RAG 效果提升的最后一步—— 微调LLM
如果说,rerank能够让RAG的效果实现百尺竿头更进一步,那么LLM微调应该是RAG效果提升的最后一步。
把召回的数据,经过粗排,重排序后,送给模型,由模型最后总结答案。LLM的确已经是RAG的最后一步了。
这里还是会遇到一个问题,召回的正确的答案,但是答案藏在比较长的上下文中。例如 top10的数据,又或者是top20的数据中。这非常考验模型的能力。看到一篇论文,非常好,在分享如何微调LLM,来做好这最后一步。
论文中提到一个观点,我非常赞同:“增强LLM的长上下文的排序能力,有助于提升回答的效果” ps(这个是我自己总结的观点
)
本篇文章主要介绍SFT微调的方法,SFT数据的构建,测试数据集,测试指标,以及最后的效果。
论文地址:https://simg.baai.ac.cn/paperfile/68c487ed-fafd-4bac-81e0-f8be1b56e845.pdf
一、核心内容
提出在RAG中微调LLM的方法。用于提升同时对上下文进行排序和生成答案的能力。在70B的LLM上进行微调,最终的能力能够比肩chatGPT4的能力。

在生物医学领域的 RAG 基准测试中,RankRAG 表现出对新领域的出色泛化能力。

并且rerank能力能够超过BGE。

二、为什么要微调模型?
2.1 RAG当前存在的问题
-
检索器容量有限:
- 目前的RAG系统通常使用稀疏检索或中等大小的嵌入模型作为检索器,这些模型由于效率考虑,通常需要索引数以百万计的文档。这些模型独立地编码问题和文档,并使用向量相似性度量来计算问题和文档之间的相似性,但嵌入模型的有限容量和查询及文档的独立处理限制了它们估计问题和文档文本相关性的能力。
-
选择top-k上下文的权衡:
- 尽管最新的长上下文LLM可以作为输入来生成答案,但性能随着检索到的上下文数量k的增加而迅速饱和。较小的k可能无法捕获所有相关信息,从而影响召回率;而较大的k虽然提高了召回率,但可能会引入不相关的内容,从而影响LLM生成准确答案的能力。
-
专家排名模型的零样本泛化能力有限:
- 虽然现有的一些研究通过指令微调LLM来增强其在RAG中的能力,但如果初始检索结果不佳,这些方法可能仍然无效。此外,专家排名模型相比于多用途的LLM本身,在零样本泛化能力上可能相对有限。
-
检索器的效率问题:
- 由于需要处理大量的文档,检索器的效率成为一个问题,尤其是在需要快速响应的场景中。
-
上下文相关性不足:
- 检索器可能难以在整个嵌入空间中学习有效的局部对齐,以支持准确的匹配,这限制了检索器在新任务或新领域中的有效性。
-
上下文重排的需求:
- 尽管检索器能够检索到相关的上下文,但可能需要一个额外的重排步骤来确保最相关的上下文被优先考虑,这增加了处理的复杂性。
2.2 微调的目标:
-
提高指令遵循能力:通过监督微调(SFT),可以显著提升LLMs遵循给定指令的能力。这是因为在多种下游任务中,能够准确理解和遵循指令对于提供有用和准确的回答至关重要。
-
优化RAG任务性能:尽管LLMs在生成文本方面表现出色,但它们在检索增强型生成(RAG)任务中的表现并不总是最优,尤其是在从检索到的上下文中提取答案的能力方面。微调可以帮助LLMs更好地适应这类任务。
-
解决现有RAG流程的局限性:当前的RAG系统存在一些限制,例如检索器容量有限,以及在挑选top-k上下文时存在的权衡问题。微调可以帮助LLMs更有效地处理这些问题,提高检索到的上下文的相关性。
-
上下文排序能力:在RAG中,需要一种机制来确保检索到的上下文与问题高度相关。通过微调,LLMs可以学习如何评估和排序检索到的上下文,以选择最相关的信息。
-
数据效率:论文中提到,即使是在只有少量排序数据的情况下,通过特定的微调方法,RankRAG也能实现很好的性能。这说明微调可以提高模型对数据的利用效率。
-
零样本学习能力:通过指令微调,LLMs能够在没有额外训练数据的情况下,对新任务或新领域展示出更好的零样本学习能力。
-
提升泛化能力:微调可以帮助模型在不同的任务和领域中更好地泛化,如论文中提到的在生物医学领域的RAG基准测试中,即使没有在该领域的数据上进行微调,RankRAG也展现出了良好的性能。
-
应对长尾知识问题:微调可以帮助模型更好地处理长尾知识问题,即那些在传统数据集中不常见但在实际应用中可能非常重要的问题。
三、如何微调模型?
3.1 模型微调主要分为两个阶段:

-
第一阶段:监督微调(Supervised Fine-Tuning, SFT)
- 这个阶段的目的是提高大型语言模型(LLMs)遵循指令的能力,从而在各种下游任务上获得更好的零样本结果。
- 使用的数据集包括私有众包对话数据集、公共对话数据集、长形问答数据集、LLM生成的指令、以及一些特定的数据集如FLAN和Chain-of-thought数据集。
- 此阶段确保了训练数据与评估任务的数据没有重叠。
-
第二阶段:统一指令微调(Unified Instruction-Tuning)
- 这个阶段的目的是专门针对检索增强型生成(RAG)任务和上下文排序进行优化。
- 指令微调的数据混合包括以下几部分:
- 第一阶段的SFT数据,以维持LLM的指令遵循能力。
- 上下文丰富的问答(QA)数据,增强LLM使用上下文生成答案的能力。
- 检索增强型QA数据,提高LLM在生成时对不相关上下文的鲁棒性。
- 上下文排序数据,使用MS MARCO通道(passage)排序数据集,提高LLM的排序能力。
- 检索增强型排序数据,训练LLM确定给定问题下多个上下文的相关性。
微调过程中,模型会接收到特定的指令模板,这些模板会根据不同的数据集和任务类型进行调整。例如,对于需要短答案的数据集,指令会指示模型“用简短的片段回答问题”,而对于需要长答案或涉及数学计算的数据集,则会有相应的具体指令。
微调后,模型在推理时采用“检索-重排-生成”的流程,即首先检索器检索文档,然后模型计算问题与检索到的文档之间的相关性得分,并据此重排文档,最后使用重排后的上下文生成最终答案。
这种微调方法使得RankRAG模型能够在多种知识密集型NLP任务中表现出色,尤其是在上下文排序和答案生成方面。
3.2 如何构造SFT数据
Stage-I 的监督微调(Supervised Fine-Tuning,简称 SFT)阶段使用了总共 128K(即 128,000)个 SFT 样本。这些样本来自于多种不同的数据集,包括私有众包对话数据集、公共对话数据集、长形问答数据集、LLM 生成的指令以及一些特定的数据集如 FLAN 和 Chain-of-thought 数据集。这些数据集被用来增强模型遵循指令的能力,从而在各种下游任务中获得更好的零样本结果。
数据配比

采用了以下步骤来构造微调数据:
-
数据收集:
- 收集多种类型的数据集,包括对话数据集、长形问答数据集、阅读理解数据集、事实验证数据集等。
-
数据预处理:
- 对收集的数据进行清洗和格式化,以确保数据质量和一致性。这可能包括去除无关信息、修正错误和格式化文本。
-
任务特定指令设计:
- 根据不同任务的需求,设计特定的指令模板。例如,对于需要短答案的QA任务,设计简短的回答指令;对于需要长答案或进行数学计算的任务,设计相应的指令。
-
上下文丰富的QA数据:
- 利用包含丰富上下文的QA任务数据,增强模型使用上下文生成答案的能力。
-
检索增强型QA数据:
- 结合检索到的上下文和正确答案,构造检索增强型QA数据,提高模型在面对不相关上下文时的鲁棒性。
-
上下文排序数据:
- 使用如MS MARCO等排名数据集,构造上下文排序任务,训练模型评估查询和上下文之间的相关性。
-
检索增强型排名数据:
- 结合检索到的多个上下文和正确答案,构造检索增强型排名任务,训练模型识别问题相关的所有上下文。
-
数据混合:
- 将不同来源和类型的数据按照一定的比例混合,形成统一的微调数据集。这有助于模型学习多样化的任务和提高泛化能力。
-
避免数据污染:
- 确保训练数据与测试数据集没有重叠,避免模型在测试时对训练数据产生记忆,确保评估结果的有效性。
-
数据集的标准化:
- 将不同来源的数据集转换为统一的格式,以便于模型处理和学习。
-
数据集的平衡:
- 确保数据集中各类样本的平衡,避免某些类别的样本过多或过少,影响模型的公平性和准确性。
-
数据集的标注:
- 对于需要明确答案或评估标准的任务,进行数据标注,包括正确答案、相关性标签等。
通过这些步骤,可以构造出适合模型微调的数据集,这些数据集将用于提升模型在特定任务上的性能。在RankRAG的案例中,这些数据集将特别针对上下文排序和检索增强型生成任务进行优化。
四、优化后的效果有哪些?
4.1模型能力提升
-
性能提升:通过RankRAG框架的指令微调,LLMs在多个知识密集型基准测试中的表现显著优于现有的专家排名模型和其他强基线模型。
-
上下文排序能力增强:RankRAG通过在训练中加入上下文排序数据,使得模型在检索到的上下文中更有效地识别和排序最相关的信息。
-
数据效率:RankRAG显示出了数据效率,即使只用一小部分排序数据进行训练,也能在RAG任务的评估中取得很好的效果,超越了使用10倍多排序数据进行微调的LLMs。
-
泛化能力:RankRAG在没有针对生物医学数据进行指令微调的情况下,在生物医学领域的RAG基准测试中表现出色,显示了其在新领域中的泛化能力。
-
检索增强型生成(RAG)改进:RankRAG在RAG任务中通过引入额外的重排步骤,提高了检索到的上下文的相关性,从而提升了最终答案的准确性。
-
减少不相关上下文的影响:通过重排步骤,RankRAG能够过滤掉不相关或嘈杂的上下文,减少这些上下文对LLM生成准确答案的干扰。
-
提高检索器的容量:尽管检索器本身的容量有限,但通过RankRAG的优化,即使是在检索器检索结果不理想的情况下,模型仍然能够通过上下文重排来提高性能。
-
零样本学习能力:RankRAG在多个任务上的零样本学习能力得到了提升,这表明微调后的模型能够更好地适应未见过的任务。
-
效率与性能的平衡:尽管增加了重排步骤可能会带来额外的处理时间,但研究表明,这种时间开销相对较小,并且可以通过调整重排的上下文数量来平衡效率和性能。
-
在不同上下文大小下的表现:论文中的实验结果表明,与没有排序的RAG方法不同,RankRAG即使在较小的上下文大小(如k=5)下也能表现良好,这得益于重排步骤能够优先考虑最相关的上下文。
这些优化效果表明,RankRAG框架通过指令微调,能够显著提升LLMs在复杂问答任务中的性能,尤其是在需要结合大量检索到的文档信息来生成准确答案的场景中。
4.2 rerank效果的提升
RankRAG 模型在重排(rerank)能力方面表现出色,并且在某些方面优于现有的重排模型,如BGE(Bi-Encoder with Gradient-based End-to-end optimization)。
-
数据效率:RankRAG 显示出了在仅有少量重排数据的情况下就能获得很好的性能。论文中提到,即使只使用了约1%的MS MARCO数据集作为重排数据,RankRAG 也能够实现非常引人注目的结果。这表明 RankRAG 在数据使用上非常高效。
-
性能比较:在与BGE等其他重排模型的比较中,RankRAG 在多数情况下,即使使用的重排数据量是其他模型的十分之一,也能取得更好的召回率(Recall)和其他评估指标,如R@5、R@10、R@20等。这表明 RankRAG 在重排任务上具有优势。
-
不同检索器的性能:论文还展示了 RankRAG 在使用不同的检索器(如DPR和Contriever)时的性能。无论使用哪种检索器,RankRAG 都能实现一致的性能提升,这表明 RankRAG 对于检索器的选择具有很好的鲁棒性。
-
上下文大小对性能的影响:在分析不同的上下文大小(k值)对性能的影响时,RankRAG 显示出即使在较小的上下文大小(如k=5)下也能表现良好,这与没有重排步骤的常规RAG方法不同,后者通常需要更多的上下文来获得较好的性能。
-
效率与性能的平衡:论文还讨论了 RankRAG 在效率和性能之间取得的平衡。尽管增加了重排步骤可能会带来额外的处理时间,但研究表明,这种时间开销相对较小,并且可以通过调整重排的上下文数量来平衡效率和性能。
总结来说,RankRAG 在重排能力方面表现出了数据效率和性能上的优势,即使在数据量较少的情况下也能实现良好的性能,并且在不同的检索器和上下文大小下都能保持稳定的表现。这些特性使得 RankRAG 在实际应用中具有很大的潜力。
五、测评
5.1 评测指标是如何设计的
对于不同的任务类型,作者设计了不同的评估指标来衡量 RankRAG 模型的性能。以下是根据论文内容,评测指标的设计:
-
开放域问答(OpenQA)任务:
- 主要使用 Exact Match (EM) 作为主要评估指标,即模型生成的答案与参考答案完全一致时才计为正确。
- 对于 TriviaQA 和 PopQA,除了 Exact Match 外,还报告了 Accuracy,即正确答案占总答案的比例。
- 对于 HotpotQA 和 2WikimQA,使用了 F1 分数,这是一种综合考虑精确度和召回率的指标。
-
事实验证(Fact verification)任务:
- 使用 Accuracy 作为评估指标,即模型正确验证事实的比例。
-
对话问答(Conversational QA)任务:
- 使用 F1 分数 作为评估指标,这同样是一种综合考虑精确度和召回率的指标。
-
上下文排序(Context Ranking)任务:
- 对于上下文排序任务,设计了不同的评估指标,如 Recall、R@5、R@10 和 R@20,这些指标衡量了在重排后,检索到的前5、前10和前20个文档中相关文档的比例。
-
检索增强型生成(RAG)任务:
- 在评估 RAG 任务时,除了上述的 Exact Match、Accuracy 和 F1 分数外,还可能考虑其他指标,如答案的置信度或答案的相关性评分。
-
效率评估:
- 论文还考虑了模型的效率,通过评估重排步骤引入的额外处理时间来衡量。这涉及到检索、重排和生成每个步骤所需的时间,并分析这些时间的增加对整体性能的影响。
-
数据效率:
- 评估了模型在不同数量的排序数据下的的性能,以确定模型在数据使用上的效率。
-
零样本学习能力:
- 评估了模型在没有额外训练数据的情况下对新任务的适应能力。
这些评估指标的设计旨在全面衡量 RankRAG 模型在各种知识密集型 NLP 任务上的性能,包括准确性、鲁棒性、泛化能力以及效率。通过这些指标,研究者能够深入理解模型的优势和局限性,并与其他基线模型进行比较。
5.2 测试数据集


测试数据集包括:
-
开放域问答(OpenQA):
- NQ(Natural Questions): 基于维基百科构建的问答数据集。
- TriviaQA: 包含由琐事爱好者提出的问题和独立收集的证据文档的问答数据集。
- PopQA: 集中在长尾实体上的实体中心问答数据集。
- HotpotQA: 需要理解和链接多个文档信息的多跳问答数据集。
- 2WikimQA: 测试机器在两个不同的维基百科实体上的理解能力,评估跨语言和跨文化检索及问答的能力。
-
事实验证(Fact verification):
- FEVER: 旨在支持研究自动验证事实性声明的数据集。
-
对话问答(Conversational QA):
- Doc2Dial: 一个文档基础的对话问答数据集,涵盖多个领域。
- TopiOCQA: 需要代理搜索整个维基百科来回答用户问题的数据集。
- INSCIT: 研究用户问题不明确并需要澄清的情况的数据集。
-
生物医学领域的RAG基准测试(Biomedical Benchmarks):
- MMLU-med: 包含生物医学相关问题的子集。
- MedQA: 来自美国医学执照考试的问答数据集。
- MedMCQA: 来自印度医学入学考试的多项选择题数据集。
- PubmedQA: 基于PubMed摘要的生物医学研究问答数据集。
- BioASQ: 从生物医学文献构建的问题,不提供地面真实片段。
这些数据集覆盖了不同的任务类型和领域,用于评估RankRAG模型在各种知识密集型任务上的表现。论文中还提到了使用不同的检索器(如DPR和Contriever)来测试RankRAG的上下文重排能力。通过在这些数据集上进行测试,研究者能够全面评估RankRAG的性能和泛化能力。
六、prompt
论文是非常贴心的,给里prompt。这个可以在给的论文链接中查看。
相关文章:
RAG 效果提升的最后一步—— 微调LLM
如果说,rerank能够让RAG的效果实现百尺竿头更进一步,那么LLM微调应该是RAG效果提升的最后一步。 把召回的数据,经过粗排,重排序后,送给模型,由模型最后总结答案。LLM的确已经是RAG的最后一步了。 这里还是会…...

C语言 | Leetcode C语言题解之第230题二叉搜索树中第K小的元素
题目: 题解: /*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/int search_num(struct TreeNode* root, int k, int *result, int num) {if(num k 1){retu…...
YOWOv2(yowov2)动作识别+Fastreid身份识别 详细安装与实现
首先yowov2是一款简单且实时的时空动作检测方案,fastreid是行人重识别(身份识别) yowov2介绍链接直达fastreid链接直达为时空动作检测任务设计实时框架仍然是一个挑战。YOWOv2 提出了一种新颖的实时动作检测框架,利用三维骨干和二…...

【微服务】Spring Cloud中如何使用Eureka
摘要 Eureka作为Netflix开源的服务发现框架,在Spring Cloud体系中扮演着至关重要的角色。本文详细介绍了Eureka的基本概念、工作原理以及如何在Spring Cloud中集成和使用Eureka进行服务发现和管理。通过深入分析Eureka的注册与发现机制、区域感知和自我保护等高级特…...

【Neo4j】实战 (数据库技术丛书)学习笔记
Neo4j实战 (数据库技术丛书) 第1章演示了应用Neo4j作为图形数据库对改进性能和扩展性的可能性, 也讨论了对图形建模的数据如何正好适应于Neo4j数据模型,现在到了该动 手实践的时间了。第一章 概述 Neo4j将数据作为顶点和边存储(或者用Neo4j术语,节点和关系存 储)。用户被定…...

【Perl】Perl 语言入门
1. Perl语言介绍 Perl 是一种高级、解释型、动态编程语言,由Larry Wall在1987年发布。Perl 以其强大的文本处理能力而闻名,特别是在处理报告生成、文件转换、系统管理任务等方面。它吸收了C、Shell脚本语言、AWK、sed等语言的特性,并加入了大…...
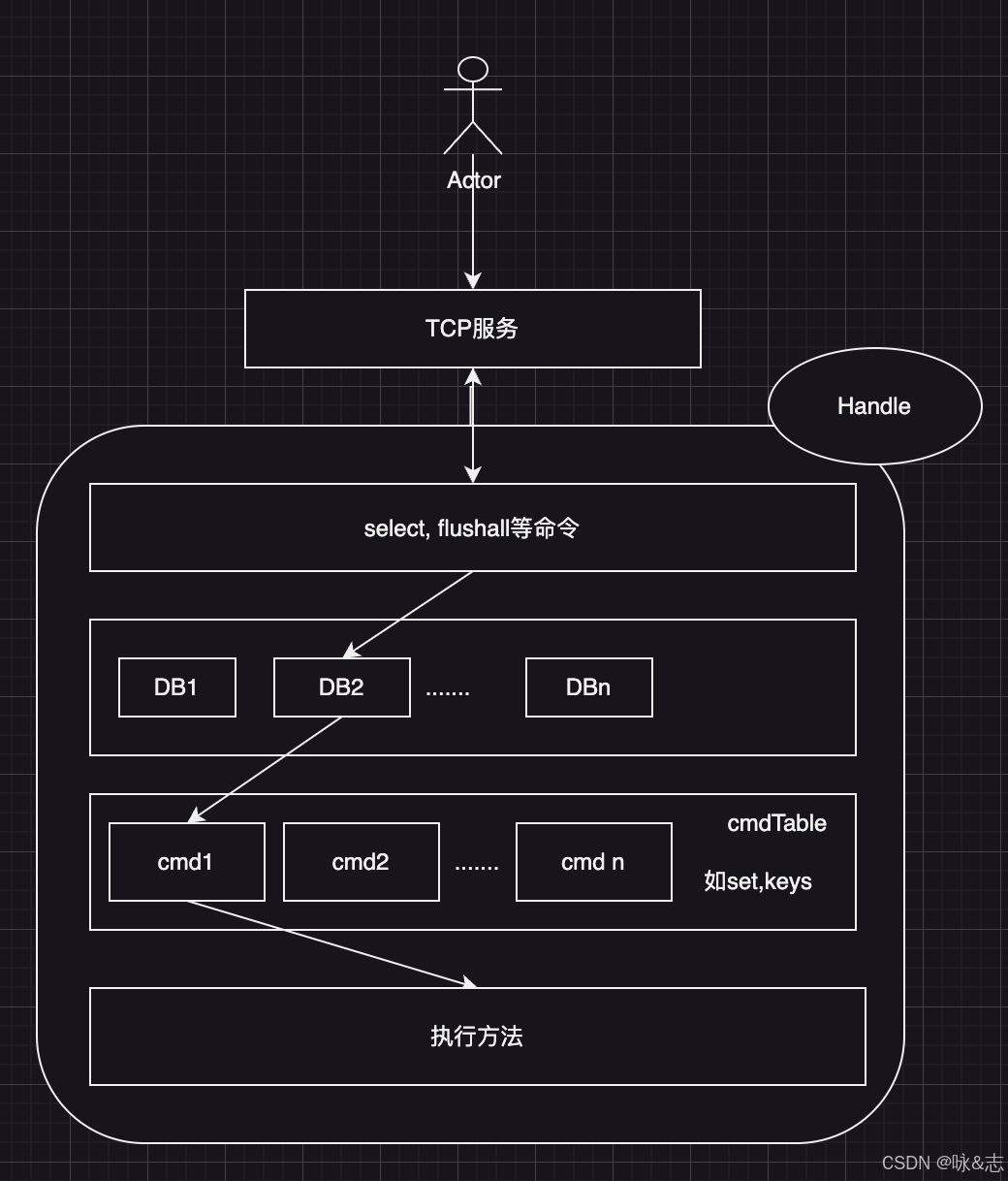
godis源码分析——database存储核心1
前言 redis的核心是数据的快速存储,下面就来分析一下godis的底层存储是如何实现,先分析单机服务。 此文采用抓大放小原则,先大的流程方向,再抓细节。 流程图 源码分析 现在以客户端连接,并发起set key val命令为例…...
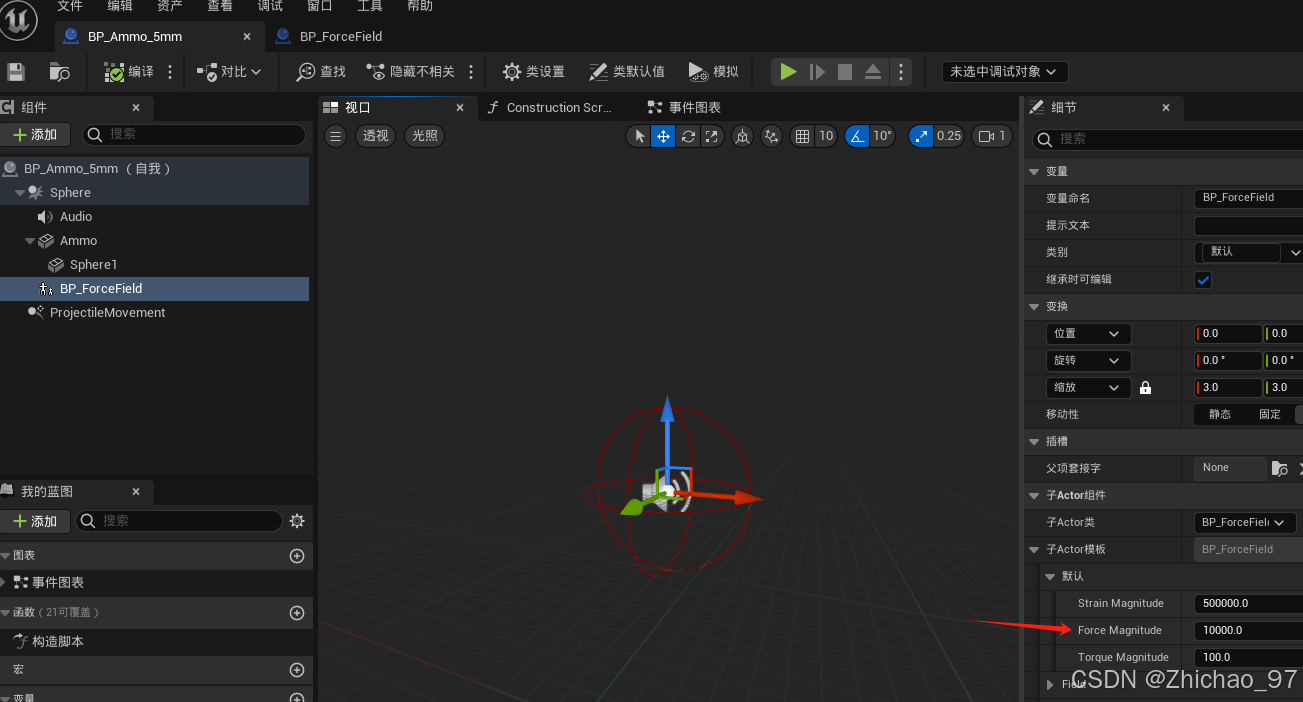
【UE5.1】Chaos物理系统基础——06 子弹破坏石块
前言 在前面我们已经完成了场系统的制作(【UE5.1】Chaos物理系统基础——02 场系统的应用_ue5)以及子弹的制作(【UE5.1 角色练习】16-枪械射击——瞄准),现在我们准备实现的效果是,角色发射子弹来破坏石柱。…...

Django是干什么的?好用么?
Django是一个开源的Python Web框架,用于快速开发高质量的Web应用程序。它提供了许多功能和工具,以简化常见的Web开发任务,如路由、请求处理、数据库管理等。 Django的优点包括: 简单易用:Django提供了清晰的文档和丰…...

C语言实现数据结构B树
B树(B-Tree)是一种自平衡的树数据结构,它维护着数据的有序性,并允许搜索、顺序访问、插入、删除等操作都在对数时间内完成。B树广泛用于数据库和操作系统的文件系统中。 B树的基本特性 根节点:根节点至少有两个子节点…...

[论文阅读]MaIL: Improving Imitation Learning with Mamba
Abstract 这项工作介绍了mamba模仿学习(mail),这是一种新颖的模仿学习(il)架构,为最先进的(sota)变换器策略提供了一种计算高效的替代方案。基于变压器的策略由于能够处理具有固有非…...

在HTML中使用JavaScript
在 HTML 中使用 JavaScript 有以下几种常见的方式: 一、内联脚本 (一)基本语法 内联脚本是将 JavaScript 代码直接嵌入到 HTML 文件的 <script> 标签内部。 <!DOCTYPE html> <html lang"en"> <head> <…...
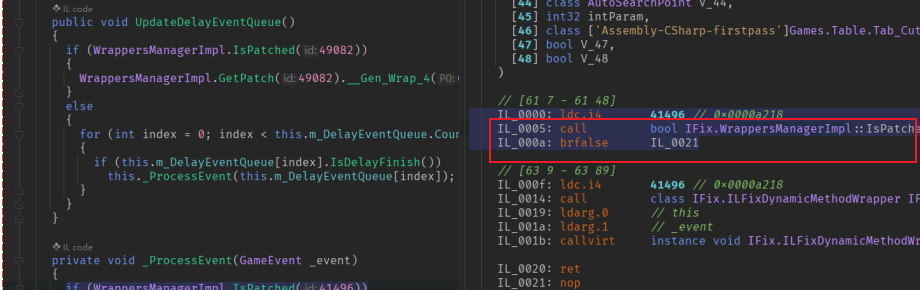
InjectFix 热更新解决方案
简介 今天来谈一谈,项目种的客户端热更新解决方案。InjectFix是腾讯xlua团队出品的一种用于Unity中C#代码热更新热修复的解决方案。支持Unity全系列,全平台。与xlua的思路类似,InjectFix解决的痛点主要在于Unity中C#代码写的逻辑在发包之后无…...
PHP7.4安装使用rabbitMQ教程(windows)
(1),安装rabbitMQ客户端erlang语言 一,erlang语言安装 下载地址1—— 下载地址2——https://www.erlang.org/patches/otp-27.0 二,rabbitMQ客户端安装 https://www.rabbitmq.com/docs/install-windows (…...
分页以及tab栏切换,动态传类型
<view class"disTitle"><view class"disName">账户明细</view><view class"nav"><u-tabs lineWidth"0" :activeStyle"{color: #FD893F }" :list"navList" change"tabsChange&quo…...

【算法】平衡二叉树
难度:简单 题目 给定一个二叉树,判断它是否是 平衡二叉树 示例: 示例1: 输入:root [3,9,20,null,null,15,7] 输出:true 示例2: 输入:root [1,2,2,3,3,null,null,4,4] 输出&…...

五、 计算机网络(考点篇)
1 网络概述和模型 计算机网络是计算机技术与通信技术相结合的产物,它实现了远程通信、远程信息处理和资源共享。计算机网络的功能:数据通信、资源共享、管理集中化、实现分布式处理、负载均衡。 网络性能指标:速率、带宽(频带宽度或传送线路…...

如何解决数据分析问题:IPython与Pandas结合
如何解决数据分析问题:IPython与Pandas结合 数据分析是现代科学研究、商业决策和技术开发中的一个重要环节。IPython和Pandas是两个强大的工具,它们可以大大简化和加速数据分析的过程。本文将为初学者详细介绍如何结合使用IPython和Pandas来解决数据分析…...

如何在 Microsoft Edge 上使用开发人员工具
Microsoft Edge 提供了一套强大的开发人员工具,可帮助 Web 开发人员检查、调试和优化他们的网站或 Web 应用程序。 无论您是经验丰富的 Web 开发人员还是刚刚起步,了解如何有效地使用这些工具都可以对开发过程产生重大影响。 在本文中,我们…...

《Linux系统编程篇》认识在linux上的文件 ——基础篇
前言 Linux系统编程的文件操作如同掌握了一把魔法钥匙,打开了无尽可能性的大门。在这个世界中,你需要了解文件描述符、文件权限、文件路径等基础知识,就像探险家需要了解地图和指南针一样。而了解这些基础知识,就像学会了魔法咒语…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...