【MySQL】常见的MySQL日志都有什么用?
MySQL日志的内容非常重要,面试中经常会被问到。同时,掌握日志相关的知识也有利于我们理解MySQL 底层原理,必要时帮助我们排查解决问题。
MySQL中常见的日志类型主要有下面几类(针对的是InnoDB 存储引擎):
- 错误日志(error log):对 MySQL 的启动、运行、关闭过程进行了记录。
- 二进制日志(binarylog,binlog):主要记录的是更改数据库数据的 SQL语句。
- 一般查询日志(general querylog):已建立连接的客户端发送给 MySQL服务器的所有 SQL记录,因为 SQL的量比较大,默认是不开启的,也不建议开启。
- 慢查询日志(sow querylog):执行时间超过long_query_time 秒钟的査询,解决 SQL 慢查询问题的时候会用到。
- 事务日志(redo log 和 undo log):redo log 是重做日志,undo log 是回滚日志。
- 中继日志(relay log): relay log 是复制过程中产生的日志,很多方面都跟 binary log 差不多。不过relay log 针对的是主从复制中的从库。
- DDL日志(metadatalog):DDL语句执行的元数据操作
二进制日志(binlog)和事务日志(redo log 和 undo log)比较重要,需要我们重点关注.
1. 慢查询日志
慢查询日志记录了执行时间超过 long_query_time (默认是 10s,通常设置为1s)的所有查询语句,在解决 SQL 慢查询(SQL执行时间过长)问题的时候经常会用到。
找到慢 SQL是优化 SQL语句性能的第一步,然后再用 EXPLAIN 命令可以对慢 SQL进行分析,获取执行计划的相关信息。
可以通过 show variables like “slow_query_log";命令来查看慢查询日志是否开启,默认是关闭的。

可以通过 SET GLOBAL slow_query_log=ON 打开
long_query_time参数定义了一个查询消耗多长时间才可以被定义为慢查询,默认是 10s,通过SHOW VARIABLES LIKE'%long_query_time%';命令即可查看:

还可以对其进行修改:set global long_query_time = 12
在实际项目中,慢查询日志可能会比较大,直接分析的话不太方便,我们可以借助 MySQL官方的慢查询分析调优工具 mysqldumpslow。我的博客也简单接好了mysqldumpslow工具:
【MySQL】mysqldumpslow工具 -- 总结慢查询日志文件-CSDN博客
1.1 如何查询当前慢查询语句的个数?
在MySQL中有一个变量专门记录当前慢查询语句的个数,可以通过 show global status like'%slo
w_queries%';命令查看。

1.2 如何优化慢查询
MySQL为我们提供了EXPLAIN命令,来获取执行计划的相关信息。
执行计划 是指一条 SQL 语句在经过 MySQL 查询优化器 的优化会后,具体的执行方式。执行计划通常用于 SQL性能分析、优化等场景。通过 EXPLAIN 的结果,可以了解到如数据表的查询顺序、数据查询操作的操作类型、哪些索引可以被命中、哪些索引实际会命中、每个数据表有多少行记录被查询等信息。具体我们可以通过下面的一些常见手段优化SQL:
1. 避免使用 SELECT *
SELECT *会消耗更多的 CPU。
SELECT *无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、
blob、text)。
SELECT *无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)
SELECT<字段列表> 可减少表结构变更带来的影响。
2. 分页优化
普通的分页在数据量小的时候耗费时间还是比较短的。
如果数据量变大,达到百万甚至是千万级别,普通的分页耗费的时间就非常长了。
如何优化呢?可以将上述 SQL 语句修改为子查询。

我们先查询出 limit 第一个参数对应的主键值,再根据这个主键值再去过滤并 limit,这样效率会更快一些。不过,这种方法只适用于id 是正序的。
不过,子查询的结果会产生一张新表,会影响性能,应该尽量避免大量使用子查询。并且,这种方法只适用于 ID 是正序的。在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的 ID,此时的ID 是离散目不连续的。
3. 少做join
阿里巴巴开发手册:

可以看看知乎上的讨论:
https://www.zhihu.com/question/68258877![]() https://www.zhihu.com/question/682588774. 建议不使用外键与级联
https://www.zhihu.com/question/682588774. 建议不使用外键与级联
阿里巴巴Java开发手册:

5. 选择合适的字段类型
6. 尽量用 UNION ALL代替 UNION
UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作,更耗时,更消耗 CPU 资源
UNION ALL不会再对结果集进行去重操作,获取到的数据包含重复的项
不过,如果实际业务场景中不允许产生重复数据的话,还是可以使用 UNION。
7. 批量操作
对于数据库中的数据更新,如果能使用批量操作就要尽量使用,减少请求数据库的次数,提高性能。
8. 正确使用索引
这一块内容比较多,后面单独博客介绍
2. binlog 二进制日志
binlog(binary log 即二进制日志文件) 主要记录了对 MSQL数据库执行了更改的所有操作(数据库执行的所有 DDL和 DML语句),包括表结构变更(CREATE、ALTER、DROP TABLE.)、表数据修改(INSERT.UPDATE、DELETE..),但不包括 SELECT、SHOW 这类不会对数据库造成更改的操作。
可以使用 show binary logs;命令查看所有二进制日志列表:

2.1 binlog的格式
一共有 3种类型二进制记录方式:
- Statement 模式:每一条会修改数据的sql都会被记录在binlog中,如inserts,updates,deletes.·
- Row 模式(推荐):每一行的具体变更事件都会被记录在binlog中。·
- Mixed 模式:Statement 模式和 Row 模式的混合。默认使用 Statement 模式,少数特殊具体场景自动切换到 Row 模式。
相比较于 Row 模式来说,statement 模式下的日志文件更小,磁盘 IO 压力也较小,性能更好有些。不过,其准确性相比于 Row 模式要差。
MySQL 5.1.5 之前 binlog 的格式只有 STATEMENT,5.1.5 开始支持 ROW 格式的 binlog,从 5.1.8 版本开始,MySQL 开始支持 MIXED 格式的 binlog。MySQL 5.7.7 之前,默认使用 Statement 模式。MySQL5.7.7 开始默认使用 Row 模式。
可以使用 show variables like'%binlog format%'; 查看 binlog 使用的格式
2.2 binlog作用
binlog 最主要的应用场景是 主从复制 ,主备、主主、主从都离不开binlog,需要依靠 binlog 来同步数据,保证数据一致性。
主从复制的原理如下图所示:

1.主库将数据库中数据的变化写入到 binlog
2.从库连接主库
3.从库会创建一个 I0 线程向主库请求更新的 binlog
4.主库会创建一个 binlog dump 线程来发送 binlog ,从库中的 I/0 线程负责接收5.从库的 I/0 线程将接收的 binlog 写入到 relay log 中
6.从库的 SQL线程读取 relay log 同步数据本地(也就是再执行一遍 SQL)
2.3 binlog的刷盘时机如何选择?
对于InnoDB存储引擎而言,事务在执行过程中,会先把日志写入到 binlogcache 中,只有在事务提交的时候,才会把 binlogcache 中的日志持久化到磁盘上的 binlog 文件中。写入内存的速度更快,这样做也是为了效率考虑。
因为一个事务的 binlog 不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为 binlog cache。我们可以通过 binlog_cache_size 参数控制单个线程 binlogcache大小,如果存储内容超过了这个参数,就要暂存到磁盘(swap)。
那么 binlog 是什么时候刷到磁盘中的呢?可以通过 sync_binlog参数控制 biglog 的刷盘时机,取值范围是 0-N,默认为 0:
·0:不去强制要求,由系统自行判断何时写入磁盘
·1:每次提交事务的时候都要将binlog写入磁盘:
·N:每 N个事务,才会将binlog写入磁盘。有丢失的风险
MySQL5.7 之前,sync_binlog 默认值为0。在 MySQL5.7之后,sync_binlog 默认值为1.通常情况下,不建议将sync_binlog的值设置为0。如果对性能要求比较高或者出现磁盘 io 瓶颈的话,可以适当将 sync_binlog 的值调大,不过,这样会增加数据丢失的风险。
2.4 什么情况下会重新生成binlog?
当遇到以下3种情况时,MySQL会重新生成一个新的日志文件,文件序号递增
- MySQL服务器停止或重启
- 使用 flush logs 命令后
- binlog 文件大小超过 max binlog size 变量的阈值后。
3. redo log 重做日志
我们知道 InnoD8 存储引擎是以页为单位来管理存储空间的,我们往 MySQL 插入的数据最终都是存在于页中的,准确点来说是数据页这种类型。为了减少磁盘 IO 开销,还有一个叫做 Buffer Pool(缓冲池) 的区域,存在于内存中。当我们的数据对应的页不存在于 Buffer Pool中的话,MSQL会先将磁盘上的页缓存到 Buffer Pool中,这样后面我们直接操作的就是 Buffer Pool 中的页,这样大大提高了读写性能。
一个事务提交之后,我们对 Buffer Pool 中对应的页的修改可能还未持久化到磁盘。这个时候,如果 MySQL 突然宕机的话,这个事务的更改是不是直接就消失了呢?
很显然是不会的,如果是这样的话就明显违反了事务的持久性。
MySQLInnoDB 引擎使用 redo log 来保证事务的持久性。redo log 主要做的事情就是记录页的修改,比如某个页面某个偏移量处修改了几个字节的值以及具体被修改的内容是什么。redo log 中的每一条记录包含了表空间号、数据页号、偏移量、具体修改的数据,甚至还可能会记录修改数据的长度(取决于 redo log 类型)。
在事务提交时,我们会将 redo log 按照刷盘策略刷到磁盘上去,这样即使 MySQL 宕机了,重启之后也能恢复未能写入磁盘的数据,从而保证事务的持久性。也就是说,redo log 让 MySQL 具备了崩溃恢复能力。
1. 保障数据持久性(Durability)
Redo Log记录了所有对数据库进行的修改操作。当数据库执行写操作(INSERT、UPDATE、DELETE)时,这些操作会先被记录到Redo Log中,然后再应用到数据文件中。这样,即使在数据修改操作尚未完全写入磁盘之前系统发生故障,Redo Log也能保证数据不丢失。数据库在恢复时会从Redo Log中重做这些未完成的修改操作,确保数据的一致性。
2. 数据恢复(Recovery)
Redo Log在系统崩溃或意外断电后,帮助数据库恢复到一致状态。数据库在恢复过程中,会检查Redo Log中的记录,将所有已提交但未持久化的数据修改重新应用到数据文件中,从而恢复数据。
3. 提高写性能
为了提高写操作的性能,数据库通常会使用缓存机制(如缓冲池)将修改操作暂时存储在内存中,而不是立即写入磁盘。Redo Log的存在使得这种缓存机制成为可能,因为只要确保Redo Log已经被持久化,即使缓存中的数据尚未写入磁盘也不会有数据丢失的风险。
提交事务时log buffer 里的 redo log 会被刷新到磁盘,可以通过 innodb_flush_log_at
commit 参数控制。我们要注意设置正确的刷盘策略 innodb_flush_log_at_trx_commit,根据 MySQL 配置的刷盘策略的不同,MySQL宕机之后可能会存在轻微的数据丢失问题。
innodb_flush_log_at_trx_commit是MySQL InnoDB存储引擎中一个重要的配置参数,它决定了事务提交时日志的刷新(flush)和写入(write)策略,从而影响到数据持久性和性能。它有三种取值,分别是0、1和2,每一种取值代表一种不同的刷盘策略。
-
innodb_flush_log_at_trx_commit = 0- 描述:事务提交时,日志会写入日志缓冲区,但不会立即写入磁盘。日志文件每秒写入一次磁盘,并且每秒刷新一次日志缓冲区。
- 优点:性能较高,因为减少了磁盘I/O操作。
- 缺点:在系统崩溃时,可能会丢失最近1秒内的所有事务。
- 适用场景:适用于对性能要求高、对数据持久性要求不严格的应用场景。
-
innodb_flush_log_at_trx_commit = 1- 描述:每次事务提交时,日志都会立即写入磁盘,并且日志缓冲区也会立即刷新到磁盘。这是最安全的设置,能确保事务的持久性。
- 优点:最高的安全性,确保每个提交的事务都被持久化,即使系统崩溃也不会丢失已提交的事务。
- 缺点:性能较低,因为每次提交都会触发磁盘I/O操作。
- 适用场景:适用于对数据持久性要求很高的应用场景,例如金融系统、电子商务等。
-
innodb_flush_log_at_trx_commit = 2- 描述:每次事务提交时,日志会写入日志缓冲区,并立即刷新到磁盘,但不会立即写入日志文件。日志文件每秒写入一次磁盘。
- 优点:在一定程度上提高了性能,同时减少了可能丢失的数据量(最多丢失1秒内的事务)。
- 缺点:在系统崩溃时,可能会丢失最近1秒内的事务。
- 适用场景:适用于对性能和数据持久性有一定平衡要求的应用场景
刷盘策略总结
- 0:性能最好,但风险最大,可能丢失最近1秒的所有事务。
- 1:最安全,确保每个提交的事务都被持久化,性能相对较低。
- 2:性能和安全性之间的折中。
4. 出现数据丢失的情况
1.redo log 写入log buffer 但还未写入 page cache ,此时数据库崩溃,就会出现数据丢失(刷盘策略 innodb_flush log_at trx_commit 的值为0时可能会出现这种数据丢失);
2.redo log 已经写入 page cache 但还未写入磁盘,操作系统奔溃,也可能出现数据丟失(刷盘策略 innodb2 flush log_at trx_commit的值为2时可能会出现这种数据丢失)。

5. binlog 和 redolog 有什么区别?
- binlog 主要用于数据库还原,属于数据级别的数据恢复,主从复制是 binlog 最常见的一个应用场景,redolog 主要用于保证事务的持久性,属于事务级别的数据恢复。
- redolog 属于 InnoDB 引擎特有的,binlog 属于所有存储引擎共有的,因为 binlog 是 MySQL的 Server 层实现的。
- redolog 属于物理日志,主要记录的是某个页的修改。binlog 属于逻辑日志,主要记录的是数据库执行的所有 DDL和 DML 语句。
- binlog 通过追加的方式进行写入,大小没有限制。redolog 采用循环写的方式进行写入,大小固定,当写到结尾时,会回到开头循环写日志。
4. undo log 撤销日志
Undo Log(回滚日志)是数据库系统中用于记录数据修改操作的日志,它记录了在事务执行过程中对数据进行的所有修改操作的反向操作(即撤销操作)。Undo Log在事务回滚时起关键作用,通过Undo Log可以将数据恢复到事务开始之前的状态,从而确保事务的原子性(Atomicity)。
Undo Log如何保证事务的原子性
事务的原子性指的是事务的所有操作要么全部执行,要么全部不执行。Undo Log通过以下机制保证了事务的原子性:
-
记录撤销操作 在事务执行过程中,任何对数据的修改操作都会在实际修改之前,将相应的撤销操作记录到Undo Log中。例如,如果事务要更新一行记录的值,那么在更新之前,会将旧值记录到Undo Log中。
-
回滚事务 如果事务由于某种原因失败(如出现错误或显式回滚),数据库系统会读取Undo Log,并按照记录的撤销操作将数据恢复到事务开始前的状态。这样,可以确保失败的事务对数据库没有任何影响,从而保证事务的原子性。
引用:
读写分离和分库分表详解 | JavaGuide
相关文章:
【MySQL】常见的MySQL日志都有什么用?
MySQL日志的内容非常重要,面试中经常会被问到。同时,掌握日志相关的知识也有利于我们理解MySQL 底层原理,必要时帮助我们排查解决问题。 MySQL中常见的日志类型主要有下面几类(针对的是InnoDB 存储引擎): 错误日志(error log):对 MySQL 的启…...

IDEA社区版使用Maven archetype 创建Spring boot 项目
1.新建new project 2.选择Maven Archetype 3.命名name 4.选择存储地址 5.选择jdk版本 6.Archetype使用webapp 7.create创建项目 创建好长这样。 检查一下自己的Maven是否是自己的。 没问题的话就开始增添java包。 [有的人连resources包也没有,那就需要自己添…...
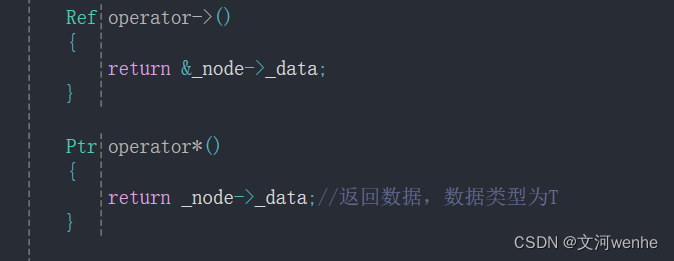
C/C++ list模拟
模拟准备 避免和库冲突,自己定义一个命名空间 namespace yx {template<class T>struct ListNode{ListNode<T>* _next;ListNode<T>* _prev;T _data;};template<class T>class list{typedef ListNode<T> Node;public:private:Node* _…...

android studio开发
Kotlin 编程简介 | Android Basics Compose - First Android app | Android Developers (google.cn) 这是官网的教程,实现试一下。 之后进入课程 您的第一个 Kotlin 程序 (google.cn) 程序可以被视为一系列指示计算机或设备执行某项操作的指令,...

PostgreSQl 物化视图
物化视图(Materialized View)是 PostgreSQL 提供的一个扩展功能,它是介于视图和表之间的一种对象。 物化视图和视图的最大区别是它不仅存储定义中的查询语句,而且可以像表一样存储数据。物化视图和表的最大区别是它不支持 INSERT…...

Win10工具:批量word转png图片
首先声明这个小工具是小编本人开发的,无任何广告,会员收费机制等,永久使用。允许公司或个人使用,不允许倒卖,否则发现后会追究法律责任,毕竟开发不易。工具是用python开发的。 功能非常单一,就…...

期货量化交易客户端开源教学第八节——TCP通信服务类
private FReciveStr: AnsiString; {接收到的数据} IsConErr: Boolean; {网络连接是否失败} FSocket_LB: Integer; {TCP连接类别,0为交易,1为行情,2为查询} FRetryCount: Integer; {网络连接重试次数} FLoginErrEvent: TLoginErrEvent; {…...

bi项目笔记
1.bi是什么 bi项目就是商业智能系统,也就是数据可视画、报表可视化系统,如下图的就是bi项目了 2.技术栈...
GPT开发相关插件)
金蝶云苍穹-插件开发(四)GPT开发相关插件
我只对GPT开发的相关插件进行讲解,因为我的是插件开发教程,关于GPT的一些提示词的写法,GPT任务的配置,请去金蝶云苍穹的文档和社区内学习。 GPT自定义操作 GPT自定义操作的代码的类要实现 IGPTAction 这个接口,这个接…...

【机器学习】精准农业新纪元:机器学习引领的作物管理革命
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀目录 🔍1. 引言📒2. 精准农业的背景与现状🍁精准农业的概念与发展历程🍂国内外精准农业实践案…...
一键掌握天气动态 - 基于Vue和高德API的实时天气查询
前言 本文将学习如何使用Vue.js快速搭建天气预报界面,了解如何调用高德地图API获取所需的天气数据,并掌握如何将两者有机结合,实现一个功能丰富、体验出色的天气预报应用 无论您是前端新手还是有一定经验,相信这篇教程都能为您带来收获。让我们一起开始这段精彩的Vue.js 高德…...

PostgreSQL修改最大连接数
在使用PostgreSQL 的时候,经常会遇到这样的错误提示, sorry, too many clients already,这是因为默认PostgreSQL最大连接数是 100, 一般情况下,个人使用时足够的,但是在生产环境,这个连接数是远远不够的&am…...

C# SqlSugar 如何使用Sql语句进行查询,并带参数进行查询,防注入
一般ORM查询单表数据已经是很简单的一种方式了 详情可以看我的另一篇文章:ORM C# 封装SqlSugar 操作数据库_sqlsugar 基类封装-CSDN博客 下面是介绍有些数据是需要比较复杂的SQL语句来进行查询的时候,则需要自行组装SQL语句来进行查询,下面…...

slf4j日志框架和logback详解
slf4j作用及其实现原理 SLF4J(Simple Logging Facade for Java)是一种日志框架的抽象层,它并不是一个具体的日志实现,而是一个接口或门面(Facade),旨在为各种不同的日志框架提供一个统一的API。…...

解决@Data与@Builder冲突的N种策略
前言 在Java项目中,Lombok的Data和Builder注解因其便捷性深受开发者喜爱,但两者并用时可能引发构造方法冲突。本文将全面解析这一问题的根源,并介绍包括利用实验性思路探讨的Tolerate概念在内的多种解决方案,确保您在实践中游刃有…...

一文看懂LUT(Lookup Table)查找表
文章目录 原理方法具体步骤和代码实现 查找表(Lookup Table,LUT)方法是一种通过预先计算并存储函数值来加速计算的方法。对于激活函数(例如ReLU),使用LUT可以在一定范围内通过查找预计算的值来近似函数计算…...

06 人以群分 基于邻域的协同过滤算法
这一讲我们将正式进入算法内容的学习。 推荐算法本质 推荐算法本质上是一一种信息处理方法,它将用户信息和物品信息处理后,最终输出了推荐结果。因为 05 讲中基于热门推荐、基于内容推荐、基于关联规则推荐等方法比较粗放,所以推荐结果往往…...

SQL性能下降的原因
一、SQL性能下降的原因 主要是性能下降SQL慢、执行时间长、等待时间长 不是一条SQL抓出来就要优化,在真实的生产环境下这种故障第一个要去复线,有可能去排查的时候没,所以没法复线。 可能需要它跑半天或者一天来缩小筛查的范围,…...

js的原型
原型: 1定义:原型是function对象的一个属性,它定义了构造函数制造出的对象的公共祖先。 通过该构造函数产生的对象,以继承该原型的属性和方法。原型也是对象。 2.利用原型特点和概念,可以提取共有属性。 3.对象如…...

FastAPI 学习之路(三十七)元数据和文档 URL
实现前的效果 那么如何实现呢,第一种方式如下: from routers.items import item_router from routers.users import user_router""" 自定义FastApi应用中的元数据配置Title:在 OpenAPI 和自动 API 文档用户界面中作为 API 的…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...