【深度强化学习】(6) PPO 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度强化学习中的近端策略优化算法(proximal policy optimization,PPO),并借助 OpenAI 的 gym 环境完成一个小案例,完整代码可以从我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 算法原理
PPO 算法之所以被提出,根本原因在于 Policy Gradient 在处理连续动作空间时 Learning rate 取值抉择困难。Learning rate 取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。除此之外,Policy Gradient 因为在线学习的性质,进行迭代策略时原先的采样数据无法被重复利用,每次迭代都需要重新采样;
同样地置信域策略梯度算法(Trust Region Policy Optimization,TRPO)虽然利用重要性采样(Important-sampling)、共轭梯度法求解提升了样本效率、训练速率等,但在处理函数的二阶近似时会面临计算量过大,以及实现过程复杂、兼容性差等缺陷。
PPO 算法具备 Policy Gradient、TRPO 的部分优点,采样数据和使用随机梯度上升方法优化代替目标函数之间交替进行,虽然标准的策略梯度方法对每个数据样本执行一次梯度更新,但 PPO 提出新目标函数,可以实现小批量更新。
鉴于上述问题,该算法在迭代更新时,观察当前策略在 t 时刻智能体处于状态 s 所采取的行为概率,与之前策略所采取行为概率
,计算概率的比值来控制新策略更新幅度,比值
记作:
若新旧策略差异明显且优势函数较大,则适当增加更新幅度;若 比值越接近 1,表明新旧策略差异越小。
优势函数代表,在状态 s 下,行为 a 相对于均值的偏差。在论文中,优势函数 使用 GAE(generalized advantage estimation)来计算:
PPO 算法可依据 Actor 网络的更新方式细化为含有自适应 KL-散度(KL Penalty)的 PPO-Penalty 和含有 Clippped Surrogate Objective 函数的 PPO-Clip。
(1)PPO-Penalty 基于KL 惩罚项优化目标函数,实验证明惩罚项系数 在迭代过程中并非固定值,需要动态调整惩罚权重,其目标函数 L 可以定义为:
惩罚项 的初始值的选择对算法几乎无影响,原因是它能在每次迭代时依据新旧策略的 KL 散度做适宜调整,首先设置 KL 散度阈值
,再通过下面的表达式计算
:
如果 时,证明散度较小,需要弱化惩罚力度,
调整为
;
如果 时,证明散度较大,需要增强惩罚力度,
调整为
。
(2)PPO-Clip 直接对新旧策略比例进行一定程度的 Clip 操作,以约束变化幅度。其目标函数的计算方式如下:
其中, 代表截断超参数,一般设定值为 0.2;
表示截断函数,负责限制比例
在
区间之内,以保证收敛性;最终
借助
函数选取未截断与截断目标之间的更小值,形成目标下限。
可以分为优势函数 A 为正数和负数两种情况,其变化趋势如下图所示:
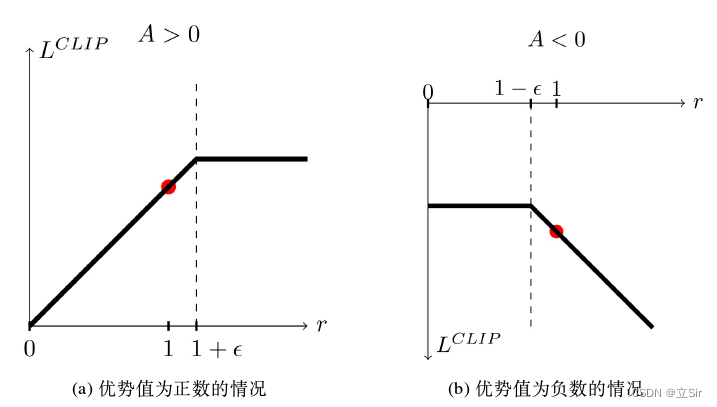
如果优势函数为正数,需要增大新旧策略比值 ,然而当
时,将不提供额外的激励;如果优势函数是负数,需要减少新旧策略比值
,但在
时,不提供额外的激励,这使得新旧策略的差异被限制在合理范围内。PPO 本质上基于 Actor-Critic 框架,算法流程如下:

PPO 算法主要由 Actor 和 Critic 两部分构成,Critic 部分更新方式与其他Actor-Critic 类型相似,通常采用计算 TD error(时序差分误差)形式。对于 Actor 的更新方式,PPO 可在KLPENL 、CLIPL 之间选择对于当前实验环境稳定性适用性更强的目标函数,经过 OpenAI 研究团队实验论证,PPO- Clip 比 PPO- Penalty有更好的数据效率和可行性。
2. 代码实现
下面我就采用 Clip 形式的 PPO。模型构建代码如下。下面的模型适用于 action 是离散的情况,连续情况的代码可以从我的 GitHub 中获取。
# 代码用于离散环境的模型
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F# ----------------------------------- #
# 构建策略网络--actor
# ----------------------------------- #class PolicyNet(nn.Module):def __init__(self, n_states, n_hiddens, n_actions):super(PolicyNet, self).__init__()self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_actions)def forward(self, x):x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x)x = self.fc2(x) # [b, n_actions]x = F.softmax(x, dim=1) # [b, n_actions] 计算每个动作的概率return x# ----------------------------------- #
# 构建价值网络--critic
# ----------------------------------- #class ValueNet(nn.Module):def __init__(self, n_states, n_hiddens):super(ValueNet, self).__init__()self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, 1)def forward(self, x):x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x)x = self.fc2(x) # [b,n_hiddens]-->[b,1] 评价当前的状态价值state_valuereturn x# ----------------------------------- #
# 构建模型
# ----------------------------------- #class PPO:def __init__(self, n_states, n_hiddens, n_actions,actor_lr, critic_lr, lmbda, epochs, eps, gamma, device):# 实例化策略网络self.actor = PolicyNet(n_states, n_hiddens, n_actions).to(device)# 实例化价值网络self.critic = ValueNet(n_states, n_hiddens).to(device)# 策略网络的优化器self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)# 价值网络的优化器self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr = critic_lr)self.gamma = gamma # 折扣因子self.lmbda = lmbda # GAE优势函数的缩放系数self.epochs = epochs # 一条序列的数据用来训练轮数self.eps = eps # PPO中截断范围的参数self.device = device# 动作选择def take_action(self, state):# 维度变换 [n_state]-->tensor[1,n_states]state = torch.tensor(state[np.newaxis, :]).to(self.device)# 当前状态下,每个动作的概率分布 [1,n_states]probs = self.actor(state)# 创建以probs为标准的概率分布action_list = torch.distributions.Categorical(probs)# 依据其概率随机挑选一个动作action = action_list.sample().item()return action# 训练def learn(self, transition_dict):# 提取数据集states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions']).to(self.device).view(-1,1)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).to(self.device).view(-1,1)next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'], dtype=torch.float).to(self.device).view(-1,1)# 目标,下一个状态的state_value [b,1]next_q_target = self.critic(next_states)# 目标,当前状态的state_value [b,1]td_target = rewards + self.gamma * next_q_target * (1-dones)# 预测,当前状态的state_value [b,1]td_value = self.critic(states)# 目标值和预测值state_value之差 [b,1]td_delta = td_target - td_value# 时序差分值 tensor-->numpy [b,1]td_delta = td_delta.cpu().detach().numpy()advantage = 0 # 优势函数初始化advantage_list = []# 计算优势函数for delta in td_delta[::-1]: # 逆序时序差分值 axis=1轴上倒着取 [], [], []# 优势函数GAE的公式advantage = self.gamma * self.lmbda * advantage + deltaadvantage_list.append(advantage)# 正序advantage_list.reverse()# numpy --> tensor [b,1]advantage = torch.tensor(advantage_list, dtype=torch.float).to(self.device)# 策略网络给出每个动作的概率,根据action得到当前时刻下该动作的概率old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()# 一组数据训练 epochs 轮for _ in range(self.epochs):# 每一轮更新一次策略网络预测的状态log_probs = torch.log(self.actor(states).gather(1, actions))# 新旧策略之间的比例ratio = torch.exp(log_probs - old_log_probs)# 近端策略优化裁剪目标函数公式的左侧项surr1 = ratio * advantage# 公式的右侧项,ratio小于1-eps就输出1-eps,大于1+eps就输出1+epssurr2 = torch.clamp(ratio, 1-self.eps, 1+self.eps) * advantage# 策略网络的损失函数actor_loss = torch.mean(-torch.min(surr1, surr2))# 价值网络的损失函数,当前时刻的state_value - 下一时刻的state_valuecritic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))# 梯度清0self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()# 反向传播actor_loss.backward()critic_loss.backward()# 梯度更新self.actor_optimizer.step()self.critic_optimizer.step()3. 案例演示
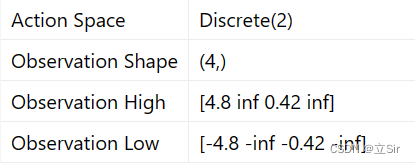
基于 OpenAI 的 gym 环境完成一个推车游戏,一个离散的环境,目标是左右移动小车将黄色的杆子保持竖直。动作维度为2,属于离散值;状态维度为 4,分别是坐标、速度、角度、角速度。
import numpy as np
import matplotlib.pyplot as plt
import gym
import torch
from RL_brain import PPOdevice = torch.device('cuda') if torch.cuda.is_available() \else torch.device('cpu')# ----------------------------------------- #
# 参数设置
# ----------------------------------------- #num_episodes = 100 # 总迭代次数
gamma = 0.9 # 折扣因子
actor_lr = 1e-3 # 策略网络的学习率
critic_lr = 1e-2 # 价值网络的学习率
n_hiddens = 16 # 隐含层神经元个数
env_name = 'CartPole-v1'
return_list = [] # 保存每个回合的return# ----------------------------------------- #
# 环境加载
# ----------------------------------------- #env = gym.make(env_name, render_mode="human")
n_states = env.observation_space.shape[0] # 状态数 4
n_actions = env.action_space.n # 动作数 2# ----------------------------------------- #
# 模型构建
# ----------------------------------------- #agent = PPO(n_states=n_states, # 状态数n_hiddens=n_hiddens, # 隐含层数n_actions=n_actions, # 动作数actor_lr=actor_lr, # 策略网络学习率critic_lr=critic_lr, # 价值网络学习率lmbda = 0.95, # 优势函数的缩放因子epochs = 10, # 一组序列训练的轮次eps = 0.2, # PPO中截断范围的参数gamma=gamma, # 折扣因子device = device)# ----------------------------------------- #
# 训练--回合更新 on_policy
# ----------------------------------------- #for i in range(num_episodes):state = env.reset()[0] # 环境重置done = False # 任务完成的标记episode_return = 0 # 累计每回合的reward# 构造数据集,保存每个回合的状态数据transition_dict = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': [],}while not done:action = agent.take_action(state) # 动作选择next_state, reward, done, _, _ = env.step(action) # 环境更新# 保存每个时刻的状态\动作\...transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)# 更新状态state = next_state# 累计回合奖励episode_return += reward# 保存每个回合的returnreturn_list.append(episode_return)# 模型训练agent.learn(transition_dict)# 打印回合信息print(f'iter:{i}, return:{np.mean(return_list[-10:])}')# -------------------------------------- #
# 绘图
# -------------------------------------- #plt.plot(return_list)
plt.title('return')
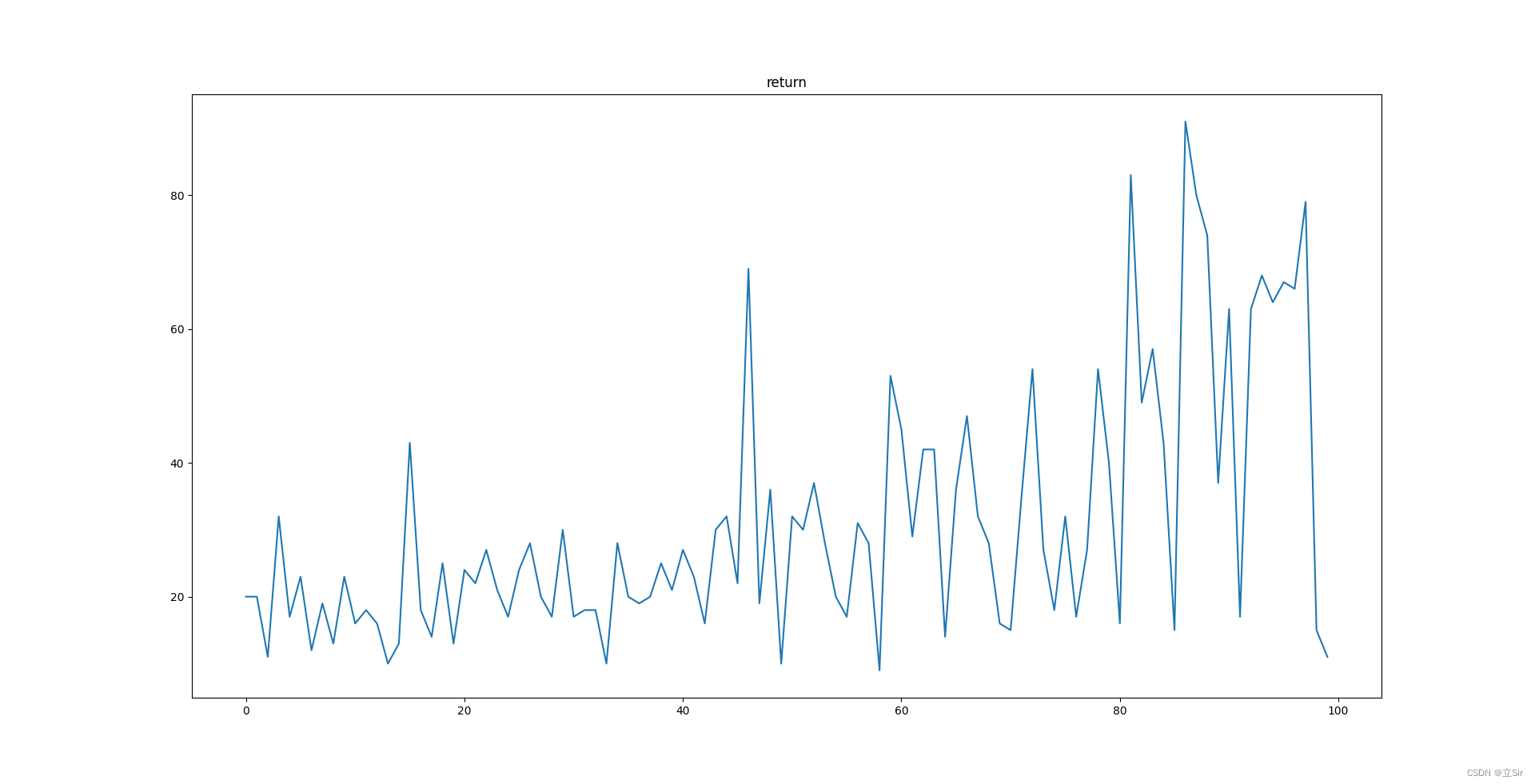
plt.show()训练100回合,绘制每回合的 return
相关文章:
【深度强化学习】(6) PPO 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度强化学习中的近端策略优化算法(proximal policy optimization,PPO),并借助 OpenAI 的 gym 环境完成一个小案例,完整代码可以从我的 GitHub 中获得: https://gith…...
【数据结构】第二站:顺序表
目录 一、线性表 二、顺序表 1.顺序表的概念以及结构 2.顺序表的接口实现 3.顺序表完整代码 三、顺序表的经典题目 1.移除元素 2.删除有序数组中的重复项 3.合并两个有序数组 一、线性表 在了解顺序表前,我们得先了解线性表的概念 线性表(linear…...
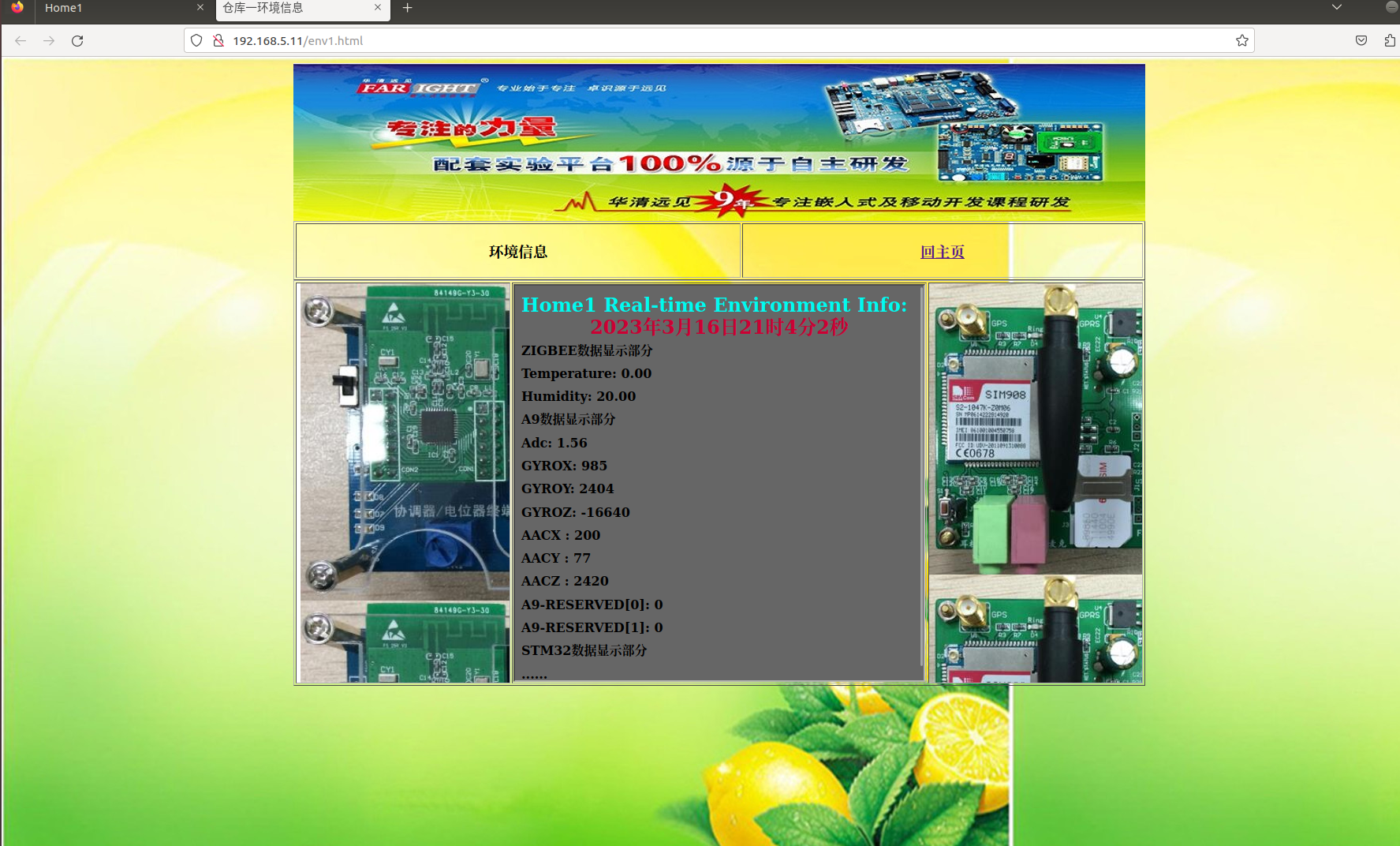
嵌入式安防监控项目——实现真实数据的上传
目录 一、相关驱动开发 二、A9主框架 三、脚本及数据上传实验 https://www.yuque.com/uh1h8r/dqrma0/tx0fq08mw1ar1sor?singleDoc# 《常见问题》 上个笔记的相关问题 一、相关驱动开发 /* mpu6050六轴传感器 */ i2c138B0000 { /* #address-cells <1>…...
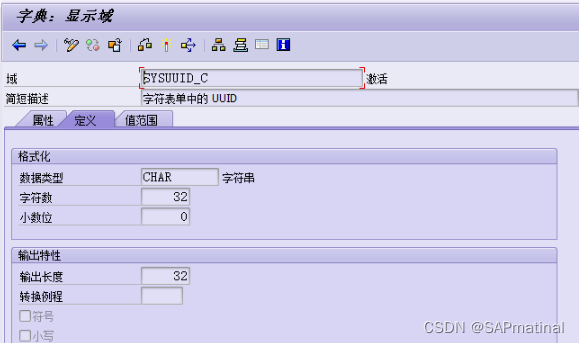
SAP 生成UUID
UUID含义是通用唯一识别码 (Universally Unique Identifier),这 是一个软件建构的标准,也是被开源软件基金会 (Open Software Foundation, OSF) 的组织应用在分布式计算环境 (Distributed Computing Environment, DCE) 领域的一部分。 UUID-Universally…...

DevOPs介绍,这一篇就足够了
一、什么是DevOps? DevOps是一种将软件开发和IT运维进行整合的文化和运动。它的目标是通过加强软件开发、测试和运维之间的协作和沟通,使整个软件开发和交付过程更加高效、快速、安全和可靠。DevOps涵盖了从计划和设计到开发、测试、交付和部署的全生命…...
libcurl库简介
一、libcurl简介libcurl是一个跨平台的网络协议库,支持http, https, ftp, gopher, telnet, dict, file, 和ldap 协议。libcurl同样支持HTTPS证书授权,HTTP POST, HTTP PUT, FTP 上传, HTTP基本表单上传,代理,cookies,和用户认证。…...
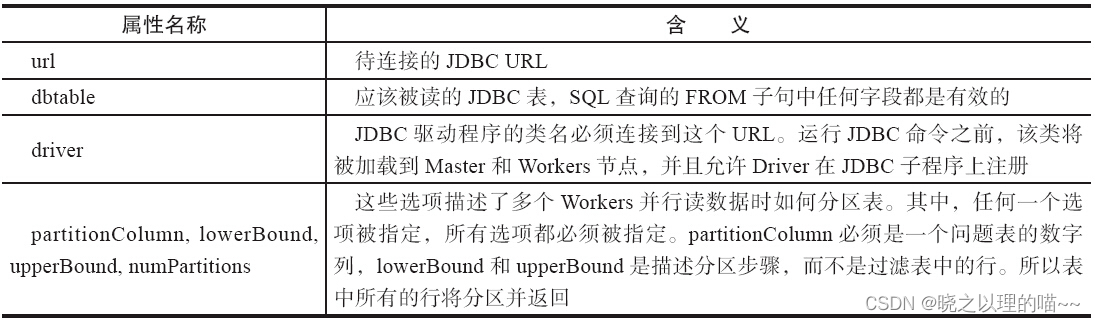
Spark SQL支持DataFrame操作的数据源
DataFrame提供统一接口加载和保存数据源中的数据,包括:结构化数据、Parquet文件、JSON文件、Hive表,以及通过JDBC连接外部数据源。一个DataFrame可以作为普通的RDD操作,也可以通过(registerTempTable)注册成…...
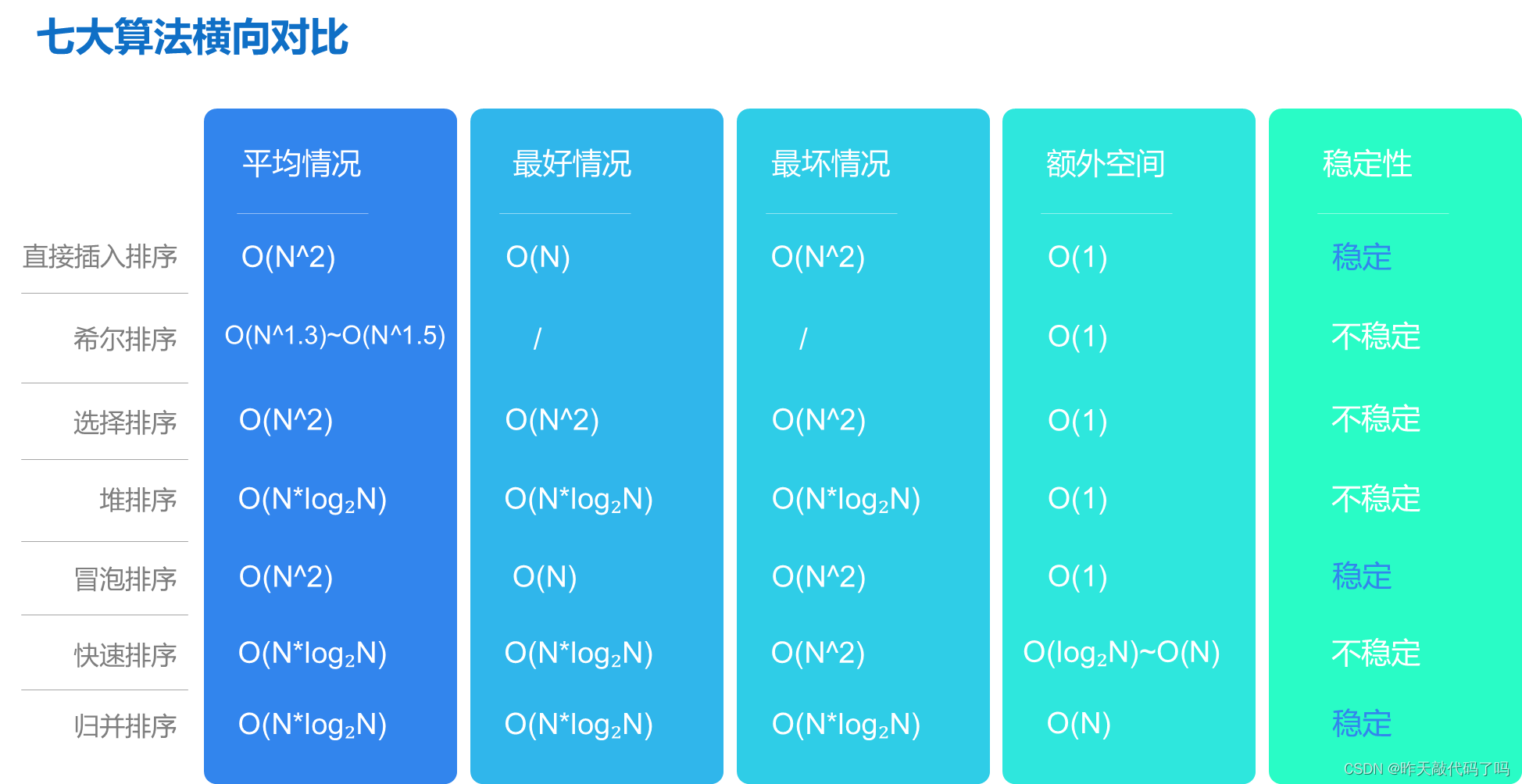
Java【归并排序】算法, 大白话式图文解析(附代码)
文章目录前言一、排序相关概念1, 什么是排序2, 什么是排序的稳定性3, 七大排序分类二、归并排序1, 图文解析2, 代码实现三、性能分析四、七大排序算法总体分析前言 各位读者好, 我是小陈, 这是我的个人主页 小陈还在持续努力学习编程, 努力通过博客输出所学知识 如果本篇对你有…...

【springboot】数据库访问
1、SQL 1、数据源的自动配置-HikariDataSource 1、导入JDBC场景 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jdbc</artifactId></dependency>数据库驱动? 为什么导入JD…...

普通和hive兼容模式下sql的差异
–odps sql –– –author:宋文理 –create time:2023-03-08 15:23:52 –– – 差异分为三块 – 1.运算符的差异 – 2.类型转换的差异 – 3.内建函数的差异 – 以下是运算符的差异: – BITAND(&) – 当输入参数是BIGINT类型的时候&…...
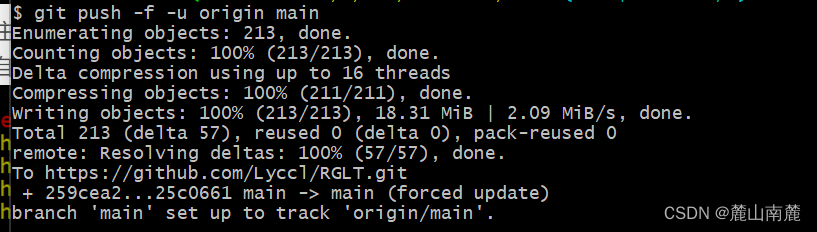
github开源自己代码
接下来,我们需要先下载Git,的网址:https://git-scm.com/downloads,安装时如果没有特殊需求,一直下一步就可以了,安装完成之后,双击打开Git Bash 出现以下界面: 第一步:…...
数据库基础语法
sql(Structured Query Language 结构化查询语言) SQL语法 use DataTableName; 命令用于选择数据库。set names utf8; 命令用于设置使用的字符集。SELECT * FROM Websites; 读取数据表的信息。上面的表包含五条记录(每一条对应一个网站信息&…...
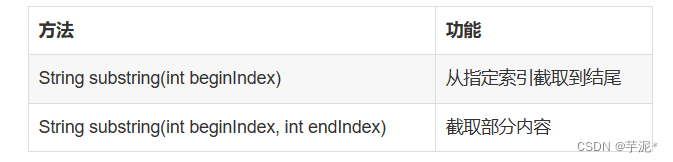
【Java】期末复习知识点总结(4)
适合Java期末的复习~ (Java期末复习知识点总结分为4篇,这里是最后一篇啦)第一篇~https://blog.csdn.net/qq_53869058/article/details/129417537?spm1001.2014.3001.5501第二篇~https://blog.csdn.net/qq_53869058/article/details/1294751…...
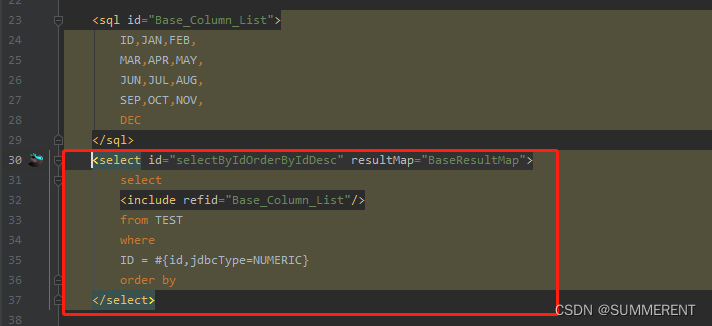
IDEA好用插件:MybatisX快速生成接口实体类mapper.xml映射文件
目录 1、在Idea中找到下载插件,Install,重启Idea 2、一个测试java文件,里面有com包 3、在Idea中添加数据库 --------以Oracle数据库为例 4、快速生成entity-service-mapper方法 5、查看生成的代码 6、自动生成(增删查改࿰…...

【JavaEE】初识线程
一、简述进程认识线程之前我们应该去学习一下“进程" 的概念,我们可以把一个运行起来的程序称之为进程,进程的调度,进程的管理是由我们的操作系统来管理的,创建一个进程,操作系统会为每一个进程创建一个 PCB&…...
智慧水务监控系统-智慧水务信息化平台建设
平台概述柳林智慧水务监控系统(智慧水务信息化平台)是以物联感知技术、大数据、智能控制、云计算、人工智能、数字孪生、AI算法、虚拟现实技术为核心,以监测仪表、通讯网络、数据库系统、数据中台、模型软件、前台展示、智慧运维等产品体系为…...
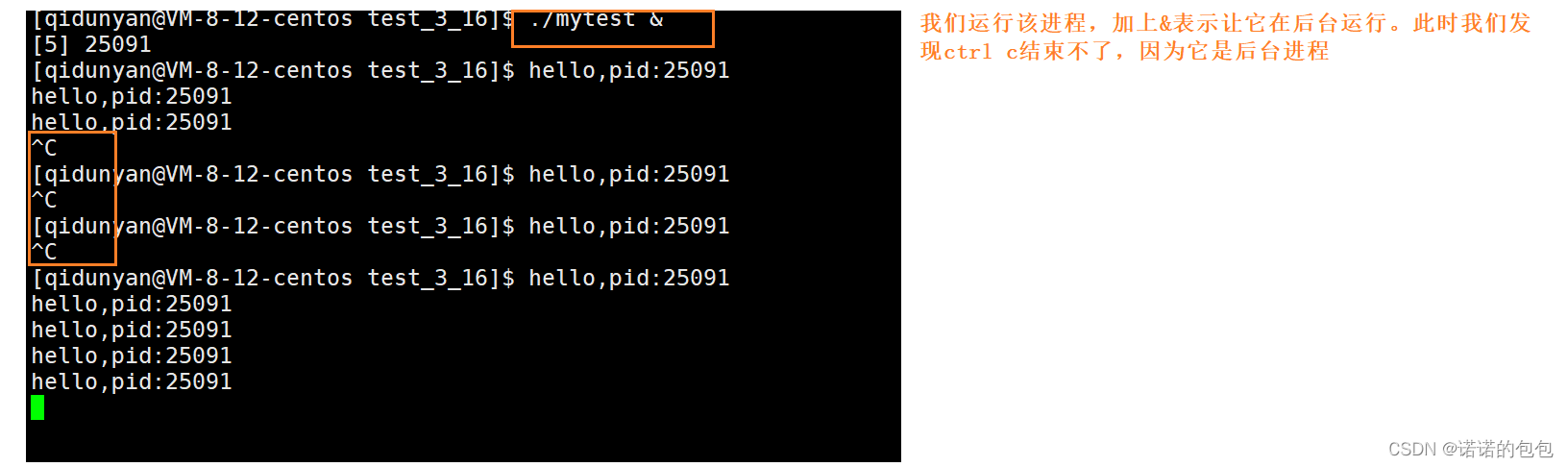
【Linux】进程优先级前后台理解
环境:centos7.6,腾讯云服务器Linux文章都放在了专栏:【Linux】欢迎支持订阅🌹相关文章推荐:【Linux】冯.诺依曼体系结构与操作系统【Linux】进程理解与学习(Ⅰ)浅谈Linux下的shell--BASH【Linux…...
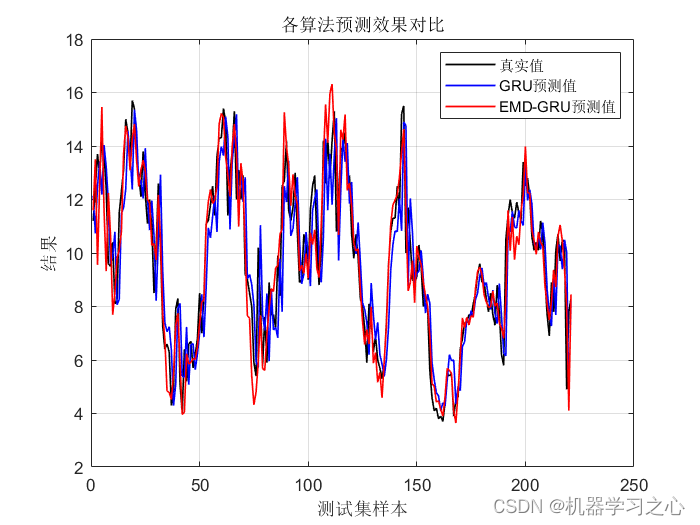
时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元)
时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元) 目录 时序预测 | MATLAB实现基于EMD-GRU时间序列预测(EMD分解结合GRU门控循环单元)效果一览基本描述模型描述程序设计参考资料效果一览...

python 模拟鼠标,键盘点击
信息爆炸 消息轰炸模拟鼠标和键盘敲击import time from pynput.keyboard import Controller as key_col from pynput.mouse import Button,Controller def keyboard_input(insertword):keyboardkey_col()keyboard.type(insertword)def mouth():mouseController()mouse.press(…...
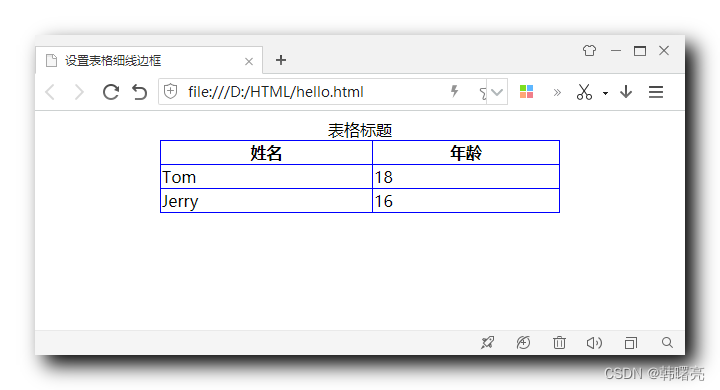
【CSS】盒子边框 ③ ( 设置表格细线边框 | 合并相邻边框 border-collapse: collapse; )
文章目录一、设置表格细线边框1、表格示例2、合并相邻边框3、完整代码示例一、设置表格细线边框 1、表格示例 给定一个 HTML 结构中的表格 , 默认样式如下 : <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8" />…...

3个步骤打造个性化PDF阅读体验:Zotero Style视觉定制指南
3个步骤打造个性化PDF阅读体验:Zotero Style视觉定制指南 【免费下载链接】zotero-style zotero-style - 一个 Zotero 插件,提供了一系列功能来增强 Zotero 的用户体验,如阅读进度可视化和标签管理,适合研究人员和学者。 项目地…...

从零到一:实战华为OceanStor SAN存储与Linux服务器的iSCSI对接
1. 环境准备:理解iSCSI与SAN存储的“桥梁”作用 大家好,我是老张,一个在运维圈子里摸爬滚打了十多年的老家伙。今天咱们不聊虚的,就来手把手干一件在数据中心里特别常见,但对新手又有点“发怵”的活儿:把一…...

突破网页图片格式壁垒:Save Image as Type让格式转换效率提升80%
突破网页图片格式壁垒:Save Image as Type让格式转换效率提升80% 【免费下载链接】Save-Image-as-Type Save Image as Type is an chrome extension which add Save as PNG / JPG / WebP to the context menu of image. 项目地址: https://gitcode.com/gh_mirrors…...

DeepSeek-OCR-2部署教程:阿里云ECS+GPU实例一键部署OCR服务全流程
DeepSeek-OCR-2部署教程:阿里云ECSGPU实例一键部署OCR服务全流程 本文介绍如何在阿里云ECS GPU实例上快速部署DeepSeek-OCR-2模型,搭建完整的OCR识别服务。 1. 环境准备与服务器选择 1.1 服务器配置要求 DeepSeek-OCR-2作为高性能OCR模型,对…...

微信 AI 入口网关设计思路优化
技术支持 wechatapi.net 将微信作为 AI 入口网关的核心在于架构分层和标准化设计,尤其需整合 WechatAPI(微信官方接口)来实现高效、可靠的交互。以下是优化后的关键设计要点,强调 WechatAPI 的集成以提升系统健壮性和扩展性。 We…...

Leather Dress Collection部署案例:高校服装设计课程AI辅助教学落地实践
Leather Dress Collection部署案例:高校服装设计课程AI辅助教学落地实践 1. 引言 想象一下,服装设计专业的学生在构思毕业设计作品时,脑海中浮现出一个大胆的想法:一套融合了未来主义与复古元素的皮革连衣裙。传统的设计流程需要…...

基于TI电赛开发板的L298N电机驱动模块PWM调速移植实战
基于TI电赛开发板的L298N电机驱动模块PWM调速移植实战 最近在准备电赛,很多同学都在为智能小车项目里的电机控制发愁。大家手里都有经典的L298N电机驱动模块,但怎么把它和TI的电赛开发板(比如MSP430系列)连起来,用PWM实…...
客户端安装以及常用命令)
OpenShift CLI (oc)客户端安装以及常用命令
oc 是 OpenShift 的命令行客户端,基于 Kubernetes 的 kubectl 构建,并扩展了许多 OpenShift 特有的功能(如构建、部署配置、路由、镜像流等)。无论你是开发人员还是集群管理员,oc 都是与 OpenShift 交互的核心工具 1.…...

福州护校,谁家最强?
引言:医学中职教育的核心价值与选择逻辑在职业教育改革持续深化的背景下,医学类中职教育因其明确的职业导向和升学优势,成为初三毕业生的重要选择方向。其中,福州市榕卫技术学校凭借其独特的历史积淀与教学成果,在福州…...

多线程Web代理服务器:Computer-Networking-A-Top-Down-Approach-NOTES作业4教程
多线程Web代理服务器:Computer-Networking-A-Top-Down-Approach-NOTES作业4教程 【免费下载链接】Computer-Networking-A-Top-Down-Approach-NOTES 《计算机网络-自顶向下方法(原书第6版)》编程作业,Wireshark实验文档的翻译和解答。 项目地…...