数据库基础语法
sql(Structured Query Language 结构化查询语言)
SQL语法
- use DataTableName; 命令用于选择数据库。
- set names utf8; 命令用于设置使用的字符集。
- SELECT * FROM Websites; 读取数据表的信息。
- 上面的表包含五条记录(每一条对应一个网站信息)和5个列(id、name、url、alexa 和country)。
重要的SQL命令
- SELECT - 从数据库中提取数据
- UPDATE - 更新数据库中的数据
- DELETE - 从数据库中删除数据
- INSERT INTO - 向数据库中插入新数据
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
- select xx,xx from table 从表中查找xx,xx
- select distinct xx ,xx from table 从表中查找xx,xx(不同的值,去掉重复值)
- select xx,xx from table where xxxxxs(某个条件) 限定条件
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。**注释:**在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
-
and or 运算符、
- 如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
- 如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
- where country=‘CN’ and alexa>50(两个条件成立)
- where country=‘CN’ or alexa>50 (一个符合就可以)
- WHERE alexa > 15 AND (country=‘CN’ OR country=‘USA’);(双条件)
-
SELECT xxxx, xxx, ... FROM table_name ORDER BY xxxx, xxx, ... ASC|DESC;- asc 升序排序
- desc 降序排序
- order by 根据xxx进行排序,用,分开可以用多个来排序
-
insert into 向表中插入新纪录
-
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);INSERT INTO Websites (name, url, alexa, country) VALUES ('百度','https://www.baidu.com/','4','CN'); 空会自动补0/null table_name:需要插入新记录的表名。 column1, column2, ...:需要插入的字段名。 value1, value2, ...:需要插入的字段值。
-
-
updata
-
UPDATE Websites SET alexa='5000', country='USA' WHERE name='菜鸟教程';//where很重要 把 "菜鸟教程" 的 alexa 排名更新为 5000,country 改为 USA。
-
-
delete
-
DELETE FROM table_name WHERE condition; 从某表删除 where条件下的值
-
-
top、limit、rownum(**注意:**并非所有的数据库系统都支持 SELECT TOP 语句。 MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。)
- select top num from table
- select * from table limit num
- select * from table where rownum<=num
-
like(指定模式)、
-
SELECT * FROM Websites
WHERE name LIKE ‘G%’;//%通配符,以G开头的 -
通配符 描述 % 替代 0 个或多个字符 _ 替代一个字符 [charlist] 字符列中的任何单一字符 [^charlist] 或 [!charlist] 不在字符列中的任何单一字符
-
-
in(where 子句中规定多个值)
- SELECT * FROM Websites
WHERE name IN (‘Google’,‘菜鸟教程’);
- SELECT * FROM Websites
-
between(取两个值之间的数)
- not between WHERE alexa NOT BETWEEN 1 AND 20;
- not in
- WHERE (alexa BETWEEN 1 AND 20)
AND country NOT IN (‘USA’, ‘IND’);
- WHERE (alexa BETWEEN 1 AND 20)
- 文本 WHERE name BETWEEN ‘A’ AND ‘H’;
SELECT column1, column2, ... FROM table_name WHERE column BETWEEN value1 AND value2;- column1, column2, …:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要查询的字段名称。
- value1:范围的起始值。
- value2:范围的结束值。
高级sql
别名
xx,xx AS xx
链接 (join)
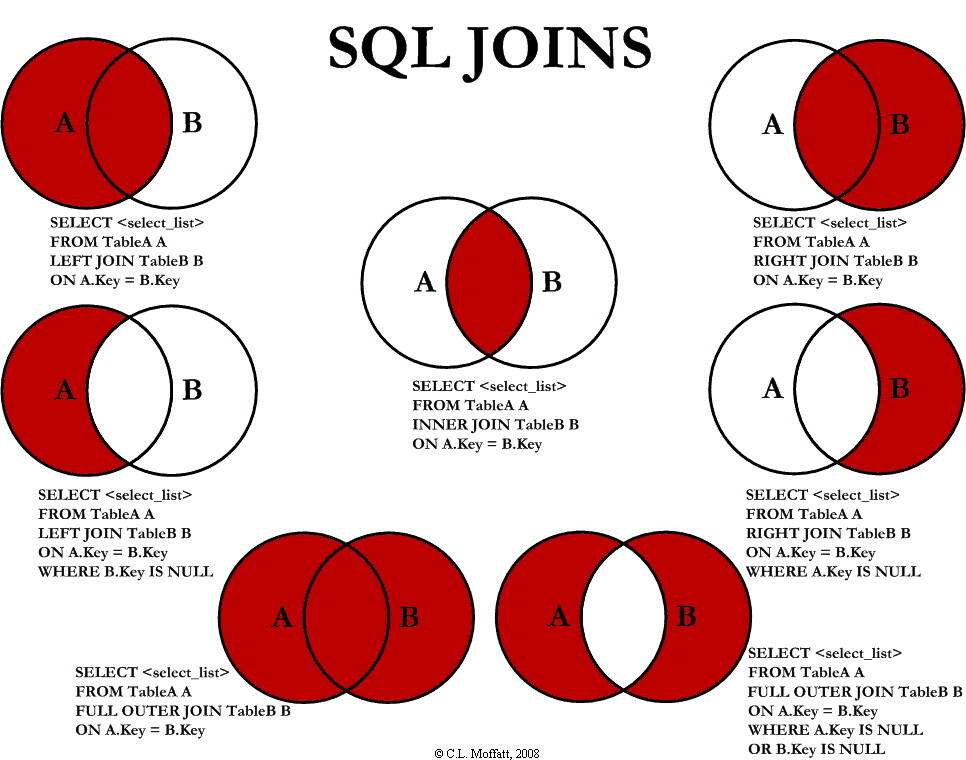
inner join 交集
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
- columns:要显示的列名。
- table1:表1的名称。
- table2:表2的名称。
- column_name:表中用于连接的列名。
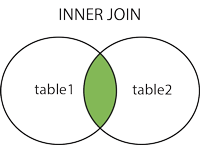
left jion(右表没有也会记录) A全部 B没有对应null
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
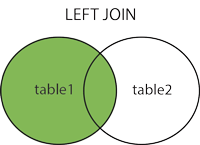
right join 右连 B全部,A没有的对应null
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
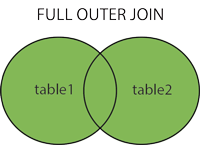
full outer join 并集
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
union
默认不允许重复
union all(可重复)
合并两个或多个select每个select语句需要拥有相同数量的列,列也必须拥有相同数据类型
select into
从一个表复制数据,然后把数据插入另一个新表中
用于拷贝表结构和数据
CREATE TABLE 新表
AS
SELECT * FROM 旧表
SELECT * 或某一列
INTO newtable [IN externaldb]
FROM table1;
insert into select
从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响。
else
- create database
- create table
constraints (约束)
-
添加 add 撤销 drop/alter
-
column_name3 data_type(size) constraint_name,
NOT NULL
- 指示某列不能存储 NULL 值。
- 添加 modify xx int not null
- 删除 modify xx int null
UNIQUE
- 保证某列的每行必须有唯一的值。
- 添加 add
- 撤销 drop
PRIMARY KEY
- NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- 添加add 撤销 drop
FOREIGN KEY
- 保证一个表中的数据匹配另一个表中的值的参照完整性。
- 添加 add 撤销 drop
CHECK
- 保证列中的值符合指定的条件。check(a>0 and/or b=‘a’)
- 添加 add 撤销 drop
DEFAULT
- 规定没有给列赋值时的默认值。
- 每个添加方式不同
- mysql alter
- sql/ms add
- oracle modify
- 撤销
- mysql alter
- sql alter
index
在不读取整表时,可快速查找数据,常用的加索引就好
-
CREATE INDEX index_name
ON table_name (column_name) -
CREATE UNIQUE INDEX index_name
ON table_name (column_name) -
drop撤销
alter table
在已有表中添加或删除修改列v(语法与环境有关)
auto increment
在新记录插入表中时生成唯一的数字(语法与环境有关)
视图 views
可视化表格
Date 函数SQL Server 和 MySQL 中的 Date 函数 | 菜鸟教程 (runoob.com)
mysql
| 函数 | 描述 |
|---|---|
| NOW() | 返回当前的日期和时间 |
| CURDATE() | 返回当前的日期 |
| CURTIME() | 返回当前的时间 |
| DATE() | 提取日期或日期/时间表达式的日期部分 |
| EXTRACT() | 返回日期/时间的单独部分 |
| DATE_ADD() | 向日期添加指定的时间间隔 |
| DATE_SUB() | 从日期减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的天数 |
| DATE_FORMAT() | 用不同的格式显示日期/时间 |
sql
| 函数 | 描述 |
|---|---|
| GETDATE() | 返回当前的日期和时间 |
| DATEPART() | 返回日期/时间的单独部分 |
| DATEADD() | 在日期中添加或减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的时间 |
| CONVERT() | 用不同的格式显示日期/时间 |
null 函数
- is null null值
- is not null 非null值
- null ≠ 0
- SQL ISNULL()、NVL()、IFNULL() 和 COALESCE() 函数 | 菜鸟教程 (runoob.com)
sql通用数据类型
| 数据类型 | 描述 |
|---|---|
| CHARACTER(n) | 字符/字符串。固定长度 n。 |
| VARCHAR(n) 或 CHARACTER VARYING(n) | 字符/字符串。可变长度。最大长度 n。 |
| BINARY(n) | 二进制串。固定长度 n。 |
| BOOLEAN | 存储 TRUE 或 FALSE 值 |
| VARBINARY(n) 或 BINARY VARYING(n) | 二进制串。可变长度。最大长度 n。 |
| INTEGER§ | 整数值(没有小数点)。精度 p。 |
| SMALLINT | 整数值(没有小数点)。精度 5。 |
| INTEGER | 整数值(没有小数点)。精度 10。 |
| BIGINT | 整数值(没有小数点)。精度 19。 |
| DECIMAL(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数,小数点后有 2 位数的数字。 |
| NUMERIC(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| FLOAT§ | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| REAL | 近似数值,尾数精度 7。 |
| FLOAT | 近似数值,尾数精度 16。 |
| DOUBLE PRECISION | 近似数值,尾数精度 16。 |
| DATE | 存储年、月、日的值。 |
| TIME | 存储小时、分、秒的值。 |
| TIMESTAMP | 存储年、月、日、小时、分、秒的值。 |
| INTERVAL | 由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| ARRAY | 元素的固定长度的有序集合 |
| MULTISET | 元素的可变长度的无序集合 |
| XML | 存储 XML 数据 |
| 数据类型 | Access | SQLServer | Oracle | MySQL | PostgreSQL |
|---|---|---|---|---|---|
| boolean | Yes/No | Bit | Byte | N/A | Boolean |
| integer | Number (integer) | Int | Number | Int Integer | Int Integer |
| float | Number (single) | Float Real | Number | Float | Numeric |
| currency | Currency | Money | N/A | N/A | Money |
| string (fixed) | N/A | Char | Char | Char | Char |
| string (variable) | Text (<256) Memo (65k+) | Varchar | Varchar Varchar2 | Varchar | Varchar |
| binary object | OLE Object Memo | Binary (fixed up to 8K) Varbinary (<8K) Image (<2GB) | Long Raw | Blob Text | Binary Varbinary |
sql函数
Aggregate 函数
从列中取得的值,返回一个单一的值
- AVG() - 返回平均值
- COUNT() - 返回这一列中符合count(内容)内容的行数
- FIRST() - 返回第一个记录的值(仅ms可用)
- sql top1 order by asc
- mysql order by asc limit1
- oraclr order by asc where xx<=1
- LAST() - 返回最后一个记录的值(仅ms可用)
- sql top1 order by decs
- mysql order by desc limit1
- oraclr order by desc where xx<=1
- MAX() - 返回指定列最大值
- MIN() - 返回指定列最小值
- SUM() - 返回指定列总和
group by
可结合聚合函数使用,根据一个或多个列对结果集进行分组
having
where 无法和聚合一起使用,HAVING 子句可以让我们筛选分组后的各组数据。
exists运算符
判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
SELECT Websites.name, Websites.url
FROM Websites
WHERE EXISTS (SELECT count FROM access_log WHERE Websites.id = access_log.site_id AND count > 200);
Scalar函数
基于输入的值,返回一个单一的值
-
UCASE() - 将某个字段转换为大写
-
LCASE() - 将某个字段转换为小写
-
MID() - 从某个文本字段提取字符,MySql 中使用
-
SELECT MID(column_name,start[,length]) FROM table_name;
-
参数 描述 column_name 必需。要提取字符的字段。 start 必需。规定开始位置(起始值是 1)。 length 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。
-
-
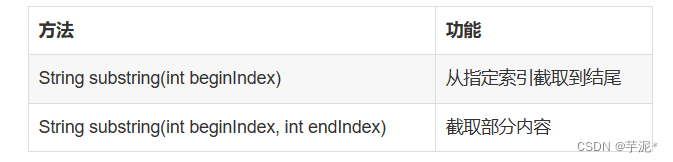
SubString(字段,1,end) - 从某个文本字段提取字符
-
LEN() - 返回某个文本字段的长度
-
mysql SELECT LENGTH(column_name) FROM table_name; -
sql SELECT LEN(column_name) FROM table_name;
-
-
ROUND() - 对某个数值字段进行指定小数位数的四舍五入
- mysql> SELECT ROUND(1.298, 1);
-> 1.3 - mysql> SELECT ROUND(1.298, 0);
-> 1
- mysql> SELECT ROUND(1.298, 1);
-
NOW() - 返回当前的系统日期和时间
-
FORMAT() - 格式化某个字段的显示方式
| SQL 语句 | 语法 |
|---|---|
| AND / OR | SELECT column_name(s) FROM table_name WHERE condition AND|OR condition |
| ALTER TABLE | ALTER TABLE table_name ADD column_name datatypeorALTER TABLE table_name DROP COLUMN column_name |
| AS (alias) | SELECT column_name AS column_alias FROM table_nameorSELECT column_name FROM table_name AS table_alias |
| BETWEEN | SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2 |
| CREATE DATABASE | CREATE DATABASE database_name |
| CREATE TABLE | CREATE TABLE table_name ( column_name1 data_type, column_name2 data_type, column_name2 data_type, … ) |
| CREATE INDEX | CREATE INDEX index_name ON table_name (column_name)orCREATE UNIQUE INDEX index_name ON table_name (column_name) |
| CREATE VIEW | CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition |
| DELETE | DELETE FROM table_name WHERE some_column=some_valueorDELETE FROM table_name (Note: Deletes the entire table!!)DELETE * FROM table_name (Note: Deletes the entire table!!) |
| DROP DATABASE | DROP DATABASE database_name |
| DROP INDEX | DROP INDEX table_name.index_name (SQL Server) DROP INDEX index_name ON table_name (MS Access) DROP INDEX index_name (DB2/Oracle) ALTER TABLE table_name DROP INDEX index_name (MySQL) |
| DROP TABLE | DROP TABLE table_name |
| GROUP BY | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name |
| HAVING | SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value |
| IN | SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,…) |
| INSERT INTO | INSERT INTO table_name VALUES (value1, value2, value3,…)orINSERT INTO table_name (column1, column2, column3,…) VALUES (value1, value2, value3,…) |
| INNER JOIN | SELECT column_name(s) FROM table_name1 INNER JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| LEFT JOIN | SELECT column_name(s) FROM table_name1 LEFT JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| RIGHT JOIN | SELECT column_name(s) FROM table_name1 RIGHT JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| FULL JOIN | SELECT column_name(s) FROM table_name1 FULL JOIN table_name2 ON table_name1.column_name=table_name2.column_name |
| LIKE | SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern |
| ORDER BY | SELECT column_name(s) FROM table_name ORDER BY column_name [ASC|DESC] |
| SELECT | SELECT column_name(s) FROM table_name |
| SELECT * | SELECT * FROM table_name |
| SELECT DISTINCT | SELECT DISTINCT column_name(s) FROM table_name |
| SELECT INTO | SELECT * INTO new_table_name [IN externaldatabase] FROM old_table_nameorSELECT column_name(s) INTO new_table_name [IN externaldatabase] FROM old_table_name |
| SELECT TOP | SELECT TOP number|percent column_name(s) FROM table_name |
| TRUNCATE TABLE | TRUNCATE TABLE table_name |
| UNION | SELECT column_name(s) FROM table_name1 UNION SELECT column_name(s) FROM table_name2 |
| UNION ALL | SELECT column_name(s) FROM table_name1 UNION ALL SELECT column_name(s) FROM table_name2 |
| UPDATE | UPDATE table_name SET column1=value, column2=value,… WHERE some_column=some_value |
| WHERE | SELECT column_name(s) FROM table_name WHERE column_name operator value |
相关文章:
数据库基础语法
sql(Structured Query Language 结构化查询语言) SQL语法 use DataTableName; 命令用于选择数据库。set names utf8; 命令用于设置使用的字符集。SELECT * FROM Websites; 读取数据表的信息。上面的表包含五条记录(每一条对应一个网站信息&…...
【Java】期末复习知识点总结(4)
适合Java期末的复习~ (Java期末复习知识点总结分为4篇,这里是最后一篇啦)第一篇~https://blog.csdn.net/qq_53869058/article/details/129417537?spm1001.2014.3001.5501第二篇~https://blog.csdn.net/qq_53869058/article/details/1294751…...
IDEA好用插件:MybatisX快速生成接口实体类mapper.xml映射文件
目录 1、在Idea中找到下载插件,Install,重启Idea 2、一个测试java文件,里面有com包 3、在Idea中添加数据库 --------以Oracle数据库为例 4、快速生成entity-service-mapper方法 5、查看生成的代码 6、自动生成(增删查改࿰…...

【JavaEE】初识线程
一、简述进程认识线程之前我们应该去学习一下“进程" 的概念,我们可以把一个运行起来的程序称之为进程,进程的调度,进程的管理是由我们的操作系统来管理的,创建一个进程,操作系统会为每一个进程创建一个 PCB&…...
智慧水务监控系统-智慧水务信息化平台建设
平台概述柳林智慧水务监控系统(智慧水务信息化平台)是以物联感知技术、大数据、智能控制、云计算、人工智能、数字孪生、AI算法、虚拟现实技术为核心,以监测仪表、通讯网络、数据库系统、数据中台、模型软件、前台展示、智慧运维等产品体系为…...
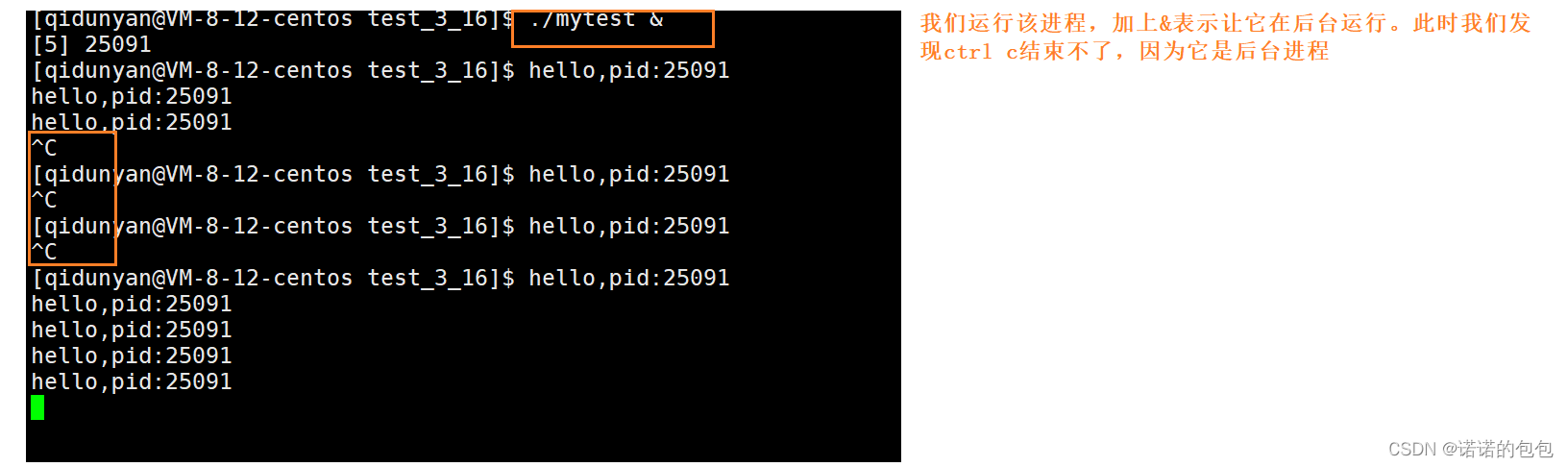
【Linux】进程优先级前后台理解
环境:centos7.6,腾讯云服务器Linux文章都放在了专栏:【Linux】欢迎支持订阅🌹相关文章推荐:【Linux】冯.诺依曼体系结构与操作系统【Linux】进程理解与学习(Ⅰ)浅谈Linux下的shell--BASH【Linux…...
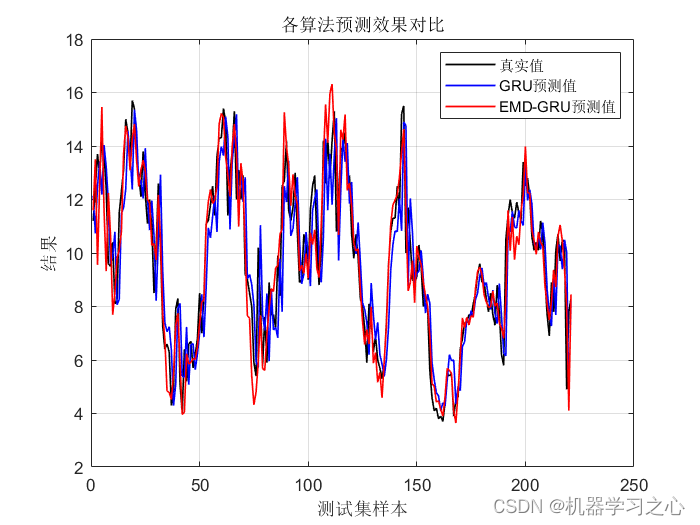
时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元)
时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元) 目录 时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元)效果一览基本描述模型描述程序设计参考资料效果一览...

python 模拟鼠标,键盘点击
信息爆炸 消息轰炸模拟鼠标和键盘敲击import time from pynput.keyboard import Controller as key_col from pynput.mouse import Button,Controller def keyboard_input(insertword):keyboardkey_col()keyboard.type(insertword)def mouth():mouseController()mouse.press(…...
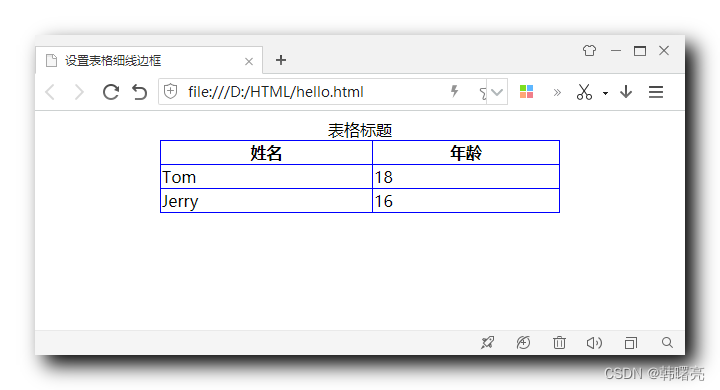
【CSS】盒子边框 ③ ( 设置表格细线边框 | 合并相邻边框 border-collapse: collapse; )
文章目录一、设置表格细线边框1、表格示例2、合并相邻边框3、完整代码示例一、设置表格细线边框 1、表格示例 给定一个 HTML 结构中的表格 , 默认样式如下 : <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8" />…...
)
TensorRT量化工具pytorch_quantization代码解析(一)
量化工具箱pytorch_quantization 通过提供一个方便的 PyTorch 库来补充 TensorRT ,该库有助于生成可优化的 QAT 模型。该工具包提供了一个 API 来自动或手动为 QAT 或 PTQ 准备模型。 API 的核心是 TensorQuantizer 模块,它可以量化、伪量化或收集张量的…...
【Kubernetes】第二十七篇 - 布署前端项(下)
一,前言 上一篇,介绍了前端项目的部署:项目的创建和 jenkins 配置; 本篇,创建 Deployment、Service,完成前端项目的部署; 二,创建 Deployment 创建 Deployment 配置文件ÿ…...
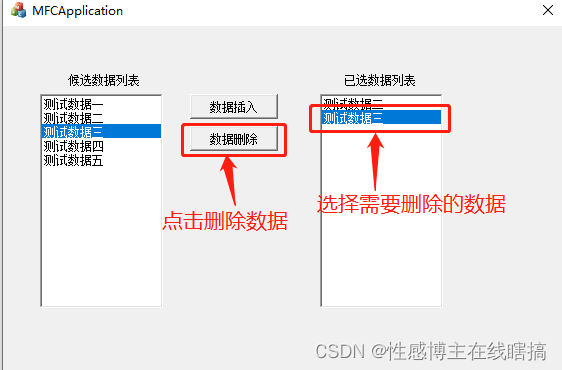
【MFC】两个ListBox控件数据交互
一.控件ID名称 界面如图下所示: 候选数据列表的ID为: 已选数据列表的ID为: 二.数据添加 可以使用以下代码往框中添加数据: ((CListBox *)GetDlgItem(IDC_LIST_TO_CHO))->AddString("测试数据"); 显示效果如下&#…...

sklearn库学习--SelectKBest 、f_regression
目录 一、SelectKBest 介绍、代码使用 介绍: 代码使用: 二、评分函数 【1】f_regression: (1)介绍: (2)F值和相关系数 【2】除了f_regression函数,还有一些适用于…...

蓝桥杯刷题第十三天
第一题:特殊日期问题描述对于一个日期,我们可以计算出年份的各个数位上的数字之和,也可以分别计算月和日的各位数字之和。请问从 1900 年 11 月 1 日至 9999 年 12 月 31 日,总共有多少天,年份的数位数字之和等于月的数…...

CPU 和带宽之间的时空权衡
在 从一道面试题看 TCP 的吞吐极限 一文的开始,我提到在环形域上两个数字比较大小的前提是在同一个半圆内,进而得到滑动窗口最大值被限定在一个环形域的一半。 现在来看更为基本的问题。如果序列号只有 2bit,甚至仅有 1bit,保序传…...
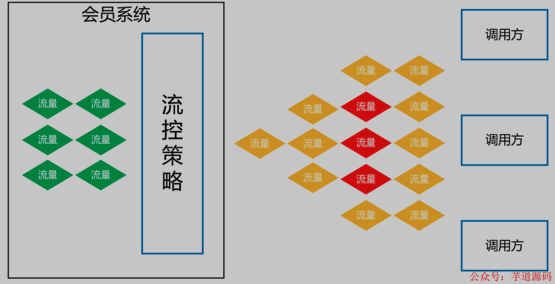
ES+Redis+MySQL,这个高可用架构设计太顶了!
一、背景 会员系统是一种基础系统,跟公司所有业务线的下单主流程密切相关。如果会员系统出故障,会导致用户无法下单,影响范围是全公司所有业务线。所以,会员系统必须保证高性能、高可用,提供稳定、高效的基础服务。 …...

【Maven】Maven的常用命令
目录 一、Maven的常用命令 1、compile 编译命令 2、test 测试命令 3 、clean 清理命令 4、package 打包命令 5、 install 安装命令 6、Maven 指令的生命周期 二、maven 的概念模型 💟 创作不易,不妨点赞💚评论❤️收藏💙一…...

python的循环结构
python中有for循环和while循环两种形式。 1. for 循环 可以用for循环来遍历不同类型的对象,如数组、列表、元组、字典、集合或字符串,并对每个元素执行一段代码。 1.1 数组的for循环 用for循环遍历一个数组,并打印出每个元素:…...

五种Python中字典的高级用法
1. 引言 Python中的字典是一种非常有用的数据结构,它允许大家存储键值对。通常来说,字典灵活、高效且易于使用,是Python中最常用的数据结构之一。字典通常被用于统计频率、映射值等任务,但在Python中使用字典也可以达到许多意想不…...

[蓝桥杯单片机]——八到十一届初赛决赛客观题
第八届初赛 一、填空题 采用外部12MHz晶振,经过系统12分频时定时器获得最大定时长度,此时定时器定时脉冲为1MHz,周期为1s,而定时器计时均为16位加法计数器,即计时长度为。 二、 选择题 ①带阻滤波器是指能通过大多数频…...

保姆级避坑指南:在Ubuntu 22.04上为ROS2 Humble编译OpenCV 4.2.0和cv_bridge
深度解析:Ubuntu 22.04下ROS2 Humble与OpenCV 4.2.0的精准版本匹配实战 当视觉SLAM遇上ROS2生态,版本依赖就像一场精密的外科手术。本文将带你穿透ORB-SLAM3等视觉算法与ROS2 Humble环境整合时的核心痛点——特别是OpenCV 4.2.0与cv_bridge的版本锁定机…...

推荐算法闲谈:如何在不同业务场景下理解和拆解核心指标
巧解决的是能不能学好,而指标分析解决的是这次改动是否真正创造了业务价值,以及为什么。一个非常常见、但又极易被忽视的事实是:推荐系统并不存在一套放之四海而皆准的核心业务指标。不同产品形态、不同交互方式、不同公司发展阶段࿰…...

OpenCV轮廓匹配避坑指南:用cv2.matchShapes做形状识别,为什么你的结果总不准?
OpenCV轮廓匹配避坑指南:为什么你的cv2.matchShapes结果总是不准? 在工业质检、医疗影像分析等场景中,形状匹配的准确性直接影响着整个系统的可靠性。许多开发者在使用OpenCV的cv2.matchShapes函数时,明明按照官方文档操作&#x…...

Z-Image-Turbo-rinaiqiao-huiyewunv实战落地:高校动漫社AI辅助创作工作流搭建
Z-Image-Turbo-rinaiqiao-huiyewunv实战落地:高校动漫社AI辅助创作工作流搭建 1. 项目背景与核心价值 高校动漫社团经常面临创作效率低、人手不足的问题。传统手绘方式需要大量时间,而通用AI绘图工具又难以保持角色一致性。Z-Image Turbo (辉夜大小姐-…...
)
香橙派Armbian系统下,用apt一键安装OpenCV的完整流程(含GPG报错解决)
香橙派Armbian系统下OpenCV-Python极简安装指南:绕过源码编译的终极方案 在单板计算机领域,香橙派凭借其出色的性价比逐渐崭露头角。当开发者尝试在这类ARM架构设备上构建计算机视觉应用时,OpenCV往往是不可或缺的核心工具。然而,…...

终极指南:3步用VR-Reversal将3D视频转为2D,普通设备也能自由探索VR世界
终极指南:3步用VR-Reversal将3D视频转为2D,普通设备也能自由探索VR世界 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址…...

Arduino串口乱码?波特率选9600还是115200?一次讲清串口通信的配置与避坑指南
Arduino串口通信终极指南:从波特率选择到实战避坑 当你第一次在Arduino串口监视器看到一堆乱码时,那种挫败感我深有体会。串口通信作为Arduino与外界对话的核心通道,其稳定性直接影响项目成败。本文将带你深入串口通信的底层逻辑,…...

经验值|React 实时数据图表性能为什么会越来越卡?
在使用 React 和 Highcharts 创建实时图表时,性能下降通常与以下几个因素有关:频繁更新状态:如果你频繁更新图表的数据状态,React 可能会进行多次重渲染,导致性能下降。建议使用 useRef 来引用图表实例,避免…...

「码动四季·开源同行」go语言:统一认证与授权如何保障服务安全
认证与授权对于当前的互联网应用是非常重要的基础功能:认证用于验证当前用户的身份,而授权意味着用户在认证成功后,会被系统授予访问系统资源的权限。只有具备相应身份和权限的人才能访问系统中的相应资源,比如在购物网站中你只能…...
)
避坑指南:pyzbar识别模糊二维码的5种图像预处理技巧(Python+OpenCV)
提升pyzbar识别率:5种图像预处理技术解决模糊二维码难题 1. 模糊二维码识别的核心挑战 在现实应用中,二维码识别经常遇到各种图像质量问题。我曾在一个物流仓储项目中亲眼目睹,由于包装反光和运输磨损,标准识别流程的失败率高达40…...