Java基础(十九):集合框架
目录
- 一、Java集合框架体系
- 二、Collection接口及方法
- 1、添加
- 2、判断
- 3、删除
- 4、其它
- 三、Iterator(迭代器)接口
- 1、Iterator接口
- 2、迭代器的执行原理
- 3、foreach循环
- 四、Collection子接口1:List
- 1、List接口特点
- 2、List接口方法
- 3、List接口主要实现类:ArrayList
- 4、List的实现类之二:LinkedList
- 5、List的实现类之三:Vector
- 五、Collection子接口2:Set
- 1、Set接口概述
- 2、Set主要实现类:HashSet
- 2.1、HashSet概述
- 2.2、HashSet中添加元素的过程
- 2.3、重写 hashCode() 方法的基本原则
- 2.4、重写equals()方法的基本原则
- 3、Set实现类之二:LinkedHashSet
- 4、Set实现类之三:TreeSet
- 六、Map接口
- 1、Map接口概述
- 2、Map中key-value特点
- 3、Map接口的常用方法
- 4、Map的主要实现类:HashMap
- 5、Map实现类之二:LinkedHashMap
- 6、Map实现类之三:TreeMap
- 7、Map实现类之四:Hashtable
- 8、Map实现类之五:Properties
- 七、Collections工具类
- 1、常用方法
- 2、举例
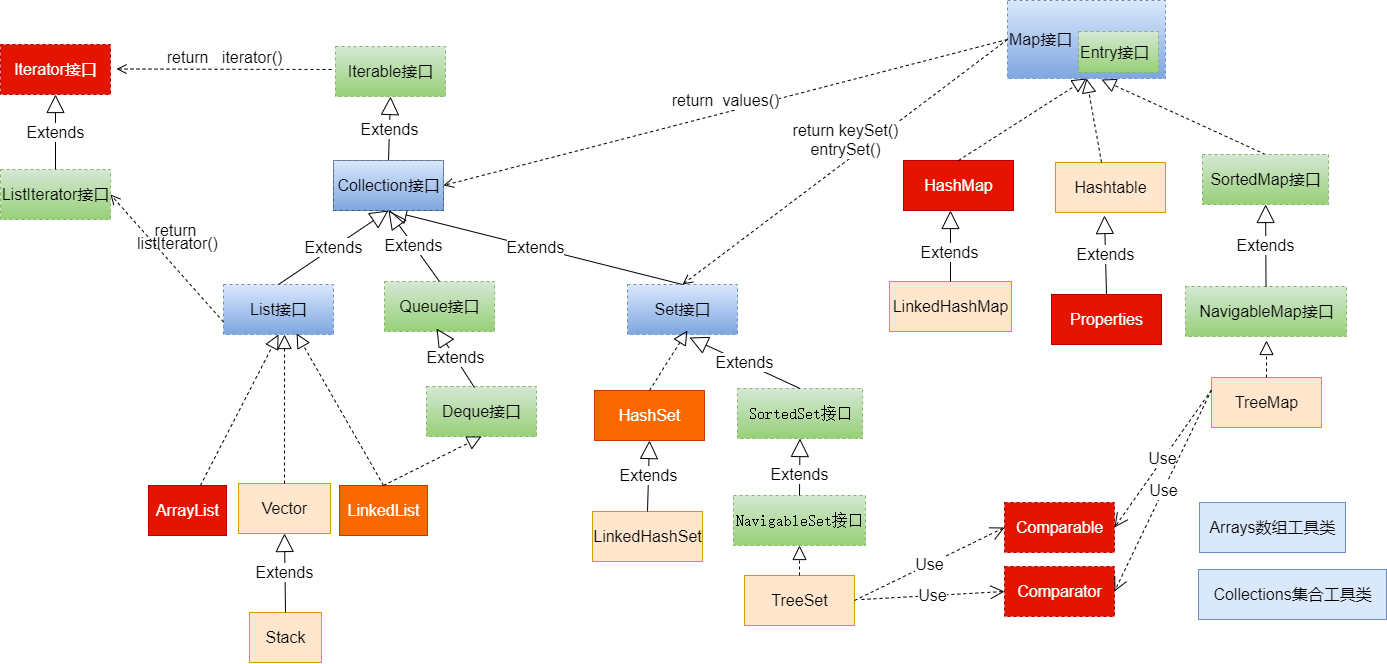
一、Java集合框架体系
Java 集合可分为 Collection 和 Map 两大体系
- Collection接口:用于存储一个一个的数据,也称
单列数据集合- List子接口:用来存储有序的、可以重复的数据(主要用来替换数组,"动态"数组)
- 实现类:ArrayList(主要实现类)、LinkedList、Vector
- Set子接口:用来存储无序的、不可重复的数据(类似于高中讲的"集合")
- 实现类:HashSet(主要实现类)、LinkedHashSet、TreeSet
- List子接口:用来存储有序的、可以重复的数据(主要用来替换数组,"动态"数组)
- Map接口:用于存储具有映射关系“key-value对”的集合,即一对一对的数据,也称
双列数据集合- HashMap(主要实现类)、LinkedHashMap、TreeMap、Hashtable、Properties
集合框架全图
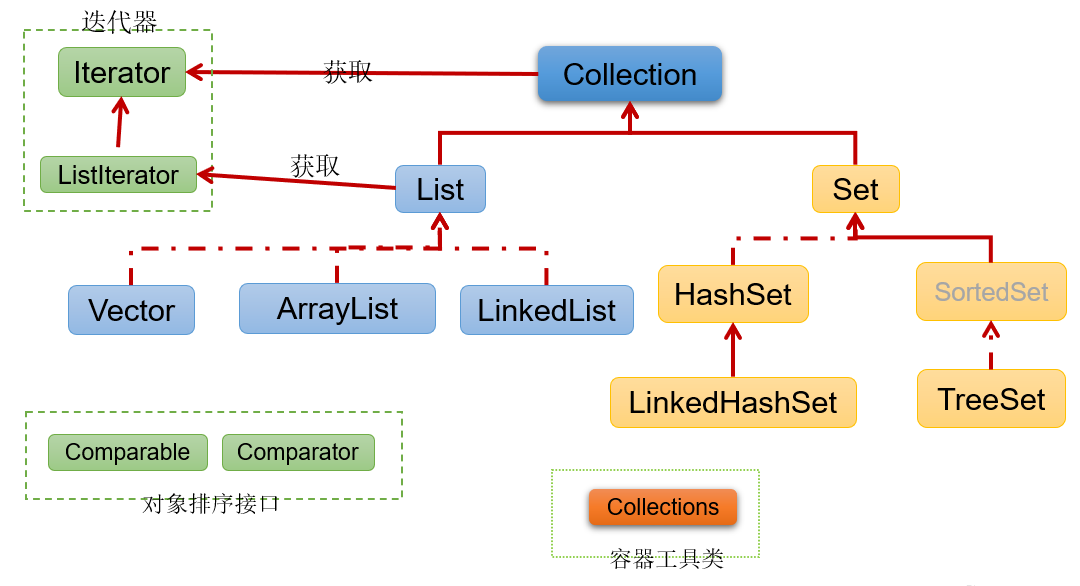
Collection接口继承树
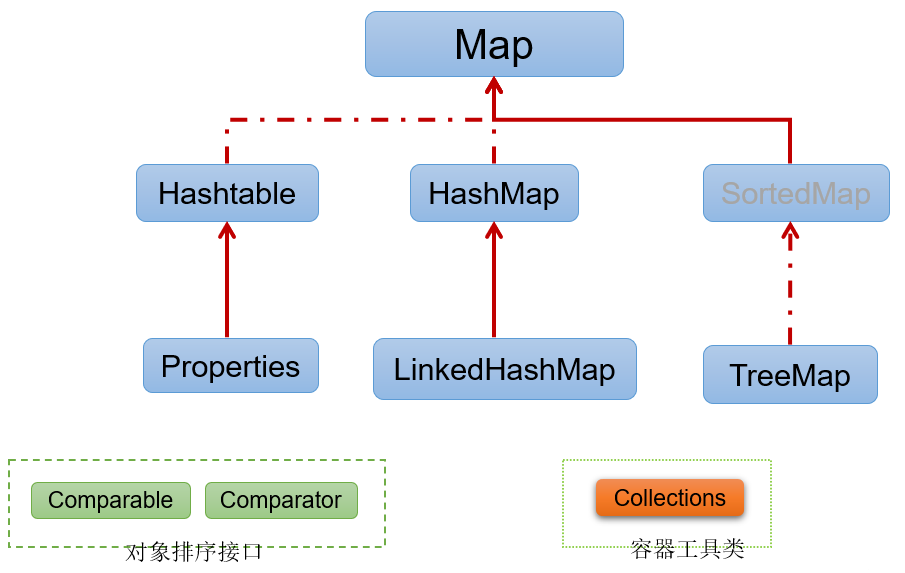
Map接口继承树
二、Collection接口及方法
- JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List)去实现
Collection 接口是 List和Set接口的父接口,该接口里定义的方法既可用于操作 Set 集合,也可用于操作 List 集合
1、添加
add(E obj):添加元素对象到当前集合中addAll(Collection other):添加other集合中的所有元素对象到当前集合中
@Test
public void test1(){Collection coll = new ArrayList();//add()coll.add("AA");coll.add(123);//自动装箱coll.add("么么哒");System.out.println(coll); // [AA, 123, 么么哒]//addAll(Collection other)Collection coll1 = new ArrayList();coll1.add("BB");coll1.add(456);coll.addAll(coll1);System.out.println(coll); // [AA, 123, 么么哒, BB, 456]coll.add(coll1);System.out.println(coll); // [AA, 123, 么么哒, BB, 456, [BB, 456]]
}
2、判断
int size():获取当前集合中实际存储的元素个数boolean isEmpty():判断当前集合是否为空集合boolean contains(Object obj):判断当前集合中是否存在一个与obj对象equals返回true的元素boolean containsAll(Collection coll):判断coll集合中的元素是否在当前集合中都存在。即coll集合是否是当前集合的“子集”boolean equals(Object obj):判断当前集合与obj是否相等
3、删除
void clear():清空集合元素boolean remove(Object obj):从当前集合中删除第一个找到的与obj对象equals返回true的元素boolean removeAll(Collection coll):从当前集合中删除所有与coll集合中相同的元素
4、其它
Object[] toArray():返回包含当前集合中所有元素的数组hashCode():获取集合对象的哈希值iterator():返回迭代器对象,用于集合遍历
@Test
public void test2(){Collection coll = new ArrayList();coll.add("AA");coll.add("AA");Person p1 = new Person("Tom",12);coll.add(p1);coll.add(128);//自动装箱//集合 ---> 数组Object[] arr = coll.toArray();System.out.println(Arrays.toString(arr)); // [AA, AA, Person{name='Tom', age=12}, 128]//hashCode():System.out.println(coll.hashCode()); // -912175978
}
三、Iterator(迭代器)接口
1、Iterator接口
- JDK专门提供了一个接口
java.util.Iterator遍历集合中的所有元素- Collection接口与Map接口主要用于
存储元素 Iterator,被称为迭代器接口,本身并不提供存储对象的能力,主要用于遍历Collection中的元素
- Collection接口与Map接口主要用于
- Collection接口继承了java.lang.Iterable接口
- 该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的- 集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前
- Iterator接口的常用方法如下
public E next():返回迭代的下一个元素public boolean hasNext():如果仍有元素可以迭代,则返回 true
- 注意:在调用it.next()方法之前必须要调用it.hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next()会抛出NoSuchElementException异常
@Test
public void test3(){Collection coll = new ArrayList();coll.add("小李广");coll.add("扫地僧");coll.add("石破天");Iterator iterator = coll.iterator(); //获取迭代器对象while(iterator.hasNext()) { //判断是否还有元素可迭代System.out.println(iterator.next()); //取出下一个元素}
}
- 使用Iterator迭代器删除元素:java.util.Iterator迭代器中有一个方法:
void remove()
@Test
public void test4(){Collection coll = new ArrayList();coll.add(1);coll.add(2);coll.add(3);coll.add(4);coll.add(5);coll.add(6);Iterator iterator = coll.iterator();while(iterator.hasNext()){Integer element = (Integer) iterator.next();if(element % 2 == 0){iterator.remove();}}System.out.println(coll); // [1, 3, 5]
}
2、迭代器的执行原理
- Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素
- 接下来通过一个图例来演示Iterator对象迭代元素的过程

3、foreach循环
- foreach循环(也称增强for循环)是 JDK5.0 中定义的一个高级for循环,专门用来
遍历数组和集合的 - foreach循环的语法格式:
for(元素的数据类型 局部变量 : Collection集合或数组){ //操作局部变量的输出操作
}
//这里局部变量就是一个临时变量,自己命名就可以
举例:
@Test
public void test5(){Collection coll = new ArrayList();coll.add("小李广");coll.add("扫地僧");coll.add("石破天");
//foreach循环其实就是使用Iterator迭代器来完成元素的遍历的。for (Object o : coll) {System.out.println(o);}
}
- 对于集合的遍历,增强for的内部原理其实是个Iterator迭代器
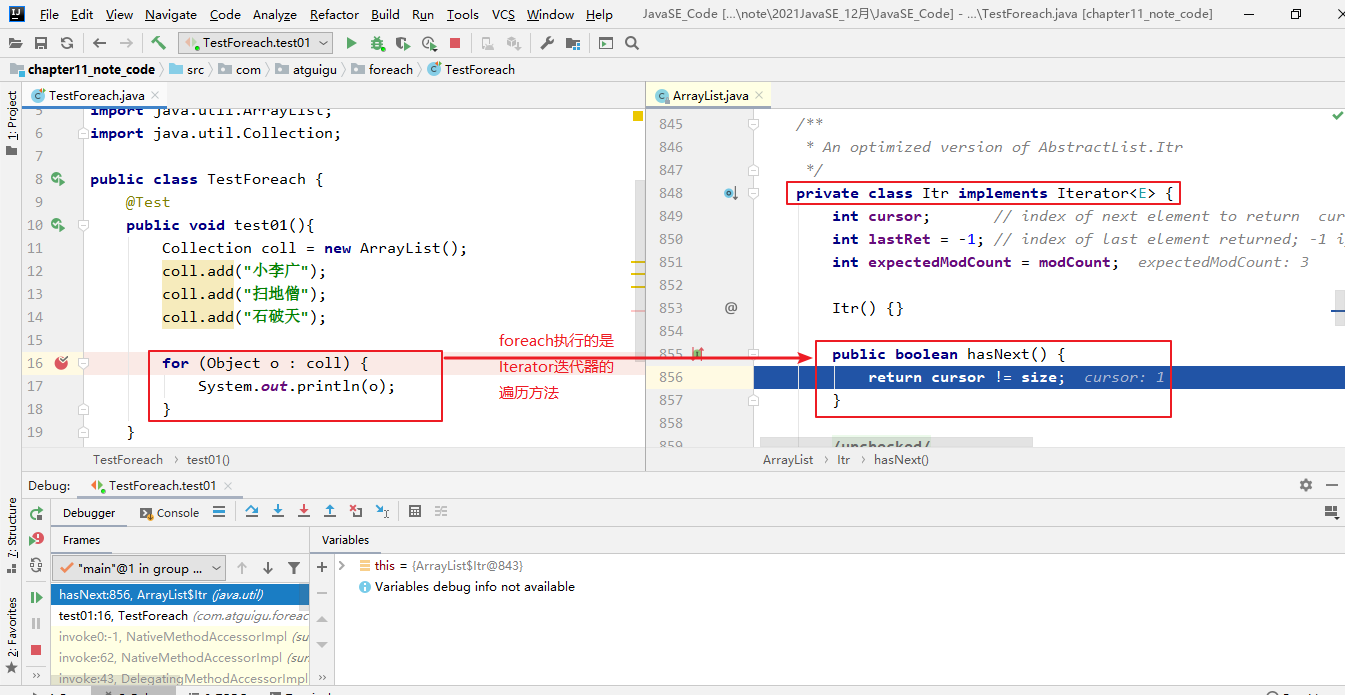
- 它用于遍历Collection和数组。通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作
public class InterviewTest {@Testpublic void testFor() {String[] arr1 = new String[]{"AA", "CC", "DD"};//赋值操作1
// for(int i = 0;i < arr1.length;i++){
// arr1[i] = "MM";
// }//赋值操作2for (String s : arr1) {s = "MM";}System.out.println(Arrays.toString(arr1));}
}
- 赋值操作1结果:[MM, MM, MM]
- 赋值操作2结果:[AA, CC, DD]
四、Collection子接口1:List
1、List接口特点
- 鉴于Java中数组用来存储数据的局限性,我们通常使用
java.util.List替代数组 - List集合类中
元素有序、且可重复,集合中的每个元素都有其对应的顺序索引 - JDK API中List接口的实现类常用的有:
ArrayList、LinkedList和Vector
2、List接口方法
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法
- 插入元素
void add(int index, Object ele):在index位置插入ele元素- boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
- 获取元素
Object get(int index):获取指定index位置的元素- List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
- 获取元素索引
- int indexOf(Object obj):返回obj在集合中首次出现的位置
- int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
- 删除和替换元素
Object remove(int index):移除指定index位置的元素,并返回此元素Object set(int index, Object ele):设置指定index位置的元素为ele
举例:
public class TestListMethod {public static void main(String[] args) {// 创建List集合对象List<String> list = new ArrayList<String>();// 往 尾部添加 指定元素list.add("图图");list.add("小美");list.add("不高兴");System.out.println(list); // [图图, 小美, 不高兴]// 往指定位置添加list.add(1,"没头脑");System.out.println(list); // [图图, 没头脑, 小美, 不高兴]// 删除指定位置元素 返回被删除元素System.out.println(list.remove(2));System.out.println(list); // [图图, 没头脑, 不高兴]// 在指定位置 进行 元素替代(改)// 修改指定位置元素list.set(0, "三毛");System.out.println(list); // [三毛, 没头脑, 不高兴]}
}
3、List接口主要实现类:ArrayList
- ArrayList 是 List 接口的
主要实现类 - 本质上,ArrayList是对象引用的一个”变长”数组
Arrays.asList(…) 方法创建集合
- Arrays.asList(…) 方法返回的 List 集合,既不是 ArrayList 实例,也不是 Vector 实例
- Arrays.asList(…) 返回值是一个固定长度的 List 集合
- 返回值对象Arrays.ArrayList,Arrays工具类的内部类ArrayList
- 继承AbstractList也就是实现List接口
- 但是Arrays.ArrayList没有重写add方法
- 所以返回的此集合不能新增
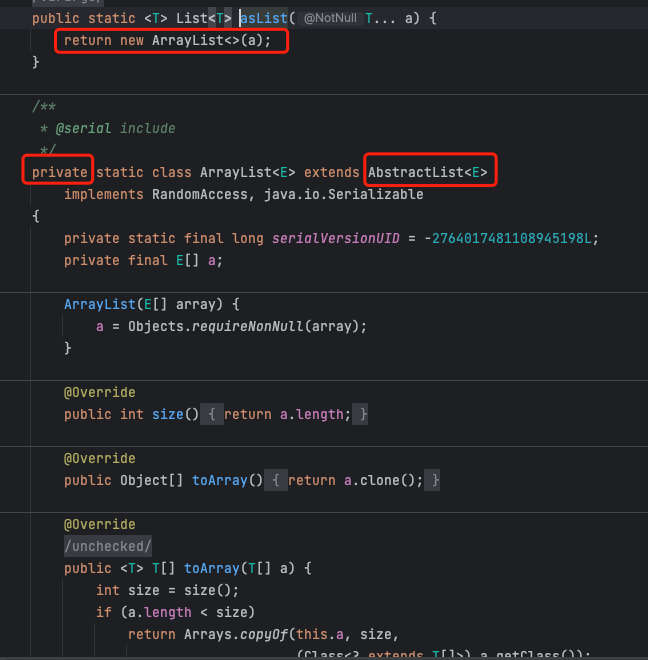
- 私有内部类,所以返回值用父类List表示,而不能用Arrays.ArrayList
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {protected AbstractList() {}public boolean add(E e) {add(size(), e);return true;}...public void add(int index, E element) {throw new UnsupportedOperationException();}
}
例子:
@Test
public void test6(){List<String> list = Arrays.asList("1", "2", "3");list.add("a");
}
输出结果:
Exception in thread "main" java.lang.UnsupportedOperationExceptionat java.util.AbstractList.add(AbstractList.java:148)at java.util.AbstractList.add(AbstractList.java:108)
4、List的实现类之二:LinkedList
- 对于频繁的
插入或删除元素的操作,建议使用LinkedList类,效率较高 - 这是由底层采用链表(
双向链表)结构存储数据决定的

- 特有方法
- void addFirst(Object obj)
- void addLast(Object obj)
- Object getFirst()
- Object getLast()
- Object removeFirst()
- Object removeLast()
5、List的实现类之三:Vector
- Vector 是一个
古老的集合,JDK1.0就有了 - 大多数操作与ArrayList相同,区别之处在于Vector是
线程安全的 - 在各种List中,最好把
ArrayList作为默认选择- 当插入、删除频繁时,使用LinkedList
- Vector总是比ArrayList慢,所以尽量避免使用
- 特有方法:
- void addElement(Object obj)
- void insertElementAt(Object obj,int index)
- void setElementAt(Object obj,int index)
- void removeElement(Object obj)
- void removeAllElements()
五、Collection子接口2:Set
1、Set接口概述
- Set接口是Collection的子接口,Set接口相较于Collection接口没有提供额外的方法
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败
- Set集合支持的遍历方式和Collection集合一样:foreach和Iterator
- Set的常用实现类有:HashSet、TreeSet、LinkedHashSet
2、Set主要实现类:HashSet
2.1、HashSet概述
- HashSet 是 Set 接口的主要实现类,大多数时候使用 Set 集合时都使用这个实现类
- HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存储、查找、删除性能
- HashSet 具有以下
特点:- 不能保证元素的排列顺序
- HashSet 不是线程安全的
- 集合元素可以是 null
- HashSet 集合
判断两个元素相等的标准:- 两个对象通过
hashCode()方法得到的哈希值相等 - 并且两个对象的
equals()方法返回值为true
- 两个对象通过
- 对于存放在Set容器中的对象,对应的类一定要
重写hashCode()和equals(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码” - HashSet集合中元素的无序性,不等同于随机性。这里的无序性与元素的添加位置有关
- 具体来说:我们在添加每一个元素到数组中时
- 具体的存储位置是由元素的hashCode()调用后返回的hash值决定的
- 导致在数组中每个元素不是依次紧密存放的,表现出一定的无序性
2.2、HashSet中添加元素的过程
- 第1步:当向 HashSet 集合中存入一个元素时
- HashSet 会调用该对象的 hashCode() 方法得到该对象的
hashCode值 - 然后根据 hashCode值
- 通过某个
散列函数决定该对象在 HashSet 底层数组中的存储位置
- HashSet 会调用该对象的 hashCode() 方法得到该对象的
- 第2步:如果要在数组中存储的位置上没有元素,则直接添加成功
- 第3步:如果要在数组中存储的位置上有元素,则继续比较
- 如果两个元素的hashCode值不相等,则添加成功
- 如果两个元素的
hashCode()值相等,则会继续调用equals()方法- 如果equals()方法结果为false,则添加成功
- 如果equals()方法结果为true,则添加失败
- 第3步两种添加成功的操作,由于该底层数组的位置已经有元素了,则会通过
链表的方式继续链接,存储
2.3、重写 hashCode() 方法的基本原则
- 在程序运行时,同一个对象多次调用 hashCode() 方法应该返回相同的值
- 当两个对象的 equals() 方法比较返回 true 时,这两个对象的 hashCode() 方法的返回值也应相等
- 对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值
注意:如果两个元素的 equals() 方法返回 true,但它们的 hashCode() 返回值不相等,hashSet 将会把它们存储在不同的位置,但依然可以添加成功
2.4、重写equals()方法的基本原则
- 重写equals方法的时候一般都需要同时复写hashCode方法
- 通常参与计算hashCode的对象的属性也应该参与到equals()中进行计算
- 为什么用Eclipse/IDEA复写hashCode方法,有31这个数字?
- 首先,选择系数的时候要选择尽量大的系数。因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。(减少冲突)
- 其次,31只占用5bits,相乘造成数据溢出的概率较小
- 再次,31可以 由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化。(提高算法效率)
- 最后,31是一个素数,素数作用就是如果我用一个数字来乘以这个素数,那么最终出来的结果只能被素数本身和被乘数还有1来整除!(减少冲突)
举例:
public class Person {String name;int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {System.out.println("Person equals()...");if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return age == person.age && Objects.equals(name, person.name);}@Overridepublic int hashCode() {System.out.println("Person hashCode()...");return Objects.hash(name, age);}
}
@Test
public void test1(){Set set = new HashSet();set.add("AA");set.add(123);set.add("BB");set.add(new Person("Tom",12));set.add(new Person("Tom",12));Iterator iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}
}
输出结果:
Person hashCode()...
Person hashCode()...
Person equals()...
AA
BB
123
Person{name='Tom', age=12}
3、Set实现类之二:LinkedHashSet
- LinkedHashSet 是 HashSet 的子类,不允许集合元素重复
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置
- 但它同时使用
双向链表维护元素的次序 - 这使得元素看起来是以
添加顺序保存的
- 但它同时使用
- LinkedHashSet
插入性能略低于 HashSet,但在迭代访问Set 里的全部元素时有很好的性能

举例:
@Test
public void test2(){LinkedHashSet set = new LinkedHashSet();set.add("张三");set.add("张三");set.add("李四");set.add("王五");set.add("王五");set.add("赵六");System.out.println("set = " + set);//不允许重复,体现添加顺序
}
输出结果:
set = [张三, 李四, 王五, 赵六]
4、Set实现类之三:TreeSet
- TreeSet 是 SortedSet 接口的实现类,TreeSet 可以按照添加的元素的
指定的属性的大小顺序进行遍历 - TreeSet底层使用
红黑树结构存储数据 - 新增的方法如下: (了解)
- Comparator comparator()
- Object first()
- Object last()
- Object lower(Object e)
- Object higher(Object e)
- SortedSet subSet(fromElement, toElement)
- SortedSet headSet(toElement)
- SortedSet tailSet(fromElement)
- TreeSet特点:不允许重复、实现排序(自然排序或定制排序)
- TreeSet 两种排序方法:
自然排序和定制排序。默认情况下,TreeSet 采用自然排序自然排序:TreeSet 会调用集合元素的 compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列- 如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口
- 实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小
定制排序:如果元素所属的类没有实现Comparable接口,或不希望按照升序(默认情况)的方式排列元素或希望按照其它属性大小进行排序,则考虑使用定制排序。定制排序,通过Comparator接口来实现。需要重写compare(T o1,T o2)方法- 利用int compare(T o1,T o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2
- 要实现定制排序,需要将实现Comparator接口的实例作为形参传递给TreeSet的构造器
- 因为只有相同类的两个实例才会比较大小,所以向 TreeSet 中添加的应该是
同一个类的对象 - 对于 TreeSet 集合而言,它判断
两个对象是否相等的唯一标准是:- 两个对象通过
compareTo(Object obj) 或compare(Object o1,Object o2)方法比较返回值 - 返回值为0,则认为两个对象相等
- 两个对象通过
举例1:String自然排序
/*
* 自然排序:针对String类的对象
* */
@Test
public void test1(){TreeSet set = new TreeSet();set.add("MM");set.add("CC");set.add("AA");set.add("DD");set.add("ZZ");//set.add(123); //报ClassCastException的异常System.out.println(set); // [AA, CC, DD, MM, ZZ]
}
举例2:自定义类自然排序
public class User implements Comparable{String name;int age;public User() {}public User(String name, int age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +'}';}/*举例:按照age从小到大的顺序排列,如果age相同,则按照name从大到小的顺序排列* */public int compareTo(Object o) {if(this == o){return 0;}if(o instanceof User){User user = (User)o;int value = this.age - user.age;if(value != 0){return value;}return -this.name.compareTo(user.name);}throw new RuntimeException("输入的类型不匹配");}
}
/*
* 自然排序:针对User类的对象
* */
@Test
public void test2(){TreeSet set = new TreeSet();set.add(new User("Tom",12));set.add(new User("Rose",23));set.add(new User("Jerry",2));set.add(new User("Eric",18));set.add(new User("Tommy",44));set.add(new User("Jim",23));set.add(new User("Maria",18));//set.add("Tom");Iterator iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}System.out.println(set.contains(new User("Jack", 23))); //true
}
举例3:定制排序
/** 定制排序* */
@Test
public void test3(){//按照User的姓名的从小到大的顺序排列Comparator comparator = new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof User && o2 instanceof User){User u1 = (User)o1;User u2 = (User)o2;return u1.name.compareTo(u2.name);}throw new RuntimeException("输入的类型不匹配");}};TreeSet set = new TreeSet(comparator);set.add(new User("Tom",12));set.add(new User("Rose",23));set.add(new User("Jerry",2));set.add(new User("Eric",18));set.add(new User("Tommy",44));set.add(new User("Jim",23));set.add(new User("Maria",18));Iterator iterator = set.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}
}
六、Map接口
1、Map接口概述
- Map与Collection并列存在。用于保存具有
映射关系的数据:key-valueCollection集合称为单列集合,元素是孤立存在的(理解为单身)Map集合称为双列集合,元素是成对存在的(理解为情侣)
- Map 中的 key 和 value 都可以是任何引用类型的数据。但常用String类作为Map的“键”
- Map接口的常用实现类:
HashMap、LinkedHashMap、TreeMap和Properties - HashMap是 Map 接口使用
频率最高的实现类
2、Map中key-value特点
- HashMap中存储的key、value的特点如下:
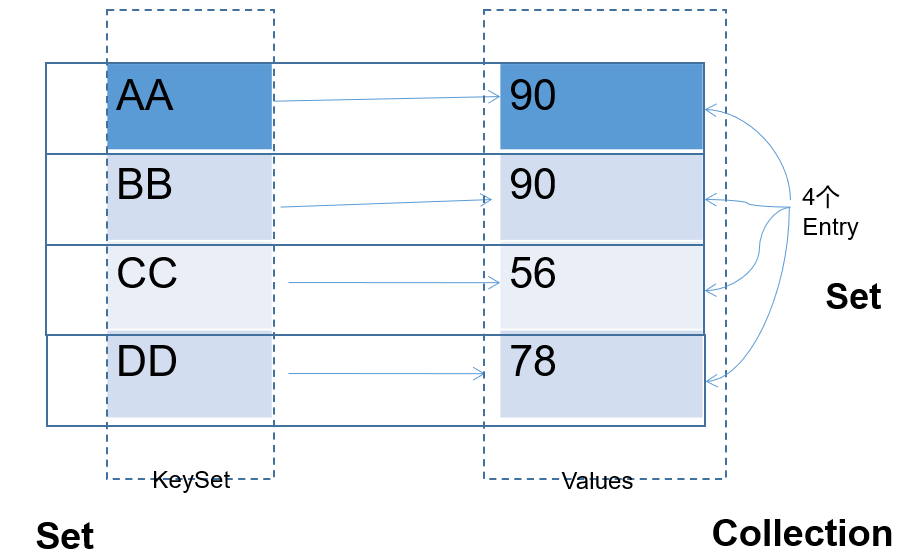
- Map 中的
key用Set来存放,不允许重复,即同一个 Map 对象所对应的类,须重写hashCode()和equals()方法
- key 和 value 之间存在单向一对一关系
- 即通过指定的 key 总能找到唯一的、确定的 value
- 不同key对应的
value可以重复 - value所在的类要重写equals()方法
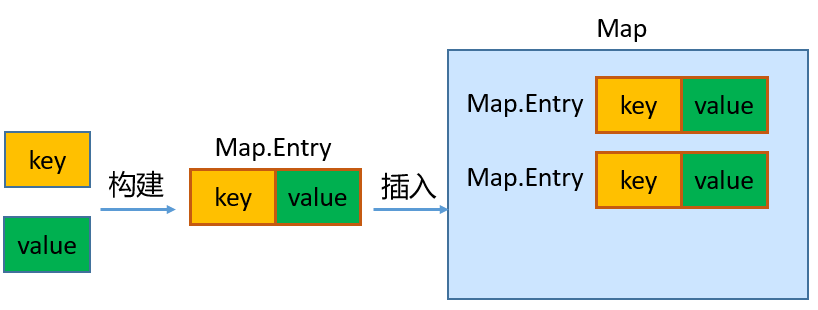
- key和value构成一个
entry。所有的entry彼此之间是无序的、不可重复的
3、Map接口的常用方法
- 添加、修改操作:
- Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
- void putAll(Map m):将m中的所有key-value对存放到当前map中
- 删除操作:
- Object remove(Object key):移除指定key的key-value对,并返回value
- void clear():清空当前map中的所有数据
- 元素查询的操作:
- Object get(Object key):获取指定key对应的value
- boolean containsKey(Object key):是否包含指定的key
- boolean containsValue(Object value):是否包含指定的value
- int size():返回map中key-value对的个数
- boolean isEmpty():判断当前map是否为空
- boolean equals(Object obj):判断当前map和参数对象obj是否相等
- 元视图操作的方法:
- Set keySet():返回所有key构成的Set集合
- Collection values():返回所有value构成的Collection集合
- Set entrySet():返回所有key-value对构成的Set集合
举例1:
@Test
public void test1(){//创建 map对象HashMap map = new HashMap();//添加元素到集合map.put("黄晓明", "杨颖");map.put("李晨", "李小璐");map.put("李晨", "范冰冰");map.put("邓超", "孙俪");System.out.println(map);//删除指定的key-valueSystem.out.println(map.remove("黄晓明"));System.out.println(map);//查询指定key对应的valueSystem.out.println(map.get("邓超"));System.out.println(map.get("黄晓明"));
}
举例2:
@Test
public void test2(){HashMap map = new HashMap();map.put("许仙", "白娘子");map.put("董永", "七仙女");map.put("牛郎", "织女");map.put("许仙", "小青");System.out.println("所有的key:");Set keySet = map.keySet();for (Object key : keySet) {System.out.println(key);}System.out.println("所有的value:");Collection values = map.values();for (Object value : values) {System.out.println(value);}System.out.println("所有的映射关系:");Set entrySet = map.entrySet();for (Object mapping : entrySet) {//System.out.println(entry);Map.Entry entry = (Map.Entry) mapping;System.out.println(entry.getKey() + "->" + entry.getValue());}
}
4、Map的主要实现类:HashMap
- HashMap是 Map 接口
使用频率最高的实现类 - HashMap是线程不安全的。允许添加 null 键和 null 值
- 存储数据采用的哈希表结构
- 底层使用
一维数组+单向链表+红黑树进行key-value数据的存储 - 与HashSet一样,元素的存取顺序不能保证一致
- 底层使用
- HashMap
判断两个key相等的标准是:两个 key 的hashCode值相等,通过 equals() 方法返回 true - HashMap
判断两个value相等的标准是:两个 value 通过 equals() 方法返回 true
举例:
@Test
public void test1(){Map map = new HashMap();map.put(null,null);map.put("Tom",23);map.put("CC",new Date());map.put(34,"AA");System.out.println(map); // {null=null, CC=Sat Apr 22 17:51:16 CST 2023, 34=AA, Tom=23}
}
5、Map实现类之二:LinkedHashMap
- LinkedHashMap 是 HashMap 的子类
- 存储数据采用的哈希表结构+链表结构
- 在HashMap存储结构的基础上,使用了一对
双向链表来记录添加元素的先后顺序 - 可以保证遍历元素时,与添加的顺序一致
- 在HashMap存储结构的基础上,使用了一对
- 通过哈希表结构可以保证键的唯一、不重复,需要键所在类重写hashCode()方法、equals()方法
举例:
@Test
public void test2(){LinkedHashMap map = new LinkedHashMap();map.put("Tom",23);map.put("CC","test");map.put(34,"AA");System.out.println(map); // {Tom=23, CC=test, 34=AA}
}
6、Map实现类之三:TreeMap
- TreeMap存储 key-value 对时,需要根据 key-value 对进行排序
- TreeMap 可以保证所有的 key-value 对处于
有序状态 - TreeSet底层使用
红黑树结构存储数据 - TreeMap 的 Key 的排序
自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口- 而且所有的 Key 应该是同一个类的对象
- 否则将会抛出 ClasssCastException
定制排序:创建 TreeMap 时,构造器传入一个 Comparator 对象- 该对象负责对 TreeMap 中的所有 key 进行排序
- 此时不需要 Map 的 Key 实现 Comparable 接口
- TreeMap判断
两个key相等的标准:两个key通过compareTo()方法或者compare()方法返回0
举例1:自然排序
@Test
public void test1(){TreeMap map = new TreeMap();map.put("CC",45);map.put("MM",78);map.put("DD",56);map.put("GG",89);System.out.println(map); // {CC=45, DD=56, GG=89, MM=78}
}
举例1:定制排序
@Test
public void test2(){//按照User的姓名的从小到大的顺序排列TreeMap map = new TreeMap(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof User && o2 instanceof User){User u1 = (User)o1;User u2 = (User)o2;return u1.name.compareTo(u2.name);}throw new RuntimeException("输入的类型不匹配");}});map.put(new User("Tom",12),67);map.put(new User("Rose",23),"87");map.put(new User("Jerry",2),88);map.put(new User("Eric",18),45);map.put(new User("Tommy",44),77);map.put(new User("Jim",23),88);map.put(new User("Maria",18),34);System.out.println(map);
}
7、Map实现类之四:Hashtable
- Hashtable是Map接口的
古老实现类,JDK1.0就提供了 - 不同于HashMap,Hashtable是
线程安全的 - Hashtable实现原理和HashMap相同,功能相同
- 底层都使用哈希表结构(
数组+单向链表),查询速度快 - 与HashMap一样,Hashtable 也不能保证其中 Key-Value 对的顺序
- Hashtable判断两个key相等、两个value相等的标准,与HashMap一致
- 与HashMap不同,Hashtable
不允许使用 null 作为 key 或 value
8、Map实现类之五:Properties
- Properties 类是 Hashtable 的子类,该对象用于处理属性文件
- 由于属性文件里的 key、value 都是字符串类型,所以Properties 中要求 key 和 value 都是
字符串类型 - 存取数据时,建议使用setProperty(String key,String value)方法和getProperty(String key)方法
举例1:
@Test
public void test3() throws IOException {Properties pros = new Properties();pros.load(new FileInputStream("jdbc.properties"));String user = pros.getProperty("user");System.out.println(user);
}
七、Collections工具类
参考操作数组的工具类:Arrays,Collections 是一个操作 Set、List 和 Map 等集合的工具类
1、常用方法
- Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作
- 还提供了对集合对象设置不可变、对集合对象实现同步控制等方法(均为static方法)
排序操作:
reverse(List):反转 List 中元素的顺序- shuffle(List):对 List 集合元素进行随机排序
sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序- sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
- swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
查找
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
- Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素
- Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素
- int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数
复制、替换
- void copy(List dest,List src):将src中的内容复制到dest中
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
- 提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图
添加
- boolean addAll(Collection c,T… elements)将所有指定元素添加到指定 collection 中
同步
- Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题
2、举例
@Test
public void test1(){List list = Arrays.asList(45, 43, 65, 6, 43, 2, 32, 45, 56, 34, 23);//reverse(List):反转 List 中元素的顺序
// Collections.reverse(list); // [23, 34, 56, 45, 32, 2, 43, 6, 65, 43, 45]//shuffle(List):对 List 集合元素进行随机排序,每次不一样
// Collections.shuffle(list); // [65, 32, 34, 23, 45, 45, 2, 43, 43, 56, 6]//sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
// Collections.sort(list); // [2, 6, 23, 32, 34, 43, 43, 45, 45, 56, 65]//sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序Collections.sort(list, new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof Integer && o2 instanceof Integer){Integer i1 = (Integer) o1;Integer i2 = (Integer) o2;// return i1 - i2;return -(i1.intValue() - i2.intValue());}throw new RuntimeException("类型不匹配");}}); // [65, 56, 45, 45, 43, 43, 34, 32, 23, 6, 2]System.out.println(list);
}
@Test
public void test2(){List list = Arrays.asList(45, 43, 65, 6, 43, 2, 32, 45, 56, 34, 23);System.out.println(list);Object max = Collections.max(list);Object max1 = Collections.max(list,new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof Integer && o2 instanceof Integer){Integer i1 = (Integer) o1;Integer i2 = (Integer) o2;// return i1 - i2;return -(i1.intValue() - i2.intValue());}throw new RuntimeException("类型不匹配");}});System.out.println(max); // 65System.out.println(max1); // 2int count = Collections.frequency(list, 45);System.out.println("45出现了" + count + "次"); // 45出现了2次
}
@Test
public void test3(){List src = Arrays.asList(45, 43, 65, 6, 43, 2, 32, 45, 56, 34, 23);//void copy(List dest,List src):将src中的内容复制到dest中//错误的写法:
// List dest = new ArrayList();//正确的写法:List dest = Arrays.asList(new Object[src.size()]);Collections.copy(dest,src);System.out.println(dest);
}
@Test
public void test4(){//提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。List list1 = new ArrayList();//list1可以写入数据list1.add(34);list1.add(12);list1.add(45);List list2 = Collections.unmodifiableList(list1);//此时的list2只能读,不能写list2.add("AA");//不能写System.out.println(list2.get(0));//34
}
@Test
public void test5(){//Collections 类中提供了多个 synchronizedXxx() 方法List list1 = new ArrayList();//返回的list2就是线程安全的List list2 = Collections.synchronizedList(list1);list2.add(123);HashMap map1 = new HashMap();//返回的map2就是线程安全的Map map2 = Collections.synchronizedMap(map1);
}
相关文章:
Java基础(十九):集合框架
目录 一、Java集合框架体系二、Collection接口及方法1、添加2、判断3、删除4、其它 三、Iterator(迭代器)接口1、Iterator接口2、迭代器的执行原理3、foreach循环 四、Collection子接口1:List1、List接口特点2、List接口方法3、List接口主要实现类:Array…...

execute_script与JS
JavaScript简称JS,有的测试场景需要JS脚本辅助完成Selenium无法做到的测试工作。webdriver提供了execute_script()方法调用JS代码。execute_script()可以在当前窗口/框架中执行JS脚本,并返回结果。可以使用它操作DOM元素、获取元素属性、执行异步操作等。…...

访问 Postman OAuth 2.0 授权的最佳实践
OAuth 2.0 代表了 web 安全协议的发展,便于在多个平台上进行授权服务,同时避免暴露用户凭据。它提供了一种安全的方式,让用户可以授权应用程序访问服务。 在 Postman 中开始使用 OAuth 2.0 Postman 是一个流行的API客户端,支持 …...

《BASeg: Boundary aware semantic segmentation for autonomous driving》论文解读
期刊:Neural Networks | Journal | ScienceDirect.com by Elsevier 年份:2023 代码:https://github.com/Lature-Yang/BASeg 摘要 语义分割是自动驾驶领域街道理解任务的重要组成部分。现有的各种方法要么专注于通过聚合全局或多尺度上下文…...

高效利用iCloud指南
高效利用iCloud的指南主要包括以下几个方面: 一、注册与登录 创建Apple ID: 如果尚未拥有Apple ID,可以在苹果官网或iOS设备的设置中创建。Apple ID是访问iCloud服务的前提。登录iCloud: 在苹果设备上,进入“设置”应…...

【MySQL】常见的MySQL日志都有什么用?
MySQL日志的内容非常重要,面试中经常会被问到。同时,掌握日志相关的知识也有利于我们理解MySQL 底层原理,必要时帮助我们排查解决问题。 MySQL中常见的日志类型主要有下面几类(针对的是InnoDB 存储引擎): 错误日志(error log):对 MySQL 的启…...

IDEA社区版使用Maven archetype 创建Spring boot 项目
1.新建new project 2.选择Maven Archetype 3.命名name 4.选择存储地址 5.选择jdk版本 6.Archetype使用webapp 7.create创建项目 创建好长这样。 检查一下自己的Maven是否是自己的。 没问题的话就开始增添java包。 [有的人连resources包也没有,那就需要自己添…...
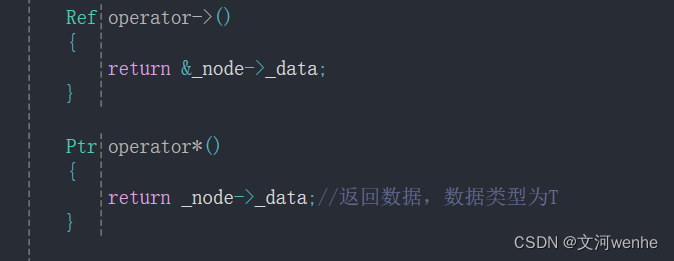
C/C++ list模拟
模拟准备 避免和库冲突,自己定义一个命名空间 namespace yx {template<class T>struct ListNode{ListNode<T>* _next;ListNode<T>* _prev;T _data;};template<class T>class list{typedef ListNode<T> Node;public:private:Node* _…...

android studio开发
Kotlin 编程简介 | Android Basics Compose - First Android app | Android Developers (google.cn) 这是官网的教程,实现试一下。 之后进入课程 您的第一个 Kotlin 程序 (google.cn) 程序可以被视为一系列指示计算机或设备执行某项操作的指令,...

PostgreSQl 物化视图
物化视图(Materialized View)是 PostgreSQL 提供的一个扩展功能,它是介于视图和表之间的一种对象。 物化视图和视图的最大区别是它不仅存储定义中的查询语句,而且可以像表一样存储数据。物化视图和表的最大区别是它不支持 INSERT…...

Win10工具:批量word转png图片
首先声明这个小工具是小编本人开发的,无任何广告,会员收费机制等,永久使用。允许公司或个人使用,不允许倒卖,否则发现后会追究法律责任,毕竟开发不易。工具是用python开发的。 功能非常单一,就…...

期货量化交易客户端开源教学第八节——TCP通信服务类
private FReciveStr: AnsiString; {接收到的数据} IsConErr: Boolean; {网络连接是否失败} FSocket_LB: Integer; {TCP连接类别,0为交易,1为行情,2为查询} FRetryCount: Integer; {网络连接重试次数} FLoginErrEvent: TLoginErrEvent; {…...

bi项目笔记
1.bi是什么 bi项目就是商业智能系统,也就是数据可视画、报表可视化系统,如下图的就是bi项目了 2.技术栈...
GPT开发相关插件)
金蝶云苍穹-插件开发(四)GPT开发相关插件
我只对GPT开发的相关插件进行讲解,因为我的是插件开发教程,关于GPT的一些提示词的写法,GPT任务的配置,请去金蝶云苍穹的文档和社区内学习。 GPT自定义操作 GPT自定义操作的代码的类要实现 IGPTAction 这个接口,这个接…...

【机器学习】精准农业新纪元:机器学习引领的作物管理革命
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀目录 🔍1. 引言📒2. 精准农业的背景与现状🍁精准农业的概念与发展历程🍂国内外精准农业实践案…...
一键掌握天气动态 - 基于Vue和高德API的实时天气查询
前言 本文将学习如何使用Vue.js快速搭建天气预报界面,了解如何调用高德地图API获取所需的天气数据,并掌握如何将两者有机结合,实现一个功能丰富、体验出色的天气预报应用 无论您是前端新手还是有一定经验,相信这篇教程都能为您带来收获。让我们一起开始这段精彩的Vue.js 高德…...

PostgreSQL修改最大连接数
在使用PostgreSQL 的时候,经常会遇到这样的错误提示, sorry, too many clients already,这是因为默认PostgreSQL最大连接数是 100, 一般情况下,个人使用时足够的,但是在生产环境,这个连接数是远远不够的&am…...

C# SqlSugar 如何使用Sql语句进行查询,并带参数进行查询,防注入
一般ORM查询单表数据已经是很简单的一种方式了 详情可以看我的另一篇文章:ORM C# 封装SqlSugar 操作数据库_sqlsugar 基类封装-CSDN博客 下面是介绍有些数据是需要比较复杂的SQL语句来进行查询的时候,则需要自行组装SQL语句来进行查询,下面…...

slf4j日志框架和logback详解
slf4j作用及其实现原理 SLF4J(Simple Logging Facade for Java)是一种日志框架的抽象层,它并不是一个具体的日志实现,而是一个接口或门面(Facade),旨在为各种不同的日志框架提供一个统一的API。…...

解决@Data与@Builder冲突的N种策略
前言 在Java项目中,Lombok的Data和Builder注解因其便捷性深受开发者喜爱,但两者并用时可能引发构造方法冲突。本文将全面解析这一问题的根源,并介绍包括利用实验性思路探讨的Tolerate概念在内的多种解决方案,确保您在实践中游刃有…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...