尚硅谷大数据技术-数据湖Hudi视频教程-笔记03【Hudi集成Spark】
大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品)
- B站直达:https://www.bilibili.com/video/BV1ue4y1i7na 尚硅谷数据湖Hudi视频教程
- 百度网盘:https://pan.baidu.com/s/1NkPku5Pp-l0gfgoo63hR-Q?pwd=yyds
- 阿里云盘:https://www.aliyundrive.com/s/uMCmjb8nGaC(教程配套资料请从百度网盘下载)
尚硅谷大数据技术-数据湖Hudi视频教程-笔记01【Hudi概述、Hudi编译安装】
尚硅谷大数据技术-数据湖Hudi视频教程-笔记02【Hudi核心概念(基本概念、数据写、数据读)】
尚硅谷大数据技术-数据湖Hudi视频教程-笔记03【Hudi集成Spark】
尚硅谷大数据技术-数据湖Hudi视频教程-笔记04【Hudi集成Flink】
尚硅谷大数据技术-数据湖Hudi视频教程-笔记05【Hudi集成Hive】
目录
第4章 集成 Spark
026
027
028
029
030
031
第4章 集成 Spark
026
第4章 集成 Spark
4.1 环境准备
4.1.1 安装Spark
4.1.2 启动Hadoop(略)
4.2 spark-shell 方式
4.2.1 启动 spark-shell
1)启动命令
[atguigu@node001 ~]$ spark-shell \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18760 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node001:4040
Spark context available as 'sc' (master = local[*], app id = local-1704790850201).
Spark session available as 'spark'.
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.2.2/_/Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.scala> 027
4.2.1 启动 spark-shell
2)设置表名,基本路径和数据生成器
scala> import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.QuickstartUtils._scala> import scala.collection.JavaConversions._
import scala.collection.JavaConversions._scala> import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql.SaveMode._scala> import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceReadOptions._scala> import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.DataSourceWriteOptions._scala> import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.config.HoodieWriteConfig._scala> scala> val tableName = "hudi_trips_cow"
tableName: String = hudi_trips_cowscala> val basePath = "file:///tmp/hudi_trips_cow"
basePath: String = file:///tmp/hudi_trips_cowscala> val dataGen = new DataGenerator
dataGen: org.apache.hudi.QuickstartUtils.DataGenerator = org.apache.hudi.QuickstartUtils$DataGenerator@66e6b022scala> scala> scala> val inserts = convertToStringList(dataGen.generateInserts(10))
inserts: java.util.List[String] = [{"ts": 1704209002713, "uuid": "58f04a7a-6d32-42a6-8915-dfc00ae845fc", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.4726905879569653, "begin_lon": 0.46157858450465483, "end_lat": 0.754803407008858, "end_lon": 0.9671159942018241, "fare": 34.158284716382845, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1704623138251, "uuid": "d2c871b0-e98e-44ee-815b-09fbcc5771bb", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.6100070562136587, "begin_lon": 0.8779402295427752, "end_lat": 0.3407870505929602, "end_lon": 0.5030798142293655, "fare": 43.4923811219014, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1704362707376, "uuid": "74e4699e-3644-477e-9d12-bf83a67c59c1", "rider": "rider-213", "driver"...scala> val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
df: org.apache.spark.sql.DataFrame = [begin_lat: double, begin_lon: double ... 8 more fields]scala> df.write.format("hudi").| options(getQuickstartWriteConfigs).| option(PRECOMBINE_FIELD_OPT_KEY, "ts").| option(RECORDKEY_FIELD_OPT_KEY, "uuid").| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").| option(TABLE_NAME, tableName).| mode(Overwrite).| save(basePath)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'
7744528 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
7744558 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
7747037 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:///tmp/hudi_trips_cow/.hoodie/metadatascala> 
028
4.2.3 查询数据
scala> val tripsSnapshotDF = spark.| read.| format("hudi").| load(basePath)
tripsSnapshotDF: org.apache.spark.sql.DataFrame = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 13 more fields]scala> tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")scala> scala> spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
+------------------+-------------------+-------------------+-------------+
| fare| begin_lon| begin_lat| ts|
+------------------+-------------------+-------------------+-------------+
| 33.92216483948643| 0.9694586417848392| 0.1856488085068272|1704256809374|
| 64.27696295884016| 0.4923479652912024| 0.5731835407930634|1704362707376|
| 93.56018115236618|0.14285051259466197|0.21624150367601136|1704216687193|
| 27.79478688582596| 0.6273212202489661|0.11488393157088261|1704494741512|
| 43.4923811219014| 0.8779402295427752| 0.6100070562136587|1704623138251|
| 66.62084366450246|0.03844104444445928| 0.0750588760043035|1704568660989|
|34.158284716382845|0.46157858450465483| 0.4726905879569653|1704209002713|
| 41.06290929046368| 0.8192868687714224| 0.651058505660742|1704563419431|
+------------------+-------------------+-------------------+-------------+scala> spark.sql("select * from hudi_trips_snapshot where fare > 20.0").show()
+-------------------+--------------------+--------------------+----------------------+--------------------+-------------------+-------------------+----------+-------------------+-------------------+------------------+---------+-------------+--------------------+--------------------+
|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| begin_lat| begin_lon| driver| end_lat| end_lon| fare| rider| ts| uuid| partitionpath|
+-------------------+--------------------+--------------------+----------------------+--------------------+-------------------+-------------------+----------+-------------------+-------------------+------------------+---------+-------------+--------------------+--------------------+
| 20240109190932344|20240109190932344...|ca1d00a7-8eeb-49c...| americas/united_s...|7608cfb3-4a20-418...| 0.1856488085068272| 0.9694586417848392|driver-213|0.38186367037201974|0.25252652214479043| 33.92216483948643|rider-213|1704256809374|ca1d00a7-8eeb-49c...|americas/united_s...|
| 20240109190932344|20240109190932344...|74e4699e-3644-477...| americas/united_s...|7608cfb3-4a20-418...| 0.5731835407930634| 0.4923479652912024|driver-213|0.08988581780930216|0.42520899698713666| 64.27696295884016|rider-213|1704362707376|74e4699e-3644-477...|americas/united_s...|
| 20240109190932344|20240109190932344...|fb17af56-2f63-481...| americas/united_s...|7608cfb3-4a20-418...|0.21624150367601136|0.14285051259466197|driver-213| 0.5890949624813784| 0.0966823831927115| 93.56018115236618|rider-213|1704216687193|fb17af56-2f63-481...|americas/united_s...|
| 20240109190932344|20240109190932344...|c745152f-893d-461...| americas/united_s...|7608cfb3-4a20-418...|0.11488393157088261| 0.6273212202489661|driver-213| 0.7454678537511295| 0.3954939864908973| 27.79478688582596|rider-213|1704494741512|c745152f-893d-461...|americas/united_s...|
| 20240109190932344|20240109190932344...|d2c871b0-e98e-44e...| americas/brazil/s...|1c69c03e-47de-4d9...| 0.6100070562136587| 0.8779402295427752|driver-213| 0.3407870505929602| 0.5030798142293655| 43.4923811219014|rider-213|1704623138251|d2c871b0-e98e-44e...|americas/brazil/s...|
| 20240109190932344|20240109190932344...|6983e2a6-61e4-4df...| americas/brazil/s...|1c69c03e-47de-4d9...| 0.0750588760043035|0.03844104444445928|driver-213|0.04376353354538354| 0.6346040067610669| 66.62084366450246|rider-213|1704568660989|6983e2a6-61e4-4df...|americas/brazil/s...|
| 20240109190932344|20240109190932344...|58f04a7a-6d32-42a...| americas/brazil/s...|1c69c03e-47de-4d9...| 0.4726905879569653|0.46157858450465483|driver-213| 0.754803407008858| 0.9671159942018241|34.158284716382845|rider-213|1704209002713|58f04a7a-6d32-42a...|americas/brazil/s...|
| 20240109190932344|20240109190932344...|f464f5d9-c284-4a8...| asia/india/chennai|38325a98-dd9a-453...| 0.651058505660742| 0.8192868687714224|driver-213|0.20714896002914462|0.06224031095826987| 41.06290929046368|rider-213|1704563419431|f464f5d9-c284-4a8...| asia/india/chennai|
+-------------------+--------------------+--------------------+----------------------+--------------------+-------------------+-------------------+----------+-------------------+-------------------+------------------+---------+-------------+--------------------+--------------------+scala> 
029
4.2.4 更新数据
val tripsSnapshotDF1 = spark.read.format("hudi").load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot1")spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show(20)
scala> val tripsSnapshotDF1 = spark.read.format("hudi").load(basePath)
tripsSnapshotDF1: org.apache.spark.sql.DataFrame = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 13 more fields]scala> tripsSnapshotDF1.createOrReplaceTempView("hudi_trips_snapshot1")scala> spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show(20)
+-------------------+--------------------+----------------------+---------+----------+------------------+
|_hoodie_commit_time| _hoodie_record_key|_hoodie_partition_path| rider| driver| fare|
+-------------------+--------------------+----------------------+---------+----------+------------------+
| 20240123152755513|c1f36d67-9031-415...| americas/united_s...|rider-213|driver-213| 64.27696295884016|
| 20240123152755513|a1914586-f6f8-468...| americas/united_s...|rider-213|driver-213| 33.92216483948643|
| 20240123152755513|7779f311-34fb-412...| americas/united_s...|rider-213|driver-213| 93.56018115236618|
| 20240123152755513|bc90314b-537a-409...| americas/united_s...|rider-213|driver-213| 27.79478688582596|
| 20240123152755513|aef5f9e3-e31a-42c...| americas/united_s...|rider-213|driver-213|19.179139106643607|
| 20240123152755513|1dda1939-c3a7-488...| americas/brazil/s...|rider-213|driver-213|34.158284716382845|
| 20240123152755513|7f6b775b-1480-425...| americas/brazil/s...|rider-213|driver-213| 43.4923811219014|
| 20240123152755513|ce7f6bb2-53de-46b...| americas/brazil/s...|rider-213|driver-213| 66.62084366450246|
| 20240123152755513|10b632a9-59e5-4ef...| asia/india/chennai|rider-213|driver-213|17.851135255091155|
| 20240123152755513|8a78e424-e64a-40f...| asia/india/chennai|rider-213|driver-213| 41.06290929046368|
+-------------------+--------------------+----------------------+---------+----------+------------------+scala>
4.2.3 查询数据
3)时间旅行查询
030
4.2.5 增量查询
scala> spark.| read.| format("hudi").| load(basePath).| createOrReplaceTempView("hudi_trips_snapshot")scala> val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
commits: Array[String] = Array(20240123152755513) scala> val beginTime = commits(commits.length - 2)
java.lang.ArrayIndexOutOfBoundsException: -1... 59 elidedscala> scala> scala> val updates = convertToStringList(dataGen.generateUpdates(10))
updates: java.util.List[String] = [{"ts": 1705879465411, "uuid": "c1f36d67-9031-4157-a8d2-13b6d30b1572", "rider": "rider-284", "driver": "driver-284", "begin_lat": 0.7340133901254792, "begin_lon": 0.5142184937933181, "end_lat": 0.7814655558162802, "end_lon": 0.6592596683641996, "fare": 49.527694252432056, "partitionpath": "americas/united_states/san_francisco"}, {"ts": 1705399614657, "uuid": "1dda1939-c3a7-4884-9b70-4ef87bc050f9", "rider": "rider-284", "driver": "driver-284", "begin_lat": 0.1593867607188556, "begin_lon": 0.010872312870502165, "end_lat": 0.9808530350038475, "end_lon": 0.7963756520507014, "fare": 29.47661370147079, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1705403081035, "uuid": "1dda1939-c3a7-4884-9b70-4ef87bc050f9", "rider": "rider-...scala> val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
df: org.apache.spark.sql.DataFrame = [begin_lat: double, begin_lon: double ... 8 more fields]scala> df.write.format("hudi").| options(getQuickstartWriteConfigs).| option(PRECOMBINE_FIELD_OPT_KEY, "ts").| option(RECORDKEY_FIELD_OPT_KEY, "uuid").| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").| option(TABLE_NAME, tableName).| mode(Append).| save(basePath)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'scala> val updates = convertToStringList(dataGen.generateUpdates(10))
updates: java.util.List[String] = [{"ts": 1705790965039, "uuid": "c1f36d67-9031-4157-a8d2-13b6d30b1572", "rider": "rider-243", "driver": "driver-243", "begin_lat": 0.9045189017781902, "begin_lon": 0.38697902072535484, "end_lat": 0.21932410786717094, "end_lon": 0.7816060218244935, "fare": 44.596839246210095, "partitionpath": "americas/united_states/san_francisco"}, {"ts": 1705482677807, "uuid": "ce7f6bb2-53de-46bd-87f8-ff19f367bd1d", "rider": "rider-243", "driver": "driver-243", "begin_lat": 0.856152038750905, "begin_lon": 0.3132477949501916, "end_lat": 0.8742438057467156, "end_lon": 0.26923247017036556, "fare": 2.4995362119815567, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1705754253073, "uuid": "c1f36d67-9031-4157-a8d2-13b6d30b1572", "rider": "rider...scala> val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
df: org.apache.spark.sql.DataFrame = [begin_lat: double, begin_lon: double ... 8 more fields]scala> df.write.format("hudi").| options(getQuickstartWriteConfigs).| option(PRECOMBINE_FIELD_OPT_KEY, "ts").| option(RECORDKEY_FIELD_OPT_KEY, "uuid").| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").| option(TABLE_NAME, tableName).| mode(Append).| save(basePath)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'scala> val updates = convertToStringList(dataGen.generateUpdates(10))
updates: java.util.List[String] = [{"ts": 1705393408046, "uuid": "10b632a9-59e5-4ef4-811c-1250a817c74a", "rider": "rider-563", "driver": "driver-563", "begin_lat": 0.16172715555352513, "begin_lon": 0.6286940931025506, "end_lat": 0.7559063825441225, "end_lon": 0.39828516291900906, "fare": 16.098476392187365, "partitionpath": "asia/india/chennai"}, {"ts": 1705982569737, "uuid": "8a78e424-e64a-40f8-8eb7-f8e3741ab17e", "rider": "rider-563", "driver": "driver-563", "begin_lat": 0.9312237784651692, "begin_lon": 0.67243450582925, "end_lat": 0.28393433672984614, "end_lon": 0.2725166210142148, "fare": 27.603571822228822, "partitionpath": "asia/india/chennai"}, {"ts": 1705602950761, "uuid": "bc90314b-537a-409e-9d93-9c8663d578cc", "rider": "rider-563", "driver": "driver-5...scala> val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
df: org.apache.spark.sql.DataFrame = [begin_lat: double, begin_lon: double ... 8 more fields]scala> df.write.format("hudi").| options(getQuickstartWriteConfigs).| option(PRECOMBINE_FIELD_OPT_KEY, "ts").| option(RECORDKEY_FIELD_OPT_KEY, "uuid").| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").| option(TABLE_NAME, tableName).| mode(Append).| save(basePath)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'scala> scala> scala> spark.| read.| format("hudi").| load(basePath).| createOrReplaceTempView("hudi_trips_snapshot")scala> val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
commits: Array[String] = Array(20240123155641315, 20240123155717896, 20240123155726796)scala> val beginTime = commits(commits.length - 2)
beginTime: String = 20240123155717896scala> val tripsIncrementalDF = spark.read.format("hudi").| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).| load(basePath)
tripsIncrementalDF: org.apache.spark.sql.DataFrame = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 13 more fields]scala> tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")scala> spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()
+-------------------+------------------+-------------------+------------------+-------------+
|_hoodie_commit_time| fare| begin_lon| begin_lat| ts|
+-------------------+------------------+-------------------+------------------+-------------+
| 20240123155726796| 54.16944371261484| 0.7548086309564753|0.5535762898838785|1705960250638|
| 20240123155726796| 37.35848234860164| 0.9084944020139248|0.6330100459693088|1705652568556|
| 20240123155726796| 84.66949742559657|0.31331111382522836|0.8573834026158349|1705867633650|
| 20240123155726796| 38.4828225162323|0.20404106962358204|0.1450793330198833|1705405789140|
| 20240123155726796| 55.31092276192561| 0.826183030502974| 0.391583018565109|1705428608507|
| 20240123155726796|27.603571822228822| 0.67243450582925|0.9312237784651692|1705982569737|
+-------------------+------------------+-------------------+------------------+-------------+scala> 4.2.6 指定时间点查询
scala> val beginTime = "000"
beginTime: String = 000scala> val endTime = commits(commits.length - 2)
endTime: String = 20240123155717896scala> val tripsPointInTimeDF = spark.read.format("hudi").| option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).| option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).| option(END_INSTANTTIME_OPT_KEY, endTime).| load(basePath)
tripsPointInTimeDF: org.apache.spark.sql.DataFrame = [_hoodie_commit_time: string, _hoodie_commit_seqno: string ... 13 more fields]scala> tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")scala> spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()
+-------------------+------------------+-------------------+-------------------+-------------+
|_hoodie_commit_time| fare| begin_lon| begin_lat| ts|
+-------------------+------------------+-------------------+-------------------+-------------+
| 20240123155717896|44.596839246210095|0.38697902072535484| 0.9045189017781902|1705790965039|
| 20240123155641315| 90.9053809533154|0.19949323322922063|0.18294079059016366|1705742911148|
| 20240123155717896|26.636532270940915|0.12314538318119372|0.35527775182006427|1705655264707|
| 20240123155717896| 51.42305232303094| 0.7071871604905721| 0.876334576190389|1705609025064|
| 20240123155641315| 91.99515909032544| 0.2783086084578943| 0.2110206104048945|1705585303503|
| 20240123155717896| 89.45841313717807|0.22991770617403628| 0.6923616674358241|1705771716835|
| 20240123155717896| 71.08018349571618| 0.8150991077375751|0.01925237918893319|1705812754018|
+-------------------+------------------+-------------------+-------------------+-------------+scala> 031
4.2.7 删除数据
3.2.6 删除策略
1)逻辑删:将 value 字段全部标记为 null。
2)物理删:
(1)通过 OPERATION_OPT_KEY 删除所有的输入记录
(2)配置 PAYLOAD_CLASS_OPT_KEY = org.apache.hudi.EmptyHoodieRecordPayload 删除所有的输入记录
(3)在输入记录添加字段:_hoodie_is_deleted
4.2.8 覆盖数据
032
4.3 Spark SQL方式
4.3.1 创建表
[atguigu@node001 ~]$ nohup hive --service metastore &
[1] 11371
[atguigu@node001 ~]$ nohup: 忽略输入并把输出追加到"nohup.out"[atguigu@node001 ~]$ jpsall
================ node001 ================
3472 NameNode
4246 NodeManager
4455 JobHistoryServer
11384 -- process information unavailable
10456 SparkSubmit
3642 DataNode
4557 SparkSubmit
11437 Jps
================ node002 ================
6050 Jps
2093 DataNode
2495 NodeManager
2335 ResourceManager
================ node003 ================
5685 Jps
2279 SecondaryNameNode
2459 NodeManager
2159 DataNode
[atguigu@node001 ~]$ netstat -anp | grep 9083
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
tcp6 0 0 :::9083 :::* LISTEN 11371/java
[atguigu@node001 ~]$ spark-sql \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
0 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1410 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1410 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
8317 [main] WARN org.apache.spark.util.Utils - Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
8319 [main] WARN org.apache.spark.util.Utils - Service 'SparkUI' could not bind on port 4041. Attempting port 4042.
Spark master: local[*], Application Id: local-1706012797408
spark-sql (default)> show databases;
namespace
default
edu2077
Time taken: 11.185 seconds, Fetched 2 row(s)
spark-sql (default)> > create database spark_hudi;
Response code
Time taken: 11.725 seconds
spark-sql (default)> use spark_hudi;
Response code
Time taken: 0.673 seconds
spark-sql (default)> create table hudi_cow_nonpcf_tbl (> uuid int,> name string,> price double> ) using hudi;
422168 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
422406 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
425565 [main] WARN org.apache.hadoop.hive.ql.session.SessionState - METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
Response code
Time taken: 10.492 seconds
spark-sql (default)> show tables;
namespace tableName isTemporary
hudi_cow_nonpcf_tbl
Time taken: 1.444 seconds, Fetched 1 row(s)
spark-sql (default)> desc hudi_cow_nonpcf_tbl;
col_name data_type comment
_hoodie_commit_time string
_hoodie_commit_seqno string
_hoodie_record_key string
_hoodie_partition_path string
_hoodie_file_name string
uuid int
name string
price double
Time taken: 2.179 seconds, Fetched 8 row(s)
spark-sql (default)> create table hudi_mor_tbl (> id int,> name string,> price double,> ts bigint> ) using hudi> tblproperties (> type = 'mor',> primaryKey = 'id',> preCombineField = 'ts'> );
Response code
Time taken: 1.803 seconds
spark-sql (default)> show tables;
namespace tableName isTemporary
hudi_cow_nonpcf_tbl
hudi_mor_tbl
Time taken: 0.257 seconds, Fetched 2 row(s)
spark-sql (default)> desc hudi_mor_tbl;
col_name data_type comment
_hoodie_commit_time string
_hoodie_commit_seqno string
_hoodie_record_key string
_hoodie_partition_path string
_hoodie_file_name string
id int
name string
price double
ts bigint
Time taken: 0.636 seconds, Fetched 9 row(s)
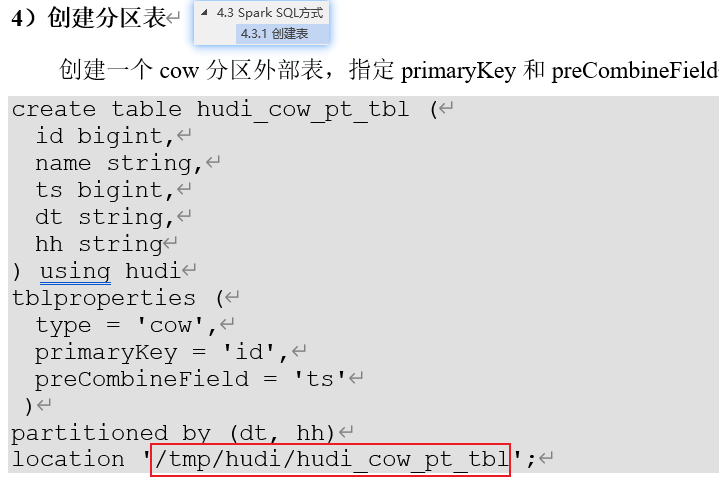
spark-sql (default)> create table hudi_cow_pt_tbl (> id bigint,> name string,> ts bigint,> dt string,> hh string> ) using hudi> tblproperties (> type = 'cow',> primaryKey = 'id',> preCombineField = 'ts'> )> partitioned by (dt, hh)> location '/tmp/hudi/hudi_cow_pt_tbl';
Response code
Time taken: 21.88 seconds
spark-sql (default)> create table hudi_ctas_cow_nonpcf_tbl> using hudi> tblproperties (primaryKey = 'id')> as> select 1 as id, 'a1' as name, 10 as price;
1514254 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_ctas_cow_nonpcf_tbl/.hoodie/metadata
1546852 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1546852 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 63.078 seconds
spark-sql (default)> select * from hudi_ctas_cow_nonpcf_tbl;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name price
20240123205131373 20240123205131373_0_0 id:1 bee32427-f490-40dd-89ed-3bacd3adf6fb-0_0-17-15_20240123205131373.parquet 1 a1 10
Time taken: 1.636 seconds, Fetched 1 row(s)
spark-sql (default)> create table hudi_ctas_cow_pt_tbl> using hudi> tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts')> partitioned by (dt)> as> select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt;
1646675 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_ctas_cow_pt_tbl/.hoodie/metadata
1664435 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1664435 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 26.019 seconds
spark-sql (default)> select * from hudi_ctas_cow_pt_tbl;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name price ts dt
20240123205354771 20240123205354771_0_0 id:1 dt=2021-12-01 88ad8031-2239-4bce-8494-5bf109012400-0_0-69-1259_20240123205354771.parquet 1 a1 10 1000 2021-12-01
Time taken: 2.829 seconds, Fetched 1 row(s)
spark-sql (default)> 033
4.3.2 插入数据

spark-sql (default)> show tables;
namespace tableName isTemporary
hudi_cow_nonpcf_tbl
hudi_cow_pt_tbl
hudi_ctas_cow_nonpcf_tbl
hudi_ctas_cow_pt_tbl
hudi_mor_tbl
Time taken: 1.298 seconds, Fetched 5 row(s)
spark-sql (default)> insert into hudi_cow_nonpcf_tbl 1, 'a1', 20;
Error in query:
mismatched input '1' expecting {'(', 'FROM', 'MAP', 'REDUCE', 'SELECT', 'TABLE', 'VALUES'}(line 1, pos 32)== SQL ==
insert into hudi_cow_nonpcf_tbl 1, 'a1', 20
--------------------------------^^^spark-sql (default)> insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
458055 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
458212 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
475300 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_cow_nonpcf_tbl/.hoodie/metadata
517206 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
517206 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 80.477 seconds
spark-sql (default)> insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
640716 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_mor_tbl/.hoodie/metadata
694713 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
694723 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 71.597 seconds
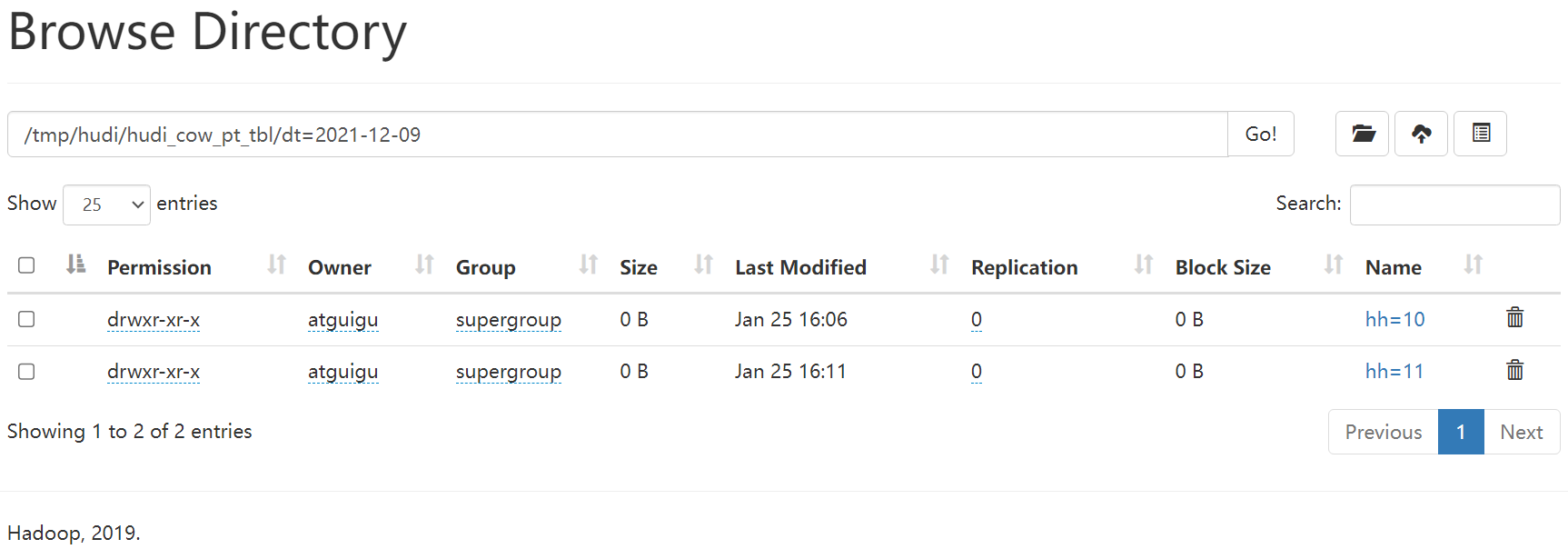
spark-sql (default)> insert into hudi_cow_pt_tbl partition (dt, hh)> select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
743011 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl/.hoodie/metadata
04:48 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
04:49 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
04:53 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
Response code
Time taken: 46.44 seconds
spark-sql (default)> insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
10:06 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
10:07 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
10:11 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
Response code
Time taken: 71.592 seconds
spark-sql (default)> select * from hudi_mor_tbl;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name price ts
20240125160415749 20240125160415749_0_0 id:1 a81ca1da-f642-45c5-ac7e-eb93de803ba8-0_0-65-1253_20240125160415749.parquet 1 a1 20.0 1000
Time taken: 23.135 seconds, Fetched 1 row(s)
spark-sql (default)> -- 向指定preCombineKey的表插入数据,则写操作为upsert
spark-sql (default)> insert into hudi_mor_tbl select 1, 'a1_1', 20, 1001;
1353572 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1353573 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 46.455 seconds
spark-sql (default)> select id, name, price, ts from hudi_mor_tbl;
id name price ts
1 a1_1 20.0 1001
Time taken: 2.081 seconds, Fetched 1 row(s)
spark-sql (default)> set hoodie.sql.bulk.insert.enable=true;
key value
hoodie.sql.bulk.insert.enable true
Time taken: 0.214 seconds, Fetched 1 row(s)
spark-sql (default)> set hoodie.sql.insert.mode=non-strict;
key value
hoodie.sql.insert.mode non-strict
Time taken: 0.027 seconds, Fetched 1 row(s)
spark-sql (default)> insert into hudi_mor_tbl select 1, 'a1_2', 20, 1002;
1538483 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1538486 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 42.906 seconds
spark-sql (default)> select id, name, price, ts from hudi_mor_tbl;
id name price ts
1 a1_2 20.0 1002
1 a1_1 20.0 1001
Time taken: 1.015 seconds, Fetched 2 row(s)
spark-sql (default)> set hoodie.sql.bulk.insert.enable=false;
key value
hoodie.sql.bulk.insert.enable false
Time taken: 2.396 seconds, Fetched 1 row(s)
spark-sql (default)> create table hudi_cow_pt_tbl1 (> id bigint,> name string,> ts bigint,> dt string,> hh string> ) using hudi> tblproperties (> type = 'cow',> primaryKey = 'id',> preCombineField = 'ts'> )> partitioned by (dt, hh)> location '/tmp/hudi/hudi_cow_pt_tbl1';
1737608 [main] WARN org.apache.hadoop.hive.ql.session.SessionState - METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
Response code
Time taken: 12.013 seconds
spark-sql (default)> insert into hudi_cow_pt_tbl1 select 1, 'a0', 1000, '2021-12-09', '10';
1765548 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1/.hoodie/metadata
22:14 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
22:15 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
22:23 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
Response code
Time taken: 64.552 seconds
spark-sql (default)> select * from hudi_cow_pt_tbl1;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name ts dt hh
20240125162301446 20240125162301446_0_0 id:1 dt=2021-12-09/hh=10 1e1b2016-8b33-4d4b-a824-4cd53ab7e8ec-0_0-290-5658_20240125162301446.parquet 1a0 1000 2021-12-09 10
Time taken: 1.702 seconds, Fetched 1 row(s)
spark-sql (default)> insert into hudi_cow_pt_tbl1 select 1, 'a1', 1001, '2021-12-09', '10';
23:04 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
23:05 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
23:09 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
Response code
Time taken: 16.112 seconds
spark-sql (default)> select * from hudi_cow_pt_tbl1;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name ts dt hh
20240125162431677 20240125162431677_0_0 id:1 dt=2021-12-09/hh=10 1e1b2016-8b33-4d4b-a824-4cd53ab7e8ec-0_0-329-6292_20240125162431677.parquet 1a1 1001 2021-12-09 10
Time taken: 1.122 seconds, Fetched 1 row(s)
spark-sql (default)> select * from hudi_cow_pt_tbl1 timestamp as of '20220307091628793' where id = 1;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name ts dt hh
Time taken: 20.962 seconds
spark-sql (default)> 034
4.3.4 更新数据
1)update
035
4.3.4 更新数据
2)MergeInto
相关文章:
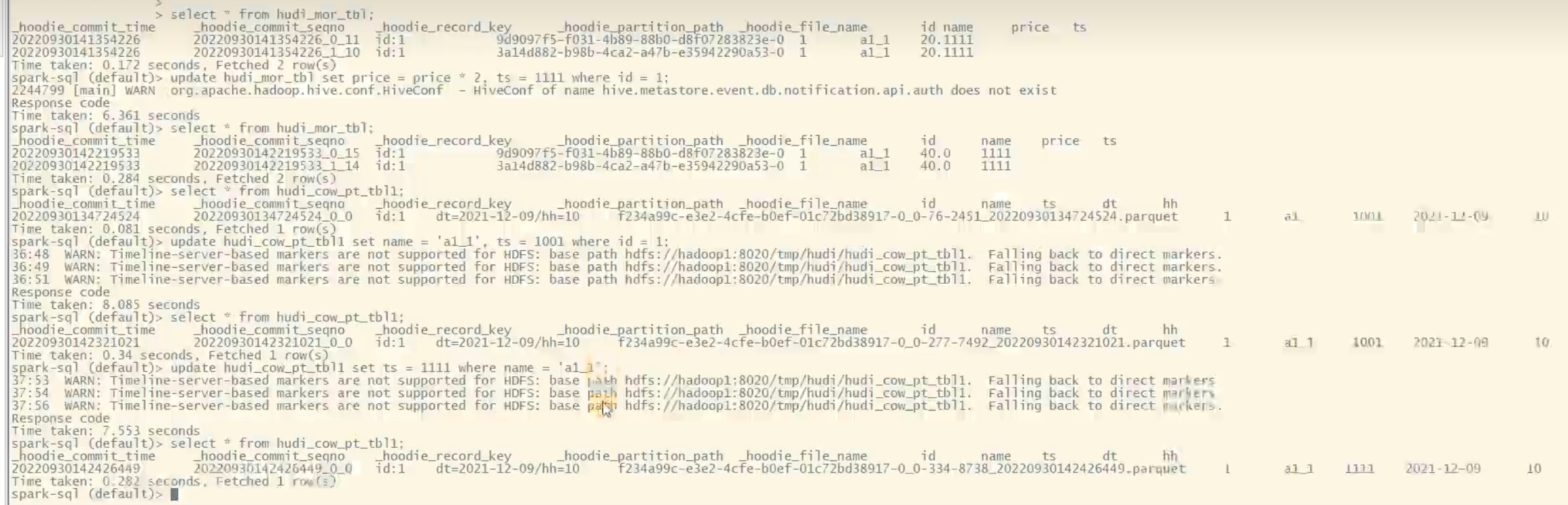
尚硅谷大数据技术-数据湖Hudi视频教程-笔记03【Hudi集成Spark】
大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品) B站直达:https://www.bilibili.com/video/BV1ue4y1i7na 尚硅谷数据湖Hudi视频教程百度网盘:https://pan.baidu.com/s/1NkPku5Pp-l0gfgoo63hR-Q?pwdyyds阿里…...

【python】Pandas中IndexError: single positional indexer is out of bounds的报错分析
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

ubuntu上通过修改grub启动参数,将串口重定向到sol
要修改 GRUB 启动参数以实现串口重定向到 Serial Over LAN (SOL),你需要编辑 /etc/default/grub 文件,并更新 GRUB 配置。这里是详细步骤: 1. 编辑 /etc/default/grub 打开终端并使用文本编辑器(如 nano 或 vim)编辑…...
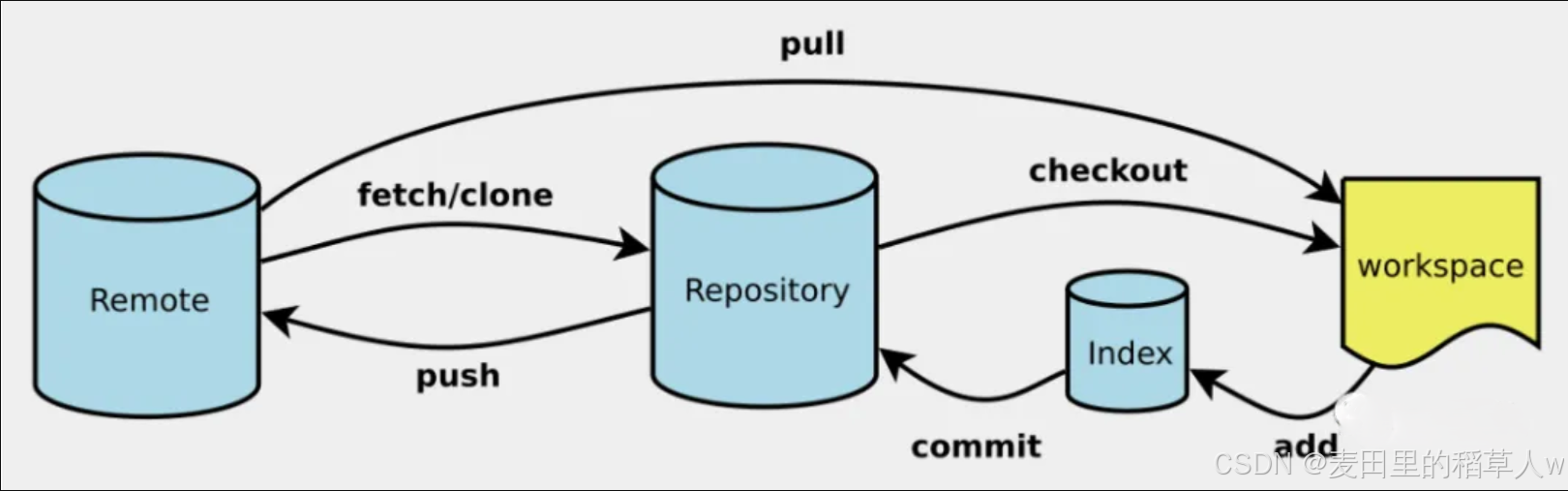
【Git】(基础篇四)—— GitHub使用
GitHub使用 经过上一篇的文章,相信大家已经对git的基本操作熟悉了,但哪些使用git的方法只是在本地仓库进行,本文介绍如何使用git和远程仓库进行连接使用。 Github和Gitee 主要用到的两个远程仓库在线平台是github和gitee GitHub GitHub …...

【Qt+opencv】基础的图像绘制
文章目录 前言line函数ellipse函数rectangle函数circle函数fillPoly函数putText函数总结 前言 在计算机视觉和图像处理领域,OpenCV是一个强大的库,提供了丰富的功能和算法。而Qt是一个跨平台的C图形用户界面应用程序开发框架,它为开发者提供…...

使用Nginx OpenResty与Redis实现高效IP黑白名单管理
1、引言 在当今数字化时代,网络安全已成为企业和个人用户关注的焦点。IP黑白名单作为一种有效的网络安全策略,允许我们精确控制对Web资源的访问权限。通过白名单,我们可以确保只有可信的IP地址能够访问敏感资源;而黑名单则可以阻…...

EasyExcel导入导出数据类型转换
前言: 1、基本数据类型转换:当前原始的数据类型是interger类型,需要在导出时将其映射为对应的字符串,并且导入时可以将字符串重新映射为interger类型。 2、时间格式转换:数据从数据库中获取的类型为LocalDate类型&…...

stm32入门-----EXTI外部中断(下——实践篇)
目录 前言 一、硬件介绍 1.对射红外线传感器 2.旋转编码器 二、EXTI外部中断C编程 1.开启RCC时钟 2.配置GPIOK口初始化 3.配置AFIO 4.配置EXIT 5.配置NVIC 三、EXIT外部中断项目实操 1.对射红外传感器计数 2.选择编码器计数 前言 本期接着上一期的内容继续学习stm3…...

深度学习落地实战:基于UNet实现血管瘤超声图像分割
前言 大家好,我是机长 本专栏将持续收集整理市场上深度学习的相关项目,旨在为准备从事深度学习工作或相关科研活动的伙伴,储备、提升更多的实际开发经验,每个项目实例都可作为实际开发项目写入简历,且都附带完整的代码与数据集。可通过百度云盘进行获取,实现开箱即用 …...

Python进阶(4)--正则表达式
正则表达式 在Python中,正则表达式(Regular Expression,简称Regex)是一种强大的文本处理工具,它允许你使用一种特殊的语法来匹配、查找、替换字符串中的文本。 在这之前,还记得之前我们是通过什么方法分割…...

RCA连接器是什么?一文读懂
RCA连接器,也就是我们在电视机、DVD播放器、通讯设备、立体声设备和游戏设备后面常见的彩色插头,其历史可以追溯到近一个世纪以前。这种现今广泛使用的电缆接口,最初是由美国无线电公司(RCA)开发并命名的,在…...

【linux】服务器安装NVIDIA驱动
【linux】服务器安装NVIDIA驱动 【创作不易,求点赞关注收藏】😀 文章目录 【linux】服务器安装NVIDIA驱动一、关闭系统自带驱动nouveau二、下载英伟达驱动三、安装英伟达驱动1、禁用X服务器和相关进程2、在TTY终端安装驱动3、验证是否安装成功4、重新启…...

【达梦数据库】关于用户、模式、表空间等如何理解?
与MySQL的用户有所区别,MySQL是单实例多库,DM7以上版本是单库多实例架构, MySQL访问方式: 一个root访问多个库,访问前切换一下就ok 比如MySQL到DM的迁移是,MySQL的一个库对应dm中的一个表空间和一个用户。比…...

一篇就够mysql高阶知识总结
一、事务的ACID原则 序号原则说明1原子性(Atomicity)事务是数据库的逻辑工作单位,事务中包括的诸操作要么都做,要么都不做2一致性(Consistency)事务执行的结果必须是使数据库从一个一致性状态变到另一个一…...

CTF-Web习题:[BJDCTF2020]ZJCTF,不过如此
题目链接:[BJDCTF2020]ZJCTF,不过如此 解题思路 访问靶场链接,出现的是一段php源码,接下来做一下代码审阅,发现这是一道涉及文件包含的题 主要PHP代码语义: file_get_contents($text,r); 把$text变量所…...

【IEEE出版】第四届能源工程与电力系统国际学术会议(EEPS 2024)
第四届能源工程与电力系统国际学术会议(EEPS 2024) 2024 4th International Conference on Energy Engineering and Power Systems 重要信息 大会官网:www.iceeps.com 大会时间:2024年8月9-11日 大会…...

浅谈Vue:text-align: center、align-items: center、justify-content: center三种居中的区别和用法
text-align: center、align-items: center 和 justify-content: center 是用于不同布局场景下的CSS属性。它们在水平和垂直居中元素方面有所不同,具体取决于你使用的布局模型(如块级元素、Flexbox、Grid)。以下是它们的区别和适用场景&#x…...

理解UI设计:UI设计师的未来发展机遇
UI设计师的出现是互联网时代的设计变革。随着移动互联网的快速发展,移动产品设计师非常短缺。高薪资让许多其他行业的设计师已经转向了UI设计。那么什么是UI设计呢?UI设计师负责什么?UI设计的发展趋势和就业前景如何?这些都是许多…...

关键字 internal
在C#中,internal 关键字是一个访问修饰符,它用于限制类型或类型成员的访问性。当一个类型(类、结构体、接口、枚举等)或类型成员(字段、属性、方法、事件等)被声明为 internal 时,它只能在同一程…...

C学习(数据结构)-->单链表习题
目录 一、环形链表 题一:环形链表 思路: 思考一:为什么? 思考二:快指针一次走3步、4步、......n步,能否相遇 step1: step2: 代码: 题二: 环形链表 I…...
)
保姆级教程:从WOS下载文献到Citespace出图,手把手搞定科研可视化(附避坑指南)
科研可视化实战:从WOS数据采集到Citespace图谱优化的完整指南 第一次打开Citespace时,看着满屏的英文参数和报错提示,我盯着屏幕发了十分钟呆——这大概是每个科研新手都会经历的"震撼教育"。文献计量分析本应是揭示知识脉络的利器…...
)
别再手动整理了!用Python脚本5分钟搞定ImageNet验证集标签映射(附完整代码)
5分钟极速搞定ImageNet验证集标签映射:Python自动化实战指南 每次处理ImageNet验证集时,你是否也对着那些晦涩的数字标签头疼不已?手动查表不仅效率低下,还容易出错。今天我们就来彻底解决这个痛点——用Python脚本自动完成标签映…...

理视康新零售系统开发要点
业务模式设计新零售模式需整合线上线下渠道,构建会员体系、分销机制与数据中台。通过小程序、APP或H5实现线上商城,线下门店采用智能硬件(如AR试戴、智能货架)提升体验。结合LBS技术实现附近门店导流,支持到店自提或同…...

C++的std--ranges中的验证编译期
C20引入的std::ranges库彻底改变了范围操作的方式,其中编译期验证机制是其最强大的特性之一。这种机制允许开发者在编译阶段捕获潜在错误,显著提升了代码的健壮性和性能。本文将深入探讨std::ranges中编译期验证的核心机制及其实际应用价值。编译时概念检…...

如何快速解锁AMD 780M APU的完整AI性能?终极优化指南
如何快速解锁AMD 780M APU的完整AI性能?终极优化指南 【免费下载链接】ROCmLibs-for-gfx1103-AMD780M-APU ROCm Library Files for gfx1103 and update with others arches based on AMD GPUs for use in Windows. 项目地址: https://gitcode.com/gh_mirrors/ro/…...

别再只用UI库了!用Tailwind CSS V4快速给Canvas画板组件搭个现代感工具栏
用Tailwind CSS V4为Canvas画板打造专业级工具栏的5个关键技巧 在构建现代Web绘图应用时,Canvas提供了强大的绘图能力,但往往需要配套的UI控件来实现完整的用户体验。传统UI库虽然方便,却可能带来冗余的样式和性能开销。Tailwind CSS V4以其原…...

ClawdBot优化升级:如何配置国内大模型,提升响应速度与效果
ClawdBot优化升级:如何配置国内大模型,提升响应速度与效果 1. 项目概述 ClawdBot(现更名为MoltBot)是一款开源的个人AI助手工具,它能够在本地设备上运行,通过vLLM提供后端模型能力。这个工具特别适合开发…...

文脉定序详细步骤:自定义prompt模板提升BGE-m3在垂直领域表现
文脉定序详细步骤:自定义prompt模板提升BGE-m3在垂直领域表现 1. 理解文脉定序与BGE-m3的核心价值 文脉定序是一款基于BGE-m3模型的智能语义重排序系统,专门解决传统搜索引擎"搜得到但排不准"的痛点。它通过全交叉注意机制,对问题…...

C语言入门避坑指南:从雨课堂高频错题解析编程新手常见误区
C语言入门避坑指南:从雨课堂高频错题解析编程新手常见误区 刚接触C语言时,很多同学会被看似简单的语法规则绊倒。那些在课堂上反复强调的细节,往往成为考试中最容易丢分的陷阱。本文将结合电子科技大学《程序设计与算法基础I》课程的真实错题…...

从温控器到无人机:PID参数整定的‘手感’秘籍,附C语言代码避坑指南
从温控器到无人机:PID参数整定的‘手感’秘籍与实战避坑指南 在工业自动化和智能硬件开发中,PID控制算法就像一位隐形的调音师,默默调节着系统的每一个细微变化。无论是缓慢升温的工业烘箱,还是高速响应的四旋翼无人机,…...