蔚来汽车:拥抱TiDB,实现数据库性能与稳定性的飞跃
作者: Billdi表弟 原文来源: https://tidb.net/blog/449c3f5b

演讲嘉宾:吴记 蔚来汽车Tidb爱好者
整理编辑:黄漫绅(表妹)、李仲舒、吴记
本文来自 TiDB 社区合肥站走进蔚来汽车——来自吴记老师的演讲《TiDB 在新能源车企的实践:MySQL 到 TiDB 的迁移思考》。这次分享将深入探讨新能源车企从 MySQL 迁移到 TiDB 的过程与实践。我们将分享迁移过程中的挑战和动机,面对单表数量增长至 20 亿带来的应对策略,并详细介绍 TiDB 如何优化多表 Join 场景下的查询效率。此外,也将分享使用 TiDB 过程中常见的问题与解决方法,帮助大家更有效地应用 TiDB 解决企业数据库管理中的挑战。
活动回顾及 PPT 下载: https://asktug.com/t/topic/1020557
演讲视频实录: https://www.bilibili.com/video/BV1LC4y1C7Yq
企业介绍
蔚来是一家全球化的智能电动汽车公司,致力于通过提供高性能的智能电动汽车与极致用户体验。2023 年第三季度中国汽车市场销量 566.8 万辆,同比增长 2.4%,其中新能源车型销量合计接近 200 万辆,同比增长 36%。其中,蔚来在中国 30 万元以上的纯电汽车市场中位列第一,市场份额占比 45%。
业务挑战
随着业务的快速扩张,蔚来公司内部某些业务的数据量急剧增加,部分业务的日增数据量达到千万级别。在MySQL数据库中,一些表的记录数已超过 20 亿条。在多种业务场景中,需要对这些大型表与其他表进行联接查询,这导致了严重的性能瓶颈,查询效率低下,甚至在某些情况下查询经常超时。由于查询需求的多样性,传统的基于 hash 的分表策略已无法满足业务需求。
我们目前面临的数据库挑战主要包括:
- 性能问题 :在执行包含 20 亿记录的大表与不同规模的其他表(百万、几十万、几万)的联接查询时,性能显著下降,特别是对于聚合函数如
count的查询几乎不可行。 - 时间维度跨度大 :大多查询场景需要结合时间维度进行时间范围查询,通常要查询中过滤最近半年的数据,但是仍然有对历史数据查询的可能。
- 表结构复杂性 :大型表初始包含 20 多亿条记录,拥有 30 多个字段,其中约 10 个字段需要与其他三个表进行联接查询。
- 写入与同步延迟 :部分数据库表的单表写入数据量巨大,导致主从复制(master-slave replication)出现延迟,影响多个业务流程。
- DDL执行缓慢 :在MySQL中,由于单表数据量过大,执行数据定义语言(DDL)操作变得非常缓慢,有时需要数小时才能完成。
为了解决这些问题,我们可能需要考虑以下策略:
- 优化查询 :重写查询逻辑,减少不必要的联接和数据扫描。
- 索引优化 :为常用于联接和查询的字段创建索引,提高查询效率。
- 分区表 :根据业务逻辑对表进行分区,以提高查询和维护的性能。
- 读写分离 :通过读写分离来减轻主数据库的压力,提高查询响应速度。
- 分布式数据库 :考虑使用分布式数据库解决方案,以支持水平扩展和负载均衡。
- 异步处理 :对于不需要即时返回结果的查询,采用异步处理方式。
为什么选择 TiDB?
通过调研,蔚来数据应用团队将目光放到了分布式数据库上,TiDB 作为一款流行度很广的开源分布式 HTAP 数据库,开始进入团队调研和应用的视野。
在调研中,蔚来数据应用团队认为 TiDB 作为一款开源 分布式关系型数据库 , 在线事务处理 ,在线分析处理 融合型分布式数据库产品,具备 水平弹性扩容或者缩容 、 金融级高可用 、 实时 HTAP 、云原生的分布式数据库、 兼容 MySQL 5.7 /MySQL 8.0 协议和 MySQL 生态 等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
TiDB的多项优势特性有效满足了蔚来数据应用团队在处理大规模数据和高并发事务时的需求:
-
分布式架构 :TiDB 采用分布式关系型数据库架构,有效突破了单机处理能力的局限,提升了整体性能,扩展性。
-
高可用性: TiDB 通过使用 Raft 一致性算法,数据在各 TiKV 节点间复制为多副本,以确保某个节点宕机时数据的安全性,同时具备同城双中心、两地三中心的金融级高可用方案。
-
水平弹性扩展 :TiDB 不仅支持传统关系型数据库的事务和分析功能,还具备非关系型数据库的水平扩展能力和灵活性,提供了高性能的数据存储解决方案。
-
分布式强一致性事务处理 :TiDB 支持 ACID(原子性、一致性、隔离性、持久性)事务,确保在分布式环境下的数据一致性和完整性。
-
MySQL 协议高度兼容性 :TiDB 与 MySQL 协议高度兼容,支持广泛的 MySQL SQL 语法以及 MySQL 生态系统工具,降低了从 MySQL 迁移到 TiDB 的学习成本和技术障碍,实现了平滑过渡。
-
灵活的分区功能 :TiDB 提供了灵活的分区机制,支持 hash、range、list、key 等分区,简化了数据管理和维护工作,使得业务逻辑与数据分片解耦,提高了查询效率。
-
强大的数据同步工具 :
- DM可以方便的实现数据从mysql(全量+增量)同步到TIDB
- TiCDC 工具支持基于 Binlog 的数据同步,允许 TiDB 与 MySQL或者TIDB 之间实现主从复制,确保数据的实时同步和一致性。
-
丰富的生态系统 :TiDB 拥有一个成熟的生态系统,包括 TiFlash 提供的列式存储引擎,优化了分析型查询的性能;TiSpark 允许 TiDB 作为存储层,结合 Spark 的强大计算能力,提供了灵活的大数据处理能力。
通过这些特性,TiDB 不仅为蔚来提供了一个高性能、高可用的数据库解决方案,还通过其强大的生态系统,支持蔚来在数据管理和分析方面的需求,推动了业务的持续创新和发展。
架构对比
蔚来数据应用团队从架构、存储层面对比了 TiDB 与 MySQL 的区别与优势:
TiDB 架构详细描述
TiDB Server 层:
- SQL解析与优化 :TiDB Server负责接收客户端的SQL请求,进行语法解析和逻辑优化,生成执行计划。这一步骤是查询优化的关键,TiDB Server会利用其优化器来决定最有效的查询执行路径。
- 分布式协调器PD(Placement Driver) :PD是TiDB的元数据管理组件,负责存储集群的元信息,包括数据分布和节点状态。它与TiDB Server交互,协调数据的分布和负载均衡。
- 分布式存储TiKV :TiKV是一个分布式的键值存储系统,负责存储实际的数据。TiDB Server通过PD与TiKV进行交互,获取或写入数据。
- 执行器 :在获取到数据后,TiDB Server的执行器负责进行数据的进一步处理,包括合并、排序、分页和聚合等操作。
特点 :
- 水平扩展 :TiDB Server可以轻松地通过增加节点来扩展系统的处理能力。
- 高可用性 :TiDB Server设计为无状态,可以快速故障转移,保证服务的连续性。
- 强一致性 :通过分布式事务和MVCC机制,TiDB保证了事务的ACID属性。
MySQL架构详细描述
传统单体架构:
- 集中式处理 :MySQL的所有数据库操作,包括SQL解析、查询优化、数据存储和检索,都在同一服务器上完成。
- 单一数据存储 :数据存储在本地磁盘或连接的存储系统中,没有分布式存储的概念。
- 垂直扩展依赖 :由于是单体架构,MySQL通常通过增加单个服务器的硬件能力(如CPU、内存、存储)来提升性能,这称为垂直扩展。
特点 :
- 简化管理 :由于所有组件都在一个服务器上,管理和维护相对简单。
- 扩展性限制 :垂直扩展有其物理限制,当达到硬件极限时,性能提升会遇到瓶颈。
- 事务和并发处理 :MySQL通过行锁和表锁等机制来处理并发和事务,但在高并发场景下可能会遇到性能瓶颈。
结构对比总结
- 扩展性 :TiDB的分布式架构允许其水平扩展,而MySQL主要依赖垂直扩展。
- 容错能力 :TiDB通过多节点和副本机制提供高可用性,MySQL则依赖于主从复制和故障转移机制。
- 性能 :TiDB通过分布式计算和存储优化了大规模数据集的性能,MySQL在大规模数据集下可能会遇到性能瓶颈。
- 复杂性与灵活性 :TiDB的架构较为复杂,但提供了更高的灵活性和扩展性;MySQL架构简单,但在处理大规模和高并发场景时可能需要额外的优化措施。
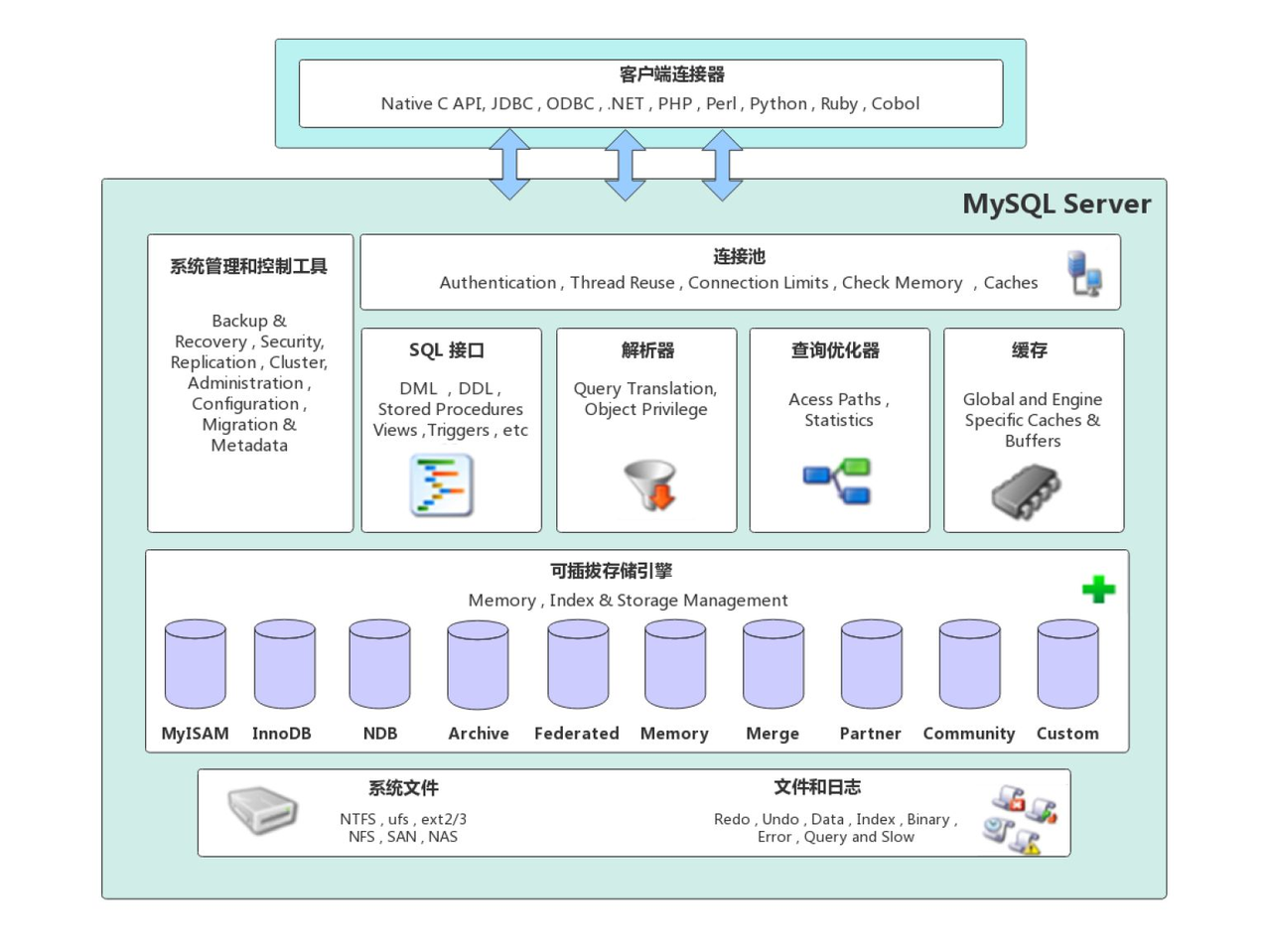
MySQL 架构图
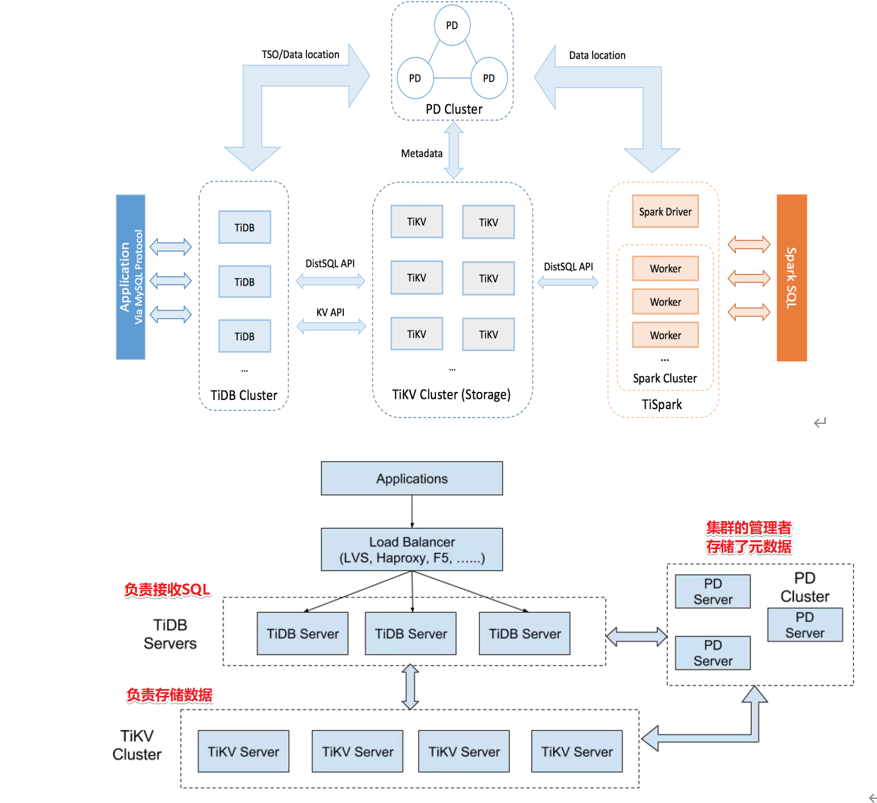
TiDB 架构图
存储层
MySQL存储架构
InnoDB存储引擎:
- MySQL的默认存储引擎是InnoDB,它是一个健壮的事务型存储引擎,支持ACID事务。
- 所有数据都存储在表空间中,表空间可以包含多个数据文件和日志文件。
- 表数据以B+树的索引结构存储,这为快速的数据访问提供了基础。
B+树索引结构:
- 主键索引和非主键索引都是B+树结构,其中非主键索引的叶子节点存储主键值,用于快速定位到具体的数据行。
- B+树的每个节点可以存储更多的键值,这意味着相比B树,B+树的高度更低,查询效率更高。
事务和MVCC:
- InnoDB通过行级锁定和MVCC机制来支持高并发的读写操作。
- 通过Undo日志来实现MVCC,允许在不锁定资源的情况下读取历史数据版本。
TiDB存储层
TiKV分布式键值存储:
- TiKV是TiDB的分布式存储层,它使用RocksDB作为其本地存储引擎,优化了写入性能和磁盘空间使用。
- TiKV将数据分散存储在多个节点上,通过Raft协议保证数据的强一致性和高可用性。
MVCC版本控制:
- TiKV使用MVCC机制来处理并发控制和历史数据版本,每个事务都会获取一个全局唯一的时间戳(TS)作为版本号。
- 通过这种方式,TiKV可以支持同一时间点的多个事务读取到一致的数据快照。
数据存储格式:
- 主键数据存储格式为
tablePrefix{tableID}_recordPrefixSep{Col1},其中Value包含了行数据的所有列值。 - 唯一索引的存储格式为
tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue,Value为对应的行ID。 - 非唯一索引的存储格式与唯一索引类似,但每个索引值后附加行ID,
Value可能为null。
特点:
- TiKV的存储层设计为易于扩展,可以水平扩展以适应不断增长的数据量。
- 通过Raft协议,TiKV能够在多个副本之间同步数据,提高了数据的可用性和容错能力。
存储层对比总结
- 扩展性 :TiDB的TiKV存储层设计为分布式,易于水平扩展,而MySQL的InnoDB存储引擎通常需要垂直扩展。
- 并发控制 :TiDB使用MVCC和TSO(Timestamp Ordering)来实现并发控制,而MySQL使用行级锁定和MVCC。
- 数据一致性 :TiKV通过Raft协议保证跨多个节点的数据一致性,InnoDB则依赖于单个服务器的事务日志和恢复机制。
- 存储效率 :TiKV的RocksDB存储引擎优化了写入性能和压缩,而InnoDB的B+树结构优化了读取性能。
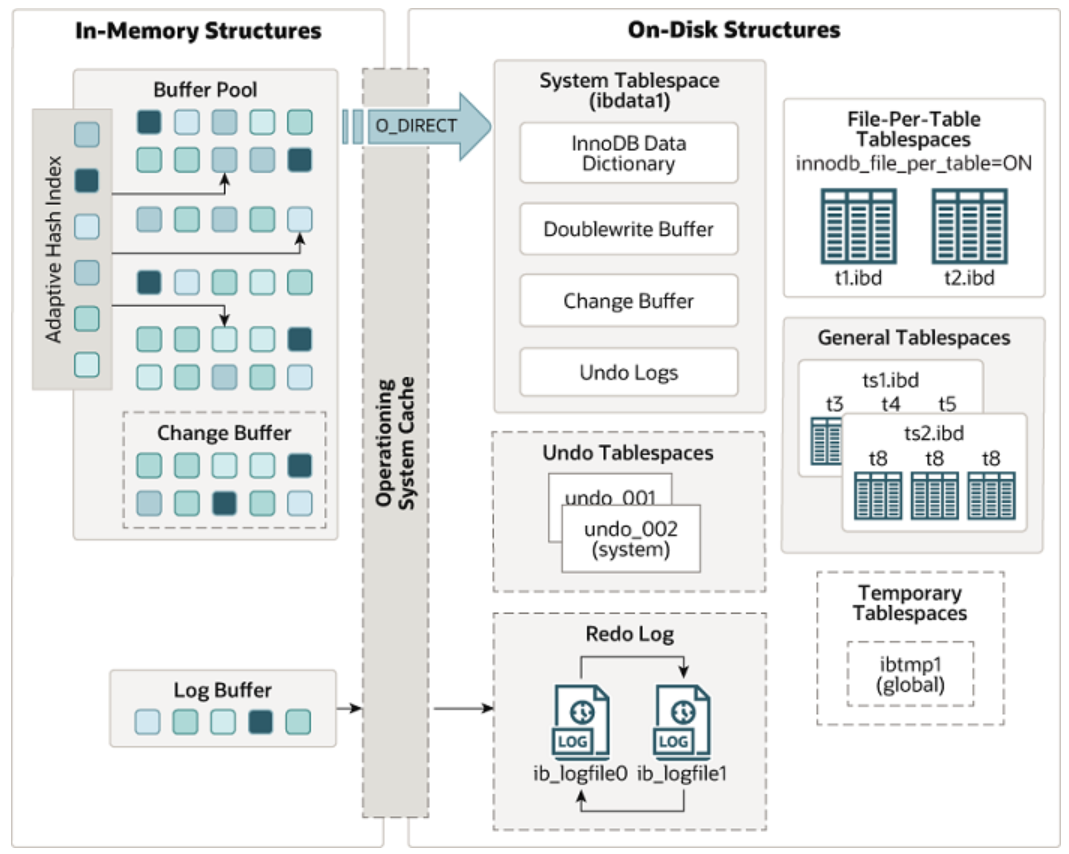
MySQL 存储架构
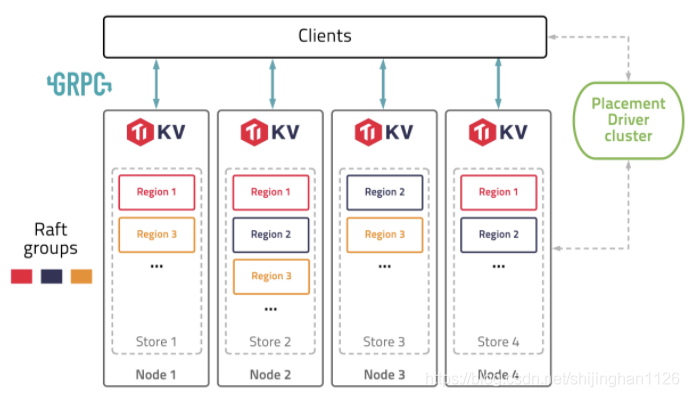
TiDB 存储层架构
TiDB索引实现
KV存储模型:
- TiDB的索引基于键值(Key-Value)存储模型实现。这种模型非常适合分布式环境,因为它允许数据的水平分割和分布式存储。
主键索引:
- 主键索引使用行的主键值作为键,行数据的序列化形式作为值。例如,如果
Col1是主键,则键可能表示为tablePrefix{tableID}_recordPrefixSep{Col1}。 - 这种映射允许TiDB通过主键值直接访问对应的行数据,提供了高效的数据检索。
唯一索引:
- 唯一索引使用索引列的值作为键,行的主键值作为值。例如,键可能表示为
tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue,值是对应的RowID。 - 这种设计确保了索引的唯一性,并且可以通过索引值快速定位到具体的数据行。
非唯一索引:
- 非唯一索引与唯一索引类似,但允许同一个键对应多个值。在这种情况下,键仍然是索引列的值,但值是包含
RowID的列表。 - 这允许TiDB处理具有相同索引值的多行数据。
特点:
- TiDB的索引实现简化了分布式环境下的数据访问,通过键值对直接映射,提高了查询效率。
- 由于TiDB的存储层TiKV使用RocksDB,索引数据也被优化存储,以减少磁盘空间的使用。
MySQL索引实现
B+树结构:
- MySQL的索引基于B+树结构,这是一种自平衡树,优化了读写性能和空间使用。
- B+树的所有数据都存储在叶子节点,内部节点仅存储键值和指向子节点的指针,这减少了查找过程中的磁盘I/O操作。
主键索引:
- 主键索引是聚簇索引,非主键索引是二级索引。聚簇索引的叶子节点直接包含行数据,而非主键索引的叶子节点包含主键值,用于快速跳转到聚簇索引。
非主键索引:
- 非主键索引的叶子节点不直接存储行数据,而是存储对应的主键值。查询时,需要通过主键值回表查询,访问聚簇索引以获取完整的行数据。
特点:
- B+树结构减少了查询过程中的I/O操作次数,提高了数据访问速度。
- 聚簇索引和非聚簇索引的设计,优化了数据的物理存储,减少了冗余和空间使用。
索引实现对比总结
- 数据访问方式 :TiDB通过键值对直接映射数据,而MySQL通过B+树结构进行索引。
- 分布式适应性 :TiDB的索引实现更适合分布式环境,易于水平扩展。MySQL的B+树索引则优化了单个服务器上的数据访问。
- 查询效率 :TiDB的索引实现允许快速的数据检索,特别是在分布式查询中。MySQL的B+树索引通过减少I/O操作提高了查询效率。
- 存储优化 :TiDB的RocksDB存储引擎优化了索引数据的存储,而MySQL的B+树结构减少了索引的存储空间需求。
MySQL 索引 b+tree
TiDB 中 Rocksdb 分布式 leveldb lsm
TiDB事务处理和MVCC
TiDB事务模型:
- TiDB支持两种类型的锁:乐观锁和悲观锁,以适应不同的业务场景。
- 乐观锁 :适用于写冲突较少的环境,通过检测在事务开始后数据是否被其他事务修改来避免锁的争用。如果检测到冲突,事务会进行重试。
- 悲观锁 :适用于高冲突环境,通过在事务开始时就锁定涉及的数据行,防止其他事务修改这些数据。
MVCC实现:
- TiDB采用MVCC机制来提供在不锁定资源的情况下读取历史数据版本的能力,从而提高并发性能。
- MVCC通过为每个事务分配一个全局唯一的时间戳(TS),并使用这个时间戳来确定数据的可见性。
- 在TiDB中,每个数据行都保存了多个版本,每个版本都有一个开始和结束的时间戳。查询操作会根据当前事务的时间戳来确定应该读取哪个版本的数据。
MySQL事务处理和MVCC
InnoDB事务模型:
- MySQL的InnoDB存储引擎支持ACID(原子性、一致性、隔离性、持久性)事务。
- InnoDB使用行级锁定机制来处理并发写入,确保事务的隔离性。
MVCC实现:
- InnoDB通过Undo Log来实现MVCC,允许在不锁定资源的情况下读取历史数据版本。
- Undo Log记录了数据在事务开始前的状态,这样即使在其他事务修改了数据之后,当前事务仍然可以读取到事务开始前的数据状态。
- InnoDB的MVCC主要通过Read View来实现,Read View是一个快照,包含了在事务开始时所有已提交的数据的可见性信息。
锁机制:
- InnoDB主要使用悲观锁,通过行锁和表锁来处理数据的并发访问,防止数据的不一致性。
- 行锁在SELECT ... FOR UPDATE或INSERT/UPDATE/DELETE操作时自动加锁,以保证事务的原子性和隔离性。
- 表锁在某些特定的操作,如全表扫描或某些类型的索引操作中使用。
事务与MVCC对比总结
- 锁机制 :TiDB支持乐观锁和悲观锁,提供了更灵活的锁策略,而MySQL主要使用悲观锁。
- MVCC实现 :TiDB使用时间戳和版本控制来实现MVCC,而InnoDB使用Undo Log和Read View。
- 并发性能 :TiDB的MVCC机制通过减少锁的争用来提高并发性能,特别是在高并发读写的场景下。InnoDB的MVCC通过Undo Log减少锁的使用,但在高冲突环境下可能仍然会遇到锁争用。
- 历史数据访问 :TiDB和InnoDB都允许在不锁定资源的情况下访问历史数据版本,提高了系统的并发读取能力。
通过这种详细的事务和MVCC机制对比,我们可以更深入地理解TiDB和MySQL在事务处理和并发控制方面的差异,以及它们如何适应不同的业务场景和性能需求。
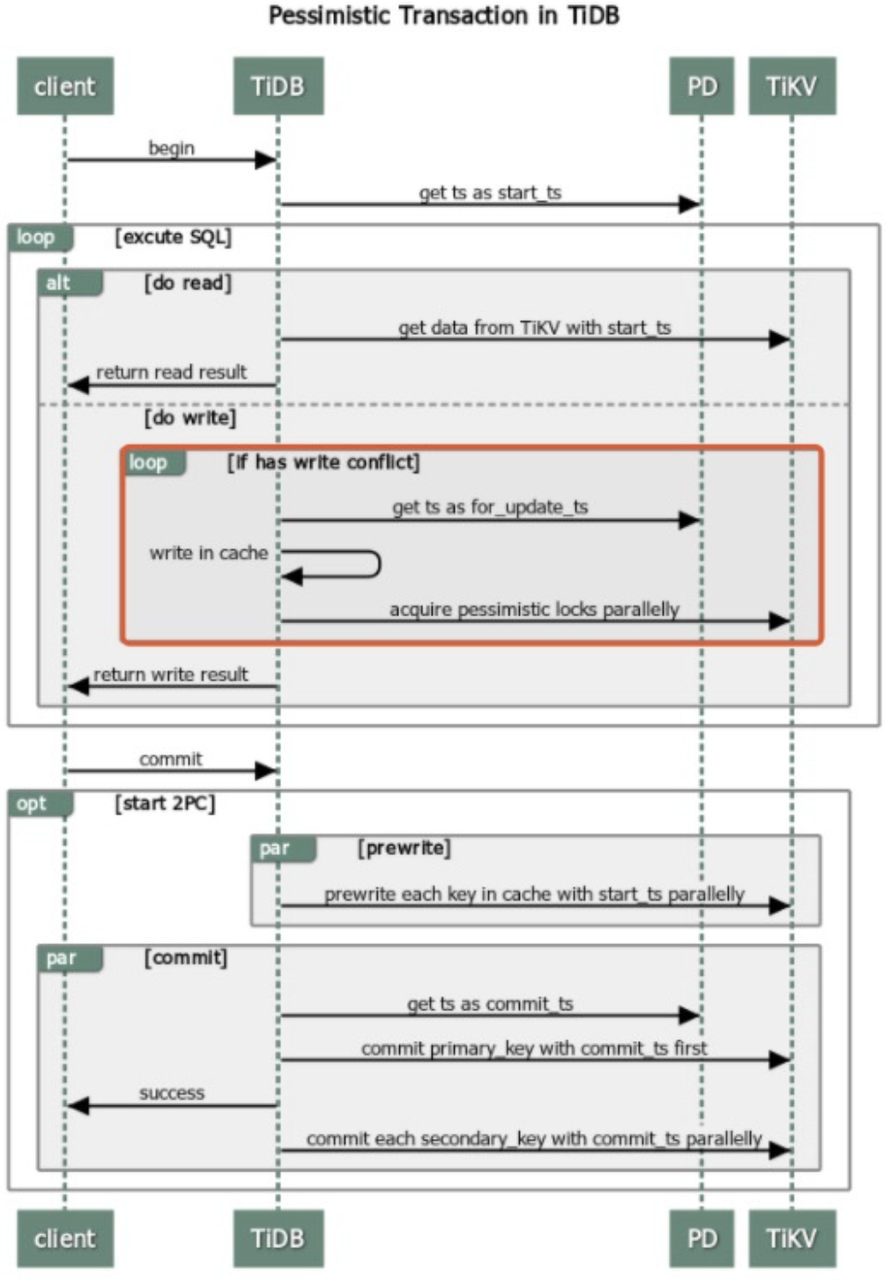
TiDB 同时支持了乐观锁和悲观锁模式
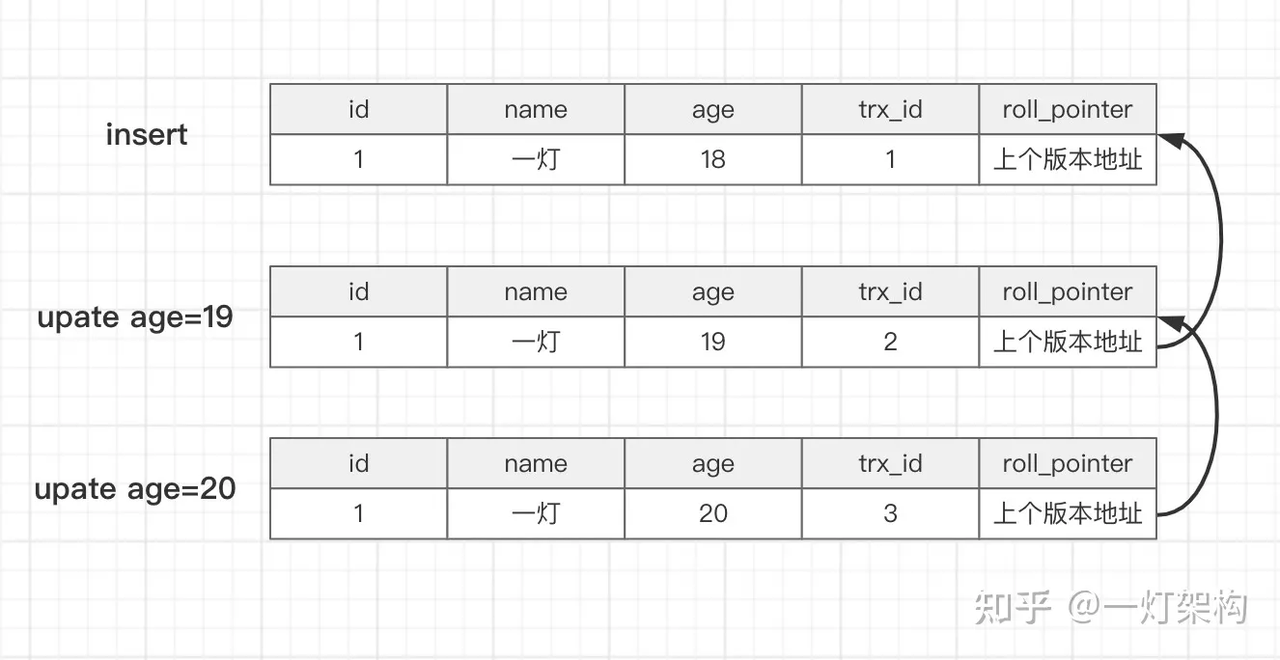
MySQL 通过undolog实现( Redo Log、Undo Log、Bin Log )

TiDB MVCC 的实现
SQL生命周期
- TiDB SQL执行 :分布式环境中,SQL执行涉及多个组件和步骤,包括索引使用、存储引擎选择等。
- 性能分析工具 :使用
EXPLAIN和EXPLAIN ANALYZE分析SQL执行计划和实际执行情况。
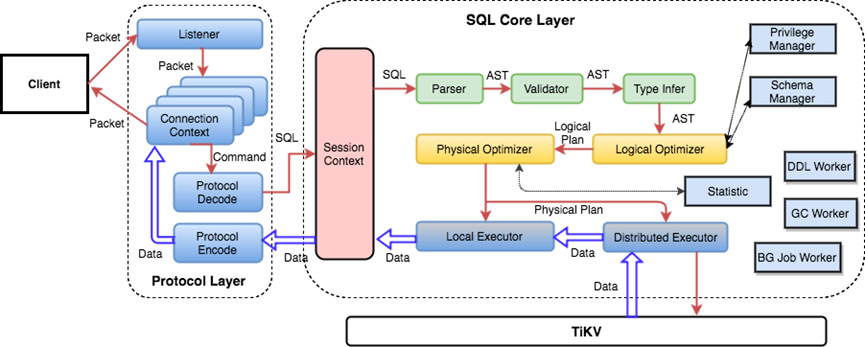
由于是分布式数据库,在 TiDB 中 SQL 的执行和 MySQL 有很大区别,如索引实现、存储机制等。
- 在 TiDB 中查询一条 SQL 是如何执行的,使用的引擎,索引等信息操作如下:
explain yoursql;
explain analyze yoursql; //真实执行
- SQL 语法的兼容性
TiDB 语法兼容了 MySQL 8.0 的绝大部分语法,目前仅发现新版的 MySQL 一些特殊语法不支持,比如default CURRENT_DATE;同时新增了一些语法,比如主键索引 auto_random 的类型,基本上业务上一般已经用的 MySQL 的 SQL 基本都支持。
分区的使用
- TiDB分区 :支持多种分区类型,如Range、List和Hash分区,简化数据管理并提高查询效率。
- 分区表分析 :自动分析分区数据分布,优化查询计划。
TiDB 当前支持的类型包括 Range 分区 、 Range COLUMNS 分区 、 Range INTERVAL 分区 、 List 分区 、 List COLUMNS 分区 和 Hash 分区
- 查看分区的数据
/*查看分区的数据分布*/SHOW STATS_META where table_name = "table_demo";
/*从分区直接查询数据*/CREATE TABLE table_demo (`id` bigint(20) primary key auto_random,start_time timestamp(3)
) PARTITION BY RANGE (FLOOR(UNIX_TIMESTAMP(`start_time`)))SELECT * FROM table_demo PARTITION (p1) where xxx;
/* 新增分区 */
ALTER TABLE table_demo ADD PARTITION(PATITION p2 VALUES LESS THAN ( FLOOR(UNIX_TIMESTAMP(`start_time`))/* 删除分区 */
ALTER TABLE table_demo drop partition p1
- 分区表的说明:
TiDB 每个分区都是单独的一张表,会对每个分区进行统计,如查询的时候进行逻辑优化,推算数据在哪些分区里面;TiFlash 也支持分区。
- 分区表的分析
TiDB 分区表分析有利于统计索引(分区)的分布情况
show variables like '%tidb_auto_analyze_end_time%';
set global tidb_auto_analyze_end_time = "06:00 +0000";
analysis table table_name; //分析表,有利于执行计划
列式存储 TiFlash
TiDB 提供了列式存储引擎 TiFlash,它是 TiKV 的列存扩展,在提供了良好的隔离性的同时,也兼顾了强一致性。
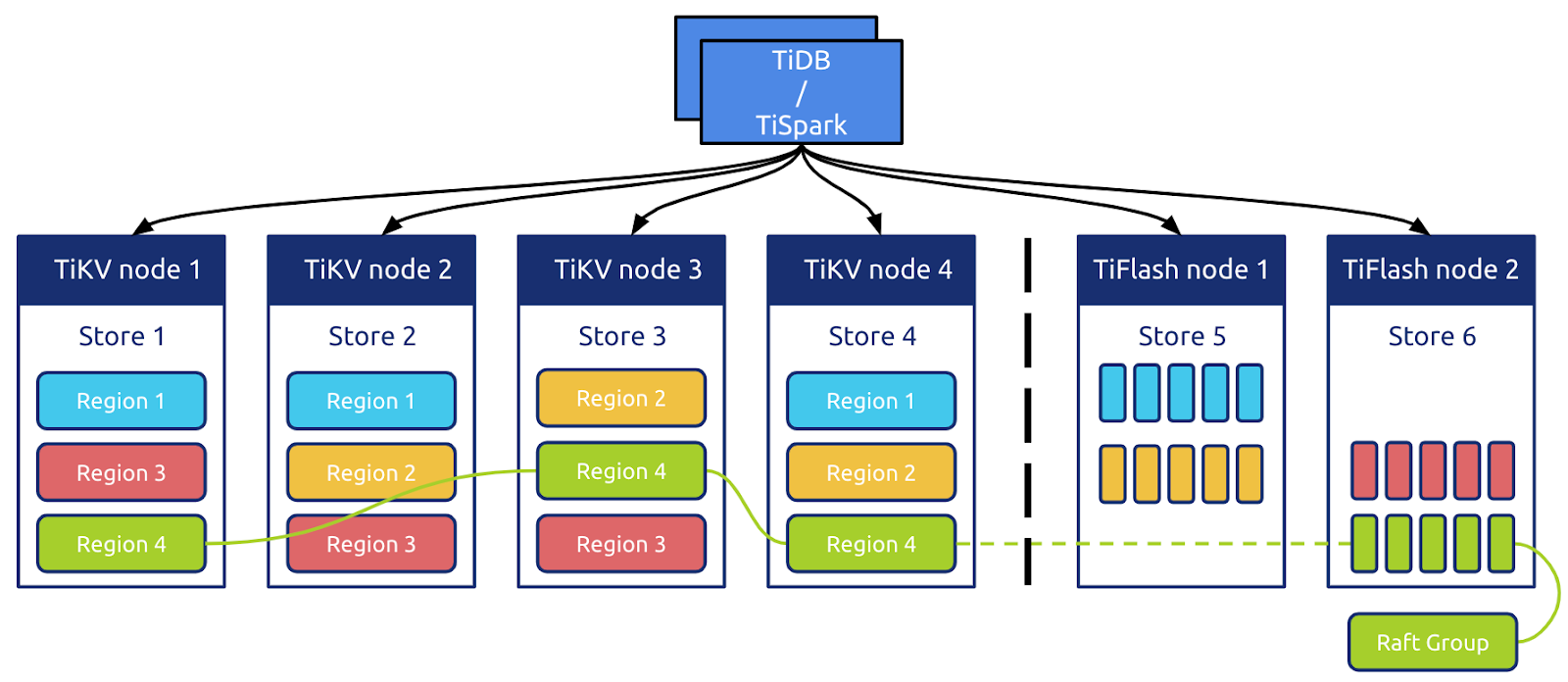
只需在 TiDB 做出一些设置,数据就可以从 TiKV->TiFlash 同步过去。
//增加tiflash副本
ALTER TABLE table_name SET TIFLASH REPLICA count;//查看数据同步进度
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = '<db_name>' and TABLE_NAME = '<table_name>';
TiDB 可以根据表分析的情况综合索引信息和数据量,自动选择使用 TiFlash 或者 TiKV,也可以在 SQL 内指定使用的存储引擎,且支持多表。
select /*+ read_from_storage(tiflash[table_name]) */ ... from table_name;
解决方案
原始的 MySQL 数据库中都是用户业务数据,蔚来数据团队为了稳妥采取了先将数据写入到 MySQL,再通过 DM ( TiDB Data Migration )将数据同步到 TiDB 中,内部各大系统直接使用 TiDB 进行查询,大幅优化了查询性能。
同步之后,蔚来数据团队用 20 亿单表业务数据作验证,分别在 MySQL 和 TiDB 运行,进行性能对比:
| Join 性能 | 查询耗时稳定性 | Count 性能 | 体验 | |
| MySQL | 查询的性能比较稳定快,平均 5s,但是30% 查询条件下超时,业务无法接受 | join 查询比较稳定 | 几乎无法 count | 分页功能无法使用,只能下一页 |
| TiDB | 部分条件快,部分条件慢,大部分条件下在 2-3s 左右,95% 的查询 2s 内出结果 | 稳定 | count 比较快 3s 左右 | 可以分页,分页数几十万可能sql内存超限制 |
在此基础上,蔚来数据应用团队又对 TiDB 性能又做出进一步优化,如使用分区表,缩小减少潜在的查询范围,使用 TiFlash 列存,进一步优化查询效率等。
经过优化,TiDB 的 Join 查询业务上 80% 查询达到 2s 内,20% 查询在 5s 内。Count 结果很快,用户体验非常好。
总结
目前,TiDB 已经在蔚来内部得到了大范围推广,有多个业务开始使用 TiDB。业务方反馈 TiDB 真正解决了业务中的很多问题,并且在使用中表现非常平稳,稳定性超乎预料,大大增强了使用国产分布式数据库的信心。
活动回顾









相关文章:
蔚来汽车:拥抱TiDB,实现数据库性能与稳定性的飞跃
作者: Billdi表弟 原文来源: https://tidb.net/blog/449c3f5b 演讲嘉宾:吴记 蔚来汽车Tidb爱好者 整理编辑:黄漫绅(表妹)、李仲舒、吴记 本文来自 TiDB 社区合肥站走进蔚来汽车——来自吴记老师的演讲…...

【Django+Vue3 线上教育平台项目实战】构建高效线上教育平台之首页模块
文章目录 前言一、导航功能实现a.效果图:b.后端代码c.前端代码 二、轮播图功能实现a.效果图b.后端代码c.前端代码 三、标签栏功能实现a.效果图b.后端代码c.前端代码 四、侧边栏功能实现1.整体效果图2.侧边栏功能实现a.效果图b.后端代码c.前端代码 3.侧边栏展示分类及…...

对比 UUIDv1 和 UUIDv6
UUIDv6是UUIDv1的字段兼容版本,重新排序以改善数据库局部性。UUIDv6主要在使用UUIDv1的上下文中实现。不涉及遗留UUIDv1的系统应该改用UUIDv7。 与 UUIDv1 将时间戳分割成低、中、高三个部分不同,UUIDv6 改变了这一序列,使时间戳字节从最重要…...
记一次饱经挫折的阿里云ROS部署经历
前言 最近在参加的几个项目测评里,我发现**“一键部署”这功能真心好用,省下了不少宝贵时间和力气,再加上看到阿里云现在有个开源上云**的活动。趁着这波热潮,今天就聊聊怎么从头开始,一步步搞定阿里云的资源编排服务…...

代码运行故障排除:PyCharm中的问题解决指南
代码运行故障排除:PyCharm中的问题解决指南 引言 PyCharm,作为一款流行的集成开发环境(IDE),提供了强大的工具来支持Python开发。然而,即使是最先进的IDE也可能遇到代码无法运行的问题。这些问题可能由多…...

css实现渐进中嵌套渐进的方法
这是我们想要的实现效果: 思路: 1.有一个底色的背景渐变 2.需要几个小的块级元素做绝对定位通过渐变filter模糊来实现 注意:这里的采用的定位方法,所以在内部的元素一律要使用绝对定位,否则会出现层级的问题&…...

JavaWeb后端学习
Web:全球局域网,万维网,能通过浏览器访问的网站 Maven Apache旗下的一个开源项目,是一款用于管理和构建Java项目的工具 作用: 依赖管理:方便快捷的管理项目以来的资源(jar包)&am…...

VUE_TypeError: Cannot convert a BigInt value to a number at Math.pow 解决方法
错误信息 TypeError: Cannot convert a BigInt value to a number at Math.pow vue 或 react package.json添加 "browserslist": {"production": ["chrome > 67","edge > 79","firefox > 68","opera >…...

Linux下mysql数据库的导入与导出以及查看端口
一:Linux下导出数据库 1、基础导出 要在Linux系统中将MySQL数据库导出,通常使用mysqldump命令行工具。以下是一个基本的命令示例,用于导出整个数据库: mysqldump -u username -p database_name > export_filename.sql 其中&a…...

Open3d入门 一文读懂三维点云
三维点云技术的发展始于20世纪60年代,随着激光雷达和三维扫描技术的进步,在建筑、考古、地理信息系统和制造等领域得到了广泛应用。20世纪90年代,随着计算机处理能力的提升,点云数据的采集和处理变得更加高效,推动了自…...
-基础介绍)
pyinstaller系列教程(一)-基础介绍
1.介绍 PyInstaller是一个用于将Python应用程序打包为独立可执行文件的工具,它支持跨平台操作,包括Windows、Linux和MacOS等操作系统。特点如下: 跨平台支持:PyInstaller可以在多个操作系统上运行,并生成相应平台的可…...

echarts图表:类目轴
category 类目轴,适用于离散的类目数据。 例如商品名称、时间等。 类目轴上的每个刻度代表一个类目,刻度之间没有量的关系,只是简单的分类。 在类目轴上,数据点会对应到相应的类目上。...

SSM贫困生申请管理系统-计算机源码84308
摘要 随着教育信息化的不断推进,越来越多的高校开始借助信息技术手段提升贫困生申请管理的效率与准确性。为此,我们设计并实现了SSM贫困生申请管理系统,旨在通过信息化手段优化贫困生申请流程,提高管理效率,为贫困生提…...

[C++]——同步异步日志系统(5)
同步异步日志系统 一、日志消息格式化设计1.1 格式化子项类的定义和实现1.2 格式化类的定义和实现 二、日志落地类设计2.1 日志落地模块功能实现与测试2.2 日志落地模块功能功能扩展 一、日志消息格式化设计 日志格式化模块的作用:对日志消息进行格式化,…...

Qt项目:基于Qt实现的网络聊天室---TCP服务器和token验证
文章目录 TCP服务器设计客户端TCP管理者ChatServerAsioIOServicePoolSession层LogicSystem总结 token验证模块完善protoStatusServer验证token客户端处理登陆回包用户管理登陆界面 本篇完成的模块是TCP服务器的设计和token验证 TCP服务器设计 客户端TCP管理者 因为聊天服务要…...

深入理解C++构造函数
目录 1.引言 2.默认构造函数 3.自定义构造函数 4.带继承关系类的构造函数 5.带多重继承关系类的构造函数 6.带虚继承关系类的构造函数 7.总结 1.引言 对于学过C的来说,构造函数是非常熟悉不过的了。但是你真正了解它吗?构造函数内部初始化变量的顺…...

J025_斗地主游戏案例开发(简版)
一、需求描述 完成斗地主游戏的案例开发。 业务:总共有54张牌; 点数:3、4、5、6、7、8、9、10、J、Q、K、A、2 花色:黑桃、红桃、方片、梅花 大小王:大王、小王 点数分别要组合4种花色,大小王各一张。…...

路径规划 | 飞蛾扑火算法求解二维栅格路径规划(Matlab)
目录 效果一览基本介绍程序设计参考文献 效果一览 基本介绍 路径规划 | 飞蛾扑火算法求解二维栅格路径规划(Matlab)。 飞蛾扑火算法(Firefly Algorithm)是一种基于自然界萤火虫行为的优化算法,在路径规划问题中也可以应…...

优化Cocos Creator 包体体积
优化Cocos Creator 包体体积 引言一、优化图片文件体积:二、优化声音文件体积:三、优化引擎代码体积:四、 优化字体字库文件大小: 引言 优化Cocos Creator项目的包体体积是一个常见且重要的任务,尤其是在移动设备和网…...

TCPDump协议分析工具
TCPDump协议分析工具 TCPDump是一个强大的命令行工具,用于捕获和分析网络数据包。它能够实时监控和记录网络流量,帮助网络管理员和安全专家排查网络问题、分析流量和检测网络攻击。以下是TCPDump的详细介绍,包括其安装、基本使用、过滤规则和…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
uni-app学习笔记三十五--扩展组件的安装和使用
由于内置组件不能满足日常开发需要,uniapp官方也提供了众多的扩展组件供我们使用。由于不是内置组件,需要安装才能使用。 一、安装扩展插件 安装方法: 1.访问uniapp官方文档组件部分:组件使用的入门教程 | uni-app官网 点击左侧…...