神经网络中如何优化模型和超参数调优(案例为tensor的预测)
总结:
初级:简单修改一下超参数,效果一般般但是够用,有时候甚至直接不够用
中级:optuna得出最好的超参数之后,再多一些epoch让train和testloss整体下降,然后结果就很不错。
高级:在中级的基础上,更换更适合的损失函数之后,在train的时候backward反向传播这个loss,optuna也更改这个loss标准,现在效果有质的改变。
问题:
最近在做cfd领域,需要流场进行预测,然后流场提取出来再深度学习就是一个多维度tensor,而神经网络的目的就是通过模型预测让预测的tensor与实际的tensor的结果尽可能的接近,具体来说就是让每个值之间的误差尽可能小。
目前情况:现在模型大概以及确定,但是效果一般般,这时候就需要进行下面的调优方法。
优化方法:
一、初级优化:
简单修改一下超参数,效果一般般但是够用,有时候甚至直接不够用

二、中级优化:optuna调参,然后epoch加多
optuna得出最好的超参数之后,再多一些epoch让train和testloss整体下降,然后结果就很不错。

三、高级优化:
在中级的基础上,现在更换更适合的损失函数之后,在train的时候backward反向传播这个loss,optuna也更改这个loss标准,现在效果有质的改变。
也就是下面这三行代码
smooth_l1 = F.smooth_l1_loss(out.view(shape1, shape2), y.view(shape1, shape2))#!!!!!!!!!!!!!
smooth_l1.backward() #用这个smooth_l1_loss反向传播#!!!!!!!!!!!!!!!!!!!!!!!!!
return test_smooth_l1 #test中的最后一个epoch的test_smooth_l1!!!!!!!!!!!!!!!!!!!!!!!!!!!!!


通过上面预测的数据和实际的数据进行的对比,可以发现预测的每个结果与实际的结果的误差在大约0.01范围之内(实际数据在[-4,4]之间)。
确定损失函数:
要让两个矩阵的值尽可能接近,选择合适的损失函数(loss function)是关键。常见的用于这种目的的损失函数包括以下几种:
-
均方误差(Mean Squared Error, MSE):对预测值与真实值之间的平方误差求平均。MSE对大误差比较敏感,能够显著惩罚偏离较大的预测值。
import torch.nn.functional as F loss = F.mse_loss(predicted, target) -
平均绝对误差(Mean Absolute Error, MAE):对预测值与真实值之间的绝对误差求平均。MAE对异常值不如MSE敏感,适用于数据中存在异常值的情况。
import torch loss = torch.mean(torch.abs(predicted - target)) -
平滑L1损失(Smooth L1 Loss):又称Huber Loss,当误差较小时,平滑L1损失类似于L1损失,当误差较大时,类似于L2损失。适合在有噪声的数据集上使用。
import torch.nn.functional as F loss = F.smooth_l1_loss(predicted, target)总结如下:
-
MSE:适用于需要显著惩罚大偏差的情况。
- MAE:适用于数据中存在异常值,并且你希望对异常值不那么敏感的情况。
- Smooth L1 Loss:适用于既有一定抗噪声能力又能对大偏差适当惩罚的情况。
这里根据任务选择Smooth L1 Loss。
具体做法:
目前这个经过optuna调优,然后先下面处理(思想是将loss的反向传播和optuna优化标准全换为更适合这个任务的smooth_l1_loss函数)
- 1. loss将mse更换为smooth_l1_loss,
- 2. l2.backward()更换为smooth_l1.backward(),
- 3. return test_l2更改为return test_smooth_l1
结果:point_data看着值很接近,每个值误差0.01范围内。说明用这个上面这个方法是对的。试了一下图也有优化。并step_loss现在极低。
下面代码中加感叹号的行都是上面思路修改我的项目中对应的代码行,重要!!!
import optuna
import time
import torch.optim as optim
# 求解loss的两个参数
shape1 = -1
shape2 = data.shape[1]* 3def objective1(trial):batch_size = trial.suggest_categorical('batch_size', [32])learning_rate = trial.suggest_float('learning_rate', 1e-6, 1e-2,log=True)layers = trial.suggest_categorical('layers', [2,4,6])width = trial.suggest_categorical('width', [10,20,30])#新加的weight_decay = trial.suggest_float('weight_decay', 1e-6, 1e-2,log=True)#新加的#再加个优化器optimizer_name = trial.suggest_categorical('optimizer', ['Adam', 'SGD', 'RMSprop'])# loss_function_name = trial.suggest_categorical('loss_function', ['LpLoss', 'MSELoss'])""" Read data """# data是[1991, 80, 40, 30],而data_cp是为归一化的[2000, 80, 40, 30]train_a = data[ntest:-1,:,:]#data:torch.Size:50:, 80, 40, 30。train50对应的是predict50+9+1train_u = data_cp[ntest+10:,:,:]#torch.Size([50, 64, 64, 10])#data_cp是未归一化的,第11个对应的是data的第data的第1个,两者差10# print(train_a.shape)# print(train_u.shape)test_a = data[:ntest,:,:]#选取最后200个当测试集test_u = data_cp[10:ntest+10,:,:]# print(test_a.shape)# print(test_u.shape)#torch.Size([40, 80, 40, 3])train_loader = torch.utils.data.DataLoader(torch.utils.data.TensorDataset(train_a, train_u),batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(torch.utils.data.TensorDataset(test_a, test_u),batch_size=batch_size, shuffle=False)#没有随机的train_loader,用于后面预测可视化data_loader_noshuffle = torch.utils.data.DataLoader(torch.utils.data.TensorDataset(data[:,:,:], data_cp[9:,:,:]),batch_size=batch_size, shuffle=False)# %%""" The model definition """device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = WNO1d(width=width, level=level, layers=layers, size=h, wavelet=wavelet,in_channel=in_channel, grid_range=grid_range).to(device)# print(count_params(model))# optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-6)#调参数用,优化器选择if optimizer_name == 'Adam':optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)elif optimizer_name == 'SGD':optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=weight_decay, momentum=0.9)else: # RMSpropoptimizer = optim.RMSprop(model.parameters(), lr=learning_rate, weight_decay=weight_decay)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma)train_loss = torch.zeros(epochs)test_loss = torch.zeros(epochs)myloss = LpLoss(size_average=False)""" Training and testing """for ep in range(epochs):model.train()t1 = default_timer()train_mse = 0train_l2 = 0for x, y in train_loader:x, y = x.to(device), y.to(device)optimizer.zero_grad()out = model(x)mse = F.mse_loss(out.view(shape1, shape2), y.view(shape1, shape2))# # 训练时使用 Smooth L1 Losssmooth_l1 = F.smooth_l1_loss(out.view(shape1, shape2), y.view(shape1, shape2))#!!!!!!!!!!!!!l2 = myloss(out.view(shape1, shape2), y.view(shape1, shape2))# l2.backward()smooth_l1.backward() #用这个smooth_l1_loss反向传播#!!!!!!!!!!!!!!!!!!!!!!!!!optimizer.step()train_mse += mse.item()train_l2 += l2.item()scheduler.step()model.eval()test_l2 = 0.0test_smooth_l1 =0with torch.no_grad():for x, y in test_loader:x, y = x.to(device), y.to(device)out = model(x)test_l2 += myloss(out.view(shape1, shape2), y.view(shape1, shape2)).item()test_smooth_l1 +=F.smooth_l1_loss(out.view(shape1, shape2), y.view(shape1, shape2)).item()#!!!!!!!!!!!!!!!!!!train_mse /= ntrain#len(train_loader)train_l2 /= ntraintest_l2 /= ntesttest_smooth_l1 /= ntest#!!!!!!!!!!!!!!!!!!!train_loss[ep] = train_l2test_loss[ep] = test_l2t2 = default_timer()print('Epoch-{}, Time-{:0.4f}, [step_loss:] -> Train-MSE-{:0.4f},test_smooth_l1-{:0.4f} Train-L2-{:0.4f}, Test-L2-{:0.4f}'.format(ep, t2-t1, train_mse,test_smooth_l1, train_l2, test_l2))#!!!!!!!!!!!!!!!!1if trial.should_prune():raise optuna.exceptions.TrialPruned()"""防止打印信息错位"""print(f"Trial {trial.number} finished with value: {test_l2}")return test_smooth_l1 #test中的最后一个epoch的test_smooth_l1!!!!!!!!!!!!!!!!!!!!!!!!!!!!!""" For saving the trained model and prediction data """
相关文章:
神经网络中如何优化模型和超参数调优(案例为tensor的预测)
总结: 初级:简单修改一下超参数,效果一般般但是够用,有时候甚至直接不够用 中级:optuna得出最好的超参数之后,再多一些epoch让train和testloss整体下降,然后结果就很不错。 高级:…...

使用AJAX发起一个异步请求,从【api_endpoint】获取数据,并在成功时更新页面上的【target_element】
使用AJAX发起一个异步请求,从【api_endpoint】获取数据,并在成功时更新页面上的【target_element】 在Web开发中,使用AJAX(Asynchronous JavaScript and XML,异步JavaScript和XML)可以实现在不刷新整个页面…...

【AI绘画教程】Stable Diffusion 1.5 vs 2
在本文中,我们将总结稳定扩散 1 与稳定扩散 2 辩论中的所有要点。我们将在第一部分中查看这些差异存在的实际原因,但如果您想直接了解实际差异,您可以跳下否定提示部分。让我们开始吧! Stable Diffusion 2.1 发布与1.5相比&#x…...

纯前端小游戏,4096小游戏,有音效,Html5,可学习使用
// 游戏开始运行create: function(){this.fieldArray [];this.fieldGroup this.add.group();this.score 0;//4096 增加得分this.bestScore localStorage.getItem(gameOptions.localStorageName) null ? 0 : localStorage.getItem(gameOptions.localStorageName);for(var …...

ROS、pix4、gazebo、qgc仿真ubuntu20.04
一、ubuntu、ros安装教程比较多,此文章不做详细讲解。该文章基于ubuntu20.04系统。 pix4参考地址:https://docs.px4.io/main/zh/index.html 二、安装pix4 1. git clone https://github.com/PX4/PX4-Autopilot.git --recursive 2. bash ./PX4-Autopilot…...

qt 国际化语言,英文和中文切换
1、把需要翻译转换的内用用tr()包含,比如: label->setText("hello word"); 2、在 .pro 文件中添加 TRANSLATIONS lang_en.ts \ lang_zn.ts 3、利用lupdate 工具提取…...

机器学习入门【经典的CIFAR10分类】
模型 神经网络采用下图 我使用之后发现迭代多了之后一直最高是正确率65%左右,然后我自己添加了一些Relu激活函数和正则化,现在正确率可以有80%左右。 模型代码 import torch from torch import nnclass YmModel(nn.Module):def __init__(self):super(…...

01 安装
安装和卸载中,用户全部切换为root,一旦安装,普通用户也能使用 初期不进行用户管理,全部用root进行,使用mysql语句 1. 卸载内置环境 检查是否有mariadb存在,存在走a部分卸载 ps axj | grep mysql ps ajx |…...

AI 模型本地推理 - YYPOLOE - Python - Windows - GPU - 吸烟检测(目标检测)- 有配套资源直接上手实现
Python 运行 - GPU 推理 - windows 环境准备python 代码 环境准备 FastDeploy预编译库下载 conda config --add channels conda-forge && conda install cudatoolkit11.2 cudnn8.2 pip install fastdeploy_gpu_python-0.0.0-cp38-cp38-win_amd64.whlpython 代码 impo…...

全国媒体邀约,主流媒体到场出席采访报道
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 全国媒体邀约,确保主流媒体到场出席采访报道,可以带来一系列的好处,这些好处不仅能够增强活动的可见度,还能对品牌或组织的长期形象产生积…...

计算机视觉8 图像增广
图像增广(image augmentation)是通过对训练图像进行一系列随机改变,从而产生相似但又不同的训练样本的技术。 图像增广有以下两个主要作用: 扩大训练数据集的规模;随机改变训练样本可以降低模型对某些属性的依赖&#…...
Transformer中的自注意力是怎么实现的?
在Transformer模型中,自注意力(Self-Attention)是核心组件,用于捕捉输入序列中不同位置之间的关系。自注意力机制通过计算每个标记与其他所有标记之间的注意力权重,然后根据这些权重对输入序列进行加权求和,…...
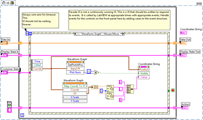
LabVIEW鼠标悬停在波形图上的曲线来自动显示相应点的坐标
步骤 创建事件结构: 打开LabVIEW,创建一个新的VI。 在前面板上添加一个Waveform Graph控件。 在后面板上添加一个While Loop和一个事件结构(Event Structure)。 配置事件结构,选择Waveform Graph作为事件源…...

操作系统发展简史(Unix/Linux 篇 + DOS/Windows 篇)+ Mac 与 Microsoft 之风云争霸
操作系统发展简史(Unix/Linux 篇) 说到操作系统,大家都不会陌生。我们天天都在接触操作系统 —— 用台式机或笔记本电脑,使用的是 windows 和 macOS 系统;用手机、平板电脑,则是 android(安卓&…...

钡铼分布式 IO 系统 OPC UA边缘计算耦合器BL205
深圳钡铼技术推出的BL205耦合器支持OPC UA Server功能,以服务器形式对外提供数据。符合IEC 62541工业自动化统一架构通讯标准,数据可以选择加密(X.509证书)、身份验证方式传送。 安全策略支持basic128rsa15、basic256、basic256s…...

实现了一个心理测试的小程序,微信小程序学习使用问题总结
1. 如何在跳转页面中传递参数 ,在 onLoad 方法中通过 options 接收 2. radio 如何获取选中的值? bindchange 方法 参数e, e.detail.value 。 如果想要获取其他属性,使用data-xx 指定,然后 e.target.dataset.xx 获取。 3. 不刷…...

vue是如何进行监听数据变化的?vue2和vue3分别是什么?vue3为什么要更换?
Vue如何进行监听数据变化的? Vue.js 通过其响应式系统来监听数据变化。这个系统允许你声明式地将数据和 DOM 绑定,一旦数据发生变化,相关的 DOM 将自动更新。Vue 使用以下机制来实现数据的监听和响应: 响应式数据:在 …...

数据结构day3
一、思维导图 二、 #include "seqlist.h"#include<myhead.h> int main(int argc, const char *argv[]) {//创建一个顺序表SeqListPtr L list_create();if(NULL L){return -1;}//调用添加函数list_add(L,123);list_add(L,435);list_add(L,856);list_add(L,65…...

免费的数字孪生平台助力产业创新,让新质生产力概念有据可依
关于新质生产力的概念,在如今传统企业现代化发展中被反复提及。 那到底什么是新质生产力?它与哪些行业存在联系,我们又该使用什么工具来加快新质生产力的发展呢?今天我将介绍一款为发展新质生产力而量身定做的数字孪生工具。 新…...

mtsys2 编译 qemu 记录
参考链接 下载 MSYS2 MSYS2 MSYS2 换源 进入目录\msys64\etc\pacman.d, 在文件mirrorlist.msys的前面插入 Server http://mirrors.ustc.edu.cn/msys2/msys/$arch在文件mirrorlist.mingw32的前面插入 Server http://mirrors.ustc.edu.cn/msys2/mingw/i686在…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...