一篇就够mysql高阶知识总结
一、事务的ACID原则
| 序号 | 原则 | 说明 |
|---|---|---|
| 1 | 原子性(Atomicity) | 事务是数据库的逻辑工作单位,事务中包括的诸操作要么都做,要么都不做 |
| 2 | 一致性(Consistency) | 事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态 |
| 3 | 隔离性(Isolation) | 一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰 |
| 4 | 持久性(Durability) | 持久性也称永久性,指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,接下来的其他操作或故障不应该对其有任何影响 |
二、数据库设计的三大范式
| 序号 | 范式 | 说明 |
|---|---|---|
| 1 | 第一范式(1NF) | 确保每列保持原子性 |
| 2 | 第二范式(2NF) | 在满足第一范式的前提下,非主属性完全依赖于码 |
| 3 | 第三范式(3NF) | 在满足第二范式的前提下,非主属性不传递依赖于码 |
三、索引
| 序号 | 索引类型 | 说明 |
|---|---|---|
| 1 | 二叉树搜索树 | 基础数据结构,用于快速查找、插入和删除 |
| 2 | 红黑树 | 平衡二叉搜索树,保持树的平衡以维持操作的高效性 |
| 3 | B树 | 适用于大量数据的磁盘读写操作,保持树的平衡 |
| 4 | B+树 | B树的变种,非叶子节点不存储数据,更适合作为数据库索引结构 |
| 5 | 索引概念 | 数据库中用于提高数据检索效率的数据结构 |
四、SQL解析
| 序号 | 内容 | 说明 |
|---|---|---|
| 1 | SQL解析 | SQL语句被数据库管理系统解析、编译和执行的过程 |
五、锁机制
| 序号 | 锁类型 | 说明 |
|---|---|---|
| 1 | 行锁 | 锁定一行数据 |
| 2 | 表锁 | 锁定整个表 |
| 3 | 范围锁 | 锁定一定范围的数据 |
| 4 | 悲观锁 | 假设最坏情况,数据在修改前会被锁定 |
| 5 | 乐观锁 | 假设最好的情况,只在更新操作时检查数据是否被其他事务修改 |
| 6 | 读写锁 | 分为读锁和写锁,读锁允许多个读操作并发,写锁则独占 |
六、JOIN查询
| 序号 | 内容 | 说明 |
|---|---|---|
| 1 | 7种常见的JOIN查询 | 包括INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN, CROSS JOIN等 |
| 2 | SQL语句 | 展示具体的SQL JOIN查询语句 |
| 3-9 | 每种JOIN查询的说明与示例 | 分别解释每种JOIN的用法及示例 |
| 10 | Union和Union All | 介绍UNION和UNION ALL的区别及使用场景 |
七、索引优化
| 序号 | 内容 | 说明 |
|---|---|---|
| 1 | 索引分类 | 单值索引、唯一索引、主键索引、复合索引 |
| 2 | Explain性能分析 | 使用EXPLAIN分析SQL查询性能 |
| 3 | 索引优化入门案例 | 展示不同场景下的索引优化案例 |
| 4 | 索引失效分析 | 分析导致索引失效的常见场景 |
| 5 | 分组排序优化 | 优化ORDER BY和GROUP BY的性能 |
索引分类
| 序号 | 索引类型 | 说明 |
|---|---|---|
| 1 | 单值索引 | 索引列中的单个值 |
| 2 | 唯一索引 | 索引列中的值必须是唯一的,允许NULL值但最多只能有一个 |
| 3 | 主键索引 | 特殊的唯一索引,一个表只能有一个主键,且不允许NULL值 |
| 4 | 复合索引(组合索引) | 索引由两个或两个以上的列组成,列的组合值必须唯一或满足特定条件 |
Explain性能分析
| 序号 | 字段 | 说明 |
|---|---|---|
| 1 | sql | 执行的SQL语句 |
| 2 | id | SELECT的标识符,如果查询包含子查询,则会出现多个id |
| 3 | select_type | SELECT的类型(SIMPLE, PRIMARY, SUBQUERY等) |
| 4 | table | 输出行所引用的表 |
| 5 | type | 连接类型(ALL, index, range, ref, eq_ref, const/system等) |
| 6 | possible_keys | 显示可能应用在这张表上的索引,但不一定实际使用 |
| 7 | key | 实际使用的索引 |
| 8 | key_len | 使用的索引的长度 |
| 9 | ref | 显示索引的哪一列或常数被用于查找值 |
| 10 | rows | MySQL认为必须检查的用来返回请求数据的行数估计值 |
| 11 | Extra | 包含不适合在其他列中显示但十分重要的额外信息,如是否使用索引等 |
索引优化入门案例
1. 驱动表与被驱动表的选择
在连接查询(如JOIN)中,优化器会决定哪个表作为驱动表(驱动其他表进行连接的表),哪个表作为被驱动表。选择正确的驱动表和被驱动表可以显著提高查询性能。通常,驱动表应该是数据量较小、过滤条件较多、索引效果好的表。
案例:
假设有两个表,employees(员工表,包含10万条记录)和departments(部门表,包含100条记录)。如果要查询每个部门下的员工信息,最好让departments表作为驱动表,因为它更小,可以更快地遍历。
SELECT employees.*, departments.department_name
FROM employees
JOIN departments ON employees.department_id = departments.id
WHERE departments.region = 'Asia';
在这个例子中,尽管employees表在JOIN条件中,但如果departments.region = 'Asia'这个条件能显著减少departments表的结果集,那么优化器可能会选择departments作为驱动表。
2. 单表索引优化
单表索引优化通常涉及为查询中经常作为条件、连接键或排序键的列添加索引。
案例:
假设employees表有一个last_name列,经常需要根据员工的姓氏来查询员工信息。
SELECT * FROM employees WHERE last_name = 'Smith';
为了提高这个查询的效率,可以在last_name列上添加索引。
CREATE INDEX idx_last_name ON employees(last_name);
3. 两表索引优化
在两表连接查询中,优化索引可以显著提高性能。通常,应该在连接键和过滤条件上添加索引。
案例:
继续上面的employees和departments表的例子,如果经常需要根据部门ID和员工的姓氏来查询信息,可以在employees.department_id和departments.id(如果尚未索引)以及employees.last_name上添加索引。
-- 假设departments.id已经是主键,因此默认有索引
CREATE INDEX idx_emp_dept_id ON employees(department_id);
CREATE INDEX idx_emp_last_name ON employees(last_name);SELECT employees.*, departments.department_name
FROM employees
JOIN departments ON employees.department_id = departments.id
WHERE employees.last_name = 'Smith';
4. 三表及以上索引优化
对于涉及三个或更多表的连接查询,索引优化的策略与两表类似,但更复杂。通常需要考虑查询中所有表之间的连接键以及过滤条件。
案例:
假设还有一个projects表(项目表),其中包含项目信息,每个员工可以参与多个项目。现在需要查询参与特定项目且姓氏为’Smith’的员工及其部门信息。
SELECT employees.*, departments.department_name, projects.project_name
FROM employees
JOIN departments ON employees.department_id = departments.id
JOIN projects ON employees.id = projects.employee_id
WHERE employees.last_name = 'Smith' AND projects.project_name = 'ProjectX';
为了优化这个查询,可以在employees.department_id、employees.id(如果尚未作为主键索引)、employees.last_name、projects.employee_id以及projects.project_name上添加索引。
-- 假设employees.id和departments.id已经是主键,因此默认有索引
CREATE INDEX idx_emp_dept_id ON employees(department_id);
CREATE INDEX idx_emp_last_name ON employees(last_name);
CREATE INDEX idx_proj_emp_id ON projects(employee_id);
CREATE INDEX idx_proj_name ON projects(project_name);
注意:虽然索引可以显著提高查询性能,但它们也会占用额外的磁盘空间,并且会降低写操作的性能(如INSERT、UPDATE、DELETE)。因此,在设计索引时需要权衡这些因素。
索引失效分析
| 序号 | 场景 | 说明 |
|---|---|---|
| 1 | 最佳左前缀法则 | 复合索引中,查询条件需要按照索引列的顺序进行 |
| 2 | 避免在索引字段上做计算 | 如WHERE YEAR(column) = 2023,这会导致索引失效 |
| 3 | 避免在索引字段上做范围查询 | 范围查询后的列将无法使用索引(如WHERE a > 10 AND b = 2) |
| 4 | 查询字段和索引字段尽量一致 | 避免使用SELECT *,尽量只选择需要的列 |
| 5 | 慎用IS NULL和IS NOT NULL | 对于索引列,这些条件可能导致索引失效 |
| 6 | LIKE的前后模糊匹配 | 如LIKE '%keyword%',这将导致索引失效,但LIKE 'keyword%'则有效 |
| 7 | 使用UNION或UNION ALL代替OR | 在某些情况下,UNION/UNION ALL可以更有效地利用索引 |
八、SQL优化
| 序号 | 内容 | 说明 |
|---|---|---|
| 1 | SQL语句优化 | 提供SQL语句优化的方法和技巧 |
| 序号 | 内容 | 说明 |
|---|---|---|
| 1 | ORDER BY之前先使用WHERE等条件 | 过滤掉不需要排序的数据,减少排序的数据量 |
| 2 | WHERE和ORDER BY所用到的索引 | 尽量使用索引来加速WHERE和ORDER BY的操作 |
| 3 | 排序的方向必须一致 | 如果WHERE条件中使用了索引的某一列进行排序,确保排序方向一致 |
SQL语句优化
- 避免SELECT * :尽量指定需要查询的列,减少数据传输量。
- 使用表连接代替子查询:在可能的情况下,使用JOIN代替子查询可以提高查询效率。
- 优化WHERE子句:确保WHERE子句中的条件能够利用索引。
- 使用LIMIT限制结果集:如果只需要部分数据,使用LIMIT来减少处理的数据量。
- 合理使用聚合函数:聚合函数(如SUM, COUNT, AVG等)
九、额外优化技术
| 序号 | 内容 | 说明 |
|---|---|---|
| 1 | 截取查询分析 | 分析慢查询日志,优化大量数据插入等场景 |
| 2 | 开启慢SQL查询日志 | 监控并优化慢查询 |
| 3 | show profile | 使用MySQL的show profile命令分析查询性能 |
相关文章:

一篇就够mysql高阶知识总结
一、事务的ACID原则 序号原则说明1原子性(Atomicity)事务是数据库的逻辑工作单位,事务中包括的诸操作要么都做,要么都不做2一致性(Consistency)事务执行的结果必须是使数据库从一个一致性状态变到另一个一…...

CTF-Web习题:[BJDCTF2020]ZJCTF,不过如此
题目链接:[BJDCTF2020]ZJCTF,不过如此 解题思路 访问靶场链接,出现的是一段php源码,接下来做一下代码审阅,发现这是一道涉及文件包含的题 主要PHP代码语义: file_get_contents($text,r); 把$text变量所…...

【IEEE出版】第四届能源工程与电力系统国际学术会议(EEPS 2024)
第四届能源工程与电力系统国际学术会议(EEPS 2024) 2024 4th International Conference on Energy Engineering and Power Systems 重要信息 大会官网:www.iceeps.com 大会时间:2024年8月9-11日 大会…...

浅谈Vue:text-align: center、align-items: center、justify-content: center三种居中的区别和用法
text-align: center、align-items: center 和 justify-content: center 是用于不同布局场景下的CSS属性。它们在水平和垂直居中元素方面有所不同,具体取决于你使用的布局模型(如块级元素、Flexbox、Grid)。以下是它们的区别和适用场景&#x…...

理解UI设计:UI设计师的未来发展机遇
UI设计师的出现是互联网时代的设计变革。随着移动互联网的快速发展,移动产品设计师非常短缺。高薪资让许多其他行业的设计师已经转向了UI设计。那么什么是UI设计呢?UI设计师负责什么?UI设计的发展趋势和就业前景如何?这些都是许多…...

关键字 internal
在C#中,internal 关键字是一个访问修饰符,它用于限制类型或类型成员的访问性。当一个类型(类、结构体、接口、枚举等)或类型成员(字段、属性、方法、事件等)被声明为 internal 时,它只能在同一程…...

C学习(数据结构)-->单链表习题
目录 一、环形链表 题一:环形链表 思路: 思考一:为什么? 思考二:快指针一次走3步、4步、......n步,能否相遇 step1: step2: 代码: 题二: 环形链表 I…...

MATLAB6:M文件和控制流
文章目录 一、实验目的二、实验内容三、仿真结果四、实践中遇到的问题及解决方法 一、实验目的 1. 熟悉运用MATLAB的控制指令。 2. 理解M脚本文件和函数文件的本质区别。 3. 能够运用所学知识,编制程序解决一般的计算问题。 二、实验内容 1.for循环结构及注…...

网页数据抓取:融合BeautifulSoup和Scrapy的高级爬虫技术
网页数据抓取:融合BeautifulSoup和Scrapy的高级爬虫技术 在当今的大数据时代,网络爬虫技术已经成为获取信息的重要手段之一。Python凭借其强大的库支持,成为了进行网页数据抓取的首选语言。在众多的爬虫库中,BeautifulSoup和Scrap…...

Linux应用——网络基础
一、网络结构模型 1.1C/S结构 C/S结构——服务器与客户机; CS结构通常采用两层结构,服务器负责数据的管理,客户机负责完成与用户的交互任务。客户机是因特网上访问别人信息的机器,服务器则是提供信息供人访问的计算机。 例如&…...

白骑士的C++教学实战项目篇 4.3 多线程网络服务器
系列目录 上一篇:白骑士的C教学实战项目篇 4.2 学生成绩管理系统 在这一节中,我们将实现一个多线程网络服务器项目,通过该项目,我们将学习套接字编程的基础知识以及如何使用多线程处理并发连接。此外,我们还将实现一个…...

Go语言并发编程-Context上下文
Context上下文 Context概述 Go 1.7 标准库引入 context,译作“上下文”,准确说它是 goroutine 的上下文,包含 goroutine 的运行状态、环境、现场等信息。 context 主要用来在 goroutine 之间传递上下文信息,包括:取…...
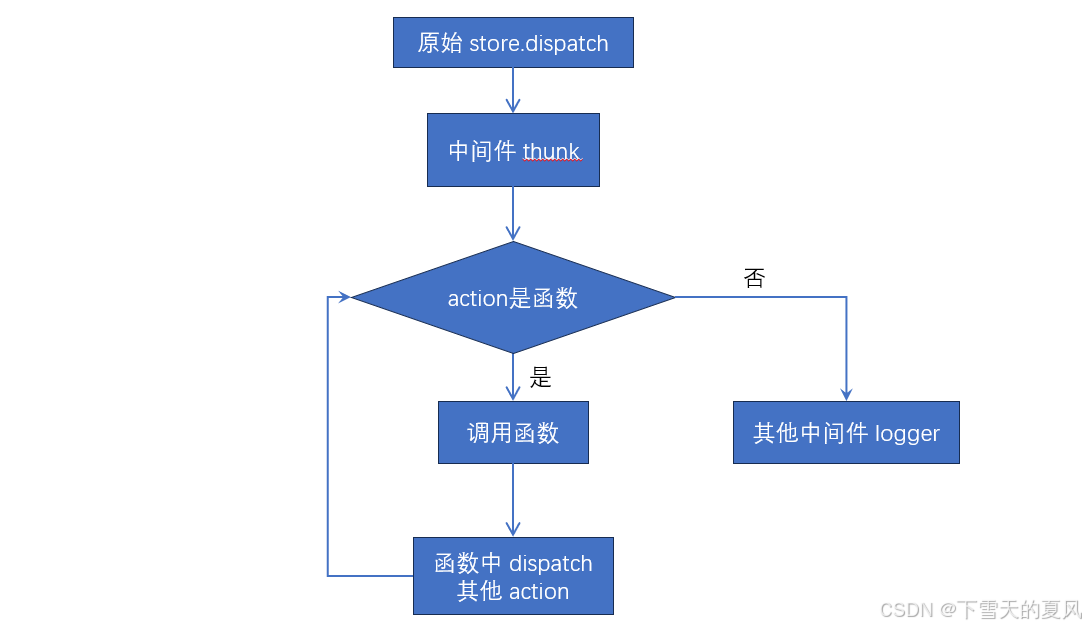
React@16.x(62)Redux@4.x(11)- 中间件2 - redux-thunk
目录 1,介绍举例 2,原理和实现实现 3,注意点 1,介绍 一般情况下,action 是一个平面对象,并会通过纯函数来创建。 export const createAddUserAction (user) > ({type: ADD_USER,payload: user, });这…...

【Qt】QTcpServer/QTcpSocket通信
这里写目录标题 1.pro文件2.服务器3.客户端 1.pro文件 QT network2.服务器 h文件 #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <QTcpServer> #include <QTcpSocket>QT_BEGIN_NAMESPACE namespace Ui { class MainW…...

【时时三省】单元测试 简介
目录 1,单元测试简介 2,单元测试的目的 3,单元测试检查范围 4,单元测试用例设计方法 5,单元测试判断通过标准 6,测试范围 7,测试频率 8,输出成果 经验建议: 山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 1,单元测试简介 单元测试在以V模型…...
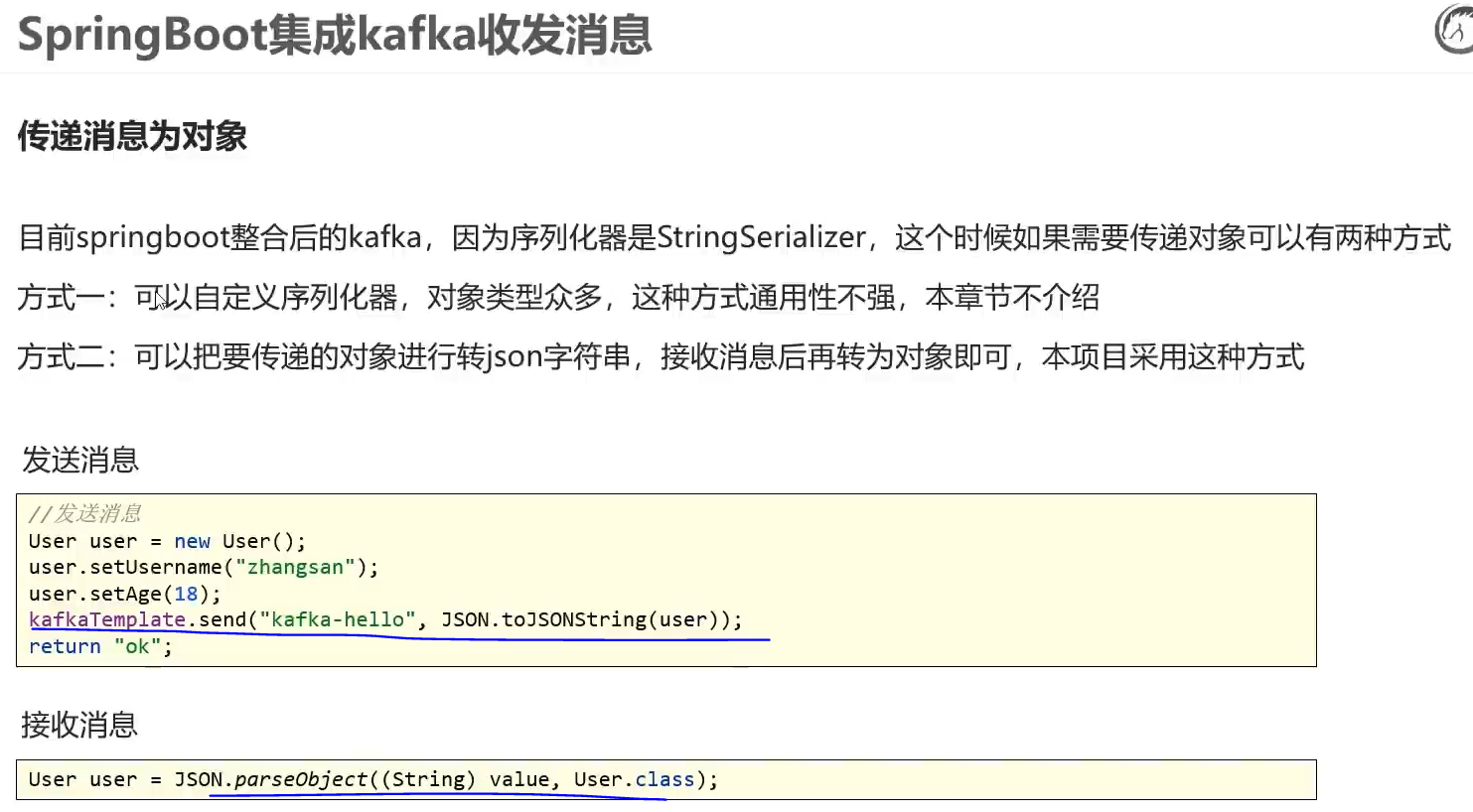
中间件——Kafka
两个系统各自都有各自要去做的事,所以只能将消息放到一个中间平台(中间件) Kafka 分布式流媒体平台 程序发消息,程序接收消息 Producer:Producer即生产者,消息的产生者,是消息的入口。 Brok…...
中介者模式(行为型)
目录 一、前言 二、中介者模式 三、总结 一、前言 中介者模式(Mediator Pattern)是一种行为型设计模式,又成为调停者模式,用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地互相引用,从而使其耦合…...
)
定个小目标之刷LeetCode热题(45)
32. 最长有效括号 给你一个只包含 ( 和 ) 的字符串,找出最长有效(格式正确且连续)括号 子串的长度。 示例 1: 输入:s "(()" 输出:2 解释:最长有效括号子串是 "()"有事…...

golang 实现负载均衡器-负载均衡原理介绍
go 实现负载均衡器 文章目录 go 实现负载均衡器代码实现介绍负载均衡的核心组件与工作流程核心组件工作流程 总结 算法详细描述:1. 轮询(Round Robin)2. 最少连接(Least Connections)3. IP散列(IP Hash&…...
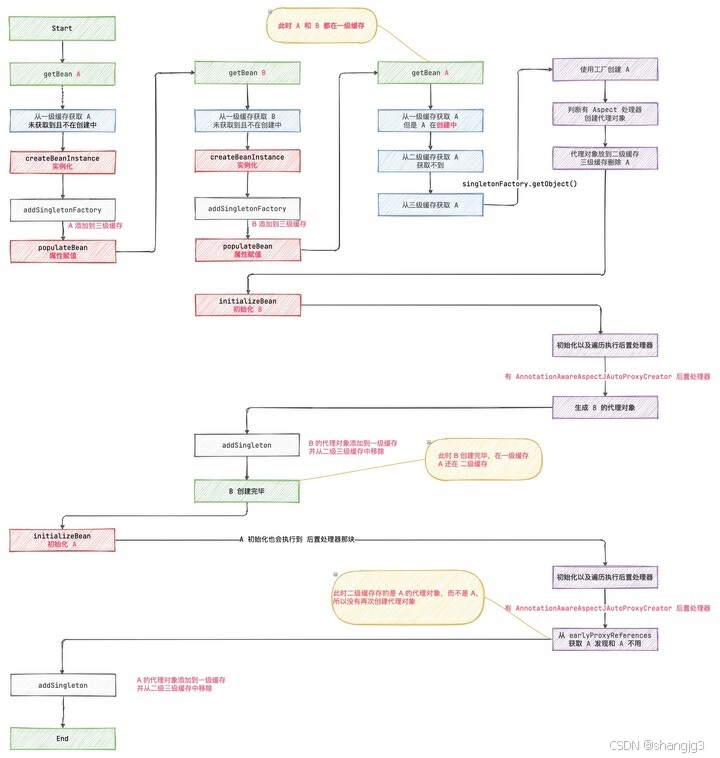
spring是如何解决循环依赖的,为什么不是两级
1. Spring使用三级缓存来解决循环依赖问题 Spring使用三级缓存来解决循环依赖问题,而不是使用两级缓存。 在Spring框架中,解决循环依赖的关键在于正确地管理Bean的生命周期和依赖关系。循环依赖指的是两个或多个Bean相互依赖,如果…...

ChatTTS音色克隆实战:从零构建高效语音合成模型
最近在做一个语音交互项目,需要为不同角色定制专属语音。传统的语音合成方案要么音色固定,要么克隆流程复杂、耗时巨大。直到我尝试了ChatTTS,才发现音色克隆可以如此高效。今天就来分享一下我的实战经验,希望能帮你绕过我踩过的那…...

嵌入式C语言面试核心问题与实战技巧
嵌入式C语言面试核心问题深度解析1. 预处理指令与宏定义1.1 常量定义与类型安全#define SEC_YEAR (365*24*60*60)UL这个宏定义展示了三个关键点:使用括号确保运算顺序正确使用UL后缀防止16位系统溢出让预处理器计算表达式而非硬编码结果1.2 参数化宏设计#define MIN…...

AI画家助手:OpenClaw+GLM-4.7-Flash自动生成Midjourney提示词并管理作品
AI画家助手:OpenClawGLM-4.7-Flash自动生成Midjourney提示词并管理作品 1. 为什么需要AI画家助手? 去年我开始尝试用Midjourney进行艺术创作时,遇到了两个头疼的问题:一是提示词(prompt)优化需要反复调试…...

提示工程进阶:让AI原生应用更智能的7种方法
提示工程进阶:让AI原生应用更智能的7种方法关键词:提示工程、AI原生应用、LLM优化、Prompt设计、Few-shot学习、思维链、结构化输出摘要:当你在使用ChatGPT写代码卡壳时,或是用智能客服解决问题却得到“人工智障”回复时ÿ…...
:顺序表(ArrayList)的实现与应用)
【数据结构与算法】第5篇:线性表(一):顺序表(ArrayList)的实现与应用
一、什么是顺序表顺序表是最简单的一种线性结构。用一段地址连续的存储单元依次存储数据元素。你可以把它理解为一个可以自动扩容的数组。C语言的原生数组长度是固定的,不够用的时候只能重新申请更大的数组,把数据搬过去。顺序表封装了这个过程ÿ…...

选型指南:74HC14、74LVC14、CD40106...这么多施密特非门,你的项目到底该用哪一款?
施密特触发器选型实战:从74HC14到CD40106的工程决策指南 在数字电路设计中,施密特触发器就像一位经验丰富的守门员,能够有效过滤信号噪声并确保数字系统的稳定运行。但当你打开元器件采购平台,面对74HC14、74LVC14、CD40106等数十…...

定位精准度如何保障?住宅代理在本地SERP验证中的优势
本地SERP验证是企业优化地域营销、把控本地搜索展示效果的核心环节。如何在不同城市、不同区域准确获取真实的搜索结果?住宅代理凭借其独特的产品特性,成为解决这一问题的首选。提升结果精准度优质的住宅代理服务商拥有规模庞大、覆盖广泛的IP资源池&…...

Vue Toast组件:轻量级通知解决方案的无侵入式集成实践
Vue Toast组件:轻量级通知解决方案的无侵入式集成实践 【免费下载链接】vue-sonner 🔔 An opinionated toast component for Vue. 项目地址: https://gitcode.com/gh_mirrors/vu/vue-sonner 在现代Web应用开发中,用户交互反馈是提升体…...

Windows/Mac双平台实测:Qt 6.9.0离线安装包+在线安装器对比评测
Qt 6.9.0跨平台安装全攻略:离线包与在线安装器的深度实测 当开发团队需要为Windows和macOS双平台部署Qt 6.9.0开发环境时,选择正确的安装方式往往能节省数小时的配置时间。本文将基于真实企业级部署场景,通过20组对照实验数据,揭示…...
)
别再让漏洞扫描报警了!手把手教你给老旧Linux服务器升级OpenSSH和OpenSSL(附systemd服务修复秘籍)
企业级Linux服务器安全加固实战:OpenSSH与OpenSSL深度升级指南 凌晨三点,刺耳的安全告警声再次划破运维中心的宁静——漏洞扫描报告上醒目的红色标记显示:OpenSSH 7.4存在CVE-2023-38408高危漏洞。这不是演习,而是每位运维工程师都…...