深层神经网络示例
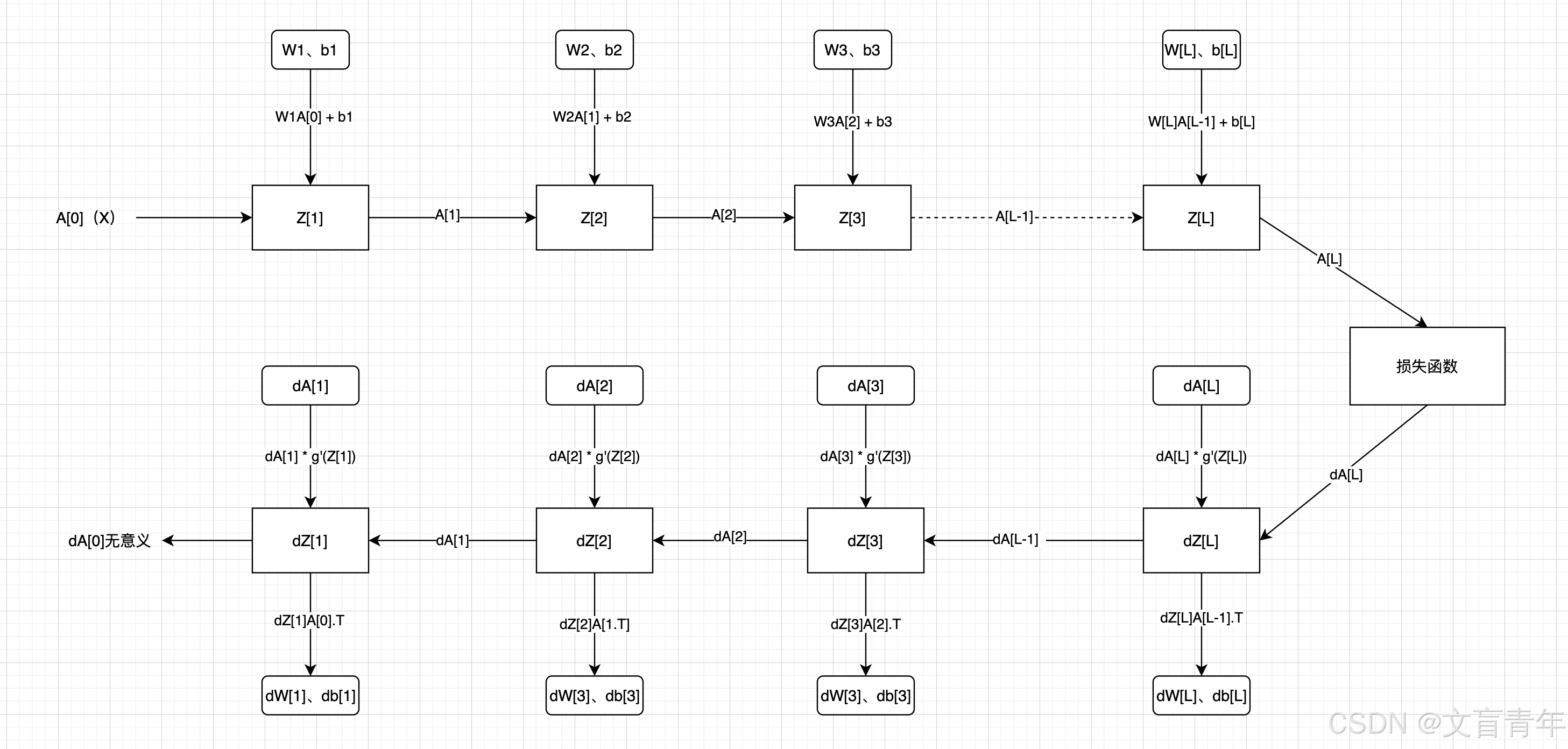
维度说明:
A[L]、Z[L]:(本层神经元个数、样本数)
W[L]:(本层神经元个数、上层神经元个数)
b[L]:(本层神经元个数、1)
dZ[L]:dA[L] * g’A(Z[L])
dZ[L]:(本层神经元个数、样本数)
dw = dL/dz * dz/dw = dz*x(链式法则)
db = dz(链式法则)
dW[L]:(本层神经元个数、上层神经元个数)
dA[L]:(本层神经元个数、样本数)
da = dz * w
dA[L-1] = W[L].T dZ[L],注意这里没有除以神经元个数,得到平均da。比如结果的第一个元素是多个dw1 * dz + dw1 * dz+ …dw1 * dz(神经元个数)的累加和
输出层采用sigmoid,隐藏层采用tanh
import numpy as np
# 设置一些画图相关的参数
import matplotlib.pyplot as pltplt.rcParams['figure.figsize'] = (5.0, 4.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
from project_03.utils.dnn_utils import *
from project_03.utils.testCases import *def load_dataset():train_dataset = h5py.File('../deep_learn_01/project_01/datasets/train_catvnoncat.h5', 'r')train_set_x_orig = np.array(train_dataset['train_set_x'][:])train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # 加载训练数据test_dataset = h5py.File('../deep_learn_01/project_01/datasets/test_catvnoncat.h5', "r") # 加载测试数据test_set_x_orig = np.array(test_dataset["test_set_x"][:])test_set_y_orig = np.array(test_dataset["test_set_y"][:])classes = np.array(test_dataset["list_classes"][:]) # 加载标签类别数据,这里的类别只有两种,1代表有猫,0代表无猫train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0])) # 把数组的维度从(209,)变成(1, 209),这样好方便后面进行计算[1 1 0 1] -> [[1][1][0][1]]test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0])) # 从(50,)变成(1, 50)return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classesdef sigmoid(Z):A = 1 / (1 + np.exp(-Z))return Adef relu(Z):A = np.maximum(0, Z)assert (A.shape == Z.shape)return Adef initialize_parameters_deep(layers_dims):""":param layers_dims: list of neuron numexample: layer_dims=[5,4,3],表示输入层有5个神经元,第一层有4个,最后二层有3个神经元(还有输出层的1个神经元):return: parameters: the w,b of each layer"""np.random.seed(1)parameters = {}L = len(layers_dims)for l in range(1, L):parameters[f"W{l}"] = np.random.randn(layers_dims[l], layers_dims[l - 1]) / np.sqrt(layers_dims[l - 1])parameters[f"b{l}"] = np.zeros((layers_dims[l], 1))assert (parameters[f"W{l}"].shape == (layers_dims[l], layers_dims[l - 1]))assert (parameters[f"b{l}"].shape == (layers_dims[l], 1))return parameters # W1,b1,W2,b2def linear_forward(A, W, b):"""线性前向传播"""Z = np.dot(W, A) + bassert (Z.shape == (W.shape[0], A.shape[1]))return Zdef linear_activation_forward(A_prev, W, b, activation):""":param A_prev: 上一层得到的A,输入到本层来计算本层的Z和A,第一层时A_prev就是输入X:param W:本层的w:param b:本层的b:param activation: 激活函数"""Z = linear_forward(A_prev, W, b)if activation == "sigmoid":A = sigmoid(Z)elif activation == "relu":A = relu(Z)else:assert (1 != 1), "there is no support activation!"assert (A.shape == (W.shape[0], A_prev.shape[1]))linear_cache = (A_prev, W, b)cache = (linear_cache, Z)return A, cachedef L_model_forward(X, parameters):"""前向传播:param X: 输入特征:param parameters: 每一层的初始化w,b"""caches = []A = XL = len(parameters) // 2 # W1,b1,W2,b2, L=2for l in range(1, L):A_prev = AA, cache = linear_activation_forward(A_prev, parameters[f"W{l}"], parameters[f"b{l}"], 'relu')caches.append(cache) # A1,(X,W1,b1,Z1)AL, cache = linear_activation_forward(A, parameters[f"W{L}"], parameters[f"b{L}"], activation="sigmoid")caches.append(cache) # A2,(A1,W2,b2,Z2)assert (AL.shape == (1, X.shape[1]))return AL, cachesdef compute_cost(AL, Y):m = Y.shape[1]logprobs = np.multiply(Y, np.log(AL)) + np.multiply((1 - Y), np.log(1 - AL))cost = (-1 / m) * np.sum(logprobs)assert (cost.shape == ())return costdef linear_backward(dZ, cache):""":param dZ: 后面一层的dZ:param cache: 前向传播保存下来的本层的变量:return 本层的dw、db,前一层da"""A_prew, W, b = cachem = A_prew.shape[1]dW = np.dot(dZ, A_prew.T) / mdb = np.sum(dZ, axis=1, keepdims=True) / mdA_prev = np.dot(W.T, dZ)assert (dA_prev.shape == A_prew.shape)assert (dW.shape == W.shape)assert (db.shape == b.shape)return dA_prev, dW, dbdef linear_activation_backward(dA, cache, activation):""":param dA: 本层的dA:param cache: 前向传播保存的本层的变量:param activation: 激活函数:"sigmoid"或"relu":return 本层的dw、db,前一次的dA"""linear_cache, Z = cache# 首先计算本层的dZif activation == 'relu':dZ = 1 * dAdZ[Z <= 0] = 0elif activation == 'sigmoid':A = sigmoid(Z)dZ = dA * A * (1 - A)else:assert (1 != 1), "there is no support activation!"assert (dZ.shape == Z.shape)# 这里我们又顺带根据本层的dZ算出本层的dW和db以及前一层的dAdA_prev, dW, db = linear_backward(dZ, linear_cache)return dA_prev, dW, dbdef L_model_backward(AL, Y, caches):""":param AL: 最后一层A:param Y: 真实标签:param caches: 前向传播的保存的每一层的相关变量 (A_prev, W, b),Z"""grads = {}L = len(caches) # 2Y = Y.reshape(AL.shape) # 让真实标签与预测标签的维度一致dAL = -np.divide(Y, AL) + np.divide(1 - Y, 1 - AL) # dA2# 计算最后一层的dW和db,由成本函数来计算current_cache = caches[-1] # 1,2grads[f"dA{L - 1}"], grads[f"dW{L}"], grads[f"db{L}"] = linear_activation_backward(dAL, current_cache,"sigmoid") # dA1, dW2, db2# 计算前L-1层的dw和db,因为最后一层用的是sigmoid,for c in reversed(range(1, L)): # reversed(range(1,L))的结果是L-1,L-2...1。是不包括L的。第0层是输入层,不必计算。 caches[0,1] L = 2 1,1# c表示当前层grads[f"dA{c - 1}"], grads[f"dW{c}"], grads[f"db{c}"] = linear_activation_backward(grads[f"dA{c}"],caches[c - 1],"relu")return gradsdef update_parameters(parameters, grads, learning_rate):L = len(parameters) // 2for l in range(1, L + 1):parameters[f"W{l}"] = parameters[f"W{l}"] - grads[f"dW{l}"] * learning_rateparameters[f"b{l}"] = parameters[f"b{l}"] - grads[f"db{l}"] * learning_ratereturn parametersdef dnn_model(X, Y, layers_dim, learning_rate=0.0075, num_iterations=3000, print_cost=False):np.random.seed(1)costs = []parameters = initialize_parameters_deep(layers_dim)for i in range(0, num_iterations):AL, caches = L_model_forward(X, parameters)cost = compute_cost(AL, Y)grads = L_model_backward(AL, Y, caches)parameters = update_parameters(parameters, grads, learning_rate)if print_cost and i % 100 == 0:print("训练%i次后成本是: %f" % (i, cost))costs.append(cost)# 画出成本曲线图plt.plot(np.squeeze(costs))plt.ylabel('cost')plt.xlabel('iterations (per tens)')plt.title("Learning rate =" + str(learning_rate))plt.show()return parametersdef predict(X, parameters):m = X.shape[1]n = len(parameters) // 2p = np.zeros((1, m))probas, caches = L_model_forward(X, parameters)# 将预测结果转化成0和1的形式,即大于0.5的就是1,否则就是0for i in range(0, probas.shape[1]):if probas[0, i] > 0.5:p[0, i] = 1else:p[0, i] = 0return pif __name__ == "__main__":train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()# 我们要清楚变量的维度,否则后面会出很多问题。下面我把他们的维度打印出来。train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).Ttest_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).Tprint("train_set_x_flatten shape: " + str(train_set_x_flatten.shape))print("test_set_x_flatten shape: " + str(test_set_x_flatten.shape))train_set_x = train_set_x_flatten / 255test_set_x = test_set_x_flatten / 255layers_dims = [12288, 20, 7, 5, 1]# 根据上面的层次信息来构建一个深度神经网络,并且用之前加载的数据集来训练这个神经网络,得出训练后的参数parameters = dnn_model(train_set_x, train_set_y, layers_dims, num_iterations=2000, print_cost=True)# 对训练数据集进行预测pred_train = predict(train_set_x, parameters)print("预测准确率是: " + str(np.sum((pred_train == train_set_y) / train_set_x.shape[1])))# 对测试数据集进行预测pred_test = predict(test_set_x, parameters)print("预测准确率是: " + str(np.sum((pred_test == test_set_y) / test_set_x.shape[1])))
相关文章:
深层神经网络示例
维度说明: A[L]、Z[L]:(本层神经元个数、样本数) W[L]:(本层神经元个数、上层神经元个数) b[L]:(本层神经元个数、1) dZ[L]:dA[L] * g’A…...

vue中获取剪切板中的内容
目录 1.说明 2.示例 3.总结 1.说明 在系统中的画面或者时外部文件中进行拷贝处理后,在页面中可以获取剪切板的内容。 2.示例 方式①(直接获取) // 异步函数获取剪切板内容 async function getClipboardContent(ev: any) {try {ev.preventDefault()const clip…...

十五、【机器学习】【监督学习】- 神经网络回归
系列文章目录 第一章 【机器学习】初识机器学习 第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression) 第三章 【机器学习】【监督学习】- 支持向量机 (SVM) 第四章【机器学习】【监督学习】- K-近邻算法 (K-NN) 第五章【机器学习】【监督学习】- 决策树…...

知识图谱和 LLM:利用Neo4j驾驭大型语言模型(探索真实用例)
这是关于 Neo4j 的 NaLLM 项目的一篇博客文章。这个项目是为了探索、开发和展示这些 LLM 与 Neo4j 结合的实际用途。 2023 年,ChatGPT 等大型语言模型 (LLM) 因其理解和生成类似人类的文本的能力而风靡全球。它们能够适应不同的对话环境、回答各种主题的问题,甚至模拟创意写…...

目标检测入门:4.目标检测中的一阶段模型和两阶段模型
在前面几章里,都只做了目标检测中的目标定位任务,并未做目标分类任务。目标检测作为计算机视觉领域的核心人物之一,旨在从图像中识别出所有感兴趣的目标,并确定它们的类别和位置。现在目标检测以一阶段模型和两阶段模型为代表的。…...

zookeeper+kafka消息队列群集部署
kafka拓扑架构 zookeeper拓扑架构...

[K8S]一、Flink on K8S
Kubernetes | Apache Flink 先编辑好这5个配置文件,然后再直接执行 kubectl create -f ./ kubectl get all kubectl get nodes kubectl get pods kubectl get pod -o wide kubectl get cm -- 获取所有的configmap 配置文件 kubectl logs pod_name -- 查看…...

系统架构设计师教程 第3章 信息系统基础知识-3.1 信息系统概述
系统架构设计师教程 第3章 信息系统基础知识-3.1 信息系统概述 3.1.1 信息系统的定义3.1.1.1 信息系统3.1.1.2 信息化3.1.2 信息系统的发展3.1.2.1 初始阶段3.1.2.2 传播阶段3.1.2.3 控制阶段3.1.2.4 集成阶段3.1.2.5 数据管理阶段3.1.2.6 成熟阶段3.1.3 信息系统的分类3.…...

Gemma的简单理解;Vertex AI的简单理解,与chatGpt区别
目录 Gemma的简单理解 Vertex AI的简单理解 Gemma Vertex AI Gemma Vertex AI和chatcpt区别 一、定义与功能 二、技术特点 三、应用场景 四、获取与部署 Gemma的简单理解 定义与功能: Gemma是谷歌开源的一款大语言模型,它采用了Gemini架构,并提供了20亿(2B)和7…...

Lua 数组
Lua 数组 Lua 是一种轻量级的编程语言,广泛用于游戏开发、脚本编写和其他应用程序。在 Lua 中,数组是一种非常基础和重要的数据结构。本文将详细介绍 Lua 数组的概念、用法和操作方法。 数组的概念 在 Lua 中,数组实际上是一个列表&#x…...

游戏中的敏感词算法初探
在游戏中起名和聊天需要服务器判断是否含有敏感词,从而拒绝或屏蔽敏感词显示,这里枚举一些常用的算法和实际效果。 1.字符串匹配算法 常用的有KMP,核心就是预处理出next数组,也就是失配信息,时间复杂度在O(mn) 。还有个…...

使用Java和Apache Kafka Streams实现实时流处理应用
使用Java和Apache Kafka Streams实现实时流处理应用 大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿! 引言 实时流处理已经成为现代应用开发中不可或缺的一部分。Apache Kafka Streams是一个强大的库…...

分享 .NET EF6 查询并返回树形结构数据的 2 个思路和具体实现方法
前言 树形结构是一种很常见的数据结构,类似于现实生活中的树的结构,具有根节点、父子关系和层级结构。 所谓根节点,就是整个树的起始节点。 节点则是树中的元素,每个节点可以有零个或多个子节点,节点按照层级排列&a…...

【柴油机故障诊断】基于斑马优化算法ZOA优化柴油机故障诊断附Matlab代码
% 柴油机故障诊断 - 基于斑马优化算法(Zebra Optimization Algorithm,ZOA)优化Transformer模型 % 代码示例仅为演示用途,实际应用中可能需要根据具体情况进行适当修改 % 初始化参数 maxIterations = 100; % 最大迭代次数 populationSize = 50; % 种群大小 % 斑马优化算法…...

C1W4.Assignment.Naive Machine Translation and LSH
理论课:C1W4.Machine Translation and Document Search 文章目录 1. The word embeddings data for English and French words1.1The dataThe subset of dataLoad two dictionaries 1.2 Generate embedding and transform matricesExercise 1: Translating English…...

智能听诊器:宠物健康监测的革新者
宠物健康护理领域迎来了一项激动人心的技术革新——智能听诊器。这款创新设备以其卓越的精确度和用户友好的操作,为宠物主人提供了一种全新的健康监测方法。 使用智能听诊器时,只需将其放置在宠物身上,它便能立即捕捉到宠物胸腔的微小振动。…...

001、Mac系统上Stable Diffusion WebUI环境搭建
一、目标 如标题所述,在苹果电脑(Mac)上搭建一套Stable Diffusion本地服务,以实现本地AI生图目的。 二、安装步骤 1、准备源码【等价于准备软件】 # 安装一系列工具库,包括cmake,protobuf,rust,python3.10,git,wge…...

k8s一些名词解释
潮汐计算 是一种根据负载变化动态调整资源分配的计算模式。其核心思想是利用峰值和非峰值时段的资源需求差异,动态地扩展或缩减计算资源。在 Kubernetes 环境中,可以通过自动扩展(auto-scaling)机制,根据工作负载的变化自动调整计算资源,最大化资源利用率并减少不必要的…...

ArkUI组件——循环控制/List
循环控制 class Item{name: stringprice:number}private items:Array<Item> [new Item("A0",2399),new Item("BE",1999),new Item("Ro",2799)] ForEach(this.items,(item:Item) > {})List组件 列表List是一种复杂的容器,…...

定制开发AI智能名片商城微信小程序在私域流量池构建中的应用与策略
摘要 在数字经济蓬勃发展的今天,私域流量已成为企业竞争的新战场。定制开发AI智能名片商城微信小程序,作为私域流量池构建的创新工具,正以其独特的优势助力企业实现用户资源的深度挖掘与高效转化。本文深入探讨了定制开发AI智能名片商城微信…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...