统计软件与数据分析--Lesson3
dataframe数据常用python操作
- dataframe数据常用知识点
- 1.创建dataframe
- 1.1使用字典创建DataFrame:
- 1.2使用列表创建DataFrame:
- 1.3使用numpy数组创建DataFrame:
- 1.4从TXT文件中创建DataFrame:
- 1.5从CSV文件中创建DataFrame:
- 1.6从Excel文件中创建DataFrame:
- 2.dataframe数据保存
- 3.dataframe数据查看和选择
- 3.1查看前/后n行:
- 3.2选择DataFrame中的某列/某行:
- 3.3选择DataFrame中的多列/多行
- 3.4选择DataFrame中的特定行和列
- 3.5选择DataFrame中的特定列组成子数据框
- 4.dataframe数据查询
- 4.1条件查询
- 4.2模糊查询
- 4.3多条件查询
- 4.4查询数据框的元素是否在指定列表中
- 5.dataframe数据预处理
- 5.1删除缺失值
- 5.2填充缺失值
- 5.3数据替换:
- 5.4去除重复数据:
- 5.5更改数据类型:
- 5.6删除指定的某一列/某一行
- 5.7删除指定的某多列/某多行
- 5.8 dataframe某列或多列或所有列重命名
- 5.9 dataframe索引列相关操作
- 5.10 dataframe排序相关操作
- 6.dataframe数据运算
- 6.1算术运算
- 6.2统计运算
- 6.3行列运算
- 6.4聚合运算
- 6.5merge运算扩展
- 6.6其他运算
- 7.dataframe 时间序列基本操作
- 7.1生成时间序列数据
- 7.2按时间排序
- 7.3统计时间范围内的数据
- 7.4时间偏移
- 7.5时间重采样
- 7.6移动窗口函数
- 7.7时间差
- 7.8时间索引
- 7.9时间戳转换
- 7.10按照时间周期进行统计
- 7.11提取年、月、日等信息
- 7.12按照日期数据进行分组
- 7.13时区转换
- 7.14绘制时间序列图
- 7.15时间运算
- 8.dataframe数据可视化
- 8.1使用pandas自带的可视化工具
- 8.2使用matplotlib库
- 8.3使用seaborn库
- 8.4 使用matplotlib库绘制拼接子图
dataframe数据常用知识点
DataFrame是Python中pandas库中一个非常重要的数据结构,它类似于电子表格或SQL表格,可以存储和操作带标签的二维数据。DataFrame的重要知识点如下:
-
1.创建DataFrame:可以通过读取外部文件、手动创建或从其他数据结构中创建DataFrame。常用的函数包括pandas.DataFrame()、pandas.read_csv()、pandas.read_excel()等。
-
2.DataFrame数据存取:可以通过不同的函数保存到txt、csv、excel等文件中,同样也可以利用不同的函数从不同的文件中读取数据。常用的函数包括.to_csv()、.to_excel()等。
-
3.数据查看和选择:可以使用.head()和.tail()方法查看前几行和后几行数据,使用.iloc[]和.loc[]方法选择数据。
-
4.数据查询:常见的 DataFrame 查询操作包括条件查询、模糊查询和多条件查询等。
-
5.数据清洗:包括数据的缺失值处理、重复值处理、数据类型转换等。常用的函数包括dropna()、fillna()、drop_duplicates()、astype()等。
-
6.数据运算:可以进行多种数据运算,包括列之间的运算、行之间的运算、元素级运算等。常用的运算包括加减乘除、apply()、groupby()、merge()等。
-
7.时间序列操作:pandas提供了多种时间序列处理和分析的工具,包括resample()、rolling()等。这些工具可以用于处理时间序列数据,如时间序列数据的重采样、平滑处理等。
-
8.数据可视化:可以使用pandas自带的可视化工具进行数据可视化。常用的函数包括plot()、hist()、boxplot()等。此外,还有其他专业的可视化库(如matplotlib和seaborn)。
总之,DataFrame是Python中非常重要的数据结构之一,可以用于处理和分析各种类型的数据,掌握这些知识点可以更好地使用DataFrame进行数据处理和分析。
1.创建dataframe
三种常用的创建DataFrame的方式,分别是使用字典、列表和numpy数组:
1.1使用字典创建DataFrame:
- 1.直接转换,字典所有的key均为列
import pandas as pd#创建字典
data = {'name': ['Tom', 'Jack', 'Steve', 'Lucky'], 'age': [28, 14, 19, 22], 'gender': ['M', 'M', 'M', 'F']}#将字典转换成DataFrame
df = pd.DataFrame(data)#打印DataFrame
print(df)
- 2.字典所有的key为数据框的索引(index),值转换为数据框的列
可以通过pd.DataFrame.from_dict()将字典的键转换为数据框的索引(index),将字典的值转换为数据框的列,然后使用columns参数为列指定名称。
import pandas as pd# 创建一个示例字典
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}# 将字典转换为数据框,键为index,值为列,列名为A、B、C
df = pd.DataFrame.from_dict(data, orient='index', columns=['col1', 'col2', 'clo3'])
print(df)
在上面的代码中,orient='index’参数指定将字典的键用作索引(即行标签),将字典的值用作列。通过columns参数指定列的名称。输出:
col1 col2 col3
A 1 4 7
B 2 5 8
C 3 6 9
1.2使用列表创建DataFrame:
import pandas as pd#创建列表
data = [['Tom', 28, 'M'], ['Jack', 14, 'M'], ['Steve', 19, 'M'], ['Lucky', 22, 'F']]#将列表转换成DataFrame
df = pd.DataFrame(data, columns=['name', 'age', 'gender'])#打印DataFrame
print(df)
1.3使用numpy数组创建DataFrame:
import pandas as pd
import numpy as np#创建numpy数组
data = np.array([['Tom', 28, 'M'], ['Jack', 14, 'M'], ['Steve', 19, 'M'], ['Lucky', 22, 'F']])#将numpy数组转换成DataFrame
df = pd.DataFrame(data, columns=['name', 'age', 'gender'])#打印DataFrame
print(df)
实际应用中,还可以通过读取外部文件、从数据库中读取数据等方式创建DataFrame:
上次学习了python数据的存取,我们先将上面的dataframe数据分别存到txt、csv、excel文件中:
import pandas as pddf.to_csv('./data/data_df.txt', index=False, sep='\t')#保存到txt
df.to_csv('./data/data_df.csv', index=False, sep='\t')#保存到csv#保存到excel
writer = pd.ExcelWriter('./data/data_df.xlsx')
df.to_excel(writer, index=False, sheet_name='Sheet1')
writer.save()
再分别从不同的外部文件中读取数据:
1.4从TXT文件中创建DataFrame:
import pandas as pd从CSV文件中读取数据
df = pd.read_csv('./data/data_df.txt')# 打印DataFrame
print(df)
1.5从CSV文件中创建DataFrame:
import pandas as pd从CSV文件中读取数据
df = pd.read_csv('./data/data_df.csv')# 打印DataFrame
print(df)
1.6从Excel文件中创建DataFrame:
import pandas as pd#从Excel文件中读取数据
df = pd.read_excel('./data/data_df.xlsx')#打印DataFrame
print(df)
此外还可以从MySQL数据库中创建DataFrame:
import pandas as pd
import mysql.connector#连接MySQL数据库
cnx = mysql.connector.connect(user='root', password='password', host='127.0.0.1', database='test')#从数据库中读取数据
df = pd.read_sql('SELECT * FROM data', con=cnx)#关闭数据库连接
cnx.close()#打印DataFrame
print(df)
上面这些是在实际应用中如何直接创建或通过读取外部文件、从数据库中读取数据等方式创建DataFrame。需要注意的是,不同的数据格式和数据源需要使用不同的读取函数,例如读取JSON文件需要使用pd.read_json()函数,读取SQLite数据库需要使用pd.read_sqlite()函数等等。同时,对于一些大型数据集,可以使用分块读取的方式进行处理,以避免内存不足的问题。
2.dataframe数据保存
见 统计软件与数据分析—Lesson2 之 3.1.4保存Dataframe
3.dataframe数据查看和选择
创建一个dataframe,后续操作均基于这个df进行:
#创建DataFrame
data = {'name': ['Tom', 'Jack', 'Steve', 'Lucky'], 'age': [28, 14, 19, 22], 'gender': ['M', 'M', 'M', 'F']}
df = pd.DataFrame(data)
3.1查看前/后n行:
- 查看DataFrame的前n行:df.head(n)
#查看前2行数据
print(df.head(2))
- 查看DataFrame的后n行:df.tail(n)
#查看后2行数据
print(df.tail(2))
3.2选择DataFrame中的某列/某行:
- 选择DataFrame中的某列:df[‘列名’]
#选择name列
name = df['name']#打印name列
print(name)
- 选择DataFrame中的某行: df.loc[n]
#选择第2行
row = df.iloc[1]# 打印第2行
print(row)
3.3选择DataFrame中的多列/多行
- 选择DataFrame中的多列:df[[‘列名1’, ‘列名2’]]
# 选择name和age列
cols = df[['name', 'age']]# 打印name和age列
print(cols)
- 选择DataFrame中的多行:df.iloc[a:b]
# 选择第2-3行
rows = df.iloc[1:2]# 打印第2-3行
print(rows)
3.4选择DataFrame中的特定行和列
df.at[行数, ‘列名’]
#选择第2行和name列
cell = df.at[1, 'name']#打印第2行和name列的值
print(cell)
3.5选择DataFrame中的特定列组成子数据框
#选择name列构成新的子数据框,索引列不变
df_new = df[['name']]#打印新的子数据框
print(df_new )
4.dataframe数据查询
常见的 DataFrame 查询操作包括条件查询、模糊查询和多条件查询等,下面给出一些示例:
4.1条件查询
假设有一个 DataFrame df,其中有 name、age、gender 等列,可以使用如下方式进行条件查询:
#查询 age 大于等于20 岁的行
df[df['age'] >= 20]#查询 name 是 'Tom' 的行
df[df['name'] == 'Tom']4.2模糊查询
模糊查询一般使用 str.contains() 方法,可以匹配包含某个字符串的行。
#查询 name 中包含 'Tom' 的行
df[df['name'].str.contains('Tom')]#查询 name 中以 'T' 开头的行
df[df['name'].str.startswith('T')]4.3多条件查询
可以通过 & 和 | 连接多个条件进行查询。
#查询 age 大于等于 20 岁且 gender 是女性的行
df[(df['age'] >= 20) & (df['gender'] == 'F')]#查询 age 小于 20 岁或者 gender 是男性的行
df[(df['age'] < 20) | (df['gender'] == 'M')]
4.4查询数据框的元素是否在指定列表中
查询数据框的元素是否在指定列表中,若在返回对应的行
isin是pandas库中的一个函数,它用于检查数据框中的每个元素是否存在于给定的列表中。下面是一个示例:
# 使用isin函数选取age列中值为25或27的行
df[df['age'].isin([19,22,27])]
5.dataframe数据预处理
数据清洗是数据分析的重要步骤之一,可以帮助我们提高数据质量和准确性。在Python中,pandas库提供了丰富的函数和方法,可以方便地进行数据清洗和处理。以下是几个常用的数据清洗示例:
5.1删除缺失值
- (1)删除含有缺失值的行:df.dropna()默认为行
import pandas as pd#创建含有缺失值的DataFrame
data = {'name': ['Tom', 'Jack', 'Steve', 'Lucky'], 'age': [28, None, 19, 22], 'gender': ['M', 'M', None, 'F']}
df = pd.DataFrame(data)#查看含有缺失值的行
null_rows = df[df.isnull().any(axis=1)]
print('含有缺失值的行为:',null_rows)#删除含有缺失值的行
df = df.dropna()#查看删除后的DataFrame数据
print('删除缺失数行后的DataFrame数据为:')
print(df)
- (2)删除含有缺失值的列:df.dropna(axis=1)
#查看含有缺失值的列
print('含有缺失值的列为:')
print(df.isnull().any())#删除含有缺失值的列
df = df.dropna(axis=1)#查看删除后的DataFrame数据
print('删除缺失数列后的DataFrame数据为:')
print(df)
- (3)删除DataFrame中缺失值达到一定比例的列:
import pandas as pd#创建一个示例数据框
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [5, 4, 3, 2, 1],'C': [1, 2, 3, None, None],'D': [None, None, None, None, None],'E': [None, 1, 2, 3, 4]
})#计算每一列中缺失值的比例
na_ratio = df.isna().sum() / len(df)#选出缺失值比例小于0.3的列
cols_to_keep = na_ratio[na_ratio < 0.3].index#删除缺失值比例大于等于0.3的列
df_clean = df[cols_to_keep].dropna(axis=1)print(df_clean)
5.2填充缺失值
- (1)使用常数填充缺失值:df.fillna(value=xx, inplace=True)
可以使用fillna()函数的value参数来填充缺失值。
import pandas as pd
import numpy as npdf = pd.DataFrame({'A': [1, 2, np.nan, 4], 'B': [5, np.nan, np.nan, 8]})
print(df)#使用常数填充缺失值
df.fillna(value=0, inplace=True)
print(df)
- (2)使用均值填充缺失值:df.fillna(value=df.mean(), inplace=True)
可以使用fillna()函数的mean()方法来填充缺失值,将缺失值替换成对应列的均值。
import pandas as pd
import numpy as npdf = pd.DataFrame({'A': [1, 2, np.nan, 4], 'B': [5, np.nan, np.nan, 8]})
print(df)#使用均值填充缺失值
df.fillna(value=df.mean(), inplace=True)
print(df)- (3)使用前一个/后一个非缺失值填充缺失值:df.fillna(method=‘ffill’/‘bfill’, inplace=True)
可以使用fillna()函数的method参数来指定填充方法,method='ffill’表示使用前一个非缺失值填充缺失值。
import pandas as pd
import numpy as npdf = pd.DataFrame({'A': [1, 2, np.nan, 4], 'B': [5, np.nan, np.nan, 8]})
print(df)#使用前一个非缺失值填充缺失值
df.fillna(method='ffill', inplace=True)
##使用后一个非缺失值填充缺失值
#df.fillna(method='bfill', inplace=True)
print(df)
5.3数据替换:
df[‘列名’].replace(‘旧值’, ‘新值’)
import pandas as pd#创建DataFrame
data = {'name': ['Tom', 'Jack', 'Steve', 'Lucky'], 'age': [28, 14, 19, 22], 'gender': ['M', 'M', 'M', 'F']}
df = pd.DataFrame(data)#将'F'替换为'Female'
df['gender'] = df['gender'].replace('F', 'Female')#打印清洗后的DataFrame
print(df)
5.4去除重复数据:
df.drop_duplicates()
import pandas as pd# 创建含有重复数据的DataFrame
data = {'name': ['Tom', 'Jack', 'Steve', 'Lucky', 'Tom'], 'age': [28, 14, 19, 22,28], 'gender': ['M', 'M', 'M', 'F','M']}
df = pd.DataFrame(data)# 去除重复数据
df = df.drop_duplicates()# 打印清洗后的DataFrame
print(df)
5.5更改数据类型:
df[‘列名’].astype(类型)
import pandas as pd# 创建DataFrame
data = {'name': ['Tom', 'Jack', 'Steve', 'Lucky'], 'age': [28, 14, 19, 22], 'gender': ['M', 'M', 'M', 'F']}
df = pd.DataFrame(data)# 将'age'列的数据类型更改为int
df['age'] = df['age'].astype(int)# 打印清洗后的DataFrame
print(df)
5.6删除指定的某一列/某一行
在 Pandas 中,可以使用 drop() 方法删除指定列或行。drop() 方法会返回一个新的 DataFrame,原始的 DataFrame 不会被修改。
如果要删除列,可以将 axis 参数设置为 1。如果要删除行,则将 axis 参数设置为 0。删除列时,需要指定列名,删除行时,需要指定行的索引。
以下是删除指定列或行的示例代码:
import pandas as pd# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})# 删除列
df = df.drop('A', axis=1) # 删除名为 'A' 的列# 删除行
df = df.drop(0, axis=0) # 删除索引为 0 的行在上述示例代码中,先创建了一个包含3行3列的 DataFrame 对象。然后使用 drop() 方法删除了名为 ‘A’ 的列和索引为 0 的行。
注意,drop() 方法会返回一个新的 DataFrame,而原始的 DataFrame 不会被修改。如果要在原始的 DataFrame 上进行修改,则可以将 inplace 参数设置为 True。例如:
# 删除列并在原始 DataFrame 上进行修改
df.drop('A', axis=1, inplace=True)
5.7删除指定的某多列/某多行
要删除多列或多行,可以将列名或行索引放入列表中,然后传递给 drop() 方法的 labels 参数。还需要将 axis 参数设置为 1(删除列)或 0(删除行)。
以下是删除指定多列或多行的示例代码:
import pandas as pd# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})# 删除多列
df = df.drop(['A', 'B'], axis=1) # 删除名为 'A' 和 'B' 的列# 删除多行
df = df.drop([0, 1], axis=0) # 删除索引为 0 和 1 的行
使用 drop() 方法删除了名为 ‘A’ 和 ‘B’ 的列,以及索引为 0 和 1 的行。
**再次强调**,drop() 方法会返回一个新的 DataFrame,而原始的 DataFrame 不会被修改。如果要在原始的 DataFrame 上进行修改,则可以将 inplace 参数设置为 True。例如:
# 删除多列并在原始 DataFrame 上进行修改
df.drop(['A', 'B'], axis=1, inplace=True)
以上示例代码将在原始的 DataFrame 上删除名为 ‘A’ 和 ‘B’ 的列。
5.8 dataframe某列或多列或所有列重命名
在 Pandas 中,可以使用 rename() 方法对 DataFrame 的某列或多列或所有列进行重命名。rename() 方法会返回一个新的 DataFrame,原始的 DataFrame 不会被修改。
以下是对某列或多列或所有列进行重命名的示例代码:
- (1)对某一列进行重命名:
import pandas as pd# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})# 对名为 'A' 的列进行重命名
df = df.rename(columns={'A': 'new_A'})
在上述示例代码中,先创建了一个包含3行3列的 DataFrame 对象。然后使用 rename() 方法将名为 ‘A’ 的列重命名为 ‘new_A’。
- (2)对多列进行重命名:
# 对名为 'A' 和 'B' 的列进行重命名
df = df.rename(columns={'A': 'new_A', 'B': 'new_B'})
在上述示例代码中,使用 rename() 方法将名为 ‘A’ 的列重命名为 ‘new_A’,将名为 ‘B’ 的列重命名为 ‘new_B’。
- (3)对所有列进行重命名:
# 对所有列进行重命名
df.columns = ['new_A', 'new_B', 'new_C']
在上述示例代码中,使用 columns 属性将所有列名修改为 ‘new_A’、‘new_B’ 和 ‘new_C’。
注意,rename() 方法会返回一个新的 DataFrame,而原始的 DataFrame 不会被修改。如果要在原始的 DataFrame 上进行修改,则可以将 inplace 参数设置为 True inplace=True。例如:
# 对所有列进行重命名并在原始 DataFrame 上进行修改
df.rename(columns={'A': 'new_A', 'B': 'new_B', 'C': 'new_C'}, inplace=True)
以上示例代码将在原始的 DataFrame 上将所有列名修改为 ‘new_A’、‘new_B’ 和 ‘new_C’。
5.9 dataframe索引列相关操作
在 Pandas 中,索引列(Index)是一种非常重要的数据结构,可以用来对数据进行标识、分组、合并等操作。以下是一些常用的索引列相关操作:
- (1)设置索引列:使用
set_index()函数可以设置某一列为索引列,例如:
import pandas as pd# 创建一个 DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
print(df)# 设置索引列
df = df.set_index('A')
print(df)
输出:
A B C
0 1 4 7
1 2 5 8
2 3 6 9B C
A
1 4 7
2 5 8
3 6 9
- (2)重置索引列:使用
reset_index()函数可以将索引列恢复为普通列,例如:
# 重置索引列
df = df.reset_index()
print(df)
输出:
A B C
0 1 4 7
1 2 5 8
2 3 6 9
- (3)获取索引列:使用
df.index属性可以获取 DataFrame 的索引列,例如:
# 获取索引列
index_col = df.index
print(index_col)
输出:
Int64Index([1, 2, 3], dtype='int64', name='A')
- (4)重命名索引列:使用
rename_axis()函数可以重命名索引列的名称,例如:
# 重命名索引列
df = df.rename_axis('ID')
print(df)
输出:
B C
ID
1 4 7
2 5 8
3 6 9
- (5)多级索引::可以使用多个列作为索引列,形成多级索引,例如:
# 创建一个 DataFrame
df = pd.DataFrame({'A': ['a', 'a', 'b', 'b'], 'B': ['c', 'd', 'c', 'd'], 'C': [1, 2, 3, 4]})
print(df)# 设置多级索引
df = df.set_index(['A', 'B'])
print(df)输出:
A B C
0 a c 1
1 a d 2
2 b c 3
3 b d 4C
A B
a c 1d 2
b c 3d
5.10 dataframe排序相关操作
在 Pandas 中,可以使用 sort_values() 函数对 DataFrame 进行排序,以下是一些常用的排序操作:
- (1)索引排序:可以使用
sort_index()函数对 DataFrame 进行索引排序,例如:
# 创建一个 DataFrame
df = pd.DataFrame({'A': [3, 2, 1], 'B': [6, 5, 4], 'C': [9, 8, 7]})# 索引排序
df = df.sort_index()
print(df)
输出:
A B C
0 3 6 9
1 2 5 8
2 1 4 7- (2)按某列升序排序:使用
sort_values()函数,并指定ascending=True,可以进行升序排序,例如:
# 升序排序
df = df.sort_values(by='A', ascending=True)
print(df)
输出:
A B C
2 1 4 7
1 2 5 8
0 3 6 9
- (3)按某列降序排序:使用
sort_values()函数,并指定ascending=False,可以进行降序排序,例如:
# 降序排序
df = df.sort_values(by='B', ascending=False)
print(df)
输出:
A B C
0 3 6 9
1 2 5 8
2 1 4 7
- (4)多列排序:使用
sort_values()函数,并指定多个列名,可以对多个列进行排序,例如:
# 多列排序
df = df.sort_values(by=['A', 'B'], ascending=[True, False])
print(df)
输出:
A B C
2 1 4 7
1 2 5 8
0 3 6 9
- (5)按照指定值排序:可以使用
nlargest()或nsmallest()函数,按照指定列中的最大或最小值进行排序,例如:
# 按照值排序
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})
df = df.set_index('A')# 按照 B 列中的最大值进行排序
df = df.nlargest(3, 'B')
print(df)# 按照 C 列中的最小值进行排序
df = df.nsmallest(3, 'C')
print(df)输出:
# 按照 B 列中的最大值进行排序B C
A
3 6 9
2 5 8
1 4 7# 按照 C 列中的最小值进行排序B C
A
1 4 7
2 5 8
3 6 9其中,nlargest()、nsmallest()函数的参数说明如下:
n:指定返回的行数;
columns:指定用于排序的列;
frac:指定返回的行数所占原 DataFrame 的比例;
replace:指定是否允许重复采样,默认为 False;
- (6)随机排序:可以使用
sample()函数对 DataFrame 进行随机排序,例如:
# 随机排序
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})# 随机排序
df = df.sample(frac=1)
print(df)
输出:
A B C
2 3 6 9
1 2 5 8
0 1 4 7
sample() 函数的参数random_state:指定随机种子,用于复现随机结果。
如果上述排序要在原dataframe上操作inplace:是否在原数据框排序,即是否覆盖原 DataFrame,默认为 False。
注意,排序同样是返回一个新的 DataFrame,而原始的 DataFrame 不会被修改。inplace:是否在原数据框排序,即是否覆盖原 DataFrame,默认为 False。如果要在原始的 DataFrame 上进行修改,则可以将 inplace 参数设置为 True inplace=True。
6.dataframe数据运算
pandas中DataFrame数据运算主要包括以下几类:
6.1算术运算
加、减、乘、除等运算符号用于数据框之间的运算。
import pandas as pddf1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2 = pd.DataFrame({'A': [10, 20, 30], 'B': [40, 50, 60]})#加法运算
df_add = df1 + df2
print(df_add)#减法运算
df_sub = df1 - df2
print(df_sub)#乘法运算
df_mul = df1 * df2
print(df_mul)#除法运算
df_div = df1 / df2
print(df_div)
6.2统计运算
- (1)pandas库来进行描述性统计分析
pandas 提供了多种方法来进行描述性统计分析,以下是一些常用的方法:
- describe(): 生成一份包含统计信息的 DataFrame,包括计数、均值、标准差、最小值、下四分位数、中位数、上四分位数和最大值。
- mean(): 计算每个数值列的平均值。
- median(): 计算每个数值列的中位数。
- mode(): 计算每个数值列的众数。
- std(): 计算每个数值列的标准差。
- min(): 计算每个数值列的最小值。
- max(): 计算每个数值列的最大值。
- quantile(): 计算每个数值列的分位数。
这些方法都是基于 Pandas DataFrame 的列进行操作的,可以对整个 DataFrame 或部分 DataFrame 的列进行操作。
例如,以下代码将使用 describe() 方法对 DataFrame 的数值列进行描述性统计分析:
import pandas as pd# 创建一个 DataFrame
data = {'A': [1, 2, 3, 4, 5],'B': [2, 4, 6, 8, 10],'C': [3, 6, 9, 12, 15]}
df = pd.DataFrame(data)# 使用 describe() 方法进行描述性统计分析
print(df.describe())
输出:
A B C
count 5.000000 5.000000 5.000000
mean 3.000000 6.000000 9.000000
std 1.581139 3.162278 4.743416
min 1.000000 2.000000 3.000000
25% 2.000000 4.000000 6.000000
50% 3.000000 6.000000 9.000000
75% 4.000000 8.000000 12.000000
max 5.000000 10.000000 15.000000
该结果展示了 DataFrame 中数值列的计数、均值、标准差、最小值、下四分位数、中位数、上四分位数和最大值。
- (2)对数据框中的数据进行统计分析,例如求和、均值、方差、标准差等。示例代码如下:
import pandas as pddf = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})#求和
df_sum = df.sum()
print(df_sum)#均值
df_mean = df.mean()
print(df_mean)#方差
df_var = df.var()
print(df_var)#标准差
df_std = df.std()
print(df_std)
6.3行列运算
- (1)可以对数据框的所有行列进行运算。
import pandas as pddf = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})#对列求和
df_sum_columns = df.sum(axis=0)
print(df_sum_columns)#对行求和
df_sum_rows = df.sum(axis=1)
print(df_sum_rows)
- (2)指定列之间的运算
DataFrame中可以对不同列进行加减乘除等运算,结果将保存为一个新的列。
import pandas as pd#创建DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)#对A列和B列进行加法运算
df['C'] = df['A'] + df['B']#对A列和B列进行乘法运算
df['D'] = df['A'] * df['B']#打印结果
print(df)
- (3)指定行之间的运算
可以使用apply()方法对DataFrame中的每一行进行运算,结果将保存为一个新的列。
import pandas as pd#创建DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)#对每一行进行加法运算
df['C'] = df.apply(lambda row: row['A'] + row['B'], axis=1)#对每一行进行乘法运算
df['D'] = df.apply(lambda row: row['A'] * row['B'], axis=1)#打印结果
print(df)
- (4)元素级运算
DataFrame中的元素级运算可以使用类似NumPy中的函数进行运算,例如numpy.sin()等。
import pandas as pd
import numpy as np#创建DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)#对A列进行元素级sin函数运算
df['C'] = np.sin(df['A'])#对B列进行元素级cos函数运算
df['D'] = np.cos(df['B'])#打印结果
print(df)
6.4聚合运算
可以对数据框进行分组聚合计算。
- (1)groupby运算
groupby可以将DataFrame中的数据按照指定的列进行分组,然后对分组后的数据进行聚合运算。
import pandas as pd#创建DataFrame
data = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'], 'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'], 'C': [1, 2, 3, 4, 5, 6, 7, 8], 'D': [9, 10, 11, 12, 13, 14, 15, 16]}
df = pd.DataFrame(data)#对A列进行groupby运算,并对C列和D列进行聚合运算(求平均值)
grouped = df.groupby(['A']).agg({'C': 'mean', 'D': 'mean'})#打印结果
print(grouped)
- (2)merge运算
merge运算可以将两个DataFrame按照指定的列进行合并,类似于SQL中的JOIN操作。
import pandas as pd#创建DataFrame
df1 = pd.DataFrame({'key': ['foo', 'bar', 'baz', 'qux'], 'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['foo', 'bar', 'baz', 'qux'], 'value': [5, 6, 7, 8]})#合并DataFrame
merged = pd.merge(df1, df2, on='key')#打印结果
print(merged)
6.5merge运算扩展
在pandas中,可以使用merge()函数实现DataFrame的合并。下面给出几个示例:
- (1)纵向合并两个DataFrame:pd.concat([df1, df2])
import pandas as pd#创建两个DataFrame
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],'B': ['B4', 'B5', 'B6', 'B7'],'C': ['C4', 'C5', 'C6', 'C7'],'D': ['D4', 'D5', 'D6', 'D7']})#纵向合并两个DataFrame
df = pd.concat([df1, df2])
- (2)横向合并两个DataFrame:pd.merge(df1, df2, on=‘key’)
import pandas as pd#创建两个DataFrame
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})#横向合并两个DataFrame
df = pd.merge(df1, df2, on='key')
- (3)使用多个键合并DataFrame:pd.merge(df1, df2, on=[‘key1’, ‘key2’])
import pandas as pd#创建两个DataFrame
df1 = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],'key2': ['K0', 'K1', 'K0', 'K1'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})df2 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],'key2': ['K0', 'K0', 'K0', 'K0'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})#使用多个键合并DataFrame
df = pd.merge(df1, df2, on=['key1', 'key2'])
pandas中的merge()函数还支持多种合并方式(如左连接、右连接、内连接、外连接等)。下面是每种连接方式的示例:
- (4)左连接(left join):pd.merge(df1, df2, on=‘key’, how=‘left’)
左连接返回左侧数据集中所有的行,同时返回与右侧数据集中匹配的行。如果在右侧数据集中没有匹配的行,则返回空值。
import pandas as pddf1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],'value': [5, 6, 7, 8]})left_join = pd.merge(df1, df2, on='key', how='left')
print(left_join)
- (5)右连接(right join): pd.merge(df1, df2, on=‘key’, how=‘right’)
右连接返回右侧数据集中所有的行,同时返回与左侧数据集中匹配的行。如果在左侧数据集中没有匹配的行,则返回空值。
import pandas as pddf1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],'value': [5, 6, 7, 8]})right_join = pd.merge(df1, df2, on='key', how='right')
print(right_join)
- (6)内连接(inner join):pd.merge(df1, df2, on=‘key’, how=‘inner’)
内连接返回左侧和右侧数据集中都存在的行。
import pandas as pddf1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],'value': [5, 6, 7, 8]})inner_join = pd.merge(df1, df2, on='key', how='inner')
print(inner_join)
- (7)外连接(outer join):pd.merge(df1, df2, on=‘key’, how=‘outer’)
外连接返回左侧和右侧数据集中所有的行,如果某一侧数据集中没有匹配的行,则返回空值。
import pandas as pddf1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],'value': [5, 6, 7,8]})outer_join = pd.merge(df1, df2, on='key', how='outer')
print(outer_join)
6.6其他运算
包括透视表运算、窗口函数运算等。
import pandas as pddf = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]})#透视表运算
df_pivot = pd.pivot_table(df, values=['B', 'C'], index='A', aggfunc='sum')
print(df_pivot)#窗口函数运算
df_roll_mean = df.rolling(window=2).sum()
print(df_roll_mean)
7.dataframe 时间序列基本操作
DataFrame在时间序列分析中是非常重要的工具,可以轻松处理时间序列数据,如按时间排序、统计时间范围内的数据、时间偏移等等。以下是一些时间序列分析的示例:
7.1生成时间序列数据
import pandas as pd
import numpy as nprng = pd.date_range('1/1/2020', periods=10, freq='D')
# rng = pd.date_range(start='2022-01-01', end='2022-12-31', freq='D')
df = pd.DataFrame({'date': rng, 'value': np.random.randn(10)})
这里生成了一个包含10天数据的DataFrame,其中date列为时间序列,value列为随机数列。
7.2按时间排序
#按照date列升序排列
df_ascend = df.sort_values('date')#按照date列降序排列
df_descend = df.sort_values('date', ascending=False)#打印排序结果
print("df_ascend:")
print(df_ascend)
print("df_descend:")
print(df_descend)
7.3统计时间范围内的数据
df.loc[(df['date'] >= '2020-01-03') & (df['date'] <= '2020-01-07')]
这里选取了2020年1月3日至7日之间的数据。
7.4时间偏移
df['shifted'] = df['value'].shift(1)
这里将value列向下平移了一个单位,生成了一个新的列shifted。
7.5时间重采样
df.set_index('date').resample('W').mean()
这里按照每周对数据进行重采样,并计算每周的平均值。
7.6移动窗口函数
df['rolling_mean'] = df['value'].rolling(window=3).mean()
这里计算了value列的移动平均值,窗口大小为3。
7.7时间差
df['diff'] = df['date'].diff()#计算两个日期之间的天数
#df['diff'] = (df['date2'] - df['date1']).dt.days
这里计算了每一天和前一天之间的时间差。
7.8时间索引
df = df.set_index('date')
这里将date列设置为索引。
7.9时间戳转换
-(1)pd.to_datetime() 是 pandas 中的一个函数,用于将字符串或数值型的时间数据转换为 pandas 中的 datetime 类型。该函数的常用参数如下:
arg:表示需要转换的时间数据,可以是单个时间数据或时间数据列表或 Series 或 DataFrame。
format:表示需要转换的时间数据的格式,通常只有在时间数据的格式与默认格式不一致时才需要指定。
errors:表示错误处理方式,有两个可选值,分别是 raise 和 coerce,默认值为 raise。如果为 raise,则在转换出现错误时抛出异常;如果为 coerce,则将转换错误的数据设置为 NaT(pandas 中的缺失值)。
下面是几个示例:
import pandas as pd# 示例1:将字符串型时间数据转换为 datetime 类型
str_time = '2023-03-10 12:00:00'
datetime_time = pd.to_datetime(str_time)
print(datetime_time)# 示例2:将数值型时间数据转换为 datetime 类型
int_time = 20230310
datetime_time = pd.to_datetime(int_time, format='%Y%m%d')
print(datetime_time)# 示例3:将时间数据列表转换为 datetime 类型
time_list = ['2023-03-03 12:00:00', '2023-03-10 13:00:00', '2023-03-17 14:00:00']
datetime_list = pd.to_datetime(time_list)
print(datetime_list)# 示例4:将 DataFrame 中的某一列int列转换为 datetime 类型
df = pd.DataFrame({'Date': [20230303, 20230310', '20230317'], 'value': [1, 2, 3]})
df['Date'] = pd.to_datetime(df['Date'], format='%Y%m%d')
print(df)
在上面的示例中,分别使用 pd.to_datetime() 函数将不同类型的时间数据转换为 datetime 类型,其中 format 参数用于指定时间数据的格式。
-
第一个示例中的时间数据格式默认符合 datetime 标准格式,因此无需指定 format 参数。
-
第二个示例中的时间数据为整型,需要指定时间格式。
-
第三个示例中的时间数据为列表,直接调用 pd.to_datetime() 函数即可。
-
最后一个示例中,将 DataFrame 中的某一列转换为 datetime 类型,并将结果更新到原 DataFrame 中。
-
(2)在 Python 中,可以使用
datetime 模块将时间数据从 int 或字符串类型转换为 datetime 类型。datetime 类型表示一个具体的日期和时间,可以方便地进行日期和时间的计算和比较。
下面是一个将 int 类型时间数据转换为 datetime 类型的示例:
import datetime# 将 int 类型时间数据转换为 datetime 类型
int_time = 20220313 # 表示 2022 年 3 月 13 日
datetime_time = datetime.datetime.strptime(str(int_time), '%Y%m%d')
print(datetime_time)
在上面的代码中,首先定义了一个 int 类型的时间数据 int_time,表示 2022 年 3 月 13 日。然后使用 strptime() 函数将 int_time 转换为 datetime 类型的数据。其中 %Y%m%d 是 datetime 类型的时间格式,对应的是 int_time 的格式。转换后,将结果打印输出。
需要注意的是,strptime() 函数将字符串解析成 datetime 对象时,需要指定正确的时间格式。上面的示例中,%Y%m%d表示年月日的顺序,如果时间数据的格式与此不同,需要根据实际情况修改时间格式。
如果时间数据的类型是字符串,可以直接使用 datetime.datetime.strptime() 函数将其转换为 datetime 类型。例如:
# 将字符串类型时间数据转换为 datetime 类型
str_time = '2022-03-13 12:00:00'
datetime_time = datetime.datetime.strptime(str_time, '%Y-%m-%d %H:%M:%S')
print(datetime_time)
在上面的代码中,将一个字符串类型的时间数据 str_time 转换为 datetime 类型的数据,时间格式为 %Y-%m-%d %H:%M:%S,转换后将结果打印输出。
7.10按照时间周期进行统计
df.groupby(pd.Grouper(freq='M')).sum()
这里按照每个月进行数据统计。
7.11提取年、月、日等信息
- 1.若date为索引且格式为datetime,则可直接进行年、月、日、周、季等信息的提取
df['year'] = df.index.year
df['month'] = df.index.month
df['day'] = df.index.day
df['weekday'] = df.index.weekday
df['quarter'] = df.index.quarter
- 2.若date为dataframe的一列且格式不为datetime,则可按照如下方式进行年、月、日、周、季等信息的提取
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday
df['quarter'] = df['date'].dt.quarter
7.12按照日期数据进行分组
df.groupby('year').mean()
7.13时区转换
df = df.tz_localize('UTC').tz_convert('US/Pacific')
这里将时区从UTC转换为美国太平洋时区。
7.14绘制时间序列图
df.plot(x='date', y='value')
7.15时间运算
1.在pandas中,可以使用pd.Timedelta对象来进行时间加减运算。下面是一些示例:
假设有一个日期时间列df[‘datetime’],可以使用pd.Timedelta对象将其加上一定的时间:
import pandas as pd# 创建一个示例DataFrame
df = pd.DataFrame({'datetime': ['2023-03-14 12:00:00', '2023-03-14 13:00:00', '2023-03-14 14:00:00']})
df['datetime'] = pd.to_datetime(df['datetime']) # 将字符串转换为日期时间格式# 将日期时间列加上10分钟
df['datetime'] = df['datetime'] + pd.Timedelta(minutes=10)
print(df)
输出:
datetime
0 2023-03-14 12:10:00
1 2023-03-14 13:10:00
2 2023-03-14 14:10:00
同样,也可以将日期时间列减去一定的时间:
# 将日期时间列减去5天
df['datetime'] = df['datetime'] - pd.Timedelta(days=5)
print(df)
输出:
datetime
0 2023-03-09 12:10:00
1 2023-03-09 13:10:00
2 2023-03-09 14:10:00
除了分钟和天数,还可以使用其他的时间单位,例如秒、小时、周等等。具体的时间单位可以参考pd.Timedelta的文档。
2.在Python中,还可以使用datetime模块和timedelta类来进行日期和时间的相关运算。以下是一些示例:
- (1)日期加减
from datetime import datetime, timedelta# 当前时间
now = datetime.now()# 昨天
yesterday = now - timedelta(days=1)# 明天
tomorrow = now + timedelta(days=1)# 一周后
next_week = now + timedelta(weeks=1)- (2)时间差计算
from datetime import datetime# 两个时间之差
start_time = datetime(2022, 3, 14, 12, 0, 0)
end_time = datetime(2022, 3, 14, 14, 30, 0)
duration = end_time - start_time
print(duration.total_seconds()) # 输出时间差的总秒数-
(1)日期加减
-
(1)日期加减
以上是一些时间序列分析的示例,pandas在时间序列分析中提供了丰富的功能,可以满足不同的需求。
8.dataframe数据可视化
8.1使用pandas自带的可视化工具
在Python中,pandas自带了一些可视化工具,可以方便地对DataFrame数据进行可视化。下面给出几个使用pandas自带可视化工具绘制图表的示例:
- 1.绘制折线图
import pandas as pd#创建数据集
data = {'year': [2010, 2011, 2012, 2013, 2014, 2015],'sales': [5, 7, 3, 4, 6, 8]}
df = pd.DataFrame(data)#绘制折线图
df.plot(x='year', y='sales')
- 2.绘制柱状图
import pandas as pd#创建数据集
data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen'],'population': [2154, 2424, 1404, 1211]}
df = pd.DataFrame(data)# 绘制柱状图
df.plot(kind='bar', x='city', y='population')
- 3.绘制散点图
import pandas as pd#创建数据集
data = {'height': [165, 170, 175, 180, 185],'weight': [55, 60, 65, 70, 75]}
df = pd.DataFrame(data)#绘制散点图
df.plot(kind='scatter', x='height', y='weight')
- 4.绘制箱线图
import pandas as pd#创建数据集
data = {'gender': ['Male', 'Male', 'Female', 'Female'],'height': [180, 175, 165, 170]}
df = pd.DataFrame(data)#绘制箱线图
df.boxplot(by='gender', column='height')
pandas自带的可视化工具可以方便地对DataFrame数据进行可视化,但其可视化效果可能不如其他专业的可视化库(如matplotlib和seaborn)。因此,在实际使用中,我们需要根据具体情况选择合适的可视化工具。
8.2使用matplotlib库
import pandas as pd
import matplotlib.pyplot as plt#创建DataFrame数据
data = {'name': ['Tom', 'Jerry', 'Mike', 'Lucy'],'score': [80, 75, 90, 85],'age': [20, 21, 22, 20]}
df = pd.DataFrame(data)#绘制柱状图
plt.bar(df['name'], df['score'])
plt.xlabel('Name')
plt.ylabel('Score')
plt.title('Student Scores')
plt.show()#绘制散点图
plt.scatter(df['age'], df['score'])
plt.xlabel('Age')
plt.ylabel('Score')
plt.title('Student Scores')
plt.show()#绘制折线图
plt.plot(df['name'], df['score'], marker='o')
plt.xlabel('Name')
plt.ylabel('Score')
plt.title('Student Scores')
plt.show()
8.3使用seaborn库
- 1.使用seaborn库绘制柱状图
import pandas as pd
import seaborn as sns#创建数据集
data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen'],'population': [2154, 2424, 1404, 1211]}
df = pd.DataFrame(data)#绘制柱状图
sns.barplot(x='city', y='population', data=df)
plt.title('Population Data')
plt.show()
- 2.使用seaborn库绘制散点图
import pandas as pd
import seaborn as sns#创建数据集
data = {'height': [165, 170, 175, 180, 185],'weight': [55, 60, 65, 70, 75]}
df = pd.DataFrame(data)#绘制散点图
sns.scatterplot(x='height', y='weight', data=df)
plt.title('Height and Weight Data')
plt.show()
- 3.使用seaborn库绘制箱线图
import pandas as pd
import seaborn as sns#创建数据集
data = {'gender': ['Male', 'Male', 'Female', 'Female'],'height': [180, 175, 165, 170]}
df = pd.DataFrame(data)#绘制箱线图
sns.boxplot(x='gender', y='height', data=df)
plt.title('Height Data')
plt.show()
8.4 使用matplotlib库绘制拼接子图
在 Python 中,可以使用 Matplotlib 库来绘制拼接子图。Matplotlib 提供了 subplot() 函数,该函数可以将画布分割为多个子区域,并在每个子区域中绘制图形。
以下是一个简单的示例,演示如何使用 subplot() 函数绘制拼接子图:
import matplotlib.pyplot as plt
import numpy as np# 生成数据
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.tan(x)
y4 = np.arcsin(x)
# 绘制子图
plt.figure(figsize=(8, 6))plt.subplot(2, 2, 1)
plt.plot(x, y1)
plt.title('sin(x)')plt.subplot(2, 2, 2)
plt.plot(x, y2)
plt.title('cos(x)')plt.subplot(2, 2, 3)
plt.plot(x, y3)
plt.title('tan(x)')plt.subplot(2, 2, 4)
plt.plot(x, y4)
plt.title('arcsin(x)')plt.tight_layout()
plt.show()
上述代码中,我们首先使用 NumPy 库生成了三个函数曲线的数据。然后,我们使用 subplot() 函数将画布分割为 2 行 2 列的四个子区域,并在每个子区域中绘制一个函数曲线。subplot() 函数的前两个参数分别指定子区域的行数和列数,第三个参数指定当前子区域的索引(从左上角开始计数)。在循环中,我们先使用 plot() 函数绘制曲线,然后使用 title() 函数设置子图的标题。最后,我们使用 tight_layout() 函数调整子图之间的间距,并使用 show() 函数显示图形。输出结果如下图所示:
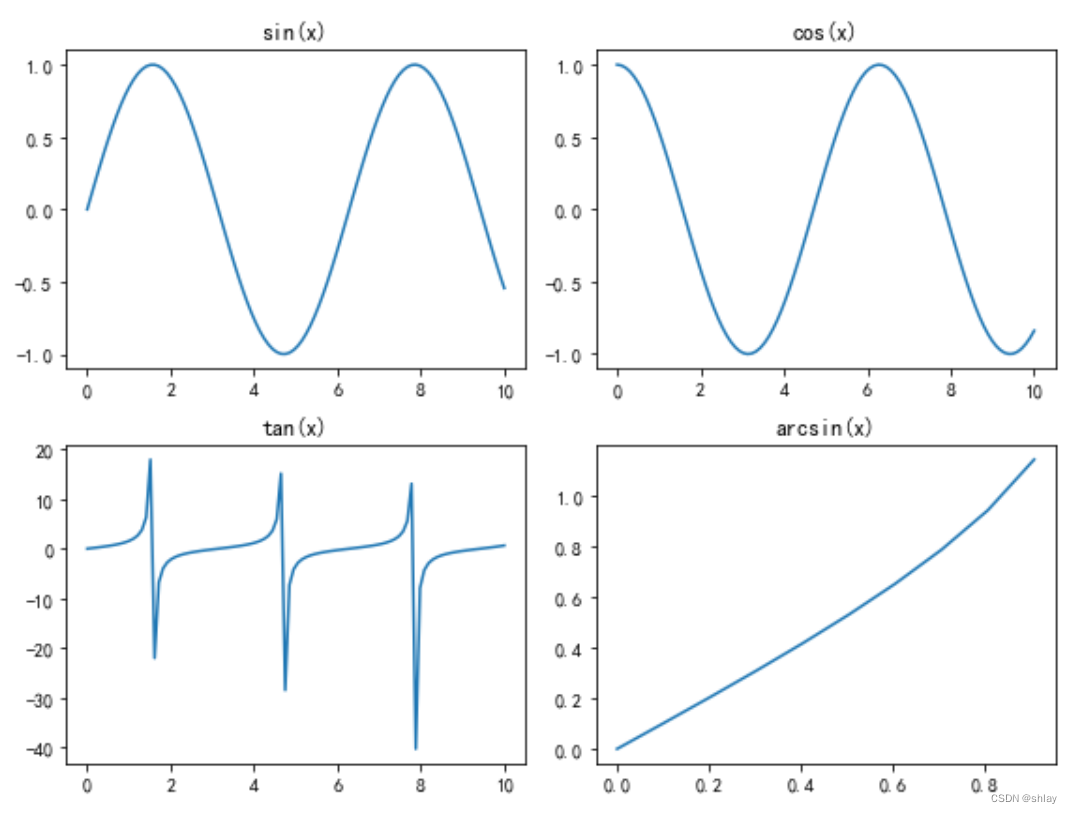
以上示例只是其中一部分,数据可视化的方式和种类非常多,具体使用哪种方式取决于数据的特点和需要展示的内容。
相关文章:
统计软件与数据分析--Lesson3
dataframe数据常用python操作dataframe数据常用知识点1.创建dataframe1.1使用字典创建DataFrame:1.2使用列表创建DataFrame:1.3使用numpy数组创建DataFrame:1.4从TXT文件中创建DataFrame:1.5从CSV文件中创建DataFrame:…...

竞赛无人机搭积木式编程——以2022年TI电赛送货无人机一等奖复现为例学习(7月B题)
在学习本教程前,请确保已经学习了前4讲中无人机相关坐标系知识、基础飞行控制函数、激光雷达SLAM定位条件下的室内定点控制、自动飞行支持函数、导航控制函数等入门阶段的先导教程。 同时用户在做二次开发自定义的飞行任务时,可以参照第5讲中2021年国赛植…...

oracle基础操作
oracle基础操作语法: 1、查询会话 SQL> select count(*) from v$session;2、增大连接数 SQL> alter system set processes5000 scope spfile;3、增大会话数 SQL> alter system set sessions7552 scopespfile;4、查询 参数: SQL> sho…...

python爬虫数据写入excel
在Jmeter118中描述了如何将接口请求的响应数据写入到csv中,同样的接口如果采用python写法,会简便很多,主要是用到了python中的pandas库#爬取展台数据import requestsimport pandas as pdurlhttps://ficonline.cfaa.cn/Exhibition/searchExhib…...
优思学院|六西格玛DMAIC,傻傻搞不清?
DMAIC还是搞不清? DMAIC是一个用于过程改进和六西格玛的问题解决方法论。它是以下五个步骤的缩写: 定义(Define):明确问题,设定项目的目标和目的。绘制流程图,并收集数据,以建立未来…...
【Linux】网络编程套接字(下)
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...

【Linux网络】网络编程套接字(上)
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...
十二、51单片机之DS1302
1、DS1302简介 (1)详情查看数据手册。 (2)管角描述 管教名称功能1Vcc2双供电配置中的主电源供电引脚2X1与标准的32.768kHz晶振相连。用于ds1302记时。3X24GND电源地5CE输入信号,CE信号在读写时必须保持高电平6I/O输入/推挽输出I/O,是三线接口的双向数…...
ChatGPT-4震撼发布
3月15日消息,美国当地时间周二,人工智能研究公司OpenAI发布了其下一代大型语言模型GPT-4,这是其支持ChatGPT和新必应等应用程序的最新AI大型语言模型。该公司表示,该模型在许多专业测试中的表现超出了“人类水平”。GPT-4, 相较于…...
HTML樱花飘落
樱花效果 FOR YOU GIRL 以梦为马,不负韶华 LOVE YOU FOREVER 实现代码 <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html><head><meta http-equiv"…...

力扣-排名靠前的旅行者
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:1407. 排名靠前的旅行者二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其…...

马上要面试了,还有八股文没理解?让ChatGPT来给你讲讲吧——如何更好使用ChatGPT?
最近这段时间 ChatGPT 掀起了一阵 AI 热潮,目前来看网上大部分内容都是在调戏 AI,很少有人写如何用 ChatGPT 做正事儿。 作为一个大部分知识都是从搜索引擎和 GitHub 学来的程序员,第一次和 ChatGPT 促膝长谈后,基本认定了一个事…...

怎么避免服务内存溢出?
在高并发、高吞吐的场景下,很多简单的事情,会变得非常复杂,而很多程序并没有在设计时针对高并发高吞吐量的情况做好内存管理。 自动内存管理机制的实现原理 做内存管理,主要考虑申请内存和内存回收两部分。 申请内存的步骤&…...
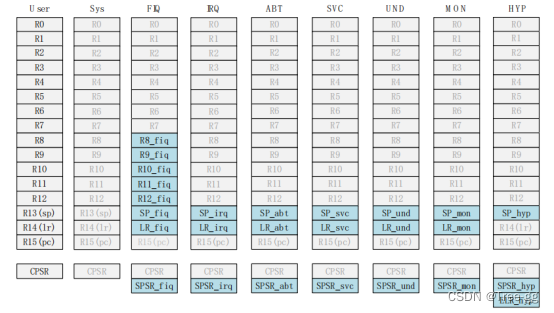
01_I.MX6U芯片简介
目录 I.MX6芯片简介 Corterx -A7架构简介 Cortex-A处理器运行模型 Cortex-A 寄存器组 IMX6U IO表示形式 I.MX6芯片简介 ARM Cortex-A7内核可达900 MHz,128 KB L2缓存。 并行24bit RGB LCD接口,可以支持1366*768分辨率。 3.8/10/16位 并行摄像头传感器接口(CS…...
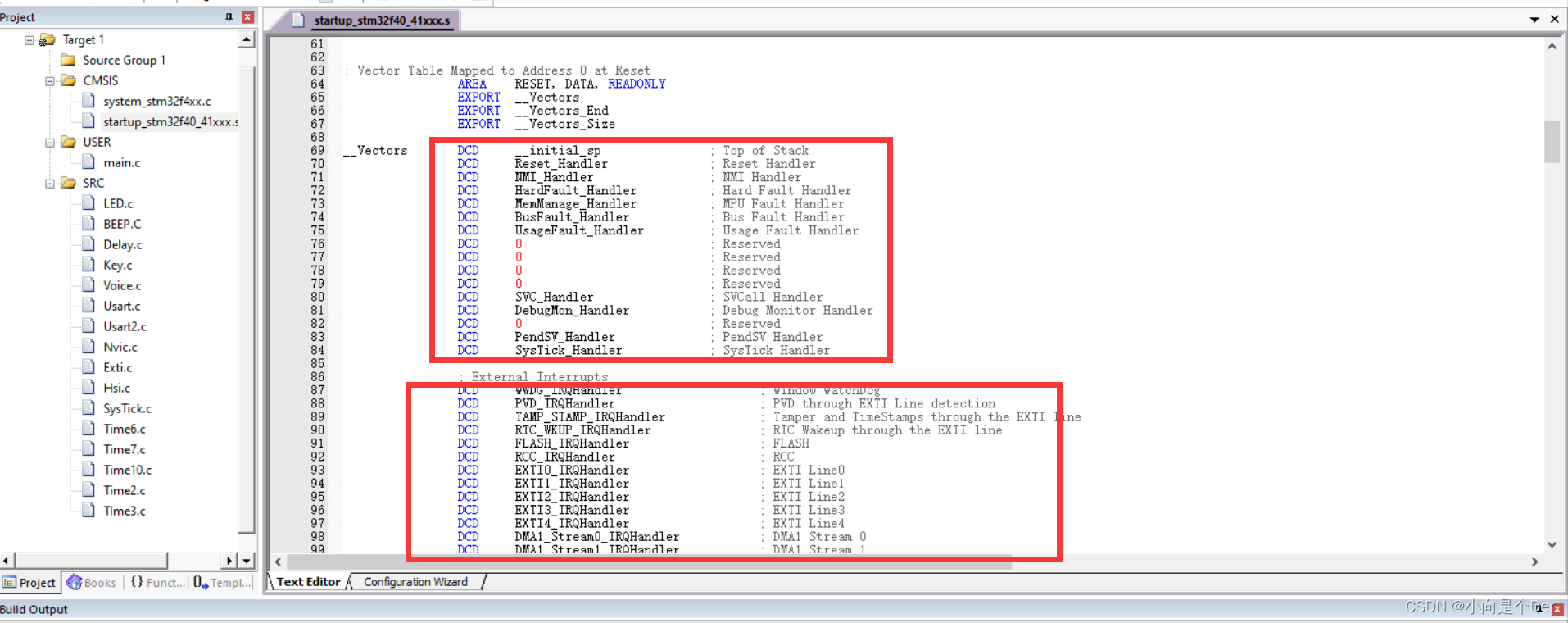
嵌入式学习笔记——STM32的中断控制体系
STM32的中断控制体系前言STM32中断的概念中断类型中断控制常用控制函数区分中断源与中断信号配置中断优先级分组问题中断使能中断服务函数总结前言 上一篇中,借着串口接受的问题,简要说了一下串口中断的作用和用法,本文将对STM32的中断控制体…...
如何发布自己的npm包
一、什么是npm npm是随同nodejs一起安装的javascript包管理工具,能解决nodejs代码部署上的很多问题,常见的使用场景有以下几种: ①.允许用户从npm服务器下载别人编写的第三方包到本地使用。 ②.允许用户从npm服务器下载并安装别人编写的命令…...

Qt QProcess管道命令带“|”多命令执行获取stdout输出问题总结
问题描述: 在Qt中,使用system和QProcess执行命令,system执行的命令,我们通常不需要获取stdout的输出结果,所以只需要得到返回结果,知道成功失败即可。 而用到QProcess,多半是要获取输出的返回信息。 这里的返回信息只要是标准输出的即可,当然了,也可以是别的channe…...
【JavaEE进阶篇2】spring基于注解开发1
在上一篇文章当中,我们提到了怎样使用spring来创建一个bean对象。下面,我们继续来研究一下,更加优胜的开发方式:基于注解开发【JavaEE进阶篇1】认识Spring、认识IoC、使用spring创建对象_革凡成圣211的博客-CSDN博客springIoc、使…...

统一登录验证统一返回格式统一异常处理的实现
统一登录验证&统一返回格式&统一异常处理的实现 一、用户登录权限效验1.1 最初的用户登录验证1.2 Spring AOP 用户统一登录验证的问题1.3 Spring 拦截器1.3.1 准备工作1.3.2 自定义拦截器1.3.3 将自定义拦截器加入到系统配置1.4 拦截器实现原理1.4.1 实现原理源码分析1…...

【建议收藏】华为OD面试,什么场景下会使用到kafka,消息消费中需要注意哪些问题,kafka的幂等性,联合索引等问题
文章目录 华为 OD 面试流程一、什么场景下会使用到 kafka二、消息消费中需要注意哪些问题三、怎么处理重复消费四、kafka 的幂等性怎么处理的五、kafka 会怎么处理消费者消费失败的问题六、数据库设计中,你会如何去设计一张表七、联合索引有什么原则华为 OD 面试流程 机试:三…...

Qwen3-4B Instruct-2507企业级落地:集成至内部OA系统实现自然语言工单处理
Qwen3-4B Instruct-2507企业级落地:集成至内部OA系统实现自然语言工单处理 1. 引言:当工单处理遇上大语言模型 想象一下这个场景:公司内部OA系统的客服工单界面,每天涌入上百条来自不同部门的请求。有员工问:“我的打…...

3种方案永久激活IDM:开源工具实现无限制使用的完整指南
3种方案永久激活IDM:开源工具实现无限制使用的完整指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 作为互联网上最受欢迎的下载管理器之一&#…...

OpCore-Simplify:从8小时到30分钟,智能OpenCore EFI配置的终极指南
OpCore-Simplify:从8小时到30分钟,智能OpenCore EFI配置的终极指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在开源系统…...

告别重复劳动:用快马AI生成自动化脚本,提升日常运维效率三倍
告别重复劳动:用快马AI生成自动化脚本,提升日常运维效率三倍 日常运维工作中,最让人头疼的就是那些重复性操作。比如每周都要手动检查几十台服务器的配置文件状态,或者挨个备份关键配置。这种工作不仅枯燥,还容易出错…...

DownKyi视频存储方案全攻略:从需求分析到跨设备同步的完整指南
DownKyi视频存储方案全攻略:从需求分析到跨设备同步的完整指南 【免费下载链接】downkyicore 哔哩下载姬(跨平台版)downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视…...

如何在Windows系统上高效运行Android应用:告别模拟器的5个实用技巧
如何在Windows系统上高效运行Android应用:告别模拟器的5个实用技巧 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在数字化工作与娱乐日益融合的今天&…...

如何打破小米与Home Assistant的生态壁垒?ha_xiaomi_home给你答案
如何打破小米与Home Assistant的生态壁垒?ha_xiaomi_home给你答案 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 想象一下这样的场景:你已经拥…...

Windows苹果设备驱动终极指南:3分钟解决iPhone/iPad连接难题
Windows苹果设备驱动终极指南:3分钟解决iPhone/iPad连接难题 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.com/…...

如何判断重庆SEO优化公司的实力_重庆SEO优化服务有哪些特点
如何判断重庆SEO优化公司的实力_重庆SEO优化服务有哪些特点 在当前数字化营销的时代,一个企业的在线表现直接影响到其市场竞争力。而在重庆这个经济发展迅速的城市,SEO优化服务显得尤为重要。如何判断一家重庆SEO优化公司的实力,又有哪些特点…...

Pi0具身智能v1快速原型验证:用浏览器交互,迭代你的机器人UI/UX设计
Pi0具身智能v1快速原型验证:用浏览器交互,迭代你的机器人UI/UX设计 1. 为什么需要快速原型验证工具 在机器人开发领域,从算法设计到实际部署往往存在巨大鸿沟。传统开发流程中,工程师需要: 编写复杂的仿真环境代码等…...