TreeSet 与 TreeMap And HashSet 与 HashMap
目录
Map
TreeMap
put()方法 :
get()方法 :
Set> entrySet() (重) :
foreach遍历 :
Set
哈希表
哈希冲突 :
冲突避免 :
冲突解决 ---- > 比散列(开放地址法) :
开散列 (链地址法 . 开链法)
简介 :
在Java中 , TreeSet 与 TreeMap 利用搜索树实现 Map 与 Set , 其实它们的底层就是一个红黑树(仅作了解).
HashSet与HashMap底层是Hash表.
关于搜索 :
Map和set是一种专门用来搜索的容器.其搜索的效率与其具体的实例化子类有关.
像我们之前常见的搜索方式有 :
1.直接遍历 , 时间复杂度为O(n) , 元素如果比较多那么效率就会很慢很慢.
2.二分查找, 时间复杂度为O(logn),但搜索前必须要求序列是有序的.
在现实中会有一些查找 : 例如
根据一个人的姓名去查找它的成绩,或者根据姓名去查找电话号码.
如果是这样的一些查找那么上述的两种方式就不太适合了,而Map和Set就是一种适合动态查找的集合容器.根据Map和Set我们就可去实现这种要求去查询.
Map
对于Map来说它是一个Key - Value 模型 Key 就是一个关键字 而Value就是Key对应的一种结果
例如 :
统计文件中每个单词出现的次数 , 那么Map就可以实现, <单词 , 单词出现的次数>
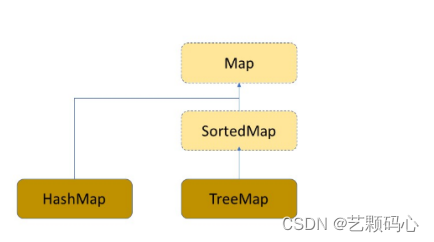
Map 与 SortedMap 是两个接口 , HashMap 与 TreeMap 就是两个普通类.
TreeMap
以下就是Map中的一些方法 :
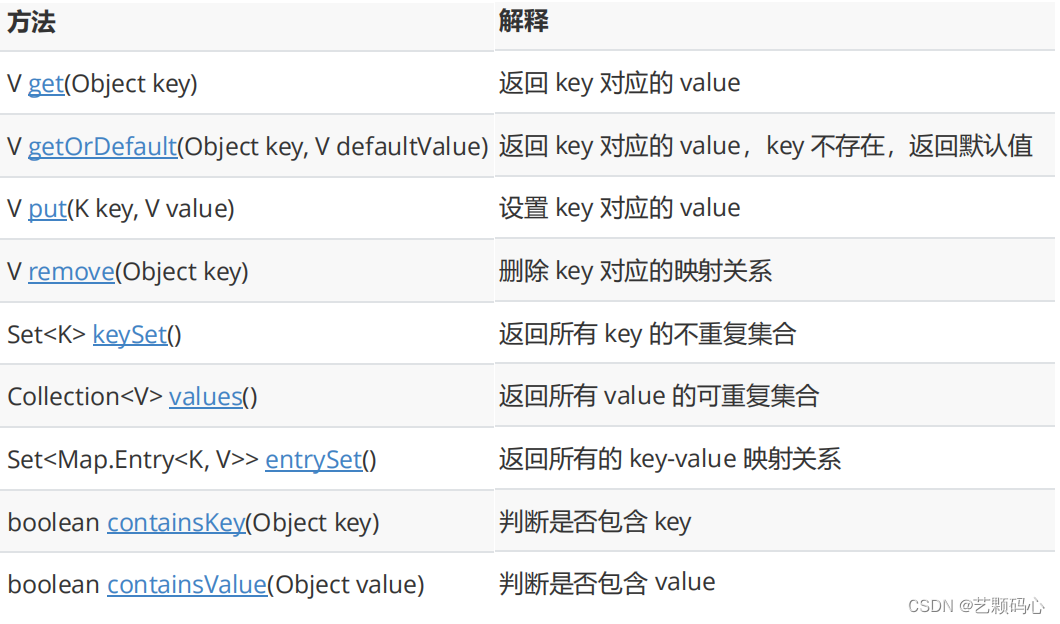
put()方法 :
put方法的一些注意点 :
public class Test {public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);System.out.println(treeMap);}
}
上面我们提到了TreeMap与TreeSet它的底层就是一个搜索树.在上一篇文章中我们讲到搜索树的原理以及是如何进行增,删,查的操作.

get()方法 :
根据get方法 : 当我们传进去一个Key关键字那么它就会输出相对应的value
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);Integer val = treeMap.get("he");System.out.println(val);}
如果treeMap对象中不存在所要查找的关键字Key时 , 则会返回一个null.

或者我们可以使用另一个方法 :
如果treeMap对象中不存在abc这个字符串时 , 则输出默认值10.
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);Integer val = treeMap.getOrDefault("abc",10);System.out.println(val);}
KeySet()方法 :
将treeMap对象中全部key放入keySet中.
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);Set<String> keySet = treeMap.keySet();System.out.println(keySet);}
Set<Map.Entry<K, V>> entrySet() (重) :
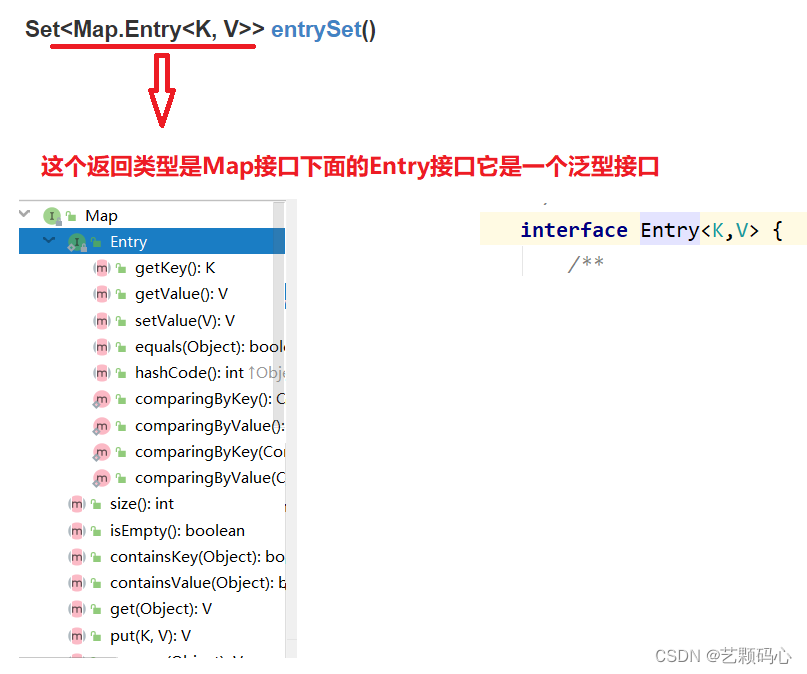
这个方法它会将所有存在treeMao对象中的Key - Value 模型返回.
public static void main(String[] args) {Map<String,Integer> treeMap = new TreeMap<>();treeMap.put("he",3);treeMap.put("she",6);treeMap.put("it",8);Set<Map.Entry<String, Integer>> entry = treeMap.entrySet();System.out.println(entry);}
foreach遍历 :
我们就可以使用Entry里面的getKey()方法来得到每一个模型的关键字key :
for (Map.Entry<String, Integer> entry: set) {System.out.print(entry.getKey() + " ");
}
注意 :
1.Map是一个接口,不能直接实例化对象, 如果要实例化对象只能实例化其实现类TreeMap或者HashMap.
2.Map中存放的键值对的Key是唯一的,value是可以重复的

3 . 在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但是HashMap的key和value都可以为空。

使用Collection<V> values()方法
Set
Set是一个纯Key模型. 因此它只存关键词key.
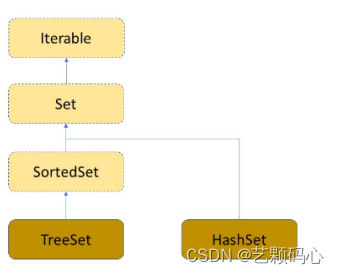
Set 与 SortedSet 就是两个接口 , 而 TreeSet 和 HashSet是两个普通类.
TreeSet使用add的方法来添加Key.但是如果重复它就不放入.
public static void main(String[] args) {Set<String> set = new TreeSet<>();set.add("she");set.add("he");set.add("he");System.out.println(set);}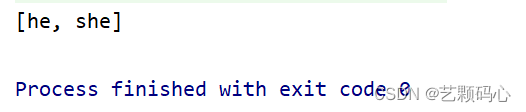
TreeSet底层也是去调用TreeMap.
注意 :
哈希表
在顺序结构以及平衡树中, 查找一个元素时,必须要经过关键码的多次比较.顺序查找时间复杂度O(n),平衡树中为树的高度,即O(logn).
而哈希表它就可以直接以O(1)的速度去查找!!!!
实现方法 : 构造一种存储结构 , 通过某种函数使元素的存储位置与它的关键码之间能够建立---映射关系,那么在查找时通过该函数就可以很快找到该元素.
哈希函数 (散列函数) : 哈希方法中使用的转换函数称为哈希(散列)函数 , 构造出来的结构称为哈希表(HashTable)(或者称散列表)
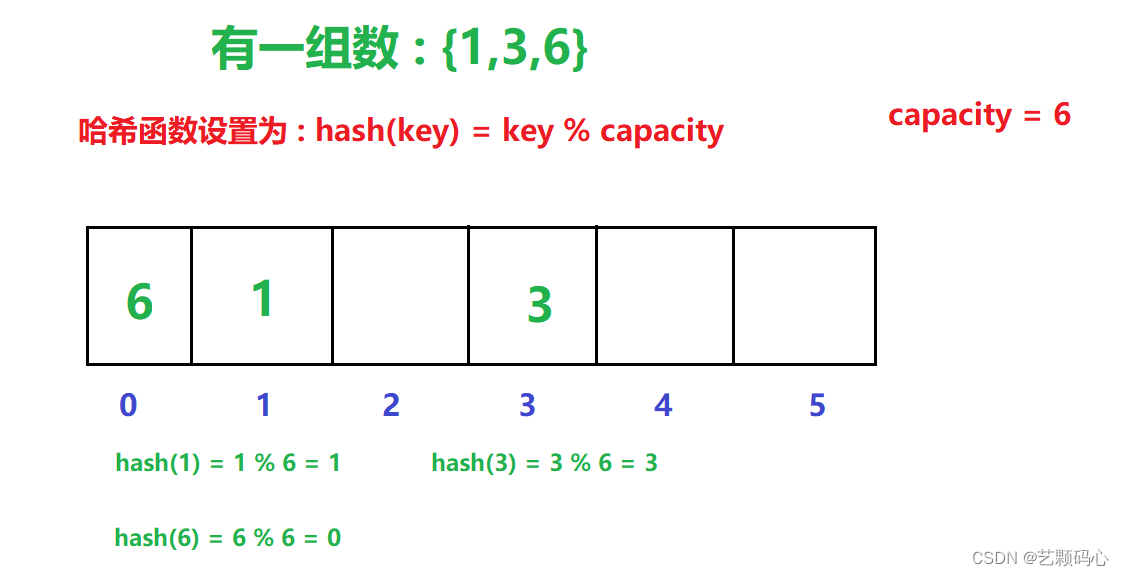
例如 : 有一组数 {1,4,3,2,75,23}
哈希函数设置为 : hash(key) = key % capacity ; capacity为元素底层空间总的大小
哈希冲突 :
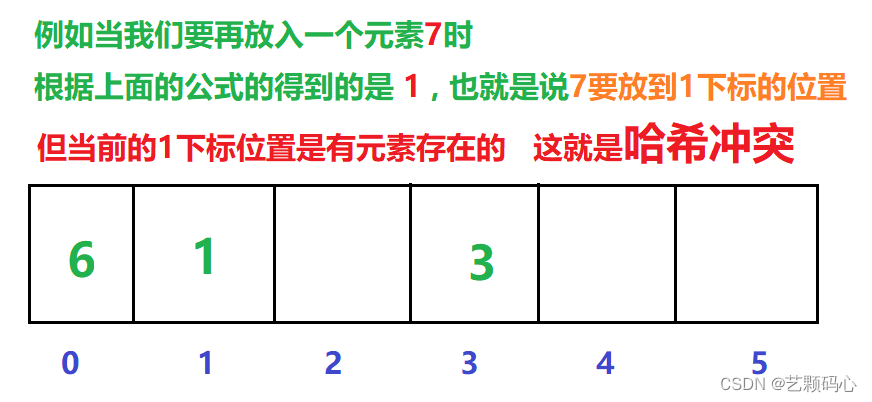
冲突避免 :
首先我们要明白一点 : 在哈希表底层数组的容量往往是小于实际要存储的关键字的数量的, 这就导致了 : 冲突的发生是必然的 , 因此我们要做的就是尽量的降低冲突率.
冲突避免 -----> 负载因子调节 (重点)
散列表的载荷因子定义为 : α = 填入表中的元素个数 / 散列表的长度

冲突解决的两种方法 :
冲突解决 ---- > 比散列(开放地址法) :
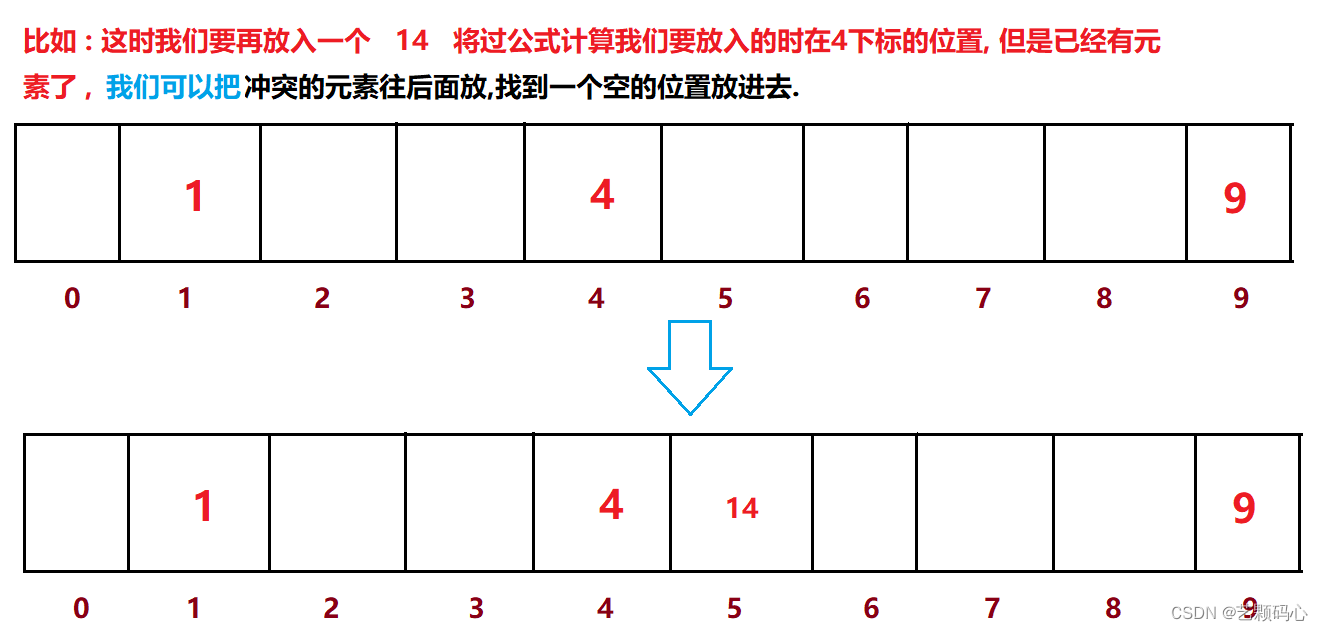
上面这种方法叫做线性探测 : 缺点是如果我们要删除4下标这个元素,如果直接删掉之后,那14就找不到了,因此我们在删4的时候只能是通过标记法来标记他已经被删除.
相比起比散列, 开散列会好很多
开散列 (链地址法 . 开链法):
它是由数组 + 链表 + 红黑树 组织起来的
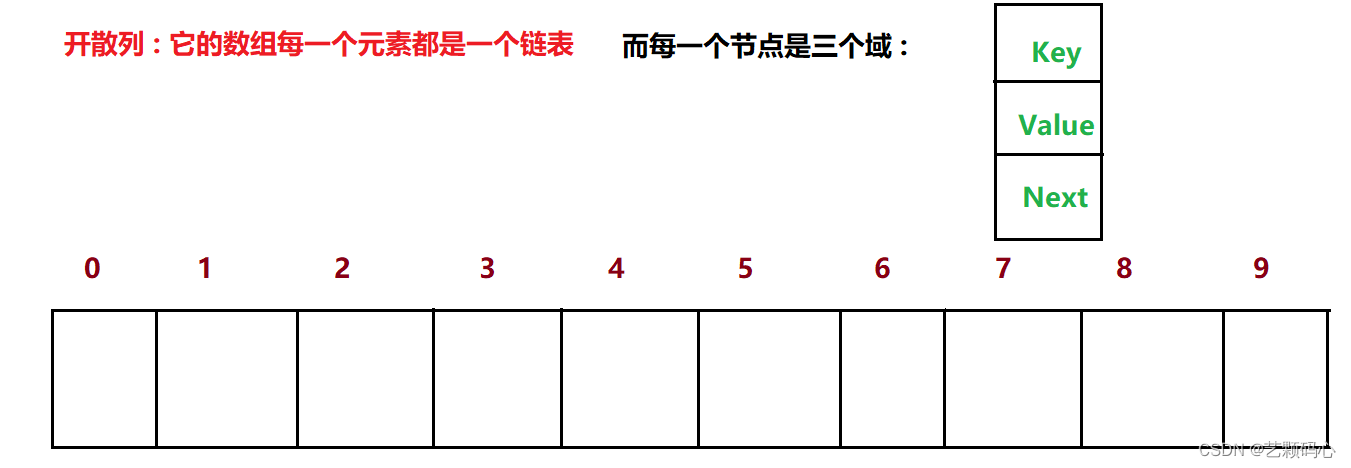
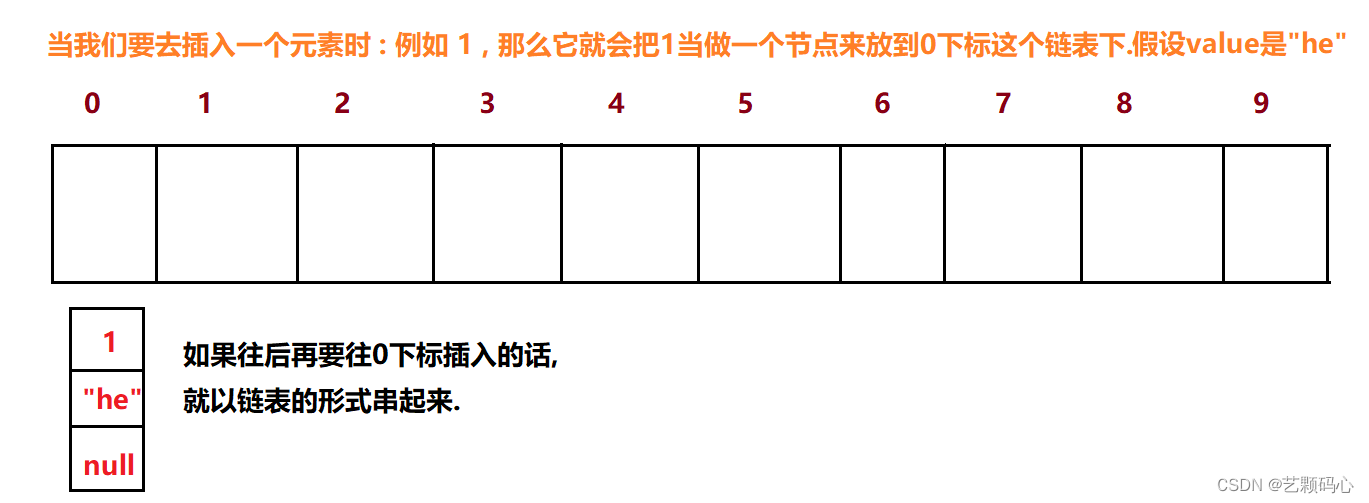
红黑树的体现 :
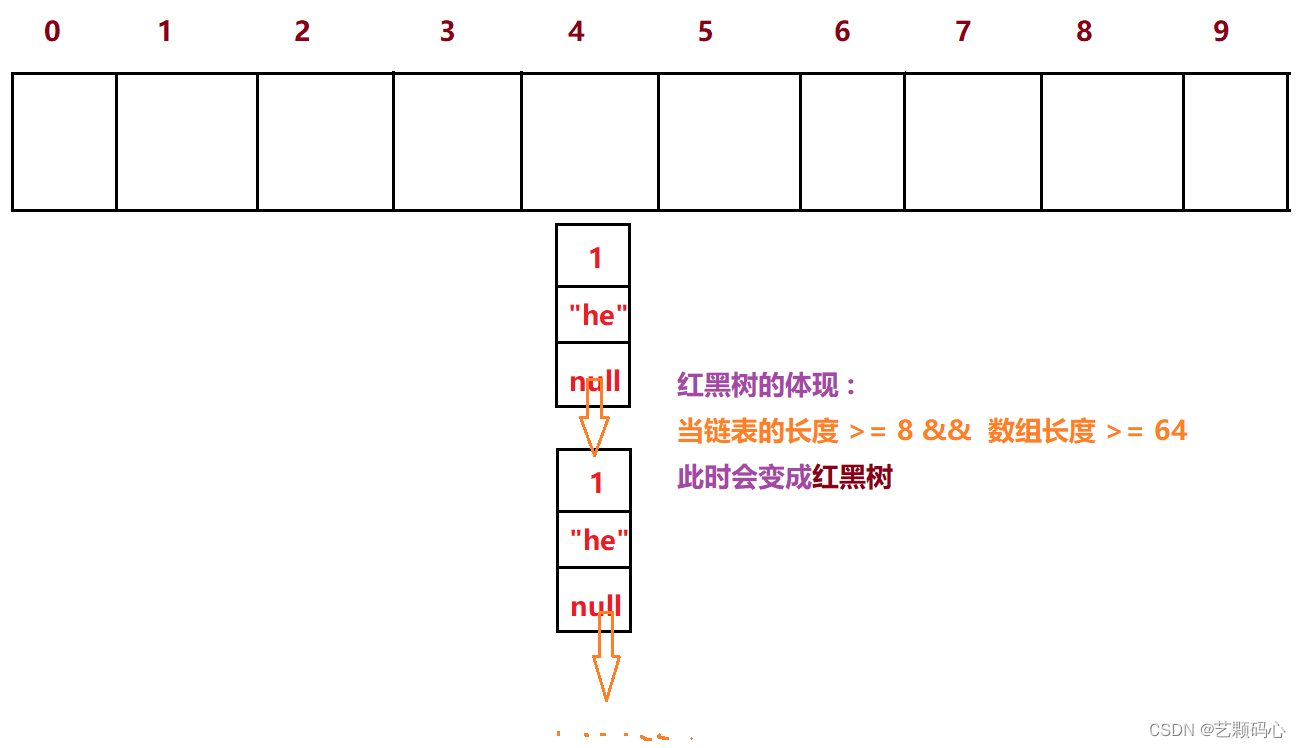
在java底层代码中 , 每一个下标下是一个链表, 采用的是尾插.
接下来我们来实现一下哈希表下面的put方法 :
我采用了头插的方式.
public class HashBuck {static class Node {public int key;public int val;public Node next;public Node(int key, int value) {this.key = key;this.val = value;}}public Node[] array;public int usedSize;//负载因子 设置为0.7public static final double loadFactor = 0.7;public HashBuck() {this.array = new Node[10];}public void put(int key, int val) {int index = key % array.length;Node cur = array[index];while (cur != null) {if (cur.key == key) {cur.val = val;}cur = cur.next;}Node newNode = new Node(key,val);newNode.next = array[index];array[index] = newNode;usedSize++;//如果负载因子 大于0.7那就扩容数组if (calculateLoadFactor() >= loadFactor) {//扩容}}//计算负载因子public double calculateLoadFactor() {return (usedSize*1.0) / array.length;}}重点在于 : 如果负载因子超过了0.7,那么我们就要去扩容,
扩容要注意 :
一定要重新哈希计算,假设我们最开始的14存在了4下标,扩容后它应该在14下标.
//扩容private void resize() {Node[] newArray = new Node[2*array.length];for (int i = 0; i < array.length; i++) {Node cur = array[i];Node curNext = null;while (cur != null) {curNext = cur.next;int index = cur.key % newArray.length; //找到了在新数组当中的位置cur.next = newArray[index];newArray[index] = cur;cur = curNext;}}this.array = newArray;}get方法 :
public int get(int key) {int index = key % array.length;Node cur = array[index];while (cur != null) {if (cur.key == key) {return cur.val;}cur = cur.next;}return -1;}我们在去求哈希参数的位置时 , 用key%数组的长度. 但是如果key是引用类型呢?
那我们就去调用hashcode方法 , 如果引用数据类型没有实现hashcode方法,那么就会调用Object里面的hashcode方法.
class Student {public int age;public String name;public Student(int age, String name) {this.age = age;this.name = name;}
}
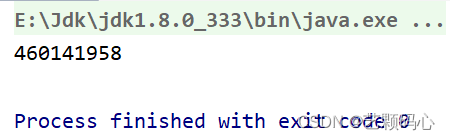
public class Test {public static void main(String[] args) {Student stu = new Student(12,"zs");System.out.println(stu.hashCode());}
}
但是问题又来了 : 如果stu 与 stu2里面的两个参数值一样 , 按照我们的理解它们应该是一样的 :
但结果确实不一样的两个结果.
public static void main(String[] args) {Student stu = new Student(12,"zs");System.out.println(stu.hashCode());Student stu2 = new Student(12,"zs");System.out.println(stu2.hashCode());}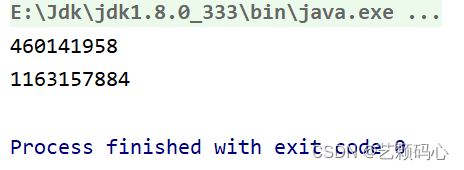
要想解决这个问题 , 我们就去Student里面去重写hashCode方法.
class Student {public int age;public String name;public Student(int age, String name) {this.age = age;this.name = name;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age &&Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(age, name);}
}可以看到重写后的哈希方法里 , return语句 括号里面有两个参数 , 也就意味着根据age与name去形成结果. 因此在一样的age 与 name 的情况下 , 它们调用hashCode返回的值都是相同的.
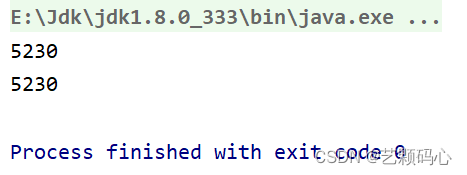
将上面的代码转变为引用类型 :
package demo2;public class HashBuck<K,V> {static class Node<K,V> {public K key;public V value;public Node<K,V> next;public Node(K key, V value) {this.key = key;this.value = value;}}public Node<K,V>[] array;public int usedSize;public static final double loadFactor = 0.7;public HashBuck() {this.array = (Node<K,V>[])new Node[10];}public void put(K key, V value) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];while (cur != null) {if (cur.key.equals(key)) {cur.value = value;return;}cur = cur.next;}Node<K,V> node = new Node<>(key,value);node.next = array[index];array[index] = node;usedSize++;if (calculateLoadFactor() >= loadFactor) {resize();}}private void resize() {Node<K,V>[] newArray = (Node<K,V>[])new Node[2*array.length];for (int i = 0; i < array.length; i++) {Node cur = array[i];Node curNext = null;while (cur != null) {curNext = cur.next;int index = cur.key.hashCode() % newArray.length; //找到了在新数组当中的位置cur.next = newArray[index];newArray[index] = cur;cur = curNext;}}this.array = newArray;}public double calculateLoadFactor() {return (usedSize*1.0) / array.length;}public V get(K key) {int index = key.hashCode() % array.length;Node<K,V> cur = array[index];while (cur != null) {if (cur.key.equals(key)) {return cur.value;}cur = cur.next;}throw new RuntimeException("找不到Key所对应的Value");}
}
重点要注意一下 : 在求哈希函数时 , 要用key.hashCode() % 数组的长度. 再然后引用数据类型之间比较相不相同要用equals()方法.
问题 : hashCode()一样 , equals一定一样吗 ?
equals()一样 , hashCode()一定一样吗 ?
答案分别为 : 不一定 , 一定 .
以上就是我对 HashMap 与 HashSet 的一些见解 . 希望可以帮到大家~~~
相关文章:
TreeSet 与 TreeMap And HashSet 与 HashMap
目录 Map TreeMap put()方法 : get()方法 : Set> entrySet() (重) : foreach遍历 : Set 哈希表 哈希冲突 : 冲突避免 : 冲突解决 ---- > 比散列(开放地址法) : 开散列 (链地址法 . 开链法) 简介 : 在Java中 , TreeSet 与 TreeMap 利用搜索树实现 Ma…...
Java围棋游戏的设计与实现
技术:Java等摘要:围棋作为一个棋类竞技运动,在民间十分流行,为了熟悉五子棋规则及技巧,以及研究简单的人工智能,决定用Java开发五子棋游戏。主要完成了人机对战和玩家之间联网对战2个功能。网络连接部分为S…...

第七十三章 使用 irisstat 实用程序监控 IRIS - 使用选项运行 irisstat
文章目录第七十三章 使用 irisstat 实用程序监控 IRIS - 使用选项运行 irisstat使用选项运行 irisstatirisstat Options第七十三章 使用 irisstat 实用程序监控 IRIS - 使用选项运行 irisstat 使用选项运行 irisstat 不带选项运行 irisstat 会生成基本报告。通常,…...

【博客619】PromQL如何实现Left joins以及不同metrics之间的复杂联合查询
PromQL如何实现Left joins以及不同metrics之间的复杂联合查询 1、场景 我们需要在PromQL中实现类似SQL中的连接查询: SELECT a.value*b.value, * FROM a, b2、不同metrics之间的复杂联合查询 瞬时向量与瞬时向量之间进行数学运算: 例如:根…...
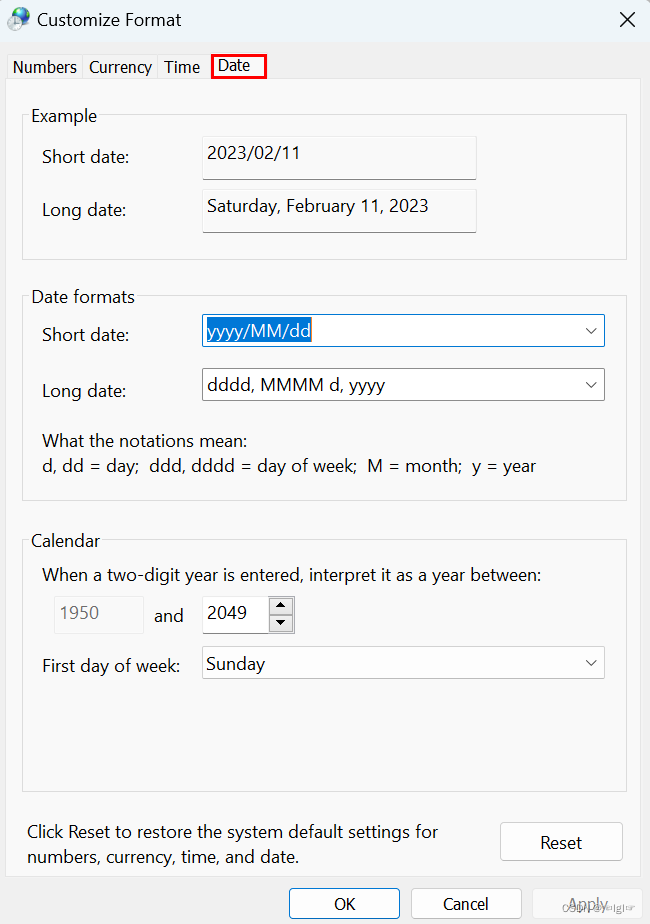
Win11自定义电脑右下角时间显示格式
Win11自定义电脑右下角时间显示格式 一、进入附加设置菜单 1、进入控制面板,选择日期和时间 2、选择修改日期和时间 3、选择修改日历设置 4、选择附加设置 二、自定义时间显示出秒 1、在选项卡中,选时间选项卡 2、在Short time的输入框中输入H:m…...
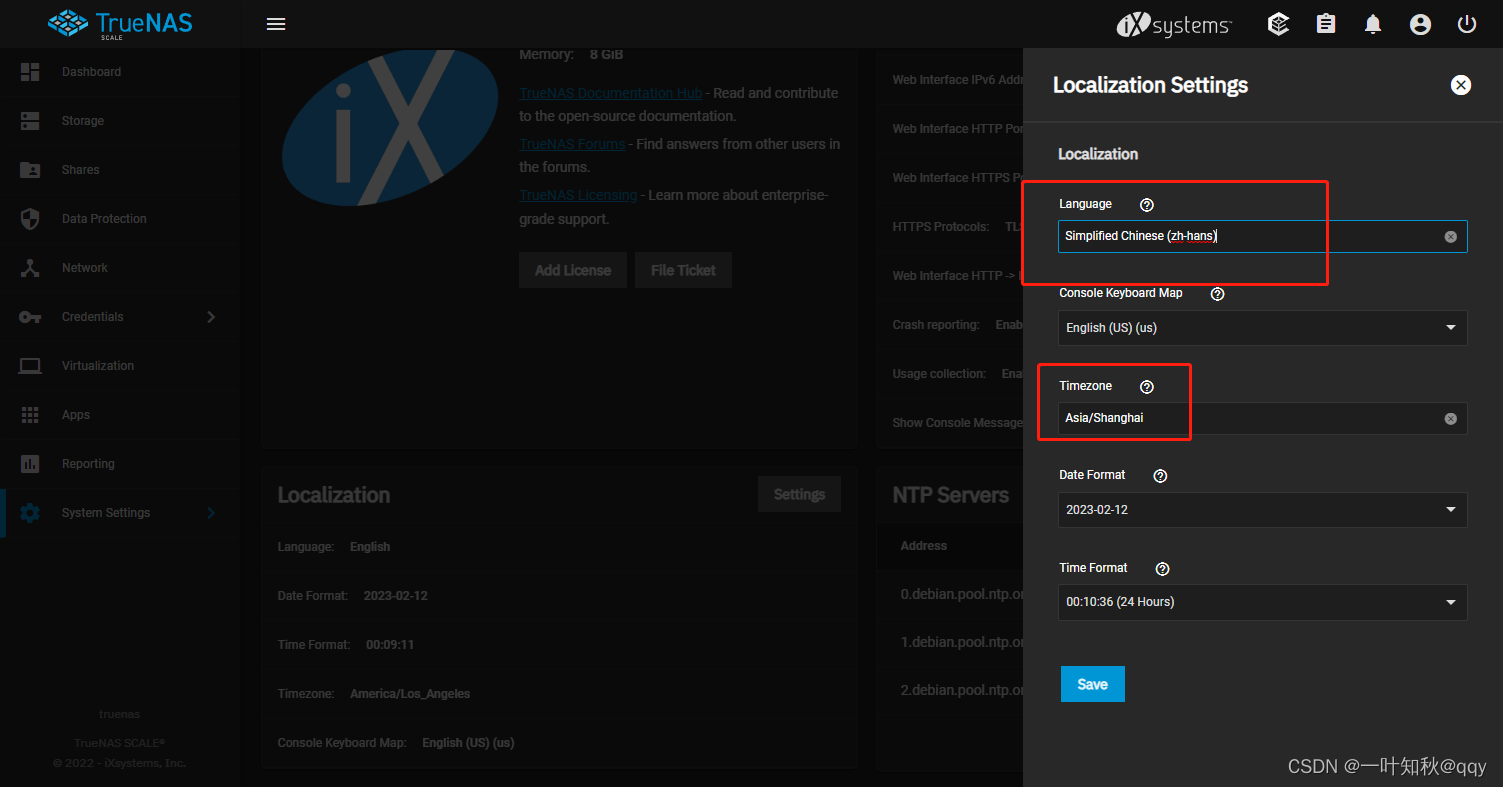
TrueNas篇-trueNas Scale安装
安装TrueNAS Scale 在尝试trueNas core时发下可以成功安装,但是一直无法成功启动,而且国内对我遇见的错误几乎没有案例,所以舍弃掉了,而且trueNas core是基于Linux的,对Linux的生态好了很多,还可以可以在t…...
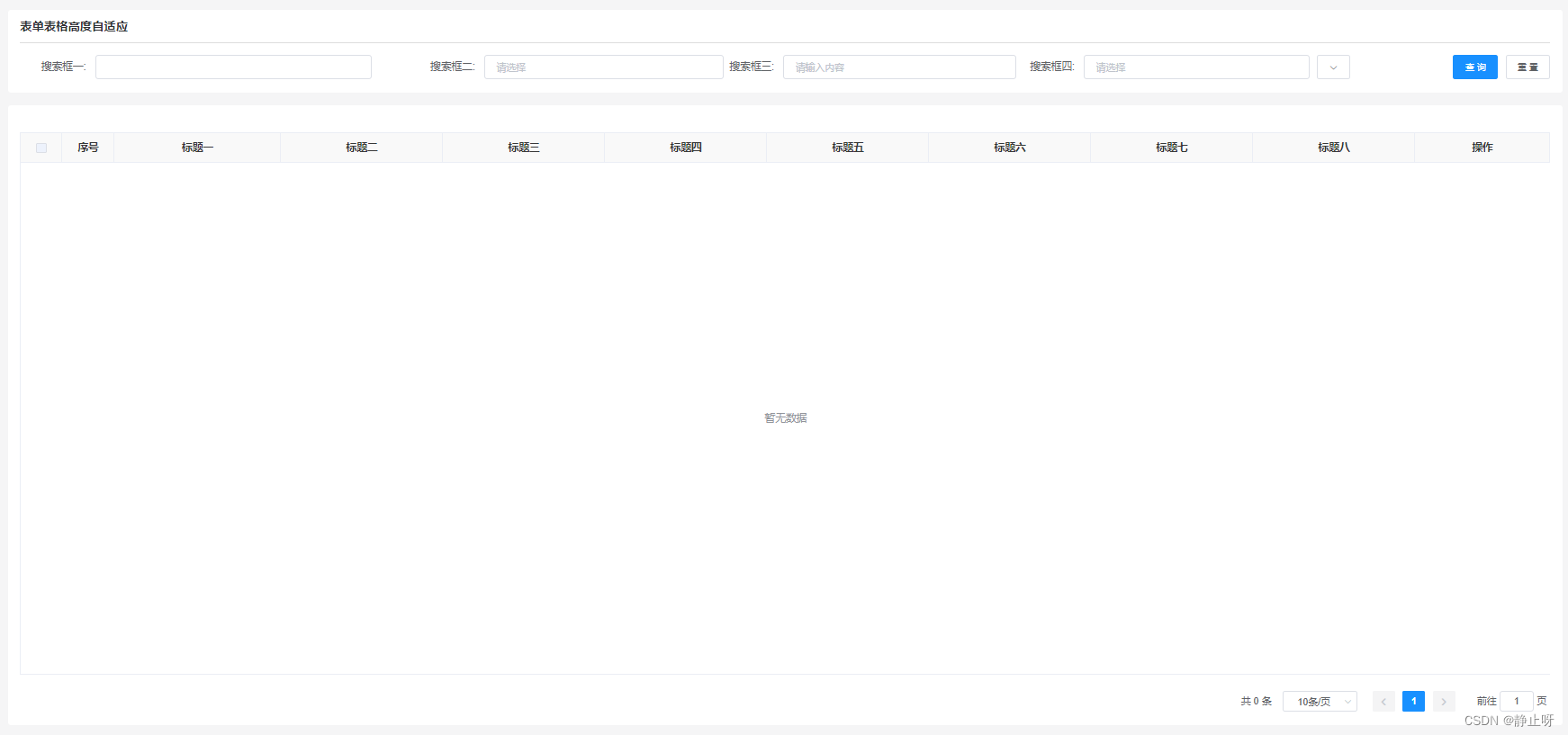
element表单搜索框与表格高度自适应
一般在后台管理系统中,表单搜索框和表格的搭配是非常常见的,如下所示: 在该图中,搜索框有五个,分为了两行排列。但根据大多数的UI标准,搜索框默认只显示一行,多余的需要进行隐藏。此时的页面被…...

MySQL使用技巧整理
title: MySQL使用技巧整理 date: 2021-04-11 00:00:00 tags: MySQL categories:数据库 重建索引 索引可能因为删除,或者页分裂等原因,导致数据页有空洞,重建索引的过程会创建一个新的索引,把数据按顺序插入,这样页面…...

七大设计原则之里氏替换原则应用
目录1 里氏替换原则2 里氏替换原则应用1 里氏替换原则 里氏替换原则(Liskov Substitution Principle,LSP)是指如果对每一个类型为 T1 的对象 o1,都有类型为 T2 的对象 o2,使得以 T1 定义的所有程序 P 在所有的对象 o1 都替换成 o2 时,程序 P…...

1行Python代码去除图片水印,网友:一干二净
大家好,这里是程序员晚枫。 最近小明在开淘宝店(店名:爱吃火锅的少女),需要给自己的原创图片加水印,于是我上次给她开发了增加水印的功能:图片加水印,保护原创图片,一行…...
)
Connext DDS属性配置参考大全(2)
DDSSecure安全com.rti.servcom.rti.serv.load_plugin...
)
一起Talk Android吧(第四百九十二回:精简版动画)
文章目录概念介绍使用方法示例代码经验总结各位看官们大家好,上一回中咱们说的例子是"动画集合:AnimatorSetBuilder",这一回中咱们说的例子是" 精简版动画"。闲话休提,言归正转,让我们一起Talk Android吧&…...
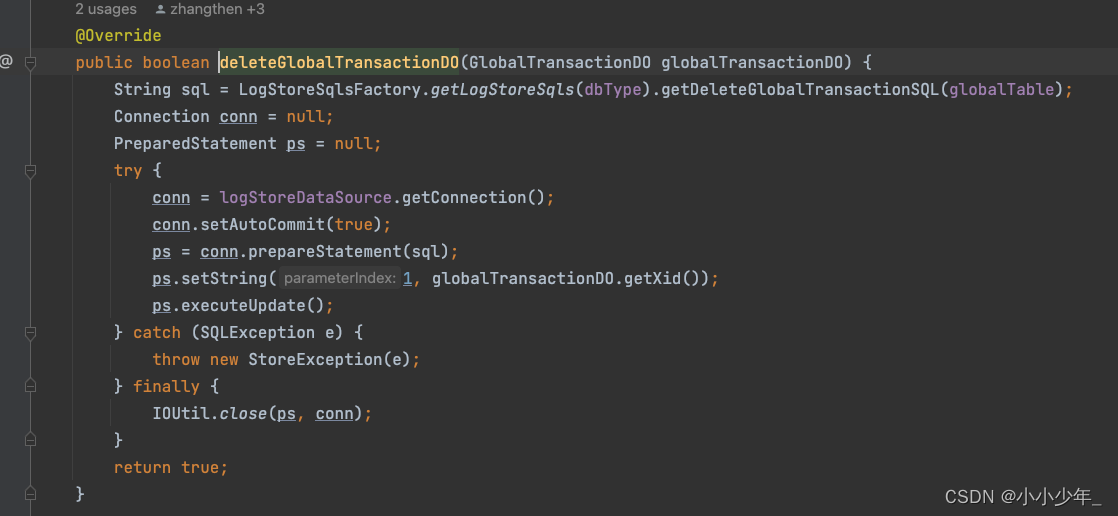
seata源码-全局事务回滚服务端源码
这篇博客来记录在发起全局事务回滚时,服务端接收到netty请求是如何处理的 1. 发起全局事务回滚请求 在前面的博客中,有说到过,事务发起者在发现分支事务执行异常之后,会提交全局事务回滚的请求到netty服务端,这里是发…...
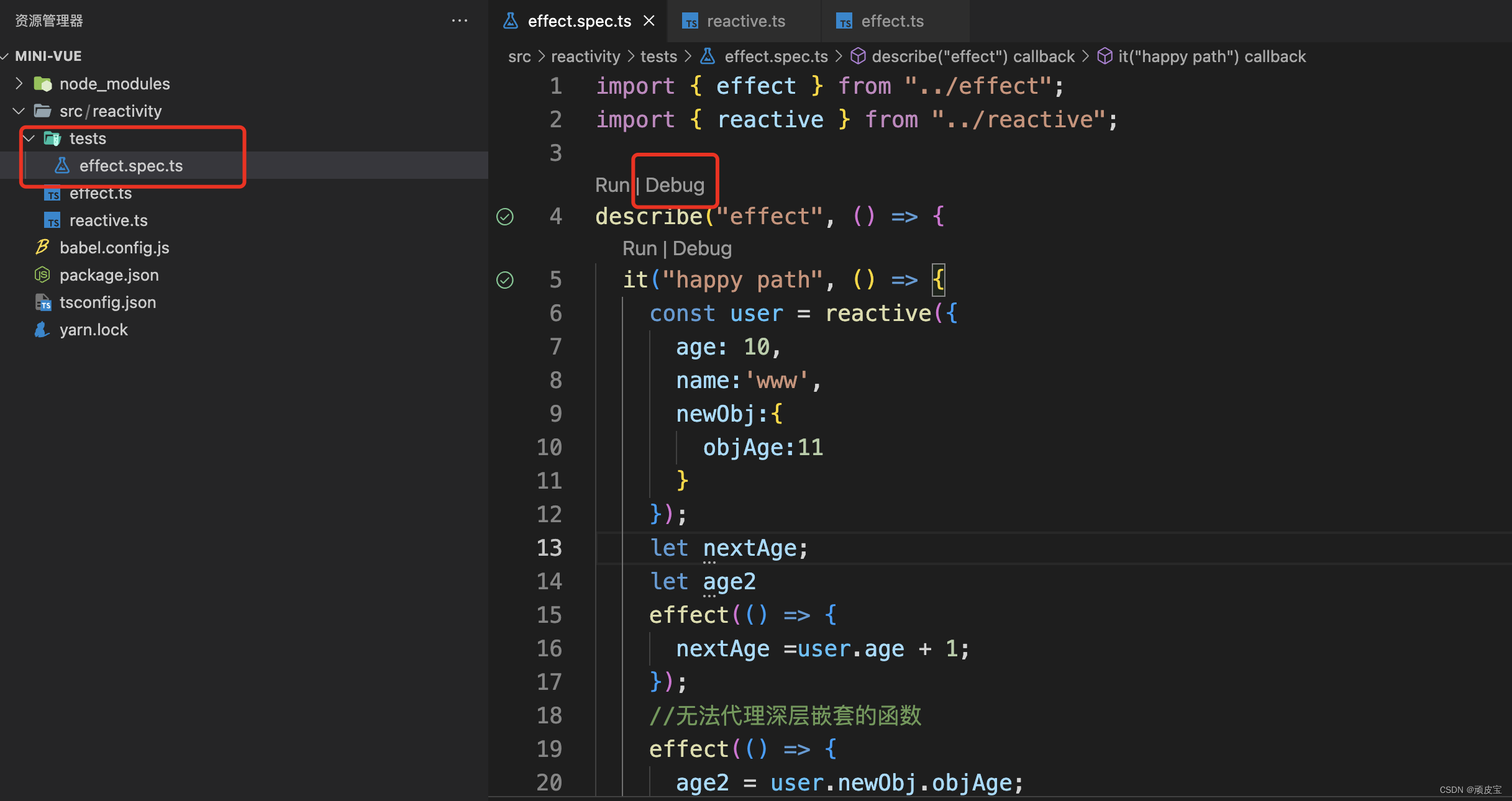
【Vue3源码】第一章 effect和reactive
文章目录【Vue3源码】第一章 effect和reactive前言1、实现effect函数2、封装track函数(依赖收集)3、封装reactive函数4、封装trigger函数(依赖触发)5、单元测试【Vue3源码】第一章 effect和reactive 前言 今天就正式开始Vue3源码…...

C函数指针
函数指针是指向函数的指针变量。通常我们说的指针变量是指向一个整型、数组或字符型等变量,而函数指针是指向函数。函数指针可以像一般函数一样,用于调用函数、传递参数。函数指针变量的声明:typedef int (*fun_ptr)(int,int); // 声明一个指…...

2023同等学力申请硕士计算机综合国考
同等学力国考报名要开始了 2023年2月15日,中国教育考试网和“全国同等学力人员申请硕士学位管理工作信息平台”(https://tdxl.chsi.com.cn,联系服务电话:010-67410388)公布报名工作通知。考生须按照通知要求进行注册或…...

英语基础-并列句概述
什么是并列句?并列句就是用连词把独立的句子连接起来,使得句子之间产生并列的逻辑。 1. 并列句中的逻辑 1. 小明步行上学,小红骑自行车上班。 Ming goes to school on foot,and Hong goes to work by bike. 平行逻辑 2. 小红经常玩手机…...
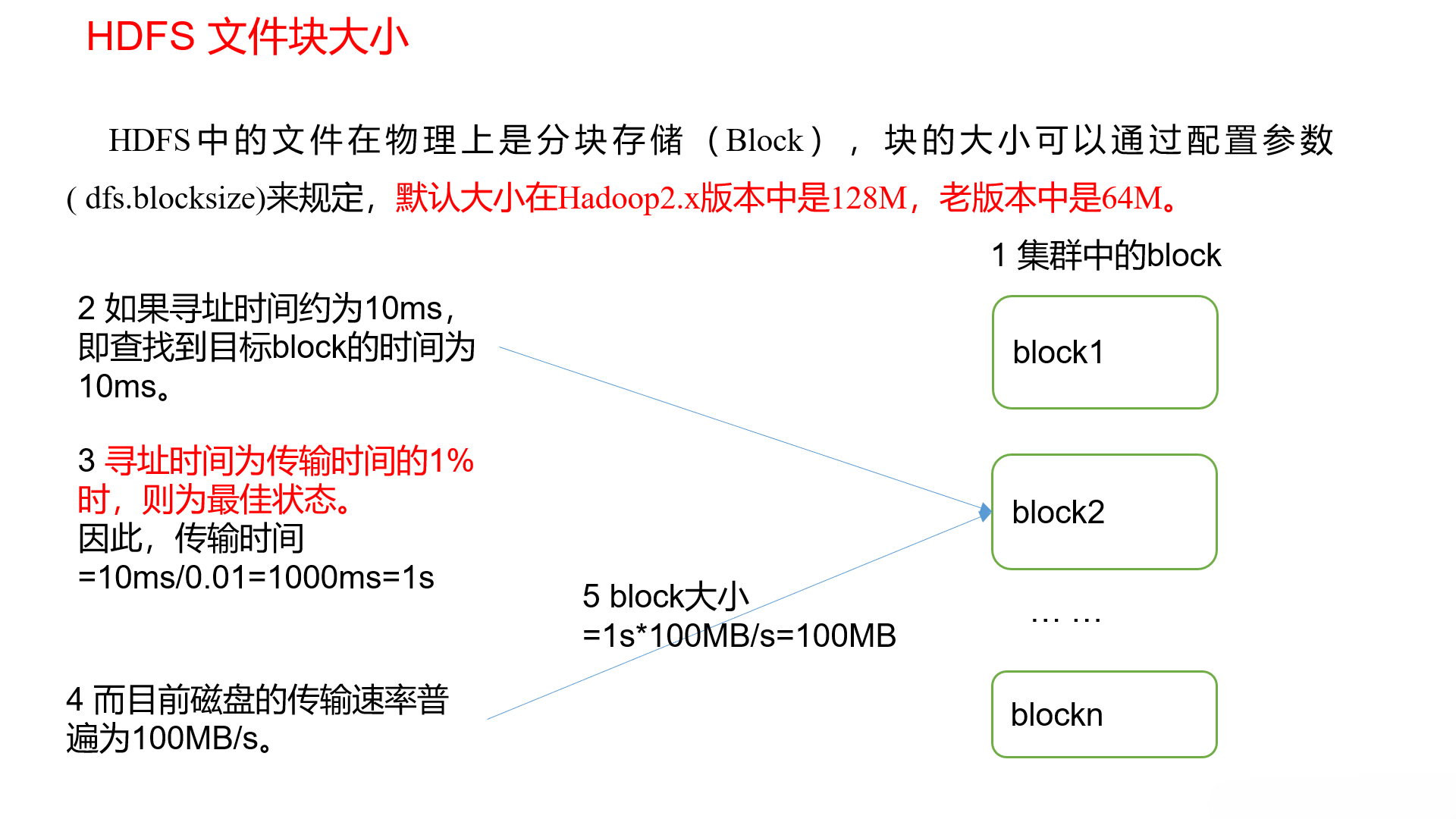
大数据框架之Hadoop:HDFS(一)HDFS概述
1.1HDFS产出背景及定义 HDFS 产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件…...
20230210组会论文总结
目录 【Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method】 【ShuffleMixer: An Efficient ConvNet for Image Super-Resolution】 【A Close Look at Spatial Modeling: From Attention to Convolution 】 【DEA-Net: Single i…...

Python - 数据容器dict(字典)
目录 字典的定义 字典数据的获取 字典的嵌套 字典的各种操作 新增与更新元素 [Key] Value 删除元素 pop和del 清空字典 clear 获取全部的键 keys 遍历字典 容器通用功能总览 字典的定义 使用{},不过存储的元素是一个个的:键值对&#…...

一站式融合赋能,企业级私有化视频会议系统EasyDSS助力企业培训全流程闭环管理
传统企业培训往往面临诸多痛点,线下培训受地域、时间限制,直播培训错过即无,核心内容无法有效沉淀,会议、直播、点播多平台切换,操作繁琐效率低,EasyDSS企业级私有化视频会议系统,打破单一功能局…...

别再折腾官方源了!用XianDian-IaaS-v2.2在CentOS7上30分钟搞定OpenStack最小化部署
30分钟极速部署OpenStack:XianDian-IaaS在CentOS7上的实战指南 OpenStack作为开源云计算平台的标杆,其强大的灵活性和模块化设计吸引了大量企业用户。但官方部署流程的复杂性往往让初学者望而却步——依赖项冲突、版本兼容性问题、繁琐的配置步骤&#x…...

Aurix/Tricore实验解析:从链接脚本到汇编指令的Trap向量表构建
1. 理解Trap机制与向量表基础 在Aurix/Tricore架构中,Trap(陷阱)是处理器响应异常事件的硬件机制,相当于汽车的安全气囊——平时看不见,但遇到碰撞时会立即触发保护。与中断不同,Trap是同步触发的ÿ…...
!)
AI Agent工程师进阶指南:掌握核心技能,冲击高薪(P7-P8必备)!
本文详细介绍了AI Agent工程师的能力分层,从API调用工程师到系统设计工程师再到基础设施架构师,明确了不同层级的能力要求和市场现状。文章深入剖析了核心技术栈,包括向量数据库、RAG系统、Agent架构、Memory系统以及生产化工程等关键领域&am…...
)
机械革命无界14X实战:用VMware 17.5给AMD 8845HS装macOS 15(附8核/16核OC引导)
机械革命无界14X实战:AMD 8845HS笔记本在VMware 17.5上运行macOS 15全攻略 最近不少技术爱好者都在尝试将macOS系统运行在AMD平台的笔记本上,尤其是搭载锐龙8845HS处理器的设备。作为一款性能强劲的移动处理器,8845HS配合780M核显确实具备运…...

如何降低ai率?盘点3个降ai率神器与5个手改技巧,降aigc全流程解析!
最近我发现很多同学都在苦恼ai率这件事,后台发来的截图里,那报告,简直红得触目惊心。 现在的系统早已是next level,不是看你用了什么词,而是在分析你的文本生成逻辑。今天这篇文章,我不讲虚的,…...

Ubuntu系统资源监控实战:从命令行到图形化工具全解析
1. 为什么需要监控Ubuntu系统资源? 刚装好的Ubuntu系统跑得飞快,用着用着突然发现电脑变卡了?浏览器开多几个标签页就开始转圈?这种情况我遇到过太多次了。后来才发现,很多时候是因为某个程序偷偷吃掉了大量CPU或内存资…...

数据驱动决策的基石:Awesome Public Datasets实用探索手册
数据驱动决策的基石:Awesome Public Datasets实用探索手册 【免费下载链接】awesome-public-datasets A topic-centric list of HQ open datasets. 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-public-datasets 在数据驱动决策日益成为商业竞…...
5个场景带你体验KISS Translator:让网页双语阅读不再是难题
5个场景带你体验KISS Translator:让网页双语阅读不再是难题 【免费下载链接】kiss-translator A simple, open source bilingual translation extension & Greasemonkey script (一个简约、开源的 双语对照翻译扩展 & 油猴脚本) 项目地址: https://gitcod…...
)
别再只测烟雾了!用STM32CubeMX+MQ-2传感器,做个厨房燃气泄漏+烟雾双检测器(附完整代码)
厨房安全卫士:基于STM32CubeMX与MQ-2的燃气烟雾双模检测系统 厨房是家庭安全事故的高发区域,燃气泄漏和烟雾积聚都可能引发严重后果。传统烟雾报警器功能单一,而市面上的复合型安防设备价格昂贵。本文将带你用STM32单片机和MQ-2气敏传感器&am…...