介绍 Elasticsearch 中的 Learning to Tank - 学习排名
作者:来自 Elastic Aurélien Foucret

从 Elasticsearch 8.13 开始,我们提供了原生集成到 Elasticsearch 中的学习排名 (learning to rank - LTR) 实现。LTR 使用经过训练的机器学习 (ML) 模型为你的搜索引擎构建排名功能。通常,该模型用作第二阶段重新排名器,以提高由更简单的第一阶段检索算法返回的搜索结果的相关性。
这篇博文将解释此新功能如何帮助提高文本搜索中的文档排名以及如何在 Elasticsearch 中实现它。
无论你是尝试优化电子商务搜索、为检索增强生成 (RAG) 应用程序构建最佳上下文,还是基于数百万篇学术论文制作基于问答的搜索,你可能已经意识到准确优化搜索引擎中的文档排名是多么困难。这就是学习排名的作用所在。
了解相关性特征以及如何构建评分函数
相关性特征是确定文档与用户查询或兴趣的匹配程度的信号,所有这些都会影响搜索相关性。这些特征可能会因上下文而异,但它们通常分为几类。让我们来看看不同领域中使用的一些常见相关性特征:
- 文本相关性分数(例如 BM25、TF-IDF):从文本匹配算法得出的分数,用于衡量文档内容与搜索查询的相似性。这些分数可以从 Elasticsearch 中获得。
- 文档属性(例如产品价格、发布日期):可以直接从存储的文档中提取的特征。
- 流行度指标(例如点击率、浏览量):文档的流行度或访问频率的指标。流行度指标可以通过搜索分析工具获得,Elasticsearch 提供了开箱即用的搜索分析工具。
评分函数结合了这些特征,为每个文档生成最终的相关性分数。得分较高的文档在搜索结果中的排名较高。
使用 Elasticsearch Query DSL 时,你会隐式编写一个评分函数,该函数对相关性特征进行加权,并最终定义你的搜索相关性。
Elasticsearch 查询 DSL 中的评分
考虑以下示例查询:
{"query": {"function_score": {"query": {"multi_match": {"query": "the quick brown fox","fields": ["title^10", "content"]}},"field_value_factor": {"field": "monthly_views","modifier": "log1p"}}}
}
该查询转换为以下评分函数:
score = 10 x title_bm25_score + content_bm25_score + log(1+ monthly_views)虽然这种方法效果很好,但它有一些局限性:
- 权重是估算的:分配给每个特征的权重通常基于启发式或直觉。这些猜测可能无法准确反映每个特征在确定相关性方面的真正重要性。
- 文档之间的统一权重:手动分配的权重统一应用于所有文档,忽略特征之间的潜在相互作用以及它们的重要性在不同查询或文档类型之间的变化。例如,新近度的相关性对于新闻文章可能更重要,但对于学术论文则不那么重要。
随着特征和文档数量的增加,这些限制变得更加明显,使得确定准确的权重变得越来越具有挑战性。最终,所选权重成为一种折衷方案,可能导致许多情况下排名不理想。
一个引人注目的替代方案是用基于 ML 的模型替换使用手动权重的评分函数,该模型使用相关性特征计算分数。
你好,学习排名 (LTR)!
LambdaMART 是一种流行且有效的 LTR 技术,它使用梯度提升决策树 (GBDT) 从判断列表中学习最佳评分函数。
判断列表是一个数据集,其中包含查询和文档对以及它们相应的相关性标签或等级。相关性标签通常是二进制的(例如相关/不相关)或分级的(例如,0 表示完全不相关,4 表示高度相关)。判断列表可以由人工手动创建,也可以从用户参与度数据(例如点击次数或转化次数)生成。
下面的示例使用分级相关性判断。

LambdaMART 使用决策树将排名问题视为回归任务,其中树的内部节点是相关性特征的条件,而叶子是预测分数。

LambdaMART 使用梯度提升树方法,在训练过程中,它会构建多个决策树,其中每棵树都会纠正其前辈的错误。此过程旨在根据判断列表中的示例优化 NDCG 等排名指标。最终模型是各个树的加权和。
XGBoost 是一个著名的库,它提供了 LambdaMART 的实现,使其成为基于梯度提升决策树实现排名的热门选择。
在 Elasticsearch 中开始使用 LTR
从 8.13 版开始,Learning To Rank 直接集成到 Elasticsearch 和相关工具中,作为技术预览功能。
训练并将 LTR 模型部署到 Elasticsearch
Eland 是我们用于 Elasticsearch 中的 DataFrames 和机器学习的 Python 客户端和工具包。Eland 与大多数标准 Python 数据科学工具兼容,例如 Pandas、scikit-learn 和 XGBoost。
我们强烈建议使用它来训练和部署你的 LTR XGBoost 模型,因为它提供了简化此过程的功能:
1)训练过程的第一步是定义 LTR 模型的相关特征。使用下面的 Python 代码,你可以使用 Elasticsearch Query DSL 指定相关功能。
from eland.ml.ltr import LTRModelConfig, QueryFeatureExtractorfeature_extractors=[# We want to use the score of the match query for the fields title and content as a feature:QueryFeatureExtractor(feature_name="title_bm25_score",query={"match": {"title": "{{query_text}}"}}),QueryFeatureExtractor(feature_name="content_bm25_score",query={"match": {"content": "{{query_text}}"}}),# We can use a script_score query to get the value# of the field popularity directly as a featureQueryFeatureExtractor(feature_name="popularity",query={"script_score": {"query": {"exists": {"field": "popularity"}},"script": {"source": "return doc['popularity'].value;"},}},)
]ltr_config = LTRModelConfig(feature_extractors)
2)该过程的第二步是构建训练数据集。在此步骤中,你将计算并添加判断列表每一行的相关性特征:

为了帮助你完成此任务,Eland 提供了 FeatureLogger 类:
from eland.ml.ltr import FeatureLoggerfeature_logger = FeatureLogger(es_client, MOVIE_INDEX, ltr_config)feature_logger.extract_features(query_params={"query": "foo"},doc_ids=["doc-1", "doc-2"]
)
3)当训练数据集建立后,模型训练起来非常容易(如 notebook 中所示):
from xgboost import XGBRanker
from sklearn.model_selection import GroupShuffleSplit# Create the ranker model:
ranker = XGBRanker(objective="rank:ndcg",eval_metric=["ndcg@10"],early_stopping_rounds=20,
)# Shaping training and eval data in the expected format.
X = judgments_with_features[ltr_config.feature_names]
y = judgments_with_features["grade"]
groups = judgments_with_features["query_id"]# Split the dataset in two parts respectively used for training and evaluation of the model.
group_preserving_splitter = GroupShuffleSplit(n_splits=1, train_size=0.7).split(X, y, groups
)
train_idx, eval_idx = next(group_preserving_splitter)train_features, eval_features = X.loc[train_idx], X.loc[eval_idx]
train_target, eval_target = y.loc[train_idx], y.loc[eval_idx]
train_query_groups, eval_query_groups = groups.loc[train_idx], groups.loc[eval_idx]# Training the model
ranker.fit(X=train_features,y=train_target,group=train_query_groups.value_counts().sort_index().values,eval_set=[(eval_features, eval_target)],eval_group=[eval_query_groups.value_counts().sort_index().values],verbose=True,
)
4)训练过程完成后,将模型部署到 Elasticsearch:
from eland.ml import MLModelLEARNING_TO_RANK_MODEL_ID = "ltr-model-xgboost"MLModel.import_ltr_model(es_client=es_client,model=trained_model,model_id=LEARNING_TO_RANK_MODEL_ID,ltr_model_config=ltr_config,es_if_exists="replace",
)
要了解有关我们的工具如何帮助你训练和部署模型的更多信息,请查看此端到端 notebook。
在 Elasticsearch 中使用 LTR 模型作为重新评分器
在 Elasticsearch 中部署模型后,你可以通过 rescorer 增强搜索结果。重新评分器允许你使用 LTR 模型提供的更复杂的评分来优化搜索结果的首次排名:
GET my-index/_search
{"query": {"multi_match": {"fields": ["title", "content"],"query": "the quick brown fox"}},"rescore": {"learning_to_rank": {"model_id": "ltr-model-xgboost","params": {"query_text": "the quick brown fox"}},"window_size": 100}
}在此示例中:
- 首次查询:multi_match 查询检索在标题和内容字段中与查询 "the quick brown fox" 匹配的文档。此查询旨在快速捕获大量潜在相关文档。
- 重新评分阶段:learning_to_rank 重新评分器使用 LTR 模型细化首次查询中的顶级结果。
- model_id:指定已部署的 LTR 模型的 ID(在我们的示例中为 ltr-model-xgboost)。
- params:提供 LTR 模型提取与查询相关的特征所需的任何参数。此处 query_text 允许你指定我们的某些特征提取器期望的用户发出的查询。
- window_size:定义首次查询发出的搜索结果中要重新评分的顶级文档(top documents)数量。在此示例中,将对前 100 个文档进行重新评分。
通过将 LTR 集成为两阶段检索过程,你可以通过结合以下方式优化检索过程的性能和准确性:
- 传统搜索的速度:首次查询可以非常快速地检索大量具有广泛匹配的文档,从而确保快速响应时间。
- 机器学习模型的精度:LTR 模型仅应用于顶部结果(top results),优化其排名以确保最佳相关性。这种有针对性的模型应用可以提高精度,而不会影响整体性能。
自己尝试一下!?
无论你是在努力为电子商务平台配置搜索相关性,旨在提高 RAG 应用程序的上下文相关性,还是只是想提高现有搜索引擎的性能,你都应该认真考虑 LTR。
要开始实施 LTR,请务必访问我们的 notebook,其中详细介绍了如何在 Elasticsearch 中训练、部署和使用 LTR 模型,并阅读我们的文档。如果你根据这篇博文构建了任何内容,或者你对我们的讨论论坛和社区 Slack 频道有疑问,请告诉我们。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一次 Elasticsearch 工程师培训何时开始!
原文:Elasticsearch Learning to Rank: How to Improve Search Ranking — Search Labs
相关文章:
介绍 Elasticsearch 中的 Learning to Tank - 学习排名
作者:来自 Elastic Aurlien Foucret 从 Elasticsearch 8.13 开始,我们提供了原生集成到 Elasticsearch 中的学习排名 (learning to rank - LTR) 实现。LTR 使用经过训练的机器学习 (ML) 模型为你的搜索引擎构建排名功能。通常,该模型用作第二…...

2024年计算机软考中级【硬件工程师】面试题目汇总(附答案)
硬件工程师面试题汇总分析 1、解释一下同步电路和异步电路 解题思路 同步电路和异步电路是指同步时序电路和异步时序电路。由于存储电路中触发器的动作特点不同,因此可以把时序电路分为同步时序电路和异步时序电路两种。同步时序电路所有的触发器状态的变化都是在同…...
ThinkPad改安装Windows7系统的操作步骤
ThinkPad:改安装Windows7系统的操作步骤 一、BIOS设置 1、先重新启动计算机,并按下笔记本键盘上“F1”键进入笔记本的BIOS设置界面。 2、进入BIOS设置界面后,按下键盘上“→”键将菜单移动至“Restart“项目,按下键盘上“↓”按键…...

微软Edge浏览器全解析教程
微软Edge浏览器全解析教程 微软Edge浏览器,作为微软公司精心打造的一款现代化网页浏览器,自其首次发布以来,凭借其卓越的性能、出色的用户体验和不断迭代的功能,赢得了广大用户的青睐。本文将全面解析微软Edge浏览器的各个方面&a…...

【过题记录】7.20
前两题一直在打模拟赛,有点忙,就没更 Red Playing Cards 算法:动态规划 其实这就是一个线段覆盖问题,只不过大线段能够包含小线段。 这就启发我们,对于每个大线段分别跑一个dp,合并在他内部的小线段。而后…...
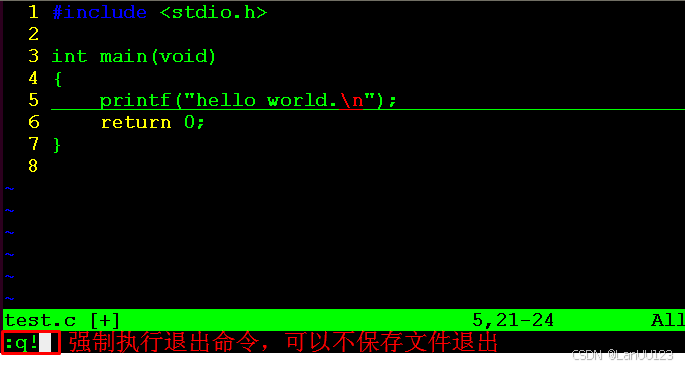
Linux系统学习日记——vim操作手册
Vim编辑器是linux下的一个命令行编辑器,类似于我们windows下的记事本。 目录 打开文件 编辑 保存退出 打开文件 打开 hello.c不存在也可以打开,保存时vim会自动创建。 效果 Vim打开时,处于命令模式,即执行命令的模式&#x…...

【深度学习图片】图片清洗,只留下图像中只有一张人脸的,而且人脸是全的
环境: conda install pytorch torchvision torchaudio pytorch-cuda11.8 -c pytorch -c nvidia -ypip install onnx1.15 onnxruntime-gpu1.17pip install insightface0.7.3pip install opencv-pythonpip install gradio图片清洗,只留下图像中只有一张人脸…...

如何在 PostgreSQL 中处理海量数据的存储和检索?
🍅关注博主🎗️ 带你畅游技术世界,不错过每一次成长机会!📚领书:PostgreSQL 入门到精通.pdf 文章目录 如何在 PostgreSQL 中处理海量数据的存储和检索?一、优化表结构设计二、分区技术三、数据压…...

【中项】系统集成项目管理工程师-第2章 信息技术发展-2.2新一代信息技术及应用-2.2.1物联网与2.2.2云计算
前言:系统集成项目管理工程师专业,现分享一些教材知识点。觉得文章还不错的喜欢点赞收藏的同时帮忙点点关注。 软考同样是国家人社部和工信部组织的国家级考试,全称为“全国计算机与软件专业技术资格(水平)考试”&…...

Redis集群的主从复制原理-全量复制和增量复制-哨兵机制
Redis集群的主从复制原理-全量复制和增量复制-哨兵机制 作用 数据备份 这一点直观,因为现在有很多节点,每个节点都保存了原始数据的备份. 读写分离 这一点主要是当发生读写的时候,读数据的操作大部分都会进入到从节点,而写数据的操作都会进入到主节点&…...

23年阿里淘天笔试题 | 卡码网模拟
第一题 字典序最小的 01 字符串 解题思路: 模拟,统计遇到的连续的1的个数记为num,直到遇到0,如果k>num,直接将第一个1置为0,将遇到的0置为1,否则将第一个1偏置num-k个位置置为0࿰…...

【SpringBoot】单元测试之测试Service方法
测试Service方法 SpringBootTest public class UserServiceTest{ Autowired private UserService userService; Test public void findOne () throws Exception{ Assert.assertEquals("1002",userService.findOne()); } } 测试Controller接口方法 Runwith(S…...
剪辑师和小白都能用的AI解说神器,一键把短剧变解说视频-手把手教程-2024
为什么短剧、综艺、电影和电视剧需要以解说形式在抖音、快手和TikTok推广? 此类专业影视内容由于时间过长、平台用户的习惯、算法去重需求和版权问题,专业的影视综节目通常需要用解说类型的视频来不断重复的宣发剧集。具体的原因如下: 1. 视…...

我去,怎么http全变https了
项目场景: 在公司做的一个某地可视化项目。 部署采用的是前后端分离部署,图片等静态资源请求一台minio服务器。 项目平台用的是http 图片资源的服务器用的是https 问题描述 在以https请求图片资源时,图片请求成功报200。 【现象1】: 继图…...

IDEA的详细设置
《IDEA破解、配置、使用技巧与实战教程》系列文章目录 第一章 IDEA破解与HelloWorld的实战编写 第二章 IDEA的详细设置 第三章 IDEA的工程与模块管理 第四章 IDEA的常见代码模板的使用 第五章 IDEA中常用的快捷键 第六章 IDEA的断点调试(Debug) 第七章 …...

为什么Spring选择使用容器来管理对象,而不是直接使用new
为什么Spring选择使用容器来管理对象,而不是直接使用new 在Java应用程序开发中,对象的创建和管理是一项基础且关键的任务。传统上,开发者习惯于使用new关键字直接在代码中实例化对象。然而,随着应用程序规模的扩大和复杂度的增加…...

腾讯云发送短信验证码
1、在腾讯云平台中 开通短信服务 2、发送短信 2.1引用jar包 <dependency><groupId>com.tencentcloudapi</groupId><artifactId>tencentcloud-sdk-java-sms</artifactId><version>3.1.1043</version> </dependency>2.2 发送短…...

嵌入式人工智能(13-基于树莓派4B的指纹识别-AS608)
1、指纹识别模块 指纹识别是一种生物识别技术,通过分析人体指纹的纹理特征来进行身份验证。每个人的指纹纹路都是独一无二的,通过将指纹与事先存储的指纹数据库进行比对,可以确定是否为同一人。指纹识别在安全领域得到广泛应用,例…...

【Vue】`v-on` 指令详解:事件绑定与处理的全面指南
文章目录 一、v-on 指令概述缩写语法 二、v-on 的基本用法1. 绑定方法2. 内联处理器 三、v-on 指令的高级用法1. 事件修饰符.stop.prevent.capture.self.once 2. 按键修饰符.enter自定义按键修饰符 3. 系统修饰符 四、v-on 指令的实际应用1. 表单处理模板部分 (<template>…...

【Spark On Hive】—— 基于电商数据分析的项目实战
文章目录 Spark On Hive 详解一、项目配置1. 创建工程2. 配置文件3. 工程目录 二、代码实现2.1 Class SparkFactory2.2 Object SparkFactory Spark On Hive 详解 本文基于Spark重构基于Hive的电商数据分析的项目需求,在重构的同时对Spark On Hive的全流程进行详细的…...

【DexGraspNet与多指手抓取算法详解】第六章 运动规划与轨迹优化
目录 第六章 运动规划与轨迹优化 6.1 从静态姿态到动态轨迹 6.1.1 抓取前运动规划 6.1.1.1 快速扩展随机树 (RRT) 6.1.1.1.1 状态空间采样 6.1.1.1.2 碰撞检测机制 6.1.1.2 轨迹平滑处理 6.1.1.2.1 B样条插值 6.1.1.2.2 速度与加速度约束 6.2 基于优化的轨迹生成 6.…...

Java后端如何优雅地封装第三方API调用逻辑以对接美团外卖霸王餐接口
Java后端如何优雅地封装第三方API调用逻辑以对接美团外卖霸王餐接口 在Java后端开发中,对接第三方API(如美团外卖霸王餐接口)是常见的需求。直接在业务代码中拼接URL、处理JSON、写HTTP请求不仅导致代码臃肿,还难以维护和测试。 本…...

BEYOND REALITY Z-Image避坑指南:解决生成图片模糊、全黑的常见问题
BEYOND REALITY Z-Image避坑指南:解决生成图片模糊、全黑的常见问题 1. 为什么你的Z-Image生成效果不理想? 当你第一次使用BEYOND REALITY Z-Image时,可能会遇到这样的困扰:明明输入了详细的提示词,生成的图片却要么…...

CVPR 2026 | 全架构通吃!MatchED 插件式模块,CNN/Transformer/扩散模型都能无缝集成
点击上方“小白学视觉”,选择加"星标"或“置顶” 重磅干货,第一时间送达边缘检测是计算机视觉领域的基石任务,从图像分割、深度估计到3D重建,几乎所有高阶视觉任务都依赖精准的边缘信息。但长期以来,一个核心…...

RWKV7-1.5B-G1A助力运维:利用Xshell脚本自动化模型部署与监控
RWKV7-1.5B-G1A助力运维:利用Xshell脚本自动化模型部署与监控 1. 引言 "又到周五下午4点,运维团队收到紧急需求——需要在10台服务器上部署最新的RWKV7-1.5B-G1A模型服务。"这样的场景对运维工程师来说再熟悉不过。传统的手动部署方式不仅耗…...

CLIP ViT-H-14多场景适配方案:教育题库图像索引、医疗报告配图推荐、设计素材库检索
CLIP ViT-H-14多场景适配方案:教育题库图像索引、医疗报告配图推荐、设计素材库检索 1. 项目概述 CLIP ViT-H-14图像编码服务是基于CLIP ViT-H-14(laion2B-s32B-b79K)模型的图像特征提取解决方案。这项服务通过RESTful API和Web界面两种方式,为不同行业…...

Linux系统CPU负载与使用率详解及性能监控
1. CPU负载与CPU使用率的本质区别在Linux系统监控和性能调优过程中,CPU负载和CPU使用率这两个指标经常被混淆使用。作为系统管理员,我曾多次遇到团队成员将这两个概念混为一谈的情况,这往往导致对系统性能问题的误判。让我们先从一个实际案例…...

从羊肠小道到智能高速:HTTP1到HTTP3的演进之路
引言 计算机网络就像一张遍布全球的道路系统,服务器是一座座城市、村庄,客户端是穿梭其中的车辆,而HTTP协议,就是规范车辆通行、货物传递的交通规则。从HTTP1到HTTP3的演进,本质上就是这条“网络道路”的升级史——从泥…...
数码管显示)
51单片机学习(五)数码管显示
如有大佬发现我文章里的错误,希望多多指出,或者有缺少的也欢迎告诉我,我会尽快补充上去的,感谢各位的支持,要互三的d我哦!一.数码管数码管显示屏和U4 74HC245U574H138译码器一位数码管引脚定义一个数码管由…...

2021必修 首门CSS架构系统精讲 理论+实战玩转蘑菇街 百度网盘
在前端开发的职场鄙视链里,存在一个极其普遍的误区:认为电商页面就是“简单的列表详情”,没什么技术含量。殊不知,电商是前端技术最残酷的练兵场:毫秒级的首屏速度、像素级的视觉还原、千人千面的动态布局、以及大促期…...