PyTorch张量数值计算
文章目录
- 1、张量基本运算
- 2、阿达玛积
- 3、点积运算
- 4、指定运算设备⭐
- 5、解决在GPU运行PyTorch的问题
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、张量基本运算
PyTorch 计算的数据都是以张量形式存在
可以在 CPU 中运算, 也可以在 GPU 中运算.
基本运算中,包括 add、sub、mul、div、neg 等函数,
以及这些函数的带下划线的版本 add_、sub_、mul_、div_、neg_,
其中带下划线的版本为修改原数据。
| 操作类型 | 函数 | 示例代码 | 代码解释 |
|---|---|---|---|
| 创建张量 | torch.randint | data = torch.randint(0, 10, [2, 3]) | 生成一个2x3的随机整数张量,范围在0到9之间。 |
| 不修改原数据 | add | new_data = data.add(10) | 将每个元素加上10,生成一个新张量。 |
| 修改原数据 | add_ | data.add_(10) | 将每个元素加上10,直接修改原数据。 |
| 减法 | sub | data.sub(100) | 将每个元素减去100,生成一个新张量。 |
| 乘法 | mul | data.mul(100) | 将每个元素乘以100,生成一个新张量。 |
| 除法 | div | data.div(100) | 将每个元素除以100,生成一个新张量。 |
| 取反 | neg | data.neg() | 将每个元素取反,生成一个新张量。 |
代码:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 1:25# 导入PyTorch库
import torch# 定义测试函数
def test():# 生成一个2x3的随机整数张量,范围在0到9之间data = torch.randint(0, 10, [2, 3])print(data)print('-' * 50)# 1. 不修改原数据# 使用add函数将每个元素加上10,生成一个新张量new_data = data.add(10) # 等价 new_data = data + 10print(new_data)print('-' * 50)# 2. 直接修改原数据# 注意: 带下划线的函数为修改原数据本身# 使用add_函数将每个元素加上10,直接修改原数据data.add_(10) # 等价 data += 10print(data)# 3. 其他函数# 使用sub函数将每个元素减去100,生成一个新张量print(data.sub(100))# 使用mul函数将每个元素乘以100,生成一个新张量print(data.mul(100))# 使用div函数将每个元素除以100,生成一个新张量print(data.div(100))# 使用neg函数将每个元素取反,生成一个新张量print(data.neg())
效果:

2、阿达玛积
阿达玛积(Hadamard Product),又称为元素积(element-wise product),是指两个相同尺寸的矩阵对应元素相乘得到的新矩阵。
阿达玛积与矩阵乘法不同,矩阵乘法是行与列的点积,而阿达玛积只是简单的元素相乘。
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 2:25
import torchdef test():data1 = torch.tensor([[1, 2], [3, 4]])data2 = torch.tensor([[5, 6], [7, 8]])# 第一种方式data = torch.mul(data1, data2)print(data)print('-' * 50)# 第二种方式data = data1 * data2print(data)print('-' * 50)if __name__ == '__main__':test()

3、点积运算
点积(Dot Product)是向量计算中的一种基本运算,它将两个向量对应元素相乘并求和。
点积在机器学习和深度学习中广泛应用于各种计算,如向量相似性、神经网络中的加权和计算等。

点积运算要求第一个矩阵 shape: (n, m),
第二个矩阵 shape: (m, p),
两个矩阵点积运算 shape 为: (n, p)。
- 运算符 @ 用于进行两个矩阵的点乘运算
- torch.mm 用于进行两个矩阵点乘运算, 要求输入的矩阵为2维
- torch.bmm 用于批量进行矩阵点乘运算, 要求输入的矩阵为3维
- torch.matmul 对进行点乘运算的两矩阵形状没有限定.
- 对于输入都是二维的张量相当于 mm 运算.
- 对于输入都是三维的张量相当于 bmm 运算
- 对数输入的 shape 不同的张量, 对应的最后几个维度必须符合矩阵运算规则
三维矩阵:

torch.randn(3, 4, 5)参数个数不限,从左到右依次是维度。
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 2:35
import torch# 1. 点积运算
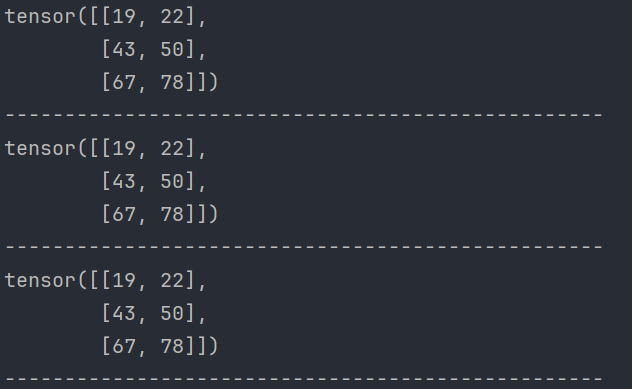
def test01():# 创建两个张量,data1 为 3x2 矩阵,data2 为 2x2 矩阵data1 = torch.tensor([[1, 2], [3, 4], [5, 6]])data2 = torch.tensor([[5, 6], [7, 8]])# 第一种方式:使用 @ 运算符进行矩阵乘法(点积运算)data = data1 @ data2print(data)print('-' * 50)# 第二种方式:使用 torch.mm 函数进行矩阵乘法data = torch.mm(data1, data2)print(data)print('-' * 50)# 第三种方式:使用 torch.matmul 函数进行矩阵乘法data = torch.matmul(data1, data2)print(data)print('-' * 50)# 2. torch.mm 和 torch.matmul 的区别
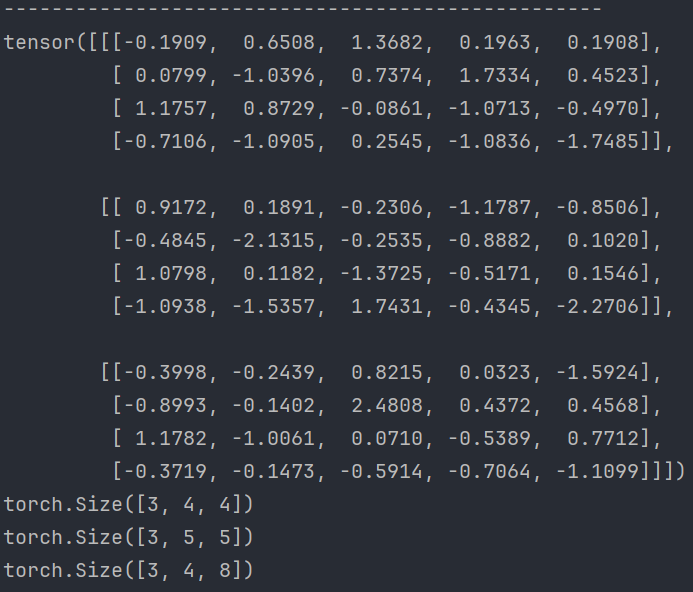
def test02():# matmul 可以处理不同维度的张量# 第一个张量的形状为 (3, 4, 5)# 第二个张量的形状为 (5, 4)# torch.mm 只能处理二维矩阵的乘法,而 matmul 可以处理高维度张量的乘法print(torch.randn(3, 4, 5))print(torch.matmul(torch.randn(3, 4, 5), torch.randn(5, 4)).shape)# 反转张量的顺序,第二个张量的形状为 (3, 4, 5)# 第一个张量的形状为 (5, 4)# 结果形状仍然符合矩阵乘法规则print(torch.matmul(torch.randn(5, 4), torch.randn(3, 4, 5)).shape)# 3. torch.bmm 函数的用法
def test03():# 批量点积运算# 第一个维度为 batch_size# data1 的形状为 (3, 4, 5)# data2 的形状为 (3, 5, 8)# torch.bmm 可以处理批量的矩阵乘法data1 = torch.randn(3, 4, 5)data2 = torch.randn(3, 5, 8)# 进行批量矩阵乘法运算,结果形状为 (3, 4, 8)data = torch.bmm(data1, data2)print(data.shape)
4、指定运算设备⭐
PyTorch 默认会将张量创建在 CPU 控制的内存中, 即: 默认的运算设备为 CPU。
我们也可以将张量创建在 GPU 上, 能够利用对于矩阵计算的优势加快模型训练。
将张量移动到 GPU 上有两种方法:
- 使用 cuda 方法
- 直接在 GPU 上创建张量
- 使用 to 方法指定设备
| 指定设备的方式 | 示例代码 | 代码解释 |
|---|---|---|
使用 cuda 方法 | python data = torch.tensor([10, 20, 30]) data = data.cuda() | 使用 cuda() 方法将张量从 CPU 移动到 GPU。 |
| 在创建张量时指定设备 | python data = torch.tensor([10, 20, 30], device='cuda:0') | 在创建张量时,通过 device 参数直接指定设备为 GPU。 |
使用 to 方法 | python data = torch.tensor([10, 20, 30]) data = data.to('cuda:0') | 使用 to() 方法将张量从 CPU 移动到 GPU。 |
使用 cpu 方法 | python data = data.cpu() | 使用 cpu() 方法将张量从 GPU 移动到 CPU。 |
使用 torch.device | python device = torch.device("cuda" if torch.cuda.is_available() else "cpu") tensor = torch.randn(3, 4, 5, device=device) | 使用 torch.device 动态选择设备,并在创建张量时指定设备。 |
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 2:58
import torch
import torchvision# 1. 使用 cuda 方法
def test01():data = torch.tensor([10, 20, 30])print('存储设备:', data.device)# 如果安装的不是 gpu 版本的 PyTorch# 或电脑本身没有 NVIDIA 卡的计算环境# 下面代码可能会报错data = data.cuda()print('存储设备:', data.device)# 使用 cpu 函数将张量移动到 cpu 上data = data.cpu()print('存储设备:', data.device)# 输出结果:# 存储设备: cpu# 存储设备: cuda:0# 存储设备: cpu# 2. 直接将张量创建在 GPU 上
def test02():data = torch.tensor([10, 20, 30], device='cuda:0')print('存储设备:', data.device)# 使用 cpu 函数将张量移动到 cpu 上data = data.cpu()print('存储设备:', data.device)# 输出结果:# 存储设备: cuda:0# 存储设备: cpu# 3. 使用 to 方法
def test03():data = torch.tensor([10, 20, 30])print('存储设备:', data.device)data = data.to('cuda:0')print('存储设备:', data.device)# 输出结果:# 存储设备: cpu# 存储设备: cuda:0# 4. 存储在不同设备的张量不能运算
def test04():data1 = torch.tensor([10, 20, 30], device='cuda:0')data2 = torch.tensor([10, 20, 30])print(data1.device, data2.device)# RuntimeError: Expected all tensors to be on the same device,# but found at least two devices, cuda:0 and cpu!data = data1 + data2print(data)def test05():# 检查CUDA是否可用,并选择设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# device = "cpu"print("Using device:", device)# 构建一个形状为 (3, 4, 5) 的随机张量,并指定设备tensor = torch.randn(3, 4, 5, device=device)print("Tensor:", tensor)print("Shape:", tensor.shape)print("Device:", tensor.device)data = torch.randn(5, 4, device=device)print(torch.matmul(tensor, data))def test06():print("PyTorch版本: ", torch.__version__) # 打印PyTorch版本print("torchvision版本 ", torchvision.__version__) # 打印torchvision版本print("CUDA是否可用: ", torch.cuda.is_available()) # 检查CUDA是否可用if __name__ == '__main__':test04()
5、解决在GPU运行PyTorch的问题
请参考我的这篇文章:https://xzl-tech.blog.csdn.net/article/details/140478985
相关文章:
PyTorch张量数值计算
文章目录 1、张量基本运算2、阿达玛积3、点积运算4、指定运算设备⭐5、解决在GPU运行PyTorch的问题 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法&am…...

Dockerfile相关命令
Dockerfile Dockerfile 是一个用来构建Docker镜像的文本文件,包含了一系列构建镜像所需的指令和参数。 指令详解 Dockerfile 指令说明FROM指定基础镜像,用于后续的指令构建,必须为第一个命令MAINTAINER指定Dockerfile的作者/维护者。&…...

【AI教程-吴恩达讲解Prompts】第1篇 - 课程简介
文章目录 简介Prompt学习相关资源 两类大模型原则与技巧 简介 欢迎来到面向开发者的提示工程部分,本部分内容基于吴恩达老师的《Prompt Engineering for Developer》课程进行编写。《Prompt Engineering for Developer》课程是由吴恩达老师与 OpenAI 技术团队成员 I…...

Leetcode - 周赛406
目录 一,3216. 交换后字典序最小的字符串 二,3217. 从链表中移除在数组中存在的节点 三,3218. 切蛋糕的最小总开销 I 四,3219. 切蛋糕的最小总开销 II 一,3216. 交换后字典序最小的字符串 本题要求交换一次相邻字符…...

【JavaScript 算法】拓扑排序:有向无环图的应用
🔥 个人主页:空白诗 文章目录 一、算法原理二、算法实现方法一:Kahn算法方法二:深度优先搜索(DFS)注释说明: 三、应用场景四、总结 拓扑排序(Topological Sorting)是一种…...

Fastgpt本地或服务器私有化部署常见问题
一、错误排查方式 遇到问题先按下面方式排查。 docker ps -a 查看所有容器运行状态,检查是否全部 running,如有异常,尝试docker logs 容器名查看对应日志。容器都运行正常的,docker logs 容器名 查看报错日志带有requestId的,都是 OneAPI 提示错误,大部分都是因为模型接…...

基于深度学习的股票预测
基于深度学习的股票预测是一项复杂且具有挑战性的任务,涉及金融数据的分析和预测。其目的是利用深度学习模型来预测股票价格的走势,从而帮助投资者做出更为准确的投资决策。以下是对这一领域的系统介绍: 1. 任务和目标 股票预测的主要任务和…...

UNiapp 微信小程序渐变不生效
开始用的一直是这个,调试一直没问题,但是重新启动就没生效,经查询这个不适合小程序使用:不适合没生效 background-image:linear-gradient(to right, #33f38d8a,#6dd5ed00); 正确使用下面这个: 生效,适合…...

FinClip 率先入驻 AWS Marketplace,加速全球市场布局
近日,凡泰极客旗下的小程序数字管理平台 FinClip 已成功上线亚马逊云科技(AWS)Marketplace。未来,FinClip 将主要服务于海外市场的开放银行、超级钱包、财富管理、社交电商、智慧城市解决方案等领域。 在全球市场的多样性需求推动…...

ChatGPT对话:Windows如何将Python训练模型转换为TensorFlow.js格式
【编者按】编者目前正在做手机上的人工智能软件,第一次做这种工作,从一些基本工作开始与ChatGPT交流。对初学者应该有帮助。 一天后修改文章补充内容: 解决TensorFlow 2.X与TensorFlow Decision Forests版本冲突问题: 在使用tens…...

封装网络请求 鸿蒙APP HarmonyOS ArkTS
一、效果展示 通过在页面直接调用 userLogin(params) 方法,获取登录令牌 二、申请网络权限 访问网络时候首先需要申请网络权限,需要修改 src/main 目录下的 module.json5 文件,加入 requestPermissions 属性,详见官方文档 【声明权…...

2024年度上半年中国汽车保值率报告
来源:中国汽车流通协会&精真估 近期历史回顾: 2024上半年房地产企业数智化转型报告.pdf 2024国产院线电影路演数据洞察报告.pdf 空间数据智能大模型研究-2024年中国空间数据智能战略发展白皮书.pdf 2024年全球资产管理报告 2024年中型律师事务所的法…...

Go语言之内存分配
文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ Go 语言程序所管理的虚拟内存空间会被分为两部分:堆内…...

北京交通大学《深度学习》专业课,实验3卷积、空洞卷积、残差神经网络实验
一、实验要求 1. 二维卷积实验(平台课与专业课要求相同) ⚫ 手写二维卷积的实现,并在至少一个数据集上进行实验,从训练时间、预测精 度、Loss变化等角度分析实验结果(最好使用图表展示) ⚫ 使用torch.nn…...

WPF中UI元素继承关系
在 WPF(Windows Presentation Foundation)框架中,UI 元素是基于一个层次化的类结构构建的,这个结构以 FrameworkElement 类为核心,大多数 UI 元素都是 FrameworkElement 或其派生类的子类。FrameworkElement 类本身又继…...

qml 实现一个listview
主要通过qml实现listvie功能,主要包括右键菜单,滚动条,拖动改变内容等,c 与 qml之间的变量和函数的调用。 main.cpp #include <QQuickItem> #include <QQmlContext> #include "testlistmodel.h" int main…...

【Leetcode】十六、深度优先搜索 宽度优先搜索 :二叉树的层序遍历
文章目录 1、深度优先搜索算法2、宽度优先搜索算法3、leetcode102:二叉树的层序遍历4、leetcode107:二叉树的层序遍历II5、leetcode938:二叉搜索树的范围和 1、深度优先搜索算法 深度优先搜索,即DFS,从root节点开始&a…...

Ruby教程
Ruby是一种动态的、面向对象的、解释型的脚本语言,以其简洁和易读性而闻名。Ruby的设计哲学强调程序员的生产力和代码的可读性,同时也融合了功能性和面向对象编程的特性。 以下是一个基础的Ruby教程,涵盖了一些基本概念和语法: …...

react + pro-components + ts完成单文件上传和批量上传
上传部分使用的是antd中的Upload组件,具体如下: GradingFilingReportUpload方法是后端已经做好文件流,前端只需要调用接口即可 单文件上传 <Uploadkey{upload_${record.id}}showUploadList{false}accept".xlsx"maxCount{1}customRequest{({ file }) > {const …...

暑假第一周——ZARA仿写
iOS学习 前言首页:无限轮播图商城:分类我的:自定义cell总结 前言 结束了UI的基础学习,现在综合运用开始写第一个demo,在实践中提升。 首页:无限轮播图 先给出效果: 无限轮播图,顾…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...