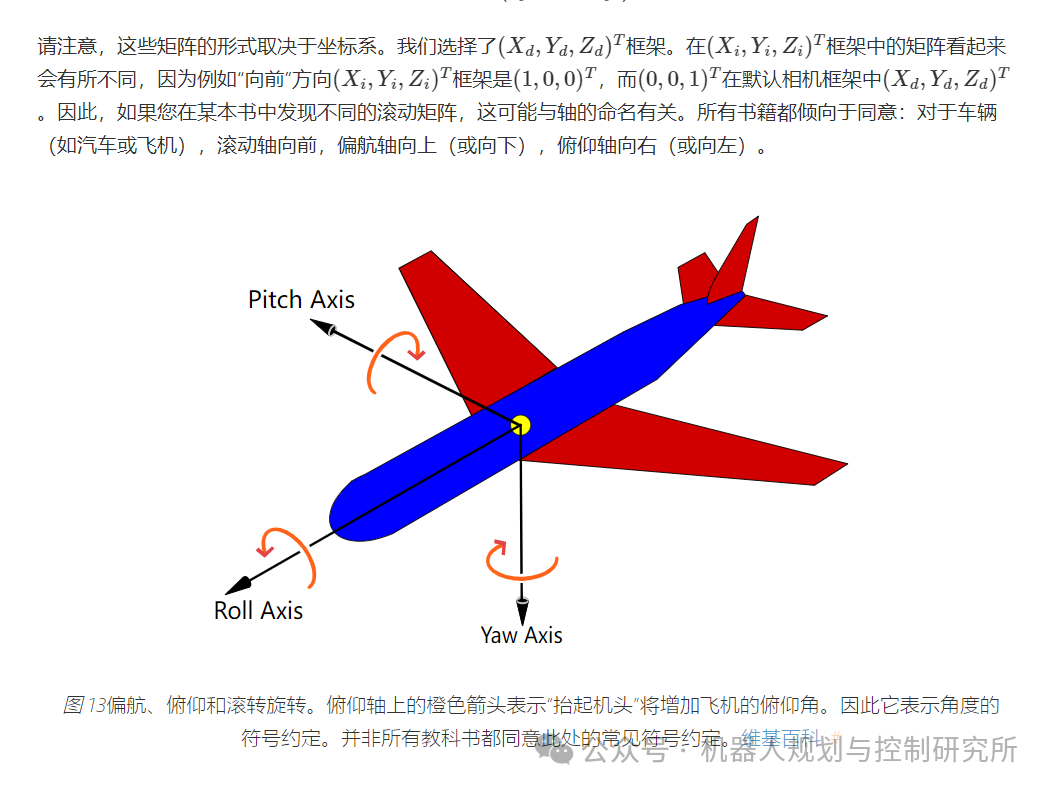
自动驾驶算法———车道检测(一)
“
在本章中,我将指导您构建一个简单但有效的车道检测管道,并将其应用于Carla 模拟器中捕获的图像。管道将图像作为输入,并产生车道边界的数学模型作为输出。图像由行车记录仪(固定在车辆挡风玻璃后面的摄像头)捕获。车道边界模型是一个多项式
在这里,x𝑥和𝑦y以米为单位。它们在道路上定义了一个坐标系,如图1所示。
管道由两个步骤组成
-
使用神经网络,检测图像中车道边界的像素
-
将车道边界像素与道路上的点关联起来,
然后拟合多项式。
该方法的灵感来自参考文献[ GBN+19 ]中描述的“基线”方法,其性能接近最先进的车道检测方法。
”

图 1道路坐标系。该视角称为鸟瞰图。
01
—
图像基础

为了表示图像,我们使用形状为 (H,W,3) 的三维数组。我们称该数组有 H 行、W 列和 3 个颜色通道(红色、绿色和蓝色)。让我们用 Python 加载图像并查看一下!
import numpy as npimport matplotlib.pyplot as pltfrom pathlib import Pathimport cv2img_fn = str(Path("images/carla_scene.png"))img = cv2.imread(img_fn)# opencv (cv2) stores colors in the order blue, green, red, but we want red, green, blueimg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img)plt.xlabel("$u$") # horizontal pixel coordinateplt.ylabel("$v$") # vertical pixel coordinateprint("(H,W,3)=",img.shape)
(H,W,3)= (512, 1024, 3)
让我们检查一下第 100 行和第 750 列的像素:
u,v = 750, 100img[v,u]
array([28, 59, 28], dtype=uint8)这意味着 处的像素具有红色强度 28、绿色强度 59 和蓝色强度 28。因此,它是绿色的。如果我们看一下图像,这是有道理的,因为 处有一棵树。此外,上面的输出“ ”告诉我们红色、绿色和蓝色强度存储为 8 位无符号整数,即。因此,它们是 0 到 255 之间的整数。u,v = 750, 100u,v = 750, 100dtype=uint8uint8
下面的示意图总结了我们迄今为止学到的关于存储数字光栅图像的知识:

如果您的数字图像是由相机拍摄的,那么数字图像中的像素与相机图像传感器中的“传感器像素”之间存在直接对应关系。

图像传感器由二维光电传感器阵列组成。每个光电传感器通过光电效应将入射光转换为电能,然后通过模数转换器将其转换为数字信号。为了获得颜色信息,一个“传感器像素”被分成 2×2 的光电传感器网格,并在这 4 个光电传感器前面放置不同的颜色滤镜。一个光电传感器仅通过蓝色滤镜接收光,一个仅通过红色滤镜接收光,两个通过绿色滤镜接收光。将这 4 个测量值结合起来可得到一个颜色三重奏:。这就是所谓的拜耳滤镜。(red_intensity, green_intensity, blue_intensity)

针孔相机模型
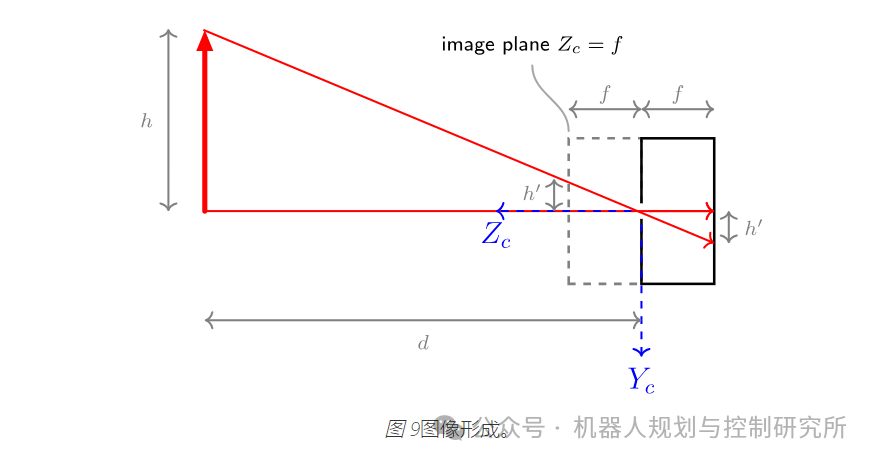
想象一下将图像传感器放在物体前面。
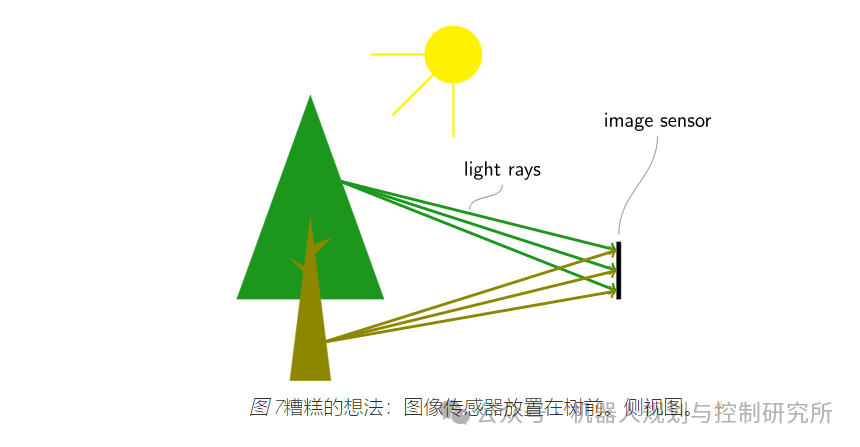
您将无法捕捉到如此清晰的图像,因为图像传感器上的某个点会受到整个环境光线的照射。现在想象一下将图像传感器放在一个带有非常小的针孔(也称为光圈)的盒子里。
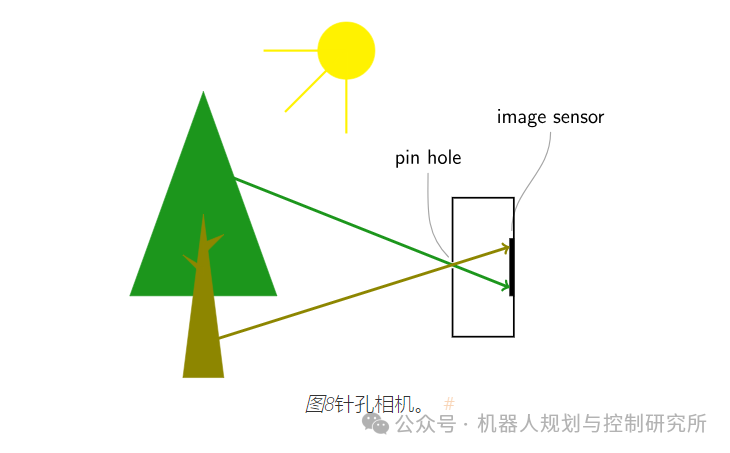
现在大部分光线都被挡住了,我们在图像传感器上得到了正确的图像。图像被上下翻转了,但这不应该困扰我们。在理想针孔的情况下,图像传感器上的每个点都只会被来自外部的一束光线击中。
理想针孔:一个很好的近似值
在现实世界中,孔的尺寸不能太小,因为进入盒子的光线不够。此外,我们还会遭受衍射的影响。孔也不能太大,因为来自不同角度的光线会照射到图像传感器上的同一点,图像会变得模糊。为了防止模糊,真实的相机中会安装镜头。我们将在本节讨论的针孔相机模型不包括镜头的影响。然而,事实证明,它非常接近带镜头的相机,也是相机的事实模型。因此,在下文中,我们可以继续将针孔视为理想的针孔。
下面的草图介绍了图像平面:


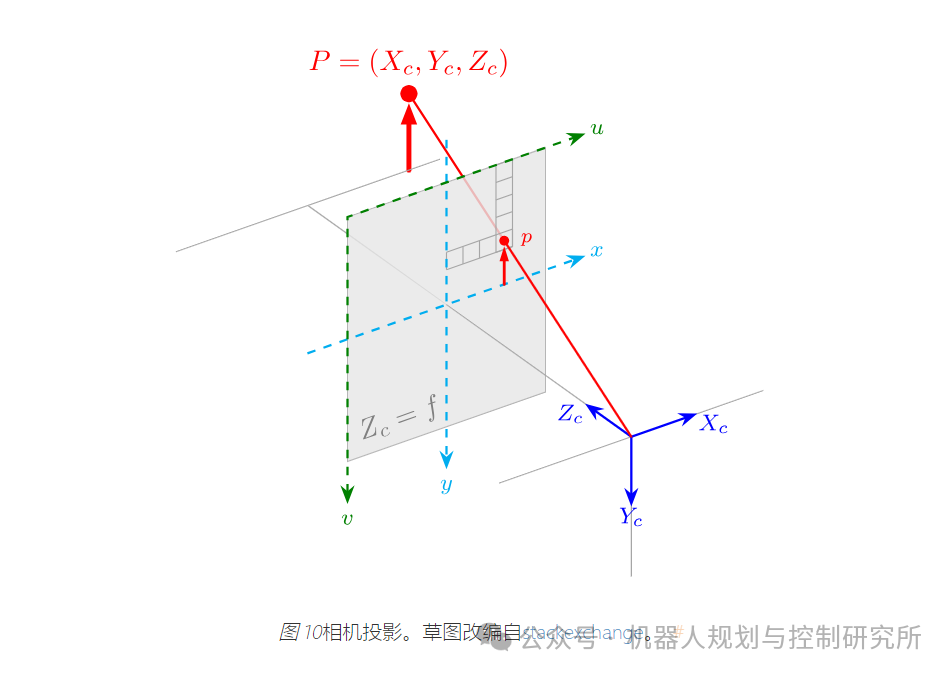
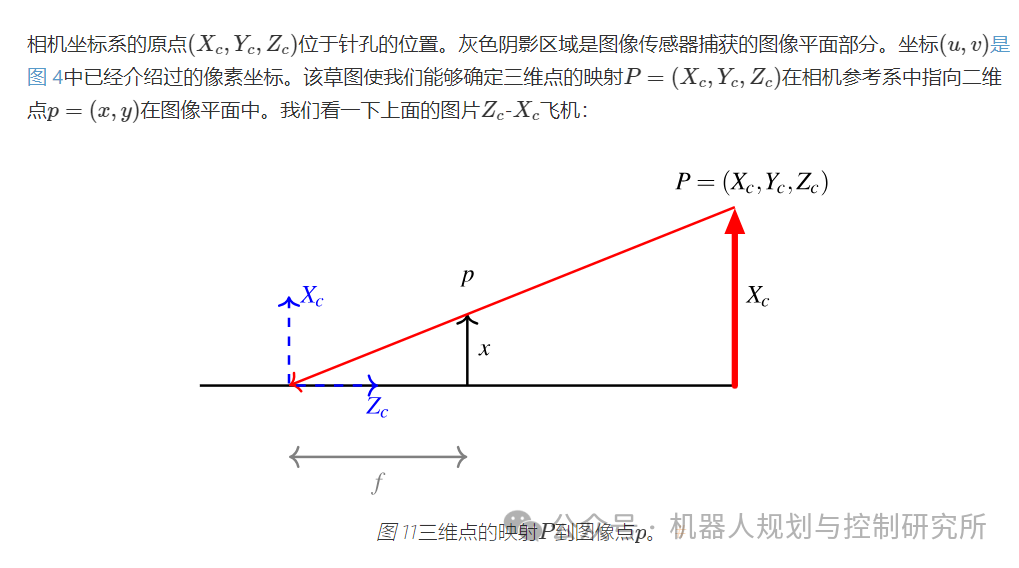







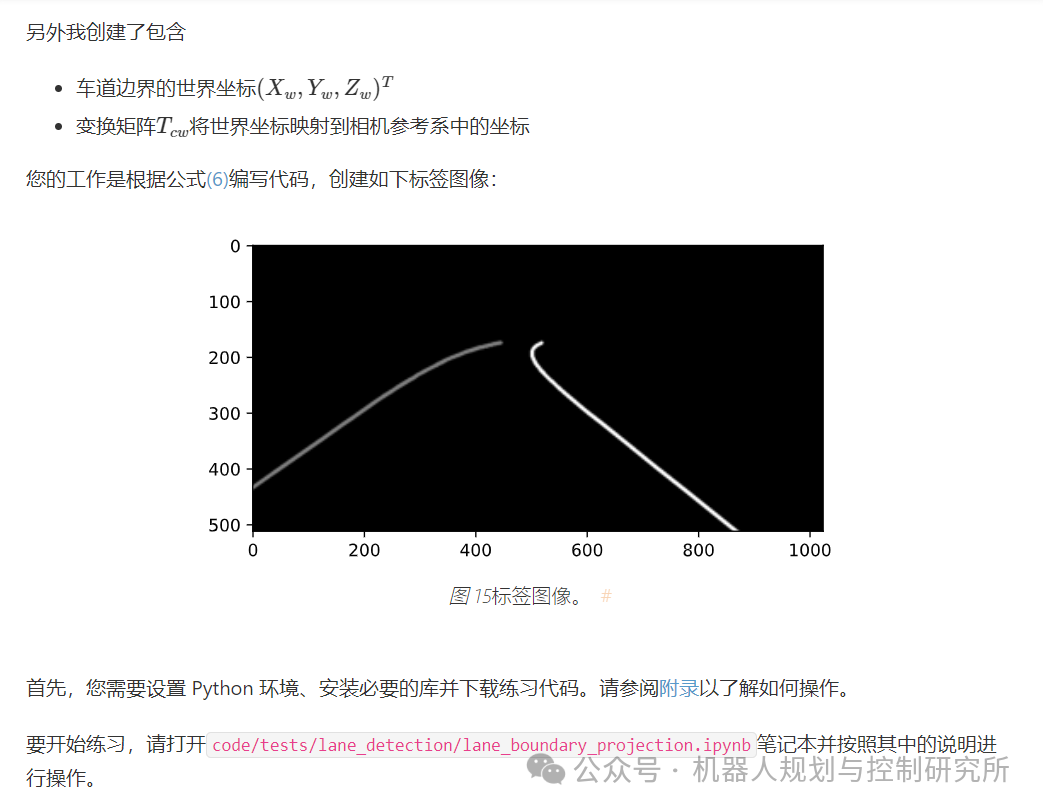
练习:将车道边界投影到图像
现在你应该开始做你的第一个练习了。对于这个练习,我为你准备了一些
数据。我使用安装在车辆上的相机传感器在 Carla 模拟器中捕捉到了一张
图片:

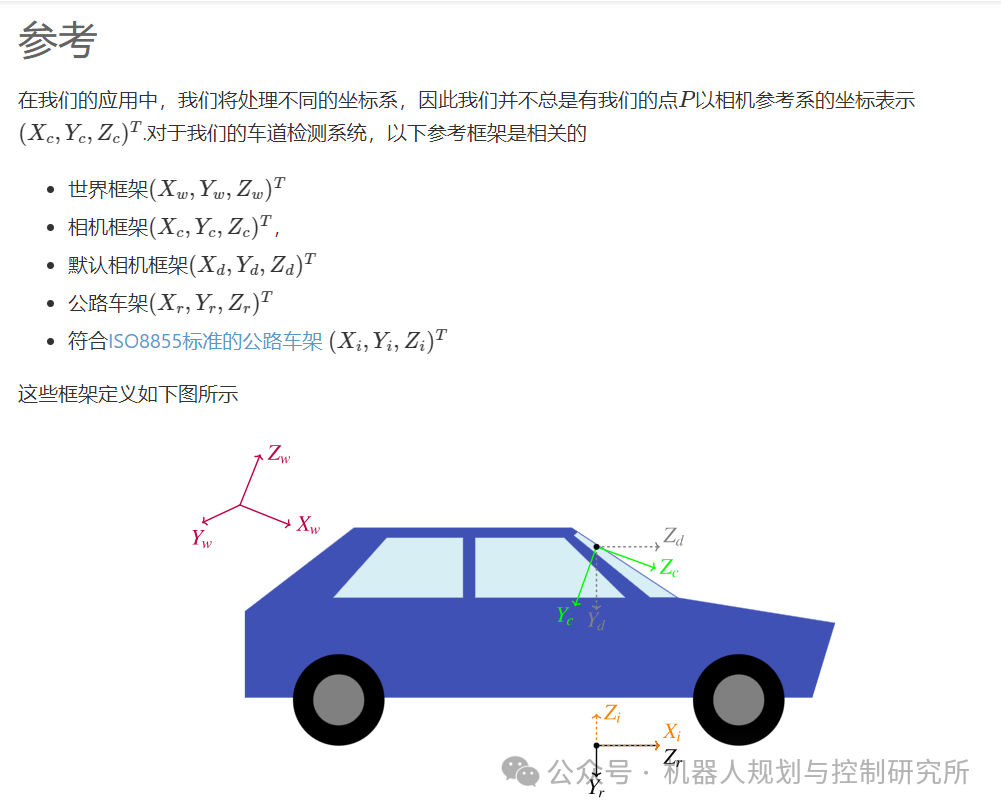
参考
-
HZ03
-
Richard Hartley 和 Andrew Zisserman。计算机视觉中的多
视图几何。剑桥大学出版社,2003 年。
02
—
车道边界分割
对于车道检测流程,我们想要训练一个神经网络,该神经网络会获取一张图像,并估计每个像素属于左车道边界的概率、属于右车道边界的概率以及不属于任何车道边界的概率。这个问题称为语义分割。
先决
对于本节,我假设以下内容
-
你知道什么是神经网络,并且之前自己训练过一个
-
你知道语义分割的概念
如果你不满足先决条件 1,我建议你查看以下免费资源之一
-
CS231n:用于视觉识别的卷积神经网络
-
对于这门优秀的斯坦福课程,你可以在网上找到所有的学习材料。课程笔记还没有完成,但确实存在的笔记非常好!请注意,当你点击详细课程大纲时,你可以看到所有讲座的幻灯片。你可能想使用2017 年的版本,因为其中包含讲座视频。但是,对于练习,你应该使用2020版本(与 2017 年非常相似),因为你可以在Google Colab中进行编程。Google Colab 让你可以在 Google 服务器上免费使用 GPU(深度学习所需的昂贵硬件)。即使你不想使用 Colab,2020 年的课程也有更好的本地工作说明(包括 anaconda)。对于你可以在 tensorflow 和 pytorch 之间选择的练习,我建议你使用 pytorch。如果你真的渴望尽快回到这门课程,你可以在了解语义分割后停止 CS231n。
-
为程序员提供实用的深度学习
-
如果您的背景更多的是编码而不是数学/科学,那么我推荐这门课程。您可以在这里找到视频讲座,在这里找到用 jupyter 笔记本编写的书(如果您喜欢,还有一个印刷版本)。我建议使用 Google Colab 进行练习。fastai 课程使用 fastai 库进行讲授,该库可帮助您使用很少的代码行来训练 pytorch 模型。即使您选择不研究 fastai 课程,我也建议您查看fastai 库,因为它使训练模型变得非常容易。也许先从阅读计算机视觉教程开始)。
关于先决条件 2 ,我推荐Jeremy Jordan 撰写的这篇关于语义分割的非常好的博客文章(主要基于 CS231n)。
最后,你需要有 GPU 才能进行练习。但拥有GPU 并不是先决条件。你可以使用Google Colab,它允许你在 Google 服务器上运行 Python 代码。要在 Colab 上访问 GPU,你应该点击“运行时”,然后点击“更改运行时类型”,最后选择“GPU”作为“硬件加速器”。有关如何使用 Colab 的更多详细信息,请参阅附录。
练习:训练神经网络进行车道边界
车道分割模型应将形状为 (512,1024,3) 的图像作为输入。这里,512 是图像高度,1024 是图像宽度,3 代表红、绿、蓝三个颜色通道。我们使用形状为 (512,1024) 的输入图像和相应的标签来训练模型,其中label[v,u]可以取值为 0、1 或 2,表示像素(𝑢,𝑣)是“无边界”、“左边界”还是“右边界”。
模型的输出应是output形状为 (512,1024,3) 的张量。
-
这个数字
output[v,u,0]给出了像素(𝑢,𝑣)不属于任何车道边界的一部分。 -
这个数字
output[v,u,1]给出了像素(𝑢,𝑣)是左车道边界的一部分。 -
这个数字
output[v,u,2]给出了像素(𝑢,𝑣)是右侧车道边界的一部分。 -
收集训练
我们可以使用 Carla 模拟器收集训练数据。我写了一个
collect_data.py脚本请注意,从四个数据项(图像、车道边界、交通矩阵、标签图像)中,只有图像和标签图像对于训练我们的深度学习模型是必要的。
所有数据均在“Town04”Carla 地图上收集,因为这是唯一一张有可用高速公路的地图(“Town06”的高速公路要么完全笔直,要么有 90 度转弯)。为简单起见,我们只为高速公路构建一个系统。因此,我们只使用地图中道路曲率较低的部分,不包括城市道路。
地图的一部分被任意选为“验证区”。在此区域中创建的所有数据的文件名都添加了字符串“validation_set”。
现在您需要将一些训练数据导入到您的机器上!我建议您下载我使用脚本为您创建的一些训练数据
collect_data.py。但如果您真的想要,您也可以自己收集数据。推荐:下载数据
只需继续打开中的启动代码
code/exercises/lane_detection/lane_segmentation.ipynb即可。它将有一个 Python 实用函数,可为您下载数据。替代方案:自己生成数据
-
存储来自相机传感器的图像
-
存储从 Carla 高清地图获得的车道边界的世界坐标
-
存储变换矩阵𝑇𝑐𝑤将世界坐标映射到相机参考系中的坐标
-
存储标签图像,该图像是根据车道边界坐标和变换矩阵创建的,如上一节练习中所示
-
在 Carla 地图上创建一辆车
-
将 RGB 摄像头传感器安装到车辆上
-
将车辆移动到不同的位置并
-
-
模型
为了创建和训练模型,您可以选择任何您喜欢的深度学习框架。
如果你需要一些指导,我建议使用 fastai。你可以使用fastai 文档中的语义分割示例,根据手头的数据集稍微修改一下,它就可以正常工作了!如果你愿意,你可以得到一些提示:
没有提示
好的,没有提示。如果您遇到困难,请尝试查看“有限提示”或“详细提示”。
基本提示高级提示
存储你的模型
您将需要训练好的模型来进行接下来的练习。因此,请将训练好的模型保存到磁盘。在 pytorch 中,您可以通过 执行此操作
torch.save。对于 fastai,您可以执行torch.save(learn.model, './fastai_model.pth')可选:参与 kaggle 活动
我为你准备的训练数据也可以在kaggle上找到。如果你愿意,你可以用 kaggle 笔记本在线创建你的模型。他们还提供免费的 GPU 访问。一旦你对你的解决方案感到满意,可以考虑在 kaggle 上发布你的笔记本。我很想看到它😃。
具体指引详见《https://thomasfermi.github.io/Algorithms-for-Automated-Driving/LaneDetection/Segmentation.html》
03
—
从像素转换米
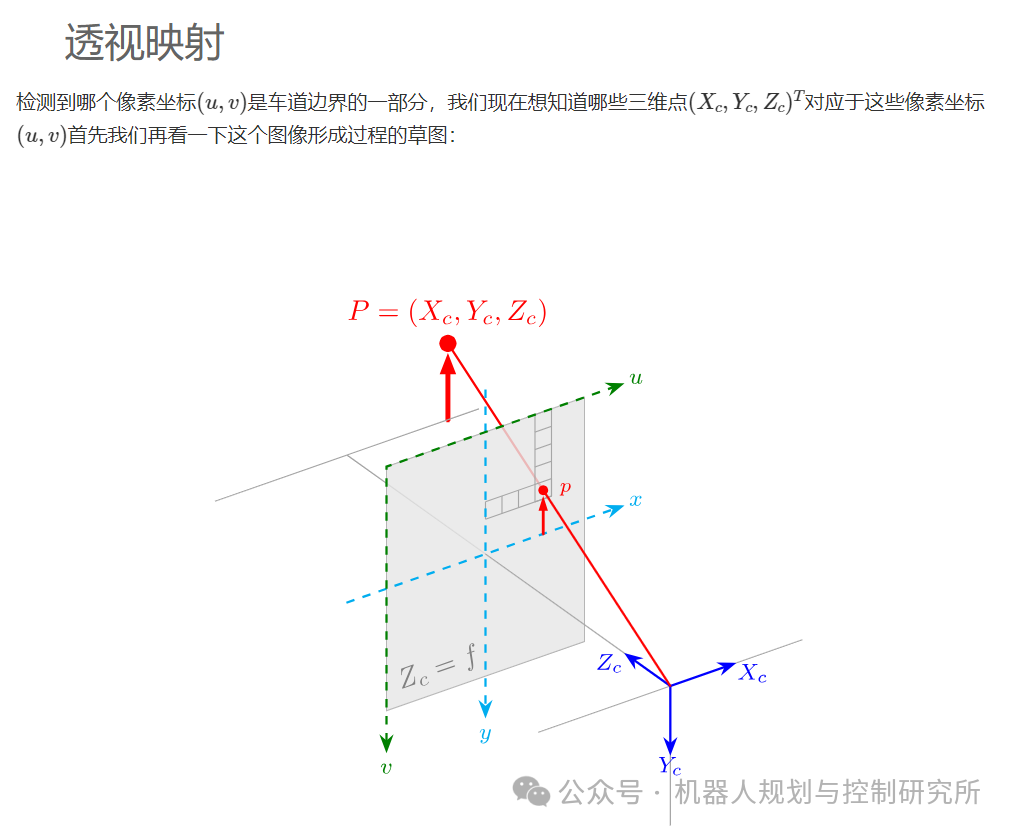

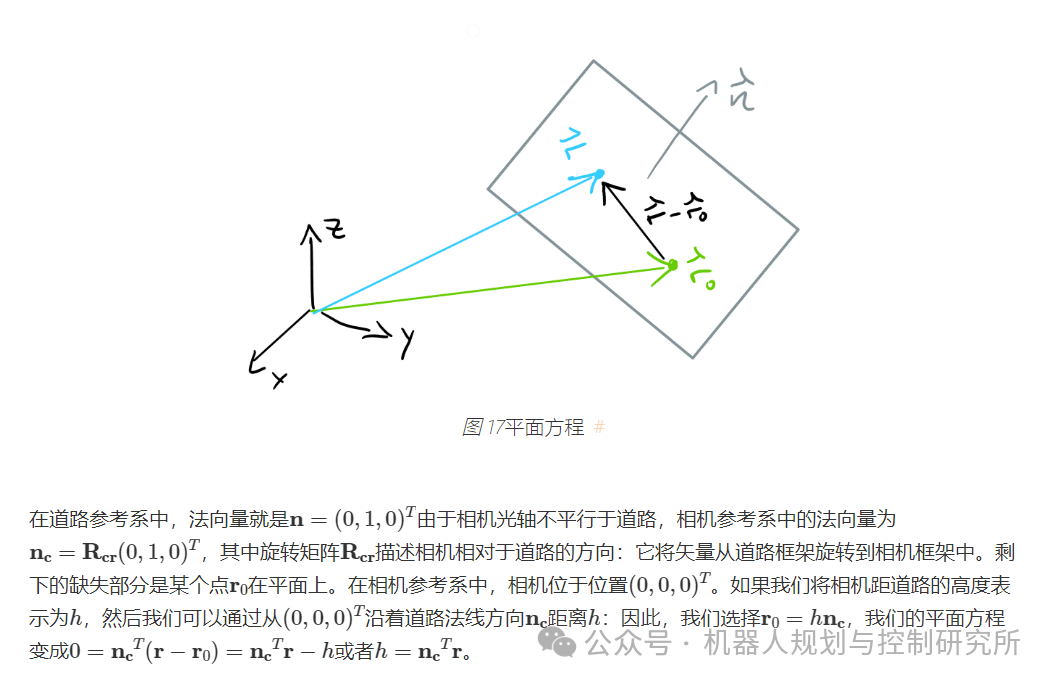


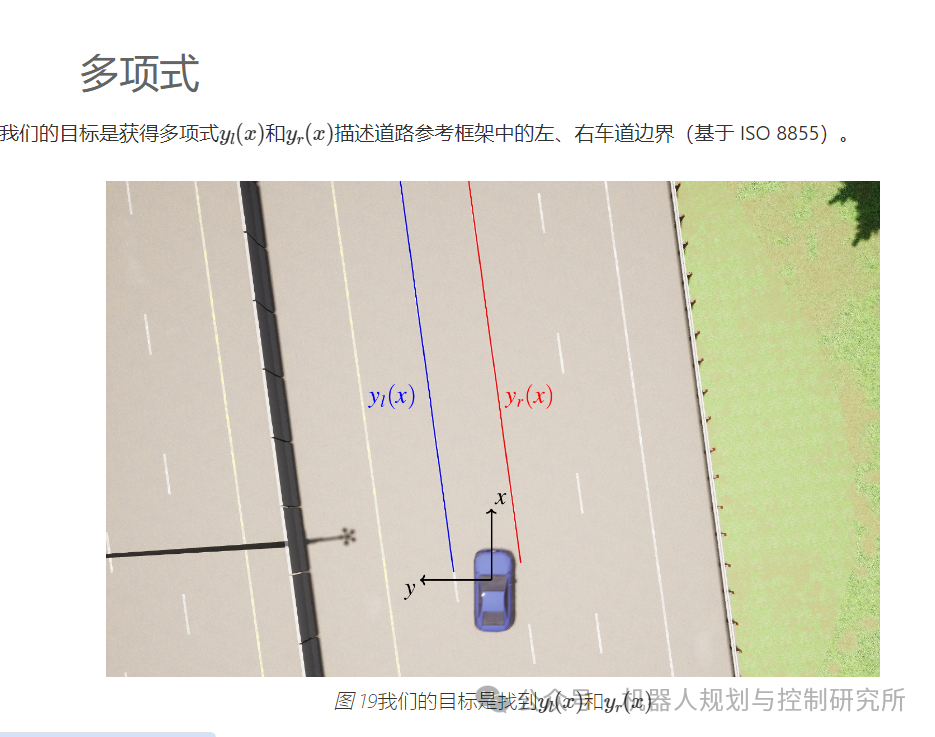
import numpy as npimport matplotlib.pyplot as plt
从车道边界分割中,我们知道我们的语义分割模型将以摄像头图像作为输入,并返回output形状为 (H,W,3) 的张量。具体来说,像素prob_left = output[v,u,1](𝑢,𝑣)是左车道边界的一部分。我将output[v,u,1]神经网络为一些示例图像计算的张量保存在 npy 文件中。让我们来看看。
prob_left = np.load("../../data/prob_left.npy")plt.imshow(prob_left, cmap="gray")plt.xlabel("$u$");plt.ylabel("$v$");
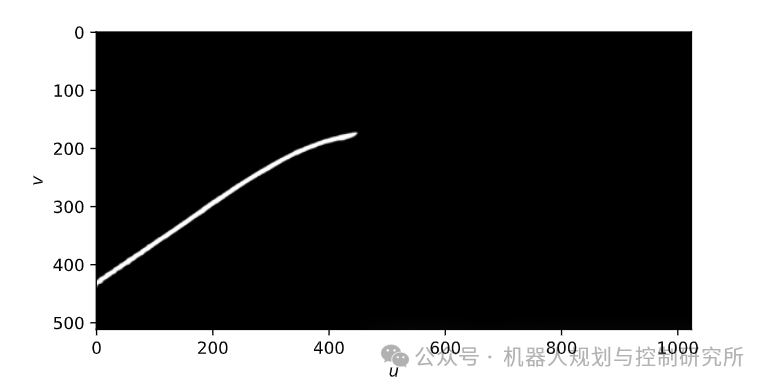
上图显示prob_left[v,u]了每个(u,v)。现在想象一下,(u,v,prob_left[v,u])我们不是使用三元组,而是使用三元组(x,y,prob_left(x,y)),其中(𝑥,𝑦)是道路上的坐标,如图19所示。如果我们有这些三元组,我们可以过滤所有较大的(x,y,prob_left[x,y])点prob_left[x,y]。我们将获得一个点列表(𝑥𝑖,𝑦𝑖)它们是左车道边界的一部分,我们可以使用这些点来拟合多项式𝑦𝑙(𝑥)!但从 到(u,v,prob_left[v,u])实际上(x,y,prob_left[x,y])并不难,因为你uv_to_roadXYZ_roadframe_iso8855在上一个练习中实现了该函数。此函数将(𝑢,𝑣)进入(𝑥,𝑦,𝑧)(注意𝑧=0对于道路像素)
这意味着我们可以开始编写一些代码来收集三元组(x,y,prob_left[x,y])
import syssys.path.append('../../code')from solutions.lane_detection.camera_geometry import CameraGeometrycg = CameraGeometry()xyp = []for v in range(cg.image_height):for u in range(cg.image_width):X,Y,Z= cg.uv_to_roadXYZ_roadframe_iso8855(u,v)xyp.append(np.array([X,Y,prob_left[v,u]]))xyp = np.array(xyp)

x_arr, y_arr, p_arr = xyp[:,0], xyp[:,1], xyp[:,2]mask = p_arr > 0.3coeffs = np.polyfit(x_arr[mask], y_arr[mask], deg=3, w=p_arr[mask])polynomial = np.poly1d(coeffs)
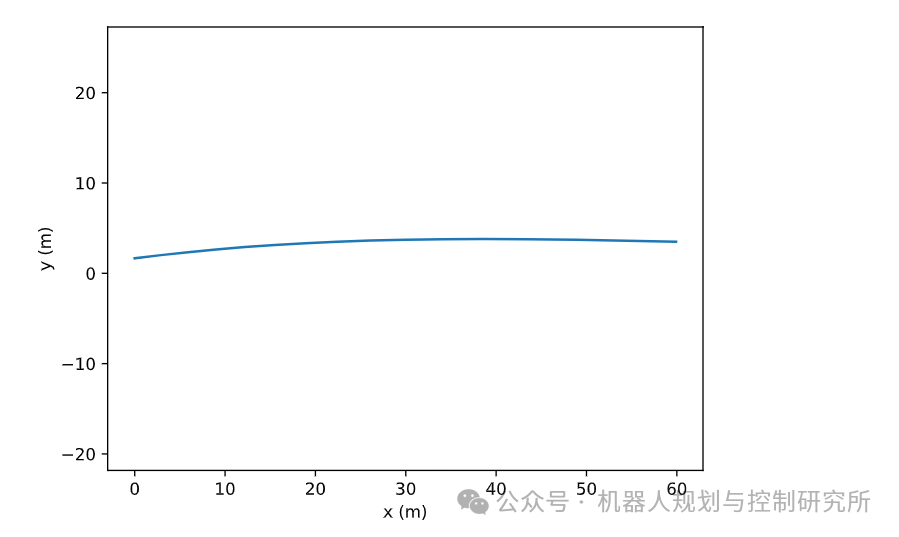
让我们绘制多项式:
x = np.arange(0,60,0.1)y = polynomial(x)plt.plot(x,y)plt.xlabel("x (m)"); plt.ylabel("y (m)"); plt.axis("equal");
管道封装成一个
您现在已经了解了车道检测流程的两个步骤:车道边界分割和多项式拟合。为了便于将来使用,将整个流程封装到一个类中会很方便。在下面的练习中,您将实现这样一个LaneDetector类。现在,让我们看一下LaneDetector实际操作的示例解决方案。首先,我们加载一个图像
import cv2img_fn = "images/carla_scene.png"img = cv2.imread(img_fn)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img);

现在我们导入该类LaneDetector并创建它的一个实例。为此,我们指定使用 pytorch 函数存储的模型的路径save。
from solutions.lane_detection.lane_detector import LaneDetectormodel_path ="../../code/solutions/lane_detection/fastai_model.pth"ld = LaneDetector(model_path=model_path)
从现在开始,我们可以通过将任何图像(与训练集没有太大差别)传递给实例来获取车道边界多项式ld。
poly_left, poly_right = ld(img)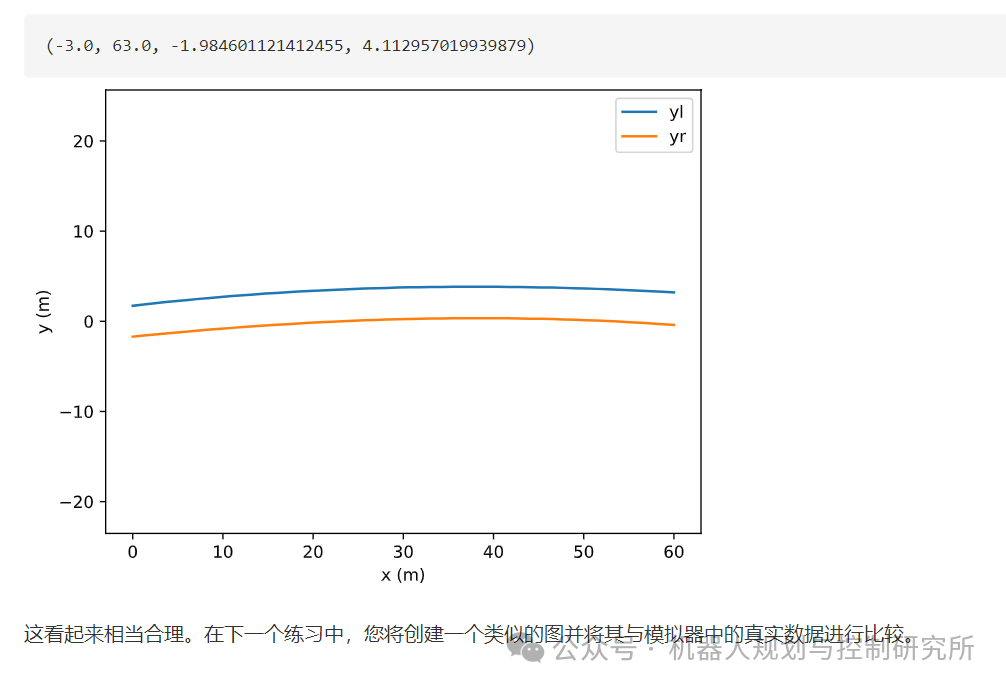
Reference
https://thomasfermi.github.io/Algorithms-for-Automated-Driving/LaneDetection/InversePerspectiveMapping.html
相关文章:
自动驾驶算法———车道检测(一)
“ 在本章中,我将指导您构建一个简单但有效的车道检测管道,并将其应用于Carla 模拟器中捕获的图像。管道将图像作为输入,并产生车道边界的数学模型作为输出。图像由行车记录仪(固定在车辆挡风玻璃后面的摄像头)捕获。…...

小程序自学教程
从0开始搭建微信小程序前后台 0、准备 如何安装?去CSDN搜索“xxx安装教程”即可。 (1)工具 IntelliJ IDEA(必选)——Java开发集成环境,可以前后端同时使用 Web Storm——web开发集成环境,主要…...

How do I format markdown chatgpt response in tkinter frame python?
题意:怎样在Tkinter框架中使用Python来格式化Markdown格式的ChatGPT响应? 问题背景: Chatgpt sometimes responds in markdown language. Sometimes the respond contains ** ** which means the text in between should be bold and ### te…...

vs2019 QT无法打开源文件QModbusTcpClient
vs2019无法打开源文件QModbusTcpClient 如果配置的msvc2019,则查找到Include目录 然后包含: #include <QtSerialBus/qmodbustcpclient.h>...

初识c++(命名空间,缺省参数,函数重载)
一、命名空间 1、namespace的意义 在C/C中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全 局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名 冲突…...

印尼Facebook直播网络需要达到什么要求?
在全球化浪潮的推动下,海外直播正受到企业、个人和机构的广泛关注和青睐。无论是用于营销、推广还是互动,海外直播为各种组织提供了更多机会和可能性。本文将探讨在进行印尼Facebook直播前,需要满足哪些网络条件以确保直播的质量和用户体验。…...
)
力扣题解(最长回文子串)
5. 最长回文子串 给你一个字符串 s,找到 s 中最长的 回文子串 。思路: 对于第i个字符,可能的回文子串构成方式有两种,一种是以i位置元素为中心元素,向着两边扩展,一种是以i位置和i1位置元素为中心…...

数据湖表格式 Hudi/Iceberg/DeltaLake/Paimon TPCDS 性能对比(Spark 引擎)
当前,业界流行的集中数据湖表格式 Hudi/Iceberg/DeltaLake,和最近出现并且在国内比较火的 Paimon。我们现在看到的很多是针对流处理场景的读写性能测试,那么本篇文章我们将回归到大数据最基础的场景,对海量数据的批处理查询。本文…...

脚本练习-每5分钟执行一次获取当前服务器的基本情况
设计一个shell程序,每5分钟执行一次获取当前服务器的基本情况(内存使用率,CPU负载,I/O,磁盘使用率),保存到120.20.20.20数据库上数据库帐号aaa密码bbb库名test表名host 创建一个名为server_stat…...

技术探索之kotlin浅谈
Kotlin是一种静态类型编程语言,它运行在Java虚拟机(JVM)上,可以与Java代码互操作。Kotlin由JetBrains开发,是一种现代、简洁且安全的编程语言。它在2011年首次亮相,2017年被谷歌宣布为Android官方开发语言。…...

机器学习之常用优化器
机器学习之常用优化器 1、SGD 优化器1.2、 SGD 的优缺点 2、 Adam 优化器2.1、设置 Adam 优化器2.2、使用 Adam 优化器的训练流程2.3、Adam 优化器的优缺点 3. AdamW 优化器3.1、示例3.2、训练过程3.3、AdamW 优化器的优点 1、SGD 优化器 在 PyTorch 中,设置 SGD 优…...

机器学习基本概念,Numpy,matplotlib和张量Tensor知识进一步学习
机器学习一些基本概念: 监督学习 监督学习是机器学习中最常见的形式之一,它涉及到使用带标签的数据集来训练模型。这意味着每条训练数据都包含输入特征和对应的输出标签。目标是让模型学会从输入到输出的映射,这样当给出新的未见过的输入时…...
博客前端项目学习day01
这里写自定义目录标题 登录创建项目配置环境变量,方便使用登录页面验证码登陆表单 在VScode上写前端,采用vue3。 登录 创建项目 检查node版本 node -v 创建一个新的项目 npm init vitelatest blog-front-admin 中间会弹出询问是否要安装包,…...

java Collections.synchronizedCollection方法介绍
Collections.synchronizedCollection 是 Java 中的一个实用方法,用于创建一个线程安全的集合。它通过包装现有的集合对象来实现线程安全,以确保在多线程环境中对集合的访问是安全的。 主要功能 线程安全:通过同步包装现有的集合,使得在多线程环境中对集合的所有访问(包括…...

力扣每日一题:3011. 判断一个数组是否可以变为有序
力扣官网:前往作答!!!! 今日份每日一题: 题目要求: 给你一个下标从 0 开始且全是 正 整数的数组 nums 。 一次 操作 中,如果两个 相邻 元素在二进制下数位为 1 的数目 相同 &…...

ubuntu 上vscode +cmake的debug调试配置方法
在ubuntu配置pcl点云库以及opencv库的时候,需要在CMakeLists.txt中加入相应的代码。配置完成后,无法调试,与在windows上体验vs studio差别有点大。 找了好多调试debug配置方法,最终能用的有几种,但是有一种特别好用&a…...

使用Redis实现签到功能:Java示例解析
使用Redis实现签到功能:Java示例解析 在本博客中,我们将讨论一个使用Redis实现的签到功能的Java示例。该示例包括两个主要方法:sign()和signCount(),分别用于用户签到和计算用户当月的签到次数。 1. 签到方法:sign()…...

tableau标靶图,甘特图与瀑布图绘制 - 9
标靶图,甘特图与瀑布图 1. 标靶图绘制1.1 筛选器筛选日期1.2 条形图绘制1.3 编辑参考线1.4 设置参考线1.5 设置参考区间1.6 四分位设置1.7 其他标靶图结果显示 2.甘特图绘制2.1 选择列属性2.2 选择列属性2.3 创建新字段2.4 设置天数大小及颜色 3. 瀑布图绘制3.1 she…...

双向链表专题
在之前的单链表专题中,了解的单链表的结构是如何实现的,以及学习了如何实现单链表得各个功能。单链表虽然也能实现数据的增、删、查、改等功能,但是要找到尾节点或者是要找到指定位置之前的节点时,还是需要遍历链表,这…...

SpringCoud组件
一、使用SpringCloudAlibaba <dependencyManagement><dependencies><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>2023.0.1.0</version><…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...