【Spark On Hive】—— 基于电商数据分析的项目实战


文章目录
- Spark On Hive 详解
- 一、项目配置
- 1. 创建工程
- 2. 配置文件
- 3. 工程目录
- 二、代码实现
- 2.1 Class SparkFactory
- 2.2 Object SparkFactory
Spark On Hive 详解
本文基于Spark重构基于Hive的电商数据分析的项目需求,在重构的同时对Spark On Hive的全流程进行详细的讲解。
一、项目配置
1. 创建工程
首先,创建一个空的Maven工程,在创建之后,我们需要检查一系列配置,以保证JDK版本的一致性。同时,我们需要创建出Scala的编码环境。具体可参考以下文章:
Maven工程配置与常见问题解决指南
和
Scala01 —— Scala基础
2. 配置文件
2.1 在Spark On Hive的项目中,我们需要有两个核心配置文件。
- pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.ybg</groupId><artifactId>warehouse_ebs_2</artifactId><version>1.0</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spark.version>3.1.2</spark.version><spark.scala.version>2.12</spark.scala.version><hadoop.version>3.1.3</hadoop.version><mysql.version>8.0.33</mysql.version><hive.version>3.1.2</hive.version><hbase.version>2.3.5</hbase.version><jackson.version>2.10.0</jackson.version></properties><dependencies><!-- spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${spark.scala.version}</artifactId><version>${spark.version}</version></dependency><!-- spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${spark.scala.version}</artifactId><version>${spark.version}</version></dependency><!-- spark-hive --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_${spark.scala.version}</artifactId><version>${spark.version}</version></dependency><!-- hadoop-common --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><!-- mysql --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>${mysql.version}</version></dependency><!-- hive-exec --><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>${hive.version}</version><exclusions><exclusion><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId></exclusion></exclusions></dependency><!-- HBase 驱动 --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><!-- jackson-databind --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>${jackson.version}</version></dependency><!-- jackson-databind --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>${jackson.version}</version></dependency></dependencies></project>
- log4j.properties
log4j.properties文件的主要作用是配置日志系统的行为,包括控制日志信息的输出和实现滚动事件日志。
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
----------------------- 滚动事件日志代码 -----------------------
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.DailyRollingFileAppender
log4j.appender.logfile.DatePattern='.'yyyy-MM-dd
log4j.appender.logfile.append=true
---------------------------------------------------------------
log4j.appender.logfile.File=log/spark_first.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
2.2 组件核心配置文件

在工程的resources目录下,需要存放在虚拟机中大数据服务的核心组件的配置文件,以便于Spark On Hive中调用大数据组件服务能够正常进行。
3. 工程目录
二、代码实现
-
创建数据校验方法 check:
用于确保配置项的值有效。
检查值是否为 null。
对字符串类型的值进行非空和正则表达式匹配校验。 -
创建配置设置方法 set:
先校验配置项名称和值的有效性。
使用 SparkConf.set 方法设置有效的配置项和值。 -
单例对象 SparkFactory:
提供基础配置方法,如设置应用名称、主节点等。
提供 baseConfig 方法集中进行基础配置。
提供 end 方法返回配置好的 SparkSession 实例。 -
在 SparkFactory 类中实现上述方法:
定义 build 方法,返回包含 check 和 set 方法的 Builder 对象。
在 Builder 对象中实现各种配置方法,每个方法都调用 set 方法。
使用 SparkSession.builder() 方法在 end 方法中创建并返回 SparkSession 实例。
SparkFactory配置表如下:
配置表
2.1 Class SparkFactory
- 作用:
SparkFactory类的作用是能够工厂化地创建和配置SparkSession实例,通过一系列的set和check方法来确保配置项的有效性和正确性,并最终生成一个配置好的SparkSession实例。 - 注意:我们需要在Spark官网配置页获取所有配置项的标准名称。
- 代码
class SparkFactory {def build():Builder={new Builder {val conf = new SparkConf()/*** 数据校验* @param title 校验主题* @param value 待校验的值* @param regex 若待校验值为字符串,且有特定的规则,那么提供正则表达式进一步验证格式*/private def check(title:String,value:Any,regex:String=null)={if (null == value) {throw new RuntimeException()(s"value for $title null pointer exception")}if(value.isInstanceOf[String]){if(value.toString.isEmpty){throw new RuntimeException(s"value for $title empty string exception")}if(regex!=null){if(!value.toString.matches(regex)){throw new RuntimeException(s"$title is not match regex $regex")}}}}/*** 先检查配置项名称是否正确* 再检查配置项的值是否正确* @param item 配置项名称* @param value 配置项值* @param regexValue 配置项正则规则*/private def set(item:String,value:String,regexValue:String=null)={check("name_of_config_item",item,"^spark\\..*")check(item,value,regexValue)conf.set(item,value)}// Baseprivate def setBaseAppName(appName:String)={set("spark.app.name",appName,"^\\w+$")}private def setBaseMaster(master:String)={set("spark.master",master,"yarn|spark://([a-z]\\w+|\\d{1,3}(\\.\\d{1,3}){3}):\\d{4,5}|local(\\[\\*|[1-9][0-9]*])")}private def setBaseDeployMode(deployMode:String)={set("spark.submit.deployMode",deployMode,"client|cluster")}private def setBaseEventLogEnabled(eventLogEnabled:Boolean)={set("spark.eventLog.enabled",s"$eventLogEnabled")}override def baseConfig(appName: String, master: String = "local[*]", deployMode: String = "client", eventLogEnabled: Boolean = false): Builder = {setBaseAppName(appName)setBaseMaster(master)setBaseDeployMode(deployMode)setBaseEventLogEnabled(eventLogEnabled)this}// Driverprivate def setDriverMemory(memoryGB:Int)={set("spark.driver.memory",s"${memoryGB}g","[1-9]\\d*")}private def setDriverCoreNum(coreNum: Int) = {set("spark.driver.cores", s"${coreNum}g", "[1-9]\\d*")}private def setDriverMaxResultGB(maxRstGB:Int)={set("spark.driver.maxResultSize",s"${maxRstGB}g","[1-9]\\d*")}private def setDriverHost(driverHost:String)={set("spark.submit.deployMode",driverHost,"localhost|[a-z]\\w+")}override def optimizeDriver(memoryGB: Int = 2, coreNum: Int = 1, maxRstGB: Int = 1, driverHost: String = "localhost"): Builder = {setDriverCoreNum(coreNum)setDriverMemory(memoryGB)/*** 每一个Spark行动算子触发的所有分区序列化结果大小上限*/setDriverMaxResultGB(maxRstGB)/*** Standalone 模式需要设置 DriverHost,便于 executor 与 master 通信*/if (conf.get("spark.master").startsWith("spark://")) {setDriverHost(driverHost)}setDriverHost(driverHost)this}// Executorprivate def setExecutorMemory(memoryGB: Int) = {set("spark.executor.memory", s"${memoryGB}g", "[1-9]\\d*")}private def setExecutorCoreNum(coreNum: Int) = {set("spark.executor.cores", s"$coreNum", "[1-9]\\d*")}override def optimizeExecutor(memoryGB:Int=1,coreNum:Int=1):Builder={setExecutorMemory(memoryGB)/*** Yarn模式下只能由1个核* 其他模式下,核数为所有可用的核*/if(!conf.get("spark.master").equals("yarn")){setExecutorCoreNum(coreNum)}this}// Limitprivate def setLimitMaxCores(maxCores:Int)={set("spark.cores.max",s"$maxCores","[1-9]\\d*")}private def setLimitMaxTaskFailure(maxTaskFailure:Int)={set("spark.task.maxFailures",s"$maxTaskFailure","[1-9]\\d*")}private def setLimitMaxLocalWaitS(maxLocalWaitS:Int)={set("spark.locality.wait",s"${maxLocalWaitS}s","[1-9]\\d*")}override def optimizeLimit(maxCores:Int=4,maxTaskFailure:Int=3,maxLocalWaitS:Int=3):Builder={if (conf.get("spark.master").startsWith("spark://")) {setLimitMaxCores(maxCores)}/*** 单个任务允许失败最大次数,超出会杀死本次任务*/setLimitMaxTaskFailure(maxTaskFailure)/*** 数据本地化读取加载的最大等待时间* 大任务:建议适当增加此值*/setLimitMaxLocalWaitS(maxLocalWaitS)this}// Serializeroverride def optimizeSerializer(serde:String="org.apache.spark.serializer.JavaSerializer",clas:Array[Class[_]]=null):Builder={/*** 设置将需要通过网络发送或快速缓存的对象序列化工具类* 默认为JavaSerializer* 为了提速,推荐设置为KryoSerializer* 若采用 KryoSerializer,需要将所有自定义的实体类(样例类)注册到配置中心*/set("spark.serializer",serde,"([a-z]+\\.)+[A-Z]\\w*")if(serde.equals("org.apache.spark.serializer.KryoSerializer")){conf.registerKryoClasses(clas)}this}// Netprivate def setNetTimeout(netTimeoutS:Int)={set("spark.cores.max",s"${netTimeoutS}s","[1-9]\\d*")}private def setNetSchedulerMode(schedulerMode:String)={set("spark.scheduler.mode",schedulerMode,"FAIR|FIFO")}override def optimizeNetAbout(netTimeOusS:Int=120,schedulerMode:String="FAIR"):Builder={/*** 所有和网络交互相关的超时阈值*/setNetTimeout(netTimeOusS)/*** 多人工作模式下,建议设置为FAIR*/setNetSchedulerMode(schedulerMode)this}// Dynamicprivate def setDynamicEnabled(dynamicEnabled:Boolean)={set("spark.dynamicAllocation.enabled",s"$dynamicEnabled")}private def setDynamicInitialExecutors(initialExecutors:Int)={set("spark.dynamicAllocation.initialExecutors",s"$initialExecutors","[1-9]\\d*")}private def setDynamicMinExecutors(minExecutors:Int)={set("spark.dynamicAllocation.minExecutors",s"$minExecutors","[1-9]\\d*")}private def setDynamicMaxExecutors(maxExecutors:Int)={set("spark.dynamicAllocation.maxExecutors",s"$maxExecutors","[1-9]\\d*")}override def optimizeDynamicAllocation(dynamicEnabled:Boolean=false,initialExecutors:Int=3,minExecutors:Int=0,maxExecutors:Int=6):Builder={/*** 根据应用的工作需求,动态分配executor*/setDynamicEnabled(dynamicEnabled)if(dynamicEnabled){setDynamicInitialExecutors(initialExecutors)setDynamicMinExecutors(minExecutors)setDynamicMaxExecutors(maxExecutors)}this}override def optimizeShuffle(parallelism:Int=3,shuffleCompressEnabled:Boolean=false,maxSizeMB:Int=128,shuffleServiceEnabled:Boolean=true):Builder={null}override def optimizeSpeculation(enabled:Boolean=false,interval:Int=15,quantile:Float=0.75F):Builder={null}override def warehouseDir(hdfs:String):Builder={null}override def end():SparkSession={SparkSession.builder().getOrCreate()}}}
}
2.2 Object SparkFactory
object SparkFactory {trait Builder{// 默认值能给就给/*** 基本配置* @param appName* @param master 默认是本地方式* @param deployMode 默认是集群模式* @param eventLogEnabled 生产环境打开,测试环境关闭* @return*/def baseConfig(appName:String,master:String="local[*]",deployMode:String="client",eventLogEnabled:Boolean=false):Builder/*** 驱动端优化配置* @param memoryGB 驱动程序的内存大小* @param coreNum 驱动程序的核数* @param maxRstGB 驱动程序的最大结果大小* @param driverHost 驱动程序的主机地址:驱动程序会在主机地址上运行,并且集群中的其他节点会通过这个地址与驱动程序通信* @return*/def optimizeDriver(memoryGB:Int=2,coreNum:Int=1,maxRstGB:Int=1,driverHost:String="localhost"):Builderdef optimizeExecutor(memoryGB:Int=1,coreNum:Int=1):Builder/*** 整体限制配置* @param maxCores 整体可用的最大核数* @param maxTaskFailure 单个任务失败的最大次数* @param maxLocalWaitS 容错机制:数据读取阶段允许等待的最长时间,超过时间切换到其他副本。* @return*/def optimizeLimit(maxCores:Int=4,maxTaskFailure:Int,maxLocalWaitS:Int=30):Builder/*** 默认使用:Java序列化* 推荐使用:Kryo序列化 提速或对速度又要i去* 所有的自定义类型都要注册到Spark中,才能完成序列化。* @param serde 全包路径* @param classes 自定义类型,默认认为不需要指定,Class[_]表示类型未知。* @return Builder*/def optimizeSerializer(serde:String="org.apache.spark.serializer.JavaSerializer",clas:Array[Class[_]]=null):Builder/*** 在Spark的官方配置中,netTimeOutS可能被很多超时的数据调用。* @param netTimeOusS 判定网络超时的时间* @param schedulerMode 可能很多任务一起跑,因此公平调度* @return*/def optimizeNetAbout(netTimeOusS:Int=180,schedulerMode:String="FAIR"):Builder/*** 动态分配->按需分配* 类似于配置线程池中的最大闲置线程数,根据需要去做动态分配* @param dynamicEnabled 是否开启动态分配* @param initialExecutors 初始启用的Executors的数量* @param minExecutors 最小启用的Executors的数量* @param maxExecutors 最大启用的Executors的数量* @return*/def optimizeDynamicAllocation(dynamicEnabled:Boolean=false,initialExecutors:Int=3,minExecutors:Int=0,maxExecutors:Int=6):Builder/*** 特指在没有指定分区数时,对分区数的配置。* 并行度和初始启用的Executors的数量一致,避免额外开销。** @param parallelism* @param shuffleCompressEnabled* @param maxSizeMB* @param shuffleServiceEnabled* @return*/def optimizeShuffle(parallelism:Int=3,shuffleCompressEnabled:Boolean=false,maxSizeMB:Int=128,shuffleServiceEnabled:Boolean=true):Builder/*** 推测执行,将运行时间长的任务,放到队列中,等待运行时间短的任务运行完成后,再运行。* @param enabled* @param interval Spark检查任务执行时间的时间间隔,单位是秒。* @param quantile 如果某个任务的执行时间超过指定分位数(如75%的任务执行时间),则认为该任务执行时间过长,需要启动推测执行。*/def optimizeSpeculation(enabled:Boolean=false,interval:Int=15,quantile:Float=0.75F):Builderdef warehouseDir(hdfs:String):Builderdef end():SparkSession}
}

相关文章:
【Spark On Hive】—— 基于电商数据分析的项目实战
文章目录 Spark On Hive 详解一、项目配置1. 创建工程2. 配置文件3. 工程目录 二、代码实现2.1 Class SparkFactory2.2 Object SparkFactory Spark On Hive 详解 本文基于Spark重构基于Hive的电商数据分析的项目需求,在重构的同时对Spark On Hive的全流程进行详细的…...
哪种SSL证书可以快速签发保护http安全访问?
用户访问网站,经常会遇到访问http网页时,提示网站不安全或者不是私密连接的提示,因为http是使用明文传输,数据传输中可能被篡改,数据不被保护,通常需要SSL证书来给数据加密。 SSL证书的签发速度࿰…...

深入探究理解大型语言模型参数和内存需求
概述 大型语言模型 取得了显著进步。GPT-4、谷歌的 Gemini 和 Claude 3 等模型在功能和应用方面树立了新标准。这些模型不仅增强了文本生成和翻译,还在多模态处理方面开辟了新天地,将文本、图像、音频和视频输入结合起来,提供更全面的 AI 解…...

maven 私服搭建(tar+docker)
maven私服搭建 一、linux安装nexus1、工具下载 二、 docker 搭建nexus1、镜像下载创建目录2、运行nexus3、访问确认,修改默认密码,禁用匿名用户登录4、创建仓库5、创建hostd仓库6、创建Blob Stores7、创建docker私服1、创建proxy仓库2、创建hotsed本地仓…...

银行业务知识全篇(财务知识、金融业务知识)
第一部分 零售业务 1.1 储蓄业务 4 1.1.1 普通活期储蓄(本外币) 4 1.1.2 定期储蓄(本外币) 5 1.1.3 活期一本通 9 1.1.4 定期一本通 10 1.1.5 电话银行 11 1.1.6 个人支票 11 1.1.7 通信存款 13 1.1.8 其他业务规…...

解决ElasticJob项目重启ZooKeeper注册冲突以及zkCli删除目录
解决ElasticJob项目重启ZooKeeper注册冲突以及zkCli删除目录 背景 在现代化的分布式调度系统中,ElasticJob 是一个非常流行的选择。它利用 ZooKeeper 作为注册中心来管理任务分片。然而,有时在项目重启时,会遇到 ZooKeeper 注册冲突的问题&…...

【EI检索】第二届机器视觉、图像处理与影像技术国际会议(MVIPIT 2024)
一、会议信息 大会官网:www.mvipit.org 官方邮箱:mvipit163.com 会议出版:IEEE CPS 出版 会议检索:EI & Scopus 检索 会议地点:河北张家口 会议时间:2024 年 9 月 13 日-9 月 15 日 二、征稿主题…...

vscode通过ssh链接远程服务器上的docker
目录 1 编译docker image1.1 编译镜像1.2 启动镜像 2 在docker container中启动ssh服务2.1 确认是否安装ssh server2.2 修改配置文件2.3 启动ssh服务 3 生成ssh key4 添加ssh公钥到docker container中5 vscode安装插件Remote - SSH6 在vscode中配置 1 编译docker image 一般来…...

使用NIFI连接瀚高数据库_并从RestFul的HTTP接口中获取数据局_同步到瀚高数据库中---大数据之Nifi工作笔记0067
首先来看一下如何,使用NIFI 去连接瀚高数据库. 其实,只要配置好了链接的,连接字符串,和驱动,任何支持JDBC的数据库都可以连接的. 首先我们用一个ListDatabaseTables处理器,来连接瀚高DB 主要是看这里,连接地址,以及驱动,还有驱动的位置 这个是数据连接的配置 jdbc:highgo://…...

IDEA的工程与模块管理
《IDEA破解、配置、使用技巧与实战教程》系列文章目录 第一章 IDEA破解与HelloWorld的实战编写 第二章 IDEA的详细设置 第三章 IDEA的工程与模块管理 第四章 IDEA的常见代码模板的使用 第五章 IDEA中常用的快捷键 第六章 IDEA的断点调试(Debug) 第七章 …...
)
[M前缀和] lc3096. 得到更多分数的最少关卡数目(前缀和+思维)
文章目录 1. 题目来源2. 题目解析 1. 题目来源 链接:3096. 得到更多分数的最少关卡数目 2. 题目解析 比较有意思的题目,仔细读题后发现解题没啥难度,但是如何写好、写的更简洁需要注意下: 思路: 数据量 1e5&#…...

基础vrrp(虚拟路由冗余协议)
一、VRRP 虚拟路由冗余协议 比如交换机上联两个路由器,由两个路由虚拟出一台设备设置终端设备的网关地址,两台物理路由的关系是主从关系,可以设置自动抢占。终端设备的网关是虚拟设备的ip地址,这样,如果有一台路由设备…...

《绝区零》是一款什么类型的游戏,Mac电脑怎么玩《绝区零》苹果电脑玩游戏怎么样
米哈游的《绝区零》最近在网上爆火呀,不过很多人都想知道mac电脑能不能玩《绝区零》,今天麦麦就给大家介绍一下《绝区零》是一款什么样的游戏,Mac电脑怎么玩《绝区零》。 一、《绝区零》是一款什么样的游戏 《绝区零》是由上海米哈游自主研发…...

Mysql sql技巧与优化
1、解决mysql同时更新、查询问题 2、控制查询优化 hint 3、 优化 特定类型的查 优化 COUNT() 查询 使用 近似值 业务能接受近似值的话,使用explain拿到近似值 优化关联查询 优化子查询 4、优化group by和distinct 优化GROUP BY WITH ROLLUP 5、优化 limit分页 其他…...

7.SpringBoot整合Neo4j
1.引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-neo4j</artifactId> </dependency> 说明:这里引入neo4j的版本跟spring框架的版本有关系。需要注意不同的版本在neo…...

教室管理系统的开发与实现(Java+MySQL)
引言 教室管理系统是学校和培训机构日常运营中不可或缺的工具。本文将介绍如何使用Java、Swing GUI、MySQL和JDBC开发一个简单而有效的教室管理系统,并涵盖系统的登录认证、教室管理、查询、启用、暂停和排课管理功能。 技术栈介绍 Java:作为主要编程…...

Go的入门
一、GO简介 Go语言(也叫 Golang)是Google开发的开源编程语言。 1. 语言特性 Go 语法简洁,上手容易,快速编译,支持跨平台开发,自动垃圾回收机制,天生的并发特性,更好地利用大量的分…...
windows中使用Jenkins打包,部署vue项目完整操作流程
文章目录 1. 下载和安装2. 使用1. 准备一个 新创建 或者 已有的 Vue项目2. git仓库3. 添加Jenkinsfile文件4. 成功示例 1. 下载和安装 网上有许多安装教程,简单罗列几个 Windows系统下Jenkins安装、配置和使用windows安装jenkins 2. 使用 在Jenkins已经安装的基础上,可以开始下…...

RocketMQ中概念知识点记录 和 与SpringBoot集成实现发送 同步、异步、延时、批量、tag、key、事务消息等
1. 消息模型 消息(Message): 是 RocketMQ 中数据传输的基本单位,由主题、标签、键值、消息体等组成。主题(Topic): 消息的分类,类似于邮件的主题,用于对消息进行粗粒度的分类。标签(…...

云计算实训09——rsync远程同步、自动化推取文件、对rsyncd服务进行加密操作、远程监控脚本
一、rsync远程同步 1.rsync基本概述 (1)sync同步 (2)async异步 (3)rsync远程同步 2.rsync的特点 可以镜像保存整个目录树和文件系统 可以保留原有权限,owner,group,时间,软硬链…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...
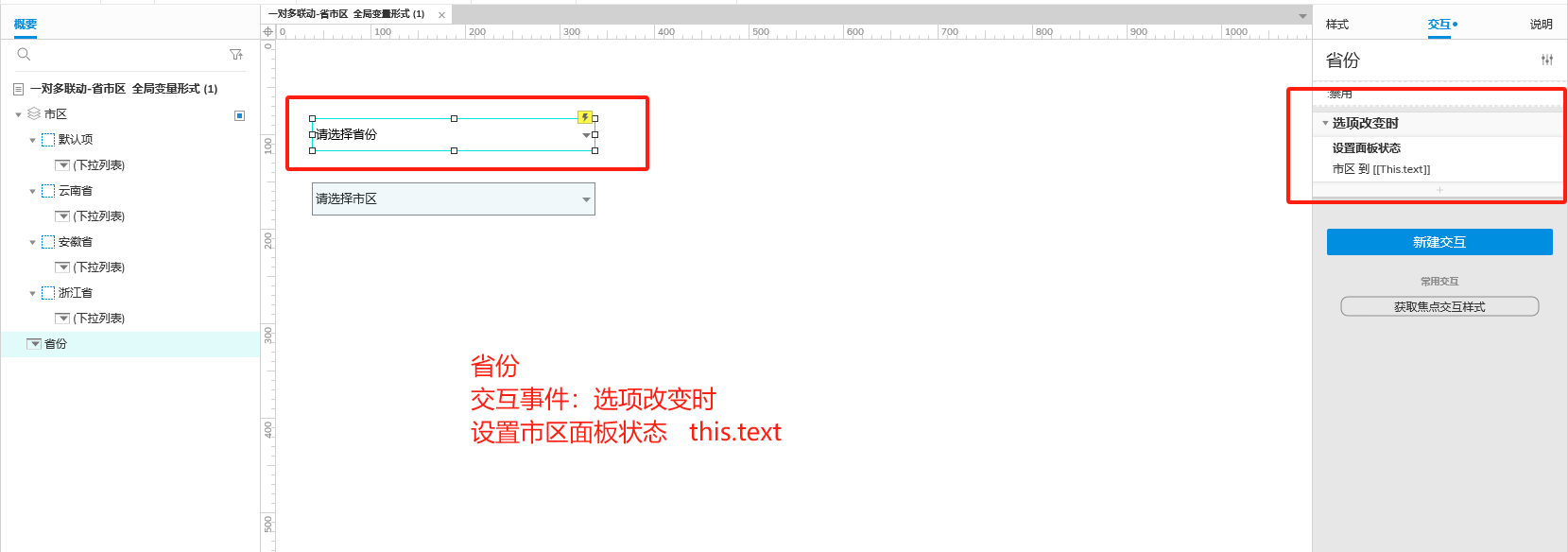
Axure 下拉框联动
实现选省、选完省之后选对应省份下的市区...