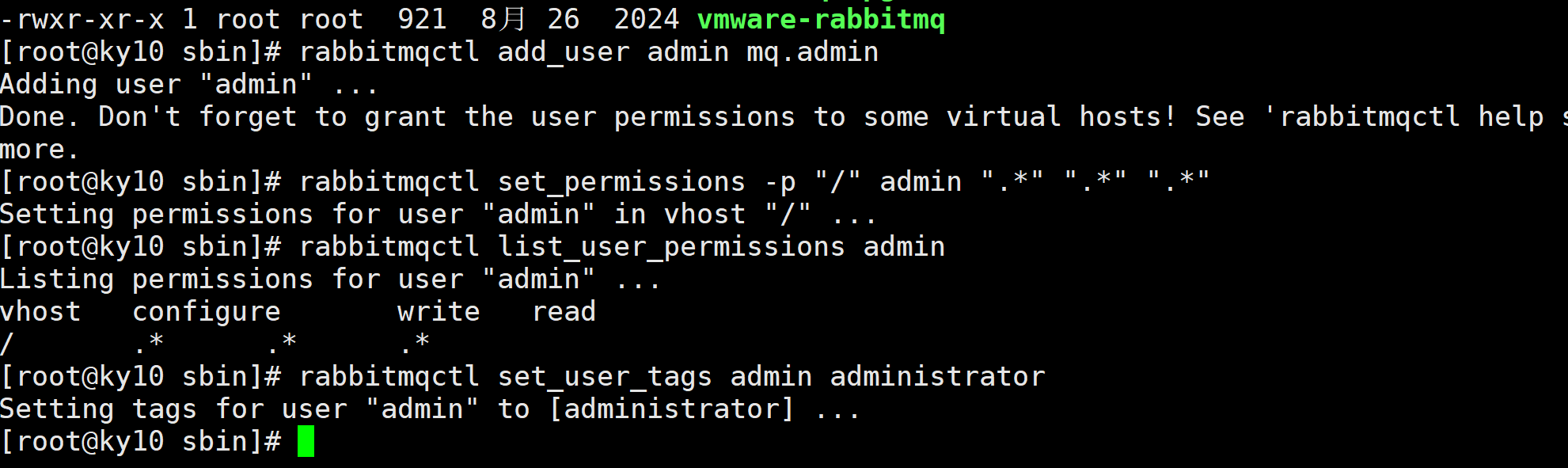
mq安装新版-3.13.7的安装
一、下载包,上传到服务器 https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.13.7/rabbitmq-server-generic-unix-3.13.7.tar.xz 二、 erlang直接安装 rpm -ivh erlang-26.2.4-1.el8.x86_64.rpm不需要配置环境变量,直接就安装了。 erl…...