Mac M1安装配置Hadoop+Flink SQL环境
Flink 1.18.1+ Hadoop 3.4.0
一、准备工作
系统:Mac M1 (MacOS Sonoma 14.3.1)
JDK:jdk1.8.0_381 (注意:尽量一定要用JDK8,少用高版本)
Scala:2.12
JDK安装在本机的/opt/jdk1.8.0_381.jdk/Contents/Home下,Scala安装在/opt/scala-2.12.10下,并在.bash_profile中已配置好环境变量
export JAVA_HOME=/opt/jdk1.8.0_381.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATHexport SCALA_HOME=/opt/scala-2.12.10
export PATH=$SCALA_HOME/bin:$PATH二、安装Hadoop
单纯运行Flink的话没必要安装Hadoop环境,但为了在Flink SQL中使用Hive数仓的话,还是得安装Hadoop基础环境。
2.1 下载解压
下载Hadoop 3.4.0(截止当前的最新版本)
国内镜像地址:Index of /apache/hadoop/common
将下载后的hadoop-3.4.0.tar.gz放到/opt下直接双击进行解压,如下:

2.2 配置Hadoop环境变量
打开.bash_profile(Mac下可用文本编辑器打开编辑),添加如下变量
export HADOOP_HOME=/opt/hadoop-3.4.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"保存使之生效:
source ~/.bash_profile2.3 配置Hadoop配置文件
1. 编辑hadoop-env.sh
打开/opt/hadoop-3.4.0/etc/hadoop/hadoop-env.sh,添加一行:
export JAVA_HOME=/opt/jdk1.8.0_381.jdk/Contents/Home2. 编辑core-site.xml
打开/opt/hadoop-3.4.0/etc/hadoop/core-site.xml,在<configuration>中添加如下配置:
<configuration><property><name>hadoop.tmp.dir</name><value>/opt/hdfs/tmp/</value></property><property><name>fs.default.name</name><value>hdfs://127.0.0.1:9000</value></property>
</configuration>其中/opt/hdfs/tmp为自定义的HDFS路径。
3. 编辑hdfs-site.xml
打开/opt/hadoop-3.4.0/etc/hadoop/hdfs-site.xml,在<configuration>中添加如下配置:
<configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>4. 编辑mapred-site.xml
打开/opt/hadoop-3.4.0/etc/hadoop/mapred-site.xml,在<configuration>中添加如下配置:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>5. 编辑yarn-site.xml
打开/opt/hadoop-3.4.0/etc/hadoop/yarn-site.xml,在<configuration>中添加如下配置:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.hostname</name><value>127.0.0.1</value></property><property><name>yarn.acl.enable</name><value>0</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>2.4 配置其他工具类jar包(使用Flink SQL时才需要配置)
下载高版本jline,替换原来的旧版本,例如下载:jline-3.26.2.jar
下载地址:https://mvnrepository.com/artifact/org.jline/jline/3.26.2
将其分别放到:
/opt/hadoop-3.4.0/share/hadoop/hdfs/lib
/opt/hadoop-3.4.0/share/hadoop/yarn/lib
这两个目录下,并将原有的jline-3.9.0.jar删掉。
注意:该配置只为了解决Flink SQL使用过程中的jar包报错问题,即Hadoop自带的jline版本太低,无法适配高版本flink,如果单纯只使用Hadoop或是Spark的能力,无需进行该配置。
2.5 设置SSH免密登录
在个人目录下输入以下命令:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/id_rsa.pub中间问是否覆盖此前的ssh,选择Y:

三、启动Hadoop
首次启动Hadoop之前必须进行Namenode格式化(以后不需要):
cd /opt/hadoop-3.4.0/sbin
hdfs namenode -format
输出如下日志信息:

运行start-all.sh直接启动,包含了启动start-dfs.sh和start-yarn.sh。出现如下信息表示启动成功:

在浏览器中输入:http://localhost:9870/
显示如下:

至此,Hadoop已正常启动。
注:关闭命令为:stop-all.sh
四、配置Flink
当前Flink最新版本为1.19.1,但目前的1.19版本仍未支持Iceberg runtime,考虑到后续可能会使用Iceberg数据湖,因此选择Flink 1.18.1。
Multi-Engine Support - Apache Iceberg

4.1 配置Flink环境变量
下载Flink 1.18.1
下载地址:Downloads | Apache Flink
将下载好的flink-1.18.1-bin-scala_2.12.tgz放到/opt下,双击进行解压。
配置环境变量,打开.bash_profile,添加如下行:
export PATH=/opt/flink-1.18.1/bin:$PATH使之生效:
source ~/.bash_profile注意:Mac里也可以在~/.zshrc中配置。
4.2 配置Flink 其他jar包(和hive/iceberg适配连接)
注意选择适配flink 1.18.1版本的jar包。
下载commons-cli-1.8.0.jar
地址:https://mvnrepository.com/artifact/commons-cli/commons-cli/1.8.0
下载flink-connector-hive_2.12-1.18.1.jar
地址:https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.18.1/
下载flink-sql-connector-hive-3.1.3_2.12-1.18.1.jar
地址:https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.3_2.12/1.18.1/
下载hive-exec-3.1.3.jar
地址:https://mvnrepository.com/artifact/org.apache.hive/hive-exec/3.1.3
下载iceberg-flink-runtime-1.18-1.5.2.jar
地址:https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-flink-runtime-1.18/1.5.2/
下载iceberg-hive-runtime-1.5.2.jar
地址:https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-hive-runtime/1.5.2/
以上jar包下载完后放到/opt/flink-1.18.1/lib下。

五、运行Flink SQL
5.1 启动Flink
运行以下命令:
cd /opt/flink-1.18.1
./bin/start-cluster.sh输出如下信息:

在浏览器中打开:http://localhost:8081/
可以看到如下信息:

注:关闭flink的命令为:
./bin/stop-cluster.sh5.2 启动Flink SQL
输入:
./bin/sql-client.sh embedded shell看到如下信息表示启动成功:

可能会有如下警告信息,可忽略,原因为log4j jar包存在冲突。
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink-1.18.1/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop-3.4.0/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
查看当前的catalogs:
show catalogs;注:Catalog 是一个元数据存储,它提供了一种集中的方式来管理元数据信息,Catalog 存储了 Flink 中使用的所有元数据,包括表结构、分区信息、用户定义函数等。对于一个数据表的定位是 catalog名.数据库名.表名。因此首先需要创建一个 Catalog,然后在 Catalog 中创建数据库,最后在数据库中创建表。
输出:

默认只有1个default_catalog。
创建新的catalog:
CREATE CATALOG hive_catalog WITH ('type'='iceberg','catalog-type'='hive','uri'='thrift://localhost:9083','clients'='5','property-version'='1','warehouse'='file:///opt/warehouse/iceberg-hive-catalog'
);注意设置“warehouse”为自己的路径,别的不用改。
查看catalogs:
show catalogs;输出:

显示新的catalog创建成功了。
若要退出Flink SQL直接输入:
exit;六、相关问题
1. Hadoop启动yarn时报错。控制台错误信息:
Starting resourcemanager ERROR: Cannot set priority of resourcemanager process 20248
在/opt/hadoop-3.4.0/logs查看相关日志,具体报错信息为:
2024-07-11 10:01:08,633 ERROR org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Error starting ResourceManager
java.lang.ExceptionInInitializerError
at com.google.inject.internal.cglib.reflect.$FastClassEmitter.<init>(FastClassEmitter.java:67)
at com.google.inject.internal.cglib.reflect.$FastClass$Generator.generateClass(FastClass.java:72)
at com.google.inject.internal.cglib.core.$DefaultGeneratorStrategy.generate(DefaultGeneratorStrategy.java:25)
at com.google.inject.internal.cglib.core.$AbstractClassGenerator.create(AbstractClassGenerator.java:216)
at com.google.inject.internal.cglib.reflect.$FastClass$Generator.create(FastClass.java:64)
at com.google.inject.internal.BytecodeGen.newFastClass(BytecodeGen.java:204)
at com.google.inject.internal.ProviderMethod$FastClassProviderMethod.<init>(ProviderMethod.java:256)
at com.google.inject.internal.ProviderMethod.create(ProviderMethod.java:71)
at com.google.inject.internal.ProviderMethodsModule.createProviderMethod(ProviderMethodsModule.java:275)
at com.google.inject.internal.ProviderMethodsModule.getProviderMethods(ProviderMethodsModule.java:144)
at com.google.inject.internal.ProviderMethodsModule.configure(ProviderMethodsModule.java:123)
at com.google.inject.spi.Elements$RecordingBinder.install(Elements.java:340)
at com.google.inject.spi.Elements$RecordingBinder.install(Elements.java:349)
at com.google.inject.AbstractModule.install(AbstractModule.java:122)
at com.google.inject.servlet.ServletModule.configure(ServletModule.java:49)
at com.google.inject.AbstractModule.configure(AbstractModule.java:62)
at com.google.inject.spi.Elements$RecordingBinder.install(Elements.java:340)
at com.google.inject.spi.Elements.getElements(Elements.java:110)
at com.google.inject.internal.InjectorShell$Builder.build(InjectorShell.java:138)
at com.google.inject.internal.InternalInjectorCreator.build(InternalInjectorCreator.java:104)
at com.google.inject.Guice.createInjector(Guice.java:96)
at com.google.inject.Guice.createInjector(Guice.java:73)
at com.google.inject.Guice.createInjector(Guice.java:62)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.build(WebApps.java:420)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:468)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1486)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1599)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:195)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1801)
Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain) throws java.lang.ClassFormatError accessible: module java.base does not "opens java.lang" to unnamed module @6cc27570
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:354)
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at java.base/java.lang.reflect.Method.checkCanSetAccessible(Method.java:199)
at java.base/java.lang.reflect.Method.setAccessible(Method.java:193)
at com.google.inject.internal.cglib.core.$ReflectUtils$2.run(ReflectUtils.java:56)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:318)
at com.google.inject.internal.cglib.core.$ReflectUtils.<clinit>(ReflectUtils.java:46)
... 29 more
原因:JDK版本太高,笔者之前装的是JDK 17。
解决方案:换成JDK 8,一切正常。试了网上别的一些解决方案,都不奏效。
2. Flink SQL执行时报错:
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration

原因:Hadoop环境变量配置有误。
解决方案:参考2.2配置Hadoop环境变量。
注:无需配置一个名称为HADOOP_CLASSPATH的变量。
注:网上另有一种方案是将flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar放到flink lib目录下,由于我们是自己单独配置了Hadoop环境,因此无需下载该jar包。
地址:https://mvnrepository.com/artifact/org.apache.flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0
3. Flink SQL启动报错:
Caused by: java.lang.ExceptionInInitializerError: Exception java.lang.NoSuchMethodError: org.jline.utils.AttributedStyle.foreground(III)Lorg/jline/utils/AttributedStyle; [in thread "main"]
at org.apache.flink.table.client.cli.parser.SyntaxHighlightStyle$BuiltInStyle.<clinit>(SyntaxHighlightStyle.java:57)
at org.apache.flink.table.client.config.SqlClientOptions.<clinit>(SqlClientOptions.java:76)
at org.apache.flink.table.client.cli.parser.SqlClientSyntaxHighlighter.highlight(SqlClientSyntaxHighlighter.java:59)
at org.jline.reader.impl.LineReaderImpl.getHighlightedBuffer(LineReaderImpl.java:3633)
at org.jline.reader.impl.LineReaderImpl.getDisplayedBufferWithPrompts(LineReaderImpl.java:3615)
at org.jline.reader.impl.LineReaderImpl.redisplay(LineReaderImpl.java:3554)
at org.jline.reader.impl.LineReaderImpl.redisplay(LineReaderImpl.java:3493)
at org.jline.reader.impl.LineReaderImpl.readLine(LineReaderImpl.java:549)

原因:jline版本太低。
解决方案:参考2.4配置相关jar包。
4. Flink SQL执行报错:
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.hive.metastore.api.NoSuchObjectException

原因:缺hive相关jar包,尤其是hive-exec-3.1.3.jar。
解决方案:参考4.2配置相关jar包。
参考:
Hadoop 安装教程 (Mac m1/m2版)_m1 安装hadoop-CSDN博客
https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/connectors/table/hive/overview/
Flink集成Iceberg小小实战-腾讯云开发者社区-腾讯云
相关文章:
Mac M1安装配置Hadoop+Flink SQL环境
Flink 1.18.1 Hadoop 3.4.0 一、准备工作 系统:Mac M1 (MacOS Sonoma 14.3.1) JDK:jdk1.8.0_381 (注意:尽量一定要用JDK8,少用高版本) Scala:2.12 JDK安装在本机的/opt/jdk1.8.0_381.jdk/C…...

【所谓生活】马太效应
简介 马太效应又称马太定律或两级分化现象。该效应描述的是在社会生活中,强者因为优势而获得更多机会,而弱者因劣势而失去机会,最终导致强者愈强、弱者愈弱的现象。这一概念最早由美国社会学家罗伯特莫顿于1968年提出,其名字来源…...
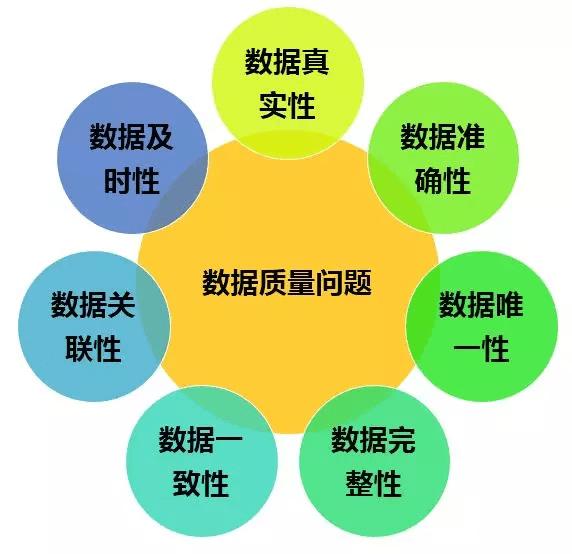
品牌进行电商数据采集的流程
品牌在进行数据分析与渠道管控时,均离不开电商数据的有力支撑,故而数据采集的质量举足轻重。电商数据采集首先要确保准确率,其次要保障覆盖率,即页面上呈现的商品信息必须采集完整,否则难以得出精确的数据分析成果&…...

面试问题:React基本概念,和所遇到的CPU和IO问题
在官方文档里面可以看见React基本设计概念,React是用 JavaScrip构建快速响应的大型Web应用程序的首选方式,但是快速响应用一定的是依赖,CPU的性能和IO的约束。 首先CPU性能原因:大部分浏览器的刷新频率为60HZ,及16.6ms…...

FOG Project 文件名命令注入漏洞复现(CVE-2024-39914)
0x01 产品简介 FOG是一个开源的计算机镜像解决方案,旨在帮助管理员轻松地部署、维护和克隆大量计算机。FOG Project 提供了一套功能强大的工具,使用户能够快速部署操作系统、软件和配置设置到多台计算机上,从而节省时间和精力。该项目支持基于网络的 PXE 启动、镜像创建和还…...

JavaScript 表单
JavaScript 表单 JavaScript 是一种广泛应用于网页开发的编程语言,它能够让网页变得更加动态和交互式。在网页设计中,表单是一个重要的组成部分,它允许用户输入数据并将其提交到服务器。JavaScript 可以用来增强表单的功能,提供更好的用户体验。本文将详细介绍如何使用 Ja…...

python程序设定定时任务
在 Windows 系统上,您可以使用任务计划程序(Task Scheduler)来设置定时任务,执行 Python 文件。以下是具体步骤: 步骤 1:准备 Python 文件 假设有一个名为 script.py 的 Python 脚本。确保它可以在命令行中正确运行。 步骤2:找到Python可执行文件的位置 知道Python可…...

win10 查看 jks 的公钥
1.使用 keytool 导出jks文件的 crt 文件 先查询别名 keytool -list -keystore oauth2.jks -storepass [你的密钥库密码] 导出crt 文件 keytool -exportcert -alias oauth2 -keystore oauth2.jks -file 777.crt 2.查看公钥 打开PowerShell # 设置.crt文件的路径 $ce…...

蓝牙模块在智能体育设备中的创新应用
随着科技的飞速发展,智能体育设备已经成为现代体育训练和健身的重要组成部分。蓝牙模块作为智能体育设备中的核心技术之一,其创新应用不仅提升了设备的智能化水平,也为运动员和健身爱好者带来了前所未有的便利和体验。本文将探讨蓝牙模块在智…...

智能家居和智能家电有什么区别?
智能家居和智能家电在定义、涵盖范围、功能特点以及系统集成度等方面存在显著区别。 一、定义 智能家居:智能家居是指通过物联网技术、人工智能技术等先进技术,将家居设备与互联网连接起来,实现智能化控制和管理的一种新型生活方式。它不仅…...
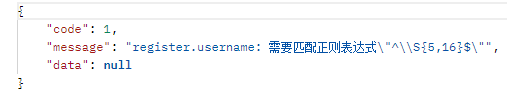
SpringBoot3 + Vue3 学习 Day 1
springboot 基础 和 注册接口的开发 学习视频基础SpringBoot 概述快速启动配置文件基本使用① application.properties② application.yml (更好) yml 配置信息的书写和获取yml 配置信息书写与获取 1 - Valueyml 配置信息书写与获取 2 - ConfigurationPr…...

如何使用在线工具将手机相册中的图片转换为JPG格式
我们经常在手机相册中保存大量的图片,无论是家庭聚会的照片还是旅行的瞬间,每一幅图像都承载着珍贵的记忆。然而,有时候我们会遇到图片格式不兼容的问题,尤其是在需要将图片分享到特定平台或编辑时。 例如,某些社交平台…...

C#医学影像管理系统源码(VS2013)
目录 一、概述 二、系统功能 系统维护 工作站 三、功能介绍 影像采集 统计模块 专业阅片 采集诊断报告 报告管理 一、概述 医学影像存储与传输系统(PACS)是一种集成了影像存储、传输、管理和诊断功能的系统。它基于数字化成像技术、计算机技术和…...

Qt Creator 项目Console 项目踩坑日记
最近在做QT的项目,但是一直是带界面(QT Widgets)程序,前几天收到个需求,是要做个socket服务端的桌面程序,界面有没有都成,然后就想着接着用 QT Widgets 搞,结果辛辛苦苦把socket服…...

[MAUI 项目实战] 笔记App(一):程序设计
文章目录 前言框架定义核心类项目地址 系列文章: [MAUI 项目实战] 笔记App(一):程序设计 [MAUI 项目实战] 笔记App(二):数据库设计 前言 有人说现在记事类app这么多,市场这么卷&a…...

VisualRules-Web案例展示(一)
VisualRules单机版以其卓越的功能深受用户喜爱。现在,我们进一步推出了VisualRules-Web在线版本,让您无需安装任何软件,即可在任何浏览器中轻松体验VisualRules的强大功能。无论是数据分析、规则管理还是自动化决策,VisualRules-W…...

使用Docker 实现 MySQL 循环复制(三)
系列文章 使用Docker 实现 MySQL 循环复制(一) 使用Docker 实现 MySQL 循环复制(二) 目录 系列文章1. 在主机上安装MySQL客户端2. 配置循环复制拓扑2.1 进入容器2.2 创建复制用户并授予复制权限2.3 复位二进制日志2.4 配置环形复…...

Spring如何管理Mapper
目录 一、背景二、猜测三、源码查看步骤1、创建MapperScannerConfigurer.java2、MapperScan注解3、MapperScannerRegistrar执行registerBeanDefinitions方法4、MapperScannerConfigurer执行postProcessBeanDefinitionRegistry方法5、执行doscan6、设置beanClass7、使用jdk生成代…...

NFS存储、API资源对象StorageClass、Ceph存储-搭建ceph集群和Ceph存储-在k8s里使用ceph(2024-07-16)
一、NFS存储 注意:在做本章节示例时,需要拿单独一台机器来部署NFS,具体步骤略。NFS作为常用的网络文件系统,在多机之间共享文件的场景下用途广泛,毕竟NFS配置方 便,而且稳定可靠。NFS同样也有一些缺点&…...

「Vue组件化」封装i18n国际化
前言 在Vue应用中实现国际化(i18n),通常需要使用一些专门的库,比如vue-i18n。本文主要介绍自定义封装i18n,支持Vue、uniapp等版本。 设计思路 一、预期效果 二、核心代码 2.1 i18n.xlsx文件准备 2.2 脚本执行 根目录main.js根目录locali18n.xlsxnode main.jsmain.js 文件…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...